
Cloud Computing (8): Multi-Cloud and Hybrid Architecture
Series finale. Multi-cloud vs hybrid cloud strategy, the 6R migration framework, hybrid networking, cross-cloud data sync and conflict resolution, vendor lock-in mitigation, disaster recovery RPO/RTO planning, FinOps cost optimization, and the trends shaping the next decade.

The first article in this series asked, “What is the cloud, and why does it matter?” Eight articles later, the question has evolved into something more practical: Which clouds, in what combination, and how do you manage them without losing your mind? Multi-cloud and hybrid architectures are how serious organizations answer that question. They distribute workloads across providers and on-premises infrastructure for resilience, cost optimization, and strategic flexibility — but they introduce a new class of problems that single-cloud architectures never face.
This final article covers the strategic, technical, and operational aspects of running across multiple clouds. We start by discussing when each pattern makes sense (it’s not always), walk through the migration framework practitioners use, delve into the network and data plumbing that makes cross-cloud work, and conclude with cost discipline, lock-in mitigation, and the trends — edge, FinOps, sovereign clouds, sustainability — shaping the next decade. The article ends, as the series does, with a synthesis tying all eight parts together.
What You Will Learn#
- Multi-cloud vs hybrid cloud vs sovereign cloud: definitions, drivers, when each is right
- The 6R migration framework and how to actually apply it
- Hybrid networking: VPN, Direct Connect / ExpressRoute, SD-WAN — bandwidth, latency, cost trade-offs
- Cross-cloud data synchronization: sync, async, CDC; conflict resolution strategies
- Multi-cloud management platforms: Anthos, Rancher, OpenShift, Crossplane
- Vendor lock-in: the five dimensions and concrete mitigations for each
- Disaster recovery patterns with RPO/RTO planning that survives an audit
- FinOps cost optimization: reserved instances, spot, right-sizing, the egress trap
- Future trends: edge, serverless portability, sovereignty, sustainability
- A capstone synthesis of the entire 8-part Cloud Computing series
Prerequisites#
- Solid understanding of at least one cloud provider
- Familiarity with Kubernetes and Infrastructure as Code (Terraform)
- Parts 1-7 of this series provide the necessary foundation
Multi-Cloud, Hybrid, Sovereign: Three Patterns, Three Drivers#
The word “multi-cloud” gets used loosely. Three distinct patterns sit underneath it, each driven by different business pressures.
| Model | Definition | Primary driver |
|---|---|---|
| Multi-cloud | Multiple public clouds (AWS + Azure + GCP) | Avoid lock-in, best-of-breed services, leverage in negotiation |
| Hybrid cloud | Public cloud + on-premises / private cloud | Regulatory constraints, latency-sensitive legacy, sunk capex |
| Sovereign cloud | Cloud region operating under a specific jurisdiction | Data residency, regulatory isolation (e.g., EU GAIA-X, China gov cloud) |
| Hybrid multi-cloud | All of the above combined | Maximum flexibility — and maximum operational surface |
When Multi-cloud Actually Makes Sense#
Multi-cloud is trendy but also expensive: each additional cloud adds another set of IAM, networking, billing, monitoring, security, and team skills to maintain. Here are the legitimate drivers:
- Risk mitigation at scale. A multi-region outage in your primary provider takes you down. For organizations whose downtime cost exceeds the multi-cloud premium, the math works.
- Best-of-breed services. GCP for ML/data warehousing (BigQuery, Vertex), AWS for breadth and ecosystem, Azure for Microsoft estate (AD, M365 integration). When the productivity gap is real, paying the integration tax is worth it.
- Compliance and data sovereignty. GDPR, India’s DPDP, China’s PIPL, and dozens of sector-specific regulations dictate where data may live. Multi-cloud is sometimes the only way to satisfy all of them.
- Negotiation leverage. Credible threat to migrate keeps your vendor honest. An AWS-only shop has no leverage on AWS pricing.
- Acquisition reality. You acquired a company on a different cloud. You’re now multi-cloud whether you wanted to be or not.
A poor driver is “cloud-agnostic for its own sake.” Building everything to the lowest common denominator discards the differentiation that led you to choose a specific cloud. Most successful multi-cloud strategies are workload-specific, not application-portable.
