
LeetCode (1): Patterns — Hash Tables
Master hash table patterns through four classic LeetCode problems — Two Sum, Group Anagrams, Longest Substring Without Repeating Characters, and Top K Frequent Elements. Learn complement search, canonical-form grouping, sliding window with counts, and bucket sort by frequency.

A hash table is the cheapest superpower in your toolbox. You spend a constant amount of memory per stored item, and in return every “is x in here?” question costs roughly one CPU instruction. Whole families of O(n²) brute-force solutions collapse into a single O(n) pass once you reach for one.
This article is the first installment of the LeetCode Patterns series. We will build hash table intuition from scratch, then work through four template problems — Two Sum, Group Anagrams, Longest Substring Without Repeating Characters, and Top K Frequent Elements — each illustrating a reusable pattern you will see again and again on harder problems.
Series Navigation#
LeetCode Patterns (10 articles):
- Hash Tables — Two Sum, Group Anagrams, Longest Substring Without Repeating Characters, Top K Frequent ← you are here
- Two Pointers — collision pointers, fast / slow, partitioning
- Linked Lists — reversal, cycle detection, merging
- Sliding Window — fixed and variable windows
- Binary Search — on indices, on answers, on real numbers
- Binary Tree Traversal — recursion, BFS, LCA
- Dynamic Programming — 1D, 2D, knapsack family
- Backtracking — permutations, combinations, pruning
- Greedy Algorithms — exchange argument, scheduling
- Stack & Queue — monotonic stack, deque tricks
What a hash table really is#
A hash table stores (key, value) pairs in an internal array. The trick is the hash function, which turns any key into an integer index that says which array slot the pair belongs in.
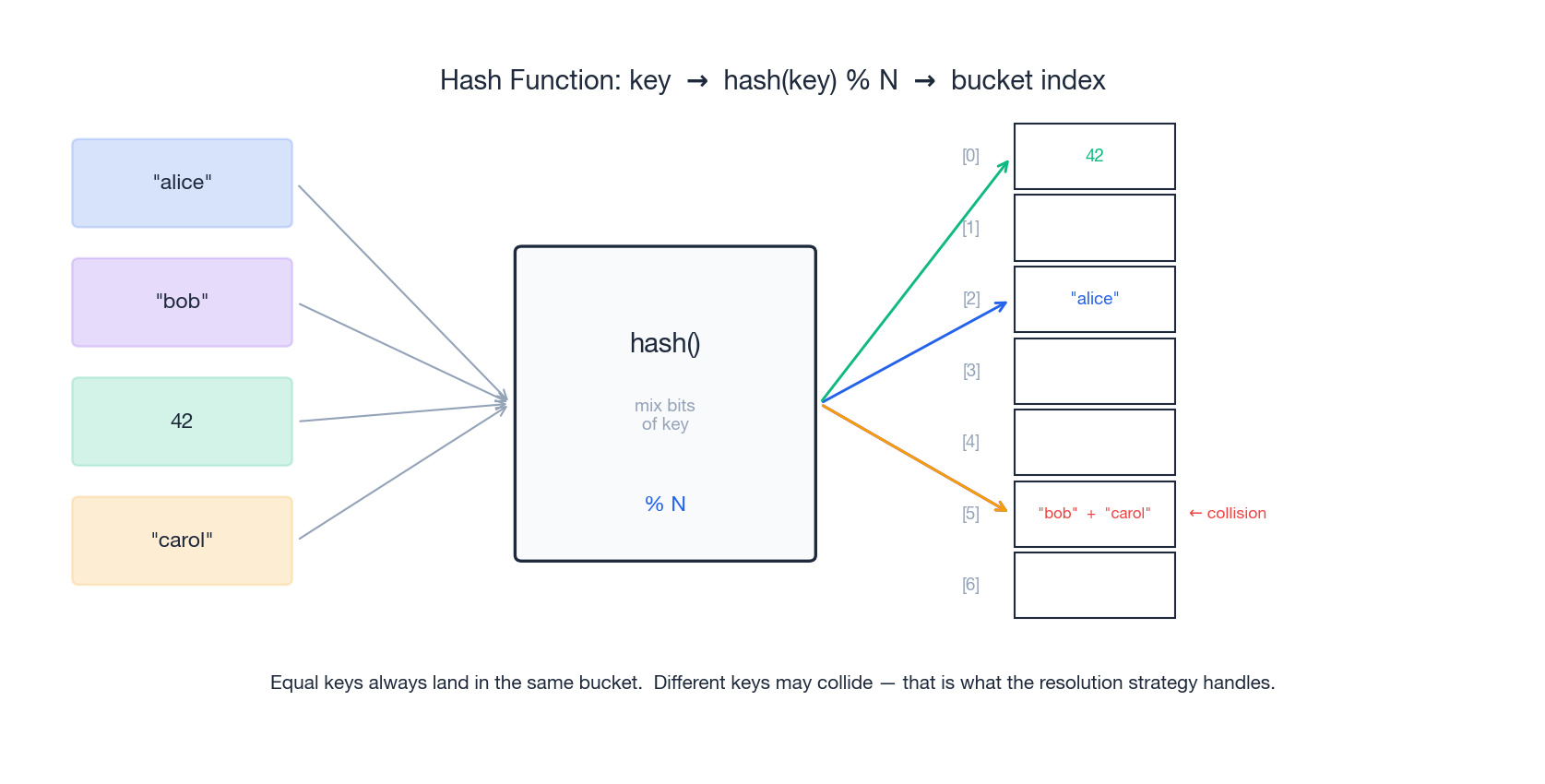
Three guarantees come out of this design:
- Determinism. The same key always hashes to the same slot. That is what makes lookups possible.
- Average-case
O(1). With a reasonable hash function, the work per insert / lookup / delete does not grow withn. - Worst-case
O(n). If too many keys collide into the same slot, you degrade to a linear scan. In practice this only happens with adversarial input or a broken hash function.
