
计算机基础(一):CPU 与计算核心
理解数据单位(位与字节)、CPU 架构、五级流水线、缓存层级、分支预测、乱序执行、多核与 SMT、Intel vs AMD 差异,以及如何选购合适的处理器。
为什么 100 Mbps 宽带下载速度只有大约 12 MB/s?为什么标称“1 TB”的硬盘在 Windows 里只显示 931 GB?为什么 32 位系统最多只能用到约 3.2 GB 内存?当 CPU 执行你的代码时,每个时钟周期里究竟发生了什么?

这是 计算机基础系列 的第一篇。我们将从 bit 和 byte 出发,深入 CPU 内部:流水线、缓存、分支预测、乱序执行、多核与 SMT(同步多线程)。读完本文后,你应该能看懂 CPU 规格表,甚至性能分析报告(perf profile),并清楚每个数字背后的实际意义。
系列导航#
计算机基础(共 6 篇):
- CPU 与计算核心,你正在阅读
- 内存与缓存层级
- 存储系统(HDD、SSD、NVMe、RAID)
- 主板、显卡与扩展总线
- 网络、电源与散热
- 综合实战:把所有部件串起来
三个真实世界的疑问#
疑问 1,带宽谜题: 运营商给你“100 Mbps”宽带,但 Chrome 下载管理器峰值只有约 12 MB/s。是不是被坑了?
疑问 2,消失的 69 GB。 你买了一块 1 TB 硬盘,Windows 却只认出 931 GB。硬盘有问题?
疑问 3,帧率反常: 朋友的 14 核 i5-13600K 跑 CS2 能到 ~450 FPS,而你那颗更“豪华”的 16 核 R9 7950X 却只有 ~420 FPS。核心更多,帧率反而更低,为什么?
这三个问题的答案,都在这篇文章里。
第一部分 —— 数据单位:计算机世界的度量衡#
位与字节#
位(bit) 是最基本的二进制单位,非 0 即 1,就像一个开关:关或开。8 个这样的开关组合在一起,可以表示 $2^8 = 256$ 种不同状态,恰好够编码最初的 ASCII 字符集(字母、数字、标点)。因此,字节(byte) 被定义为 8 位。
“Mbps vs MB/s”的陷阱在于:运营商按 每秒多少比特(Mbps) 卖带宽,而浏览器显示的是 每秒多少字节(MB/s)。换算很简单:除以 8。
| 你看到的 | 实际含义 |
|---|---|
| 100 Mbps | 每秒 1 亿个 比特 |
| 12.5 MB/s(理论最大值) | 每秒 1250 万个 字节 |
| 10–11 MB/s(典型实际值) | 扣除 TCP 开销和网络拥塞后的结果 |
所以,“100M”宽带确实只能跑出约 12 MB/s,没人骗你,只是单位不同。
与 1000 的差异从何而来?#
计算机天生以 2 的幂计数,而最接近 1000 的 2 的幂是 $2^{10} = 1024$ 。因此,操作系统内部认为 1 KB = 1024 B,1 MB = 1024 KB,依此类推。但硬盘厂商采用国际单位制(SI),其中 1 KB = 1000 B。正是这一差异,导致“1 TB”硬盘在系统中只显示为 931 GB。