Architecture Patterns#
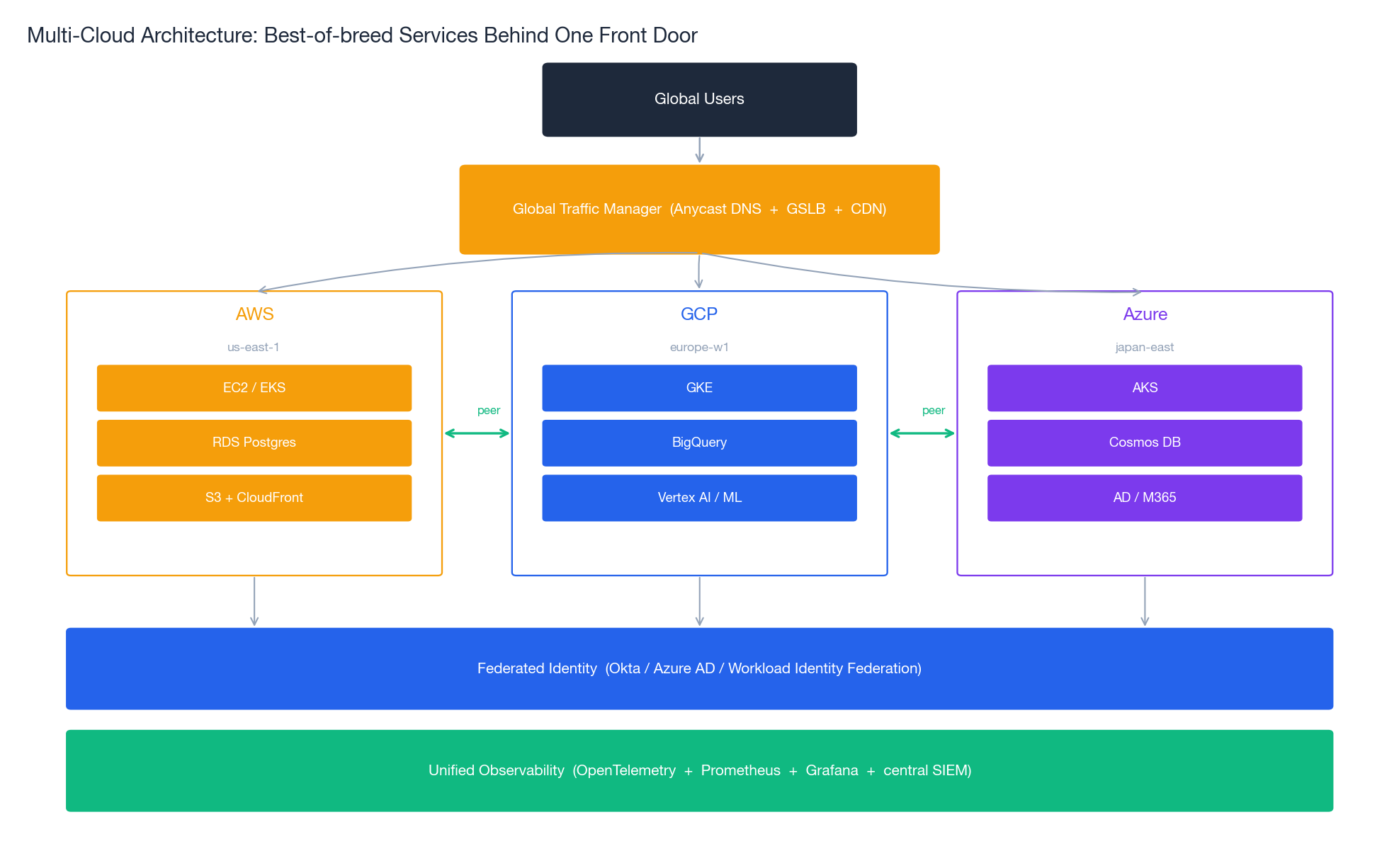
The architecture above shows the canonical multi-cloud setup: a global traffic manager (GSLB / Anycast DNS / multi-CDN) routes users to the best regional backend; each cloud runs the workloads it does best; identity and observability layers span all of them.
| Pattern | Description | When to use |
|---|---|---|
| Workload-specific | Different apps on different clouds (analytics on GCP, edge on AWS) | Most common; pragmatic |
| Active-active | Same app on multiple clouds, all serving | True high-availability and lock-in mitigation; complex sync |
| Active-passive DR | Primary on Cloud A, standby on Cloud B | Lower cost, longer recovery |
| Geographic | AWS US, Azure EU, GCP APAC | Latency optimization, data residency |
| Cloud bursting | On-prem baseline, cloud for peaks | Predictable base + unpredictable spikes |
A common mistake is adopting the active-active pattern too early. It is the most expensive pattern by far — you pay for full capacity twice, plus the engineering costs of cross-cloud data sync, conflict resolution, and dual operations. Active-passive DR with quarterly failover drills provides most of the resilience at a fraction of the cost.
The 6R Migration Framework#
Every workload moving to (or between) clouds follows one of six paths. Gartner’s 6R framework is the lingua franca migration teams use to classify and plan:
| Strategy | What it is | Speed | Risk | Cloud-native value |
|---|---|---|---|---|
| Rehost (lift and shift) | Same VM, new infrastructure | Fast | Low | Minimal — you get reliability, not optimization |
| Replatform (lift and tinker) | Modest changes (managed DB, container) | Medium | Low-Med | Moderate — meaningful operational wins |
| Repurchase (drop and shop) | Replace with SaaS | Medium | Medium | High — if the SaaS fits |
| Refactor (re-architect) | Rebuild as cloud-native | Slow | High | Maximum — and maximum risk |
| Retire | Decommission | Fast | Low | N/A — the best migration is the one you don’t do |
| Retain | Keep on-prem (for now) | N/A | None | N/A — not everything needs to move |
How to Actually Apply It#
The mistake teams make is treating 6R as a debate. It is a classification exercise. For each application:
- Inventory. Catalog every app, its tech stack, its dependencies, its actual usage. Tools like AWS Application Discovery Service or Azure Migrate help.
- Classify. Apply 6R. Most apps land on Rehost or Retire; a small set are worth Refactoring.
- Prioritize. Two axes: business value of moving vs migration risk. Start in the high-value, low-risk quadrant.
- Execute in waves. 5-15 apps per wave. Validate, learn, adjust the playbook, then do the next wave.
- Optimize after. Right-sizing and reserved capacity come after you have stable traffic patterns — typically 60-90 days post-migration.
The most important rule: the migration plan is a hypothesis. Plan to revise it after wave 1.
Hybrid Cloud Networking: Picking the Right Pipe#
The connection between on-prem (or one cloud) and another cloud is the load-bearing piece of any hybrid architecture. Get this wrong and everything downstream is painful.
