
LeetCode (3): Patterns — Linked List Operations
A complete linked list toolkit: reversal (iterative and recursive), merging sorted lists, Floyd's cycle detection, removing the nth node from end, and an LRU cache built on a doubly linked list plus hash map.
A linked list is the simplest data structure that forces you to think in pointers. Arrays let you index in $O(1)$
and forget about layout; linked lists hand you a head pointer and ask, “now what?” That single shift — from indices to references — is what makes linked-list problems so common in interviews. They are short to state, brutal to get right, and reward exactly the habits good engineers build: drawing pictures, naming pointers, and never dereferencing without checking for None.
This article covers five problems that, together, encompass every classical linked-list technique you’ll see in coding interviews:
- Reverse a linked list — the canonical pointer-rewiring exercise, both iterative and recursive.
- Merge two sorted lists — the dummy-node pattern and how it eliminates head-case clutter.
- Linked list cycle detection (Floyd) — fast/slow pointers and the algebra that proves they meet at the entrance.
- Remove the nth node from end — two pointers with a fixed gap, in a single pass.
- LRU cache — the doubly linked list + hash map combo that powers every real-world cache.
Each section follows the same format: problem, idea, code, complexity, and a worked example. The figures below show the pointer state before and after each rewiring, which is how you should solve these in your head and on the whiteboard.
Series Navigation#
LeetCode Patterns (10 articles): Hash Tables, Two Pointers, Linked List Operations (this article), Binary Tree Traversal, Dynamic Programming, Backtracking, Binary Search, Stacks and Queues, Graphs, Greedy and Bit Manipulation.
Linked List Fundamentals#
A singly linked list node carries a value and one pointer:
| |
That is the entire interface. Every algorithm in this article is just a sequence of node.next = something assignments performed in the right order, with the right safety checks.
Linked list vs. array#
| Feature | Array | Linked list |
|---|---|---|
| Random access | $O(1)$ | $O(n)$ |
| Insert / delete at known position | $O(n)$ (shift) | $O(1)$ (rewire) |
| Memory layout | Contiguous | Scattered |
| Cache locality | High | Low |
| Dynamic growth | Reallocate | Natural |
The trade-off is clear: arrays excel in access and cache behavior, while linked lists are better for frequent mutations and when you don’t need to jump around. Once you understand this, problem selection becomes obvious — “can I reach the kth element?” suggests an array; “do I need to splice out the middle without copying?” suggests a list.