| 单位(二进制,操作系统) | 字节数 | 单位(十进制,厂商) | 字节数 |
|---|---|---|---|
| 1 KiB | 1,024 | 1 KB | 1,000 |
| 1 MiB | 1,048,576 | 1 MB | 1,000,000 |
| 1 GiB | 1,073,741,824 | 1 GB | 1,000,000,000 |
| 1 TiB | 1,099,511,627,776 | 1 TB | 1,000,000,000,000 |
快速估算:实际容量 ≈ 标称容量 × 0.931。
| 标称容量 | 实际可用 | 表观损失 |
|---|---|---|
| 256 GB | 238 GiB | 7.0% |
| 1 TB | 931 GiB | 6.9% |
| 2 TB | 1,863 GiB | 6.9% |
| 4 TB | 3,726 GiB | 6.9% |
内存(RAM)不会“缩水”,因为内存模块从设计之初就按二进制单位制造:一根 8 GB 内存条就是 $8 \times 2^{30}$ 字节,与系统计算方式完全一致。
第二部分 —— 深入 CPU 核心#
CPU 到底在干什么#
CPU 的任务说起来简单,做起来极难:不断取指、解码、执行、写回结果,每秒数十亿次。流水线、缓存、分支预测等一切复杂机制,都只为让这个循环跑得更快,同时不改变程序语义。
现代 CPU 核心包含四类硬件:
- 前端(控制):取指、解码、分支预测。
- 计算单元:整数 ALU、浮点/SIMD 单元、Load/Store 单元。
- 寄存器文件:极小但极快的暂存区(x86-64 有 16 个通用寄存器,外加 AVX-512 向量寄存器)。
- 缓存:L1 指令 + L1 数据(每核独享)、L2(每核独享)、L3(多核共享)。
前端“准备”工作,计算单元“干活”,寄存器文件存放操作数,缓存则确保数据能及时喂饱整个流水线。
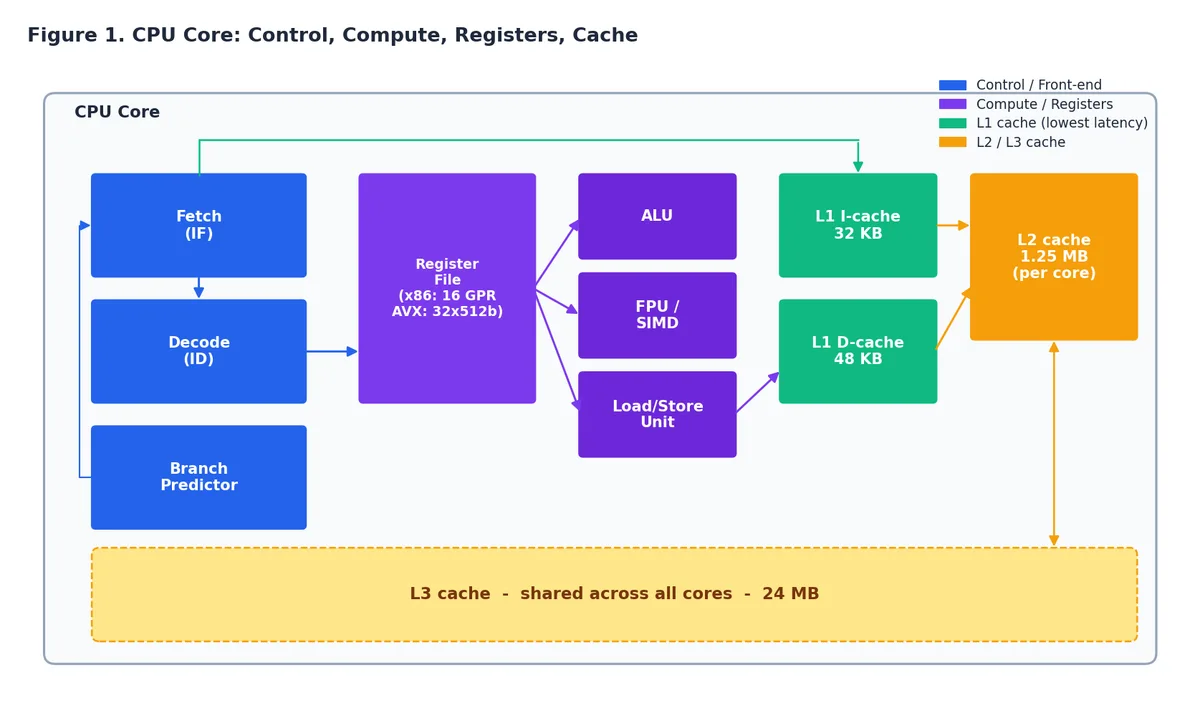
五级流水线#
经典教学模型将流水线分为五阶段:
- IF,取指令(从 L1I 读取)
- ID,解码(识别指令,读取寄存器操作数)
- EX,执行(ALU 运算)
- MEM,内存访问(加载/存储)
- WB,写回(结果写入寄存器)
若无重叠,5 条指令需 25 周期;启用流水线后,经过 4 周期“预热”,每周期完成一条指令,理想 IPC(每周期指令数)为 1.0。

现代 x86 核心(如 Intel Golden Cove 或 AMD Zen 4)远比这复杂:每周期可解码 6–8 条指令,流水线深度超 10 级。但核心思想不变:让每一级在每个周期都忙碌。任何造成“气泡”(空闲阶段)的行为都会损失吞吐量。接下来四节,讲的都是如何避免或隐藏这些气泡。
内存层级结构#