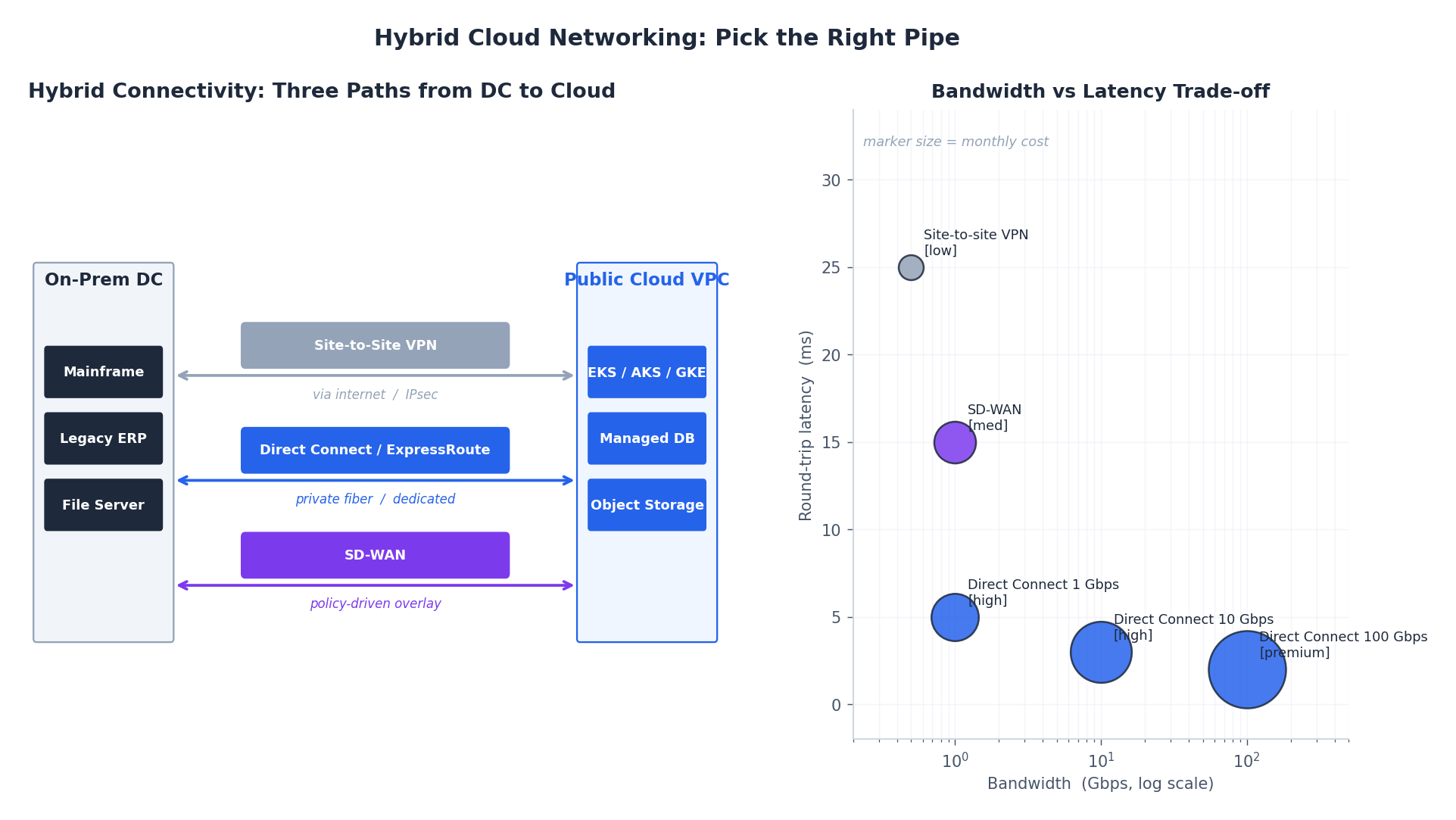
| Option | Bandwidth | Latency | Setup time | Monthly cost | When |
|---|---|---|---|---|---|
| Site-to-site VPN | Internet-limited (~ 1 Gbps practical) | High, variable (20-50 ms) | Minutes | Low | Dev, test, low-traffic prod |
| Direct Connect / ExpressRoute / Interconnect | 1 / 10 / 100 Gbps | Low, predictable (1-5 ms) | Weeks (physical fiber) | High | Production with consistent traffic |
| SD-WAN overlay | Internet + private mix | Optimized via routing | Days | Medium | Multi-site, multi-cloud, dynamic policies |
| Transit Gateway / vWAN / NCC | High | Hub-and-spoke topology | Days | Medium | Many VPCs/sites needing connectivity |
Network Topology Patterns#
- Hub-and-spoke — a central transit hub connects all sites and clouds. Simpler routing and centralized firewall, at the cost of being a potential bottleneck. The default for most enterprises.
- Full mesh — every site directly connected to every other. Optimal latency, exponential management complexity. Only viable for small numbers of sites.
- Hybrid mesh — direct paths for latency-critical traffic (DC <-> primary cloud), hub-and-spoke for the rest. Best of both worlds; the operational gold standard.
Security Across the Pipe#
Whatever pipe you pick, security on top is non-negotiable:
- Encrypt everything — IPsec for VPN, MACsec for Direct Connect (yes, even the “private” line), TLS for application-layer.
- Federate identity — Azure AD / Okta / Google Workload Identity Federation, single source of truth across clouds. Per-cloud identity siloes are how leaks happen.
- Microsegment — treat each cloud and on-prem as separate trust zones; default-deny between them, explicit allows for known flows.
- Centralized SIEM — ship logs from every environment to one place. Fragmented log silos mean attackers move freely between them.
