
System Design (5): Message Queues and Event-Driven Architecture
A practical guide to message queues and event-driven systems — covering Kafka and RabbitMQ architectures, delivery guarantees, event sourcing, CQRS, dead letter queues, backpressure, and a complete order processing pipeline design.
In 2011, LinkedIn’s engineering team was struggling with a problem that many growing companies face. Their monolithic application had become a web of tightly-coupled services, each making synchronous calls to half a dozen others. When any single service went down, cascading failures rippled through the entire system. Deploying a change to one service required coordinating with every team whose service it called.
Their solution was Apache Kafka — a distributed event log that decoupled producers from consumers. Instead of Service A calling Service B directly, Service A writes an event to Kafka, and Service B reads it when it is ready. If Service B is down, the events wait. If Service B is slow, it processes at its own pace. The producer does not need to know or care about the consumer.
That architectural pattern — decoupling through asynchronous messaging — is one of the most powerful tools in system design.
Synchronous vs Asynchronous Communication#
In a synchronous system, the caller waits for the callee to respond before proceeding. This is simple, intuitive, and works perfectly for many use cases. But it creates tight coupling.
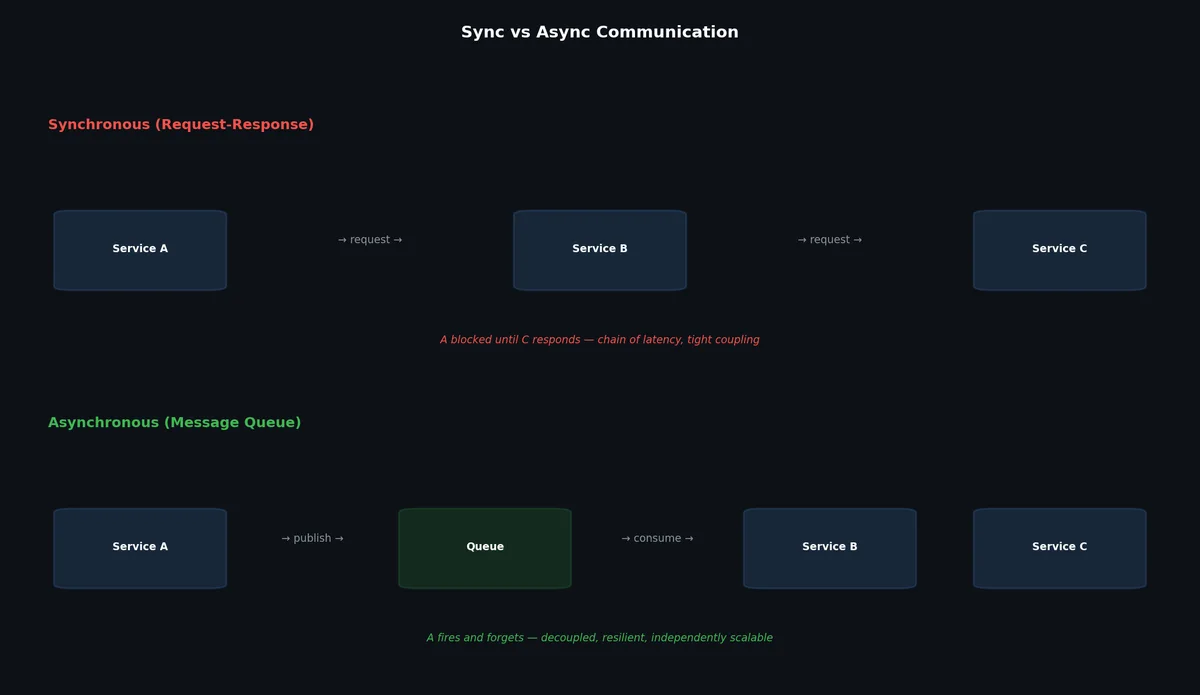
| |
In an asynchronous system, the caller sends a message and moves on. The callee processes the message independently.
| |
When to Use Async#
Use asynchronous communication when:
- The downstream operation is slow (payment processing, email sending)
- The downstream service is unreliable (third-party APIs)
- You need to fan out to multiple consumers
- The operation is not needed for the user’s immediate response
- You need to absorb traffic spikes
Stay synchronous when:
- The user needs an immediate result (login, search)
- The operation must be transactional (debit account, check authorization)
- Latency is already low and complexity is not justified
- You have fewer than 3-4 services (the overhead is not worth it)
Message Queue Fundamentals#
Every message queue system has these core components:
Producer: Application that sends messages to the queue.
Consumer: Application that reads and processes messages from the queue.
Broker: The server that stores and routes messages. May be a single server or a cluster.
Topic/Queue: A named channel for messages. Producers write to a topic; consumers read from a topic.
Partition: A subdivision of a topic for parallelism. Each partition is an ordered, immutable sequence of messages.
Consumer Group: A set of consumers that cooperatively consume a topic. Each partition is assigned to exactly one consumer within a group, enabling parallel processing.
Offset: The position of a consumer within a partition. Tracks which messages have been processed.
Apache Kafka#
Kafka is a distributed event streaming platform designed for high throughput, durability, and scalability. It models messages as an append-only log rather than a traditional queue.