Collisions are inevitable#
Two different keys can hash to the same slot — that is a collision. Hash tables handle them with one of two strategies:
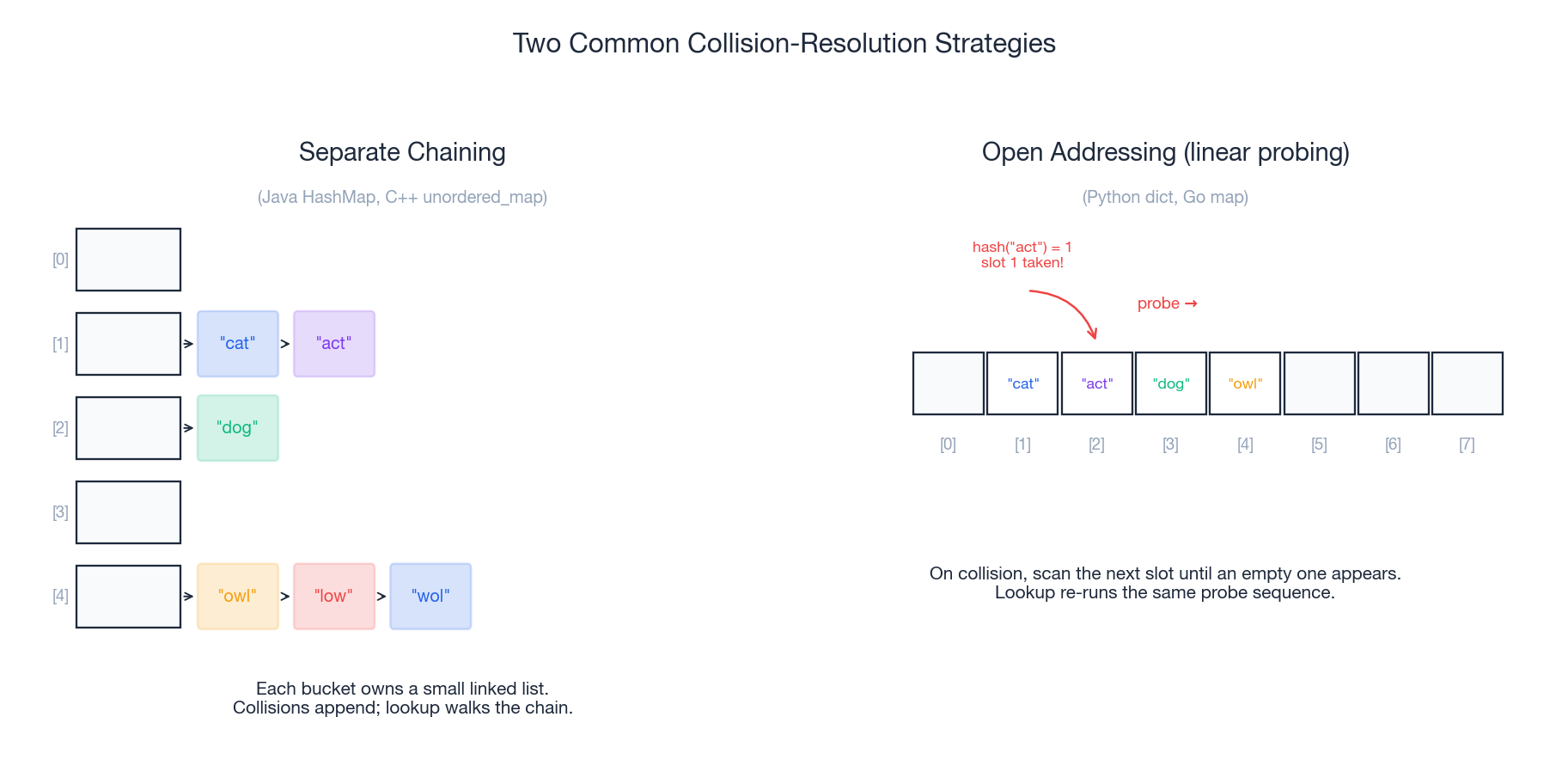
- Separate chaining keeps a small linked list (or balanced tree) inside each slot. Collisions just append to the chain. Used by Java’s
HashMapand C++’sstd::unordered_map. - Open addressing keeps one entry per slot. On a collision it probes forward (
slot+1,slot+2, …) until it finds an empty one. Used by Python’sdictand Go’smap.
You almost never implement collision handling yourself. But knowing the mechanism explains why hash tables can occasionally be slower than O(1) — and why a good hash function matters.
Hash table vs alternatives#
Why reach for a hash table instead of a sorted array or a plain array?
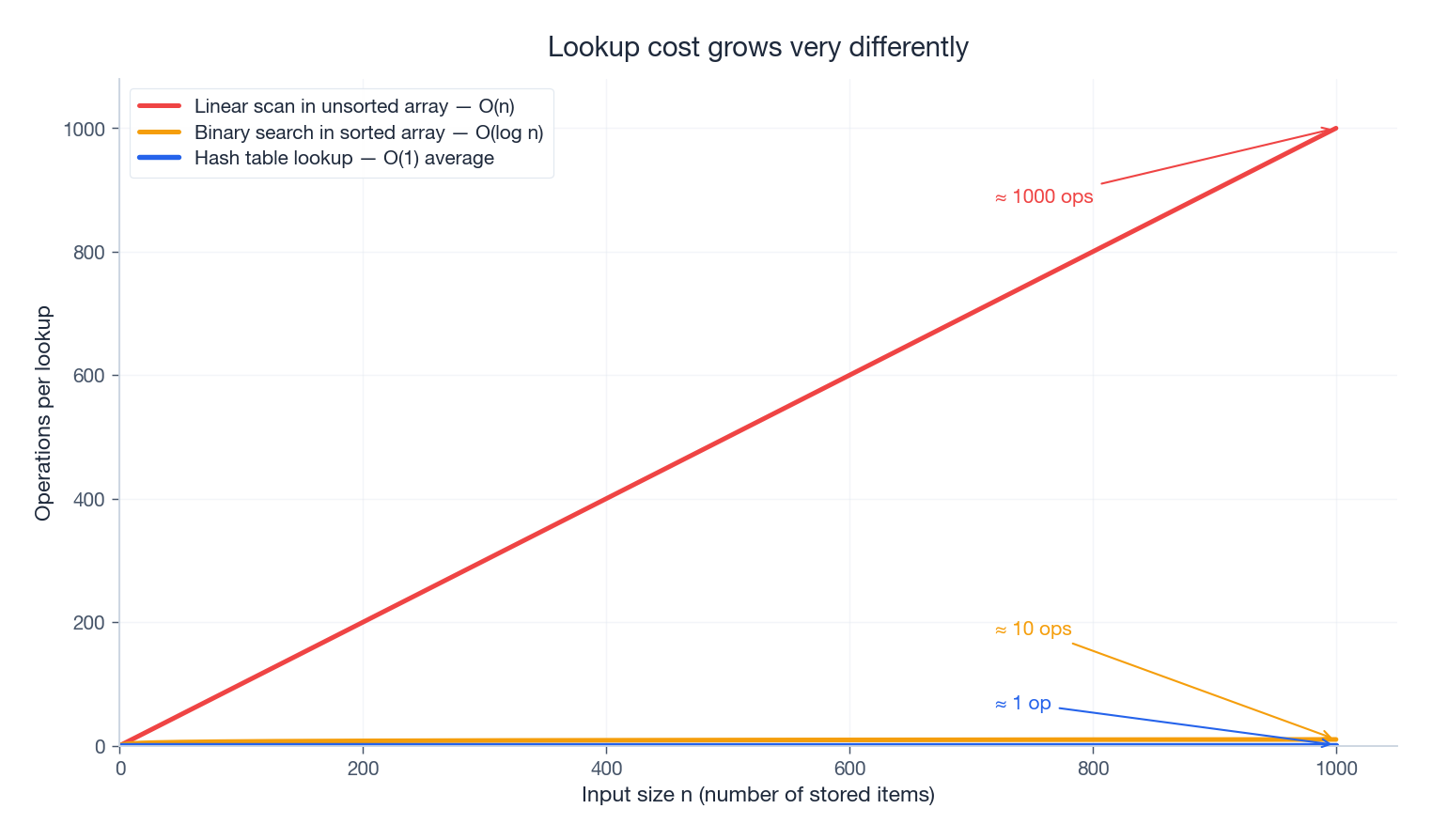
The gap is enormous as n grows. At n = 1000, a linear scan does ~1000 comparisons per lookup, binary search does ~10, a hash lookup does ~1. Memory is the price you pay: a Python dict carries roughly 8–16× the byte cost of a raw array, because it stores the hash, the key, the value, and keeps the table sparse to avoid collisions.
