Variational Autoencoder (VAE): From Intuition to Implementation and Troubleshooting
Build a VAE from scratch in PyTorch. Covers the ELBO objective, reparameterization trick, posterior collapse fixes, beta-VAE, and a complete training pipeline.
A plain autoencoder compresses and reconstructs. A variational autoencoder learns something far more useful: a smooth, structured latent space you can sample from to generate genuinely new data. That single change — making the encoder output a distribution instead of a vector — turns the network from a fancy compressor into a generative model with a tractable likelihood lower bound.
This guide walks the full path: why autoencoders fail at generation, how the ELBO derivation gets you to the loss function, why the reparameterization trick is the trick that makes everything trainable, a complete PyTorch implementation, and a tour of every common failure mode with concrete fixes.
What You Will Learn#
- Why an autoencoder’s latent space is unusable for sampling, and what VAEs change
- The ELBO objective: how reconstruction and KL fall out of a single likelihood bound
- The reparameterization trick: why naive sampling breaks gradients, and how
mu + sigma * epsfixes it - A complete PyTorch implementation: encoder, decoder, loss, training loop, sampling, interpolation
- Failure modes you will hit: posterior collapse, blurry samples, NaN gradients — with diagnostic and fix
- Useful variants: beta-VAE, conditional VAE, hierarchical VAE
- When to reach for a VAE versus a GAN or diffusion model
Prerequisites#
- PyTorch basics (
nn.Module, forward/backward, optimizers) - Probability foundations (mean, variance, the Gaussian density)
- Some experience training neural networks end-to-end
Why VAEs matter: autoencoders versus generative models#
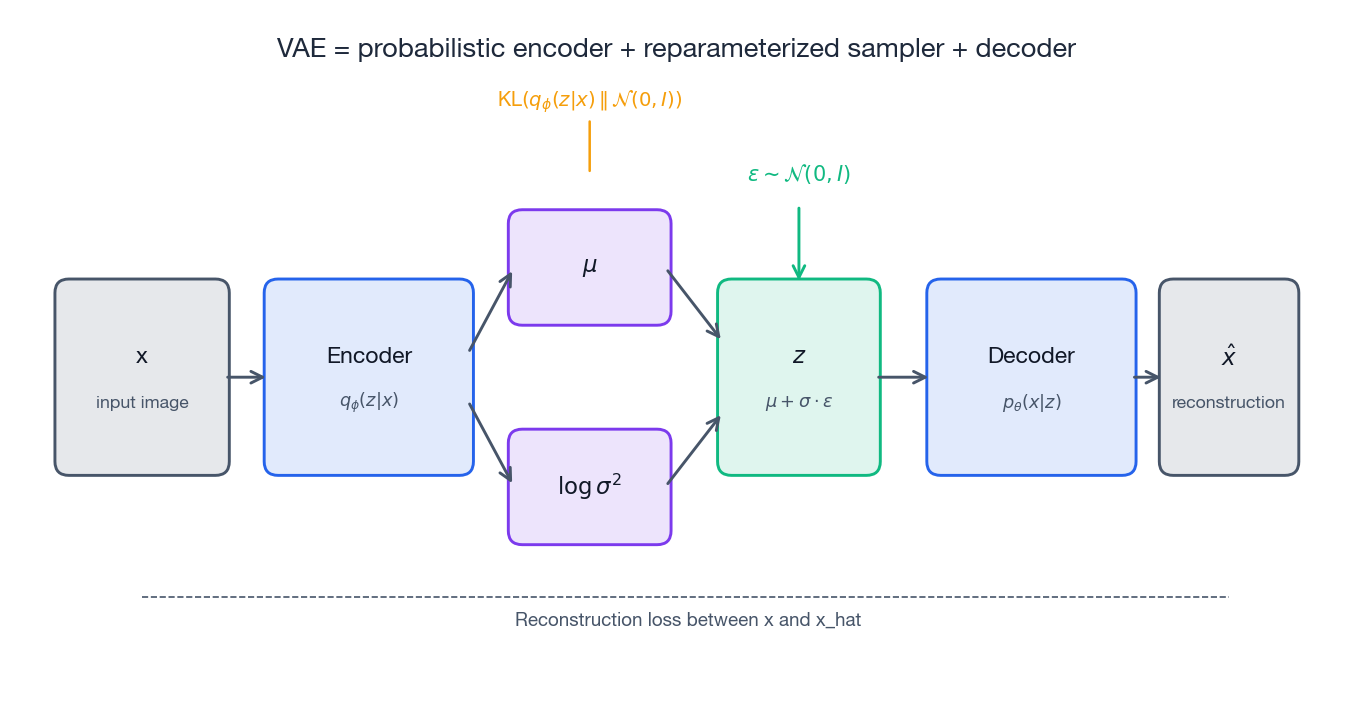
The autoencoder baseline#
$$\mathcal{L}_{\text{AE}}(x) = \|x - g_\theta(f_\phi(x))\|^2.$$This works fine for compression and denoising, but it gives you a latent space that is deterministic and unstructured. Concretely:
- You cannot sample. The decoder has only ever seen codes that the encoder produced. A random $z$ drawn from anywhere in the space will likely fall in a hole the decoder never visited and produce garbage.
