
Cloud Computing (6): Cloud Security and Privacy Protection
A working engineer's guide to cloud security: shared responsibility, IAM that actually scales, encryption at rest / in transit / in use, zero trust, compliance frameworks, and incident response that you can rehearse.

In 2019 Capital One lost a hundred million customer records. The exploit chain was small: a misconfigured WAF allowed server-side request forgery against the EC2 metadata endpoint, that endpoint handed back IAM credentials, and the IAM role those credentials belonged to had wildcard s3:* on every bucket in the account. One misconfiguration, one over-broad role, one rule the security team had not written. The bill, before legal: more than 80 million dollars.
Almost every public cloud breach since has the same shape. Not zero-days, not nation-state malware - configuration mistakes that nobody noticed until the data was already on Pastebin. The job of a cloud security engineer is therefore less about cryptographic exotica and more about systematically removing the conditions that turn a small mistake into a hundred-million-dollar one.
This article walks the full stack from the shared responsibility contract down to incident response, with code, diagrams, failure modes and rehearsable runbooks at every layer.
What You Will Learn#
- The shared responsibility model and how it shifts across IaaS / PaaS / SaaS
- IAM that scales: identities, groups, roles, policies, and the patterns that hold up under audit
- Encryption for data at rest, in transit, and in use - including the parts that almost everyone gets wrong
- DDoS protection and Web Application Firewalls, and how to rate-limit without killing legitimate users
- Zero trust architecture as a concrete set of controls, not a vendor slogan
- Compliance frameworks (SOC 2, HIPAA, GDPR, PCI DSS, ISO 27001) compared on what they actually require
- An incident response loop you can practise before you need it
Prerequisites#
- Basic networking (TCP, TLS, DNS, firewalls)
- Familiarity with at least one cloud provider’s IAM console
- Parts 1-4 of this series recommended
Shared Responsibility, Honestly#
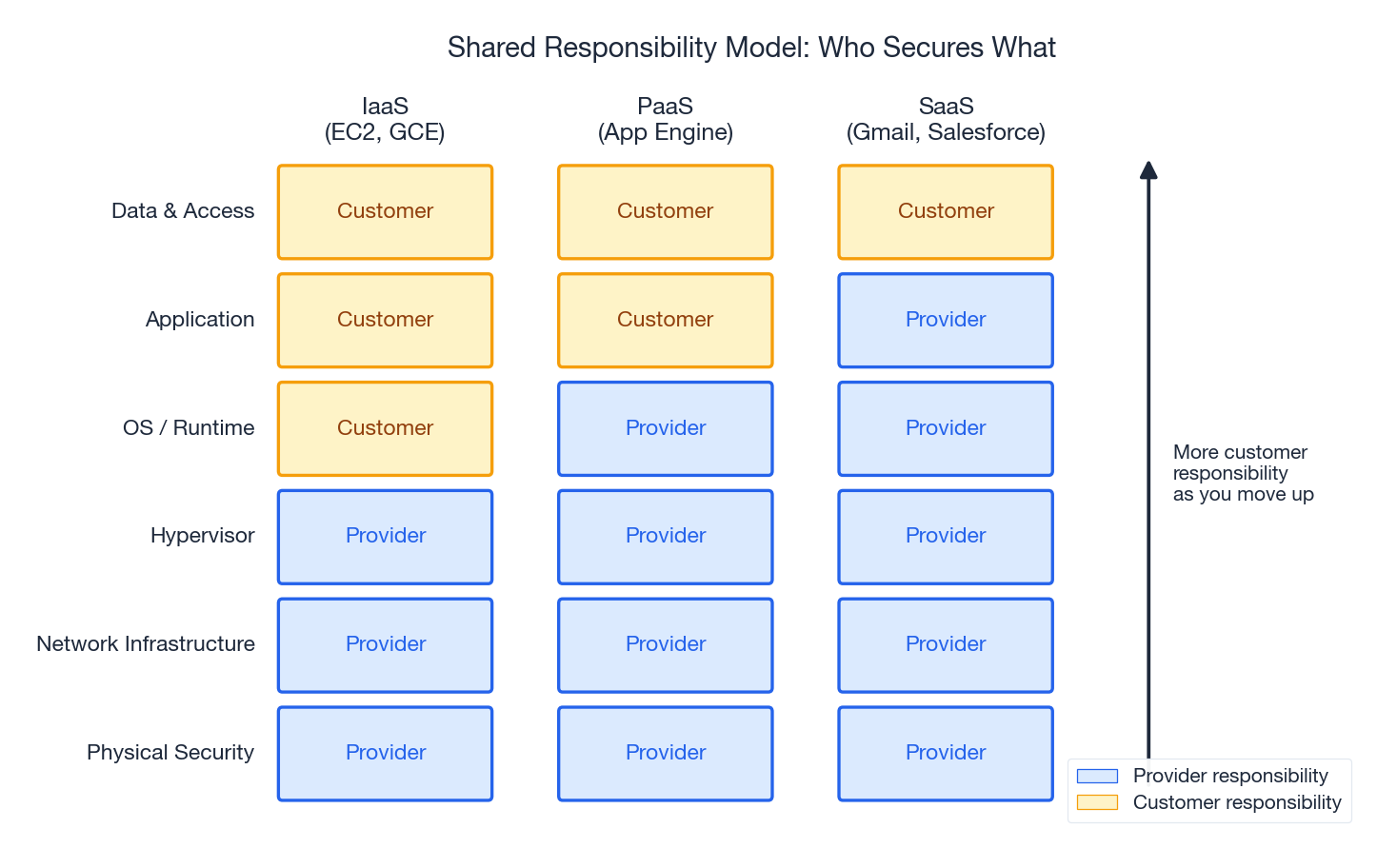
Cloud providers always publish a shared responsibility model. They publish it because every postmortem starts with the same argument: who was supposed to secure that. The answer depends on which service tier you are on.
