
Claude Code 实战(一):安装、三层配置体系,以及 `#` `@` `/init` 三剑客
完成 Claude Code 安装,掌握三层 settings.json 配置机制,并熟练运用三个低调却极其强大的原语:`#` 将内容写入项目记忆文件、`@` 引用本地文件、`/init` 自动生成项目记忆文件 CLAUDE.md。
这是《Claude Code 实战入门》十篇系列指南的第一篇。各篇顺序经过精心设计,前一篇是后一篇的必要前提。学完全部内容,你就能自如使用 90% 用户从未触碰的进阶功能。

安装#
目前官方唯一支持且推荐的安装方式如下:
| |
该脚本会将 claude 可执行文件安装到 ~/.local/bin/ 目录下(Linux / macOS)。请确保该路径已加入你的 PATH 环境变量,然后运行:
| |
登录流程会自动打开浏览器,你只需授权 CLI 即可完成。认证凭据将安全地保存在 ~/.claude/auth.json 中,注意:这里没有 API Key 被写入 ~/.zshrc 或其他 shell 配置文件中。这一点非常关键,因为绝大多数“AI 命令行工具”在此处都存在严重安全隐患。
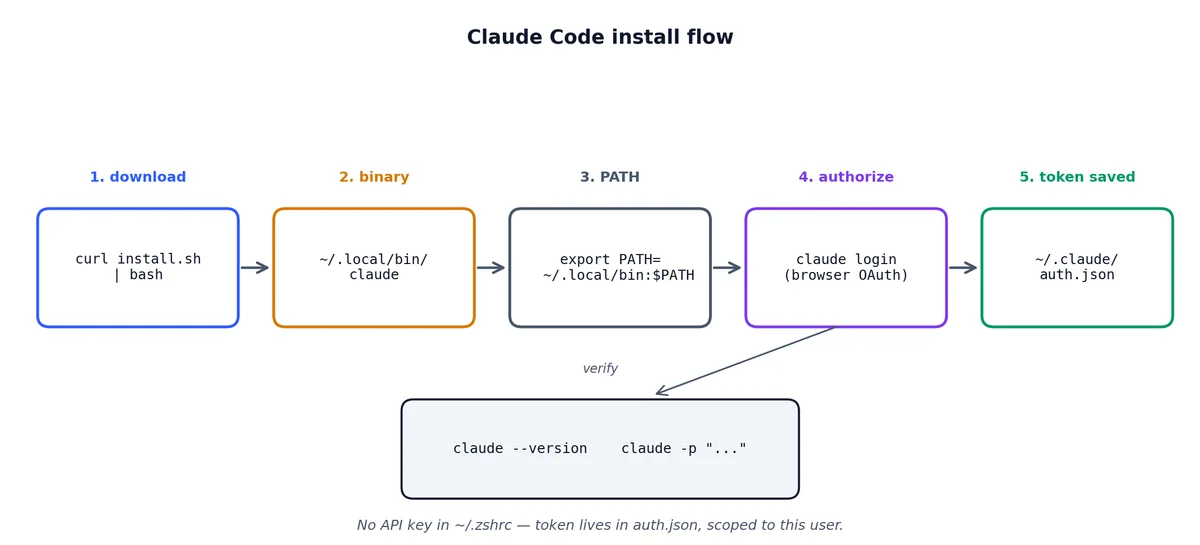
安装排障指南#
安装脚本本身很干净,但真实环境千差万别。以下是我和他人实践中高频遇到的问题及解法。
安装后提示 command not found: claude。
脚本默认将二进制文件放在 ~/.local/bin/。若该路径未加入 PATH,你有两个选择:
| |
在全新 macOS 系统上,~/.local/bin/ 几乎肯定不在你的 PATH 中。可用以下命令验证:
| |
Node.js 版本不兼容。
Claude Code 要求 Node.js ≥ 18。若你使用的是旧版本(Ubuntu LTS 用户常见),二进制文件可能静默失败或抛出难以理解的错误。检查方式:
| |
如需升级,推荐使用 nvm(最平滑):
| |
企业代理问题。
若身处企业代理环境,curl 安装可能静默失败。请先设置代理环境变量:
| |
WSL(Windows 子系统 Linux)特别说明。
在 WSL 中,基于浏览器的登录流程无法自动唤起 Windows 浏览器。CLI 会打印一个授权 URL,手动复制并在 Windows 浏览器中打开完成授权,CLI 将自动接收并保存 Token。整个过程可行,但体验稍欠流畅。
重复安装冲突。
如果你既通过 npm 全局安装过(npm install -g @anthropic/claude-code),又运行了上述安装脚本,则系统中将存在两个 claude 二进制文件,彼此冲突。检查当前生效的是哪一个:
| |
若显示的是 npm 安装路径,请卸载 npm 版本:
| |
运行它#
进入一个真实的项目目录,执行:
| |
你将看到一个交互式提示符。尝试一次简单问答,验证安装是否成功:
| |
Claude 会调用内置工具执行 ls,汇总结果并回复。若此操作成功,说明安装已完成。
你也可以在脚本中非交互式地调用 Claude Code:
| |
-p 标志(print mode)会跳过交互式循环,非常适合集成到自动化脚本、CI / CD 流水线,或处理一次性快速提问,无需开启完整会话。
