
NLP (3): RNN and Sequence Modeling
How RNNs, LSTMs, and GRUs process sequences with memory. We derive vanishing gradients from first principles, build a character-level text generator, and implement a Seq2Seq translator in PyTorch.
Open Google Translate, swipe-type a message, or dictate a memo to your phone — all these systems consume an ordered stream of tokens and produce another. A feed-forward network processes each input independently, but language is fundamentally sequential: the meaning of “mat” in the cat sat on the mat depends on every word that came before. Recurrent Neural Networks (RNNs) handle this by maintaining a hidden state that evolves as they process each token. The hidden state is the network’s running summary of the past — its memory.
This article builds up the family of recurrent architectures from scratch. We start with the vanilla RNN, derive why it cannot remember more than a dozen tokens, watch the LSTM and GRU rescue it with gating, and finish with a working English-to-French translator in PyTorch. By the end, you will understand the architectural shift that ultimately motivated attention and Transformers.
What You Will Learn#
- How RNNs maintain memory through recurrent connections and parameter sharing
- A first-principles derivation of vanishing and exploding gradients
- How LSTM gates (forget, input, output) and the cell-state highway fix long-range dependencies
- GRU as a leaner alternative to LSTM, and when to pick each
- Bidirectional and stacked RNNs for richer per-token representations
- The Seq2Seq encoder-decoder, its bottleneck, and why attention was inevitable
- Working PyTorch implementations of text generation and translation
Prerequisites: Parts 1-2 of this series (tokenization and embeddings), plus basic PyTorch (tensors, nn.Module, training loops).
The core idea: recurrence and parameter sharing#
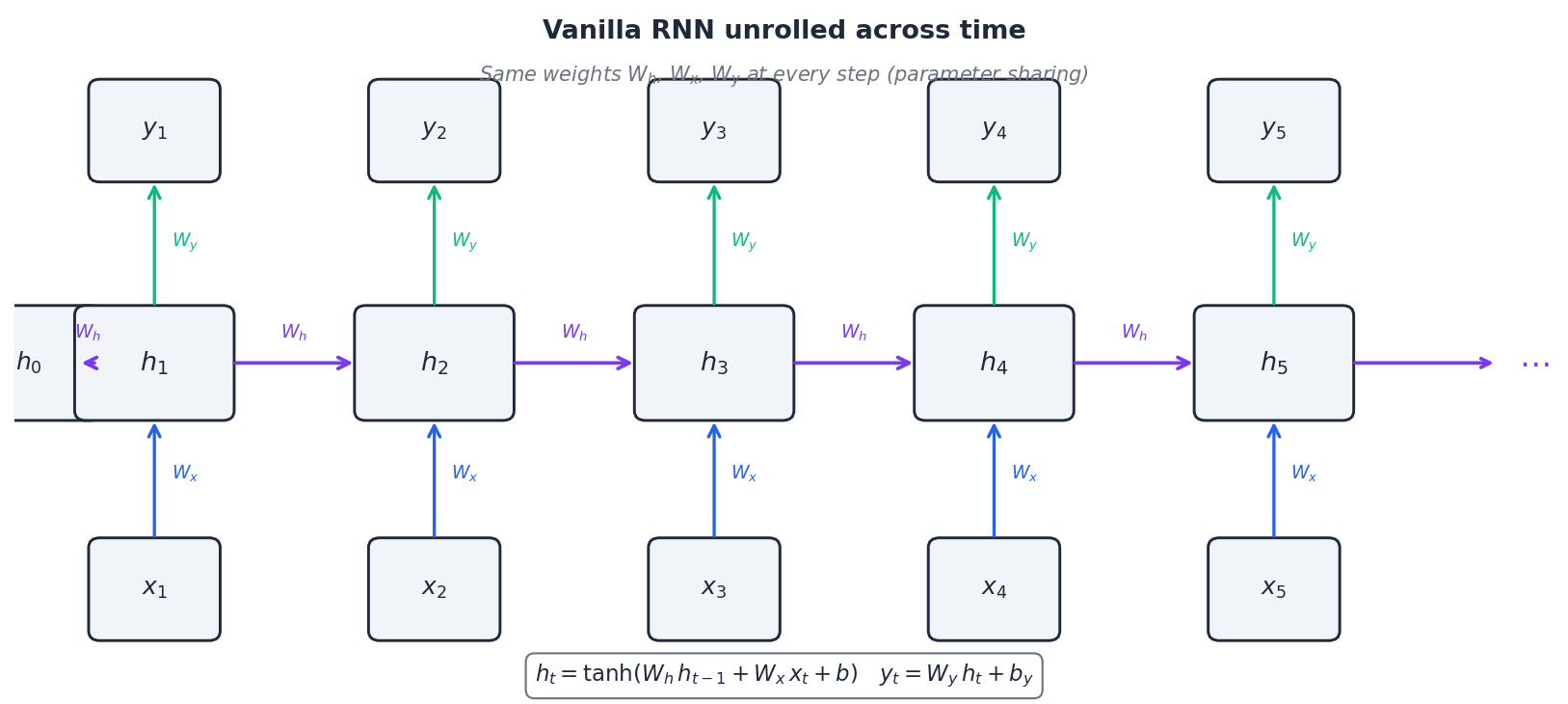
The crucial property — visible in the figure as the same arrows repeating at each step — is that the matrices $W_h$ , $W_x$ , $W_y$ are reused at every position. This single design choice gives RNNs three nice features at once:
- Generalisation across positions: a pattern learned at position 3 transfers to position 30, because the same weights see both.