Insert and delete: rewire two pointers, never more#
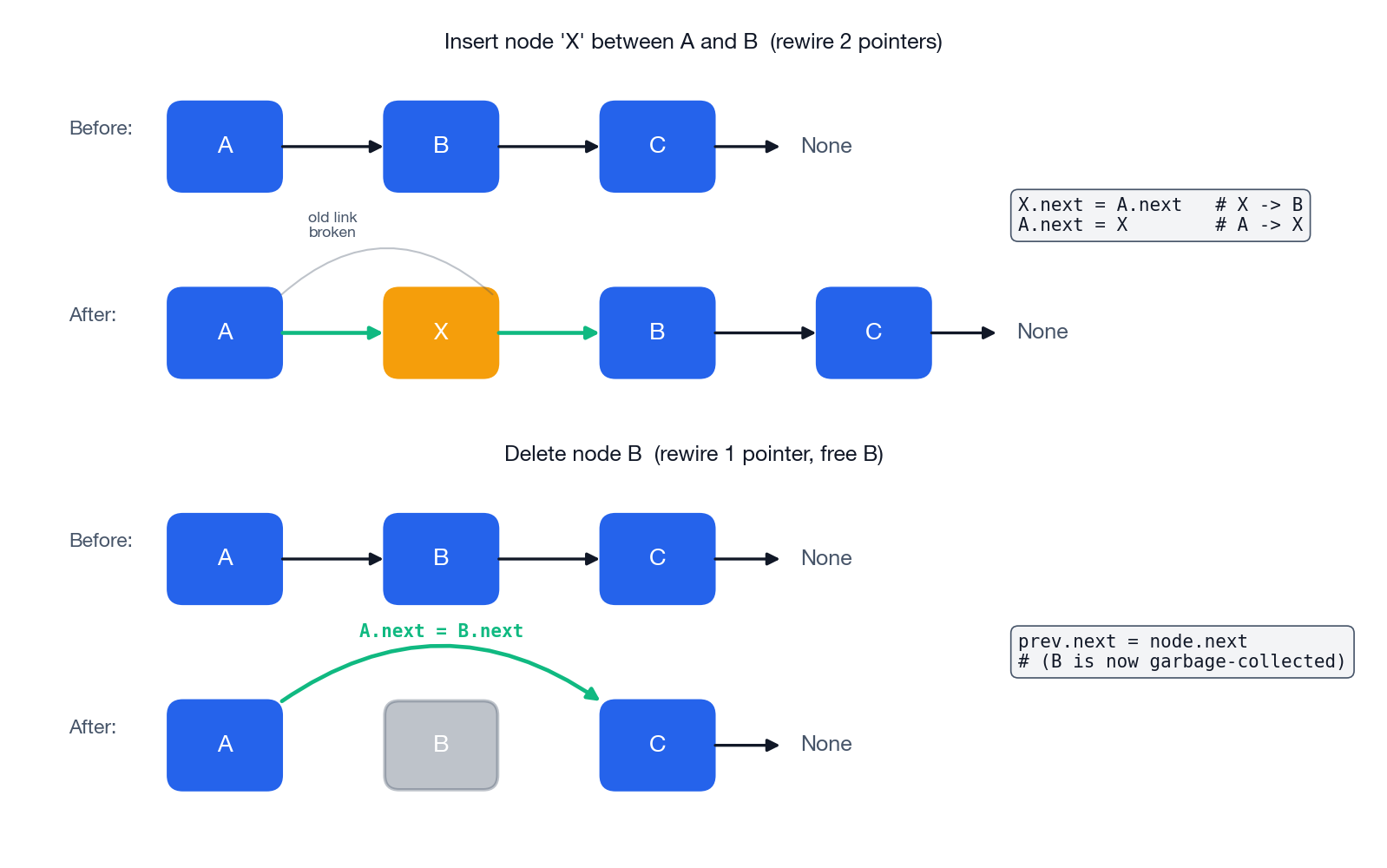
Insertion of X between A and B is exactly two assignments, in this order:
| |
If you reverse the order, A.next is overwritten before you save it, and B is unreachable. Deletion is even simpler — one assignment redirects A past B, and the garbage collector reclaims B:
| |
This is the core concept: linked list operations are pointer assignments performed in a specific order. Everything else in this article is a variation on this theme.
LeetCode 206 — Reverse Linked List#
Given the head of a singly linked list, reverse the list and return its new head.
Example:
1 → 2 → 3 → 4 → 5becomes5 → 4 → 3 → 2 → 1.Follow-up: solve it iteratively and recursively.
This is the “hello world” of pointer manipulation. The challenge is that you have to flip every next pointer in place without losing access to the rest of the list.
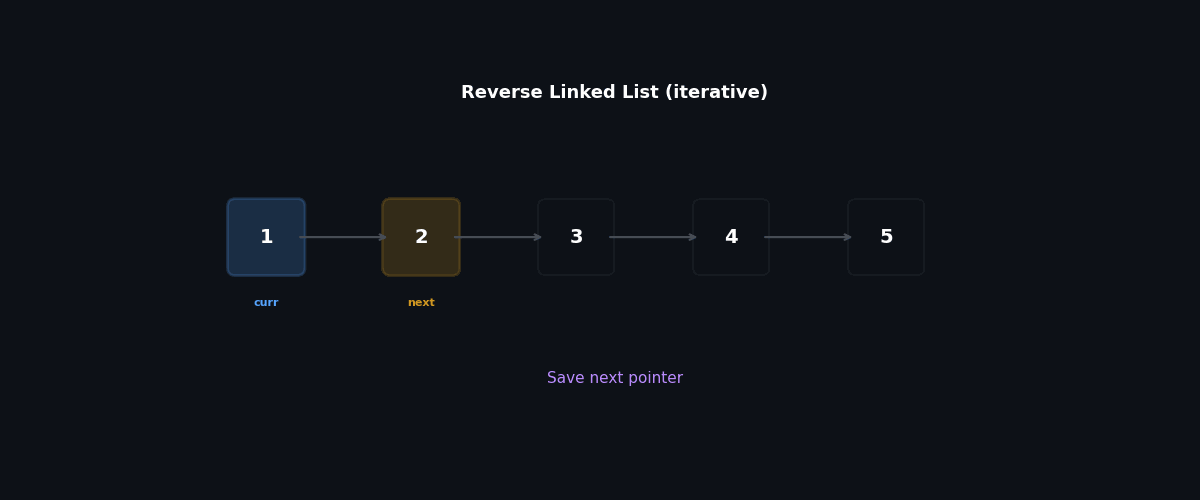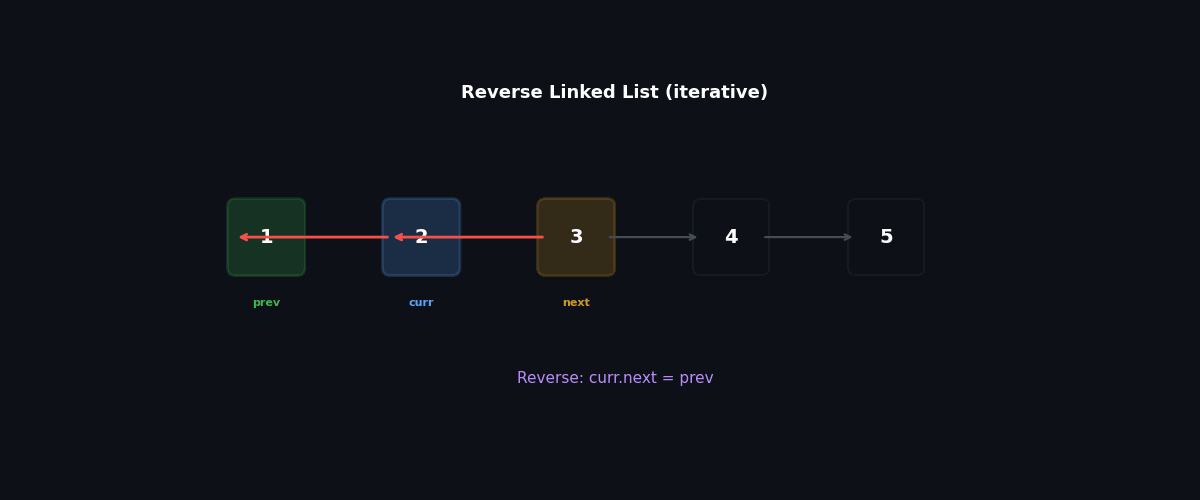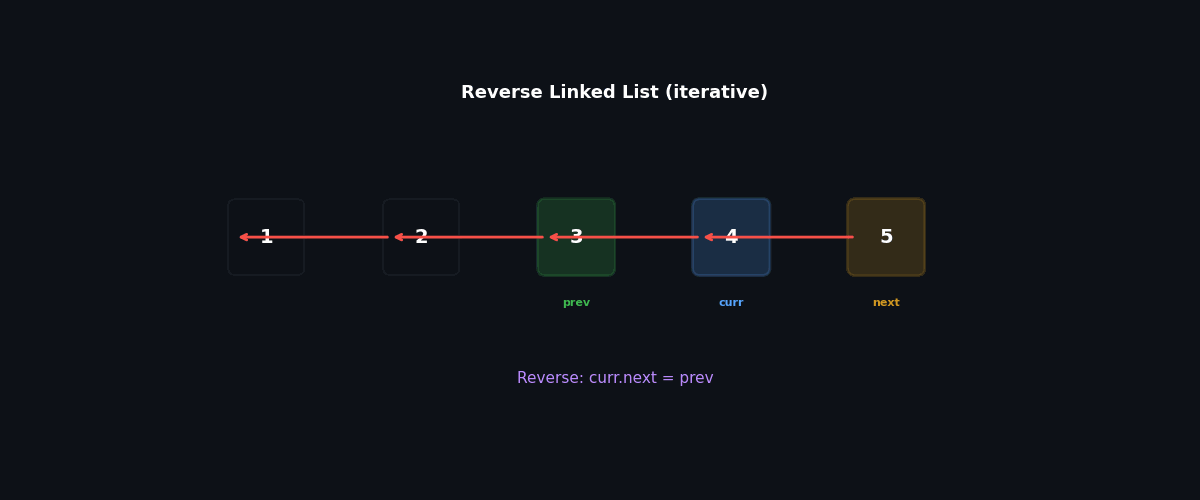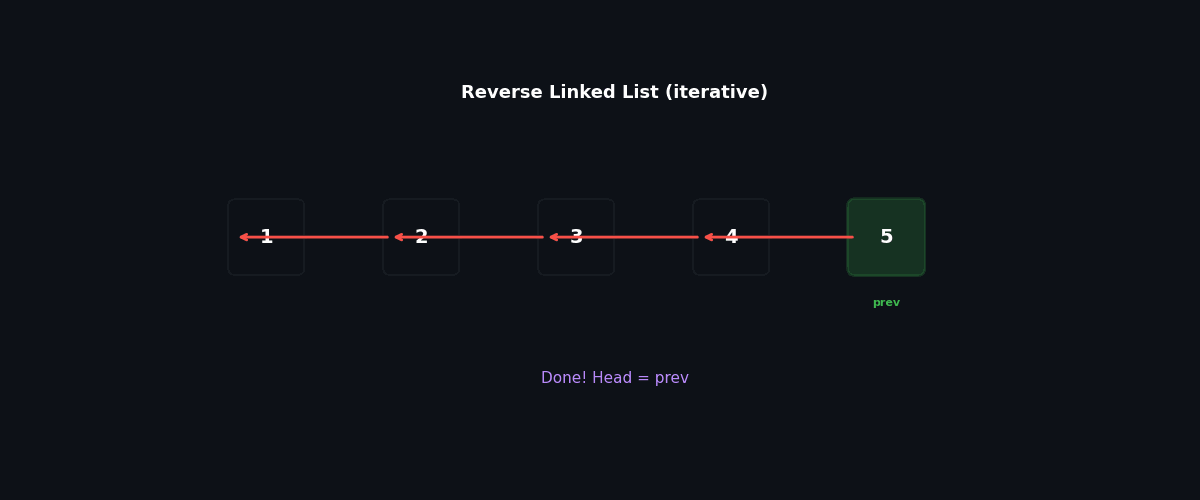
Iterative: three pointers, $O(1)$ space#
The trick is to remember that flipping curr.next = prev immediately destroys our path forward, so we must save it first.
