
云计算(一):云计算基础与架构体系
工程视角的云计算入门 -- 服务模型(IaaS、PaaS、FaaS、SaaS)、部署拓扑、CapEx vs OpEx 的经济学、地域与可用区、厂商目录,以及配套真实架构案例的决策框架。
2025 年,每个开发软件的团队都会面临一个老问题:买服务器还是租服务器?只不过答案早已反转。二十年前,我们把硬件塞进机房;如今,只需用 YAML 描述所需资源,全球云厂商便能在几秒内将其部署到位,按秒计费,一旦停付就立即回收。云计算远不止是“别人的电脑”,它是一套可编程、可计量、支持多租户的计算、存储与网络抽象层,从根本上重塑了企业的构建方式和工程师的日常工作。

作为本系列的第一篇,本文旨在夯实概念基础,因此节奏会放得较慢。读完后,你应能读懂云架构图,在厂商宣讲时提出关键问题,并基于成本、可靠性与锁定风险进行理性分析,而非依赖空洞口号。
你将学到什么#
- 云决策所依赖的七个维度,为何“上云”从来不是一个单一选择
- 从 IaaS 到 PaaS、FaaS 再到 SaaS 的服务模型,及其隐含的管理边界
- 公有云、私有云、混合云与多云部署模式的成本与复杂度权衡
- 在 36 个月周期内 CapEx 与 OpEx 的演变趋势,以及盈亏平衡点所在
- 责任共担模型,为何大多数云安全事故源于客户配置错误
- 地域(Region)与可用区(AZ)设计背后的延迟与故障半径逻辑
- AWS、Azure、GCP 与阿里云的服务目录对比地图
- 一套实用且经得起时间检验的服务选型框架
准备工作#
- 对“服务器”“网络”和“操作系统”有基本认知
- 熟悉至少一种编程语言并能使用命令行
- 无需任何云计算经验
云计算到底是什么#
最广为引用的定义来自美国国家标准与技术研究院(NIST),其列出了五个核心特征。这些特征之所以关键,正是因为它们能明确排除那些“看似云实则非云”的系统。
- 按需自助服务:开发者通过 API 或控制台直接申请资源,无需提交工单或拨打电话。
- 广泛的网络访问:资源可通过标准网络协议,从各类异构客户端访问。
- 资源池化:物理基础设施以多租户方式共享,用户无法也不必知晓其工作负载具体运行在哪台物理机上。
- 快速弹性:容量可在数分钟内自动伸缩,对用户而言近乎无限。
- 可计量服务:资源消耗以极细粒度计量并计费(如按秒、按请求、按 GB·月)。
传统数据中心若仅出租一个机柜,则至少缺失上述三项特征;而一款通过浏览器登录的 SaaS 应用通常满足全部五项。正是这一定义划清了云与非云的边界。
简史——理解今日设计决策的由来#
| 时代 | 关键事件 | 对今天的意义 |
|---|---|---|
| 1960s–1980s | 大型机与共享终端兴起,IBM CP/CMS 首次实现虚拟化 | 多租户计算的思想源头 |
| 1990s | 客户端-服务器架构普及,本地服务器与关系型数据库崛起 | “前云时代”的典型场景;绝大多数遗留系统仍停留于此 |
| 2002–2006 | Salesforce 推出 SaaS;Amazon 相继发布 S3(2006 年 3 月)和 EC2(2006 年 8 月) | 首次允许外部开发者按小时租用计算资源 |
| 2008–2014 | Google App Engine(PaaS)、Heroku、OpenStack、Docker(2013)、Kubernetes(2014) | 更高层级的抽象出现,容器革命拉开序幕 |
| 2015–2020 | Lambda(2014)问世,Serverless 成为主流,超大规模云厂商年营收突破 500 亿美元 | 按调用计费模式普及,运维层逐渐“消失” |