Cross-Cloud Data Synchronization#
Data is the hardest part of multi-cloud. Compute is portable; data has gravity.
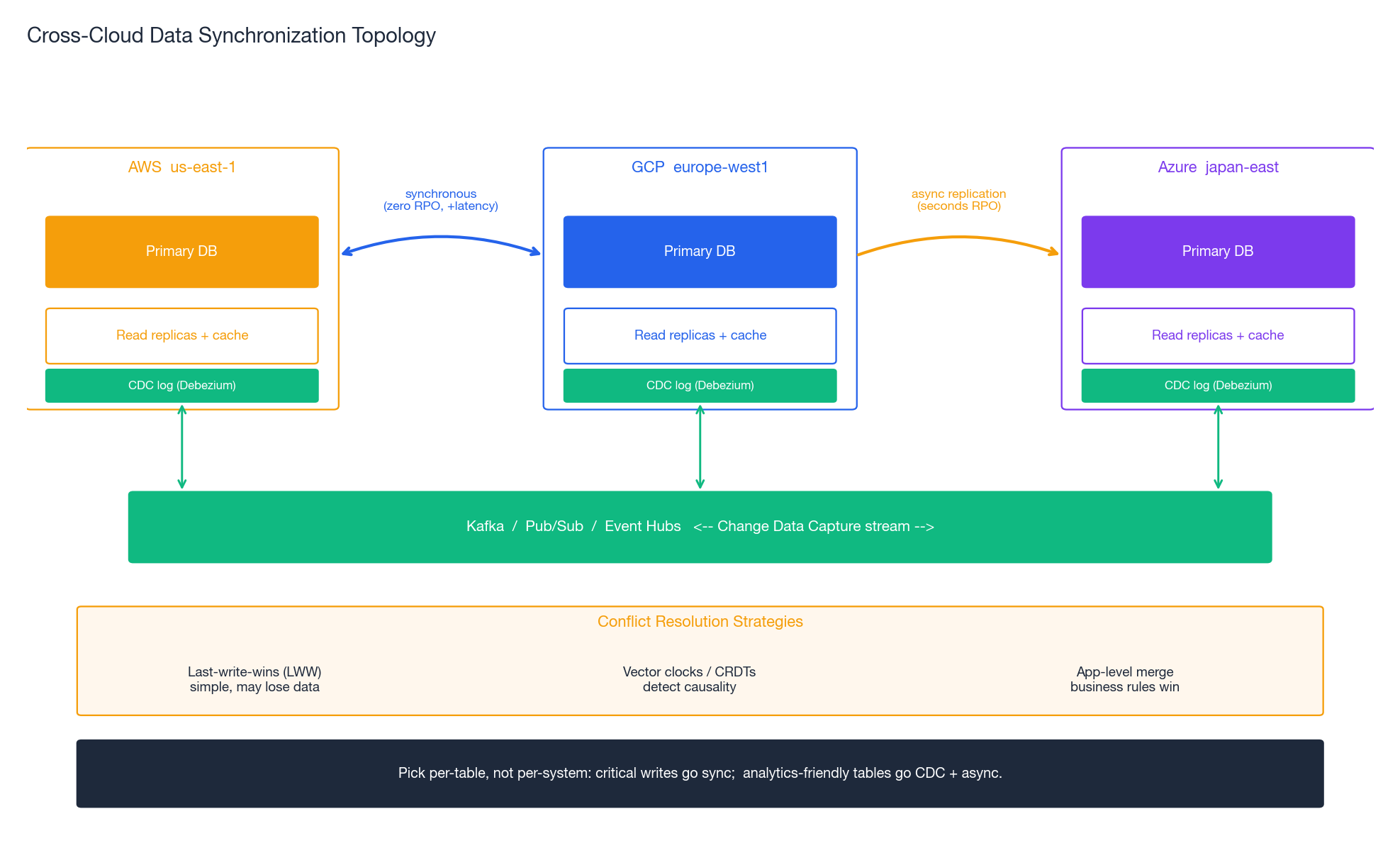
Sync Patterns and Their Trade-offs#
| Pattern | Consistency | Complexity | RPO | Use case |
|---|---|---|---|---|
| Synchronous replication | Strong | High | 0 | Financial transactions, zero data loss tolerance |
| Async replication (master-replica) | Eventual (lag = seconds) | Low | seconds | Read scaling, DR with small loss tolerance |
| Multi-master | Eventual + conflicts | Very high | 0 (writes) | Global writes, geographically distributed users |
| Change Data Capture (CDC) | Eventual (stream-based) | Medium | seconds-minutes | Analytics pipelines, event-driven architectures |
| Snapshot replication | Stale (snapshot age) | Low | hours | Cold DR, backups |
The crucial insight: pick per-table, not per-system. Critical writes (orders, payments) go synchronous; user activity logs go CDC + async; static reference data syncs via snapshots. A blanket “all data synchronously replicated” policy is the path to a system that is both expensive and slow.
Conflict Resolution#
Multi-master replication makes conflicts inevitable. Three strategies, each with a real cost:
- Last-write-wins (LWW). Simple, deterministic, silently loses data when two writes overlap. Acceptable for things where loss is fine (cache, recently-viewed lists). Wrong for orders.
- Vector clocks / CRDTs. Detect causality precisely. Solve conflicts deterministically for data structures that have a meaningful merge (counters, sets, last-writer-wins maps). Implementation cost is real — DynamoDB, Cassandra, and Riak give you primitives, but app design must cooperate.
- Application-level merge. Custom business logic decides. Most expressive, most expensive, most error-prone. Used when business rules (“the most recent shipping address wins; the most recent billing email wins”) cannot be expressed in a generic merge.