如果主存和寄存器一样快,缓存就没必要存在。但现实是,寄存器访问与机械硬盘寻道之间相差八个数量级。

| 层级 | 延迟 | 容量范围 | 技术实现 |
|---|---|---|---|
| 寄存器 | ~0.3 ns | 几十个字节 | 核心中的触发器 |
| L1 缓存 | ~1 ns | 32–64 KB | SRAM,每比特 6 个晶体管 |
| L2 缓存 | ~4 ns | 256 KB–1 MB | SRAM(密度更高,稍慢) |
| L3 缓存 | ~15 ns | 8–64 MB | SRAM(多核共享) |
| DRAM(DDR4/5) | ~90 ns | 8–128 GB | 每比特 1 晶体管 + 1 电容 |
| SSD(NVMe) | ~100 µs | 0.5–8 TB | NAND 闪存 |
| HDD | ~10 ms | 1–20 TB | 旋转磁盘 |
一个直观类比:假设 1 ns = 1 秒人类思考时间:
- L1 命中:瞬间想起。
- L3 命中:花 15 秒走到邻桌。
- DRAM:90 秒走到隔壁房间。
- SSD:一天半。
- HDD:四个月。
正因如此,一次 L3 未命中会让 CPU 白白浪费几十个周期;而一段缓存友好的内层循环,即使算术相同,也可能比缓存不友好的版本快 10 倍。
缓存未命中的三种类型#
缓存会以三种方式失效。知道是哪一种,才能对症下药。
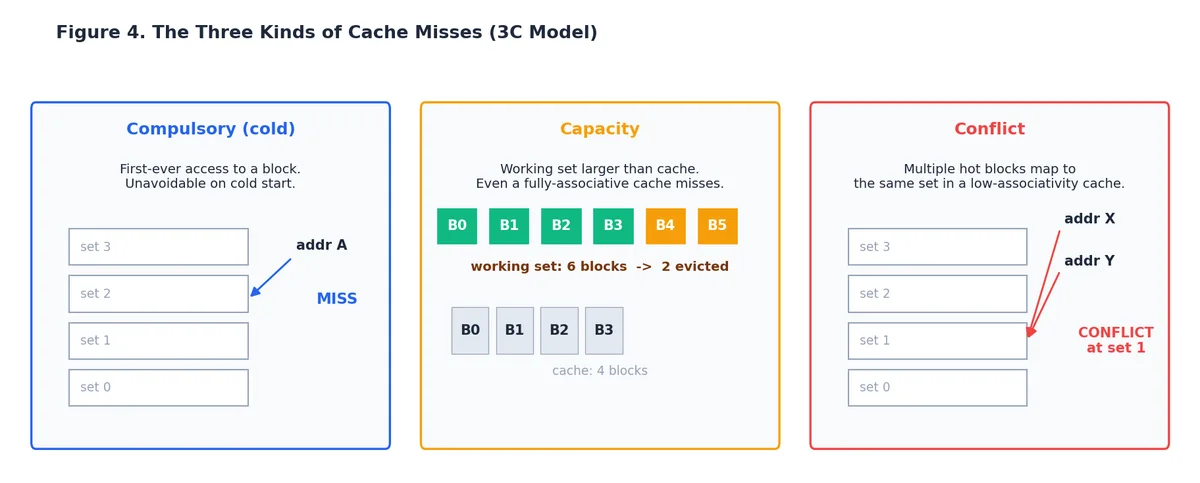
- 强制性未命中(冷启动):首次访问某数据块时必然发生。无法避免,但可通过预取隐藏延迟。
- 容量未命中:工作集大于缓存容量。即使完美管理的缓存也会失效。解决方法:缩小工作集(如分块/平铺),或使用更大缓存。
- 冲突未命中:低相联度缓存中,多个热点块争抢同一组位置。例如,两个地址相差恰好一个缓存组大小的数组会互相驱逐。解决方法:调整数据布局、填充数组,或依赖高相联度缓存。
现代 L1 缓存通常为 8 路相联,L2/L3 更高,因此纯冲突未命中已较少见,但在以 2 的幂为步长遍历数组的紧致循环中仍可能出现。
分支预测#
条件分支是流水线的噩梦:当 if (x > 0) 在 EX 阶段真正得出结果时,后续三四条指令早已按某条路径取入。若预测错误,所有在飞指令都被丢弃重取,现代核心中,一次误预测代价高达 15–20 周期。
经典方案是双比特饱和计数器,每个分支对应一个状态机:

其巧妙之处在于:单次异常不会立即翻转预测,需连续两次错误才改变方向。仅此一项,在典型负载下就能达到 ~93% 准确率。现代预测器(如 TAGE、感知机)通过记录近期分支历史,进一步将准确率推至 98% 以上,例如捕捉“外层循环走真,内层通常也走真”这类相关性。
如果你在 C++20 中见过 [[likely]] / [[unlikely]],或在 GCC 中用过 __builtin_expect,那就是你在帮编译器优化分支预测。
乱序执行#
