
云计算(二):虚拟化技术深度解析
虚拟化实战指南 -- Hypervisor(VMware、KVM、Xen、Hyper-V)、存储与网络虚拟化、性能调优以及容器对比。
没有虚拟化,就没有云计算。每个 EC2 实例、每次 Lambda 调用、每个 Kubernetes Pod,归根结底都依赖同一个核心技巧:让操作系统对底层硬件深信不疑地“被骗”。本文将带你走完整个技术栈,从让这个把戏变得廉价的 CPU 指令,到主导市场的四大 Hypervisor,再到决定虚拟机性能是达到裸机 70% 还是 99% 的生产级调优参数。

你将学到什么#
- 深入理解 CPU 虚拟化的工作原理(保护环、VT-x、EPT),以及 Type 1 与 Type 2 Hypervisor 存在的根本原因
- 动手配置 VMware ESXi、KVM、Xen 和 Hyper-V,并设置适合生产环境的最佳默认参数
- 存储虚拟化实战:LVM 与 ZFS 的应用,以及磁盘格式选择如何带来高达 4 倍的 IOPS 差异
- 网络虚拟化全景:VLAN、VXLAN 覆盖网络、Open vSwitch 与 SR-IOV
- 性能调优关键:CPU 绑核、NUMA 亲和性、大页内存、virtio 与 vhost-net
- 在线热迁移内部机制、嵌套虚拟化,以及 GPU 共享技术(vGPU / MIG)
- 安全加固策略、隔离原语,以及一份实用的故障排查手册
准备知识#
- 熟悉 Linux 命令行操作
- 掌握基本操作系统概念(进程、内核与用户空间、页表)
- 建议先阅读本系列第一篇文章(云计算基础 )
虚拟化基础#
虚拟化为硬件资源(CPU、内存、磁盘、网卡)创建虚拟副本,使多个操作系统各自“以为”自己独占整台机器。维持这一幻觉的核心组件是 Hypervisor,也称为虚拟机监视器(VMM)。
为什么需要硬件支持?#
x86 架构最初并非为虚拟化设计。它包含 17 条敏感指令(如 POPF、SGDT),这些指令会修改全局状态,但在用户模式下执行时却不会触发异常,这意味着一个简单的 Hypervisor 无法拦截它们。2000 年代初出现了两种主要解决方案:
- 二进制翻译(VMware):在运行时动态重写 Guest 内核代码,将危险指令替换为对 Hypervisor 的调用。巧妙但缓慢且复杂。
- 半虚拟化(Xen):修改 Guest OS,使其通过“hypercall”直接调用 Hypervisor。速度快,但仅适用于配合的系统(如 Linux、BSD)。
2005–2006 年,Intel VT-x 与 AMD-V 引入了新的 CPU 模式:Hypervisor 运行在 VMX root 模式,Guest 运行在 VMX non-root 模式,由硬件管理切换(VMENTER / VMEXIT)。从此,任何未经修改的操作系统都能以接近原生的速度运行。几年后,扩展页表(EPT)与嵌套页表(NPT)进一步消除了第二大开销,影子页表维护,通过硬件实现两级地址翻译。
正是这一刻,虚拟化成本低到足以支撑公有云的诞生。
Type 1 与 Type 2 Hypervisor#

| Type 1(裸金属型) | Type 2(宿主型) | |
|---|---|---|
| 运行位置 | 直接运行于硬件 | 运行于宿主操作系统之上 |
| 示例 | VMware ESXi、KVM、Xen、Hyper-V | VirtualBox、VMware Workstation、Parallels |
| 开销 | 极小 | 额外增加宿主 OS 调度层 |
| 使用场景 | 生产云、数据中心 | 开发笔记本、培训实验室 |