| |
Walkthrough on 1 → 2 → 3 → None:
| Step | prev | curr | After flip |
|---|---|---|---|
| 0 | None | 1 | — |
| 1 | 1 | 2 | None ← 1, remaining 2 → 3 → None |
| 2 | 2 | 3 | None ← 1 ← 2, remaining 3 → None |
| 3 | 3 | None | None ← 1 ← 2 ← 3 |
Return prev = 3, which now heads the reversed list.
Edge cases that the loop already handles correctly:
- Empty list (
head is None): the loop body never runs, returnprev = None. - Single node: one iteration, sets
1.next = None, returns1.
Recursive: rewire on the way back up#
The recursive view says: “reverse everything after head, then make the old head.next point back to head.”
| |
The single line that confuses everyone is head.next.next = head. Read it slowly:
head.nextis the node that comes right afterheadin the original list.- After the recursive call, that node has become the tail of the reversed sublist.
- We want the tail to point back to
head, so we assign tohead.next.next.
Then head.next = None cuts head’s outgoing link so the new tail terminates cleanly.
Iterative or recursive?#
| Approach | Time | Space | When to prefer |
|---|---|---|---|
| Iterative | $O(n)$ | $O(1)$ | Production code, long lists, no stack overflow risk |
| Recursive | $O(n)$ | $O(n)$ | Whiteboard elegance; demonstrating you can think recursively |
In an interview, lead with iterative. Mention recursive as a follow-up to show range. In production, always pick iterative — Python’s default recursion limit (1000) will bite you on long lists.
LeetCode 21 — Merge Two Sorted Lists#
Merge two sorted linked lists into one sorted list by splicing existing nodes.
Example:
l1 = [1,2,4],l2 = [1,3,4]→[1,1,2,3,4,4].
The interesting question here is not the merge — that is just standard two-pointer comparison — but how to handle the first node of the result. Without a helper, you need a special branch to decide which list contributes the head. With a dummy node, that branch disappears.