即便分支预测完美,流水线仍会因数据依赖而停顿:一次 DRAM 加载需 ~90 ns(3 GHz 下约 300 周期),任何依赖该值的指令都必须等待。顺序执行核心只能干等,后续指令全被堵住。
乱序执行(OoO) 核心则更聪明:它将数十甚至上百条解码指令暂存于重排序缓冲区(ROB),只要操作数就绪,就立即调度执行,无视程序顺序。只要最终可见结果(寄存器状态、内存)与顺序执行一致,硬件可自由重排。
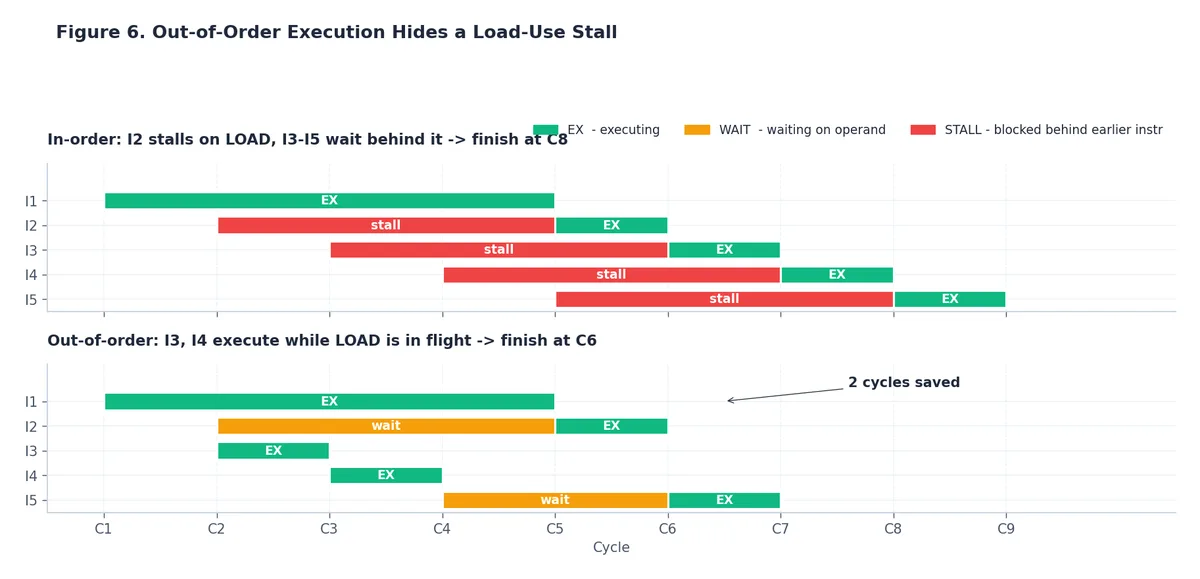
图中 I3 和 I4 不依赖那次加载。顺序核心会让它们在 I2 后等待;OoO 核心则趁加载飞行时提前执行它们。结果:6 周期而非 8 周期,这还只是小例子。在真实负载中,配合大 ROB(如 Apple M3 据传达 ~600 micro-op),性能提升显著且全自动,无需程序员干预。
这也解释了为何微基准测试常具误导性:若循环体含独立指令,CPU 会并行执行,你测到的是瓶颈单元的吞吐量,而非单操作延迟。
多核与 SMT(超线程)#
有两种方式增加并行性而不提升单核性能:
- 多核:复制前端、ALU、寄存器、L1、L2;仅共享 L3 和内存控制器。
- SMT(Intel 称 Hyperthreading):单物理核内维护两套架构寄存器,让两个软件线程共享同一组执行单元。

SMT 的关键直觉:当一线程因缓存未命中或分支误预测而停顿时,其执行单元闲置。SMT 让另一线程立即使用这些资源。在混合负载下,典型收益为 +20–30% 吞吐量,并非 2×,因为两线程共享 ALU、L1 缓存和执行端口。对于已饱和执行单元的纯计算负载(如紧致矩阵乘法),SMT 反而可能因增加缓存压力而拖慢性能,这也是 HPC 负载常禁用它的原因。
这终于解答了疑问 3。CS2 在 450 FPS 时,瓶颈不在核心数,引擎主线程才是关键。i5-13600K 的单线程性能优于 R9 7950X(更新的 P-core、更高睿频、更大 L2/core),而 7950X 的额外核心大多闲置。更多核心仅在工作可并行化时才有用,而游戏通常不可并行。
第三部分 —— 如何选择 CPU#
当下的 Intel 与 AMD 对比#
当前代际的主要权衡:
| 维度 | Intel(13/14 代酷睿) | AMD(Ryzen 7000 / 9000) |
|---|---|---|
| 单线程峰值 | 极高(P-core 睿频 ~6 GHz) | 极高(Zen 4/5 IPC 优秀) |
| 多线程吞吐 | E-core 扩展宽度 | 高核心数,对称设计 |
| 制程 | Intel 7 / Intel 4 | TSMC 5 nm / 4 nm |
| 平台寿命 | LGA 1700(支持 12/13/14 代) | AM5(承诺支持至 2027+) |
| 能效 | 高端型号较弱 | 整体更优 |
| 最佳场景 | 游戏、混合负载 | 内容创作、编译 |
按负载选型:
- 游戏:单线程最重要。中端 Intel i5/i7 或高睿频 Ryzen 7 是甜点。
- 视频剪辑、3D 渲染、大型编译:核心越多越好。选 Ryzen 9 或 Threadripper。
- 办公、网页、轻量开发:现代 4–6 核 CPU 性能绰绰有余。
- 服务器:AMD EPYC(96+ 核、12 通道 DDR5、更多 PCIe 通道)在密度和性价比领先;Intel Xeon 在特定加速负载(AMX、QAT)仍有优势。
位与 64 位:4 GB 墙从何而来?#
32 位地址总线可寻址 $2^{32} = 4\ \text{GiB}$ 。但 32 位 OS 必须将 RAM 和内存映射 I/O(显存、BIOS、PCIe 寄存器等)塞进同一空间。顶部 ~0.5–1 GiB 被 MMIO 占用,仅剩 ~3.0–3.5 GiB 给 RAM。这就是“装了 4 GB,Windows 显示 3.25 GB”的根源,唯一解法是迁移到 64 位 OS,其 $2^{64} \approx 16\ \text{EiB}$ 地址空间彻底终结此问题。
ECC、多路与服务器主频为何更低#
服务器 CPU 因负载不同而做出不同权衡:
- ECC 内存可检测并纠正单比特错误。在数千 DIMM 7×24 运行的服务器环境中,比特翻转频发;金融、科研、安全关键领域不可或缺。
- 多路架构允许多颗 CPU 共享一致内存视图,适用于超大数据库和虚拟化主机。
- 更多 PCIe 通道(64–128 vs 桌面 ~20)可驱动多 GPU、NVMe 盘和 100 GbE 网卡。
- 更低主频(全核 ~3 GHz vs 单核 5.8 GHz)以峰值频率换取持续负载下的能效与可靠性。桌面 CPU 是短跑选手,服务器 CPU 是马拉松跑者。
快速参考清单#
- 带宽用 bit,文件大小用 byte,别忘除以 8。
- 硬盘用 1000 进制,OS 用 1024 进制,标称 TB × 0.931 ≈ 实际 GiB。
- CPU 流水线理想是 1 IPC;缓存、分支预测、OoO 都为捍卫此目标。
- 内存延迟跨 八个数量级;缓存局部性通常是最大性能杠杆。
- 分支误预测耗 ~15–20 周期,DRAM 未命中耗 ~300;预测器与缓存旨在隐藏它们。
- SMT 通常带来 +20–30%,非 2×。
- 更多核心仅助益可并行工作;游戏通常不可并行。
推荐阅读#
- Hennessy & Patterson,《计算机体系结构:量化研究方法》,领域圣经。
- Bryant & O’Hallaron,《计算机系统:程序员视角》(CSAPP),本科经典。
- Agner Fog 优化手册,实战 x86 微架构细节。
- Intel® 64 和 IA-32 架构软件开发者手册。
- AMD64 架构程序员手册。
- WikiChip,现代微架构芯片图精准简洁。
下一步#
第二篇,内存与缓存层级,将探讨:
- DDR2 到 DDR5:哪些参数真正变快?