Architecture#
A Kafka cluster consists of:
Brokers: Server instances that store data and serve client requests. A production cluster typically has 3-12+ brokers.
Topics: Categories for organizing messages. A topic is divided into partitions.
Partitions: The unit of parallelism. Each partition is an ordered, append-only log stored on a single broker (with replicas on other brokers).
Replication: Each partition has a configurable number of replicas. One replica is the leader (handles reads and writes); the others are followers (replicate from the leader).
ZooKeeper/KRaft: Manages cluster metadata, broker coordination, and leader election. Kafka is migrating from ZooKeeper to KRaft (built-in consensus) as of Kafka 3.x.
How Kafka Stores Data#
Kafka partitions are stored as a sequence of segment files on disk. Each segment is a file containing messages in order. New messages are appended to the active segment. Old segments are retained based on a time or size policy and eventually deleted or compacted.
| |
Kafka Producer Configuration#
| |
The key parameter is important. Kafka hashes the key to determine the partition. Messages with the same key always go to the same partition, guaranteeing ordering for that key. This is critical for use cases like “all events for a given user must be processed in order.”
Kafka Consumer Configuration#
| |
Kafka Retention#
Unlike traditional queues where messages are deleted after consumption, Kafka retains messages based on time or size:
| |
Log compaction is particularly useful for maintaining a changelog. Kafka keeps the latest value for each key and discards older values. This lets consumers rebuild state by reading the entire compacted topic.
RabbitMQ#

RabbitMQ is a traditional message broker based on the AMQP protocol. It focuses on flexible routing, acknowledgment-based delivery, and message-level features.
Architecture#
RabbitMQ uses a different model than Kafka:
Exchange: Receives messages from producers and routes them to queues based on routing rules. There are four exchange types.
Queue: Stores messages until a consumer retrieves them. Messages are deleted after acknowledgment.
Binding: A rule that connects an exchange to a queue, optionally with a routing key pattern.
Exchange Types#
Direct Exchange: Routes messages to queues where the routing key exactly matches the binding key.
| |
Topic Exchange: Routes messages based on wildcard pattern matching on the routing key.
| |
Fanout Exchange: Routes messages to all bound queues regardless of routing key. Used for broadcast.
| |
Headers Exchange: Routes based on message header attributes instead of routing key.
RabbitMQ Consumer with Acknowledgment#
| |
Kafka vs RabbitMQ#
| Feature | Apache Kafka | RabbitMQ |
|---|---|---|
| Model | Distributed log (append-only) | Message broker (queue-based) |
| Message retention | Retained after consumption (time/size-based) | Deleted after acknowledgment |
| Ordering | Per-partition ordering guaranteed | Per-queue ordering guaranteed |
| Throughput | Very high (millions/sec per cluster) | High (tens of thousands/sec per node) |
| Routing flexibility | Topic + partition key | Exchanges, routing keys, patterns |
| Consumer model | Pull-based (consumer polls) | Push-based (broker delivers) |
| Replay | Yes (re-read from any offset) | No (messages deleted after ack) |
| Scaling | Add partitions (horizontal) | Add queues + consumers |
| Protocol | Custom binary protocol | AMQP 0-9-1 |
| Best for | Event streaming, logs, high-volume pipelines | Task queues, routing, request-reply |
| Worst for | Complex routing logic | Event replay, ultra-high throughput |
Choose Kafka when you need event replay, high throughput, consumer groups, and stream processing. Think audit logs, clickstream data, change data capture, and real-time analytics.
Choose RabbitMQ when you need complex routing, message-level acknowledgment, priority queues, and traditional task distribution. Think email sending, image processing, order fulfillment, and background jobs.
Delivery Guarantees#
Message delivery semantics are a fundamental design decision.

At-Most-Once#
The message is delivered zero or one time. If the consumer crashes before processing, the message is lost.
Implementation: Auto-commit offsets (Kafka) or auto-acknowledge (RabbitMQ) before processing.
| |
Use when: Message loss is acceptable (metrics, logs where approximation is fine).
At-Least-Once#
The message is delivered one or more times. If the consumer crashes after processing but before committing, the message is redelivered.
Implementation: Commit offset / acknowledge only after successful processing.
| |
Use when: You can handle duplicates (or make processing idempotent). This is the most common choice.
Exactly-Once#
The message is delivered and processed exactly one time. This is the hardest to achieve and usually involves transactions.
Kafka supports exactly-once semantics within its ecosystem (producer transactions + consumer read_committed isolation). But true end-to-end exactly-once requires the consumer’s side effects (database writes, API calls) to be part of the same transaction — which is often impractical.
In practice, most systems use at-least-once delivery with idempotent processing. If processing the same message twice produces the same result, duplicates are harmless.
| |
Event Sourcing#
Event sourcing is an architectural pattern where state changes are stored as a sequence of events rather than as the current state. The current state is derived by replaying all events.