- Constant parameter count: the model size is independent of sequence length, so a 10-token and a 10 000-token sentence cost the same to store.
- Variable-length input and output: nothing in the equations cares whether $T$ is 5 or 500.
Mentally, picture the network reading one token at a time, updating its “running understanding” of the sentence after each word. The hidden state at step $t$ is a learned, fixed-size summary of $x_1, \dots, x_t$ .
The vanishing gradient problem#
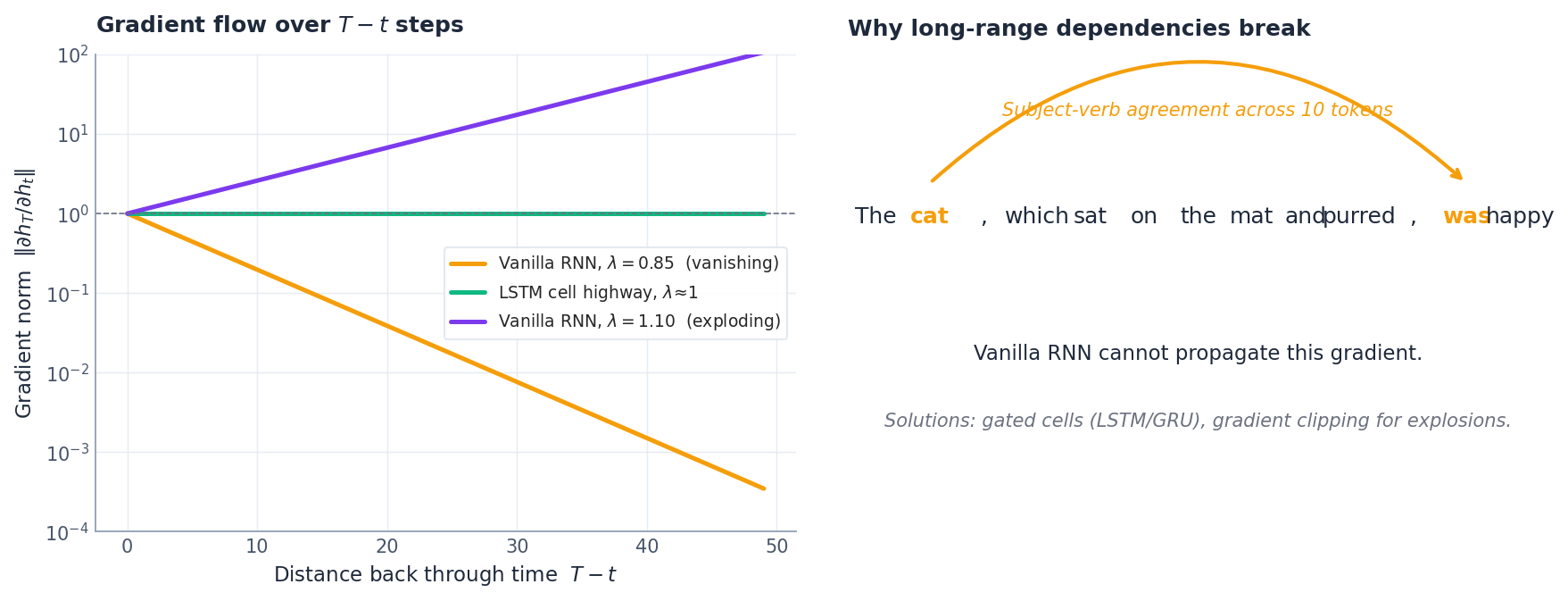
Two regimes follow immediately, and you can see both in the left panel of the figure:
- If $\lambda < 1$ , the gradient norm decays exponentially. Beyond roughly 10–20 steps the signal is numerically zero, so the optimiser cannot tell that token $t$ matters for the loss at $T$ . The model literally cannot learn the dependency.
- If $\lambda > 1$ , the gradient explodes — finite weight updates become wild, and training diverges in a single step.
The right panel illustrates this. In “The cat, which sat on the mat and purred, was happy”, the subject (“cat”) and verb (“was”) are separated by ten tokens. A vanilla RNN cannot route the gradient that far, so it never learns the agreement.