三层配置体系#

这是绝大多数用户从未细读但至关重要的部分。Claude Code 会从三个位置合并加载配置,优先级由低到高依次为:
| 层级 | 路径 | 是否提交至 Git? | 适用场景 |
|---|---|---|---|
| 机器层(Machine) | ~/.claude/settings.json | 否 | 你的个人全局偏好(如默认模型、编辑器命令) |
| 项目层(Project) | <repo>/.claude/settings.json | 是 | 团队共享的项目规范(如统一使用的 linter、测试命令) |
| 本地层(Local) | <repo>/.claude/settings.local.json | 否(已 .gitignore) | 你个人针对当前项目的私有覆盖项(如 staging 环境的私有 API Key) |
为何需要三层而非两层?因为不同配置项的归属逻辑天然不同:有些是个人且全局的(如你偏爱的模型、默认编辑器),有些是团队且共享的(如项目约定的测试命令、代码格式化规则),还有一些是个人但限定于某项目的(如你自己的 staging 数据库密码)。
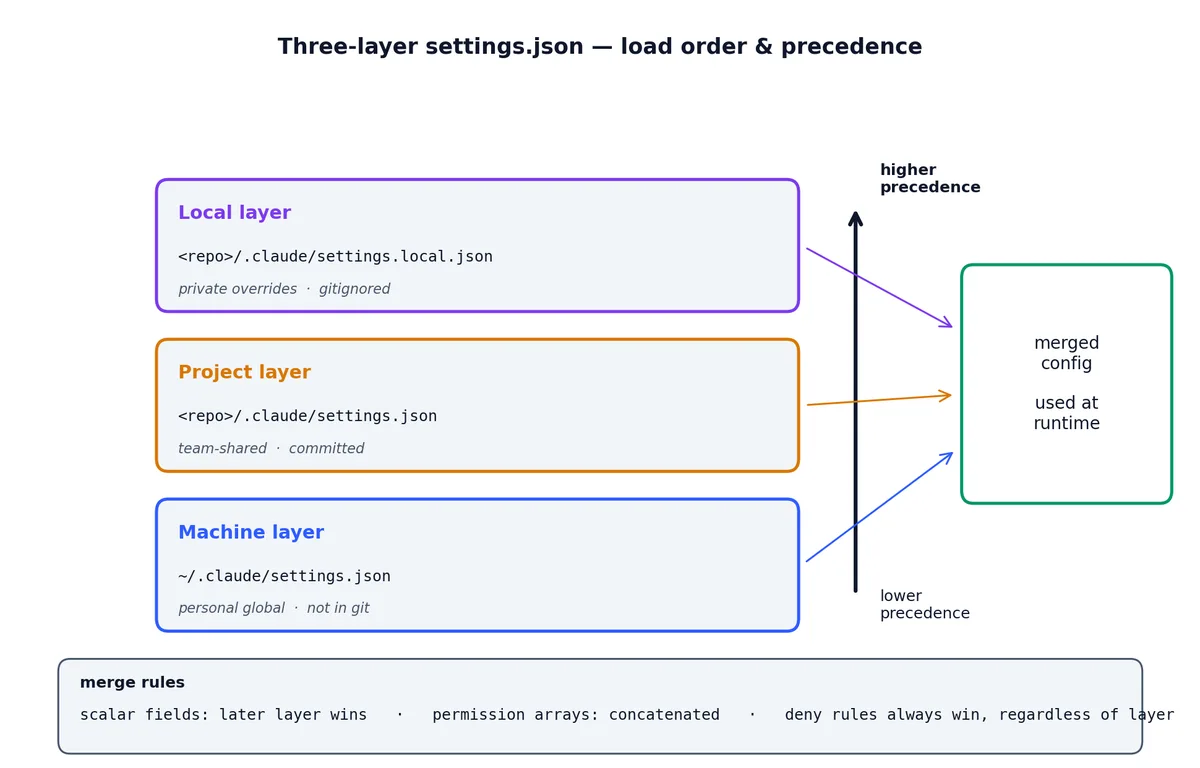
合并规则详解#
配置采用深度合并(deep merge),后加载的层级覆盖前一层级的同名字段。例如:
- 若机器层设
"model": "claude-opus-4-7",而项目层未定义model字段,则最终使用 Opus; - 若项目层明确设
"model": "claude-sonnet-4-7",则项目层胜出; - 若本地层再覆盖为
"model": "claude-haiku-4-7",则最终生效的是 Haiku。
对于 permissions 对象中的数组(如 allow 列表),各层内容合并叠加。例如:项目层允许 Bash(npm test),机器层允许 Bash(docker compose up),则两者均被允许。
但 deny 规则永远具有最高优先级,无论其定义在哪一层,都会无条件屏蔽对应操作。

机器层配置 —— 你的全局默认值#
即 ~/.claude/settings.json,对所有项目生效。务必保持极简,只放入你真正希望处处生效的设置:
| |
这些均为只读命令,我绝不希望每次 Claude 执行 git status 前都弹出确认框,这毫无安全价值,只会打断我的思维流。将所有只读操作放在这里,从此彻底告别打扰。
切勿放入此处的内容:任何会修改文件、运行测试、或执行项目特有命令的权限。这些必须下沉到项目层。
项目层配置 —— 团队共识与规范#
即 <repo>/.claude/settings.json,必须提交至 Git,所有团队成员自动继承。
以一个 Next.js 项目为例:
| |
拒绝列表(deny)与允许列表(allow)同等重要。在 Claude 会话中执行 npm publish 将是灾难性的;让 AI 自主执行 prisma migrate deploy 操作生产数据库更是绝对禁止的。务必显式声明哪些操作是“禁区”。
更高级的项目配置示例(含环境变量与钩子):
| |