Data Governance Across Clouds#
- Classify data by sensitivity (PII, PHI, financial, public) and applicable regulation.
- Define lifecycle policies consistently across clouds — if you must delete user data within 30 days of a request, that policy needs to exist on AWS S3, GCS, Azure Blob, and your on-prem store, with audit evidence.
- Test backup and restore across cloud boundaries quarterly. Backups that have never been restored are wishful thinking.
- Centralize audit logging. Cloud-native audit (CloudTrail, Cloud Audit Logs, Azure Monitor) shipped to a central SIEM with retention beyond what each cloud offers natively.
Multi-Cloud Management Platforms#
Once you have workloads on more than one cloud, the operational question becomes: do you manage each one with native tooling (and accept the cognitive overhead), or use a unifying platform?
| Platform | Type | Strengths | Best for |
|---|---|---|---|
| Rancher | Open source | Unified Kubernetes management across clouds and on-prem | Container-first orgs, cost-conscious |
| OpenShift | Enterprise (Red Hat) | Integrated DevOps, RHEL stack, compliance-friendly | Regulated industries, RHEL shops |
| Anthos | Managed (Google) | GCP services everywhere, GKE-anywhere model | GCP-centric orgs |
| Crossplane | Open source | Provision any cloud resource via Kubernetes API | Platform teams building IDPs |
| Terraform / OpenTofu | IaC | Declarative provisioning across all major providers | Universal — the lingua franca |
The pragmatic stack many mature multi-cloud organizations converge on: Terraform/OpenTofu for provisioning, Kubernetes (per cloud, often with Cluster API) for runtime, ArgoCD for delivery, OpenTelemetry + Prometheus + Grafana for observability. This combination is portable, vendor-supported on every cloud, and uses skills that transfer.
Vendor Lock-in: Five Dimensions, Five Mitigations#
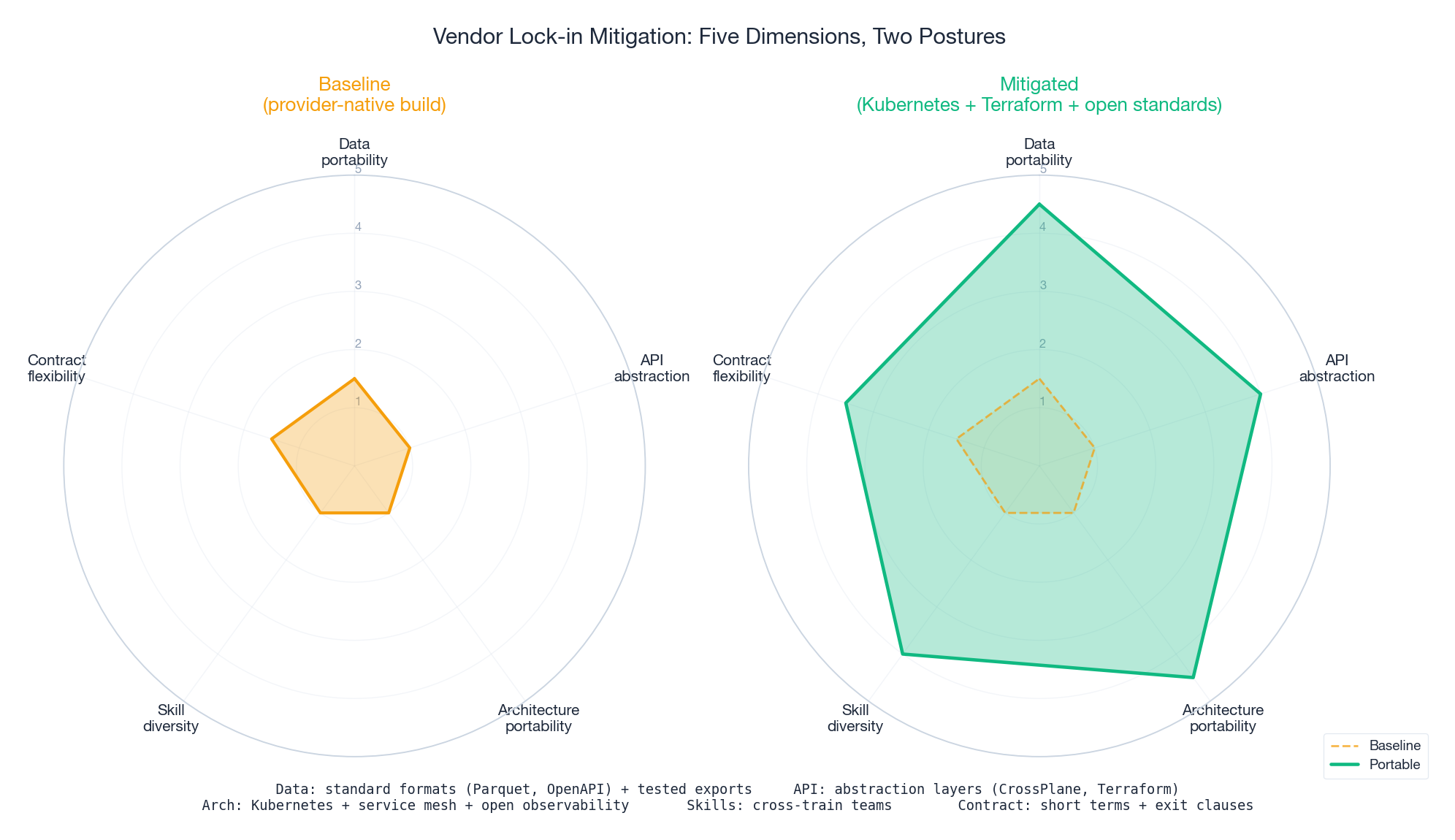
“Avoid vendor lock-in” is an empty phrase until you decompose it. Lock-in has at least five dimensions, each with a concrete mitigation:
| Dimension | Manifestation | Mitigation |
|---|---|---|
| Data | Proprietary formats, expensive egress | Standard formats (Parquet, Avro, OpenAPI); regular export tests; cold copies elsewhere |
| API | Provider-specific SDKs throughout code | Abstraction layers (Crossplane, Terraform), open standards (S3 API via Ceph/MinIO) |
| Architecture | Built on managed services with no equivalent elsewhere | Kubernetes for compute, service mesh for networking, open observability |
| Skills | Team only knows one cloud | Cross-train, hire across clouds, rotate engineers |
| Contract | Multi-year commitments with no exit | Negotiate exit clauses, shorter terms, data export rights |
When Lock-in Is Acceptable (and When It Isn’t)#
The radar above shows the gap between baseline (lots of lock-in) and a portable posture (much less). Closing the gap on every dimension is expensive. Choose deliberately:
- Accept lock-in when the managed service gives a genuine competitive edge (BigQuery for ad-hoc petabyte analytics, DynamoDB for predictable single-digit-ms KV at scale) and the benefit clearly exceeds the cost of switching later.