Pick the right structure#
Before you write code, decide what you actually need:
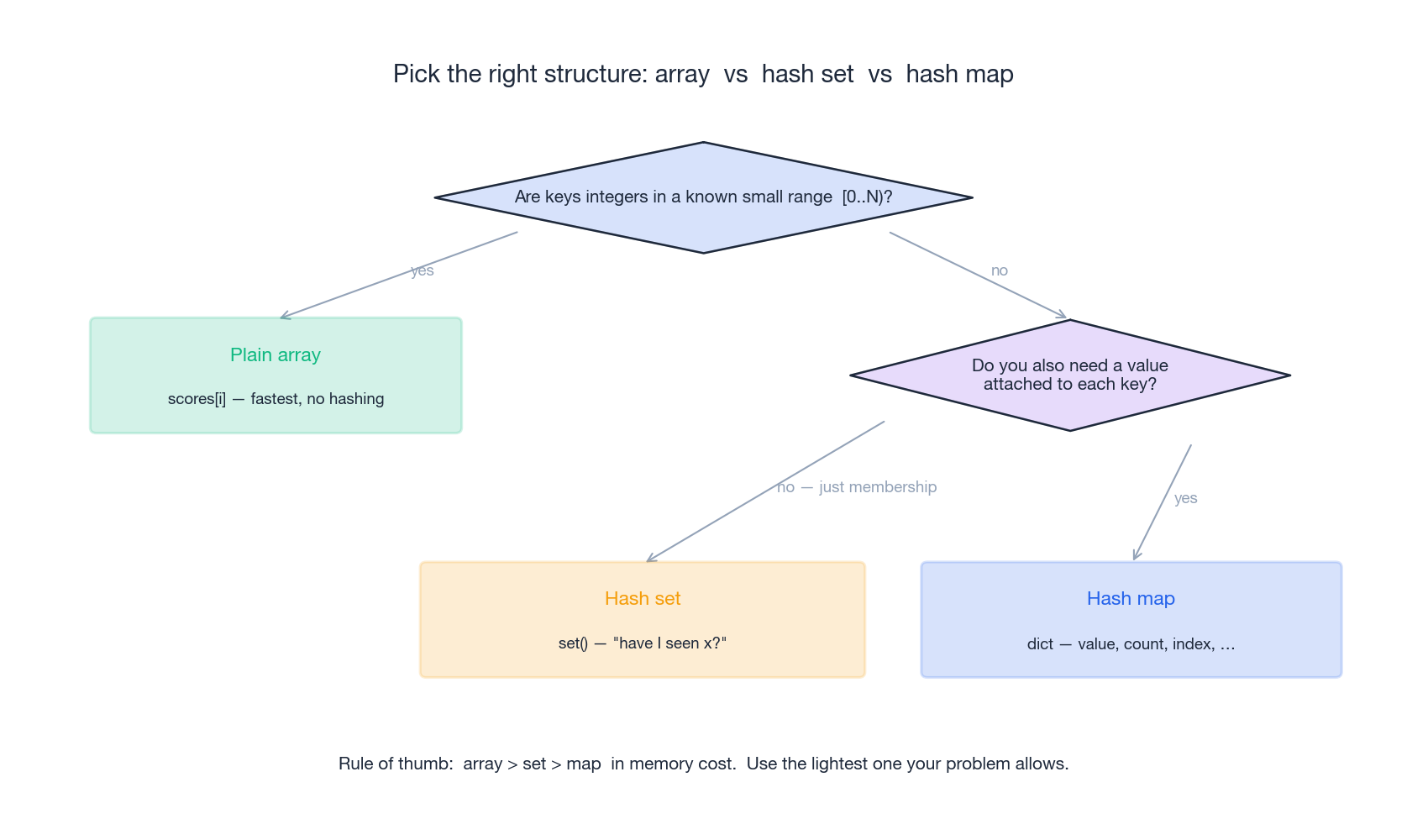
The rule of thumb is array > set > map in memory cost. Use the lightest structure that solves your problem. Concretely:
| Need | Use |
|---|---|
Index by integer in [0, N) | plain list / array |
| “Have I seen this before?” | set |
| “What value goes with this key?” | dict |
| Counting occurrences | collections.Counter |
| Auto-creating empty buckets | collections.defaultdict(list) |
In Python, set and dict share the same hash machinery, so use whichever expresses your intent — that is also the easiest code to read and debug.
Two Sum — the complement pattern#
LeetCode 1. Given an array
numsand an integertarget, return the indices of the two numbers that add up totarget. You may assume exactly one solution exists, and you may not use the same element twice.
| |
Brute force first#
The naive solution checks every pair, which is O(n²) time and O(1) space:
| |