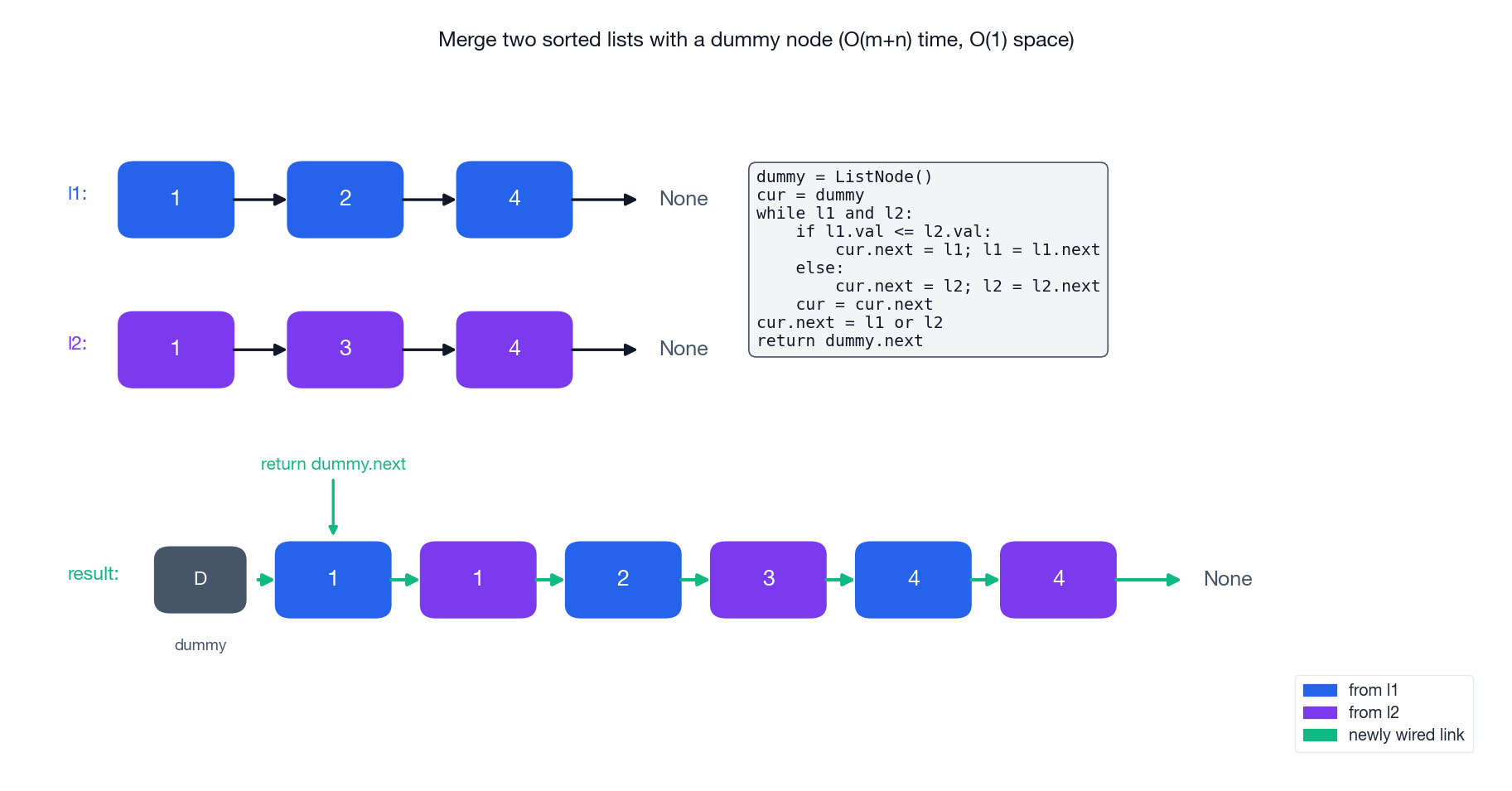
Iterative with a dummy node#
| |
Why the dummy? It guarantees there is always a “previous node” to write to. Without it, the first iteration would need to decide whether the head is from l1 or l2, which forks every subsequent branch. With the dummy, every iteration looks the same — the head case has been smuggled into the sentinel.
Walkthrough on l1 = [1,2,4], l2 = [1,3,4]:
| Step | Compare | Picked | Result so far |
|---|---|---|---|
| 1 | 1 ≤ 1 | l1 | 1 |
| 2 | 1 < 2 | l2 | 1 → 1 |
| 3 | 2 < 3 | l1 | 1 → 1 → 2 |
| 4 | 3 < 4 | l2 | 1 → 1 → 2 → 3 |
| 5 | 4 ≤ 4 | l1 | 1 → 1 → 2 → 3 → 4 |
| 6 | l1 empty | attach rest of l2 | 1 → 1 → 2 → 3 → 4 → 4 |
Return dummy.next.
Recursive variant#
| |
LeetCode 141 / 142 — Linked List Cycle (and where it begins)#
141: Detect whether a linked list has a cycle.
142: Return the node where the cycle begins, or
Noneif there is no cycle.Constraint: $O(1)$ extra space.
The brute-force solutions — hash every node, or count steps — are correct but use $O(n)$ space or two passes. Floyd’s tortoise-and-hare algorithm does it in one pass with two pointers and a small piece of algebra.
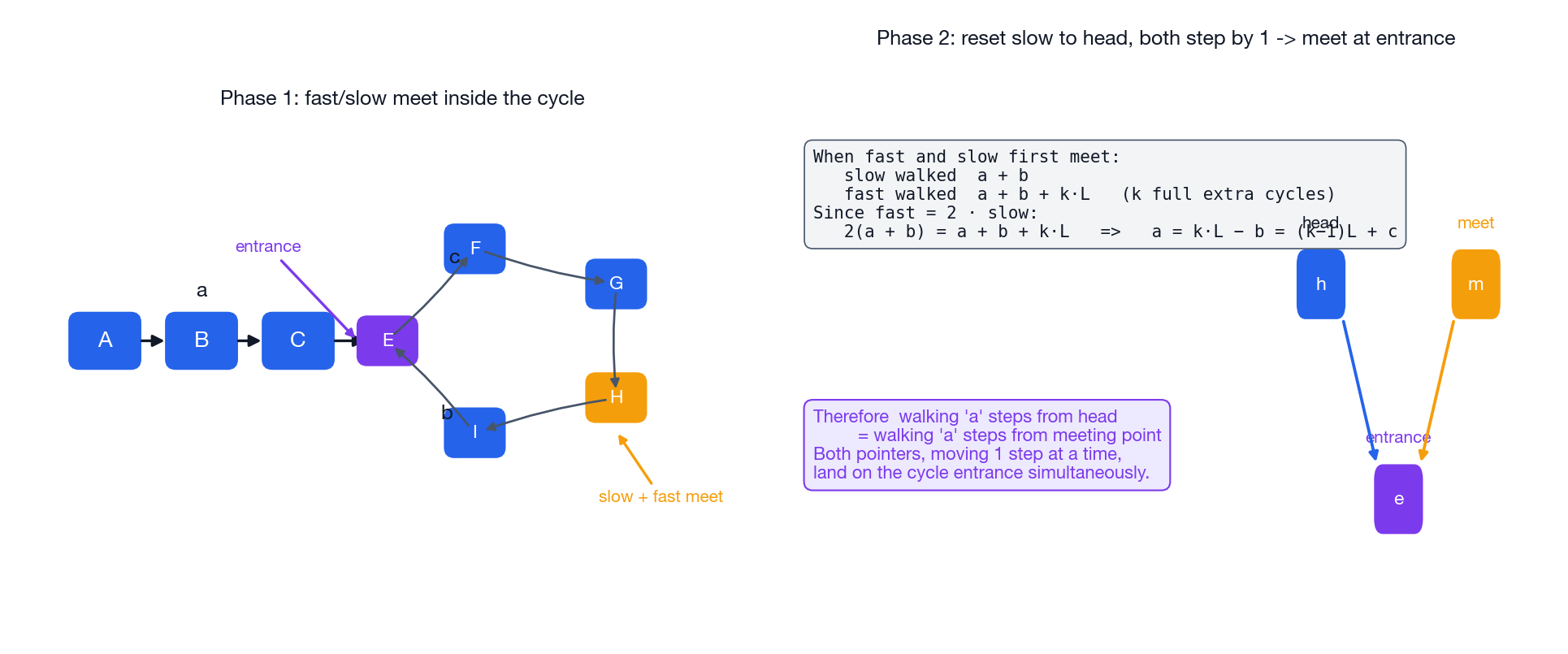
Phase 1: detect the cycle#
| |
Why does it work? If there is no cycle, fast reaches None and the loop exits. If there is a cycle, both pointers are eventually trapped inside it, and because fast gains one node per step on slow, the gap shrinks by 1 per iteration and they must collide within at most $L$
iterations (where $L$
is the cycle length).
Phase 2: locate the cycle entrance#
| |
The algebra (worth memorizing once)#
Let $a$ = distance from head to the entrance, $b$ = distance from the entrance to the meeting point along the cycle, $c$ = the rest of the cycle (so cycle length $L = b + c$ ).