KVM 是个特例:它是一个内核模块,将 Linux 本身转变为 Type 1 Hypervisor,宿主内核与 Hypervisor 实为同一内核。
核心概念#
- Hypervisor(VMM):负责将 vCPU 调度到 pCPU、分配内存,并拦截 Guest 的特权操作。
- Guest OS:运行在 VM 中的操作系统,通常对虚拟化无感知(或仅有轻微感知)。
- vCPU:宿主机调度器中的一个线程,在 VMX non-root 模式下执行 Guest 代码。
- 资源超分(Resource overcommit):分配的虚拟资源总量超过物理资源。在合理范围内是安全的,因为 Guests 很少同时达到峰值。典型安全比例:CPU 4:1–8:1,内存 1.5:1–2:1。
- 气球驱动(Ballooning):Guest 内的驱动程序,可按需将空闲内存返还给宿主机,从而支持内存超分。
历史里程碑#
| 年份 | 事件 |
|---|---|
| 1972 | IBM VM/370 —— 首个商用 OS 级虚拟化 |
| 1999 | VMware Workstation 发布,通过二进制翻译实现 x86 虚拟化 |
| 2003 | Xen 1.0 在 Linux 上引入半虚拟化 |
| 2005 | Intel VT-x 与 AMD-V 为 x86 带来硬件辅助虚拟化 |
| 2006 | KVM 合并入 Linux 2.6.20 |
| 2008 | EPT / NPT 消除影子页表开销 |
| 2013 | Docker 发布;容器成为第二波浪潮 |
| 2018 | Firecracker(微虚拟机)实现亚秒级 VM 启动,赋能 Serverless |
虚拟化类型#
| 特性 | 全虚拟化(BT) | 半虚拟化 | 硬件辅助 | 容器 |
|---|---|---|---|---|
| 是否需修改 Guest OS? | 否 | 是 | 否 | 不适用 |
| CPU 开销 | 高 | 中等 | ~1–3% | 接近零 |
| 隔离性 | 强 | 强 | 强 | 进程级 |
| 启动时间 | 30–60 秒 | 30–60 秒 | 20–45 秒 | < 1 秒 |
| 镜像大小 | GB 级 | GB 级 | GB 级 | 数十 MB |
| 示例 | 早期 VMware | Xen PV | KVM、ESXi 6+ | Docker、containerd |
容器 vs VM:隔离边界的本质区别#

这是本文最重要的示意图。VM 虚拟的是硬件,因此每个 Guest 都自带内核;容器虚拟的是操作系统,它只是一个 Linux 进程,通过命名空间(PID、mount、network、UTS、IPC、user)和 cgroups 实现资源隔离与限制,所有容器共享同一内核。
由此带来的后果包括:
- 容器若触发内核漏洞,可能危及宿主机;VM 触发内核漏洞仅导致自身崩溃。
- 容器无法运行不同内核的操作系统(例如,Linux 宿主机上无法真正运行 Windows 容器,尽管营销材料常这么说)。
- 容器启动只需毫秒级,因为无需初始化内核。
正因如此,生产环境通常采用 容器运行于 VM 之内 的架构:VM 提供安全边界,容器提供密度与速度。
启动延迟与内存开销#

上述数据解释了为何 Serverless 能基于 Firecracker 微虚拟机(冷启动约 125 毫秒,内存开销约 30 MB)实现,而非传统 KVM/QEMU VM。启动时间与内存开销相差两个数量级,彻底改变了突发型工作负载的经济模型。
Hypervisor 选型#