For n = 10⁴ that is roughly 50 million comparisons. We can do better.
The hash table insight#
While scanning left to right, every time we look at num, the question is not “is num in the array?” but “have I already seen target − num?” If yes, we have our pair. So we keep a map value → index of everything seen so far.
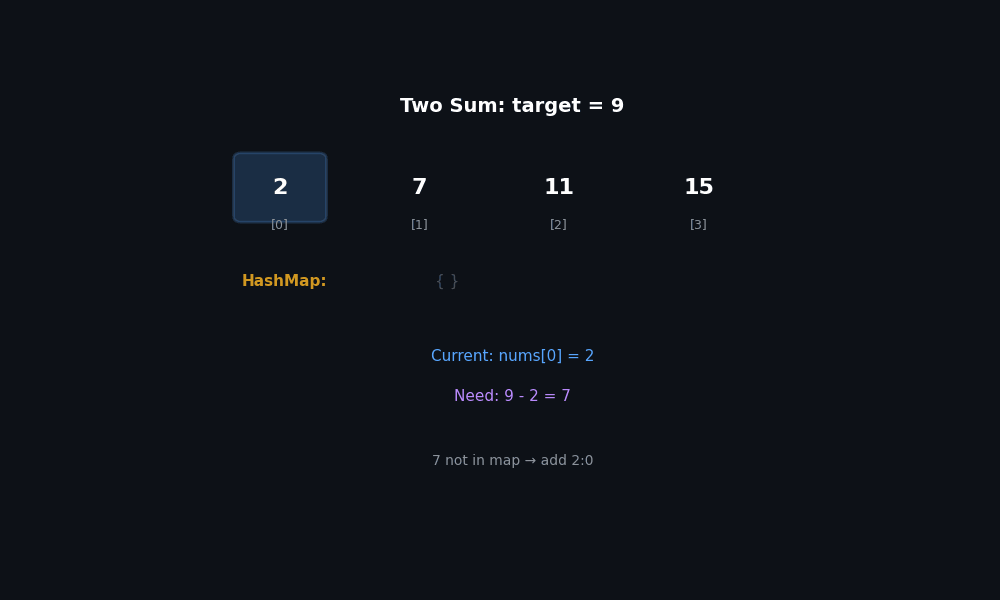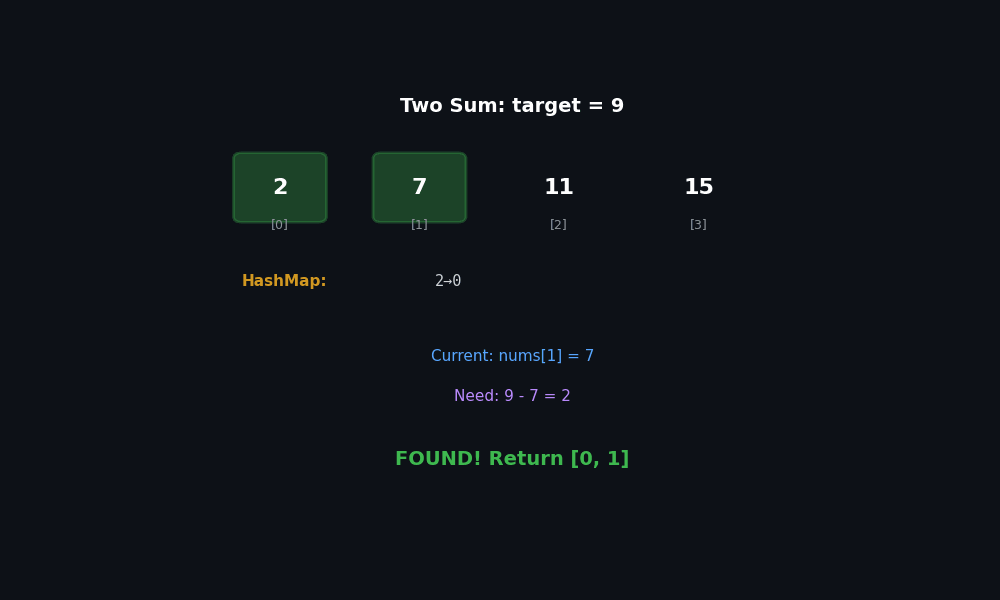
| |
Two details that matter:
- Check before insert. If you store
seen[num] = ifirst, an input likenums = [3, 0, 0]withtarget = 6would happily pairnums[0]with itself. - Return order.
seen[complement]is the earlier index, so it must come first:[seen[complement], i].
Why it is O(n)#
One pass through nums does n iterations. Each iteration is one dictionary lookup and possibly one insert — both O(1) average. Total: O(n) time, O(n) space (the dictionary holds at most n entries).
You cannot do better in time and space for the unsorted version of this problem. If the array were already sorted, the two-pointer technique (covered in part 2) achieves O(n) time and O(1) space — but that requires a sort, which is O(n log n).
Pattern: complement search#
Whenever you are looking for pairs that satisfy a relation involving the other element, ask whether you can rephrase the problem as “for each x, is there a previously-seen y such that f(x, y) holds?” If yes, a hash table will usually win:
| Problem | What you store | What you ask |
|---|---|---|
| Two Sum | seen values | target − num in seen? |
| Pairs with given difference (LeetCode 532) | seen values | num + k and num − k in seen? |
Subarray sum equals k (LeetCode 560) | prefix sums | prefix − k in seen? |
| Continuous subarray sum (LeetCode 523) | prefix sum % k | same residue seen before? |
Group Anagrams — the canonical-form pattern#
LeetCode 49. Given an array of strings, group the anagrams together.
| |
Two strings are anagrams if they have the same multiset of characters but in different orders. The whole game is to design a key that maps every anagram to the same bucket.
Approach 1 — sorted string as the key#
The most direct canonical form: sort the characters.
| |
Simple, generic, works for any character set. The cost is the sort: O(k log k) per string.