- 双通道 vs 四通道:实测数据。
- 缓存相联度、替换策略,及如何用
perf测缓存未命中。 - 内存排错:黑屏、蓝屏、MemTest86。
思考题:若 CPU 已有 L1/L2/L3 缓存,为何还需 DRAM?(提示:单位成本容量,SRAM 制造成本。)
附录 A —— 现代流水线的真实面貌#
教科书中的五级 RISC 流水线(取指→译码→执行→访存→写回)是 1990 年代产物。2025 年的 Zen 5 或 Lion Cove 核心更宽、更深、更复杂:
- 译码宽度 4–8:每周期最多译码 8 条 x86 指令。瓶颈常在前端取指,而非后端。
- 微操作缓存(μop cache):热循环可绕过译码器。若循环适配 μop 缓存,IPC 可达 ~6;溢出则跌至 ~2。
- ~600 条在飞指令:ROB 极大(Zen 5 约 448 项,Lion Cove 约 576)。CPU 持续投机执行未来 ~150 ns 的代码。
- 双整数重命名队列 × 4–6 ALU:“一个核心”内部实为小型分布式调度器。
- 200+ Load / 100+ Store 缓冲区:Store 写入 L1 需待退役,但 Load 可通过 store-to-load forwarding 提前获取。
教科书流水线仍能解释为何分支误预测代价高,但它没告诉你:现代核心上真实代价 ~16–20 周期,是因为 rename、调度器、ROB 等结构需全部清空重填。五级图让它看起来便宜;现实并非如此。
附录 B —— 在你的机器上试试这些命令#
每位工程师应掌握的三条命令。请在真实负载上运行,而非合成基准。
Linux,perf stat:
| |
关键指标:
- IPC(
instructions / cycles):低于 1.0 表示 CPU 饥饿;高于 2.0 表示前后端健康。 - 分支错误率 > 2%:热点分支难预测。
- 缓存未命中率 > 5%:工作集可能超 L2。
macOS,Instruments → Time Profiler / Counters 模板。Counters 模板暴露 Apple Silicon 计数器:INST_ALL、CYCLES、L1D_CACHE_MISS_LD、BRANCH_MISPRED_NONSPEC。指标同源,名称不同。
通用,taskset + time。将单线程基准绑定至单核,消除调度噪声:
| |
-r 5 运行五次,输出均值 ± 标准差。若标准差 > 5%,说明有其他进程干扰。
附录 C —— GPU 的独特之处#
GPU SM(流式多处理器)不是缩小版 CPU 核心,而是完全不同架构:
- 无分支预测:GPU 通过遮罩执行分支,两边都跑,错误结果丢弃。Warp 内发散分支直接减半吞吐。CPU 预测器在此无用,因 GPU 在此粒度无 per-thread PC。
- 无乱序执行:延迟靠切换 warp 隐藏,而非重排当前流。故 SM 可驻留 32–64 个 warp;CPU 仅处理一个线程流。
- 合并访存:32 线程 warp 发 32 次 load,仅当地址连续对齐时,硬件才合并为单次 128 字节事务。CPU 因缓存可容忍散乱访问;GPU 上同样模式可能浪费 32 倍带宽。
- 寄存器文件巨大:H100 SM 有 256 KB 寄存器,大于其 L1。CPU 寄存器仅几 KB。优化策略迥异。
实用结论:CPU 上表现好的代码,在 GPU 上可能因完全不同原因表现差。切勿照搬调优经验。


