
Recommendation Systems (9): Multi-Task Learning and Multi-Objective Optimization
How real recommenders juggle clicks, conversions, watch time and revenue at once. Shared-Bottom, ESMM, MMoE, PLE explained from first principles, with PyTorch code, loss-balancing strategies and the gradient-conflict story behind them.
A live e-commerce ranker doesn’t optimize just one number. The same model that decides which product to show you also predicts, in the same forward pass, whether you will click, add it to your cart, pay for it, return it, or leave a positive review. Each prediction is a different task with its own data distribution, scarcity, and incentives. These tasks are tightly coupled: a clicker is more likely to convert, a converter is more likely to write a review, and a high-CTR thumbnail can attract clicks that reduce watch time.
Multi-task learning (MTL) is how production systems handle this. Instead of training one model per objective and stitching scores together, we train one neural network with several output heads and let the shared trunk learn representations that serve all of them at once. The hard part is not the architecture diagram — it is making sure the heads cooperate instead of fighting over the shared weights.
This post provides the mental model and working code for the four architectures you’ll encounter in industry: Shared-Bottom, ESMM, MMoE, PLE. It also explains why the simple version fails (negative transfer, gradient conflict, sample selection bias) and how Uncertainty Weighting, GradNorm, and Pareto trade-offs address these issues.
What You Will Learn#
- Why ranking is inherently multi-objective and what goes wrong when you ignore that
- Sample selection bias in CVR prediction and ESMM’s chain-rule fix
- Four architectures — Shared-Bottom, ESMM, MMoE, PLE — and when each one wins
- Loss balancing: Uncertainty Weighting, GradNorm, Pareto frontiers
- A complete PyTorch training loop that you can lift into a project
Prerequisites#
- PyTorch basics (modules, forward pass, loss functions)
- CTR prediction concepts (Part 4 )
- Embedding layers (Part 5 )
Why Recommenders Are Multi-Objective#
Optimizing One Number Is the Wrong Game#
Picture a restaurant recommender. If you only optimize clicks, the model learns that lurid food photos and clickbait names work great, but your conversion rate plummets. If you only optimize bookings, you surface safe national chains with no room for discovery. If you only optimize stars, you push fancy, expensive places that few people book. The honest objective is a bundle:
- Will the user click? (engagement)
- Will they actually visit? (conversion)
- Will they enjoy it? (satisfaction)
- Will they come back? (retention)
The same pattern shows up everywhere:
| Domain | Typical objectives |
|---|---|
| E-commerce | CTR, CVR, revenue per impression, return rate, review quality |
| Short video | CTR, watch time, like/share rate, follow rate |
| Ads | CTR, CVR, cost per acquisition, lifetime value |
These metrics are correlated but distinct. The job of an MTL model is to exploit the correlation (clicks inform the conversion head about user intent) without letting one objective dominate.
Sample Selection Bias: Why Naive CVR Is Broken#
Here is the subtle problem that motivated ESMM. Suppose you want a conversion model: given a user and an item, what is $P(\text{buy} \mid \text{shown})$ ?
- Training labels exist only on clicked items — you can only observe a buy after a click.
- At serving time the model must score every candidate, including items the user never clicked.
You train on the slice of impressions that were clicked, then deploy on all impressions. This is sample selection bias: a textbook covariate shift between training and serving.
$$P(\text{buy} \mid \text{imp}) = P(\text{click} \mid \text{imp}) \cdot P(\text{buy} \mid \text{click})$$Read it in English: “the probability of buying after seeing an item equals the probability of clicking it times the probability of buying given that you clicked.” The first factor (CTR) and the product (CTCVR) are both observable on the whole impression space. So we train those two and let CVR fall out as a free byproduct — no biased slice required.
What MTL Buys You (and What It Costs)#
Wins
- Data efficiency. Sparse tasks (purchases, follows) piggyback on dense tasks (impressions, clicks).
- Implicit regularization. Sharing weights across tasks discourages overfitting to any single label.
- Cheaper serving. One forward pass produces every score the ranker needs.
- Better generalization. Joint training tends to find representations that generalize beyond any single objective.
Costs
- Negative transfer. Tasks can pull shared weights in opposite directions and make every head worse than its single-task baseline.
- Loss balancing. CTR loss may sit around 0.3 while a revenue MSE sits at 100 — naive sums let one task drown the others.
- Architecture choices. You have to decide what to share and what to keep private, with surprisingly little theory to guide you.
The architectures below are essentially four answers to the same question: how much and where to share?
