
云计算(三):云原生与容器技术
从第一性原理理解云原生:容器在内核层面到底做了什么、Kubernetes 怎样工作、Service Mesh 何时值得引入、整套技术栈在生产环境如何拼装。
从单体应用转向云原生架构,是过去十年软件工程领域最具深远影响的变革之一。容器与 Kubernetes 的名字早已耳熟能详,但真正值得深挖的是:为什么这套技术栈最终胜出?每一层究竟承担了什么职责?又有哪些关键“接缝”决定了你的平台体验是行云流水,还是步步迷宫?

本文将从第一性原理出发,逐层剖析云原生技术栈。我们先探讨驱动这一切的架构演进动因,再深入 Linux 内核层面理解容器的本质,继而向上攀登至 Kubernetes 编排层,分析服务网格(Service Mesh)在何种场景下才值得引入其复杂性,最后厘清 Helm 打包与 GitOps 交付的核心逻辑。所有示例均贴近生产实际:可直接复用的 Dockerfile、真实可用的 YAML 清单,以及在生产环境中真正关键的权衡取舍。
你将学到什么#
- 12 要素应用方法论及其每条原则背后的设计动机
- 容器内部机制:namespace、cgroup、联合文件系统(union filesystem)与镜像分层原理
- Docker 生产实践:多阶段构建、安全加固、使用 Compose 进行本地开发
- Kubernetes 架构:控制平面如何通过调和循环(reconciliation loop)驱动工作节点
- 工作负载原语:Pod、Service、Deployment、StatefulSet、DaemonSet、Job
- 网络模型:CNI 插件、NetworkPolicy、Ingress,以及 Istio 服务网格何时“回本”
- 存储机制:PV/PVC 动态供给,以及
ReadWriteMany模式的真实代价 - Helm 打包:Release 历史管理与回滚机制的底层逻辑
- 微服务模式:熔断器(circuit breakers)、Saga 事务、API 网关
- GitOps 实践:ArgoCD 如何强制推行运维纪律
前置知识#
- 熟悉 Linux 命令行及基础网络概念(如路由、DNS、TCP)
- 理解 HTTP/REST 协议,清楚 Web 应用与数据库之间的交互方式
- 建议先阅读本系列前六篇文章,尤其推荐虚拟化 、网络 和运维与 DevOps 作为背景知识
云原生:变了什么、为什么变#
“云原生”绝不等同于“把东西搬到云上运行”。一台通过 lift-and-shift 方式迁移上云的虚拟机虽然位于云中,却并非云原生。CNCF 的定义非常精准:
云原生技术赋能组织在公有云、私有云和混合云等现代动态环境中构建和运行可扩展应用。容器、服务网格、微服务、不可变基础设施和声明式 API 是这一理念的典型体现。
这句话背后,其实由三大核心思想支撑:
不可变基础设施(Immutable Infrastructure)
服务器不再是需要精心呵护的“宠物”,而是可批量替换的“牲口”。每次发布都基于全新镜像,绝不进行就地修改。此举彻底消除了配置漂移,而配置漂移正是近半数生产事故的根源。声明式 API(Declarative APIs)
用户只需描述期望状态(例如:“我需要 3 个 v1.4 版本的副本,每个分配 500 MB 内存”),平台会自动让现实状态与之对齐。相比之下,命令式脚本(“先执行步骤一,再执行步骤二”)一旦现实偏离脚本假设,便会立即失效。全栈松耦合(Loose Coupling at Every Layer)
服务彼此独立,部署相互解耦,故障局部隔离,扩缩容按需进行。代价是系统组件增多;收益则是没有任何单一组件能拖垮整个系统。
