Prompt Engineering Complete Guide: From Zero to Advanced Optimization
Master prompt engineering from zero-shot basics to Tree of Thoughts, DSPy, and automated optimization. Includes benchmarks, code, and a debugging toolkit.
The same model, two prompts: one achieves 17% accuracy on grade-school math, the other 78%. The difference isn’t magic—it’s prompt engineering. This guide covers the techniques that work, the research behind them, and how to systematically optimize prompts for production.
What You Will Learn#
- Foundations — zero-shot, few-shot, many-shot, task decomposition, and the five-block prompt skeleton.
- Reasoning techniques — Chain-of-Thought, Self-Consistency, Tree of Thoughts, Graph of Thoughts, ReAct.
- Automation — Automatic Prompt Engineering (APE), DSPy, LLMLingua compression.
- Practical templates — structured output, code generation, data extraction, multi-turn chat.
- Evaluation and debugging — metrics, A/B testing, error analysis, the failure-mode toolkit.
Prerequisites. Basic Python; experience calling any LLM API. No math background required.
Why prompt engineering matters#
When OpenAI released GPT-3 in 2020, researchers quickly noticed something surprising: the same model produced wildly different results based on how you phrased a request. A poorly worded prompt generated nonsense, while a carefully crafted one solved complex reasoning tasks. This wasn’t a bug; it’s a fundamental property of how these models learn.
Traditional programming relies on exact instructions: write a function, specify inputs and outputs, and the computer executes deterministically. Language models work differently. They predict the most likely continuation of text based on patterns learned from trillions of tokens. Your prompt doesn’t command the model; it sets up a context that nudges its probability distribution toward useful outputs.