Architecture 1: Shared-Bottom#
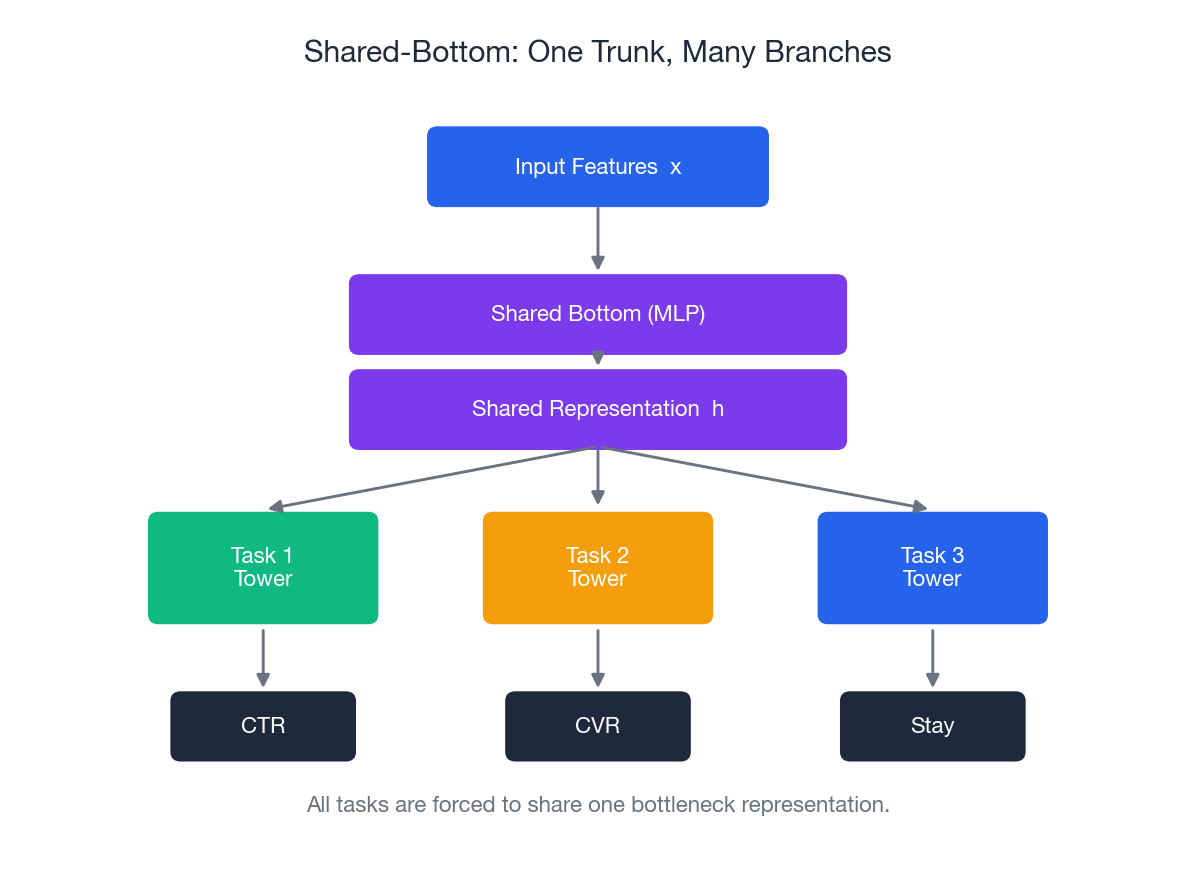
Every task sees the same $h$ . That is the single design assumption — and the single failure mode.
Implementation#
| |
Why It Eventually Hurts#
If two tasks disagree on what the shared representation should encode—e.g., CTR rewards eye-catching novelty while CVR rewards reliable signals—the trunk must compromise. This compromise often makes both tasks perform worse than their single-task baselines. This is negative transfer, and it’s the reason for the other architectures below.
Architecture 2: ESMM (Entire Space Multi-Task Model)#
ESMM was Alibaba’s answer to sample selection bias in CVR. The architecture itself is small. The trick is what gets supervised, and where.
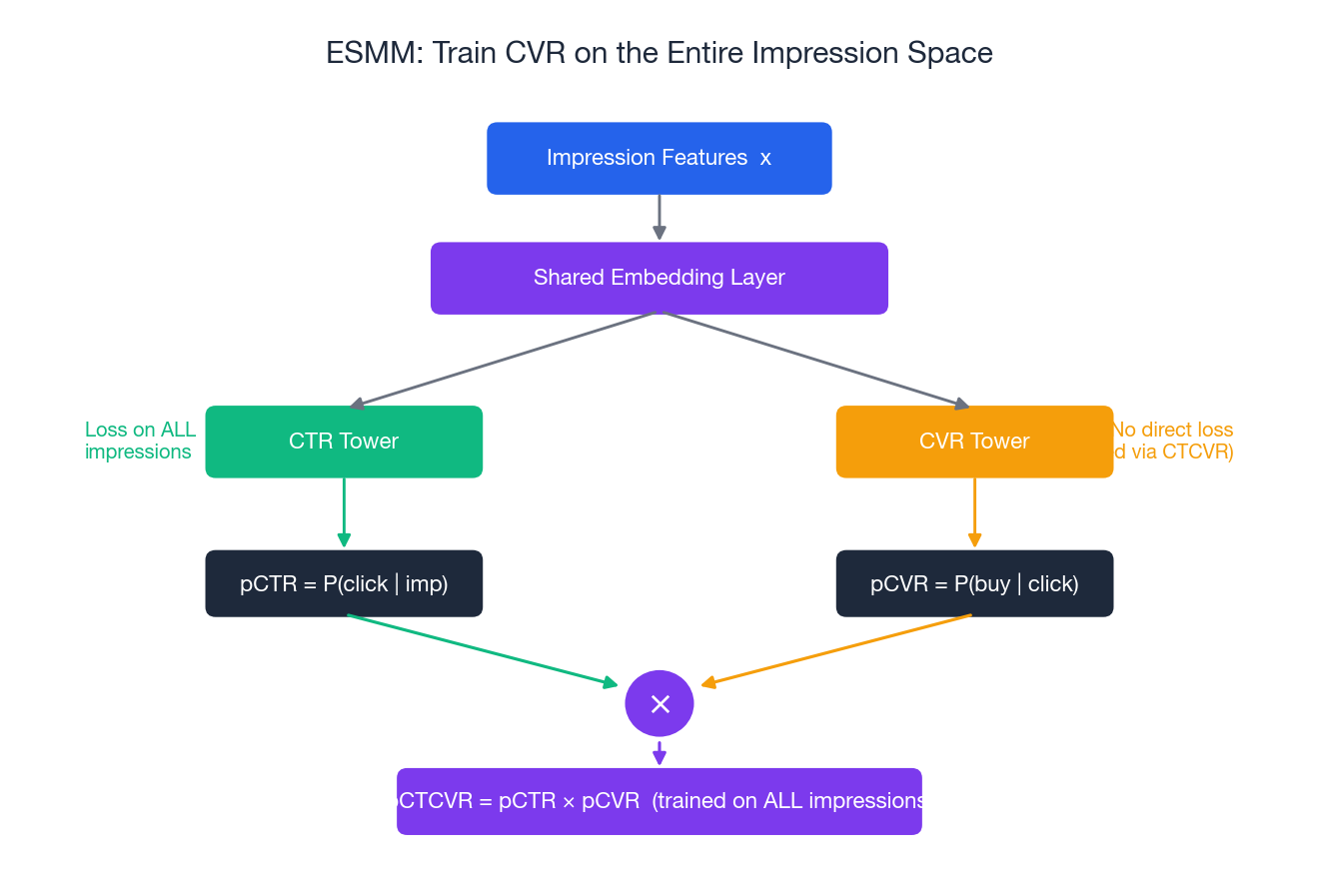
The Idea#
Don’t train CVR directly on the clicked-only slice. Train two things on the full impression space:
- pCTR = $P(\text{click} \mid \text{imp})$ , supervised by the click label
- pCTCVR = $P(\text{click and buy} \mid \text{imp})$
, supervised by
click AND buy
CVR is then defined implicitly: $\text{pCTCVR} = \text{pCTR} \times \text{pCVR}$ . Backprop through the multiplication shapes the CVR tower without ever asking it to fit a biased label.
Implementation#
| |
Why It Works#
