
LeetCode (7): Patterns — Dynamic Programming Basics
Master dynamic programming through a single recipe: define the state, write the transition, anchor the base case. Worked solutions for Climbing Stairs, House Robber, Coin Change, LIS, 0/1 Knapsack, LCS, and Edit Distance.

Dynamic programming has a reputation for being the algorithm topic that separates “competent coder” from “interview wizard”. A lot of that reputation is unearned. DP is not a bag of clever tricks; it is a single recipe applied to problems that happen to have repeated subproblems. If you can answer three questions cleanly, you can solve almost any DP problem on LeetCode:
- What does
dp[i]actually mean? (state) - How do I build
dp[i]from smaller answers? (transition) - What are the smallest answers I already know? (base case)
This article walks through that recipe, then applies it to the seven problems every DP study list eventually converges on: Climbing Stairs, House Robber, Coin Change, Longest Increasing Subsequence, 0/1 Knapsack, Longest Common Subsequence, and Edit Distance.
Why DP Exists: Overlapping Subproblems#
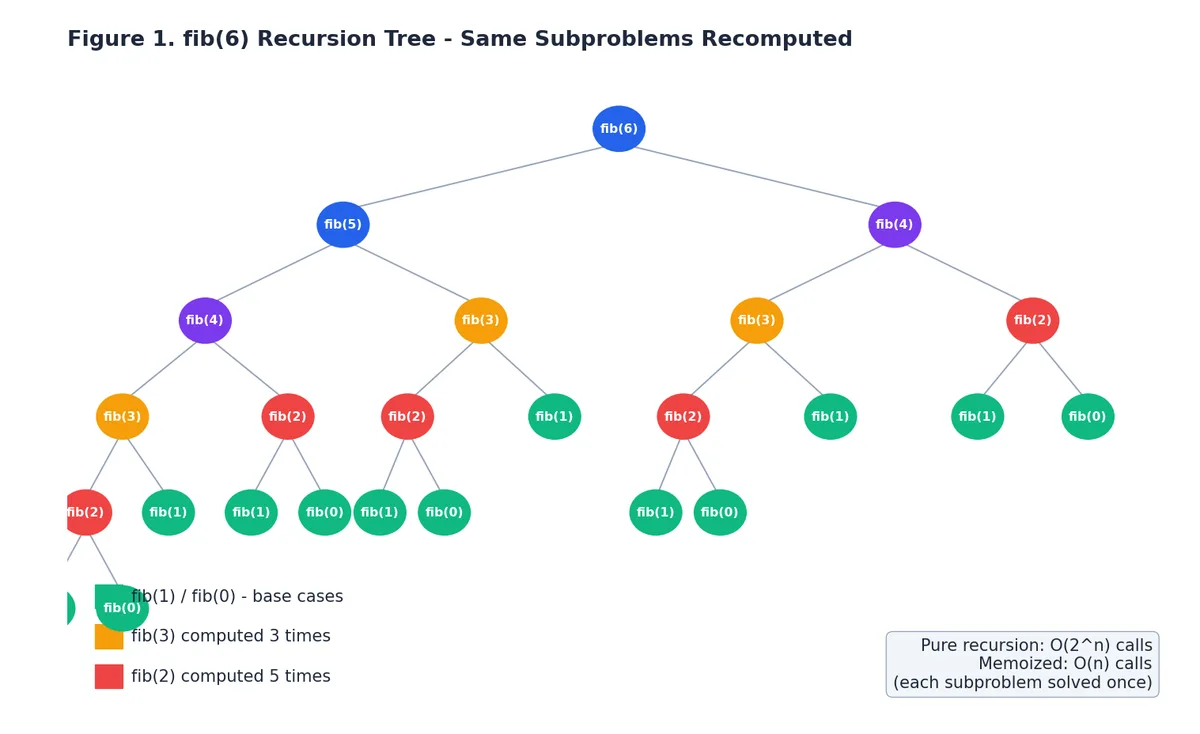
Look at the recursion tree for fib(6) above. The naive recursive
definition fib(n) = fib(n-1) + fib(n-2) is mathematically correct, but
it computes fib(2) five separate times, fib(3) three times, and so
on. The work doubles at every level, so the total cost is exponential -
$O(2^n)$
- even though there are only $n+1$
distinct subproblems we
actually care about.
