
阿里云百炼(一):平台概览与第一个请求
一个工程师视角的阿里云百炼(DashScope)导览——模型目录里真正能用的那几个、两种 endpoint 形态、异步任务模式,外加一个 入门示例 请求把后续文章的基础铺好。
只要你的产品面向中文用户,迟早都得调用百炼(Bailian)的模型,Qwen-Max 是目前实现 GPT-4 级别中文理解能力且性价比最高的选择;万相(Wanxiang)是市面上唯一支持开具中文发票、且已在生产环境稳定落地的文本生成视频(text-to-video)API;而 Qwen-TTS-Flash 则是当前唯一能自然合成粤语和四川话、不带机械播报腔的语音合成(TTS)模型。在 AI 营销平台跑了一整年的生产流量后,我真心希望入职第一天就能拿到这份指南。
本文作为系列开篇,先帮你摸清全局:百炼到底是什么、你会接触到哪些核心模型家族、两种 API 接口风格有何区别,并分别给出各自的“Hello World”示例。这样后续文章就无需反复解释这些基础概念了。

百炼是什么,DashScope 又是什么?#
命名确实容易让人困惑,因为阿里中途统一了品牌:官方文档中,“DashScope”是从 API 视角编写的,而“百炼”则是从控制台视角出发的,但它们本质上是同一个产品,只是叫法不同。

你经常会在文档里同时看到这两个名字,甚至同一段落中交替出现。简单理解:“百炼”指控制台操作,“DashScope”指 API 调用。比如,当有人说“部署一个百炼应用”,指的是在控制台完成配置;而提到“DashScope 报错”,通常是指 API 返回了非 200 的状态码。
你真正需要关注的模型清单#
百炼平台上托管了上百个模型,但经过一年的生产实践,我实际付费使用的只有以下几类:
| 系列 | 代表模型 ID | 用途 |
|---|---|---|
| Qwen LLM (文本) | qwen-max, qwen-plus, qwen-turbo, qwen3-max, qwen3-coder-plus | 聊天、推理、工具调用、代码生成 |
| Qwen-Omni (多模态) | qwen3-omni-flash, qwen3.5-omni-plus | 视频 / 音频 / 图像理解 |
| Qwen-VL (视觉) | qwen3-vl-plus | 仅图像理解(比 Omni 更便宜) |
| Wanxiang (视频) | wan2.5-t2v-plus, wan2.5-i2v-plus | 文本转视频、图像转视频 |
| Qwen-TTS | qwen3-tts-flash | 语音合成,支持 40+ 种音色 |
| Embeddings | text-embedding-v3, text-embedding-v4 | 向量检索 |
表中未列出的模型,基本属于三类之一:已弃用(deprecated)、仅是轻量封装的变体,或是处于研究预览阶段的功能。只要你坚持使用上表中的模型,就能避免因模型在上线六周后突然终止支持(EOL)而措手不及。
一句话讲清计费模式#
LLM 按 Token 计费(输入与输出分开计价,输出价格通常是输入的 2–4 倍),TTS 按音频秒数计费,万相按视频秒数计费,Embeddings 则按调用次数计费。每个模型都有免费额度,通常是 100 万 Token 或 100 次生成,且在新模型发布时会重置。这意味着,只要你能接受模型版本自动更新,几乎任何功能都可以免费用于原型验证。但生产流量务必使用独立的 API Key 并配置预算告警;我就曾因调试循环未及时关闭、整夜持续运行,收到过一笔四位数的账单。
API Key:千万别提交到代码库#
请在控制台左侧导航栏的 API-KEY 页面获取密钥。系统会提供一个默认工作空间 Key,以及按工作空间分配的独立 Key。对于任何生产项目,务必创建工作空间专属 Key,这样轮换密钥时不会影响开发环境。然后:
| |
本系列所有代码片段均通过 os.environ['DASHSCOPE_API_KEY'] 读取密钥。切勿硬编码密钥,切勿提交 .env 文件,生产环境中请将密钥交由 Secrets Manager 管理。DashScope 团队确实会撤销已泄露的密钥,但通常要等到密钥出现在公开爬虫数据中才采取行动,那时损失往往已经造成。
两种接口:OpenAI 兼容 vs DashScope 原生#
这是本文最关键的信息:根据 Qwen API 文档,所有百炼的文本和多模态模型都可通过两种不同的 HTTP 接口访问。