- No biased slice. CTR and CTCVR live on every impression. CVR is never asked to fit a label that exists only after clicking.
- Mathematical consistency. By construction $\text{pCTCVR} = \text{pCTR} \times \text{pCVR}$ , so the three scores you serve cannot contradict each other.
- Cheap to deploy. It is the same shape as a Shared-Bottom with two binary heads. Production ranking pipelines barely notice.
In Alibaba’s original paper this trick lifted CVR AUC by about 2-3% on Taobao. That is a lot for a one-line architectural change.
Architecture 3: MMoE (Multi-gate Mixture-of-Experts)#
Shared-Bottom forces every task through one bottleneck. MMoE keeps a pool of expert sub-networks and lets each task softly choose its own mixture of experts.
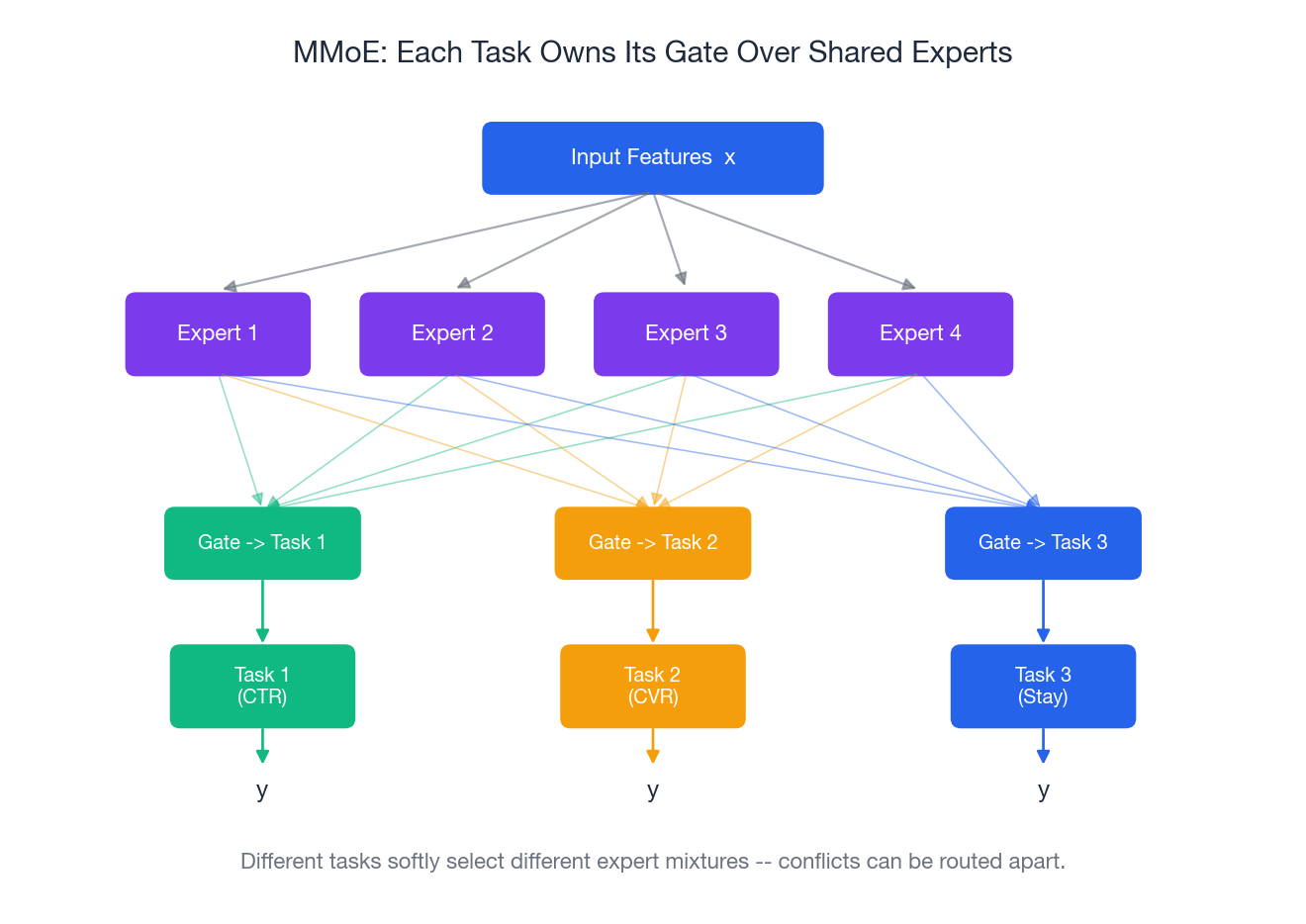
The Analogy#
You are organizing a dinner party with three jobs: cooking, decor, music. Instead of hiring one person to do all three (Shared-Bottom), you hire four specialists. Each job has its own manager (gate) who decides how much weight to give each specialist. The cooking manager leans on the chef and the sommelier; the decor manager leans on the florist and the lighting designer. The chef may still throw in a plating idea for decor — managers are free to mix.
The Math#