What helps in practice. Gradient clipping — capping the global norm at some threshold like 5.0 — solves explosion but does nothing for vanishing. The real fix requires re-architecting the recurrence so that gradients have a path that does not shrink. That path is exactly what LSTMs and GRUs introduce.
Long Short-Term Memory (LSTM)#
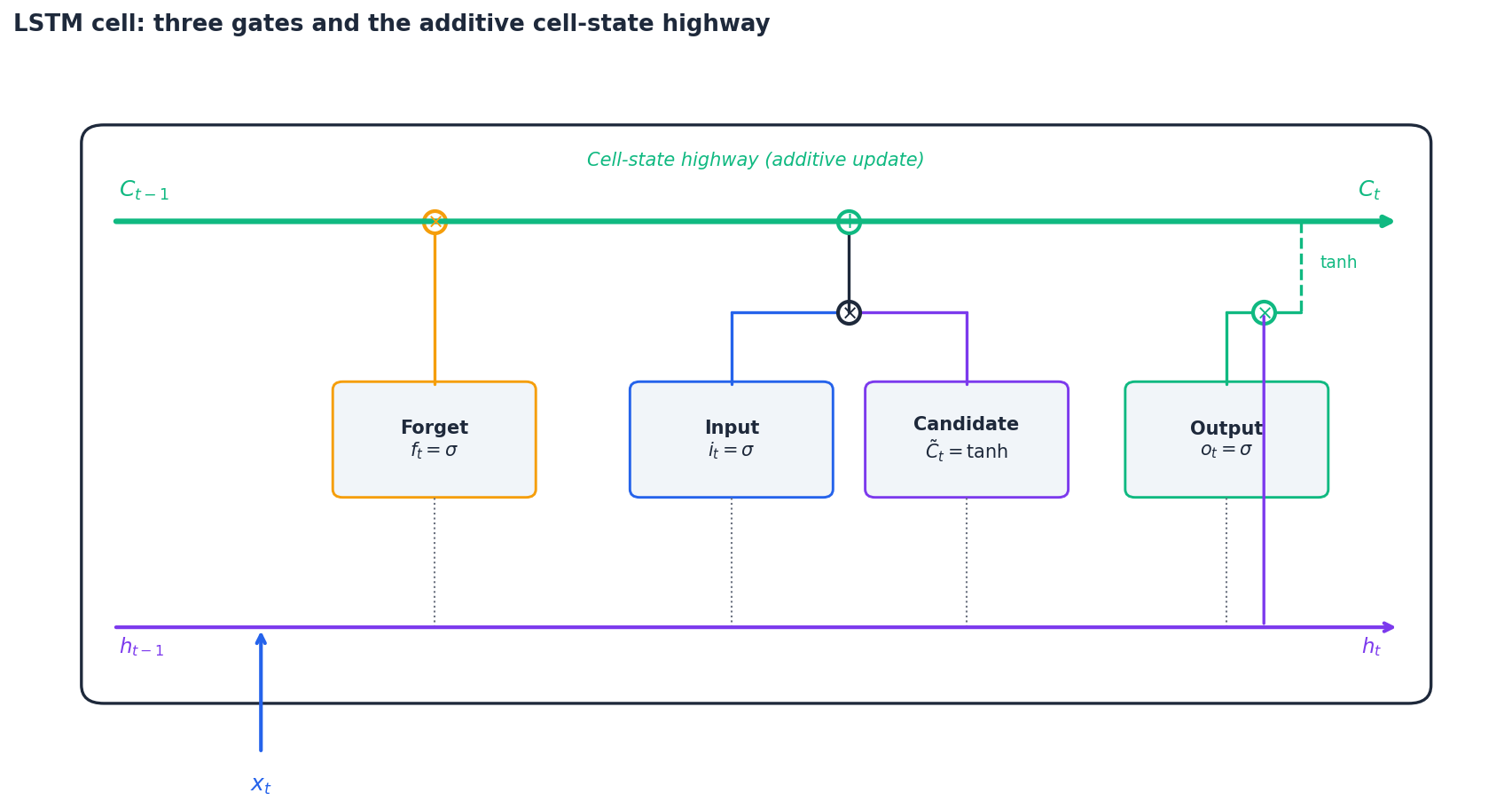
The LSTM (Hochreiter & Schmidhuber, 1997) replaces the simple recurrent unit with a gated cell that carries an explicit long-term memory $C_t$ alongside the hidden state $h_t$ .
The three gates#
Let $[h_{t-1}, x_t]$ denote the concatenation of the previous hidden state and current input. All gates share this same input.
$$f_t = \sigma(W_f [h_{t-1}, x_t] + b_f).$$ $$ i_t = \sigma(W_i [h_{t-1}, x_t] + b_i), \qquad \tilde{C}_t = \tanh(W_C [h_{t-1}, x_t] + b_C). $$ $$C_t = f_t \odot C_{t-1} + i_t \odot \tilde{C}_t.$$ $$ o_t = \sigma(W_o [h_{t-1}, x_t] + b_o), \qquad h_t = o_t \odot \tanh(C_t). $$Here $\sigma$ is the sigmoid (a soft 0–1 switch) and $\odot$ is element-wise multiplication. Each gate is a learned, position-dependent decision: forget this, write that, expose the rest.