| Layer | IaaS (EC2) | PaaS (App Engine) | SaaS (Gmail) |
|---|---|---|---|
| Data & access | You | You | You |
| Application code | You | You | Provider |
| Runtime / OS | You | Provider | Provider |
| Hypervisor | Provider | Provider | Provider |
| Network infra | Provider | Provider | Provider |
| Physical | Provider | Provider | Provider |
Three things get missed in the diagrams. First, data and access controls are always yours - even on SaaS, nobody but you decides who is allowed into your Salesforce tenant. Second, configuration of provider services is also yours - AWS gives you S3, but the bucket policy, the encryption setting and the public-access block are your responsibility, and the default for years was “open”. Third, the provider’s part of the model only kicks in when you use their service correctly; rolling your own database on EC2 puts patching, backups and HA back on you.
A useful mental rewrite: “The provider secures the substrate. Everything you can configure, you must configure correctly.”
The Threats You Will Actually See#
The Verizon DBIR and Mandiant M-Trends reports converge year after year on the same top causes for cloud incidents. In rough order of frequency:
- Misconfigured object storage. Public S3 / GCS buckets containing customer PII, source code, or backups.
- Leaked or long-lived credentials. API keys committed to GitHub, baked into AMIs, sitting in Slack scrollback.
- Over-permissive IAM. A role that needs
s3:GetObjecton one bucket getss3:*on every bucket because that was easier in the console wizard. - Unpatched applications. Public CVEs in libraries, container images, OS packages.
- Supply-chain compromise. Malicious dependencies (
event-stream), poisoned base images, typosquatted packages. - Stolen session tokens. Phished MFA codes, or browser-side token theft, replayed from elsewhere.
Cryptographic attacks against AES or TLS do not appear on this list. The defender’s leverage is in IAM hygiene, configuration management, and detection - not in inventing new ciphers.
IAM: The One Subsystem You Cannot Get Wrong#
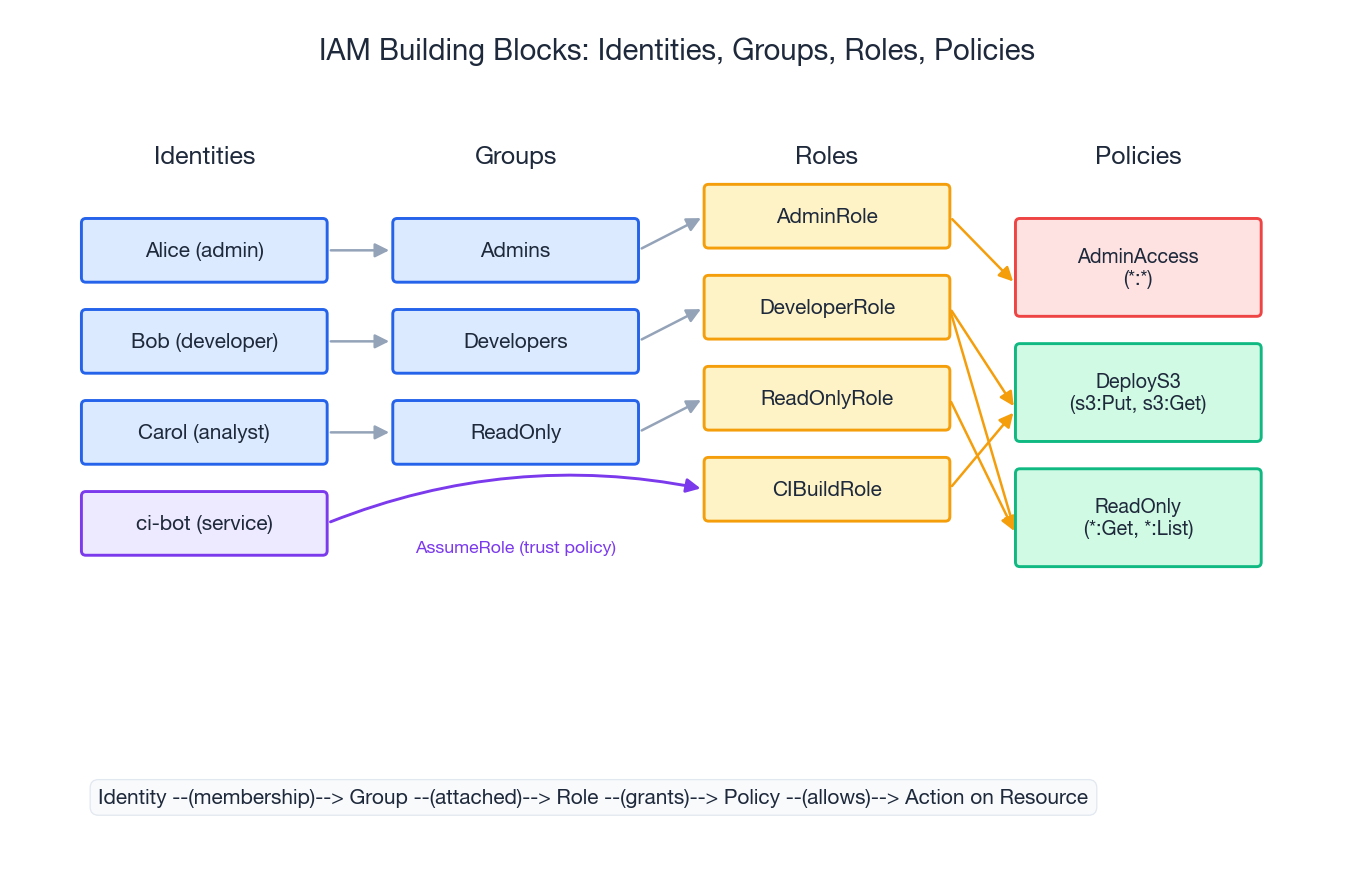
The model#
Every mature IAM system has the same four primitives:
- Identity - a human (Alice) or a machine (a CI runner). Identities prove they are themselves via passwords + MFA, certificates, or workload identity tokens.