- Mitigate lock-in when the workload is portable in principle (web apps, batch processing) and the marginal cost of using portable tech is low (Postgres on RDS instead of Aurora-specific features).
- Hard-avoid lock-in when the regulatory environment, contract length, or strategic risk demands the option to leave — and budget the additional engineering cost upfront.
A useful test: “If our primary cloud doubles their prices tomorrow, what is our credible 12-month migration path?” If you cannot answer concretely, you are more locked in than you think.
Disaster Recovery: Beyond the Backup#
DR is where multi-cloud earns most of its keep — and where most plans fail to survive a real test.
RPO and RTO: The Numbers That Drive Architecture#
- RPO (Recovery Point Objective) — how much data you can afford to lose, measured in time. RPO of 1 hour = you can lose at most 1 hour of writes.
- RTO (Recovery Time Objective) — how long you can be down. RTO of 4 hours = you have 4 hours to be back up.
These two numbers determine your architecture, your cost, and how often you test:
| Strategy | RTO | RPO | Cost | Realistic for |
|---|---|---|---|---|
| Backup and restore | Days | Hours-days | Low | Internal tools, dev/test |
| Pilot light (minimal services running) | Hours | Minutes | Medium | Important-but-not-critical apps |
| Warm standby (scaled-down full env) | Minutes-hours | Minutes | High | Customer-facing, revenue-impacting |
| Active-active (full capacity both sides) | Near-zero | Near-zero | Very high | Mission-critical, regulated |
Multi-Cloud DR Patterns#
- Cross-cloud DR. Primary on AWS, DR on Azure (or vice versa). Eliminates correlated provider failure. Cost: data transfer fees, dual operational expertise.
- Geographic DR. Different regions in the same cloud, or different providers in different regions. Cheapest if same provider; resilient against regional disasters either way.
- Hybrid DR. Cloud production, on-prem DR (or vice versa). Common when there is sunk on-prem capacity that can be repurposed.
The DR Checklist That Survives Audits#
- RPO and RTO defined per application, signed off by business owner
- Replication method chosen and matches RPO (sync vs async vs CDC vs snapshot)
- Failover automated where the RTO requires it (don’t rely on humans for sub-hour RTOs)
- DR tested end-to-end quarterly, including DNS cutover
- Runbooks documented, accessible from outside the primary environment, and current
- Backup encryption keys stored separately from backups
- At least one restore actually performed in the last 90 days
The single most underestimated DR failure: the backups exist, but no one has ever restored from them. Compatibility issues, missing schemas, expired credentials, missing IAM roles — all surface only at restore time.