OpenAI 兼容接口#
Base URL:https://dashscope.aliyuncs.com/compatible-mode/v1(中国大陆),或 https://dashscope-intl.aliyuncs.com/compatible-mode/v1(新加坡)。
该接口完全兼容 OpenAI 的通信协议。只需将官方 openai Python SDK 指向此地址,你现有的 95% OpenAI 代码几乎无需修改即可运行。这也是我的默认选择。
| |
DashScope 原生接口#
Base URL:https://dashscope.aliyuncs.com/api/v1/...,不同模态对应不同路径(如 /services/aigc/text-generation/generation、/services/aigc/multimodal-generation/generation、/services/aigc/text2video/...)。
这是阿里自研的通信协议:请求结构不同,字段命名也不同(例如使用 input.messages 而非 messages,并包含独立的 parameters 块等)。你需要使用 dashscope SDK 或直接发送原始 HTTP 请求。
| |
何时使用哪种接口?#
这些经验都是踩坑换来的:
- OpenAI 兼容接口:适用于普通聊天、函数调用、JSON 模式、流式输出等场景。只需修改一行代码,就能轻松与 GPT-4 进行 A/B 测试。
- DashScope 原生接口:万相视频生成必须使用,Qwen-TTS 必须使用,Qwen-Omni 多模态推荐使用(兼容层会丢失部分视频参数),异步任务模式必须使用,若需使用尚未回迁至兼容层的最新特性也必须使用。
一个常见误区是:看到“OpenAI 兼容”就以为所有模型都支持。事实并非如此。例如,wan2.5-t2v-plus 和 qwen3-tts-flash 仅支持原生接口。第 4 和第 5 篇文章会重点强调这一点。
Tip:当你遇到 400 错误,提示类似
parameter X is not supported时,第一步应检查是否通过兼容接口调用了仅支持原生接口的模型。我调试过的“百炼坏了”工单中,约有一半都是这个问题。
三个贯穿始终的核心概念#
model_id#
每次调用都通过一个字符串标识模型,例如 qwen-plus 或 wan2.5-t2v-plus。模型 ID 不包含版本号,阿里会在同一 ID 下更新模型权重,并在变更日志(changelog)中说明。如果你需要固定版本,请使用模型卡片中列出的带日期别名(如 qwen-plus-2025-09-11)。对于任何面向客户的功能,务必使用带日期的模型别名;我曾因未固定版本,导致模型更新后输出风格一夜之间发生突变。
异步任务#
任何耗时超过约 30 秒的操作(如视频生成、大批量 embedding、长文本 TTS)都采用异步模式。其标准流程如下:
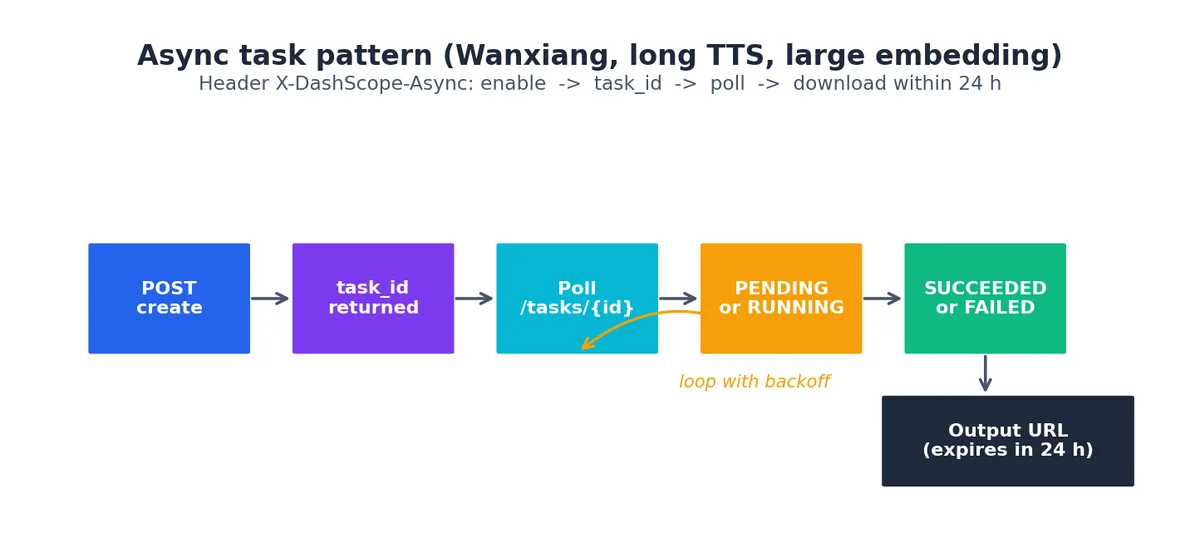
- 向创建接口发送 POST 请求,并在 Header 中添加
X-DashScope-Async: enable; - 获取返回的
task_id; - 轮询
GET /api/v1/tasks/{task_id},直到状态变为SUCCEEDED或FAILED; - 在 24 小时内下载输出结果(URL 会过期)。
第 4 篇文章将提供一个带退避策略的完整轮询实现。
流式输出#
LLM 和 Qwen-Omni 均支持 SSE 流式输出。对于启用了 enable_thinking=True 的 Qwen3 模型,流式输出是强制要求,非流式调用会被拒绝。而对于 Qwen-Omni,流式输出同样是无条件强制的(第 3 篇将详细说明)。建议尽早熟悉 stream=True 参数,你会发现它的使用频率远超预期。
一个完整的第一个请求#

将以下内容保存为 hello_bailian.py 并运行。如果成功打印出一句话,说明你的账户、密钥和网络配置均正常,可以继续阅读第 2 篇了。
| |
如果你想验证原生接口是否也能正常工作,只需替换为前文提到的 dashscope 示例代码。两种方式都应成功执行,且计费完全一致。
控制台 vs SDK vs OpenAI 兼容——何时使用哪种方式?#