- Group - a static set of identities (“Engineers”, “Finance”). Groups are an addressing convenience; they own no permissions of their own.
- Role - a named bundle of permissions. Identities or groups can assume a role; on AWS the role itself has a trust policy declaring who is allowed to assume it.
- Policy - the actual permission statements: allow / deny, on which actions, against which resources, under which conditions.
The arrow direction matters: identity -> group -> role -> policy -> action. Permissions only flow forward. You can audit any access by walking that chain backward from the resource.
Six rules that survive contact with reality#
- Least privilege, then iterate. Start from zero. Grant the smallest set that lets the task succeed. When something legitimately fails, widen narrowly - never
s3:*. - Roles, not long-lived users, for everything that runs code. EC2 instance profiles, Lambda execution roles, IRSA on EKS, Workload Identity on GKE - all give short-lived, automatically rotated credentials.
- MFA on every human identity. No exceptions for “service accounts that humans share” - those should not exist.
- Rotate. Revoke. Expire. API keys older than 90 days are a smell. Credentials of a departed employee are an incident clock that started ticking the moment they left.
- Permission boundaries and SCPs. Give teams the freedom to create their own roles, bounded by an organisation-wide policy that blocks the dangerous combinations.
- Log every grant and every use. CloudTrail, Cloud Audit Logs, Azure Activity Log - centralised, tamper-evident, retained for at least a year.
A real least-privilege policy#
Read-only access to one bucket, restricted to a corporate CIDR, and only when the caller has actually proved MFA in the current session:
| |
The MultiFactorAuthAge condition is the underused one - it forces the MFA proof to be fresh, not “they MFA’d into the console six hours ago”.
The organisation-wide guardrail#
A Service Control Policy applied at the organisation level cannot be overridden by any account-level role. Use it for blast-radius decisions:
| |
This denies any action by the root user, and any action in regions you do not operate in. Both block a large class of mistakes, including data-residency violations and crypto-mining attacks that spin up GPUs in obscure regions.