- Interpolation is brittle. Two visually similar inputs can land at distant points; two distant inputs can land near each other. A straight line in latent space passes through nonsense.
- There is no probabilistic interpretation. No prior, no likelihood, no way to talk about how likely a generated sample is.
What VAEs change: a probabilistic latent#
$$q_\phi(z \mid x) = \mathcal{N}\!\left(\mu_\phi(x),\, \sigma^2_\phi(x)\, I\right).$$The decoder defines a likelihood $p_\theta(x \mid z)$ , and we impose a fixed prior $p(z) = \mathcal{N}(0, I)$ .
Three benefits flow from this single change:
- Sampling works. Draw $z \sim p(z)$ , feed it to the decoder, get a fresh $\hat{x}$ .
- Interpolation is smooth. Encoder distributions for similar inputs overlap, so straight lines through latent space yield gradual morphs.
- Structure is enforced. The KL term in the loss (next section) actively pushes the aggregated posterior toward the prior, filling the space evenly.
The ELBO objective: where the loss comes from#
Deriving the bound#
$$\log p_\theta(x) \;\geq\; \mathbb{E}_{q_\phi(z\mid x)}\!\left[\log p_\theta(x \mid z)\right] - D_{\mathrm{KL}}\!\left(q_\phi(z\mid x)\,\|\,p(z)\right).$$This right-hand side is the Evidence Lower BOund (ELBO). Maximizing it does two things at once:
- Reconstruction term $\mathbb{E}_{q_\phi}[\log p_\theta(x \mid z)]$ : the decoder must explain $x$ well from a code sampled by the encoder.
- KL term $D_{\mathrm{KL}}(q_\phi(z\mid x)\,\|\,p(z))$ : the encoder cannot wander wherever it likes; it must stay close to the prior.
Why the KL term is load-bearing#
Without KL regularization, two pathologies appear immediately:
- Spike-and-gap latent. The encoder collapses each $x$ onto an isolated point with tiny variance. The space is a constellation of needles in vacuum — beautiful for reconstruction, useless for generation.
- Decoder ignores $z$ . With a powerful decoder you also see the opposite extreme (called posterior collapse, discussed below).
The KL term forces $q_\phi(z\mid x)$ for different inputs to overlap and to cover the prior. That overlap is what makes interpolation smooth and what makes the prior usable as a sampler.
The reparameterization trick#
The problem: gradients can’t pass through a sample#
To estimate the reconstruction term we need to draw $z \sim q_\phi(z \mid x)$ and run the decoder. But sampling is a stochastic node — backpropagation cannot pass a gradient through “draw a random number.” If we naively sample, $\nabla_\phi$ for the encoder is undefined.