$$f_k(x) = \sum_{i=1}^{n} g_k^{(i)}(x) \cdot E_i(x), \qquad g_k(x) = \mathrm{softmax}(W_k x)$$Each gate is just a tiny linear-then-softmax network. Conflicting tasks learn to point at different experts; cooperative tasks learn to share.
Implementation#
| |
When MMoE Helps#
- You suspect some tasks conflict but you don’t know which.
- You want a single architecture that gracefully handles both cooperative and antagonistic mixes.
- The gate weights themselves are useful telemetry — you can plot them and see which tasks share which experts.
Architecture 4: PLE (Progressive Layered Extraction)#
PLE, from Tencent, addresses an MMoE failure mode: even with gates, a shared expert pool can let one task’s gradients corrupt features another task depends on — the famous seesaw phenomenon where lifting CTR drops watch time by exactly the amount you lifted.
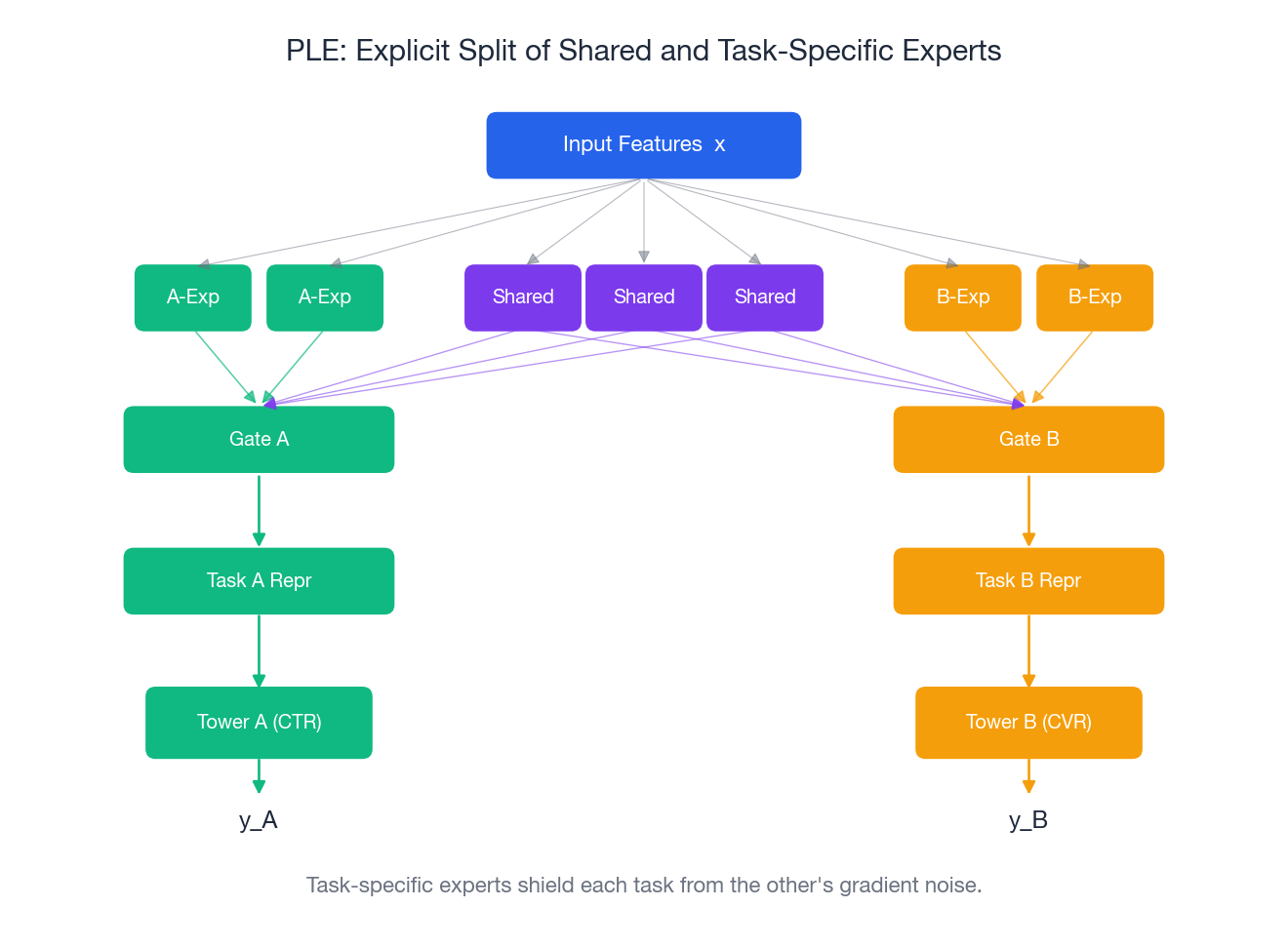
The Idea#
Make the split explicit. Each task layer has:
- Shared experts — visible to every task, learn cross-task patterns.
- Task-specific experts — private to one task, never see another task’s gradient.
Each task’s gate combines shared experts with its own task-specific experts. Stack a couple of these layers and you get progressive extraction: lower layers do generic feature work, higher layers do task-specific refinement.
Implementation#
| |
Why The Split Matters#
A task-specific expert receives gradient only from its task. So when CTR’s gradient yanks the model in a direction CVR hates, the damage is confined to the shared experts — CVR’s private experts are untouched. In Tencent’s reported video-recommendation numbers PLE bought another ~0.4% AUC over MMoE on multiple engagement metrics, and meaningfully reduced the seesaw effect.
Picking an Architecture#
| Situation | Pick | Reason |
|---|---|---|
| Tasks closely aligned, limited eng resources | Shared-Bottom | Simple, fast, good baseline |
| CVR prediction with clicked-only labels | ESMM | Removes selection bias by construction |
| Mix of related and possibly conflicting tasks | MMoE | Gates discover the right routing |
| Known mix of shared and conflicting patterns | PLE | Hard split caps negative transfer |
A reasonable progression in a real project: ship Shared-Bottom; if any single-task baseline beats your MTL model on its own task, move to MMoE; if you observe seesaw, move to PLE.
Loss Balancing: Stop One Task From Eating The Others#
CTR loss might sit around 0.3, CVR around 0.05, a revenue MSE around 100. If you sum them, the regression task drowns the others. Balancing is not a finishing touch — it is the difference between the model learning two tasks and learning one and a half.