IAM mistakes that recur#
"Action": "*"or"Resource": "*"in any non-deny statement. Almost always over-broad.iam:PassRolewithResource: "*"- this is privilege escalation in a single line.- Long-lived access keys baked into AMIs, container images, or
.envfiles committed to Git. - “Temporary” admin grants made permanent because nobody set an expiry.
- Service accounts shared between services so that no single owner can rotate the credential.
Encryption: At Rest, In Transit, In Use#
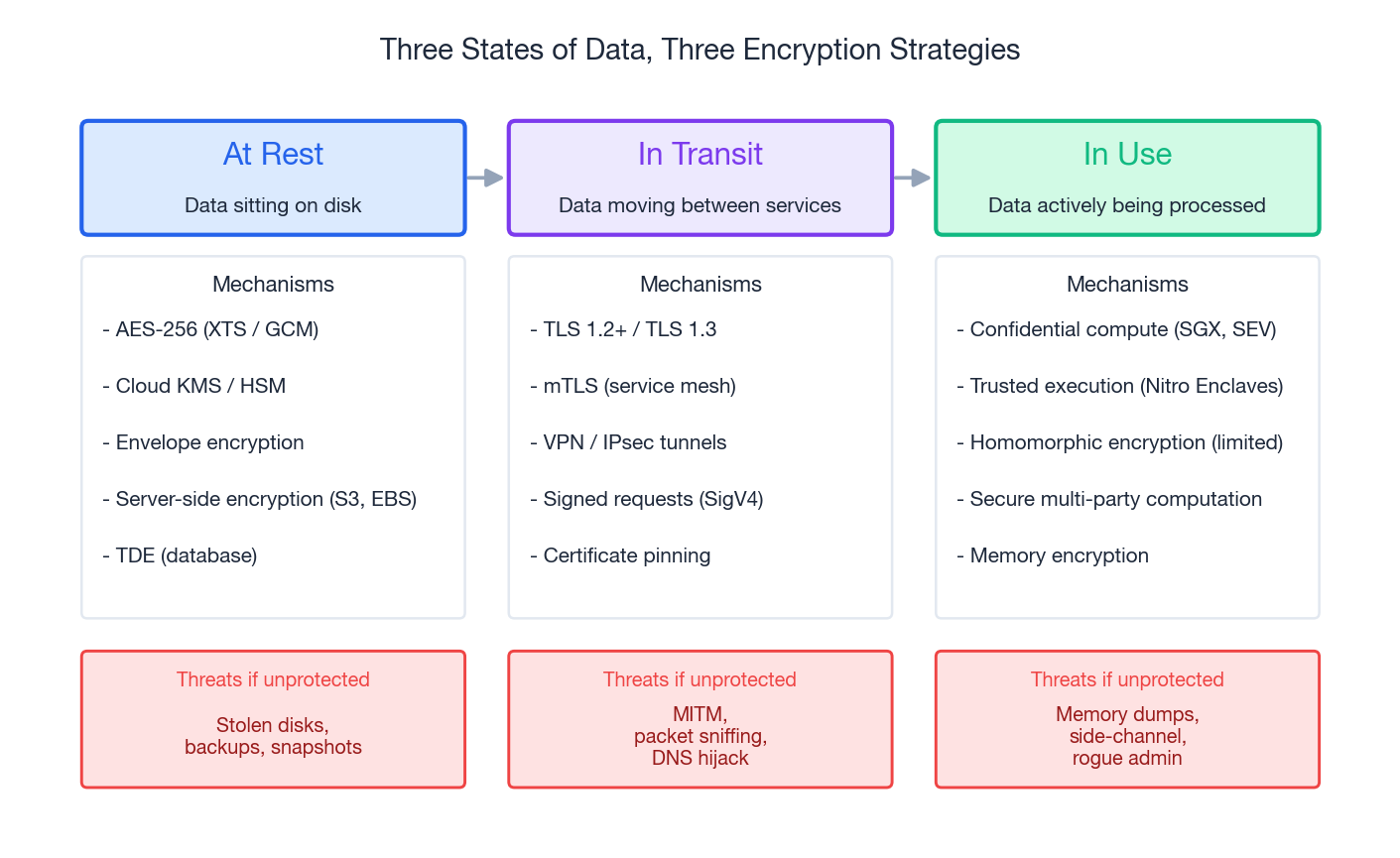
Data has three states. Each needs a different protection mechanism, and the threats that justify each are different.
At rest#
The threat is someone walking off with the disk, the snapshot, or the backup tape - or an authorised process reading raw bytes you did not intend to expose. The defence is symmetric encryption with keys you actually control.