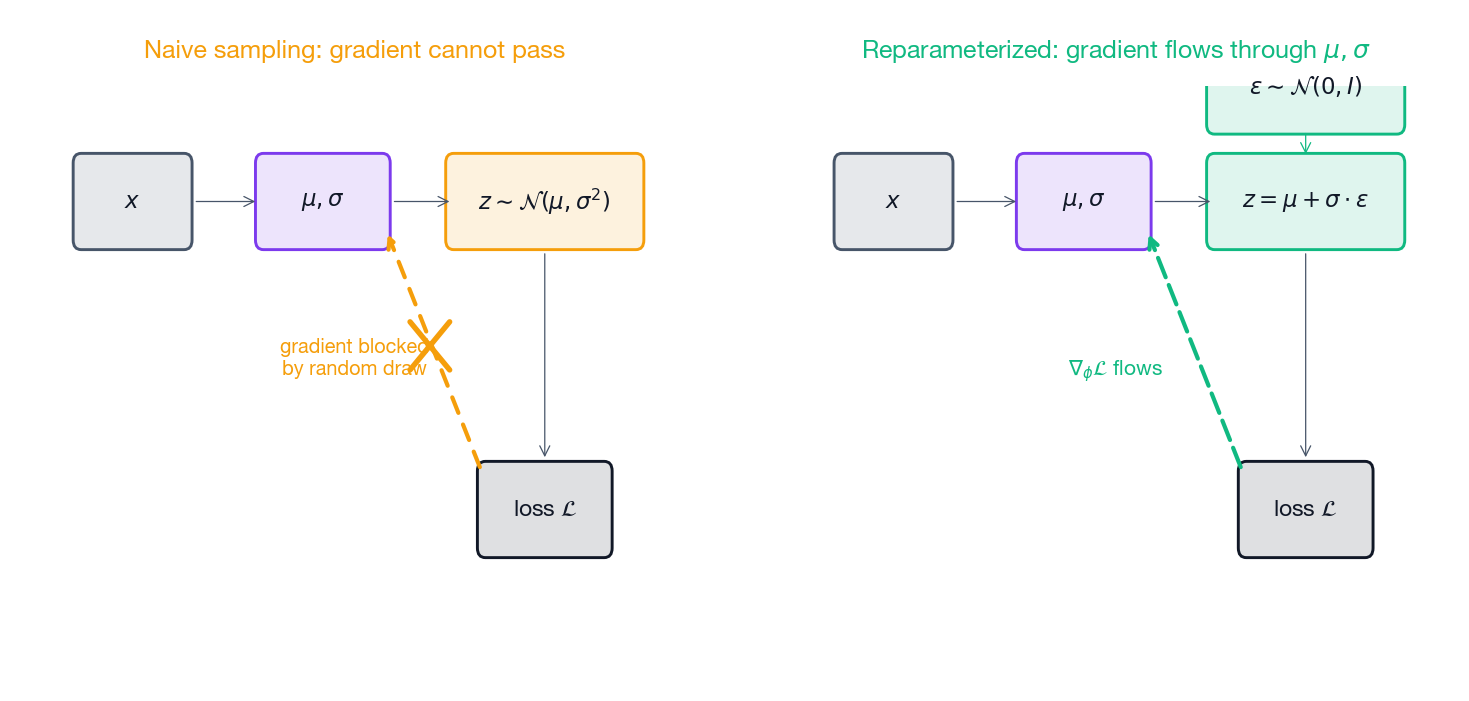
The fix: move randomness outside the parameter path#
$$z = \mu_\phi(x) + \sigma_\phi(x) \odot \epsilon, \qquad \epsilon \sim \mathcal{N}(0, I).$$Now $\epsilon$ has no parameters, and the path from $\phi$ to $z$ is fully differentiable. Gradients flow cleanly through $\mu$ and $\sigma$ .
| |
Why predict logvar instead of sigma? Two reasons, both about numerical safety:
logvaris unconstrained — any real number is valid. Predictingsigmadirectly forces you to enforce $\sigma > 0$ (e.g.,softplus), which is one more thing to get wrong.- The closed-form KL involves $\log \sigma^2$
. Predicting it directly avoids
log(exp(...))round-trips that can underflow.
Complete PyTorch implementation#
The model below is the canonical “MNIST VAE”: fully connected encoder/decoder, 20-D latent, Bernoulli decoder. It is deliberately small so you can read it end-to-end.
Network architecture#
| |
Loss function#
| |
Returning the two terms separately is worth the extra line: monitoring them is the single most useful debugging tool you have.
Training loop#
| |
Three things in this loop are not optional in practice: gradient clipping, KL annealing, and logging the two loss terms separately. You can guess why after reading the next section.