单体 vs 微服务:取舍一目了然#

上图展示了结构差异,但真正的关键在于以下四个维度的对比:
| 维度 | 单体架构 | 微服务架构 |
|---|---|---|
| 部署单元 | 单一二进制文件 | N 个独立服务 |
| 扩缩容单元 | 整个应用 | 各服务独立扩缩容 |
| 技术栈 | 单一语言/运行时 | 按服务选择多语言(polyglot) |
| 故障爆炸半径 | 100%(全站宕机) | 仅限单个服务(配合熔断机制) |
微服务并非绝对更优。它用简单性换取独立性:你付出的是分布式系统的复杂性(如网络故障、最终一致性、分布式追踪、接口契约版本管理),换来的是部署、扩缩容与故障隔离的自由。决策准则如下:如果你的团队小到“两个披萨就能喂饱”,且发布节奏以月为单位,那么一个结构良好的单体应用几乎肯定是更优选择。只有当跨团队协调成本开始主导工程师的时间投入时,才应考虑引入微服务。
要素应用:一份生存指南#
12 要素方法论 (Heroku,2011)虽早于 Kubernetes 诞生,却已成为容器化服务默认遵循的运维契约。每一条要素的存在,都是为了彻底杜绝某类特定故障模式:
| 编号 | 要素 | 为何重要 |
|---|---|---|
| 1 | 代码库 —— 一份代码,多环境部署 | 相同代码配不同配置,确保可靠的环境晋升路径 |
| 2 | 依赖 —— 显式声明并隔离 | 彻底杜绝“在我机器上能跑”的问题 |
| 3 | 配置 —— 存于环境变量,而非代码中 | 同一镜像可在 dev/staging/prod 无缝运行 |
| 4 | 后端服务 —— 视为附加资源 | 更换数据库只需修改 URL,无需代码重构 |
| 5 | 构建、发布、运行 —— 三者严格分离 | 发布产物不可变,且支持可靠回滚 |
| 6 | 进程 —— 无状态、无共享数据 | 任意副本均可处理任意请求 |
| 7 | 端口绑定 —— 应用自包含 | 无需依赖外部应用服务器(如 Tomcat、IIS) |
| 8 | 并发 —— 通过进程模型实现扩展 | 水平扩缩容成为默认选项 |
| 9 | 易处理性 —— 快速启动、优雅关闭 | 自动扩缩容与滚动更新得以顺利实施 |
| 10 | 开发/生产环境对等 —— 尽量保持一致 | 大幅减少生产环境中的意外问题 |
| 11 | 日志 —— 以事件流形式输出至 stdout | 由平台统一收集,应用无需写入文件 |
| 12 | 管理进程 —— 一次性任务也在相同环境中运行 | 数据库迁移等操作无需另建一套技术栈 |
当然,有时违反某条要素反而是合理选择(例如要素 6 在有状态系统中确实难以完全满足),但每一次妥协都意味着你主动承担了一份技术债务,务必清楚自己正在做什么。
容器:到底是什么?#
许多人将容器理解为“轻量级虚拟机”,但这种认知在关键点上存在根本性偏差。容器并非虚拟化技术,而是一种进程隔离机制。 本质上,容器只是一个(或一组)Linux 进程,内核通过特定机制向其“伪造”出一个独立的系统视图,使其误以为自己独占整台机器。
这一效果依赖于三个 Linux 内核特性:
- Namespaces,为进程提供独立的资源视图(包括 PID、网络、挂载点、UTS、IPC、用户及 cgroup)。在 PID namespace 中,容器内进程看到自己是 PID 1,且无法感知宿主机上的其他进程。
- cgroups(v2),强制实施资源限制(CPU、内存、I/O、进程数等)。当你设置
--memory=512m,一旦超限,内核会直接终止该进程。 - 联合文件系统(Union Filesystem),当前主流为 overlay2,它将多个只读镜像层叠加,并在顶部添加一个轻量级可写层,从而实现高效的写时复制(copy-on-write)语义。