钩子(Hooks)允许你在 Claude 调用特定工具前或后执行 Shell 命令。PreToolUse 在工具执行前触发,PostToolUse 在执行后触发。可用于日志记录、通知提醒或前置校验。
本地层配置 —— 你的私有覆盖项#
即 <repo>/.claude/settings.local.json,必须被 .gitignore 忽略(若尚未忽略,请立即添加)。用于存放仅属于你、且与当前项目强相关的私密信息:
| |
此处定义的环境变量,将在该项目内对 Claude 的所有 Shell 命令生效。这是存放 API Keys、数据库连接串等敏感且项目专属信息的唯一正确位置。
常见错误:将敏感值误放至项目层配置并提交到 Git。三层配置体系的设计初衷正是为了让你完全避免这种危险操作。

快速参考:各类配置项该放哪一层?#
| 配置类型 | 机器层 | 项目层 | 本地层 |
|---|---|---|---|
只读命令权限(如 git status) | ✅ | — | — |
写入 / 执行类命令权限(如 npm test) | — | ✅ | — |
危险命令的拒绝规则(如 rm -rf) | — | ✅ | — |
| API Keys、密钥等敏感信息 | — | — | ✅ |
环境变量(如 DATABASE_URL) | — | — | ✅ |
| 项目专用的测试 / 格式化命令 | — | ✅ | — |
| 钩子(Hooks)与自动化逻辑 | — | ✅ | ✅(可覆盖) |
| 模型偏好(如默认用 Sonnet) | ✅ | ⚠️(可选) | ✅(可覆盖) |

# —— 将内容写入上下文(项目记忆)#
在行首输入 #,其后内容将被追加至项目的记忆文件 CLAUDE.md 中,而非作为当前提问发送。例如:
| |
Claude 不会回复。它会自动打开 CLAUDE.md 文件,将该行插入并保存。下次对话开始时,此行指令将自动成为上下文的一部分。
这正是我避免反复解释偏好的方式:“写 Python 时必须使用类型提示。”“提交信息禁用 emoji。”“CI 使用 GitHub Actions,非 GitLab。”每一条都是一个 # 命令,永久生效。
# 的进阶用法#
# 命令远比表面看起来更灵活。以下是我长期实践中总结出的高效模式:
多行内容添加。
输入 # 后可直接键入多行内容,Claude 将在编辑器中为你打开 CLAUDE.md,方便你撰写或润色后再保存:
| |
结构化分节。
随着 CLAUDE.md 内容积累,建议用 Markdown 标题组织:
| |
# 的核心洞见:它不只是笔记工具。CLAUDE.md 中的每一行,都会被注入到每一次后续对话的系统提示词(system prompt)中。这意味着 Claude 会像你亲口下达指令一样严格遵守。例如,“未经明确询问,禁止修改 migrations/ 目录下的任何文件”这一行,将真实改变 Claude 的行为,它是配置,而非文档。
不该放入 CLAUDE.md 的内容:
- 频繁变动的信息(如当前迭代目标、今日待办清单);
- 大段文档或完整 API 规范(会严重挤占每条消息的上下文窗口);
- 应聚焦于指令、规范与结构性知识。若某条内容超过 5 行,就该考虑:它是否更适合放在独立文件中,再用
@引用?