没有“最好”的 Hypervisor,正确选择取决于你已有的技术栈、运维团队背景以及授权预算。
KVM(基于内核的虚拟机)#
KVM 将 Linux 本身转变为 Type 1 Hypervisor。它开源、内置于所有主流发行版,并支撑 OpenStack、Proxmox、Amazon EC2(Nitro)、Google Cloud 以及阿里云 ECS 的大部分实例。
在 Ubuntu/Debian 上安装:
| |
创建虚拟机:
| |
常用 virsh 命令:
| |
VMware ESXi#
ESXi 是直接运行于服务器硬件的 Type 1 Hypervisor,是企业事实标准,通常与 vCenter 配合进行集群管理。
默认 VM 硬件使用模拟 SCSI(LSI Logic)和模拟千兆网卡(E1000)。这对 Windows 安装尚可,但会严重拖累生产负载。应切换至半虚拟化设备:
| |
| 设置项 | 默认值 | 优化值 | 提升效果 |
|---|---|---|---|
| SCSI 控制器 | LSI Logic(~80K IOPS) | PVSCSI(~300K+ IOPS) | IOPS 提升 3–4 倍 |
| 网卡 | E1000(~1 Gbps) | VMXNET3(~9.5 Gbps) | 吞吐量提升约 10 倍 |
| CPU 开销 | 较高(模拟) | 较低(半虚拟化) | CPU 消耗减少 30–50% |
PVSCSI 与 VMXNET3 均需 Guest 安装 VMware Tools 驱动。建议先用传统控制器完成首次启动,再切换。
| |
Xen#
Xen 是最早的开源 Type 1 Hypervisor,曾支撑第一代 AWS EC2。它同时支持 PV 与 HVM(硬件辅助)模式。如今主要用于安全敏感场景(如 Qubes OS)及少数遗留云平台。
| |
Microsoft Hyper-V#
Hyper-V 内置于 Windows Server 及桌面版 Windows。若你的 Guest 多为 Windows,或团队习惯 PowerShell,则是合适之选。
| |
选型参考#
| 标准 | KVM | VMware ESXi | Hyper-V | Xen |
|---|---|---|---|---|
| 成本 | 免费 | $$$(按 socket 计费) | 随 Windows Server 捆绑 | 免费 |
| 管理工具 | virsh、OpenStack | vSphere(优秀 GUI) | PowerShell、Windows Admin Center | xl、XenCenter |
| 性能 | 优秀 | 优秀 | 良好 | 优秀 |
| 最佳适用 | Linux 云、OpenStack | 企业数据中心 | 微软生态 | 安全场景、遗留系统 |
存储虚拟化#
LVM(逻辑卷管理器)#
LVM 将块设备抽象为灵活、可调整大小的逻辑卷。其心智模型为:物理卷(pv)→ 卷组(vg)→ 逻辑卷(lv)。
| |
ZFS#
ZFS 将卷管理与文件系统合二为一,内置校验和、压缩、快照及 send/receive 复制功能。代价是内存占用(经验法则:每 TB 数据需 1 GB RAM 用于 ARC 缓存)。
| |
磁盘格式与 I/O 路径#
你为虚拟磁盘选择的格式,以及赋予 QEMU 的缓存模式,往往比 CPU 型号更能影响性能。
| |
| |
| 格式 | 性能 | 特性 | 最佳适用 |
|---|---|---|---|
| Raw | 最佳 | 无 | 生产数据库、延迟敏感型任务 |
| QCOW2 | 很好 | 快照、压缩、精简配置 | 通用场景、开发测试 |