- AES-256-GCM for application-level encryption.
- AES-XTS for full-disk / volume encryption (EBS, persistent disks).
- TDE (Transparent Data Encryption) for managed databases.
- Server-side encryption as the default for object storage. On AWS, set
BucketKeyEnabled: trueto cut KMS request costs by ~99%.
Use cloud KMS or an HSM-backed key store. Do not implement key rotation yourself.
| |
The envelope pattern is what every “transparent” cloud encryption feature is doing under the hood. Understanding it lets you reason about cost (one KMS call per data key, not per byte) and key rotation (re-wrap data keys, not re-encrypt petabytes).
In transit#
The threat is on-path interception, packet capture from a compromised network device, or a malicious mesh sidecar. The defence is TLS, used correctly.
| |
Three details people miss:
- Disable TLS 1.0 and 1.1 at the load balancer. They are forbidden by every current compliance regime and have known weaknesses.
- HSTS with a long
max-ageis the only thing that defeats SSL-strip downgrade attacks. - mTLS between services. Inside the cluster, service A should refuse to talk to service B unless B presents a certificate from your internal CA. Service meshes (Istio, Linkerd) make this a single line of YAML.
In use#
The hardest case. Data is decrypted in RAM to be processed, which means a sufficiently privileged process on the same host can read it. Three mitigations exist today:
- Confidential VMs (AWS Nitro Enclaves, GCP Confidential VMs, Azure Confidential Computing). The hypervisor cannot read guest memory; the guest is attested with a hardware-rooted measurement.
- Hardware enclaves (Intel SGX, AMD SEV-SNP). A small trusted region within a process where decrypted data lives.
- Homomorphic encryption / secure multi-party computation. Mathematically beautiful, currently 1000x to 1000000x slower than plaintext compute - viable only for narrow workloads (private set intersection, certain aggregations).
For most teams, “in use” protection is achieved indirectly: minimise the surface that handles plaintext, isolate it, and audit it.
DDoS Protection and the Web Application Firewall#
Three classes of attack#
| Class | Mechanism | Example | Where it hurts |
|---|---|---|---|
| Volumetric | Saturate bandwidth | UDP / DNS amplification | Network pipe |
| Protocol | Exhaust connection-state tables | SYN flood, ACK flood | Load balancer, OS |
| Application | Force expensive work | HTTP flood, Slowloris, GraphQL bomb | App servers, database |
A real attacker uses all three together. A real defender uses a layered stack.
The defence stack#
- Edge / network: AWS Shield Advanced, Cloud Armor, Cloudflare. Absorbs L3/L4 floods before they reach your VPC.
- CDN: caches static assets and presents a much larger surface than your origin, diluting the attack.
- WAF: blocks SQLi, XSS, RCE patterns, malicious bots, geographic blocks where appropriate. Use a managed ruleset as a baseline, then add narrow rules for your application.
- Rate limiting: per-IP, per-token, per-route. Catches credential-stuffing, scraping, and slow-burn application-layer attacks.
- Application: input validation, parameterised queries, query cost limits. The WAF is not your input validator.
A WAF rule set you can ship today#
| |
Tune Limit carefully. Too tight and you block your own mobile app behind a CGNAT. Run the rule in Count mode for a week before flipping to Block.
Security Logging and Detection#
What to log#
Five categories, in priority order:
- Authentication - logins, failures, MFA challenges, password resets.
- Authorisation - every grant and every deny, with the policy that decided it.
- Data access - reads and writes to sensitive resources (PII columns, KMS keys, secret stores).
- Configuration changes - IAM, security groups, KMS, infrastructure as code applies.
- Network - VPC Flow Logs, DNS query logs.
A CloudTrail event, decoded#
| |
The fields a SIEM rule actually consumes: userIdentity.arn, mfaAuthenticated, sourceIPAddress, eventName, requestParameters, and the response status. Patterns worth alerting on:
ConsoleLoginfrom a country you do not operate in.iam:CreateUseroriam:CreateAccessKeyoutside of approved automation.- A sudden spike in
s3:GetObjectcalls from one role. - Any
kms:Disable*orkms:ScheduleKeyDeletion. ec2:RunInstancesof a GPU type from a role that has never done that.
Pipeline and retention#
- Centralise into a SIEM (Security Hub, Splunk, Elastic Security, Chronicle).
- Encrypt log buckets and deny
s3:DeleteObjectto everyone, including the security team’s own role - logs you can mutate are not evidence. - Hot-tier 90 days, cold-tier 1-7 years depending on industry.
- Build dashboards before you need them; an incident at 3 AM is the wrong moment to learn Lucene syntax.