DP fixes this by storing each subproblem’s answer the first time we compute it. Two flavors:
- Top-down (memoization): keep the recursive structure, but cache the result of every call. The recursion tree is pruned so each node is visited once.
- Bottom-up (tabulation): skip recursion entirely, fill an array from the smallest subproblem upward.
Both turn $O(2^n)$ into $O(n)$ . The two ingredients that make this work are:
- Optimal substructure - the optimal answer to the whole problem is built from optimal answers to subproblems. Shortest paths, Fibonacci, knapsack value, edit distance: all qualify.
- Overlapping subproblems - the same subproblem appears many times in a naive recursion. This is what caching cancels.
If a problem has both, DP wins. If it has only optimal substructure (divide and conquer like merge sort), caching buys nothing. If it has neither, you need a different paradigm.
The Three-Step Recipe#
Every DP solution in this article follows the same outline. Practice it until it becomes muscle memory.
Step 1 - Define the state#
Pick a precise meaning for dp[i] (or dp[i][j]). Be ruthless about
this: vague state definitions are the single biggest source of buggy DP
code. Examples that work:
dp[i]= the number of ways to reach step $i$ .dp[i]= the maximum money you can rob from houses $0..i$ .dp[i][j]= the LCS length ofs1[0:i]ands2[0:j].
A good test: if I tell you dp[i-1] and dp[i-2] are correct, can you
write the formula for dp[i]? If yes, the state is meaningful.
Step 2 - Write the transition#
The transition is just “what choices do I have at index $i$ , and which one is best?” In code it is one line. The thinking around it is the real work.
For House Robber: at house $i$
you either rob it (take nums[i] and
fall back to dp[i-2]) or skip it (inherit dp[i-1]). The transition
is the maximum of those two options.
Step 3 - Anchor the base case#
Base cases are the smallest subproblems you can answer without any recursion. Get these wrong and the whole table collapses. Get them right and the rest of the array fills itself in.
For Climbing Stairs: dp[0] = 1 (one way to “stand at the bottom”) and
dp[1] = 1 (one way to take a single step). Spot check: dp[2] should
be 2, and indeed dp[1] + dp[0] = 2. The base case is consistent.
One-Dimensional DP#
1D DP problems are the gateway. The state is a single index, and the transition usually depends on a constant number of previous cells. That makes them a perfect place to internalize the recipe.

The picture above is the mental model: a row of cells, each computed from a fixed-size window of earlier cells. Once you see this, you also see why we can almost always shrink the array to a couple of variables
- you only need to remember as far back as the transition reaches.
LeetCode 70 — Climbing Stairs#
You are climbing a staircase that takes $n$ steps. Each move is 1 or 2 steps. How many distinct ways are there to reach the top?
Recipe:
- State:
dp[i]= number of distinct ways to reach step $i$ . - Transition:
dp[i] = dp[i-1] + dp[i-2](last move was a 1-step from $i-1$ or a 2-step from $i-2$ ). - Base case:
dp[0] = dp[1] = 1.
| |
O(n) time, O(n) space. Because the transition only needs the last
two values, we can shrink space to O(1):
| |
LeetCode 198 — House Robber#
Each house has some cash. You cannot rob two adjacent houses. Return the maximum total cash.
Recipe:
- State:
dp[i]= maximum cash robbed considering housesnums[0..i]. - Transition:
dp[i] = max(dp[i-1], dp[i-2] + nums[i]). Either skip house $i$ (so the answer is whateverdp[i-1]already had) or rob it (addnums[i]to the best answer two houses back). - Base case:
dp[0] = nums[0],dp[1] = max(nums[0], nums[1]).
| |
O(n) time, O(1) space after rolling. The “skip vs take” framing
generalizes to a huge family of problems - whenever a choice at index
$i$
blocks index $i-1$
, the state and transition look like House
Robber.
LeetCode 322 — Coin Change#
Given coin denominations and a target
amount, return the fewest coins that sum toamount, or $-1$ if impossible.
Recipe:
- State:
dp[a]= minimum number of coins summing to amount $a$ . - Transition:
dp[a] = min(dp[a - c] + 1 for c in coins if c <= a). For each coin denomination, the “last coin used” is $c$ , so the rest of the answer isdp[a - c]. - Base case:
dp[0] = 0(zero coins make zero), all other entries initialized to a sentinel “impossible” value.
| |
O(amount * len(coins)) time, O(amount) space. The sentinel trick
(INF = amount + 1) is worth remembering - it lets min work cleanly
without special-casing unreachable states.