| 2021–至今 | 全球云支出年化规模超 3000 亿美元,AI 需求推动 GPU 基础设施第二轮扩张 | 容量规划再度回归——这次围绕的是加速器 |
服务模型——管理边界在哪里#
可将云服务视为一个金字塔:层级越高,你需管理的内容越少,但控制力也随之下降。当前广泛采用的四层模型为 IaaS、PaaS、FaaS 和 SaaS。

基础设施即服务(IaaS)#
你租用虚拟机、虚拟磁盘和虚拟网络。从操作系统往上的一切,包括内核补丁、运行时环境、应用程序和数据,均由你负责。
- AWS EC2:提供 700 多种实例类型,涵盖通用型、内存优化型、计算优化型、存储优化型及 GPU 优化型
- Google Compute Engine:支持持续使用折扣、抢占式实例及自定义规格虚拟机
- Azure Virtual Machines:深度集成 Active Directory、.NET 与 Windows 授权体系
- 阿里云 ECS:在中国大陆市场占据主导地位,并针对通义大模型推理任务优化了实例族
适用场景:迁移现有应用且不重写代码;需要特定操作系统或内核模块;或工作负载对性能极度敏感(如 HPC、GPU 训练、低延迟交易),无法承受 hypervisor 之上的任何抽象开销。
成本参考:一台 4 vCPU、16 GB 内存的实例,按需价格约为 0.20 美元/小时(约 150 美元/月);若采用 1 年预留实例,成本可降低 30%–50%;若使用 Spot 实例且能容忍中断,则可节省 60%–80%。
平台即服务(PaaS)#
你只需提交代码与配置,云厂商负责操作系统、运行时、负载均衡与自动扩缩容。你看到的是日志与指标,而非服务器本身。
- Heroku:开创了
git push即部署的体验 - Google App Engine:可从零自动扩展至数千 QPS,全程无需人工干预
- AWS Elastic Beanstalk:上传代码后,后台自动配置 EC2、ELB、ASG 与 CloudWatch
- Vercel / Netlify:专为前端优化的 PaaS,特别适配 Next.js 等现代框架
适用场景:上线速度优先;团队规模小;应用形态标准(如 Web 应用、API 或后台任务);愿意接受运行时限制,以换取无需专人值守操作系统的便利。
函数即服务(FaaS)/ 无服务器#
你仅需提交一个函数,它按需执行,按调用次数与执行毫秒数计费。请求之间无常驻实例。
- AWS Lambda:行业标杆,单次执行最长 15 分钟
- Azure Functions、Google Cloud Functions / Cloud Run:功能类似的竞品
- 阿里云函数计算(FC)
适用场景:突发性或事件驱动型负载(如图片上传触发缩略图生成、Webhook 触发工作流);流量模式不可预测;或用于连接托管服务的胶水代码。
慎用场景:需要持久连接;要求冷启动低于 50 毫秒但不愿启用预置并发(Provisioned Concurrency);或长时间运行的计算任务,当稳态负载超过某一阈值后,单位经济性将急剧恶化。
软件即服务(SaaS)#
你直接使用应用,厂商掌控从芯片到软件的全部环节。
- 典型示例:Gmail、Salesforce、Slack、Zoom、Microsoft 365、Notion、Figma、Datadog
适用场景:该应用属于业务中的通用能力(如邮件、CRM、视频会议、可观测性)。
避免场景:该应用构成你的核心竞争力,这恰恰是你应自行构建的部分。