The stakes are high. A well-engineered prompt can reduce API costs by 10x through more efficient context usage. It can boost task accuracy from 40% to 90% on complex reasoning benchmarks. For production systems handling millions of requests, these gains translate to real business value.
Anatomy of a production prompt#

Almost every prompt in production breaks down into the same five blocks: role, context, instruction, examples, and output format. Treat them as a skeleton. Swap the body for each task; keep the bones consistent. Reusing this structure makes evaluation, caching, and version control dramatically easier.
Foundational techniques#
Zero-shot prompting#
Zero-shot means asking the model to perform a task without any demonstrations. You rely entirely on the model’s pre-training to interpret and execute the request.
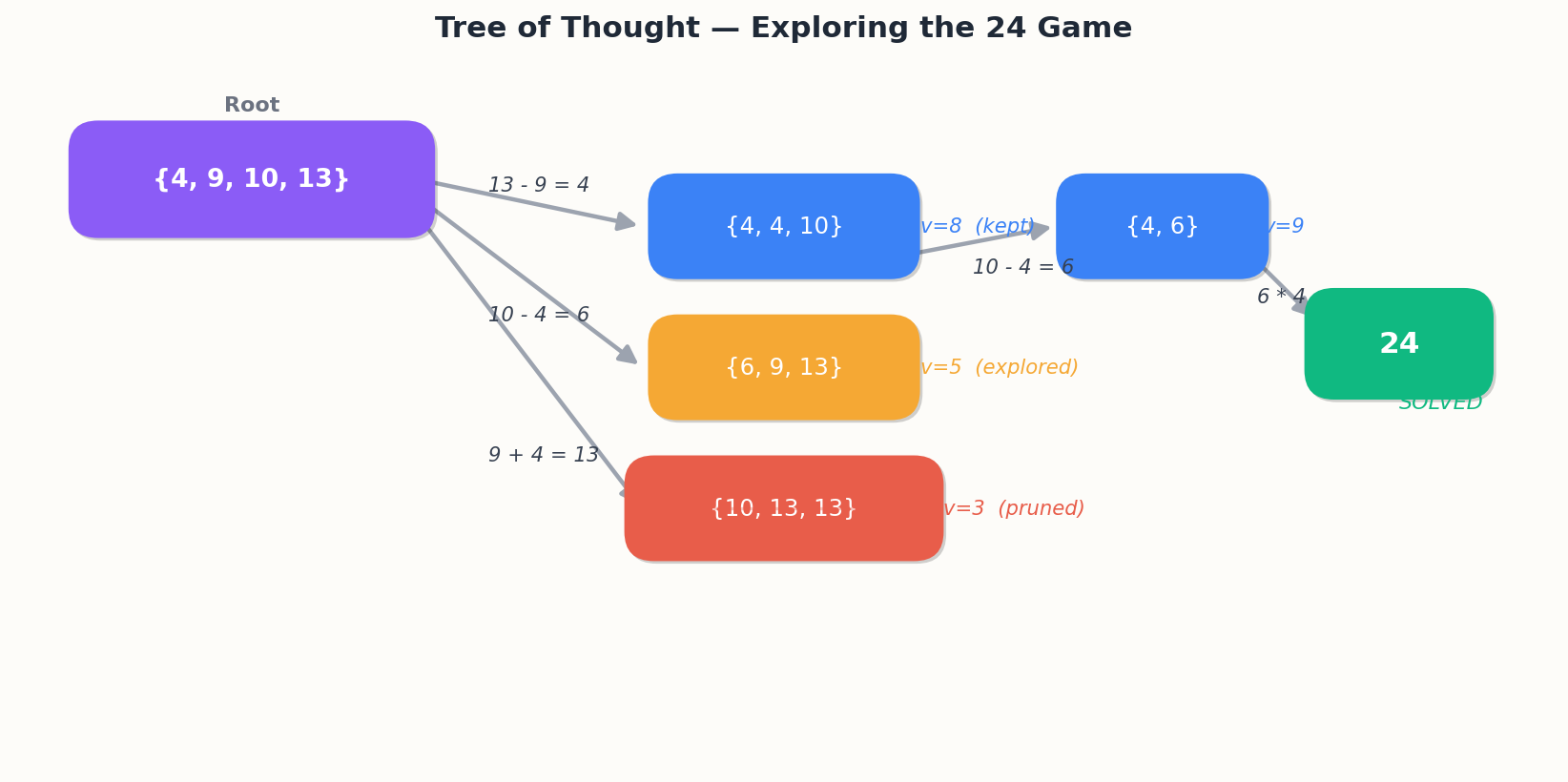
Yao et al. (2023) benchmarks:
| Task | CoT | ToT | Δ |
|---|---|---|---|
| Game of 24 | 7.3% | 74% | +66pp |
| Creative writing | 7.3 | 7.9 | +0.6 |
| Crosswords | 15.6% | 78% | +62pp |
The cost. Breadth-3 depth-4 search is ~80 LLM calls per problem. ToT pays off only when (a) there are multiple plausible solution paths and (b) self-evaluation is reliable for the task. Use it for combinatorial puzzles, planning, and constraint satisfaction. Skip it for straightforward Q&A.
A production-friendly best-first version uses a priority queue with a hard call-count cap to prevent a single problem from blowing your budget.
Graph of Thoughts (GoT)#
GoT (Besta et al., 2023) generalizes ToT to arbitrary DAGs. Thoughts can merge (combining multiple branches) or iterate (refining a single thought across rounds), enabling reasoning patterns trees cannot express.