Why this fixes vanishing gradients#
$$C_t = f_t \odot C_{t-1} + i_t \odot \tilde{C}_t.$$Differentiating gives $\partial C_t / \partial C_{t-1} = f_t$ , an element-wise scalar in $[0,1]$ . When the forget gate stays near 1, the chain product $\prod f_k$ stays near 1 too — gradients flow through the cell-state highway essentially unchanged, even over hundreds of steps. Compare this with the vanilla RNN’s multiplicative update through $W_h$ , which compounds toward zero. The LSTM trades one shared $W_h$ for a learnable, time-varying $f_t$ , and that single change is what lets it model long contexts.
The conveyor-belt analogy#
Picture the cell state as a conveyor belt running the length of the sequence. The forget gate is a worker who removes items the belt no longer needs, the input gate is a worker who places new items on, and the output gate is a window that decides which items the outside world (the rest of the network) sees right now. An item placed at step 3 can ride the belt undisturbed all the way to step 300.
Gated Recurrent Unit (GRU)#
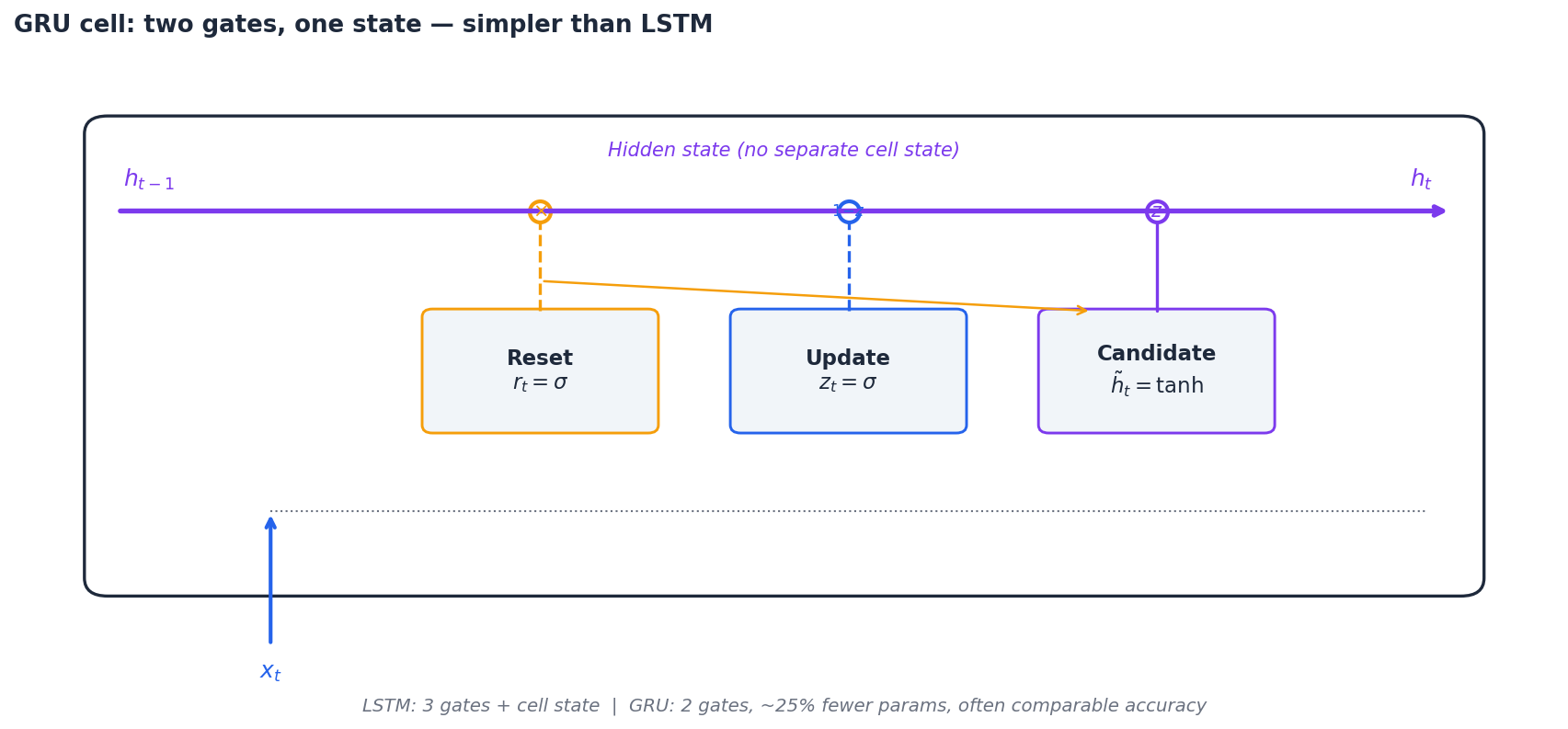
The reset gate $r_t$ controls how much of the past leaks into the candidate. The update gate $z_t$ does linear interpolation between the old state and the new candidate — when $z_t \approx 0$ , the GRU just copies $h_{t-1}$ forward, which is exactly the same gradient-preserving trick as the LSTM’s cell highway.