一张图:管理边界#
| 维度 | IaaS | PaaS | FaaS | SaaS |
|---|---|---|---|---|
| 控制力 | 高 | 中 | 低(按函数) | 仅配置 |
| 运维投入 | 高 | 中 | 低 | 无 |
| 上线速度 | 较慢 | 较快 | 事件类极快 | 最快 |
| 计费模式 | 按小时 | 按小时或请求 | 按请求 + 按毫秒 | 按席位 |
| 厂商绑定 | 低 | 中 | 中–高 | 高 |
| 典型代表 | EC2、ECS | Heroku、App Engine | Lambda、Cloud Run | Gmail、Salesforce |
最清晰的判断法则:沿金字塔向上,管理边界不断上移;边界之下归厂商负责,边界之上由你承担。
部署模型——工作负载放在哪里#
服务模型决定“租什么”,部署模型则决定“放在谁的数据中心”以及“如何联网”。

公有云#
由超大规模云厂商运营数据中心,你与陌生租户共享底层硬件,依靠加密与 hypervisor 实现隔离。最适合长尾工作负载:Web 应用、批处理任务、开发测试环境,以及初创公司几乎全部业务。
私有云#
由你(或托管服务商)为单一租户运营专用基础设施。适用于监管严格、延迟敏感或数据驻留要求高的场景:国防、特定医疗与金融业务,或工厂控制系统等对控制器响应时间要求在亚毫秒级的系统。
混合云#
公有云与私有云通过 VPN 或专线(如 AWS Direct Connect、Azure ExpressRoute、GCP Interconnect)连接,形成统一逻辑环境。经典模式是:敏感客户数据保留在本地,批处理分析与突发流量溢出至公有云。现实挑战在于:你现在必须维护两套工具链、两套安全策略和两套 on-call 轮值体系。
多云#
在生产环境中同时使用两家或以上公有云。动因包括:规避厂商锁定、利用各家最优服务(如 GCP 的 BigQuery、AWS 的 Bedrock),或满足客户强制要求。代价显著:身份管理、网络架构、可观测性与 CI/CD 均需实现云无关。
| 维度 | 公有云 | 私有云 | 混合云 | 多云 |
|---|---|---|---|---|
| 成本结构 | OpEx,低 | CapEx,高 | 混合 | 混合,更高 |
| 扩展能力 | 几乎无限 | 有限 | 灵活 | 极其灵活 |
| 控制程度 | 低 | 高 | 中 | 中–低 |
| 复杂度 | 低 | 中 | 高 | 极高 |
| 锁定风险 | 单一厂商 | 无(自主掌控) | 降低 | 最低 |
经验法则:默认采用单地域公有云。当停机开始造成实质性损失时,再增加第二地域。仅在出现战略级原因,如监管强制、客户硬性要求,或主云确实缺乏某项关键服务,才考虑引入第二家云厂商。
市场格局及其集中化成因#
云计算是现代基础设施中集中度最高的市场之一。AWS、Microsoft Azure 与 Google Cloud 三大厂商合计占据全球 IaaS+PaaS 支出的约三分之二;阿里云在中国大陆遥遥领先;其余份额由区域性及垂直领域厂商瓜分。

这种集中并非偶然。云基础设施属资本密集型行业,规模效应极为显著:每新增一个地域或可用区(AZ),即可吸引更广泛客户;每增加一项服务,又能与现有服务产生协同(如 S3 增强 EC2 粘性,IAM 则进一步加固两者)。中小厂商只能依靠低价、特定垂直领域(如游戏、科研计算)或区域优势参与竞争。
| 厂商 | 市占率 | 核心优势 | 最佳适用场景 |
|---|---|---|---|