Zero Trust, Concretely#
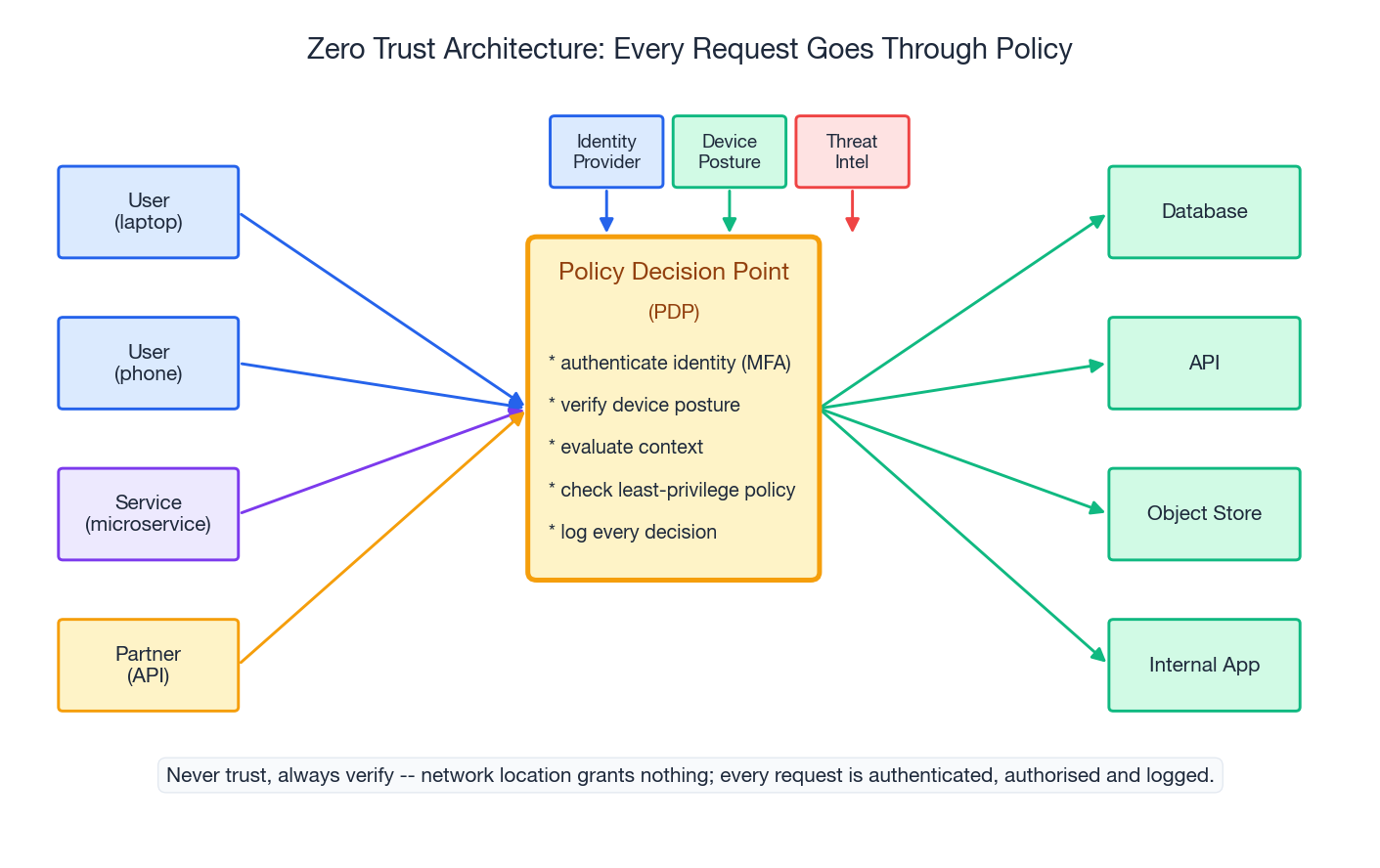
“Zero trust” is a marketing term wrapped around a simple principle: network location grants no privilege. Being inside the corporate VPN, the production VPC, or the cluster network does not by itself authorise any action.
The concrete controls that implement it:
- Identity-aware proxy in front of every internal app. No more “it’s only on the intranet, it doesn’t need auth”. Google’s BeyondCorp pioneered this; Cloudflare Access, AWS Verified Access, and Tailscale offer turnkey versions.
- Device posture as an authentication factor. The PDP checks: is the laptop encrypted, MDM-enrolled, current on patches, the right serial number from your asset registry? If not, the request is denied or quarantined regardless of credentials.