实际上,你有三种方式可以调用百炼,而选择的重要性远超文档所描述。我在一个项目中混用这三种方式长达两个月,才真正理清各自的适用边界。
位于 bailian.console.aliyun.com 的 控制台 仅适用于两类操作:资源管理(创建工作空间、API Key、RAM 权限、应用)和问题诊断(查看单次请求日志,排查模型为何返回异常结果)。它不应用于生产环境的运行时调用。控制台内置的 Playground 虽便于快速迭代提示词,但它会忽略部分 SDK 调用所需的参数,因此在 Playground 中有效的提示词,上线后仍可能表现异常。我仅将 Playground 视为“模型可达”的验证工具,而非“提示词正确”的保证。
DashScope 原生 SDK(pip install dashscope)适用于所有需要阿里特有功能的场景:异步任务、视频/TTS/万相生成、最新模型参数、跨工作空间计费所需的 workspace-id Header,或用于调试的 X-DashScope-DataInspection Header。原生 SDK 暴露了兼容层会丢弃的 parameters 字段(如 incremental_output、图像生成的 seed、联网模型的 enable_search 等)。它也是批量推理和 RemoteService 模型部署的唯一途径。
OpenAI 兼容接口 则适用于已有 OpenAI SDK 代码、且希望仅通过修改一行代码就能在百炼与 OpenAI 之间进行 A/B 测试的场景。兼容层本质上是一个轻量翻译器:它支持 chat.completions.create、embeddings.create,兼容 tools / tool_choice / response_format / stream,并通过 extra_body 传递少量 Qwen 特有参数(如 enable_thinking、enable_search)。但它不支持万相、TTS 或任何异步模式。若需这些功能,必须在该次调用中切换至原生 SDK,你完全可以在同一应用中同时使用两种客户端。
经过一年实践,我的经验法则是:
- 新项目,以 LLM 为主,追求供应商无关性 → 使用 OpenAI SDK 指向兼容接口;
- 混合场景(LLM + Omni + 视频 + TTS) → 除聊天对话路径保留兼容接口以保持消息逻辑可移植外,其余全部使用原生 SDK;
- 生产环境调试 → 仅使用原生 SDK,因其错误信息更丰富(包含
code+message+request_id,而兼容接口仅返回 OpenAI 格式的错误)。
区域路由与 RAM 权限:这些细节你必须掌握#
百炼主要涉及两个区域:北京和杭州(另有一个新加坡“国际”节点,功能上相当于第三个区域)。默认域名 dashscope.aliyuncs.com 会解析到你账号最初开通时所在的区域。这正是大量“昨天还能用,今天就报错”问题的根本原因。
具体陷阱在于:部分模型是区域绑定的。例如,wan2.5-t2v-plus 仅部署在北京区域,qwen3-omni-flash 支持多区域,而 text-embedding-v4 则先在杭州上线,六周后才扩展至北京。如果你的账号被路由到模型尚未部署的区域,会收到一个看似合理的 404 错误,提示 Model not exist。此时不应反复调试提示词,而应首先排查区域路由问题。
解决方法有两种:
| |
关于 RAM 权限,关键点在于:API Key 绑定在工作空间(workspace)上,而工作空间隶属于主账号。RAM 子账号不会自动继承主账号的百炼工作空间权限。你必须显式授权:要么直接授予 AliyunBailianFullAccess(简单但权限过大),要么编写自定义策略,将其作用域限定到具体工作空间的 ARN。策略资源格式为 acs:bailian:*:*:workspace/<workspace_id>,注意,workspace_id 位于控制台 URL 地址栏中,而非某个明显的“详情”页面。那些能登录控制台但 API 调用返回 Forbidden.RAM 的用户,几乎都是缺少这一策略。
在生产环境中,我的做法是:为每个环境(dev / staging / prod)单独创建一个 RAM 子账号,各自对应一个工作空间,并配备一个由 Secrets Store 管理的轮转 API Key。这样,跨环境的数据泄露就只能通过显式的策略变更实现,而非意外事故。
配额真相:没人会提前告诉你的现实#