| AWS | ~32% | 服务目录最全、历史最久、生态最庞大 | 企业级应用、初创公司、全球化部署、多样化需求 |
| Azure | ~23% | 深度集成 Microsoft 技术栈(AD/.NET)、混合云支持强 | 微软生态企业、受监管行业、政府机构 |
| GCP | ~10% | 数据与机器学习领先、K8s 原生、网络质量优异 | 数据分析、AI/ML、容器原生架构 |
| 阿里云 | ~4% | 中国本土覆盖深、亚太布局广、定价具竞争力 | 中国大陆业务、亚太部署、成本敏感型场景 |
| 其他 | ~30% | OCI、IBM、腾讯云、华为云及区域性专家 | 细分市场、区域性或垂直领域特定负载 |
经济学视角——CapEx 与 OpEx 的长期对比#
云的核心商业价值在于其成本曲线的形态:本地部署需提前批量采购容量,而云则按需按秒付费。
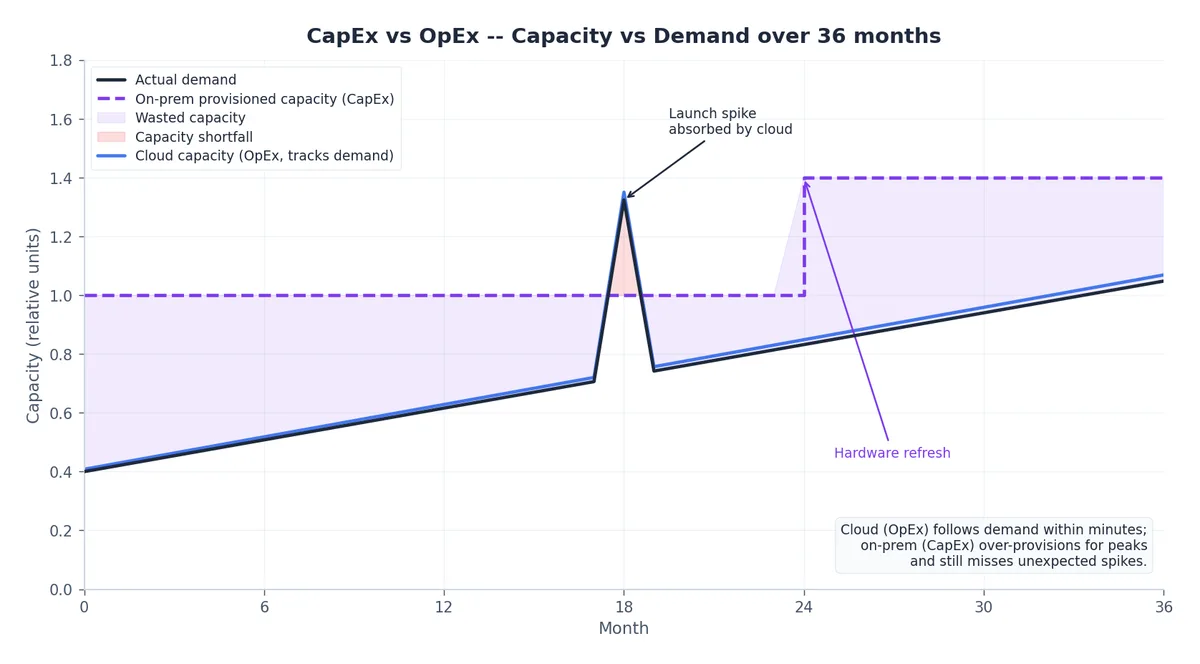
两种效应叠加:
- 容量闲置:本地硬件按峰值配置,但平均利用率仅 15%–30%,大量资源长期闲置。
- 容量不足:当需求突增(如产品发布、营销活动或病毒传播),本地环境无法弹性扩展;而云可在数分钟内吸收峰值。
对于波动型负载(绝大多数场景均属此类),无论硬件折扣多高,云在原始成本上几乎总占优。但对于稳态高利用率负载(如 7×24 小时以 80%+ 利用率运行的视频转码集群,或稳定的内部数据库集群),三年期预留实例或私有云建设可能比按需云便宜 30%–50%。
隐性成本建模要点#
标价绝非最终账单。务必计入:
- 出站流量(Egress):数据流出云平台需付费,跨区域传输同样计费
- 跨可用区流量:多数厂商对此收费;若微服务间通信频繁,此项可能主导账单
- 托管服务溢价:RDS 比在 EC2 自建 PostgreSQL 贵约 30%
- 支持计划:Business 或 Enterprise 级别通常占月支出的 3%–10%
- 人力成本:平台工程师、FinOps 分析师、安全工程师,“云团队”是真实人力投入
一份可靠的 TCO 模型应覆盖三年周期,包含本地硬件的更新周期与云的预留实例折扣,并将人力成本合理分摊至两边。
架构构建模块#
云远不止虚拟机。以下基础组件在任何成熟架构中反复出现。
虚拟化——底层基石#
Hypervisor 使多台虚拟机共享一台物理服务器。两类关键形态:
- Type 1(裸金属型):VMware ESXi、KVM、Hyper-V、Xen,直接运行于硬件,所有公有云均采用此架构
- Type 2(宿主型):VirtualBox、VMware Workstation,运行于主机操作系统之上,适用于开发测试
容器并非虚拟化的替代品,而是运行于虚拟机之上,共享主机 VM 的内核。典型 EKS 或 AKS Pod 的堆栈为:容器 → Linux VM → Hypervisor → 物理服务器。此部分将在第 2 篇(虚拟化)与第 7 篇(云原生)深入探讨。
| 特性 | 虚拟机 | 容器 |
|---|---|---|
| 隔离性 | 完整客户操作系统 | 共享内核;通过 namespace 与 cgroup 隔离 |
| 启动时间 | 通常 30–90 秒 | 通常 100 毫秒–2 秒 |
| 资源开销 | 每实例 GB 级 RAM | 每容器数十 MB |
| 适用场景 | 混合 OS、遗留应用 | 微服务、CI 工作节点、ML 训练 |
存储——按访问模式选型,而非名称#
| 类型 | 示例 | 访问协议 | 最佳用途 | 关键特性 |