| VMDK | 良好 | VMware 生态 | VMware 环境 |
cache=none + io=native 绕过宿主机页缓存,使用异步直通 I/O,这是所有自带文件系统缓存的 Guest 的正确默认配置。cache=writeback 虽更快,但宿主机崩溃会导致数据丢失;仅适用于临时性工作负载。
网络虚拟化#
VLAN#
VLAN 标签(802.1Q)将单一物理网络划分为多个隔离的广播域。
| |
局限:4094 个 VLAN ID 对单机架绰绰有余,但远不足以支撑公有云。
VXLAN#
VXLAN 将二层以太网帧封装在 UDP 包中,可在任意 IP 网络上提供 1600 万个逻辑网络(24 位 VNI)。这是多租户云网络与 Kubernetes 覆盖网络(如 Flannel、Calico VXLAN 模式)的主力技术。
| |
| |
Open vSwitch#
OVS 是支持 OpenFlow 的可编程虚拟交换机,被 OpenStack Neutron、OVN 及众多 SDN 栈采用。
| |
SR-IOV:绕过 Hypervisor#
SR-IOV(单根 I/O 虚拟化)允许网卡暴露虚拟功能(VF),直接映射到 VM,完全绕过宿主机网络栈。延迟从 ~30 µs(virtio)降至 ~3 µs(SR-IOV);吞吐量达线速。
| |
代价:热迁移变难(VM 绑定特定物理网卡),且 VM 数量受限于网卡 VF 数量。
性能优化#
CPU:绑核、NUMA、拓扑#
在多插槽主机上,最差情况是 vCPU 在插槽 A 唤醒,但内存位于插槽 B,每次缓存行访问都需跨插槽往返。通过 CPU 绑核 加 NUMA 绑定 解决:
| |
向 Guest 暴露真实 CPU 拓扑,使其调度器能做出合理决策:
| |
mode='host-passthrough' 暴露所有 CPU 特性(AVX-512、AES-NI 等),但会阻碍向异构主机热迁移;若需跨异构集群迁移,请使用 host-model。
内存:大页与气球驱动#
每个 TLB 表项映射一页。使用 4 KB 页遍历 1 GB 内存需 262,144 次;使用 2 MB 大页仅需 512 次。对数据库与 JVM,性能提升可达 5–15%。
| |
气球驱动可动态回收内存:
| |
I/O:全面采用 virtio#
KVM Guest 中务必使用 virtio 设备。它是半虚拟化方案,Guest 知晓自身处于 VM 中,通过与 Hypervisor 共享的环形缓冲区通信,而非 MMIO 模拟。vhost-net 将网络环处理移入内核,消除每次包处理的用户态往返。
| |
调优清单#
- BIOS 中启用 VT-x / AMD-V
- 磁盘与网卡使用 virtio(KVM)或 PVSCSI/VMXNET3(VMware)
- vCPU > 8 的 VM 启用 CPU 绑核 + NUMA 绑定
- 宿主机 I/O 调度器 =
none(NVMe)或mq-deadline(SATA) - 生产环境磁盘格式 = raw,
cache=none,io=native - 内存密集型 Guest 使用大页
- 网络密集型且无需热迁移的 VM 启用 SR-IOV
- 多队列 virtio-net,队列数 = vCPU 数
- 宿主机 CPU 调控器 =
performance
在线热迁移:移动运行中的 VM#
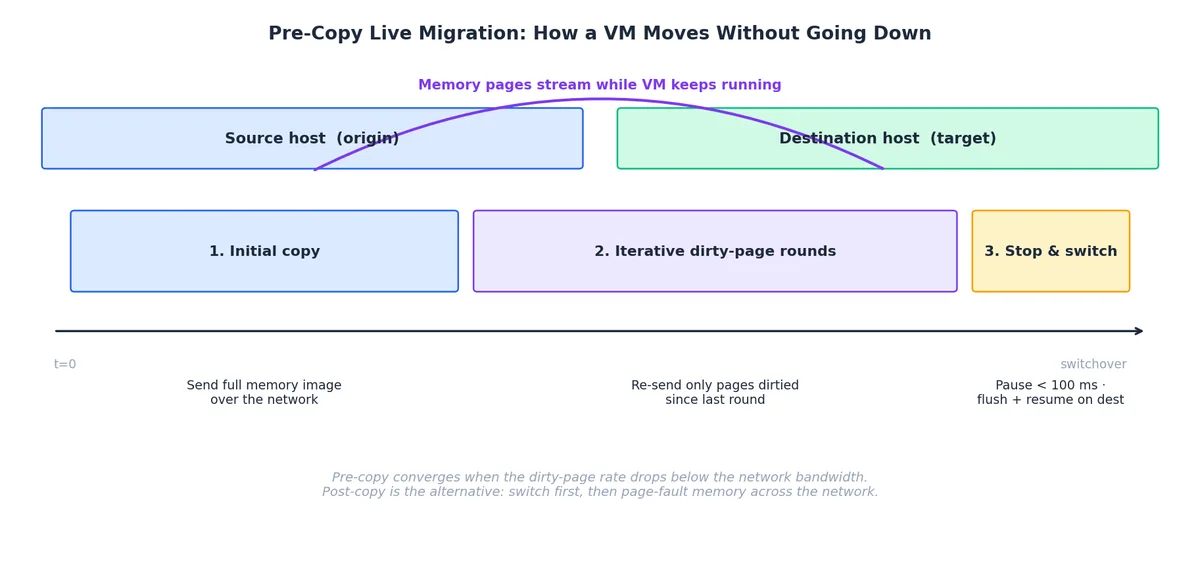
热迁移是 VM 从“另一种服务器运行方式”蜕变为“流动资源池”的关键特性。主流算法是 预拷贝(pre-copy):