Approach 2 — character count as the key#
If the alphabet is small (say lowercase English, 26 letters), counting characters is O(k) and we skip the sort:
| |
The tuple matters. Dictionary keys must be immutable and hashable — a list cannot be a key, but its tuple version can.
Pattern: canonical form#
Whenever a problem says “group / find / count things that are equal up to some symmetry”, ask “what is the canonical representation that is the same for every member of an equivalence class?” Then use that representation as a hash key.
| Problem | Equivalence | Canonical key |
|---|---|---|
| Group Anagrams | same character multiset | sorted string or 26-tuple of counts |
| Group Shifted Strings (LeetCode 249) | same gap pattern between letters | tuple of consecutive differences |
| Isomorphic Strings (LeetCode 205) | same letter pattern | normalized “first-occurrence” string |
| Group strings by length | same length | the length itself |
Longest Substring Without Repeating Characters — sliding window with a hash map#
LeetCode 3. Given a string
s, find the length of the longest substring with no repeated characters.
| |
This is where hash tables team up with the sliding window technique. We maintain a window [left, right] and slide right forward one character at a time. As soon as the new character would duplicate one already in the window, we shrink from the left until the window is valid again.
The hash map’s job: for each character, remember the most recent index where we saw it. That lets us jump left straight past the duplicate in O(1) instead of walking it forward one step at a time.
| |
The trace for "abcabcbb":
right | ch | last_seen after update | left | window | best |
|---|---|---|---|---|---|
| 0 | a | {a:0} | 0 | a | 1 |
| 1 | b | {a:0, b:1} | 0 | ab | 2 |
| 2 | c | {a:0, b:1, c:2} | 0 | abc | 3 |
| 3 | a | {a:3, b:1, c:2} | 1 | bca | 3 |
| 4 | b | {a:3, b:4, c:2} | 2 | cab | 3 |
| 5 | c | {a:3, b:4, c:5} | 3 | abc | 3 |
| 6 | b | {a:3, b:6, c:5} | 5 | cb | 3 |
| 7 | b | {a:3, b:7, c:5} | 7 | b | 3 |
Pattern: variable-size window with a hash map#
Use this template whenever you need the longest / shortest substring or subarray satisfying a constraint that you can update in O(1) as you add or drop a single element:
| |
Variants you will meet later: minimum window substring (LeetCode 76), longest substring with at most K distinct characters (LeetCode 340), permutation in string (LeetCode 567).
Top K Frequent Elements — frequency map + bucket sort#
LeetCode 347. Given an integer array
numsand an integerk, return thekmost frequent elements.
| |
Step one is obvious — count frequencies with a hash map (or Counter). Step two is the interesting design choice: how do you pick the top k?
Approach 1 — heap (O(n log k))#
Push each (count, value) pair through a min-heap of size k:
| |
Counter.most_common already uses a heap underneath. Clean, idiomatic, and good enough most of the time.
Approach 2 — bucket sort (O(n))#
Frequencies are bounded by n. So we can put each value into a bucket indexed by its count, then read the buckets back from highest to lowest:
| |
This is the classic “counts are bounded, so use the count as an index” trick. It is genuinely O(n) — no logarithmic factor — and shows up again in problems like Sort Characters by Frequency (LeetCode 451).
Pattern: frequency counting#
Three Python idioms you will use constantly:
| |
Frequency maps power: anagram checks, majority element, first unique character, sort by frequency, top-K, and any “how often does X happen?” problem.
Common Pitfalls#
A short but high-yield list — most hash table bugs in interviews fall into one of these:
- Inserting before checking. In Two Sum, store after you check. Otherwise you may pair an element with itself.
- Unhashable keys. Lists, sets, and dicts cannot be dict keys. Convert to
tuple(...)(orfrozenset(...)) first. - Mutating a key after insertion. If you change the contents of an object that is being used as a key, the hash code becomes stale and you may never find the entry again. Treat keys as immutable.
- Using
dictwhen you only needset. Storingseen[x] = Truewastes ~30–40% memory compared toseen.add(x). - Iterating while mutating. Adding or deleting keys mid-iteration can raise
RuntimeError. Iterate over a snapshot —list(d.items())— if you must mutate. - Forgetting that hash tables are unordered (in spirit). Python 3.7+ preserves insertion order, but do not rely on key order for algorithm correctness.