Cost Optimization Across Clouds: The FinOps Discipline#
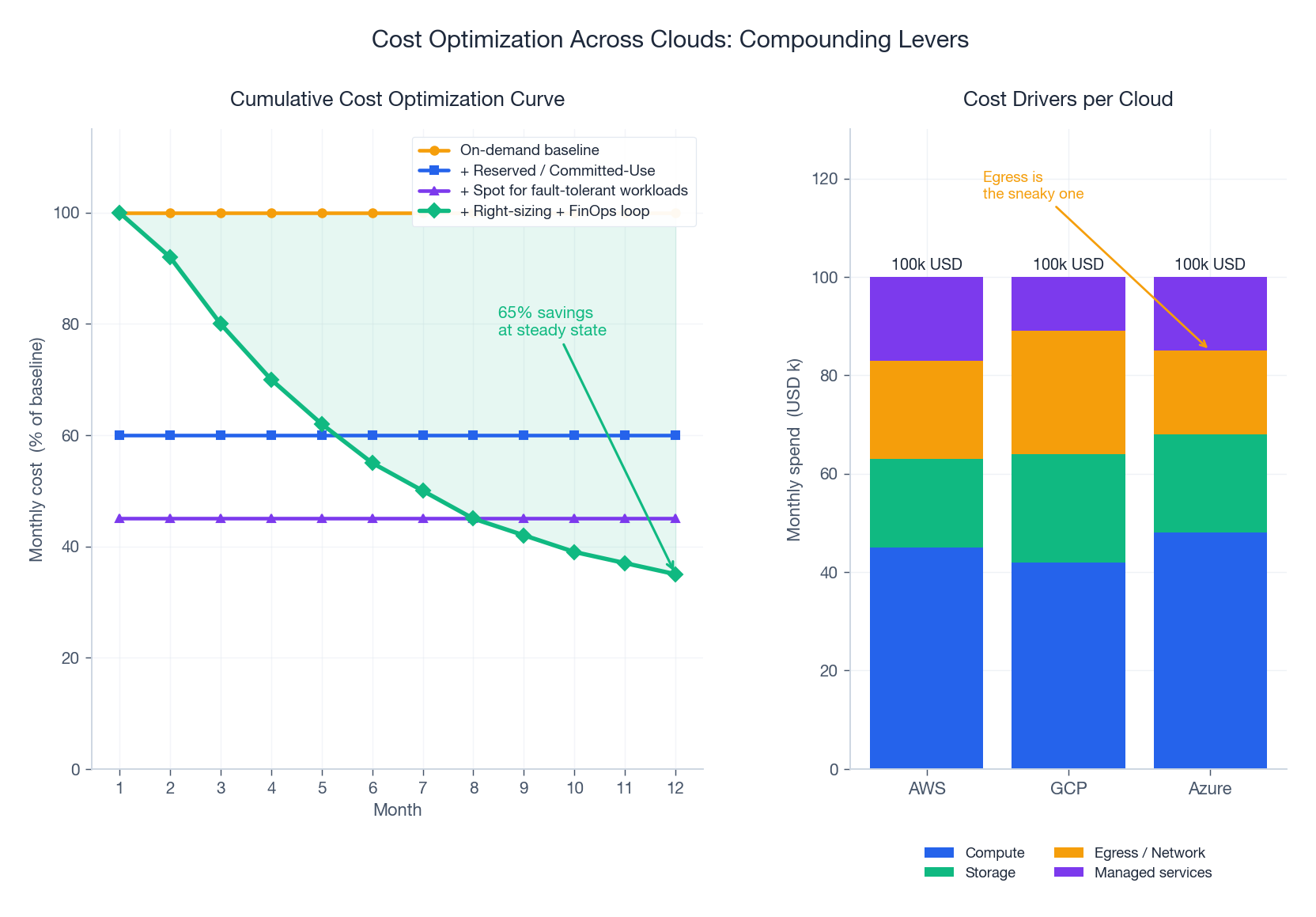
Multi-cloud costs more by default. The discipline that flips that into “multi-cloud costs less than single-cloud at scale” is FinOps: finance + engineering + business, jointly accountable for cloud spend. The compounding levers:
| Lever | Typical savings | Caveat |
|---|---|---|
| Right-sizing | 20-40% | Requires real utilization data; over-provisioning is the default |
| Reserved Instances / Committed Use / Savings Plans | 30-70% | 1- or 3-year commitment; works for steady-state baseline |
| Spot / Preemptible / Low-priority VMs | 60-90% | Workload must tolerate interruption (batch, stateless workers) |
| Storage tiering | 40-80% (on tiered data) | Lifecycle policies matter; manual tiering is a maintenance burden |
| Egress reduction | Workload-dependent | The sneaky one — co-locate, compress, use CDN aggressively |
| Idle resource cleanup | 5-15% | Untagged orphans accumulate; need a janitor process |
The Egress Trap#
Inter-cloud and inter-region egress is the line item that surprises every multi-cloud team. AWS egress is roughly $0.08-0.12 per GB; egress from Azure and GCP is similar. For a workload moving 10 TB/month between clouds, that is **~$ 1,000/month in pure transfer fees** — often more than the compute the data is feeding.
Mitigations:
- Co-locate the data and the compute. Process where the data is, send only the result.
- Use private interconnects (AWS Direct Connect to Azure ExpressRoute via a colo, or third-party fabrics like Equinix / Megaport) — transfer cost can drop to ~$0.02/GB.
- Compress and batch. A naive REST API moves 5x more bytes than a gRPC + protobuf equivalent.
- Use a CDN for read-heavy content; egress to CDN edge once, serve from cache N times.
FinOps Operating Model#
The mature FinOps loop runs monthly:
- Visibility — unified cost dashboards across clouds (CloudHealth, Cloudability, Vantage, Apptio, or roll your own with cloud APIs + a data warehouse).
- Allocation — every dollar tagged to a team / product / customer. Untagged spend is everyone’s and no one’s.
- Optimization — engineering teams own their bills and have a runway to reduce them.
- Forecasting — next quarter’s spend with confidence intervals; surprises are FinOps failures.
The Trends Shaping the Next Decade#
The cloud landscape changes fast. The trends that look durable, not just hype:
Edge Computing#
Computation at the network edge, near data sources and users. Drivers: 5G, IoT, AR/VR, real-time inference. Platforms: AWS Wavelength, Azure Edge Zones, GCP Distributed Cloud Edge, Cloudflare Workers, Fastly Compute. The hard part isn’t the runtime — it is managing thousands of distributed locations as one fleet.
Serverless and Wasm Portability#
FaaS (Lambda, Cloud Functions, Azure Functions) is mature but locked in. WebAssembly (Wasm) is changing that: a portable bytecode that runs identically across cloud providers, edge platforms, and even browsers. Projects like Spin, Wasmtime, and Cloudflare Workers’ Wasm runtime point at a future where serverless is genuinely portable. Worth tracking.
Sovereign and Regional Clouds#
GAIA-X in Europe, sovereign cloud regions in France/Germany/India, China’s distinct cloud market — all of it driven by regulation and geopolitics. The architectural implication: plan for the data residency of every dataset, not just the compute region.