LSTM vs. GRU#
| Aspect | LSTM | GRU |
|---|---|---|
| Gates | 3 (forget, input, output) | 2 (reset, update) |
| Separate cell state | Yes ($C_t$ ) | No (just $h_t$ ) |
| Parameters | $\sim\!4\times$ vanilla RNN | $\sim\!3\times$ vanilla RNN ($\approx 25\%$ fewer than LSTM) |
| Long sequences | Slight edge in many benchmarks | Comparable |
| Training speed | Slower | Faster |
Rule of thumb: start with a GRU. It trains faster, has fewer hyperparameters, and on most tasks the accuracy gap is within noise. Switch to LSTM if your sequences are very long or if your task is known to benefit from the extra capacity (some speech tasks do).
Bidirectional RNNs#
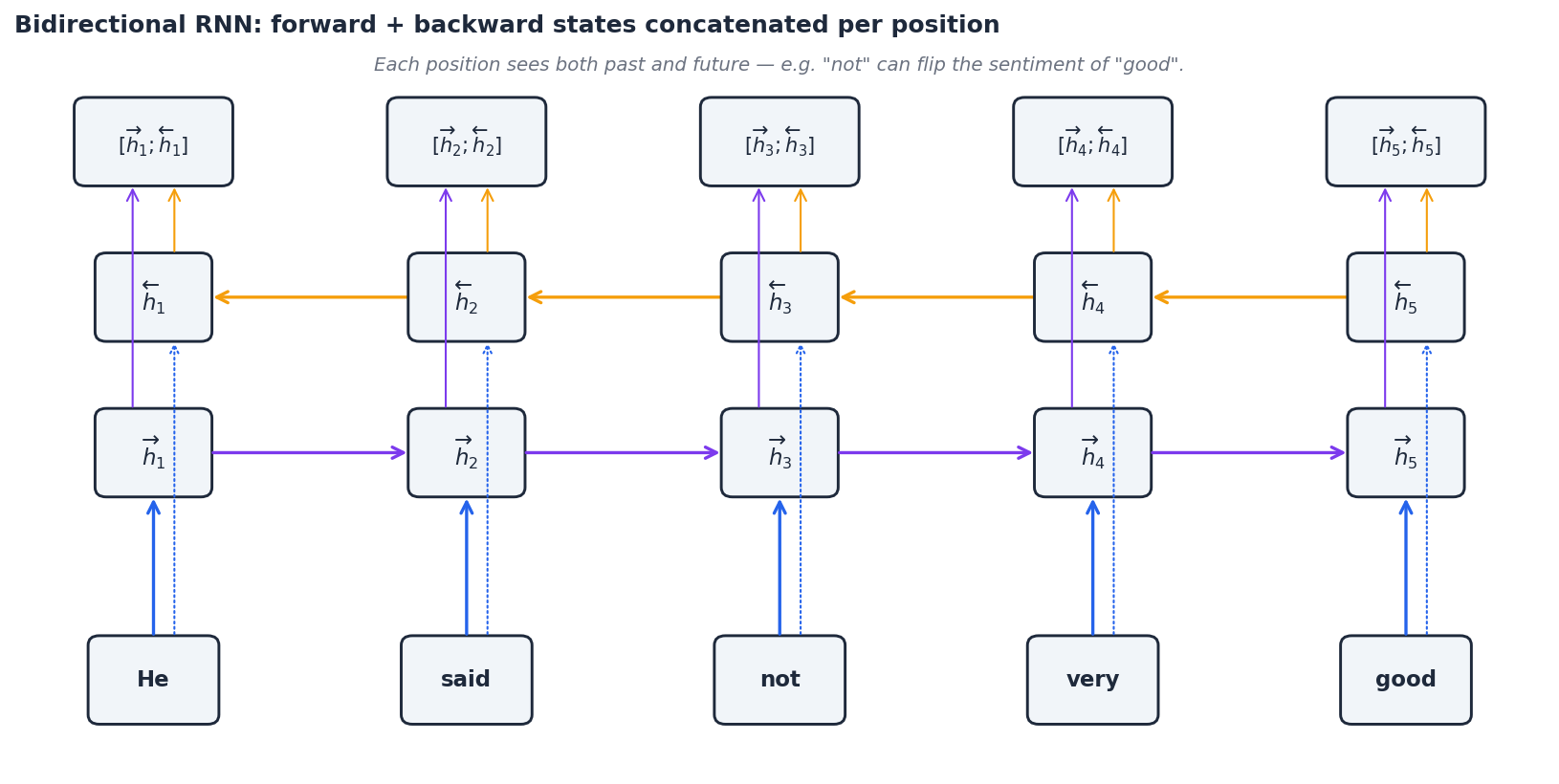
In many tasks, the future is just as informative as the past. “He said the food was not good” — without seeing “not”, a left-to-right reader would label “good” as positive sentiment.