Interview checklist#
When you suspect a hash table fits, run through this in your head before writing code:
- What is the key? A value, a sorted form, a count tuple, a prefix sum?
- What is the value? An index, a count, a list of indices, a boolean?
- Set or map? If you only need membership, a set is lighter.
- Where does the answer come from? A hit during the scan, or a final pass over the table?
- Edge cases. Empty input, single element, all duplicates, all unique, negatives.
Out loud, the script in interviews is roughly:
“Brute force is
O(n²)because for each element I compare against every other. I can avoid that by storing a hash map of<key>→<value>as I go, so each lookup becomesO(1). Total timeO(n), spaceO(n).”
What to practise next#
Once these four patterns feel automatic, here is a graded set of follow-ups:
- Easy. Contains Duplicate (217), Valid Anagram (242), Intersection of Two Arrays (349).
- Medium. Subarray Sum Equals K (560), Longest Consecutive Sequence (128), 4Sum II (454), Insert Delete GetRandom O(1) (380).
- Hard. First Missing Positive (41 — uses the input array as a hash table), Substring with Concatenation of All Words (30), Longest Substring with At Most K Distinct Characters (340).
In part 2 (Two Pointers) we will look at the other side of the trade-off: when the input is sorted (or can afford to be sorted), two pointers can match a hash table’s O(n) time while using only O(1) extra space. The interesting question is when to pick which — and we will answer it with concrete problems.
Why this pattern shows up in interviews#
Two reasons, both honest:
- Hash tables collapse
O(n²)toO(n)in one observation. That is the cleanest demonstration of “the right data structure makes the algorithm trivial,” which is half of what algorithm interviews are actually testing. If you can spot that the inner loop is searching for something the outer loop already knows, you reach for a hash table. - Every real backend uses them. A request handler doing
users[user_id]is hash-table indexing. Dedup in a stream processor isseen.add(...). The cache in front of your database is a hash table. Interviewers reach for hash table problems because they’re maximally transferable.
The pattern to recognize in problem statements: any phrase like “find pairs/triplets/groups that satisfy …” or “have we seen this before?” or “count occurrences of …” is a hash table waiting to be written.
Production analog#
Three concrete places the hash-table patterns from this article appear in code I’ve actually written:
- Two Sum / pair lookup. Reconciling two systems’ export files where a row in A should match a row in B with a complementary key. Build a dict on the smaller file once, scan the larger file once.
O(a + b)instead ofO(a * b). The same trick scales from 1k rows to 100M rows. - Group by sorted-string key. Deduplicating product SKUs that differ only in attribute order —
"red,large,cotton"vs"large,cotton,red"are the same SKU. The canonical form istuple(sorted(...)), used as a dict key. - Prefix-sum hash for “subarray sum equals K”. This shows up in time-series analytics: “find all 5-minute windows where revenue equals exactly $X”. The trick generalizes to arbitrary aggregations as long as they’re invertible (sum, XOR, count). Not invertible (max, min): you need a different structure.
The interview problem is a sandbox; the production version usually adds streaming, eviction, and concurrency on top, but the algorithm core is identical.
Test your solution on edge cases#
For Two Sum specifically — the canonical introduction problem — the cases that catch most submissions:
| |
The [3, 3] case is the famous one. A naive enumerate + seen[num] = i written before the lookup will pair index 0 with itself. The fix is the order: look up first, then store.
| |
Two lines, one in the right order. This is the entire reason this question is asked.
LeetCode Patterns 10 parts
- 01 LeetCode (1): Patterns — Hash Tables you are here
- 02 LeetCode (2): Patterns — Two Pointers
- 03 LeetCode (3): Patterns — Linked List Operations
- 04 LeetCode (4): Patterns — Sliding Window Technique
- 05 LeetCode (5): Patterns — Binary Search
- 06 LeetCode (6): Patterns — Binary Tree Traversal and Construction
- 07 LeetCode (7): Patterns — Dynamic Programming Basics
- 08 LeetCode (8): Patterns — Backtracking Algorithms
- 09 LeetCode (9): Patterns — Greedy Algorithms
- 10 LeetCode (10): Patterns — Stack and Queue