A canonical example — multi-document summarization:
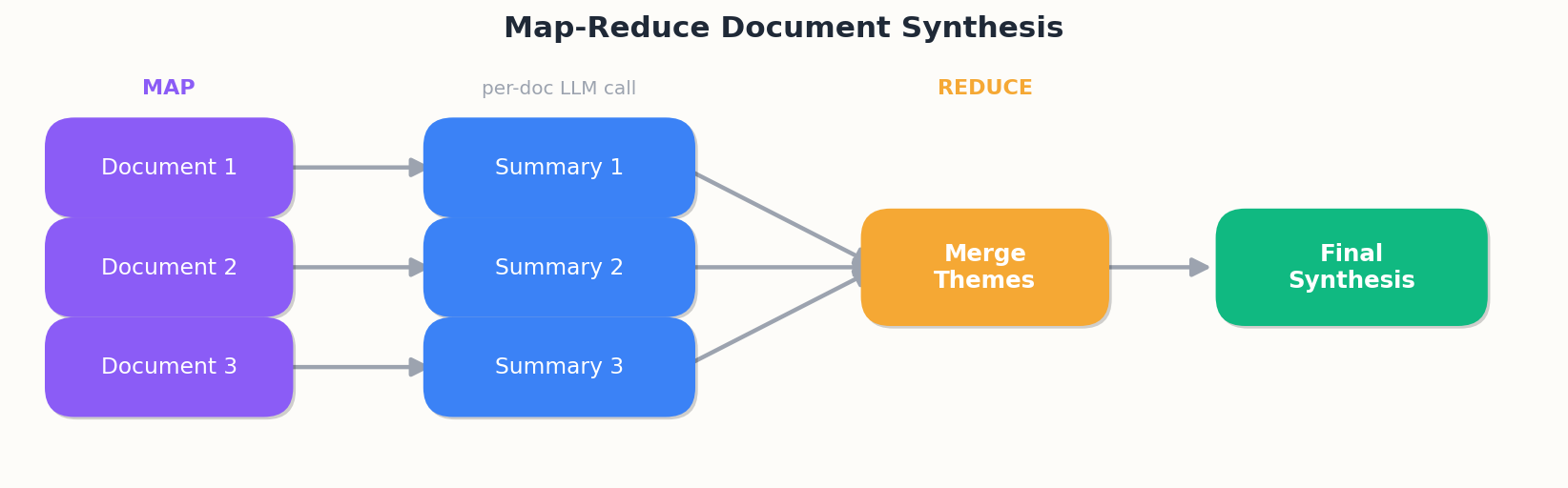
Each per-document summary is independent and can run in parallel. The merge step combines them. This is a graph, not a tree.
| |
On a 32-number sorting task, Besta et al. reported 89% accuracy at 62% lower cost than ToT — the merge operations remove redundant exploration.
ReAct (Reason + Act)#
ReAct (Yao et al., 2022) interleaves thinking with acting. The model alternates between reasoning steps and tool calls, observing the result of each action before deciding the next step.
| |
ReAct fixes three things language models are bad at on their own: stale knowledge (training data has a cutoff), precise calculations, and access to private data. A minimal agent:
| |
Performance on HotpotQA (multi-hop QA): standard prompting 28.7% → CoT 32.9% → ReAct 37.4%. On AlfWorld (interactive environment): 12% → 34%.
Best practices.
- Document tools well. The model picks tools by their docstrings.
- Truncate observations. Long search results can blow the context window.
- Cap steps. Always set a hard limit to prevent infinite loops.
- Return descriptive errors. Let the model recover instead of crashing.