$$\text{slow walked: } a + b$$ $$\text{fast walked: } a + b + kL \quad \text{(for some integer } k \geq 1\text{)}$$ $$2(a + b) = a + b + kL \implies a = kL - b = (k-1)L + c$$That last equality is the punchline. It says: walking $a$
steps from the head lands on the entrance, and walking $a$
steps from the meeting point also lands on the entrance (because $(k-1)L$
is just whole loops). So if we reset slow to head and step both pointers one node at a time, they meet at the entrance.
LeetCode 19 — Remove Nth Node From End#
Given the head of a linked list, remove the nth node from the end and return the head. Try to do it in one pass.
Example:
head = [1,2,3,4,5],n = 2→[1,2,3,5].
The naïve approach takes two passes: count the length, then walk to position length - n. The one-pass solution uses two pointers separated by a fixed gap of $n + 1$
, plus a dummy node so deleting the head requires no special case.
| |
Why $n+1$
, not $n$
? We need slow to land on the predecessor of the target so we can rewire slow.next. If fast only moves $n$
steps, the gap between them is $n$
, so when fast is None, slow is on the target, not before it. Off by one is the single most common bug here.
Why the dummy? Consider head = [1, 2], n = 2 (delete the head). With the dummy:
fastmoves 3 steps, ending atNone.slowis still atdummy.dummy.next = dummy.next.nextsetsdummy.next = 2.- Return
dummy.next = 2. Done.
Without the dummy, you would need a separate branch like if n == length: return head.next, which means computing the length first — and now you have a two-pass solution again.
LeetCode 146 — LRU Cache#
Design a data structure with
get(key)andput(key, value)that both run in $O(1)$ amortized time. When capacity is exceeded, evict the least recently used key.
This problem comes up everywhere — operating system page caches, CDN edge caches, browser caches, your ORM’s query cache. The standard solution is a small but beautiful composition: a hash map for $O(1)$ lookup, plus a doubly linked list for $O(1)$ reordering and eviction.