- Service-to-service mTLS with SPIFFE/SPIRE. Each workload has a cryptographic identity (a SPIFFE ID), short-lived certificates, and policies that say which IDs may call which.
- Continuous evaluation. Sessions are not “valid for 12 hours”; they are continuously re-evaluated against signals (IP changed, geo changed, device went non-compliant). Risky sessions are demoted or revoked.
- Micro-segmentation. A compromised pod cannot freely reach the rest of the cluster. Network policies restrict east-west traffic to declared service dependencies.
The mental model: every request runs through a Policy Decision Point that asks “who, what, from where, on what device, in what context, against this resource - allow or deny?” - and the answer is logged, every time.
Compliance Frameworks#
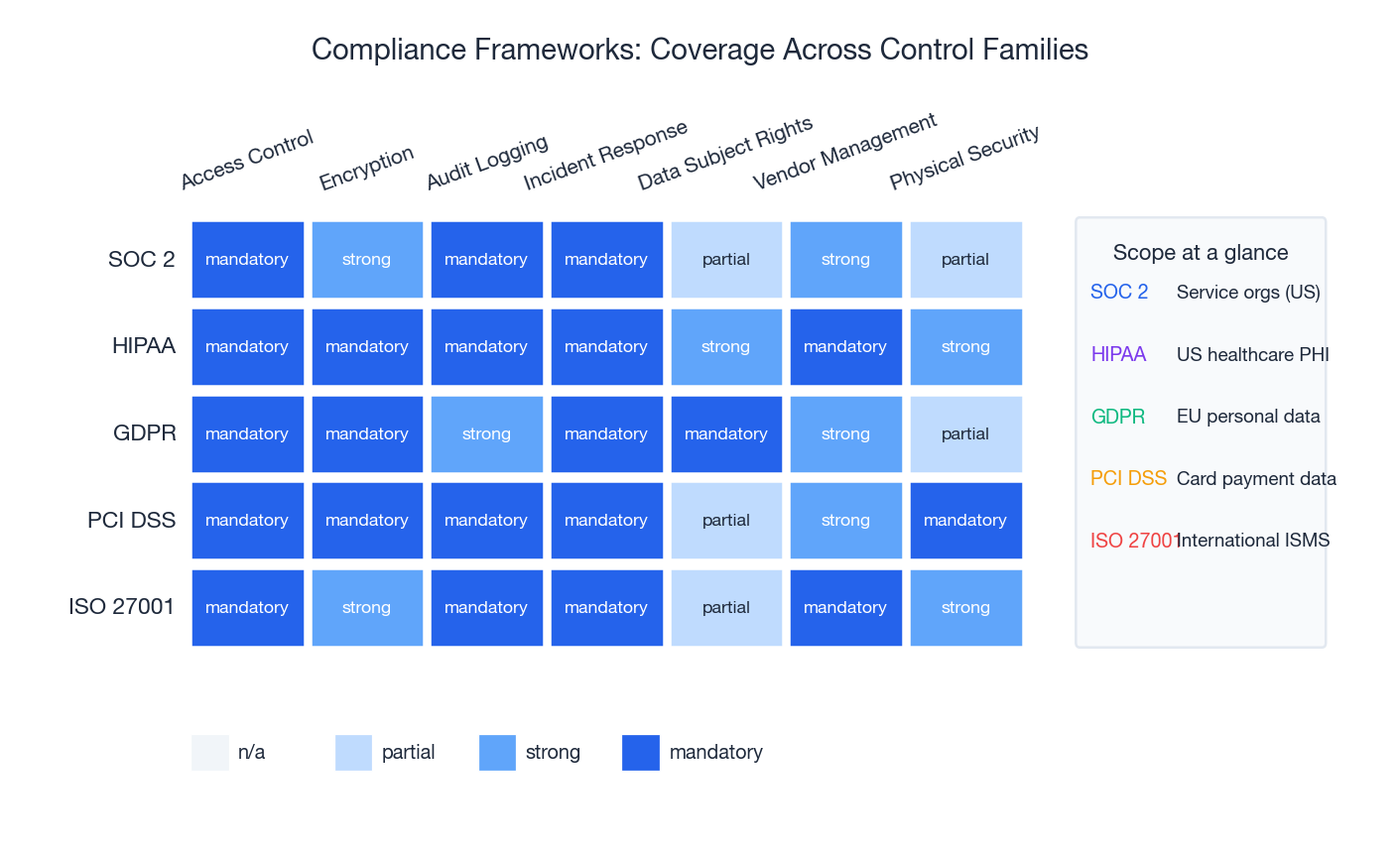
Compliance is not security, but it forces a baseline of controls and a paper trail. Five frameworks cover most engineering teams’ obligations:
| Framework | Scope | Headline requirements |
|---|---|---|
| SOC 2 | US service organisations | Trust service criteria: security, availability, processing integrity, confidentiality, privacy. Annual audit. |
| HIPAA | US healthcare PHI | BAAs with subprocessors, encryption everywhere, six-year audit retention, breach notification. |
| GDPR | EU personal data, anywhere processed | Lawful basis, data minimisation, subject access / erasure rights, 72-hour breach notification, DPIAs. |
| PCI DSS | Card payment data | Network segmentation, encrypted storage, quarterly scans, annual penetration test. |
| ISO 27001 | International ISMS | Documented information security management system, risk assessment, Annex A controls, certification audit. |
A GDPR engineering checklist#
- Data inventory: every system that touches personal data, with lawful basis recorded.