LeetCode 300 — Longest Increasing Subsequence#
Find the length of the longest strictly increasing subsequence of
nums.
This is the first 1D problem where the state is “ends at index $i$ ” rather than “considers prefix $0..i$ ” - a subtle but important distinction.
Recipe:
- State:
dp[i]= length of the longest increasing subsequence ending atnums[i]. - Transition:
dp[i] = 1 + max(dp[j] for j < i if nums[j] < nums[i]), or just $1$ if no such $j$ exists. - Base case: every
dp[i]starts at $1$ (the subsequence containing onlynums[i]). - Answer:
max(dp)- the LIS may end anywhere.
| |
O(n^2) time. There is a famous O(n log n) patience-sorting trick
using bisect, but the DP version is the one you should write first -
it makes the structure obvious.
Two-Dimensional DP#
2D DP shows up the moment your state needs to track two independent things: positions in two strings, items and capacity, row and column in a grid. The recipe is unchanged; you just have a table instead of a row.
0/1 Knapsack (Classic)#
Given $n$ items with weights $w_i$ and values $v_i$ , and a knapsack with capacity $W$ , choose a subset that maximizes total value without exceeding $W$ . Each item is used at most once.
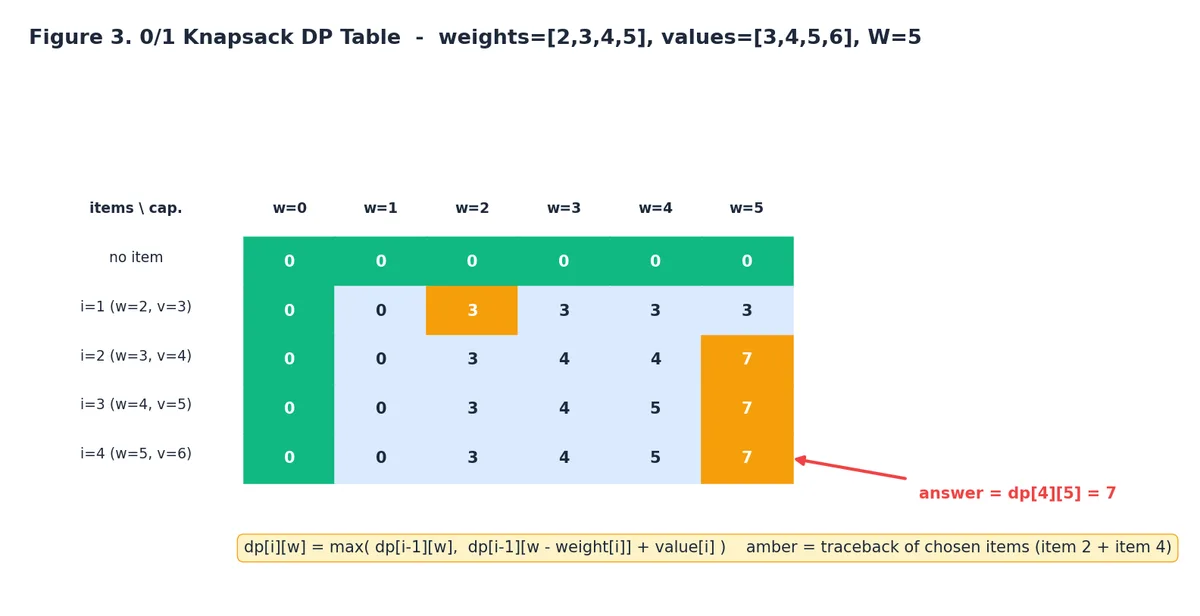
The amber cells in the figure are the optimal traceback for the example
weights [2, 3, 4, 5] and values [3, 4, 5, 6] at capacity $W = 5$
.
The answer is dp[n][W], and walking backwards through the cells tells
you which items were chosen.