@ —— 引用本地文件#
输入 @,将唤起模糊文件选择器。选中文件后,它将作为工具结果附加到下一条消息中:
| |
文件并非粘贴进你的提问文本,而是以工具调用结果的形式传入。这意味着:
✅ 它计入工具调用配额,不占用你的输入 token;
✅ 你可以轻松附加一个 2000 行的文件,而不会让提问变得难以阅读。
@ 支持通配符与目录引用#
@ 的能力远不止单文件:
| |
当你引用一个目录时,Claude 会先读取其文件列表,并根据你的提问智能筛选相关文件,而非盲目加载全部。这比听起来更聪明:例如,你输入 @src/ 速率限制逻辑实现在哪个文件?,Claude 会主动在该目录下搜索,而无需你事先知道确切文件名。
@ 的实战场景#
Bug 排查。
收到 Bug 报告后,直接附上相关文件与错误日志:
| |
Claude 同时拥有这两份代码上下文,可直接追踪数据流,无需额外搜索。
模块代码审查。
针对特定模块进行深度审查:
| |
快速理解陌生代码。
接手新项目或阅读他人代码时:
| |
@ 符号帮你省去了“请先读这个文件”的来回往返。没有它,你需要先输入 read src/core/scheduler.ts,等待 Claude 调用 Read 工具,再提出问题;有了它,文件已在上下文中就位,你的问题直达核心,每个文件节省一次往返,复杂排查中积少成多。
/init —— 初始化项目记忆文件#
每个新仓库只需运行一次 /init。Claude 将扫描整个代码库,自动生成一份 CLAUDE.md,内容涵盖:
- 项目功能概述
- 使用的语言与框架
- 构建、测试、格式化命令
- 主要目录结构及其职责
- Claude 能识别的规范(如提交信息风格、测试命名习惯等)
随后,你需要亲自编辑这份初稿。目的不是追求 Claude 的初稿完美(它并不完美),而是获得一个30 秒即可上手、而非耗时 30 分钟从零搭建的起点。
生成的 CLAUDE.md 必须提交至 Git。每位团队成员启动 Claude Code 时,都将以此为基础。这是项目共享心智模型(shared mental model)的基石。
/init 生成了什么?你又该编辑什么?#
以下是一个中等规模 Node.js 项目的典型 /init 输出:
| |
这是一个扎实的起点,但过于通用。以下是我必定手动补充的内容:
Claude 无法自动发现的关键信息:
| |
明确禁止事项(最高价值条款):
| |
这些“禁止条款”是 CLAUDE.md 中价值最高的内容。它们将原本只存在于资深工程师脑海中的隐性知识(tribal knowledge),固化为可传承、可执行的规则。
/init 最佳实践#
✅ 在空白上下文中运行 /init。
开启一个全新的 Claude 会话,立即运行 /init 并等待其完成。切勿在长对话中途运行,已有的上下文会干扰生成结果。
✅ 立即编辑,切勿拖延。
首次编辑只需 5 分钟。原始 /init 输出与经你润色后的版本,质量差距巨大:前者准确但平淡,后者则注入了真正关键的“坑点”、团队秘辛和“雷区警告”。
✅ 定期重新运行 /init。
项目持续演进,CLAUDE.md 也会随之过时。建议每几个月,或经历重大重构后,再次运行 /init。它将生成新版草稿,你只需将其与现有 CLAUDE.md 做 diff,合并新增的结构信息,同时保留你手写的宝贵规范。
✅ 严格控制长度(≤ 100 行)。CLAUDE.md 会被注入到每一次对话中。若长达 500 行,你等于在每条消息中浪费数百 token。务必精炼!参考文档请另存为独立文件,用 @ 按需引用。
团队新人入职工作流#
这是我为已启用 Claude Code 的项目设计的新工程师入职流程:
第 1 步:安装 Claude Code。
执行本文开头的 curl 命令,60 秒搞定。
第 2 步:克隆代码仓库。
仓库中已包含 .claude/settings.json 和 CLAUDE.md(均已提交 Git),新人自动获得全部团队规范。
第 3 步:创建本地配置。