仅此而已。容器与宿主机共享同一个内核,没有 hypervisor,也没有第二个操作系统。其优势显而易见:启动时间约 50 毫秒(虚拟机需约 30 秒),内存开销仅 5 MB(虚拟机通常 500 MB),单机可运行上百个容器(虚拟机通常仅几十个)。
镜像分层:让构建飞起来的缓存机制#

Dockerfile 中的每一条指令都会生成一个新层。这些层通过联合文件系统堆叠,且相同内容的层会在不同镜像乃至不同主机间自动去重。正因如此,即便基础镜像高达数 GB,两个共享该基础的镜像之间往往仅相差几 MB。
这一机制带来两条关键实践建议:
1. 按缓存复用效率排列 Dockerfile 指令顺序。
将变动频率低的内容(如系统包、语言运行时)放在前面;将每次提交都会变化的内容(如应用代码)放在最后。命中缓存的构建只需几秒,而冷构建则可能耗时数分钟。
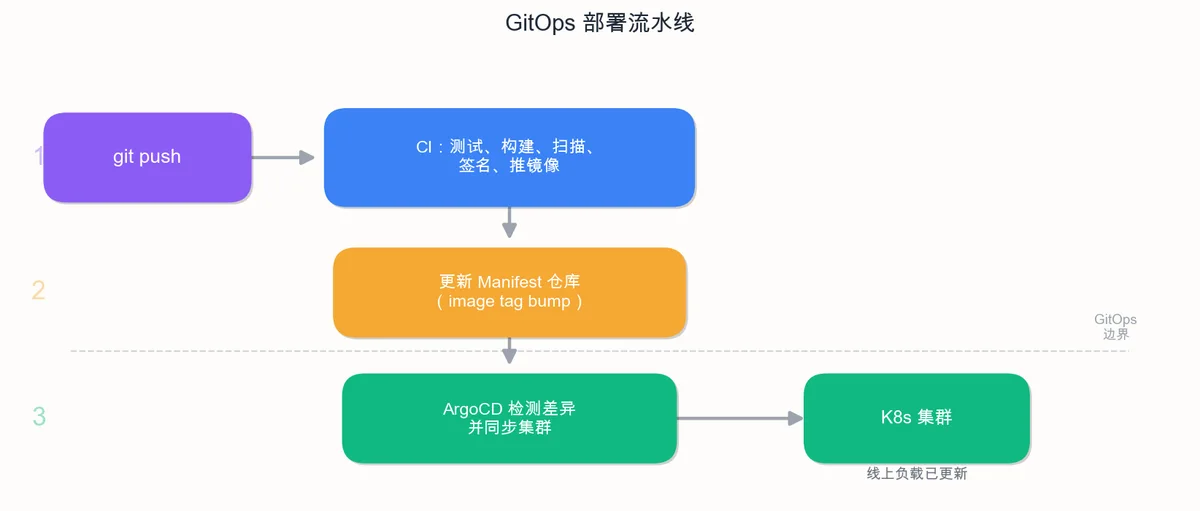
这里的核心范式是 GitOps:集群的期望状态由 Git 仓库定义。ArgoCD(或 Flux)会持续将集群实际状态与 Git 中的声明进行调和。这带来两大显著优势:
- 完整的审计追踪:每次变更都对应一次 Git 提交。想知道凌晨两点谁改了生产环境?一句
git blame即可溯源。 - 高效的灾难恢复:集群彻底崩溃?只需从 manifest 仓库执行
kubectl apply,即可快速重建。
| |
配置 selfHeal: true 意味着:“如果有人手动执行 kubectl edit 修改了资源,ArgoCD 会自动将其恢复为 Git 中定义的状态。”这正是 GitOps 所强制推行的纪律,集群状态以 Git 为准,而非某个人终端中的临时操作。
生产环境真正有用的命令#
| |
最实用的命令组合莫过于:kubectl describe(查看资源状态、事件日志及调度决策) +kubectl logs --previous(查看刚刚崩溃容器的日志内容)。
生产就绪检查表#
在宣布某个工作负载已准备好上线生产前,请务必确认以下事项:
- 使用多阶段 Dockerfile,以非 root 用户运行,基础镜像采用 distroless 或最小化版本
- 镜像通过 digest 固定版本(或至少使用不可变 tag),并在 CI 流程中完成签名与漏洞扫描
- 为每个容器明确设置 resource requests 和 limits
- 配置 liveness 与 readiness 探针(前者控制重启,后者控制流量接入)
- 设置 PodDisruptionBudget,确保集群维护期间副本数不低于
minAvailable - 若流量波动较大,配置 HorizontalPodAutoscaler 实现自动扩缩容
- NetworkPolicy 默认拒绝所有流量,仅显式放行必要通信
- 敏感信息(Secrets)存储于外部系统(如 Vault、AWS Secrets Manager 或 External Secrets Operator),避免使用明文 Kubernetes Secret
- 日志输出至 stdout,采用结构化格式(如 JSON),并汇总至中央日志系统
- 暴露 Prometheus 格式的指标,并配备对应的监控面板
- 已集成分布式追踪(推荐 OpenTelemetry)
- 已验证备份方案的有效性,尤其是针对 StatefulSet
- 针对常见故障模式编写了详细的 runbook
一个满足上述所有条件的工作负载虽不能保证绝对稳定,但可以确保后续遇到的问题都是真正具有挑战性的技术难题,而非低级失误所致。