$$ \overrightarrow{h}_t = \mathrm{RNN}_\text{fwd}(x_t, \overrightarrow{h}_{t-1}), \qquad \overleftarrow{h}_t = \mathrm{RNN}_\text{bwd}(x_t, \overleftarrow{h}_{t+1}), $$ $$ h_t = \big[\overrightarrow{h}_t \,;\, \overleftarrow{h}_t\big]. $$Each per-position representation now sees both directions of context.
Use it for: named entity recognition, part-of-speech tagging, machine-translation encoders, anything where you have the whole input up front.
Do not use it for: streaming or autoregressive generation. The backward pass requires future tokens, which by definition do not exist when you are emitting one token at a time.
Stacked RNNs#
$$ h_t^{(1)} = \mathrm{RNN}^{(1)}(x_t,\, h_{t-1}^{(1)}), \qquad h_t^{(2)} = \mathrm{RNN}^{(2)}(h_t^{(1)},\, h_{t-1}^{(2)}). $$Empirically the lower layers learn local patterns (character n-grams, word boundaries, morphology), while the higher layers capture syntax and longer-range semantics. Two to four layers is the sweet spot for most NLP tasks; beyond that, residual connections become essential to keep optimisation stable.
Sequence-to-sequence models#
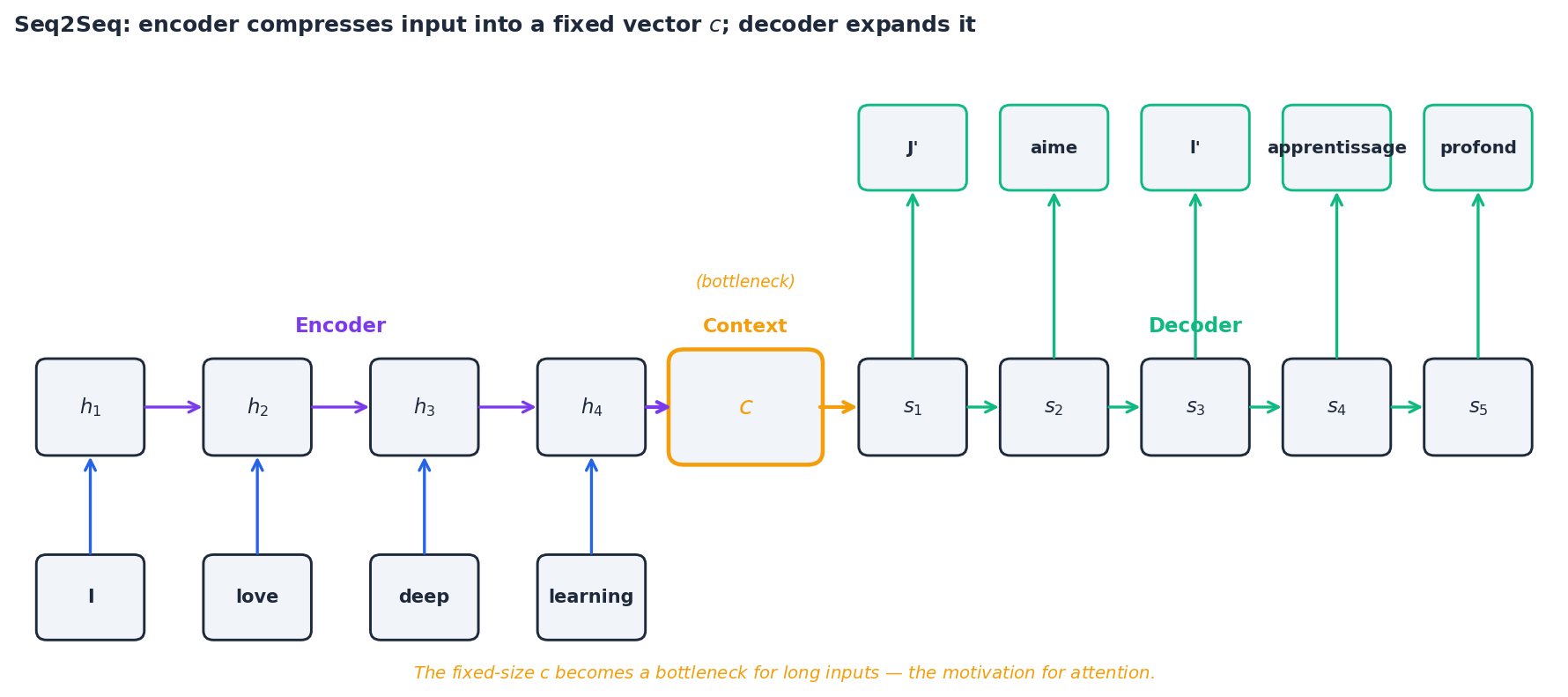
The Seq2Seq architecture (Sutskever et al., 2014) maps an input sequence to an output sequence of different length — the canonical example being machine translation. It uses two RNNs:
- An encoder reads the entire input and compresses it into a single context vector $c = h_T^{\text{enc}}$ .