- 初始拷贝:将整个 Guest 内存镜像发送至目标,同时 VM 在源端继续运行。
- 脏页轮询:源端追踪步骤 1 中被修改的页面并重发。重复直至脏页率低于网络带宽,或达到轮询上限。
- 停机切换:暂停源 VM,发送最后脏页与 CPU 状态,在目标端恢复。停机时间通常 < 100 ms,TCP 连接与用户会话得以维持。
| |
若 Guest 修改内存的速度超过链路传输能力(如内存数据库),预拷贝无法收敛。备选方案包括 后拷贝(post-copy)(先切换,缺页时跨网络加载,总停机更短,尾延迟更高)和 自动收敛(auto-converge)(节流 Guest CPU 以降低脏页率)。
前提条件:
- 共享存储,或
--copy-storage-all(较慢) - 源与目标 CPU 特性兼容(使用
host-model,非host-passthrough) - 网络带宽足够(脏页率 < 带宽),生产 VM 实际最低要求为 10 Gbps
嵌套虚拟化#

嵌套虚拟化允许 Guest VM 自身成为 Hypervisor。实际用途包括:
- 在云 VM 中运行虚拟化实验
- CI 流水线中动态创建 VM
- WSL 2(Windows 上 Hyper-V 运行 Linux,再运行容器)
- 机密计算(多层 Hypervisor 实现纵深防御)
KVM 中启用方法:
| |
随后向 L1 Guest 暴露 vmx(或 svm):
| |
开销:每层嵌套增加 VM-exit 跳转。CPU 密集型负载在 L1 损失 5–10%,L2 损失 25–40%;I/O 密集型负载若未全程使用半虚拟驱动,损失可能更大。
GPU 虚拟化#

GPU 原为单进程独占设计。跨 VM 共享需在密度与隔离间权衡:
| 模式 | 实现方式 | 隔离性 | 密度 | 说明 |
|---|---|---|---|---|
| 时间片轮转 | Hypervisor 轮询上下文 | 弱(无性能隔离) | 高 | 最便宜,常见于 ML 训练集群 |
| vGPU(NVIDIA GRID) | 中介直通,每 VM 分配虚拟 GPU | 中等 | 中等 | 显存硬 QoS;需 NVIDIA 授权 |
| MIG(A100 / H100) | 硬件将 GPU 划分为最多 7 个实例 | 强(独立 SM、L2、显存) | 固定规格(1g.5gb、2g.10gb…) | 真隔离,切片内不可细分 |
| 直通(VFIO) | 整 GPU 绑定至单 VM | 原生 | 1 VM/GPU | 裸机性能,无共享 |
典型 AI 云平台对推理使用 MIG(多小切片,硬 QoS),对训练使用直通(独占整卡)。
| |
安全与隔离#
威胁模型#
Hypervisor 的核心承诺是租户间互不可见。现实中的突破点包括:
- VM 逃逸:通过模拟设备漏洞(如 2015 年 Venom,QEMU 软盘驱动模拟)
- 侧信道攻击:共享 CPU 缓存引发(L1TF、MDS、Spectre v2)
- 管理平面漏洞:Hypervisor 内核缺陷
防御是分层的,而非完美。
Hypervisor 加固#
| |
在宿主机启用 CPU 侧信道缓解(spectre_v2=on、l1tf=full),并保持微码更新。
Guest 最佳实践#
- 最小化安装(无 GUI、无
cups、无apt-listchanges) - 自动安全更新(
unattended-upgrades) - 敏感数据全盘加密(Guest 内 LUKS)
- 按信任等级划分 VLAN,PCI 工作负载绝不可与开发 VM 同处一域
- 保持 Guest 代理(