Failure modes you will actually hit#
These are the four pathologies almost everyone runs into. Each entry gives the symptoms, the root cause, and concrete code-level fixes.
Failure 1: posterior collapse#
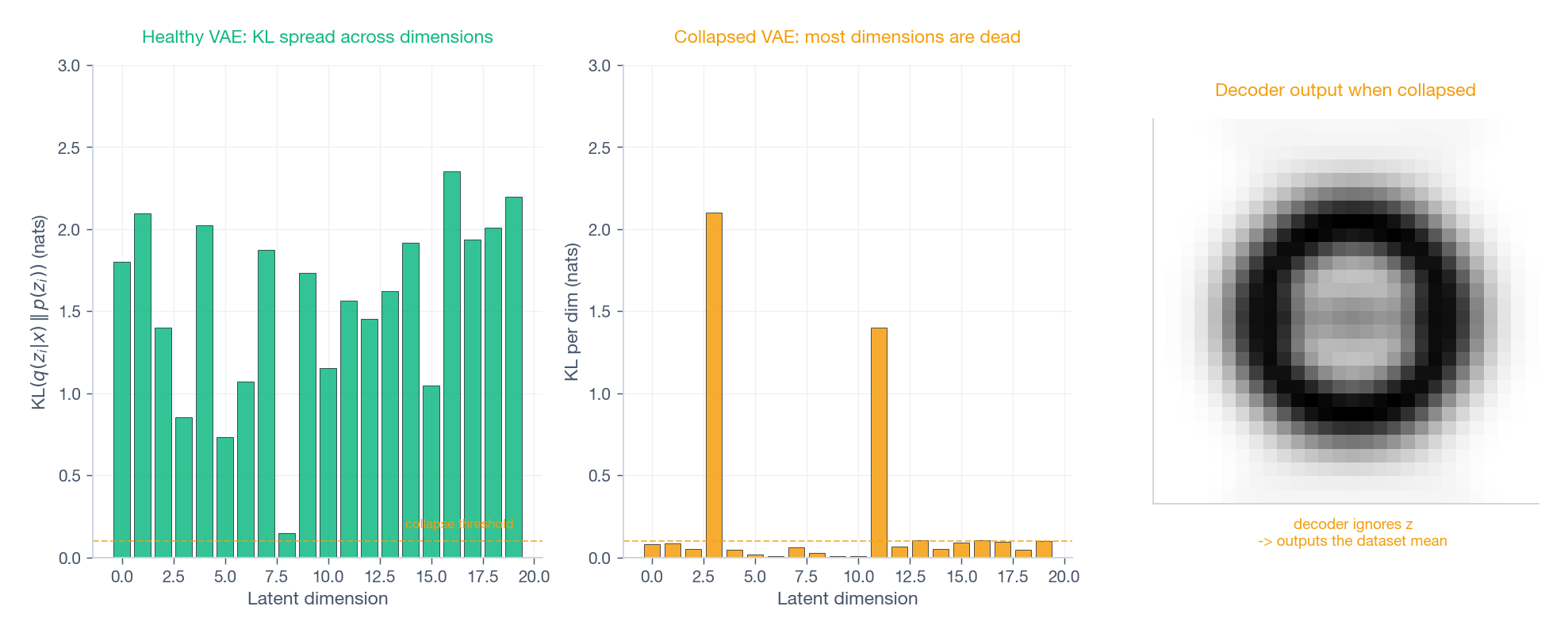
Symptoms. The KL term drops to near zero in the first few epochs and never recovers. Reconstructions look like the average training image regardless of input. Latent traversal produces no visible change.
Root cause. The decoder is powerful enough to reconstruct from $\mu$ alone, or the prior pressure overwhelms the reconstruction signal early in training. The encoder discovers it can satisfy the KL term cheaply by setting $\mu \approx 0,\ \sigma \approx 1$ for every input — i.e., ignoring $x$ .
Fixes that work, in order of how often they’re enough:
- KL annealing. Start at $\beta = 0$ and ramp linearly to 1 over the first 10–20 epochs (the loop above does this). Lets reconstruction get a foothold before KL bites.
- Free bits. Stop penalizing dimensions whose KL is already small enough — this prevents the optimizer from killing them entirely.