Uncertainty Weighting (Kendall et al., 2018)#
$$\mathcal{L}_{\text{total}} = \sum_k \frac{1}{2\sigma_k^2}\, \mathcal{L}_k + \log \sigma_k$$Hard tasks naturally inflate $\sigma_k$ , which down-weights them; the $\log \sigma_k$ term stops $\sigma_k$ from running off to infinity. The picture is what you’d hope for — the easy task’s normalized weight grows as the hard task’s shrinks:
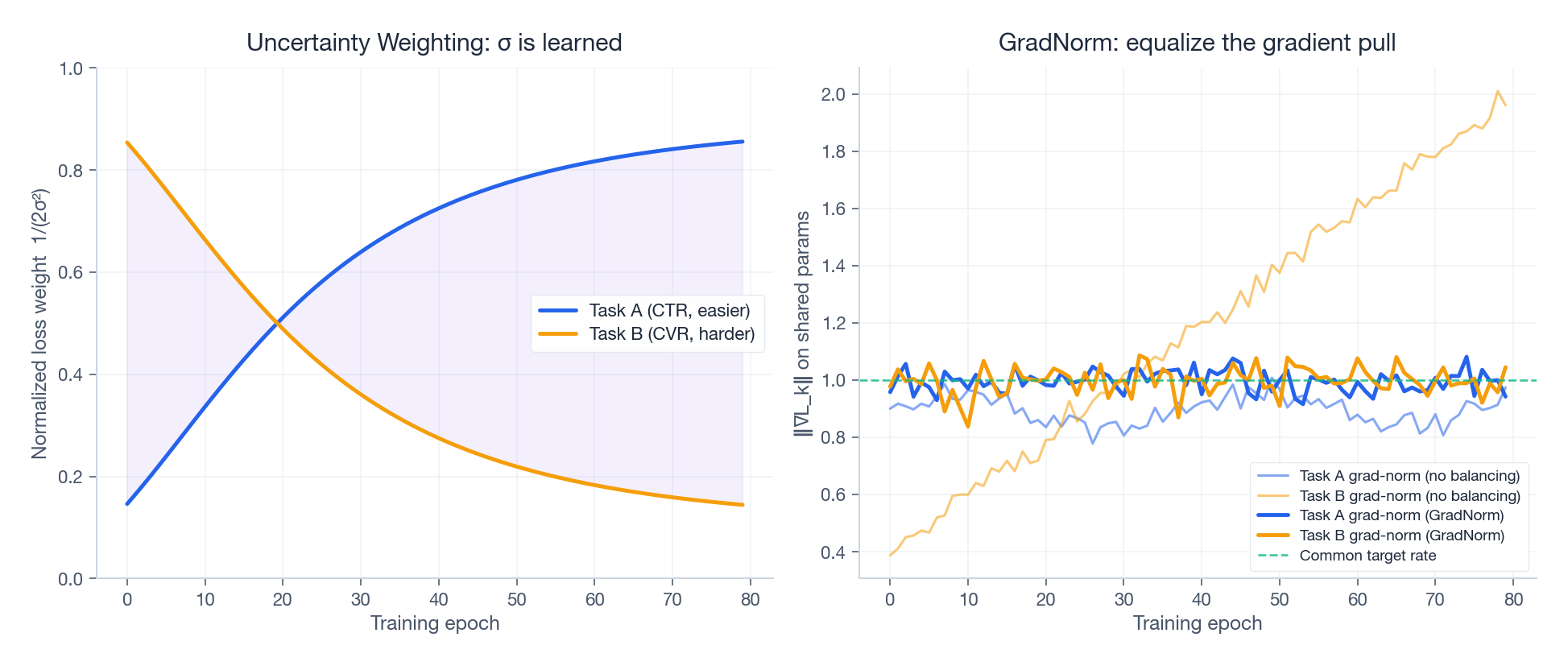
| |
GradNorm#
Uncertainty Weighting balances losses. GradNorm balances gradient magnitudes on the shared trunk. The intuition: a task whose gradient norm dwarfs the others is, mechanically, the one steering the trunk. GradNorm scales each task’s weight so that all tasks contribute roughly equal pull, with an optional bias toward tasks that are learning more slowly. The right panel above shows the raw norms drifting apart and being pulled back to a common rate.
Pareto Optimization#
When tasks genuinely conflict, no single weighting is “best” — only different trade-offs. Plotting the achievable (CTR-AUC, CVR-AUC) pairs gives you a Pareto frontier: solutions where you cannot improve one metric without sacrificing the other.