- A decoder generates the output one token at a time, conditioned on $c$ and on the tokens it has already emitted: $ s_t = \mathrm{RNN}_\text{dec}(y_{t-1}, s_{t-1}), \qquad P(y_t \mid y_{<t}, x) = \mathrm{softmax}(W_o s_t). $ The bottleneck. The whole input — possibly 50 words of context — must squeeze through the single fixed-size vector $c$ . For short sentences this is fine; for long ones, the encoder simply runs out of room. Sutskever’s original paper found that BLEU scores fell sharply once the input exceeded about 30 tokens, and that reversing the source sentence helped (which is itself a hint that the bottleneck was the problem).
This bottleneck is the direct motivation for attention, the topic of Part 4 : instead of forcing the decoder to live on a single $c$ , attention lets it look back at every encoder hidden state at each decoding step.
PyTorch implementation: character-level text generator#
Let us train a tiny LSTM that learns to generate text one character at a time.
Dataset preparation#
| |
Model#
| |
Training loop#
| |
Note the two RNN-specific tricks: detaching hidden state between batches to truncate BPTT (otherwise gradients try to flow back through the entire training corpus), and gradient clipping to defuse the exploding-gradient regime.
Sampling — temperature controls creativity#
| |
Temperature rescales logits before softmax: $P(w) = \mathrm{softmax}(\text{logits}/T)$ . Low $T$ (around 0.5) sharpens the distribution toward the mode and yields conservative, repetitive output. High $T$ (1.5+) flattens it and produces creative but often nonsensical text. $T=0.8$ is a common compromise.
PyTorch implementation: a minimal Seq2Seq translator#
A bare-bones English-to-French translator, useful for understanding the encoder-decoder pipeline before we add attention in Part 4 .
Data and vocabulary#
| |
Encoder and decoder#
| |
Training (with teacher forcing)#
| |
Inference#
| |
Caveats. This minimal implementation overfits a tiny phrase book, uses greedy decoding, and has no attention or beam search. It is meant only to make the encoder-decoder data flow concrete. For real translation systems you would add attention (Part 4 ), beam search, subword (BPE) tokenisation, and a held-out validation set for early stopping.
How they actually compare#
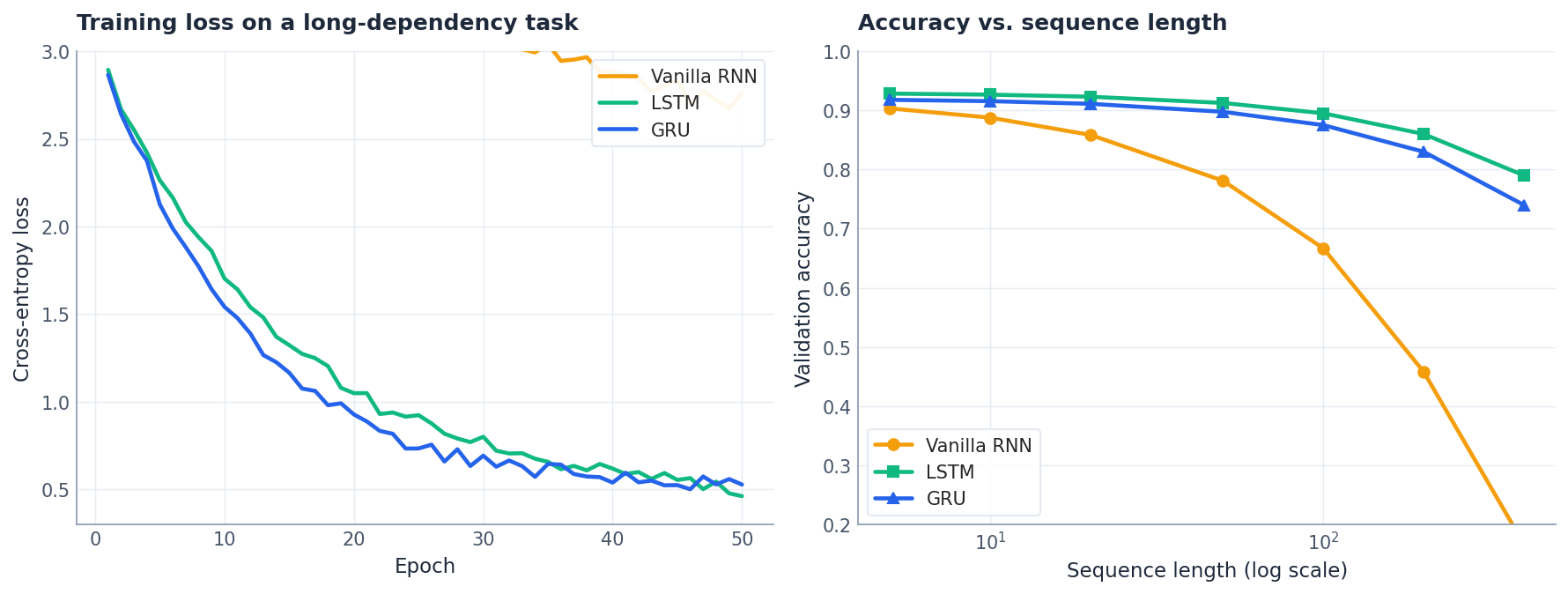
The two panels above tell the story qualitatively. On a long-dependency task, vanilla RNN training plateaus at a high loss while LSTM and GRU keep descending — the gradient highway is doing real work. As sequence length grows, vanilla RNN accuracy collapses, while LSTM and GRU degrade gracefully. The gap between LSTM and GRU is small in most settings, which is why GRU is a reasonable default.
Attention preview#
$$ \alpha_{tj} = \frac{\exp(\mathrm{score}(s_t, h_j))}{\sum_k \exp(\mathrm{score}(s_t, h_k))}, \qquad c_t = \sum_j \alpha_{tj}\, h_j. $$The context vector becomes a time-varying weighted sum of encoder states. This was the bridge from RNNs to Transformers, which we cover in Part 4 .
FAQ#