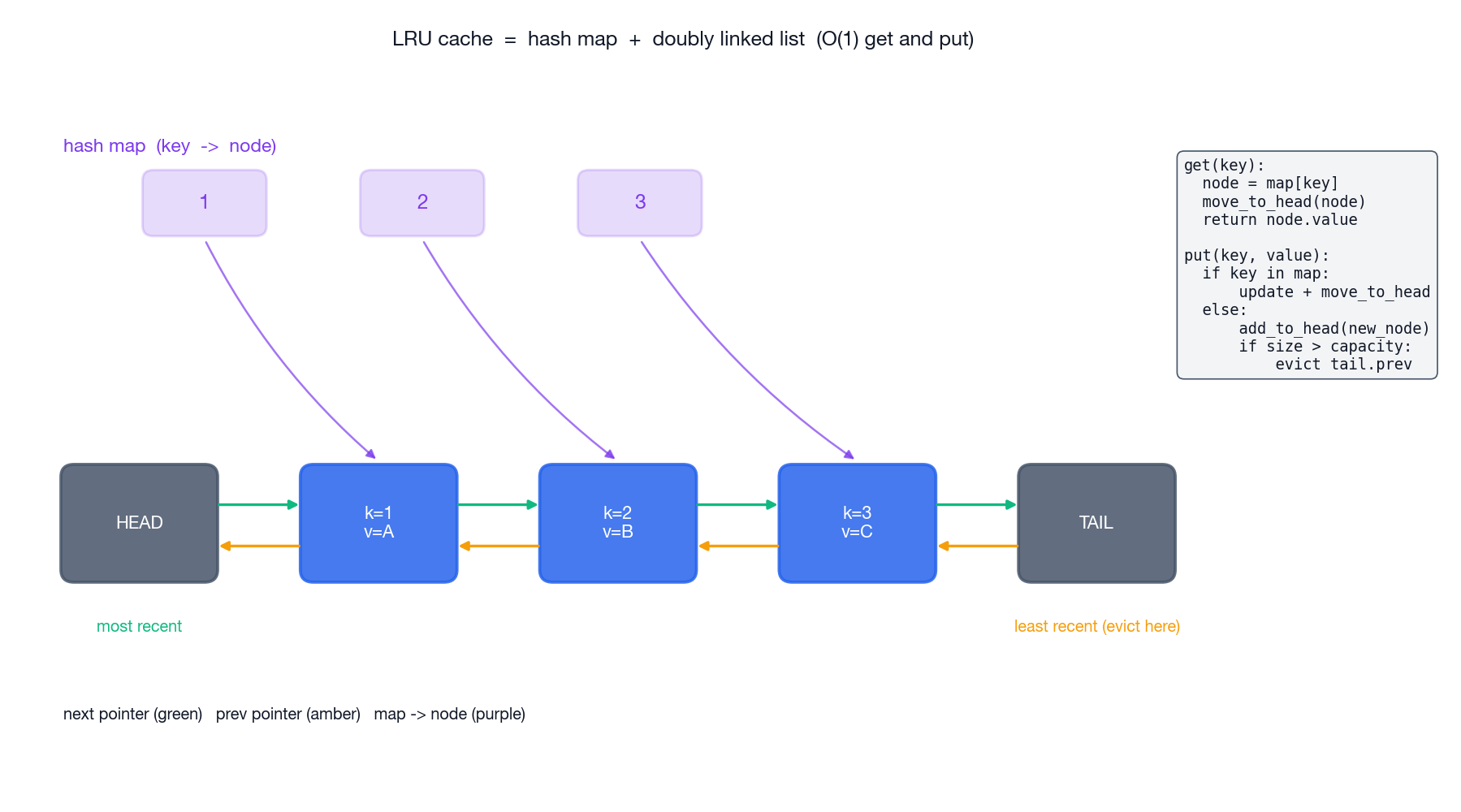
Why both data structures?#
- A hash map alone gets us $O(1)$ lookup but no notion of recency.
- A linked list alone tracks recency but lookup is $O(n)$ .
- Together: lookup the node in the map ($O(1)$ ), then unlink and re-link it at the head of the list ($O(1)$ because it is doubly linked).
The list maintains the ordering “most recently used at the head, least recently used at the tail”. Two sentinel nodes (head and tail) eliminate every edge case for inserting at the front or evicting from the back.
| |
Three things worth pausing on:
- Sentinels are not optional. They turn every insertion and removal into the same four-pointer dance, with no
if head is Nonechecks anywhere. - The node carries the
key. When we evict the LRU node, we need to delete its key from the map — without storing the key on the node, we would have to walk the map to find it. - We splice existing nodes; we never re-allocate on
get. That is what gives us true $O(1)$ amortized cost.
Pattern Cheat Sheet#
| Technique | Use it when | Examples in this article |
|---|---|---|
Three pointers (prev, curr, next) | Reversing or rewiring in place | Reverse Linked List |
| Dummy / sentinel node | The head might be modified or returned | Merge Two Sorted Lists, Remove Nth From End, LRU |
| Fast / slow pointers | Find middle, detect cycle, kth from end | Cycle II, Remove Nth From End |
| Hash map + linked list | $O(1)$ lookup and ordering | LRU Cache |
| Recursion | Operation has natural divide structure | Recursive reverse / merge |
Common Pitfalls#
- Dereferencing without checking.
curr.next.valcrashes the momentcurr.nextisNone. Always guard:while curr and curr.next:. - Losing the path forward. Before writing
curr.next = something, save the originalcurr.nextif you still need it (this is the entire point of thenxtvariable in iterative reverse). - Forgetting to advance. Every loop iteration must move at least one pointer toward termination, or you have an infinite loop.
- Off-by-one on gaps. Two-pointer gap problems live and die on whether you advance
fastbynorn + 1first. - Skipping the dummy node. Anytime the head can change, a dummy will collapse 5 lines of edge-case branching into 0.
Exercises#
Sorted roughly by difficulty within each group.