Recipe:
- State:
dp[i][w]= best total value using a subset of the first $i$ items with capacity $w$ . - Transition: at item $i$
you either skip it
(
dp[i-1][w]) or take it if it fits (dp[i-1][w - w_i] + v_i). Pick the maximum. - Base case:
dp[0][w] = 0for every $w$ (no items, no value).
| |
O(n * W) time, O(n * W) space. The 1D space-optimized version
demonstrates the most important trap in DP space optimization - you
must iterate capacity in reverse, otherwise an item gets reused:
| |
If you iterate capacity forward instead, dp[w - wi] may already have
been updated this iteration, which is the recurrence for the
unbounded knapsack (each item usable infinitely many times) - a
useful problem in its own right, but a bug here.
LeetCode 1143 — Longest Common Subsequence#
Return the length of the longest common subsequence of two strings.

Recipe:
- State:
dp[i][j]= LCS length oftext1[0:i]andtext2[0:j]. - Transition:
- If
text1[i-1] == text2[j-1]:dp[i][j] = dp[i-1][j-1] + 1(extend the previous match diagonally). - Otherwise:
dp[i][j] = max(dp[i-1][j], dp[i][j-1])(drop one character from whichever side helps).
- If
- Base case:
dp[0][j] = dp[i][0] = 0(an empty string shares nothing).
| |
O(m * n) time, O(m * n) space, optimizable to O(min(m, n)) with
two rolling rows:
| |
LeetCode 72 — Edit Distance#
Return the minimum number of insert / delete / replace operations to turn
word1intoword2.
Edit Distance is LCS with a richer choice menu. Same skeleton, three operations instead of one.
Recipe:
- State:
dp[i][j]= minimum operations to convertword1[0:i]intoword2[0:j]. - Transition:
- If
word1[i-1] == word2[j-1]:dp[i][j] = dp[i-1][j-1](characters already match, no work needed). - Otherwise: take the minimum of three options - delete
word1[i-1](dp[i-1][j] + 1), insertword2[j-1](dp[i][j-1] + 1), or replace (dp[i-1][j-1] + 1).
- If
- Base case:
dp[i][0] = i(delete every character ofword1),dp[0][j] = j(insert every character ofword2).
| |
O(m * n) time and space, with the same two-row optimization
available.
Space Optimization#

The space optimization trick is simple in principle and tricky to get right in practice. You always ask the same question: what slice of the table does my transition actually read?
- Two scalars when
dp[i]only needsdp[i-1]anddp[i-2](Fibonacci, Climbing Stairs, House Robber). - One row when
dp[i][j]only needs the previous row (Knapsack, LCS, Edit Distance). Pay attention to read order: forward sweeps versus backward sweeps determine whether the row in memory still holds the previous row’s value when you read it. - Two rows when you need both diagonal
dp[i-1][j-1]and current row reads. Easier to reason about than one row, slightly more memory.
Rule of thumb: write the O(m * n) version first, get it correct, then
prune. Skipping straight to the optimized form is how subtle off-by-one
and read-order bugs sneak in.
Top-Down vs Bottom-Up#
For every problem above, you can write a memoized recursive version that is asymptotically equivalent.
| |
When to prefer each:
- Top-down memoization wins when the recursion is the natural way
to think (tree DP, game theory, problems with irregular state
graphs).
functools.cachemakes it almost free in Python. - Bottom-up tabulation wins when you want strict control over iteration order (so you can space-optimize), or when you are worried about Python’s recursion limit on large inputs.
In interviews, leading with bottom-up signals that you have thought about iteration order and space. Falling back to top-down signals that you are comfortable with recursion. Knowing both, and converting between them on demand, is the goal.
A Map of Common DP Patterns#

Most problems you will see fit into one of four buckets:
- Linear DP - state indexed by one position. Climbing Stairs, House Robber, LIS, Maximum Subarray. The hardest part is choosing between “ends at $i$ ” and “uses prefix $0..i$ ”.
- 2D / Grid DP - state indexed by two positions, usually two strings or two grid coordinates. LCS, Edit Distance, Unique Paths, Minimum Path Sum.
- Interval DP - state indexed by an interval $[i, j]$ , filled in order of increasing interval length. Burst Balloons, Matrix Chain Multiplication, Longest Palindromic Subsequence.
- State machine DP - state indexed by a position plus a small extra dimension (held / sold, $k$ uses left, parity, mask). Stock problems with cooldowns or transaction limits, the classic 0/1 knapsack, and bitmask DP all live here.