qemu-guest-agent、vmtoolsd、Hyper-V Integration Services)更新
机密计算#
最新防护层:AMD SEV-SNP、Intel TDX、ARM CCA 使用 Hypervisor 不可见的密钥加密 Guest 内存。即使宿主机完全沦陷,租户数据仍安全。现已在 Azure Confidential VMs、GCP Confidential VMs 及阿里云 ECS gN8v 上可用。
故障排查手册#
| 症状 | 首查项 | 可能修复 |
|---|---|---|
| VM 无法启动 | journalctl -u libvirtd、qemu-img check vm.qcow2 | 磁盘损坏、权限、SELinux/AppArmor 标签 |
| CPU 缓慢 | virt-top、宿主机 mpstat -P ALL | CPU 绑核、调控器 = performance、检查 %steal |
| 磁盘缓慢 | iostat -xz 1、Guest iotop | 切换至 virtio + cache=none io=native、raw 格式 |
| 网络丢包 | ethtool -S、tc -s qdisc | 多队列 virtio、增大 ring buffer、检查 vhost CPU |
| 热迁移卡住 | virsh domjobinfo <vm> | 脏页率过高——启用 auto-converge 或 post-copy |
| 内存压力 | free -h、cat /proc/meminfo、numastat | 添加大页、修正 NUMA 绑定、降低超分 |
| VM 随机崩溃 | dmesg、/var/log/libvirt/qemu/<vm>.log | EDAC 错误 → 内存故障;否则检查内核 + 微码 |
KVM: entry failed, hardware error 0x80000021 | `dmesg | grep KVM` |
资源规格指南#
| 资源 | 轻量 | 中等 | 重型 |
|---|---|---|---|
| vCPUs | 1–2 | 2–4 | 4–8+ |
| 内存 | 2 GB | 4–8 GB | 16+ GB |
| 系统盘 | 20 GB | 30–50 GB | 50–100 GB |
| 网络 | 1 Gbps | 1–10 Gbps | 10+ Gbps(SR-IOV) |
安全超分比:
- CPU:4:1 至 8:1,延迟敏感型负载降至 2:1 或 1:1
- 内存:1.5:1 至 2:1,数据库绝不超分内存
- 磁盘:容量监控到位时,精简配置可行
案例研究#
企业数据中心整合#
某金融公司将 200 台物理服务器整合至 20 台 VMware ESXi 主机(后端为共享 NVMe SAN)。结果:机柜减少 90%,成本节省 60%,部署时间从数周缩至数小时。更大收益在于运维,单个 vCenter 集群取代了四个工单队列。
HPC 科研集群#
某研究所使用 KVM 运行紧耦合 MPI 任务,配置 host-passthrough CPU、NUMA 绑定、1 GB 大页及 SR-IOV InfiniBand。持续达成裸机吞吐量的 95–98%,同时获得实验快照能力,可跨站点迁移整个实验。
公有云计算平面#
超大规模云(AWS Nitro、阿里云 ECS Shenlong)将设备模拟完全卸载至定制 DPU,使宿主机 CPU 100% 用于 Guest,并将宿主机攻击面缩减至极简 KVM 层。性能开销仅个位数百分比,安全边界远小于传统 ESXi 主机。
阿里云特有陷阱#