Prompts are not robust by default#
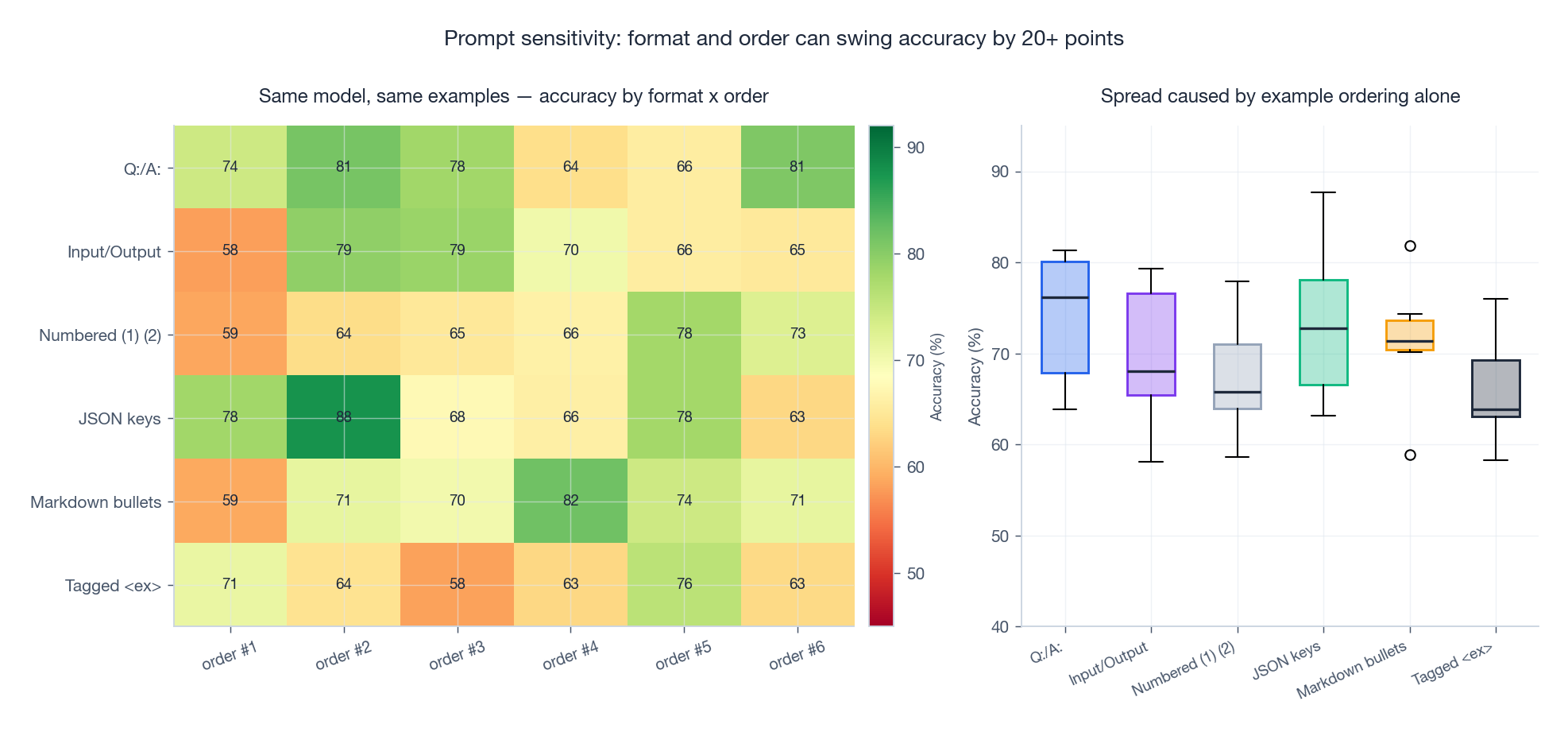
Same model, same examples, same task. Just changing the format of the demonstrations or the order of the few-shot examples can swing accuracy by 20+ points (Lu et al., 2022; Sclar et al., 2024). This is why empirical evaluation is non-negotiable. Test your prompt under multiple orderings before declaring a winner.
Optimization and automation#
Manual prompt engineering does not scale beyond a handful of tasks. The following techniques automate the process.
Automatic Prompt Engineering (APE)#
APE (Zhou et al., 2022) automates the search for the best prompt:
- Generate candidate prompts using an LLM, given the task description and a handful of examples.
- Evaluate each candidate on a validation set.
- Select the highest-performing one.
| |
Zhou et al. found APE-discovered prompts beating human-written baselines by 3–8 percentage points across many tasks. The key insight: APE explores phrasings humans would not try, optimizes directly on your data, and can test hundreds of candidates cheaply.