1 2kl_per_dim = -0.5 * (1 + logvar - mu.pow(2) - logvar.exp()) kl_loss = torch.sum(torch.clamp(kl_per_dim, min=free_bits)) - Weaken the decoder. Smaller hidden dim, dropout, or for autoregressive decoders skip the autoregressive shortcut for the first few epochs.
Failure 2: poor sample quality#
Symptoms. Reconstructions of training data look fine, but samples drawn as $z \sim \mathcal{N}(0, I)$ are noisy or unrealistic.
Root cause. The aggregated posterior $\frac{1}{N}\sum_i q_\phi(z\mid x_i)$ does not match the prior $p(z)$ . There are “holes” in the prior that the decoder never trained on.
Fixes: raise $\beta$ (1.5–4 is common); enlarge the latent ($20 \to 64$ ); train longer; switch to a stronger decoder (convolutional for images). If you still need photorealism, this is the failure mode that tells you to consider a GAN or diffusion model instead.
Failure 3: blurry reconstructions#
Symptoms. Reconstructions are recognizable but smooth and detail-poor; loss plateaus high.
Root cause. Pixel-independent likelihoods (Bernoulli or Gaussian per pixel) penalize only per-pixel error, so the optimum is the conditional mean. That mean is intrinsically blurry under uncertainty.
Fixes: add a perceptual loss (VGG features, LPIPS); switch to a discretized mixture of logistics for natural images; or move to a hierarchical VAE that uses higher-level latents for global structure and lower-level ones for detail.
Failure 4: NaN losses and exploding gradients#
Symptoms. Loss becomes NaN after a few hundred steps, or grad norm spikes by orders of magnitude.
Root cause. Almost always one of: unbounded logvar causing exp overflow in the KL; pixel values outside [0, 1] for BCE; learning rate too high; or batch where the reparameterized $\sigma$
underflows.
Fixes:
| |
Useful variants#
Beta-VAE: explicit disentanglement#
$$\mathcal{L} = \mathbb{E}_{q_\phi}[\log p_\theta(x\mid z)] - \beta \cdot D_{\mathrm{KL}}(q_\phi(z\mid x)\,\|\,p(z)),$$with $\beta \in [2, 10]$ typical for disentanglement experiments. The trade-off is exactly what you’d expect: reconstruction degrades as $\beta$ rises.
Conditional VAE: control what gets generated#
$$q_\phi(z \mid x, y), \qquad p_\theta(x \mid z, y).$$In code, just concatenate a one-hot $y$ into the encoder input and into $z$ before the decoder. To generate a specific class, sample $z \sim \mathcal{N}(0, I)$ and feed it together with the desired label.
Hierarchical VAE: latents at multiple scales#
Stack latents $z_1, z_2, \ldots, z_L$ with $z_{l-1}$ generated conditional on $z_l$ . The lower latents capture local detail, the higher ones capture global semantics. Modern variants (NVAE, Very Deep VAE) close most of the sample-quality gap with diffusion using exactly this idea.
Practical tips#
Normalize your inputs to match your likelihood#
BCE expects pixels in $[0, 1]$ ; Gaussian likelihoods (MSE) work better with zero-centered inputs.
| |
Start small with the latent#
latent_dim = 20 is a reasonable default for MNIST-scale data. Too small bottlenecks reconstruction; too large invites posterior collapse and slows training.