营销页面宣称“高并发、低延迟”,但实际数字如何?根据我最近一次配额审计的结果,免费账户的默认限制其实非常低。主要关注三个指标:
- RPM(Requests Per Minute):任意 60 秒窗口内允许的最大请求数;
- TPM(Tokens Per Minute):计入的输入与输出 Token 总量;
- TPD(Tokens Per Day):每日 Token 上限,于北京时间 00:00 重置。
以下是我实测的新建工作空间默认值(未申请配额提升):
| 模型 | RPM | TPM | 并发任务(异步) |
|---|---|---|---|
qwen-turbo | 500 | 500K | n/a |
qwen-plus | 200 | 200K | n/a |
qwen-max | 60 | 100K | n/a |
qwen3-omni-flash | 60 | 100K | n/a |
wan2.5-t2v-plus | n/a | n/a | 5 |
qwen3-tts-flash | 100 | 50K | n/a |
这些数值并非合同承诺,阿里会悄然调整。关键在于:免费档配额足以支撑开发和百级日活的原型验证,但一旦真实流量涌入(比如一条广告推文带来访问高峰),系统会立即限流。此时你会收到 Throttling.RateQuota 错误,HTTP 状态码为 429,你的重试逻辑应将 429 视为“退避后重试”,而非致命错误。
如需提升配额,请前往控制台 API-KEY → 限流配置 提交申请。对于合理请求(如当前限制的 10 倍),通常 24 小时内获批。但若无营收数据就申请将 qwen-max 配额提升 100 倍,大概率会被拒,请附上预估 QPS、平均 prompt 长度及业务背景。我提交过四次申请,仅被拒过一次。
每百万 Token 计价:这才是当前有效的参考#
定价页面每季度都会调整,下表数字未来难免变动,但价格比例相对稳定,足以用于成本规划。截至我上次审计(2026-04),人民币计价(每百万 Token)如下:
| 模型 | 输入 | 输出 | 缓存输入 | 备注 |
|---|---|---|---|---|
qwen-turbo | 0.3 | 0.6 | 0.15 | 分类任务的廉价主力 |
qwen-plus | 0.8 | 2.0 | 0.4 | 日常主力 |
qwen-max | 20 | 60 | 10 | 推理、代码审查 |
qwen3-max | 24 | 96 | 12 | 最新版,比 qwen-max 更贵 |
qwen3-coder-plus | 4 | 16 | 2 | 代码专用,中档价位 |
qwen3-omni-flash | 2.5(文本)/ 12(视觉) | 5 | n/a | 视觉 Token 单独计费 |
text-embedding-v4 | 0.7(每百万 Token) | n/a | n/a | 按调用次数计费 |
有两点必须牢记:
- 输出价格是输入的 2–4 倍。一个循环 3 次的 Function Calling Agent,账单大头往往在助手的输出 Token,而非用户输入。优化成本时,应优先压缩输出,最后再考虑精简系统提示词。
- 缓存输入享受半价优惠。百炼在 2025 年底上线了隐式 prompt 缓存机制,若在约 5 分钟内重复发送相同 prompt 前缀,即可命中缓存。你无需额外操作即可享受该优惠,但只有在日志中查看
usage.cached_tokens字段才能看到节省金额。对于带有长固定系统提示词的 RAG 应用,缓存命中率通常达 60–80%,账单相应大幅下降。
至于万相(按视频秒数)和 Qwen-TTS(按音频秒数),其计价单位是成品资产,而非 Token。一段 720p、5 秒的视频约 1.5 元;60 秒的 TTS 语音约 0.6 元。两者价格足够低廉,真正的瓶颈在于人工审核,而非 API 成本。
下一步#
第 2 篇将深入剖析 Qwen LLM 家族,如何根据延迟与成本选择模型、Function Calling 的最佳实践、JSON 模式的使用技巧,以及那个让我足足调试了四小时的 enable_thinking 参数。第 3 篇将讲解 Qwen-Omni 的强制流式要求,并提供真实的视频理解案例。第 4 篇将完整演示万相视频生成的端到端流程,第 5 篇则聚焦 Qwen-TTS 的多语言语音合成能力。
如果只能读一篇,强烈推荐第 2 篇,那里“文档没写但你必须知道”的干货密度最高。