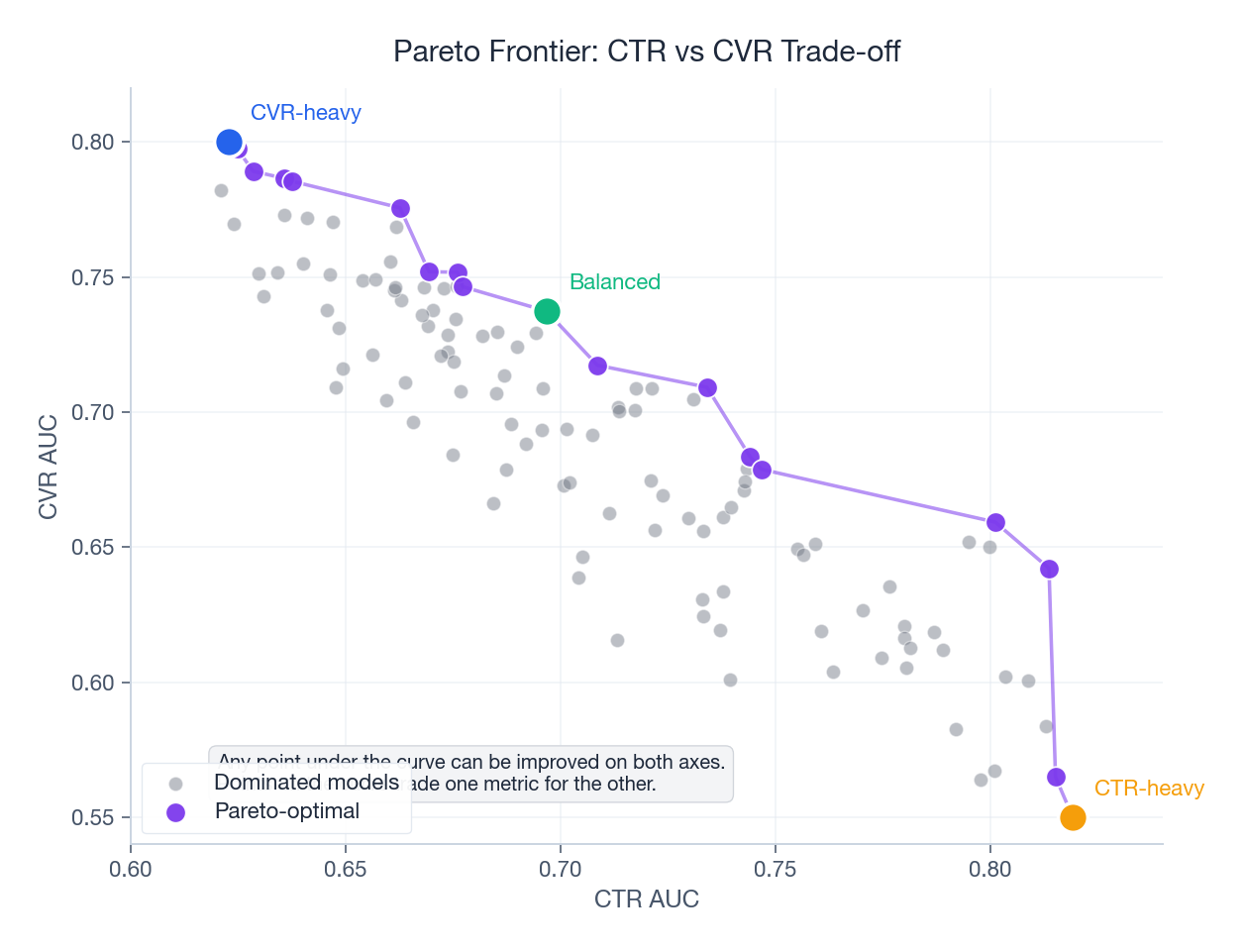
In production this is less of a math problem and more of a product call: where on the curve does the business want to sit?
Why Tasks Fight: Gradient Conflict Up Close#
Why does any of this matter? Because shared parameters get pulled in two different directions at once. Pick a single shared weight $\theta$ ; task A says “increase me” and task B says “decrease me”. The joint update is the sum of two opposing arrows — often a much smaller step than either task wanted, in a direction neither task likes.
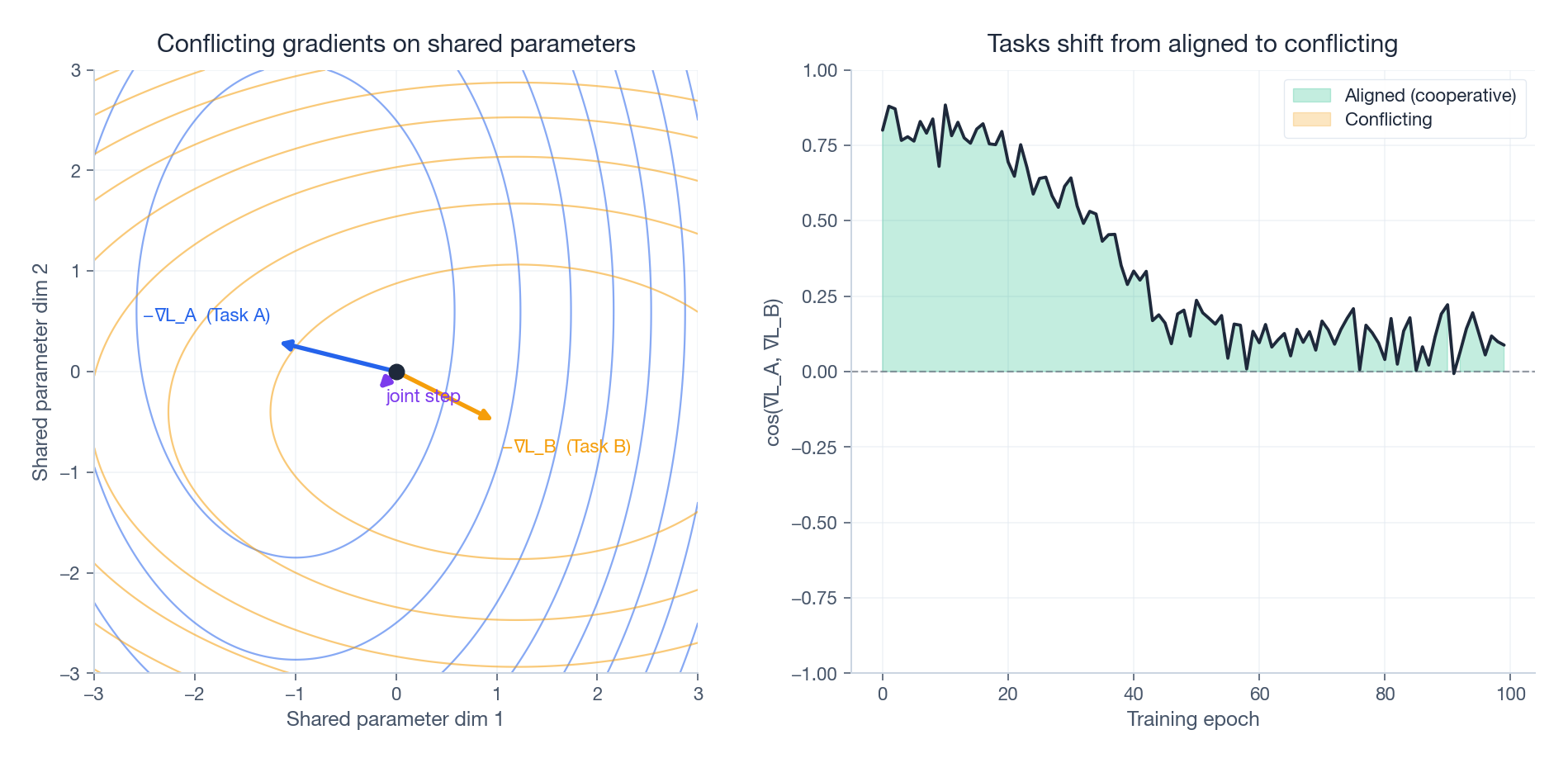
The right panel is the diagnostic you actually want in production: track the cosine similarity of the two tasks’ gradients on the shared trunk over training. If it slides negative and stays there, your model is in active gradient war. That is the precise moment to consider PLE (split the experts) or PCGrad (project away the conflicting component before stepping). Watching this number is cheap and tells you more than aggregate loss curves.