Traditional vs Event-Sourced#
| |
Benefits of Event Sourcing#
- Complete audit trail: Every change is recorded and immutable
- Temporal queries: What was the account balance at 3 PM yesterday?
- Event replay: Rebuild state from scratch, or build new projections from historical events
- Debugging: Reproduce any bug by replaying events up to the point of failure
Drawbacks#
- Complexity: More code, more infrastructure, more concepts to understand
- Storage: Event logs grow forever (though compaction helps)
- Eventual consistency: Read models are asynchronous projections, so they lag behind writes
- Schema evolution: Changing event formats requires versioning and migration strategies
CQRS#
Command Query Responsibility Segregation separates the write model (commands) from the read model (queries). This pairs naturally with event sourcing.

| |
The write model stores events in a durable event store (Kafka, EventStoreDB). The read model subscribes to events and maintains denormalized views optimized for queries. Different read models can be built for different query patterns — a search index, a reporting database, and a real-time dashboard can all consume the same event stream.
CQRS Trade-offs#
Benefits: Independent scaling of reads and writes, optimized query models, natural fit with event sourcing.
Costs: Eventual consistency between write and read models, duplicate data, operational complexity of maintaining multiple databases.
Dead Letter Queues#

When a message cannot be processed after repeated attempts, it should not block the queue forever. A dead letter queue (DLQ) is a separate queue where failed messages are sent for investigation.
| |
| |
Backpressure#
Backpressure occurs when consumers cannot keep up with producers. Without handling, queues grow unbounded, memory is exhausted, and the system crashes.
Backpressure Strategies#
Producer throttling: The producer slows down when the queue depth exceeds a threshold.
| |
Consumer scaling: Add more consumer instances when lag increases. In Kafka, you can add consumers up to the number of partitions.
Message dropping: Drop low-priority messages when the system is overwhelmed. Use a priority queue and drop the lowest-priority messages first.
Bounded queues: Set a maximum queue size. When full, either block the producer (synchronous backpressure) or reject new messages (shedding load).
Real Example: Order Processing Pipeline#
Here is a complete event-driven order processing system.
Architecture#
The system processes an order through these stages:
- Order Service: Accepts the order from the user, validates it, publishes
OrderCreatedevent - Payment Service: Consumes
OrderCreated, charges the customer, publishesPaymentCompletedorPaymentFailed - Inventory Service: Consumes
PaymentCompleted, reserves stock, publishesInventoryReservedorOutOfStock - Notification Service: Consumes all events, sends emails/push notifications to the user
- Analytics Service: Consumes all events, updates dashboards and reports
Data flow:
| |
Implementation#
| |
| |
Handling Failures#
The pipeline handles failures at each stage:
- Payment fails:
PaymentFailedevent triggers notification to user. Order status set to “payment_failed”. No inventory reserved. - Inventory unavailable:
OutOfStockevent triggers payment refund (compensating transaction) and user notification. - Consumer crashes: At-least-once delivery ensures the message is reprocessed. Idempotency checks prevent duplicate charging.
- Kafka broker failure: Replication factor of 3 ensures no data loss. Clients reconnect to surviving brokers.
Monitoring#
| |
Consumer lag is the most important metric. If lag is increasing, consumers are falling behind. If lag is stable, the system is keeping up. If lag is decreasing, consumers are catching up after a spike.
What’s Next#
Message queues decouple individual services, but how do you decide what constitutes a service in the first place? The next article tackles the monolith-vs-microservices debate honestly — when microservices help, when they hurt, and how to draw service boundaries using domain-driven design.
System Design 8 parts
- 01 System Design (1): Thinking in Systems — Load, Latency, and the Art of Estimation
- 02 System Design (2): DNS, CDN, and Load Balancing — The First Three Hops
- 03 System Design (3): API Design — REST, gRPC, GraphQL, and Choosing Wisely
- 04 System Design (4): Caching — Where to Cache, What to Evict, and When Caching Hurts
- 05 System Design (5): Message Queues and Event-Driven Architecture you are here
- 06 System Design (6): Microservices vs Monoliths — The Honest Tradeoff
- 07 System Design (7): Data Pipelines — Batch, Stream, and the Lambda Architecture
- 08 System Design (8): Case Studies — URL Shortener, Chat System, News Feed