|---|---|---|---|---|
| 对象存储 | S3、GCS、Azure Blob、OSS | HTTP/REST | 备份、媒体、静态网站、数据湖落地 | 11 个 9 持久性(99.999999999%) |
| 块存储 | EBS、Azure Managed Disks、PD | iSCSI/virtio | 数据库、高 IOPS 应用、系统盘 | io2/Hyperdisk 支持 80k+ IOPS |
| 文件存储 | EFS、Azure Files、Filestore、NAS | NFS/SMB | 共享内容、遗留应用迁移 | 支持多实例并发挂载 |
| 归档存储 | Glacier、Archive Blob、Coldline | 异步取回 | 合规归档、长期备份 | 每 TB·月仅数美分,取回需数小时 |
S3 风格的存储分级允许以取回延迟换取成本优化。典型策略:热数据存 Standard,30 天后转 Standard-IA,180 天后入 Glacier,一年后进深度归档,全程由生命周期策略自动驱动,无需人工干预。
网络——最容易踩坑的部分#
- VPC(虚拟私有云):你在云中的隔离网络,含各 AZ 子网、路由表、安全组与 NACL
- 负载均衡器:L4(NLB/TCP)追求吞吐量,L7(ALB/HTTP)支持按路径或 Header 路由
- CDN:在边缘 POP 缓存静态(及日益增多的动态)内容,如 CloudFront、Cloud CDN、Azure CDN、Cloudflare
- VPN/专线:IPSec 隧道成本低,专线延迟稳定(通常 <2ms,不走公网)
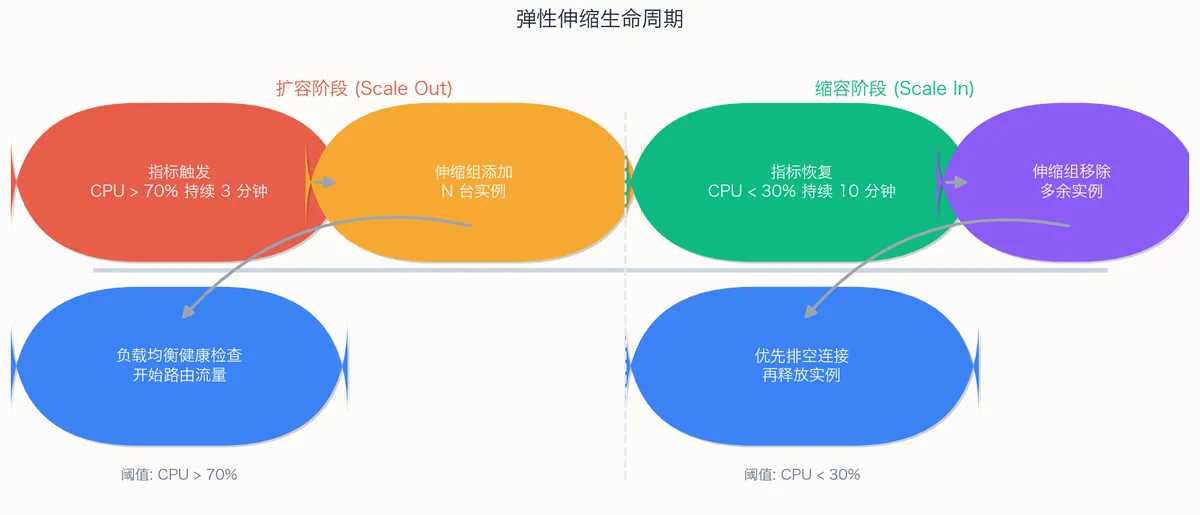
自动伸缩——弹性的核心引擎#
两个维度:
- 横向伸缩(扩/缩):增减实例数量,云原生默认方式
- 纵向伸缩(升/降配):调整实例规格,通常需重启,主要用于数据库等有状态负载
地域与可用区——故障域设计哲学#
地域(Region) 是地理区域(如 us-east-1、eu-west-1、ap-southeast-1、cn-hangzhou),彼此隔离,单地域故障不会扩散。每个地域包含多个可用区(AZ),相距数公里的独立数据中心,拥有独立电源、冷却与网络,但通过亚毫秒级光纤互联。

设计逻辑如下:
- 同地域多 AZ:成本低、实施易,副本跨 AZ 部署,负载均衡器自动故障转移,应用几乎无需改造
- 跨地域:复杂度陡增,需长距离数据复制,面临最终一致性挑战,且依赖 DNS 或全局负载均衡实现故障切换
- 边缘/POP:适用于内容分发与 DDoS 防护,不适用于有状态应用逻辑
务实建议:从第一天起就构建多 AZ 架构(边际成本极低);仅当一分钟宕机损失超过一个月复制带宽成本时,才考虑多地域架构。
责任共担模型#
过去十年几乎所有公有云安全事故,皆源于客户配置错误,公开的 S3 存储桶、泄露的 IAM 密钥、过度宽松的安全组。责任共担模型正是为厘清此问题而设。

云厂商始终负责底层基础设施安全,包括物理访问、hypervisor 及数据中心间网络平面。不同服务模型的区别仅在于责任边界的位置:
- IaaS:客户负责 OS、中间件、应用、身份与数据;厂商负责 VM 及以下所有层
- PaaS:OS 与中间件移交厂商;客户保留应用代码、身份与数据责任
- SaaS:厂商承担几乎所有责任,客户仅需管理身份(谁能登录)与数据权限(能做什么)
两大实践启示:
- 身份管理永远是你的责任:多因素认证、最小权限、密钥轮换、JIT 访问,这些功能不会自动生效。