Industrial Reference Points#
| Company | Architecture | Setting | Reported lift |
|---|---|---|---|
| Alibaba | ESMM | Taobao CVR | ~2-3% AUC over biased CVR baseline |
| MMoE | YouTube ranking | Significant improvement over Shared-Bottom across multiple objectives | |
| Tencent | PLE | Tencent Video | ~0.4% AUC over MMoE; seesaw effect reduced |
Numbers are from the original papers; production systems iterate further.
A Complete Training Pipeline#
Putting MMoE together with Uncertainty Weighting and a real-feeling training loop:
| |
FAQ#
When is MTL actually worth the complexity?#
When tasks share underlying user/item structure, and you have at least one sparse task that benefits from a dense one’s signal, and you care about serving cost. If those don’t apply — truly independent tasks, comfortable serving budget — separate models are simpler and often better.
How many experts in MMoE / PLE?#
Heuristic: at least as many experts as tasks; in practice 2-4 experts for 2-3 tasks, 4-8 for more. Too few and the experts can’t specialize; too many and they overfit and the gates collapse onto a small subset.
What about missing labels?#
Mask the loss. For each sample, only contribute the loss of tasks whose label is present. This is the standard play for CVR-style sparse labels living alongside CTR-style dense labels.
Does MTL help cold-start?#
Yes, indirectly. Dense tasks (clicks) shape representations that the sparse heads (purchases, follows) can lean on. New users with a handful of clicks get usable conversion estimates, where a single-task CVR model would have nothing to say.
How do I debug an MTL model?#
In rough order of usefulness:
- Compare each head against its single-task baseline. If MTL loses on a head, you have negative transfer.
- Plot gate weights (MMoE/PLE). Are tasks routing to different experts the way you’d expect?
- Track gradient cosine similarity between task losses on the shared trunk. Negative for long stretches → consider PLE or PCGrad.
- Ablate: drop a task, drop an expert, drop loss balancing. Whatever you remove that helps is the thing your model didn’t actually need.
Closing Thought#
The architecture progression — Shared-Bottom → ESMM → MMoE → PLE — is really a progression in how much we admit that tasks fight each other. Shared-Bottom assumes they don’t. ESMM sidesteps a specific bias problem. MMoE lets the model decide where to share. PLE makes the share/private split explicit and structural. Pair the right architecture with a sane balancing strategy (start with Uncertainty Weighting), watch your gradient cosine similarities, and you have a multi-task system that holds up in production.
Recommendation Systems 16 parts
- 01 Recommendation Systems (1): Fundamentals and Core Concepts
- 02 Recommendation Systems (2): Collaborative Filtering and Matrix Factorization
- 03 Recommendation Systems (3): Deep Learning Foundations
- 04 Recommendation Systems (4): CTR Prediction and Click-Through Rate Modeling
- 05 Recommendation Systems (5): Embedding and Representation Learning
- 06 Recommendation Systems (6): Sequential Recommendation and Session-based Modeling
- 07 Recommendation Systems (7): Graph Neural Networks and Social Recommendation
- 08 Recommendation Systems (8): Knowledge Graph-Enhanced Recommendation
- 09 Recommendation Systems (9): Multi-Task Learning and Multi-Objective Optimization you are here
- 10 Recommendation Systems (10): Deep Interest Networks and Attention Mechanisms
- 11 Recommendation Systems (11): Contrastive Learning and Self-Supervised Learning
- 12 Recommendation Systems (12): Large Language Models and Recommendation
- 13 Recommendation Systems (13): Fairness, Debiasing, and Explainability
- 14 Recommendation Systems (14): Cross-Domain Recommendation and Cold-Start Solutions
- 15 Recommendation Systems (15): Real-Time Recommendation and Online Learning
- 16 Recommendation Systems (16): Industrial Architecture and Best Practices