An iterative extension feeds the current best prompt back into the meta-prompt and asks for refinements — a kind of hill climbing in prompt space.
DSPy: declarative prompts as code#
DSPy (Khattab et al., 2023) treats prompting as a programming problem. Instead of hand-writing prompts, you write programs that compose prompts, and a compiler tunes them automatically.
The core abstractions:
- Signatures — typed input/output specs.
- Modules — composable prompt templates.
- Optimizers — automatic tuners that pick demonstrations and instructions.
A sentiment classifier:
| |
DSPy can automatically tune the underlying prompt by bootstrapping demonstrations from a training set:
| |
Multi-stage programs compose naturally:
| |
The DSPy compiler optimizes all three sub-prompts together. The trade-offs are real: a learning curve, less direct control over wording, and an upfront optimization cost. Use DSPy when you have a stable training set and a real evaluation metric.
LLMLingua: prompt compression#
LLMLingua (Jiang et al., 2023) compresses prompts to cut cost while preserving accuracy. A small LLM scores each token’s importance; low-scoring tokens are removed.
| |
The underlying technique is conditional perplexity: remove a token, measure how much the perplexity of the next prediction increases, and keep only the tokens that move the needle.
Reported impact:
- Question answering at 2x compression: 2–3% accuracy drop, 50% cost savings, 1.4x latency improvement.
- RAG at 4x compression: 5–7% accuracy drop, 75% cost savings.
Best fit: long-context scenarios (RAG, document analysis) where the cost-vs-quality trade-off is worth it. Avoid for legal or medical text where every word matters.
A sketch of an adaptive compressor that allocates budget per section by priority:
| |
Practical templates#

The figure above shows the same five-block skeleton specialized for six common tasks. The benefit is not aesthetic — it makes evaluation, caching, and version control dramatically easier.
Structured output#
Getting valid JSON out of an LLM is famously tricky. Three strategies, in order of robustness:
| |
Strategy 2 — few-shot with valid examples — works when the schema is simple. Strategy 3 — provider-native function/tool calling — is the most reliable when available; the API guarantees the JSON is well-formed.
Code generation with self-test#
| |
The pattern is generate → test → repair. The repair prompt feeds the failing test back to the model with the original instructions intact.
Multi-turn conversation management#
Long conversations exceed the context window. The fix: keep a sliding window of recent messages plus an LLM-generated summary of the older ones.
class ConversationManager:
def __init__(self, model, system_prompt: str, max_tokens: int = 4000):
self.model = model
self.system_prompt = system_prompt
self.max_tokens = max_tokens
self.history: list[dict] = []
def chat(self, user_message: str) -> str:
self.history.append({"role": "user", "content": user_message})
context = self._get_context()
response = self.model.generate(self._build_prompt(context))
self.history.append({"role": "assistant", "content": response})
return response
def _get_context(self) -> list[dict]:
ctx = [{"role": "system", "content": self.system_prompt}]
used = count_tokens(self.system_prompt)
for msg in reversed(self.history):
t = count_tokens(msg["content"])
if used + t > self.max_tokens:
break
ctx.insert(1, msg)
used += t
return ctx
def summarize_old_turns(self) -> None:
if len(self.history) < 10:
return
old = self.history[:6]
summary = self.model.generate(
f"Summarize concisely:\n{format_messages(old)}\n\nSummary:"
)
self.history = (
[{"role": "system", "content": f"Earlier conversation: {summary}"}]
+ self.history[6:]
)
Evaluation and debugging#
Prompt engineering is empirical. Without metrics you are guessing.