When you face a new problem, classify it first; the category tells you what shape the state should have.
Common Pitfalls#
A short checklist of the bugs that show up over and over:
- Vague state: you can’t write the transition cleanly because
dp[i]“kind of” represents the answer. Tighten the definition before writing code. - Wrong base case: the table is mathematically right but the starting cell is off by one. The fastest way to catch this is to hand-compute the first three or four entries.
- Forgetting “ends at” vs “considers prefix”: in LIS, this is the
difference between
max(dp)anddp[-1]. - Wrong sweep direction in 1D knapsack: forward sweep silently turns 0/1 knapsack into unbounded knapsack.
- Mutable default arguments in memoization:
def f(n, memo={}):shares the cache across calls. Usefunctools.cacheinstead. - Optimizing space too early: bug-prone, hard to debug, and usually unnecessary on a whiteboard. Space-optimize last.
FAQ#
How do I recognize a DP problem?#
Look for an optimization word (“max”, “min”, “count”, “longest”, “fewest”), a structure that lets you commit to one decision and recurse on a smaller version of the same problem, and a small enough state space that caching is feasible. If your first instinct is a recursion that branches a lot, suspect DP.
Top-down or bottom-up?#
Top-down for trees and irregular state graphs, bottom-up when you want to space-optimize. Either gets full credit in an interview as long as the analysis is correct.
I’ve defined a state but the transition won’t fall out cleanly. The state is probably too coarse. Add a dimension: a flag for “did I use the last item”, a counter for “how many transactions remain”, a bitmask for “which subset have I covered”. The state must capture every piece of information the transition depends on.
My answer is right for small cases but wrong for large ones. Almost always integer overflow (in C++/Java), recursion depth (in Python), or a bug in your space-optimized version that the 2D version didn’t have. Run the unoptimized version on the failing case and compare.
How is DP different from greedy?#
Greedy commits to a local choice and never reconsiders. DP enumerates every reasonable choice at each step and takes the best, possibly overruling earlier decisions. Activity selection works greedy; coin change in arbitrary denominations does not.
Can DP always be space-optimized?#
No. The optimization works only when the transition reads from a bounded slice of the table. Problems that need the entire table - for example, ones that reconstruct the optimal sequence by backtracking through the DP table - keep the full table.
Practice Path#
A reasonable order to internalize DP:
- Warm up on 1D: Climbing Stairs, House Robber, Maximum Subarray.
- Add a second dimension: Coin Change, Unique Paths, 0/1 Knapsack.
- Two-string DP: LCS, Edit Distance, Distinct Subsequences.
- State machines: Best Time to Buy and Sell Stock with cooldown or with $k$ transactions.
- Intervals: Longest Palindromic Subsequence, Burst Balloons.
- Bitmask DP: Travelling Salesman, Partition to K Equal Subsets.
If a problem feels impossible, write the recursive brute force first. The state of the recursion is your DP state; the recursive call arguments are your indices. Add memoization, then convert to tabulation if you need the space win.
Summary#
DP is one recipe applied seven times in this article. State, transition, base case. Once those three are nailed down, the implementation is mechanical and the analysis is immediate. The hard problem is never the code - it is choosing a state that is precise enough to make the transition obvious. Spend your time there, and the rest follows.
The seven problems above - Climbing Stairs, House Robber, Coin Change, LIS, 0/1 Knapsack, LCS, Edit Distance - are not just exercises. They are the templates that essentially every harder DP problem reduces to. Master them, and most of the LeetCode “Hard” tag becomes “I have seen this before in a different costume”.
LeetCode Patterns 10 parts
- 01 LeetCode (1): Patterns — Hash Tables
- 02 LeetCode (2): Patterns — Two Pointers
- 03 LeetCode (3): Patterns — Linked List Operations
- 04 LeetCode (4): Patterns — Sliding Window Technique
- 05 LeetCode (5): Patterns — Binary Search
- 06 LeetCode (6): Patterns — Binary Tree Traversal and Construction
- 07 LeetCode (7): Patterns — Dynamic Programming Basics you are here
- 08 LeetCode (8): Patterns — Backtracking Algorithms
- 09 LeetCode (9): Patterns — Greedy Algorithms
- 10 LeetCode (10): Patterns — Stack and Queue