我提供一个模板:
| |
第 4 步:运行 /onboard(自定义命令,详见第 3 篇)。
该命令读取 CLAUDE.md,生成一份高度定制化的一页纸入职指南,精准反映当前代码状态。
第 5 步:立刻投入开发。
从克隆仓库到拥有完整配置的 Claude Code 环境(含团队规范、正确权限、项目上下文),全程不超过 10 分钟。无需翻阅 Wiki、查找 Notion 文档、或在 Slack 中大海捞针。
核心洞见:三层配置体系让入职变成“克隆即用”。所有团队共享内容都在仓库中;所有个人专属配置只需在本地创建一次。零同步成本。

我在每个新仓库中的标准操作#
claude启动/init生成初始CLAUDE.md- 编辑
CLAUDE.md,添加 3–5 条最关键的项目特有规范与禁止条款 - 创建
.claude/settings.json,填入测试 / 格式化等命令权限 - 将
.claude/settings.local.json添加至.gitignore - 提交所有变更,收工
耗时约 5 分钟。回报立竿见影:无论是我本人,还是任何一位队友,只要首次用 Claude Code 打开这个仓库,就能立刻获得全量配置与上下文。
必备的 .gitignore 条目#
请确保你的 .gitignore 包含以下两项:
| |
settings.local.json存放个人及敏感配置,绝不可提交;todos/目录存放会话级任务追踪,属临时数据,无需共享。
切勿 gitignore .claude/settings.json 或 .claude/commands/,它们是团队资产,必须共享。
常见错误及规避方法#
❌ 错误:把所有配置塞进机器层。
有人将项目专属的 npm test 命令写入 ~/.claude/settings.json。一旦切换项目,配置即失效。项目专属命令,必须放在项目层。
❌ 错误:忽视 deny 规则。
大家热衷于设置 allow,却常忽略 deny,而后者才是真正的安全防线。请严肃思考:哪些操作一旦被 Claude 执行,后果将是灾难性的?rm -rf、npm publish、git push --force、对生产数据库执行迁移……对这些操作,必须显式 deny。
❌ 错误:把 CLAUDE.md 写成百科全书。
见过 400 行的 CLAUDE.md,堆满详细 API 文档。这意味着每条消息都浪费 400 行上下文。请牢记:CLAUDE.md 只承载指令与结构;参考材料请存为独立文件,按需 @ 引用。
❌ 错误:从不重跑 /init。
项目在变,CLAUDE.md 也必须随之进化。若自上次 /init 后,你已新增三个服务并接入 GraphQL,那么这份记忆文件就在向 Claude 传递错误的项目结构认知。
❌ 错误:忘记 .gitignore settings.local.json。
一次 API Key 泄露,足以酿成大祸。务必在创建该文件前,先将其加入 .gitignore。
下一篇预告:那些被所有人忽略的快捷键,以及四状态模式切换开关。
Claude Code 实战 10 篇
- 01 Claude Code 实战(一):安装、三层配置体系,以及 `#` `@` `/init` 三剑客 当前
- 02 Claude Code 实战(二):快捷键、四态切换与思考模式
- 03 Claude Code 实战(三):自定义斜杠命令与对话控制
- 04 Claude Code 实战(四):MCP 服务器连接万物
- 05 Claude Code 实战(五):Hooks 与 Yolo 安全网
- 06 Claude Code 实战(六):SDK 与 GitHub CI
- 07 Claude Code 实战(七):十个实用 Hooks 配方
- 08 Claude Code 实战(八):Sub-Agent 与计划模式
- 09 Claude Code 实战(九):权限模型与环境变量
- 10 Claude Code 实战(十):Skills 与四种扩展机制