Metrics, in order of cost.
def exact_match(pred, truth):
return normalize(pred) == normalize(truth)
def f1(pred, truth):
p = set(normalize(pred).split())
t = set(normalize(truth).split())
if not p or not t:
return float(p == t)
common = p & t
if not common:
return 0.0
prec = len(common) / len(p)
rec = len(common) / len(t)
return 2 * prec * rec / (prec + rec)
def semantic_similarity(pred, truth, model="all-MiniLM-L6-v2"):
from sentence_transformers import SentenceTransformer, util
m = SentenceTransformer(model)
return util.cos_sim(m.encode(pred), m.encode(truth)).item()
def llm_as_judge(pred, truth, criteria):
return parse_score(llm_call(f"""Evaluate this output.
Task: {criteria['task']}
Expected: {truth}
Actual: {pred}
Score 0-10 with brief justification:"""))
Pick the cheapest metric that correlates with what you actually care about.
A/B testing prompt variants#
class PromptExperiment:
def __init__(self, test_set, metrics):
self.test_set = test_set
self.metrics = metrics
def evaluate(self, prompt_fn):
return {
m.__name__: sum(
m(llm_call(prompt_fn(x), temperature=0), y)
for x, y in self.test_set
) / len(self.test_set)
for m in self.metrics
}
def compare(self, variants: dict) -> "pd.DataFrame":
import pandas as pd
rows = [{"prompt_name": name, **self.evaluate(fn)}
for name, fn in variants.items()]
df = pd.DataFrame(rows)
return df.sort_values(by=df.columns[1], ascending=False)
Always test on data the prompt designer has not seen.
Debugging failing prompts#
When prompts misbehave, run through this checklist:
| Symptom | Likely cause | Fix |
|---|---|---|
| Vague or wandering output | Ambiguous instructions | Add specific constraints and examples |
| Output ignores some requirement | Contradictory instructions | Resolve the conflict, set priorities |
| Output is wrong despite trying | Missing context | Provide grounding facts or retrieved docs |
| Format mismatch | No format spec | Specify schema with an example |
| Different answers each run | Too complex for one pass | Decompose into multiple steps |
A small detector that flags the most common issues:
class PromptDebugger:
AMBIGUOUS = {"relevant", "appropriate", "good", "bad",
"some", "few", "many", "stuff", "things"}
CONFLICT = {"but", "however", "although", "except"}
def check_ambiguity(self, prompt):
return any(w in prompt.lower() for w in self.AMBIGUOUS)
def check_conflicts(self, prompt):
return sum(w in prompt.lower() for w in self.CONFLICT) >= 2
def infer_format(self, text):
t = text.strip()
if t.startswith("{") and t.endswith("}"): return "json_object"
if t.startswith("[") and t.endswith("]"): return "json_array"
if "\n-" in t or "\n*" in t or "\n1." in t: return "list"
return "prose"
Error analysis#
Bucket failures by mode. The categories below cover the vast majority of mistakes:
def categorize_error(pred: str, truth: str) -> str:
p, t = normalize(pred), normalize(truth)
if not p:
return "empty_output"
if p in t or t in p:
return "partial_match"
p_w, t_w = set(p.split()), set(t.split())
overlap = len(p_w & t_w) / max(len(p_w), len(t_w))
if overlap > 0.5:
return "semantic_error"
if overlap > 0:
return "partial_hallucination"
return "complete_hallucination"
Then attack the largest bucket first.
Common Pitfalls#
| Pitfall | Fix |
|---|---|
| Vague instructions | List concrete dimensions to optimize: clarity, length, voice, format. |
| Assuming knowledge | Include the code, document, or data the prompt refers to. |
| Overly long prompts | Split, summarize, or use RAG. The “lost in the middle” effect is real. |
| Ignoring output format | Specify schema, units, and language explicitly with an example. |
| No validation | Wrap calls in a validate → retry → fail loop. |
FAQ#
Should I use higher or lower temperature?#
0 for tasks needing consistency (classification, extraction, math, code). 0.7–0.8 for creative tasks. 1.0+ rarely. Default to 0 for structured tasks, 0.7 for creative ones.