Always log reconstruction and KL separately#
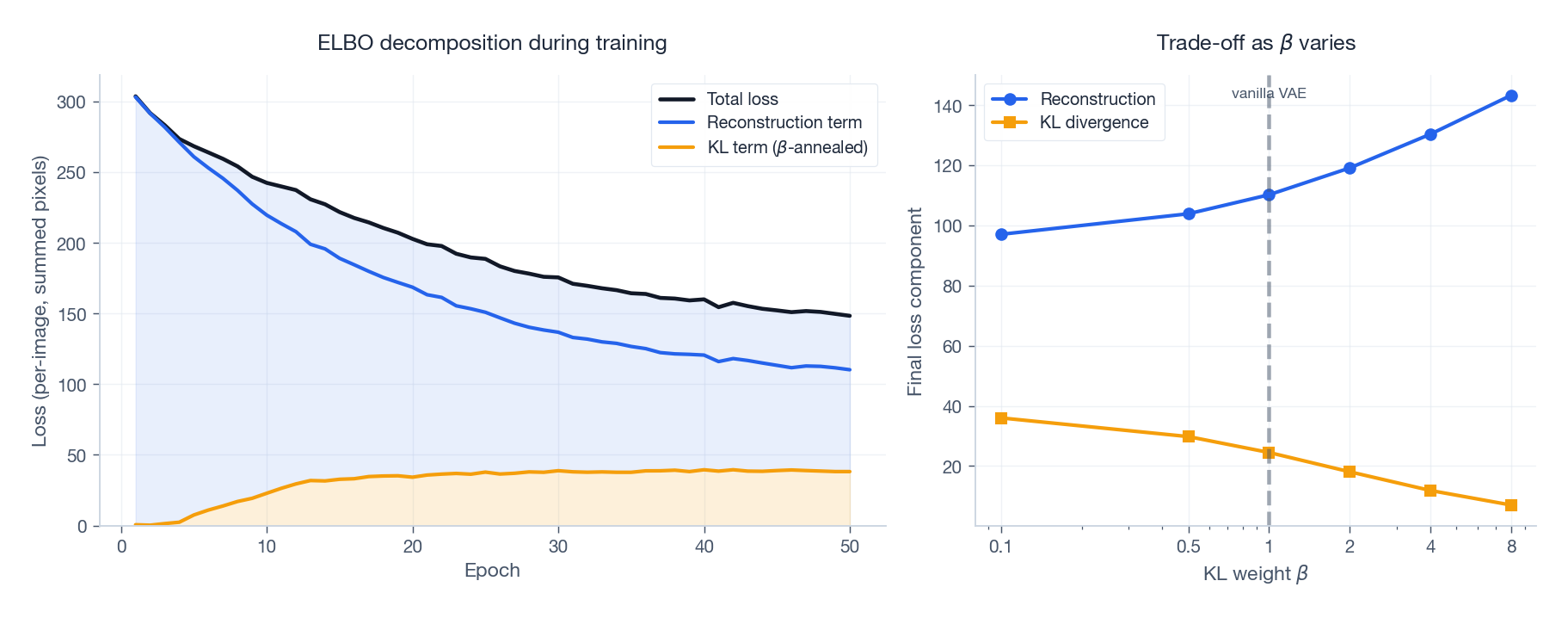
A healthy run shows reconstruction dropping monotonically and KL stabilizing at a non-trivial value (a few nats per active dimension). If KL flatlines at zero you are in posterior collapse; if it explodes, your reconstruction term is being ignored.
Visualize the latent space#
For a 2-D latent (or after PCA/t-SNE), plot $\mu(x)$ colored by class. You should see overlapping but distinguishable clusters that roughly cover the prior.
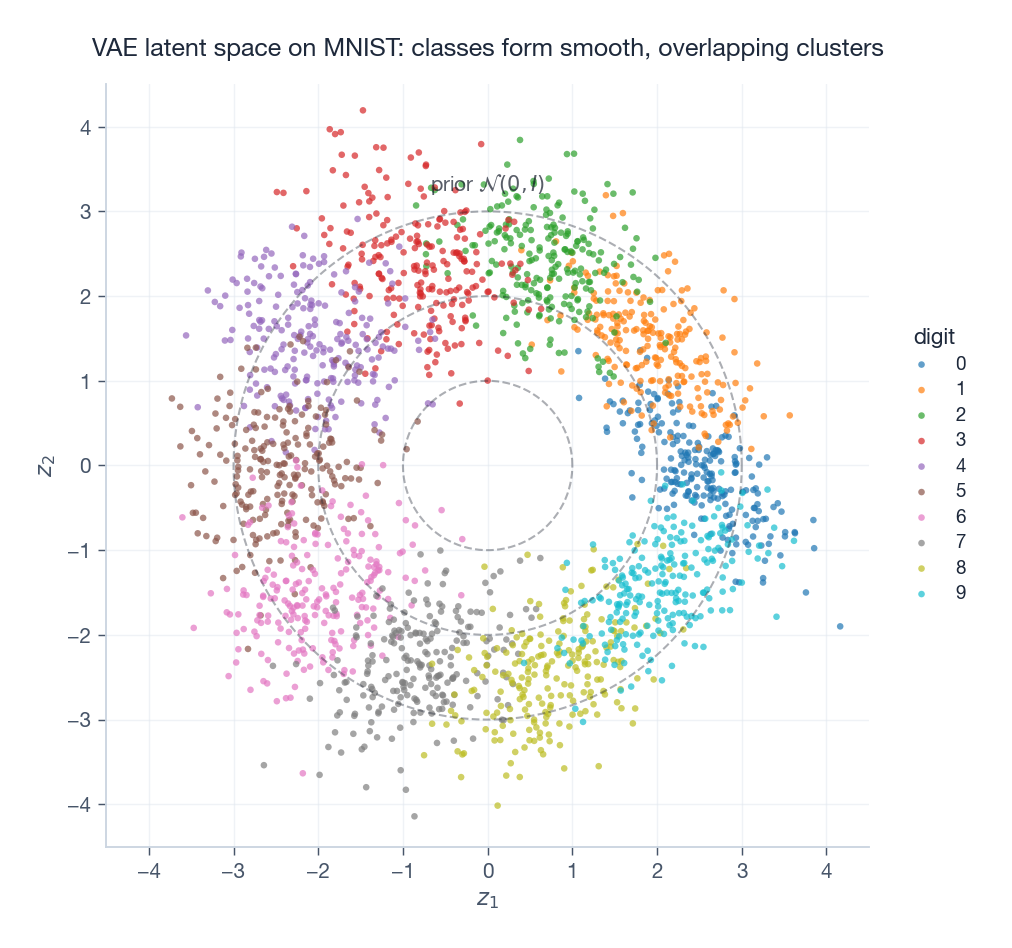
| |
Sample, and walk between samples#
Two utilities you will reach for constantly:
| |
A clean interpolation is the single most convincing visual proof that your VAE is actually working.

VAE versus the alternatives#
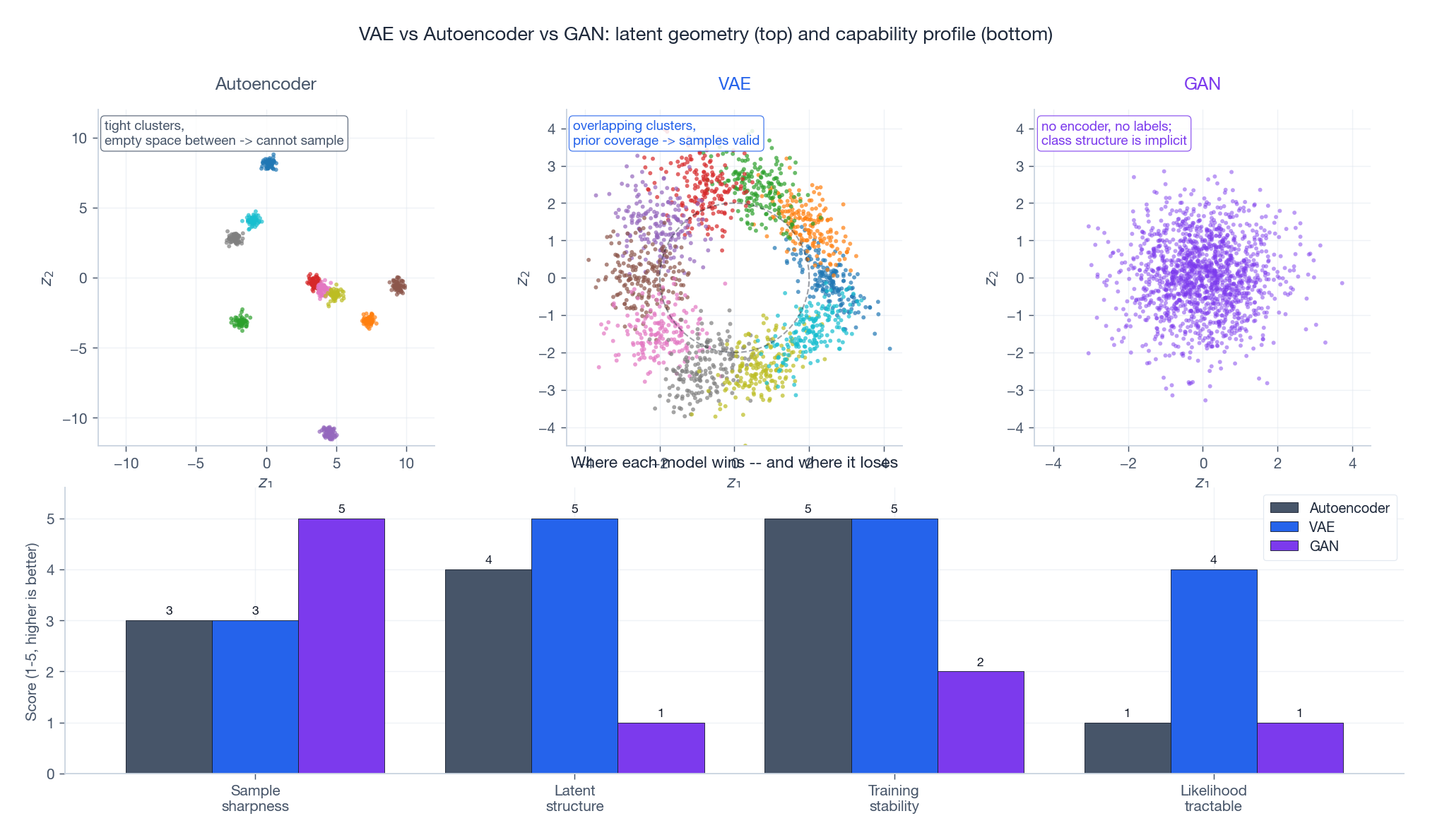
| Model | Latent space | Training | Sample quality | Interpretability |
|---|---|---|---|---|
| VAE | Explicit, smooth | Stable (ELBO) | Decent, slightly blurry | High (often disentangled) |