前述内容在各云平台通用,但阿里云 ECS 有些独有细节。以下是我亲身被账单教育过的教训:
- ECS 实例族与底层 Hypervisor。现代 ECS 实例运行于阿里云“神龙(Shenlong)”架构,类似 Nitro 的 DPU,完全卸载 I/O。旧
n4/mn4族仍用软件 Hypervisor,I/O 密集型负载表现明显不同。生产负载若涉及高网络或磁盘压力,请选用g7/c7/r7或更新实例。这点差价,远低于一个周末排查“周二 p99 为何异常”的成本。 - 突发型 t 系列陷阱。
ecs.t6与ecs.t5使用 CPU 积分。首日看似正常,随后top显示 100% CPU 占用,实际仅获单核 20% 性能,积分耗尽。若 CPU 平均占用超 ~20%,永远别选 t 实例。 - 系统盘只能扩容,不能缩容。误配 200 GB 系统盘?该实例一生都将背负此负担。需缩容?只能从小盘镜像重建实例。
- 快照计费按 GB·月,非快照数。500 GB 盘每日快照费用迅速累积。使用增量快照(阿里云默认)并按需修剪保留策略。
- 维护期热迁移会通知,非透明。阿里云邮件告知维护窗口。VM 切换时暂停约 10 秒。有状态负载(数据库、长 TCP 连接)必须能处理此中断。
Region/AZ 选择——成本与延迟的故事#
Region 选择是成本最低但影响范围最大的决策。实测数据如下:
| 选项 | 中国大陆用户延迟 | 东南亚用户延迟 | 说明 |
|---|---|---|---|
cn-hangzhou | 20–40 ms | 60–90 ms | 默认且服务最全 |
cn-shanghai | 20–40 ms | 60–90 ms | 历史故障较少;部分 SKU 缺货 |
cn-shenzhen | 30–50 ms | 40–60 ms | 港澳/东南亚最佳 |
cn-hongkong | 50–80 ms | 30–50 ms | 位于 GFW 外;全球服务无需 ICP 备案 |
ap-southeast-1(新加坡) | 80–120 ms | 10–30 ms | 东南亚枢纽;服务齐全 |
血泪教训:
- AZ 级故障真实存在。多 AZ 部署非 paranoid,而是应对下次硬件故障的必备配置。SLA 合同也要求如此。
- 跨 Region 延迟既昂贵又不对称。杭州→新加坡 ~80 ms;杭州→法兰克福 ~280 ms。若同步复制,此延迟将进入写路径。
- 带宽定价随 Region 变化。中国大陆 Region 内流量较便宜;跨境出向流量常是账单中最贵项。
何时使用 VM、容器或函数#
“VM 已过时”是错误观点。真实选择如下:
- 裸金属 ECS(神龙裸金属实例):需 GPU 直通、完整 PCIe 访问,或在其上运行另一 Hypervisor。严格延迟预算的数据库常选此。
- 标准 VM(ECS):默认选项。十年稳定接口、完整 root、任意 OS 镜像。按配置付费,闲置也计费。
- 容器服务(ACK / Serverless 容器):工作负载符合十二要素且不想管理主机。ACK Pro 提供托管控制面;ECI(弹性容器实例)实现秒级计费且无需节点管理。“无节点”选项比多数人预期更适用。
- 函数计算(FC):事件驱动、突发性强、不可预测的工作负载。每日随机触发 10 次的处理器在 FC 上仅需几分钱,而在 ECS 上会浪费 $30/月闲置费用。函数冷启动 100–500 ms,适合 webhook,但用户请求会感卡顿。
多数公司可行路径:ECS 原型 → ACK 生产化 → 剥离定时任务至 FC。Day 1 直接上 Kubernetes 是项目延期六个月的常见原因。