- 数据安全永远是你的责任:静态加密通常默认开启;传输加密需你强制实施;备份、保留策略与合规要求完全由你设计。
此主题将在第 5 篇(云安全与隐私保护)深入展开。
服务目录——读懂厂商菜单#
各大云厂商均提供数百项服务,但可归为少数家族。下图足以助你快速导航任意厂商目录。

浏览目录时的实用建议:
- 名称会变,本质不变:厂商常更名或重组,但底层原语(计算、对象存储、托管 SQL)保持稳定
- 三层同心圆结构:
- 核心层(计算、存储、网络、IAM、监控):成熟且各厂商差异小
- 托管层(数据库、消息队列、容器编排):差异化体现在易用性与定价
- 前沿层(AI、数据仓库、自研芯片):厂商争夺心智的主战场,也是锁定风险最高之处
- 先查配额,再谈架构:每个账号均有软硬配额(vCPU 数、S3 桶数、API QPS),设计前务必确认
真实案例——架构在压力下的表现#
Netflix——行星尺度的流媒体#
Netflix 于 2016 年关闭最后一个数据中心,全面迁移至 AWS,并自建 Open Connect CDN 部署于 ISP 内部以分发视频。系统由数百微服务组成,配备 Chaos Monkey 等混沌工程工具链,实现多 AZ 与多地域容灾。成果:支撑 2 亿+ 用户,达成 99.99% 级可用性,并能轻松应对爆款剧集上线导致的周末流量翻倍。
Airbnb——从初创到全球平台#
2009 年,Airbnb 是运行于 AWS 单一区域的单体应用;至 2018 年,已演进为跨多区域的数百服务架构,数据层采用 Aurora 与 Vitess,东西向流量经 Service Mesh 处理,读路径依赖 ElastiCache(Redis)与 CloudFront。迁移采取渐进式,每次拆分一个有界上下文,历时多年而非一次性重写。成果:支撑数百万房源,平稳应对不可预测的季节性高峰。
Capital One——受监管企业的云转型#
Capital One 是首批全面拥抱公有云的美国银行(2015 年宣布,2020 年完成)。技术难点不在迁移本身,而在治理,需向 SOC、PCI-DSS 及银行业监管方证明,Terraform、Cloud Custodian 等代码化控制手段与物理控制同等可审计。成果:2020 年关闭全部 8 个遗留数据中心,基础设施成本降低 30%–40%,软件交付周期从季度级缩短至天级。(2019 年因 WAF 配置错误导致 SSRF 漏洞的事故,恰是客户侧责任共担的经典反面教材。)
Spotify——主动设计的多云架构#
Spotify 主要流媒体服务运行于 GCP,数据与 ML 平台深度依赖 BigQuery、Dataflow 与 Pub/Sub;AWS 则用于特定存储与计算任务。成果:每日处理 PB 级收听数据,驱动 Discover Weekly 与 Wrapped 功能,同时有意识地管控供应商集中风险。
一套经得起复盘的决策框架#
云上最难的不是技术选型,而是一年后仍能清晰解释当初为何如此选择。以下七维框架是我反复验证后最信赖的方法。
| 维度 | 关键问题 | 误判后果 |
|---|---|---|
| 负载形态 | 稳态还是突发?CPU/内存/IO/GPU 密集型? | 实例族选错,账单翻倍 |
| 数据重力 | 数据当前位置与规模? | Egress 费用与迁移时间可能远超计算成本 |
| 延迟预算 | 用户端到端延迟目标? | 决定区域数、边缘使用、多 AZ vs 多地域 |