- Subject access request endpoint: produce all data on a person within 30 days.
- Erasure endpoint: cryptographic shredding of backups via per-tenant keys is acceptable.
- 72-hour breach notification: rehearse the comms path before you need it.
- DPIA for any new processing of high-risk data (location, health, biometrics, profiling).
- Records of processing activity (Article 30) - pull this from your data inventory, do not maintain by hand.
The pattern across all five: you cannot bolt them on at the end. Bake controls into infrastructure code, audit logging, and the deployment pipeline, and the audit becomes a paperwork exercise rather than an existential crisis.
Incident Response: The Loop#
The NIST cycle (preparation -> detection -> containment -> eradication -> recovery -> lessons learned) is correct but academic. In practice, three things determine whether your incident becomes a 30-minute footnote or a 30-day disaster:
- You have rehearsed the runbook. A tabletop every quarter and at least one live game day per year.
- You can isolate fast and forensically. Snapshot before you destroy; collect memory before you reboot.
- You write blameless postmortems with action items that actually ship. Otherwise you will see the same incident again next year.
A reusable containment script#
| |
The order matters: snapshot, isolate, revoke credentials, stop. Reverse it and you risk the malware exfiltrating during the seconds it takes to take the snapshot, or evidence being lost in the OS shutdown sequence.
Hardened Infrastructure as Code#
A secure baseline is worth nothing if a tired engineer can terraform apply an open S3 bucket on a Friday afternoon. Encode the baseline in modules and policy-as-code (OPA / Sentinel / Checkov):
| |
A Checkov policy in CI rejects any aws_s3_bucket not accompanied by these four sidecar resources. Mistakes get caught before they reach production.
The Engineer’s Pre-flight Checklist#
Identity
- MFA enforced for every human, including break-glass accounts (whose codes are in a sealed envelope, not Slack).
- No long-lived access keys for workloads; instance profiles / IRSA / Workload Identity instead.
- Quarterly review: who has admin, do they still need it?
- SCP / org policy denying root use, denying unused regions.
Encryption
- Default-encryption-on for every storage service.
- Customer-managed KMS keys with annual rotation for anything sensitive.
- TLS 1.2+ enforced at every load balancer; HSTS preload set.
- mTLS between internal services where the threat model warrants it.
Network
- Security groups deny by default; opened ports justified in code review.
- WAF in front of every public app, run for a week in count mode before block.
- DDoS protection (Shield Advanced / Cloud Armor) on prod-facing endpoints.
- VPC Flow Logs and DNS query logs enabled and shipped to SIEM.
Detection
- CloudTrail / Cloud Audit Logs to a write-once bucket in a separate account.
- Detection rules for the high-priority patterns (root use, key creation, new region, KMS disable).
- On-call rotation paged on critical alerts.
- Logs retained 90 days hot, longer per compliance.
Response
- Incident playbook documented and drilled every quarter.
- Containment automation tested against a dummy instance.
- Postmortems shared, action items tracked to closure.
- Customer / regulator comms templates pre-approved by legal.
The point of the list is not to feel safer for having ticked it. It is that every box left unchecked is a known configuration that an attacker, or a compliance auditor, will find first.
Cloud Computing 8 parts
- 01 Cloud Computing (1): Fundamentals and Architecture
- 02 Cloud Computing (2): Virtualization Technology Deep Dive
- 03 Cloud Computing (3): Cloud-Native and Container Technologies
- 04 Cloud Computing (4): Cloud Storage Systems and Distributed Architecture
- 05 Cloud Computing (5): Cloud Network Architecture and SDN
- 06 Cloud Computing (6): Cloud Security and Privacy Protection you are here
- 07 Cloud Computing (7): Cloud Operations and DevOps Practices
- 08 Cloud Computing (8): Multi-Cloud and Hybrid Architecture