FinOps as a Profession#
Cloud spend has become large enough that the FinOps Foundation has emerged as a discipline with certifications, frameworks, and dedicated teams. Five years ago FinOps was a side project of platform engineering; today it is its own role.
Sustainability and Carbon-Aware Computing#
Cloud providers publish carbon dashboards (AWS Customer Carbon Footprint Tool, GCP Carbon Footprint, Azure Sustainability Calculator). Carbon-aware schedulers (Google’s CCS, the open-source Carbon Aware SDK) shift batch workloads to times and regions where the grid is greener. This is going from “nice to have” to “required by sustainability reporting” in many jurisdictions.
Confidential Computing Goes Mainstream#
AMD SEV-SNP, Intel TDX, AWS Nitro Enclaves, Azure Confidential VMs, GCP Confidential VMs — all available now. The “data encrypted in use, not just at rest and in transit” promise is finally practical for production. Expect it to become a baseline expectation for sensitive workloads within a few years.
Case Studies: How Real Organizations Combine the Pieces#
Global Bank (Hybrid Multi-Cloud)#
Trading systems remain on-prem (sub-millisecond latency requirements). Customer-facing apps run on AWS for elasticity. Disaster recovery uses Azure as a separate provider. Identity is federated via Okta. Cost tracking via CloudHealth. Result: 35% infrastructure cost reduction vs all-on-prem, 99.99% availability, full compliance with national banking regulators in 14 jurisdictions.
Global E-Commerce (Multi-Cloud Workload-Specific)#
AWS as primary (mature ecosystem for stateless web tier). GCP for analytics, ML training, BigQuery for product analytics. CloudFront + Cloudflare for CDN globally. Cross-cloud data movement minimized: BigQuery imports from S3 once daily, not continuously. Result: handled 10x Black Friday spike without engineering intervention, 40% latency reduction in EU, 25% lower TCO than single-cloud equivalent.
Healthcare Provider (Hybrid + Sovereign)#
Patient records on HIPAA-compliant on-prem (regulatory and contractual). Telehealth on AWS GovCloud. ML inference at the edge (telemedicine clinics). Geographic separation for international subsidiaries (EU patient data in Frankfurt, never crosses borders). Result: full HIPAA + GDPR compliance, 5x user growth without infrastructure scrambling, 30% cost reduction vs all-on-prem baseline.
The Series Capstone: How It All Connects#
Eight articles and a single thread runs through them: the cloud is layered, and each layer makes a deliberate trade-off.
| Part | Layer | The trade-off |
|---|---|---|
| 1 | Fundamentals | Capex vs opex, control vs convenience |
| 2 | Virtualization | Isolation strength vs density and speed |
| 3 | Storage | Consistency vs availability vs partition tolerance (CAP) |
| 4 | Networking / SDN | Software flexibility vs hardware performance |
| 5 | Security & Privacy | Defense depth vs operational friction |
| 6 | Operations & DevOps | Automation investment vs manual control |
| 7 | Cloud-Native & Containers | Independence vs distributed-system complexity |
| 8 | Multi-Cloud & Hybrid | Portability vs differentiation, resilience vs cost |
The recurring lesson: good architecture is naming the trade-off, not denying it exists. A team that says “we want maximum portability and maximum cloud-native services and minimum cost” has not made a decision; they have written a wish list. The teams that ship are the ones that pick a corner of the trade-off space, justify it in business terms, and execute.
A second lesson, harder won: operational maturity compounds. The teams that nail the boring stuff — IaC, observability, on-call rotation, incident reviews, capacity planning, cost discipline — end up with the freedom to make bigger architectural moves. The teams that skip it get stuck firefighting and never escape.
Strategic Checklist for Your Multi-Cloud Journey#
Strategy:
- Business objectives explicit (resilience, cost, compliance, leverage — which?)
- Multi-cloud premium accepted by leadership (it costs more before it costs less)
- Workload classification done (which apps go where, and why)
Architecture:
- Pattern selected (workload-specific, active-passive DR, or active-active)
- DR strategy with RPO/RTO defined per application
- Data sync patterns chosen per dataset (sync, async, CDC, snapshot)
- Vendor lock-in mitigation explicit per dimension (data, API, arch, skills, contract)
Implementation:
- IaC (Terraform / OpenTofu) for every resource on every cloud
- Identity federated across all environments
- Network connectivity established with appropriate bandwidth/latency
- Security policies consistent across clouds (CIS benchmarks, default-deny)
- Observability unified (OpenTelemetry, central SIEM)
Operations:
- Cost tracking unified, with allocation tags enforced
- FinOps loop running monthly with engineering accountability
- DR tested quarterly, end-to-end, including failover and failback
- Runbooks current, stored outside the primary environment
- Team trained on every cloud you operate on, not just one
Continuous improvement:
- Quarterly architecture review against business objectives
- Annual portability test (can we actually leave Cloud A?)
- Tracking emerging trends (edge, Wasm, sovereignty, sustainability)
Cloud Computing 8 parts
- 01 Cloud Computing (1): Fundamentals and Architecture
- 02 Cloud Computing (2): Virtualization Technology Deep Dive
- 03 Cloud Computing (3): Cloud-Native and Container Technologies
- 04 Cloud Computing (4): Cloud Storage Systems and Distributed Architecture
- 05 Cloud Computing (5): Cloud Network Architecture and SDN
- 06 Cloud Computing (6): Cloud Security and Privacy Protection
- 07 Cloud Computing (7): Cloud Operations and DevOps Practices
- 08 Cloud Computing (8): Multi-Cloud and Hybrid Architecture you are here