| 合规要求 | 是否需满足 HIPAA/GDPR/PCI 或区域数据主权? | 限制可选区域,甚至厂商 |
| 团队能力 | 团队现有技术栈? | “最佳”服务若团队无法运维,不如“够用”服务 |
| 三年 TCO | 含出站流量、支持费、人力成本的总拥有成本? | 18 个月时账单可能带来“惊喜” |
| 锁定容忍度 | 三年后迁移该服务的成本? | 前沿服务虽好,但离开时代价高昂 |
经得起时间考验的最佳实践#
- 小步快跑,渐进扩展:从非核心服务在单账号单区域起步
- 为故障而设计:假设任何组件(含托管服务)随时可能失效;从第一天起采用多 AZ
- 优先托管服务处理通用负载:无充分理由,勿自运维 PostgreSQL
- 定期审视资源分配:多数集群超配 20%–40%;每周检查一次,收益远超成本
- 全面加密:静态加密默认开启已成标配;传输层必须强制 TLS 1.2+
- 基础设施即代码:使用 Terraform、Pulumi 或 CloudFormation,生产环境禁用手动操作
- 可观测性先行:在流量涌入前,先部署日志、指标、追踪与告警
常见问题#
云一定比本地便宜吗?
不一定。对波动负载与多数企业,云更具优势;但对超大规模、70%+ 利用率的稳态负载(如 Dropbox 曾将存储层迁出 AWS 节省数亿美元),自建可能更优。务必建模三年 TCO,含硬件更新、出站流量与人力成本。
云安全吗?
底层基础设施比绝大多数企业自建更安全;但应用与配置的安全性完全取决于你。责任共担模型是分界线,多数安全事故发生在客户侧。
厂商宕机怎么办?
宕机不可避免,需提前设计应对方案:
- 多 AZ:低成本应对常见故障(单 AZ 失效)
- 多地域:高成本应对罕见故障(整地域失效)
- 多云:极高成本应对极罕见故障(全厂商失效)
投入应匹配真实风险偏好,而非被新闻标题裹挟。
该先学哪些技能?
建议路径:
- 考取一家厂商的基础认证(如 AWS Cloud Practitioner、Azure Fundamentals、GCP ACE)
- 掌握 Linux 基础、网络原理、基础设施即代码(Terraform)
- 学习容器技术(Docker、Kubernetes)
厂商特定知识迁移成本远低于普遍认知。
学 AWS、Azure 还是 GCP?
优先选择雇主或目标雇主所用平台。三者概念相通,切换仅需数周而非数年:
- AWS:就业市场最广
- Azure:企业 IT 领域主导
- GCP:数据与机器学习领域优势明显
总结#
| 概念 | 核心要点 |
|---|---|
| 服务模型 | IaaS(控制权)→ PaaS(托管运行时)→ FaaS(按调用计费)→ SaaS(直接使用) |
| 部署模型 | 默认公有云;监管需求选私有云;遗留系统过渡用混合云;真正有战略意义才考虑多云 |
| 经济学 | OpEx 灵活匹配需求;CapEx 闲置浪费、高峰期又不足;TCO 需看三年总成本 |
| 责任共担 | 厂商负责底层基础设施安全,你负责身份、数据和配置安全 |
| 地域与 AZ | 一开始就用多 AZ;宕机损失大于复制成本时再扩展到多地域 |
| 厂商 | AWS(覆盖广)、Azure(企业级/微软生态)、GCP(数据/ML)、阿里云(中国/APAC) |
| 选型 | 先看负载形态、数据重力、延迟要求、合规性、团队能力,再算 TCO 和锁定风险——按此顺序 |
本系列后续文章将逐层深入上述主题。下一篇将聚焦虚拟化,支撑整个云计算大厦的 hypervisor 技术,从 KVM 内部机制到驱动 Lambda 的轻量级虚拟机 Firecracker。