Why tanh instead of ReLU in vanilla RNNs? Tanh outputs values in $[-1, 1]$ , which keeps the hidden state bounded across time. ReLU has unbounded positive output, so a recurrent application can blow up exponentially. LSTMs use sigmoid for gates (a soft 0–1 switch) and tanh for candidates (zero-centred values that can both add and subtract from the cell state).
What is teacher forcing, and what is its downside? During training we feed the ground-truth previous token as the decoder input rather than the model’s own prediction. This stabilises learning early on but creates a train/test mismatch — at inference the decoder must consume its own (noisy) outputs, which it has never seen during training. A standard mitigation is scheduled sampling: gradually increase the probability of feeding the model’s own prediction as training progresses.
How does temperature affect generation? It rescales logits before softmax: $P(w) = \mathrm{softmax}(\text{logits}/T)$ . Low $T$ (0.5) is peaky and conservative; high $T$ (1.5) is flat and creative but error-prone. Greedy decoding is the limit $T \to 0$ .
Are RNNs still relevant after Transformers? Transformers dominate offline NLP benchmarks, but RNNs remain useful when you need (i) a small parameter budget, (ii) genuine streaming/online inference (no need to re-attend over the whole prefix), or (iii) constant memory per step regardless of sequence length. They also remain a common ingredient in time-series forecasting and on-device speech models. And because attention can be motivated as “what if we replaced the LSTM’s forget gate with a learned look-back over all previous states?”, understanding RNNs is the cleanest path to understanding Transformers.
Summary#
- RNNs process sequences with memory via recurrent connections and parameter sharing — the same weights at every step.
- Vanilla RNNs fail on long sequences because the chained Jacobian product $\prod \partial h_{k+1} / \partial h_k$ shrinks (or explodes) exponentially.
- LSTMs add an additive cell-state highway gated by forget/input/output, giving gradients a path that does not vanish.
- GRUs simplify LSTMs to two gates and one state, often matching LSTM accuracy with ~25% fewer parameters.
- Bidirectional and stacked variants widen the per-position context and add depth, respectively.
- Seq2Seq encoder-decoders map sequences to sequences but bottleneck on a single context vector $c$ — a limitation that motivates attention, the topic of Part 4 .
NLP 12 parts
- 01 NLP (1): Introduction and Text Preprocessing
- 02 NLP (2): Word Embeddings and Language Models
- 03 NLP (3): RNN and Sequence Modeling you are here
- 04 NLP (4): Attention Mechanism and Transformer
- 05 NLP (5): BERT and Pretrained Models
- 06 NLP (6): GPT and Generative Language Models
- 07 NLP (7): Prompt Engineering and In-Context Learning
- 08 NLP (8): Model Fine-tuning and PEFT
- 09 NLP (9): Deep Dive into LLM Architecture
- 10 NLP (10): RAG and Knowledge Enhancement Systems
- 11 NLP (11): Multimodal Large Language Models
- 12 NLP (12): Frontiers and Practical Applications