| GAN | Implicit | Unstable (adversarial) | Sharp, photorealistic | Low (mode collapse common) |
| Diffusion | Implicit (per step) | Stable (denoising) | State of the art | Medium (iterative sampling) |
| Autoregressive | None | Stable (likelihood) | High but slow | Low (sequential generation) |
Reach for a VAE when you need an explicit latent representation for downstream tasks, want stable training without adversarial dynamics, or care about disentanglement.
Pick something else when photorealism is the goal (use a GAN or diffusion model), or you only need likelihoods on sequences (use an autoregressive model).
Summary: VAE in five steps#
- Encoder outputs $\mu_\phi(x)$ and $\log \sigma^2_\phi(x)$ , not a single deterministic code.
- Reparameterize: $z = \mu + \sigma \odot \epsilon$ with $\epsilon \sim \mathcal{N}(0, I)$ — gradients now flow.
- Decoder reconstructs $\hat{x}$ from $z$ .
- Loss = negative ELBO: reconstruction + $\beta$ · KL.
- Generate: $z \sim \mathcal{N}(0, I) \to$ decoder $\to \hat{x}$ .
Hyperparameters that matter most: latent dimension (start at 20), $\beta$ (default 1.0, raise for disentanglement), learning rate (1e-3 with Adam, with KL annealing over 10–20 epochs and grad clipping at 1.0).
Pitfalls to expect: posterior collapse (use KL annealing or free bits), blurry samples (raise latent dim or add perceptual loss), NaN losses (clamp logvar, clip grads).
References#
- Kingma, D.P. & Welling, M. (2013). Auto-Encoding Variational Bayes . The original VAE paper.
- Higgins, I. et al. (2017). beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework .
- Doersch, C. (2016). Tutorial on Variational Autoencoders . Excellent step-by-step derivation.
- Sohn, K., Lee, H. & Yan, X. (2015). Learning Structured Output Representation using Deep Conditional Generative Models . The CVAE paper.
- Vahdat, A. & Kautz, J. (2020). NVAE: A Deep Hierarchical Variational Autoencoder . Hierarchical VAE that competes with GANs on sample quality.
- Kingma, D.P. & Welling, M. (2019). An Introduction to Variational Autoencoders . Comprehensive monograph.