Basics
- LeetCode 206 — Reverse Linked List (covered)
- LeetCode 21 — Merge Two Sorted Lists (covered)
- LeetCode 19 — Remove Nth Node From End (covered)
- LeetCode 234 — Palindrome Linked List
Cycles and intersection
- LeetCode 141 — Linked List Cycle (covered)
- LeetCode 142 — Linked List Cycle II (covered)
- LeetCode 160 — Intersection of Two Linked Lists
Advanced
- LeetCode 25 — Reverse Nodes in k-Group
- LeetCode 23 — Merge K Sorted Lists
- LeetCode 138 — Copy List with Random Pointer
- LeetCode 146 — LRU Cache (covered)
- LeetCode 460 — LFU Cache
References#
- Introduction to Algorithms — the Elementary Data Structures chapter.
- Cracking the Coding Interview — Chapter 2 , Linked Lists.
- VisuAlgo — Linked List visualization: https://visualgo.net/en/list
- LeetCode Linked List tag — 100+ curated problems for practice.
Where Linked Lists Actually Live in Production#
Most application code never touches ListNode directly — the language’s standard library hides it. But the structure is everywhere underneath:
- LRU caches.
functools.lru_cache, Redis’s allkeys-lru eviction, every browser’s HTTP cache. They’re all hash-map + doubly-linked-list, exactly like LeetCode 146. Knowing why (O(1) move-to-front requires a node pointer, which a Python list doesn’t give you) is what the interview question actually probes. - Linux kernel lists.
include/linux/list.hdefines an intrusive doubly-linked list used by tens of thousands of kernel structures — process lists, file descriptor tables, network queues. The “container_of” trick that makes intrusive lists work is one of the most elegant pieces of C in the kernel. - Java’s
LinkedHashMapand Python’sOrderedDict. Insertion-order iteration is implemented as a hash map plus a linked list of entries. Same structure, different language. - Skip lists in Redis sorted sets. A multi-level linked list with probabilistic shortcuts. Used because they’re easier to make lock-free than balanced trees.
The point: linked-list problems aren’t “exercises.” They are the smallest examples of patterns you’ll meet again at every layer of the stack.
Cleaner Python Idioms#
The default LeetCode style is C-with-Python-syntax. A few changes make the code easier to write and to read:
| |
These three helpers turn link-list testing from “manually trace pointers” into one-liners. I keep them at the top of every linked-list file.
For reverse, the recursive form is shorter than the iterative form and it teaches the structure. Use it once you trust the stack depth:
| |
The line head.next.next = head is the entire algorithm — read it as “the node after me should now point back to me.”
A Common Bug: Mutating While Traversing#
Two-pointer linked-list code looks like array code, but the consequences of a mistake are different. The single most common bug:
| |
The fix is religious: save the next pointer before any assignment that touches .next:
| |
Every iterative linked-list algorithm follows this pattern. If your code skips a node, lands in an infinite loop, or “loses half the list,” nine times out of ten it’s because some assignment ran before the save.
Test Battery for Linked-List Code#
Before submitting, run mentally:
| Case | Why it matters |
|---|---|
head is None | while curr vs while curr.next differs here |
| Single node | Reverse, merge, remove-Nth all have a one-node degenerate case |
| Two nodes | Smallest case where pointer order matters |
| All identical values | Catches wrong “skip duplicates” logic |
| Cycle of length 1 (node points to itself) | Floyd’s slow == fast check still has to fire |
| Remove the head | The dummy-node trick exists exactly for this |
| Remove the tail | prev.next = None must actually run |
Five seconds per row, thirty-five seconds total — saves the wrong-answer slog.
Summary#
Linked-list problems are not really about linked lists. They are about being precise with mutation — naming the pointers, ordering the assignments, and never assuming the next field is non-null. The five problems above cover every technique you need: pointer rewiring, dummy nodes, fast/slow traversal, gap pointers, and the hash-map + list combination.
Once you can write reverseList from memory and explain why Floyd’s algorithm works on a napkin, the rest of the linked-list canon falls out as variations on those themes. In the next article we move from one-dimensional pointer chains to binary trees, where recursion finally feels like the natural tool instead of a clever trick.
LeetCode Patterns 10 parts
- 01 LeetCode (1): Patterns — Hash Tables
- 02 LeetCode (2): Patterns — Two Pointers
- 03 LeetCode (3): Patterns — Linked List Operations you are here
- 04 LeetCode (4): Patterns — Sliding Window Technique
- 05 LeetCode (5): Patterns — Binary Search
- 06 LeetCode (6): Patterns — Binary Tree Traversal and Construction
- 07 LeetCode (7): Patterns — Dynamic Programming Basics
- 08 LeetCode (8): Patterns — Backtracking Algorithms
- 09 LeetCode (9): Patterns — Greedy Algorithms
- 10 LeetCode (10): Patterns — Stack and Queue