How many examples in few-shot?#
2–3 for simple tasks, 5–7 is the sweet spot for most, 10+ only if the examples are diverse. Past 50 you should consider fine-tuning.
When should I fine-tune instead?#
When you have 1,000+ high-quality labeled examples, the task is highly specialized, latency or cost are critical, and you have plateaued with prompt engineering. Otherwise, prompt — it iterates 1000x faster.
How do I prevent hallucinations?#
Ground with retrieved context, instruct the model to say “I don’t know,” request quoted citations, lower the temperature, and add a verification pass.
How do I handle long documents?#
Chunk + map-reduce, retrieval-augmented generation, hierarchical summarization, or models with large context windows (Claude 3 200K, Gemini 1.5 1M). RAG is usually the right default.
Do prompts transfer across models?#
Universal techniques (clear instructions, few-shot, format specs, CoT) transfer well. Exact phrasing, format preferences (Claude likes XML), and tool-calling syntax do not. Always test on the target model.
Can I automate optimization?#
Yes — APE, DSPy, and genetic search all work. Start manual to understand the task, then automate.
XML, JSON, or plain text for prompts?#
Plain text for simple prompts. JSON for structured I/O. XML for complex multi-part prompts (especially with Claude). All three are fine — pick the one your downstream parser expects.
CoT vs ToT vs GoT — when to use which?#
| Technique | Structure | When to use | Cost |
|---|---|---|---|
| CoT | Linear chain | Multi-step reasoning, math, logic | 1–2x |
| ToT | Tree search | Multiple solution paths, planning, puzzles | 5–50x |
| GoT | Arbitrary DAG | Parallel processing, merging insights | Varies |
The future?#
Multimodal prompting, tighter automation (DSPy, APE), aggressive compression, meta-prompting (prompts that generate prompts), embodied agents. The skill will not disappear — it will shift from manual crafting to designing optimization objectives, evaluation harnesses, and orchestration.
Summary#
Prompt engineering started as trial-and-error and has matured into a discipline backed by research and reusable frameworks. The fundamentals — clear instructions, well-chosen examples, structured output — apply universally. Advanced techniques like Chain-of-Thought and Tree of Thoughts unlock capabilities that look impossible with naive prompting. APE and DSPy scale these practices to production.
But techniques alone are not enough. Effective prompt engineering requires:
- Empiricism. Test everything. What works on one model or task may fail on another.
- Iteration. Your first prompt will rarely be your best. Refine based on real failures.
- Evaluation. Without metrics you are guessing.
- Context. Understand the model’s strengths, the task’s requirements, and the trade-off between cost, latency, and quality.
Start simple. Measure constantly. Iterate relentlessly. The best prompt is the one that reliably solves your problem — not the cleverest one.
References#
- Brown et al., 2020. Language Models are Few-Shot Learners. NeurIPS.
- Wei et al., 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS.
- Kojima et al., 2022. Large Language Models are Zero-Shot Reasoners. NeurIPS.
- Wang et al., 2022. Self-Consistency Improves Chain of Thought Reasoning in Language Models. ICLR.
- Yao et al., 2023. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. NeurIPS.
- Besta et al., 2023. Graph of Thoughts: Solving Elaborate Problems with Large Language Models. AAAI.
- Yao et al., 2022. ReAct: Synergizing Reasoning and Acting in Language Models. ICLR.
- Zhou et al., 2022. Large Language Models Are Human-Level Prompt Engineers. ICLR.
- Khattab et al., 2023. DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines. arXiv.
- Jiang et al., 2023. LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models. EMNLP.
- Liu et al., 2021. What Makes Good In-Context Examples for GPT-3?. arXiv.
- Lu et al., 2022. Fantastically Ordered Prompts and Where to Find Them. ACL.
- Sclar et al., 2024. Quantifying Language Models’ Sensitivity to Spurious Features in Prompt Design. ICLR.
- Min et al., 2022. Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? EMNLP.