
计算机基础(二):内存与高速缓存系统
从存储金字塔到 DRAM 单元、从虚拟内存到 TLB、从 ECC 到 NUMA 与多通道——一条指令背后的内存系统全景。
CPU 完成一次乘法运算大约只需 0.3 纳秒,而一块机械硬盘将磁头定位到目标扇区却需要 10 毫秒,两者相差约 3000 万倍。从多级缓存、DRAM 单元、页表、TLB、ECC、NUMA 到内存通道,整套内存子系统的设计,本质上都是对这一残酷不对称性的协同回应。

这是《计算机基础深度解析》系列的第 2 篇。我们不会止步于“DDR 很快,内存断电就丢”这类浅层认知,而是追踪一条 load 指令从 CPU 流水线出发,依次穿过 L1、L2、L3 缓存,经由 TLB 和页表完成地址转换,再通过内存控制器调度至对应通道,最终抵达 DRAM 芯片内部某个电容的全过程,并揭示每一层究竟在做什么,又为何如此设计。
系列导航#
📚 深入计算机基础系列(共 6 篇):
- CPU 与计算核心
- → 内存与缓存系统 ← 当前章节
- 存储技术(HDD、SSD、NVMe、RAID)
- 主板、GPU 与扩展接口(PCIe、USB、BIOS)
- 网络、电源管理与实际问题排查
- 综合实践:从指令到系统的全局视角
存储金字塔:为什么不能只靠一种“内存”解决问题?#
倘若存在一种既快又便宜、还能提供海量容量的存储介质,计算机架构就会简单得多,直接塞满一块即可。可惜,这样的理想介质并不存在。现实是:SRAM 速度极快但成本高昂、单位面积密度低;DRAM 密度高但访问较慢;NAND Flash 更密集且具备持久性,但速度进一步下降;机械硬盘虽便宜且容量巨大,却受限于机械运动的物理极限。存储金字塔正是在速度、密度、成本与持久性之间做出的工程折衷。
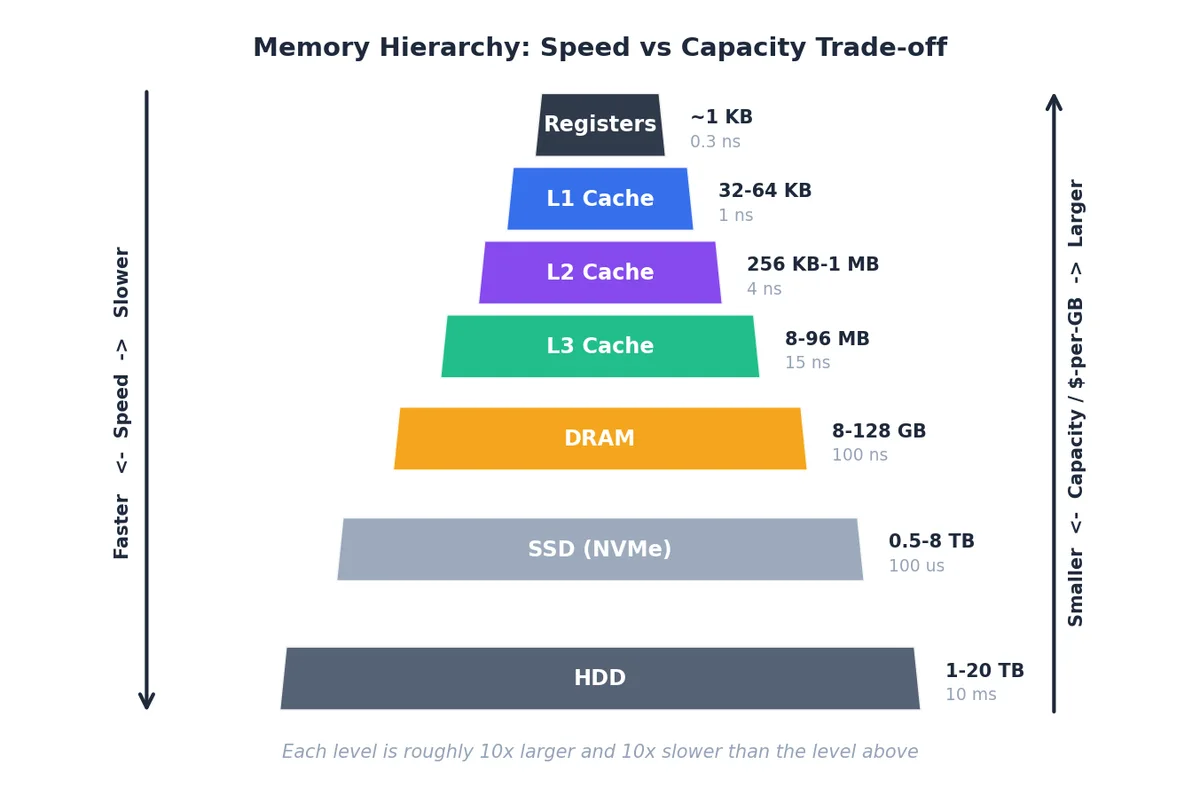
观察这张金字塔时,请记住一条经验法则:每向下一层,容量大约增加 10 倍,访问延迟也大约增加 10 倍。具体而言,CPU 寄存器访问约需 0.3 纳秒,L1 缓存约 1 纳秒,L2 约 4 纳秒,L3 约 15 纳秒,DRAM 约 100 纳秒,NVMe SSD 约 100 微秒,而机械硬盘则高达 10 毫秒。
为让这些数字更直观,不妨将其换算成“人类时间”:假设一次寄存器访问耗时 1 秒,则:
| 层级 | 实际时间 | 若寄存器访问 = 1 秒 |
|---|---|---|
| 寄存器 | 0.3 ns | 1 秒 |
| L1 缓存 | 1 ns | 3 秒 |
| L2 缓存 | 4 ns | 13 秒 |
| L3 缓存 | 15 ns | 50 秒 |
| DRAM | 100 ns | 5 分钟 |
| NVMe SSD | 100 µs | 4 天 |
| 机械硬盘 (HDD) | 10 ms | 1 年 |
每一次缓存未命中(cache miss)落到 DRAM,相当于把原本 1 秒能完成的操作拖成了泡杯咖啡的时间;而一次缺页中断(page fault)落到硬盘,则意味着 1 秒的任务变成了整整一年。正因如此,“多加点内存”或“换个更快的 SSD”并非万能解,真正决定性能的,是你工作集(working set)实际驻留在金字塔的哪一层。
DRAM 和 SRAM:为什么 CPU 的缓存设计得这么小?#
DRAM 与 SRAM 都利用晶体管和电压存储比特,但关键差异在于存储单元结构,而这一结构决定了密度、成本、速度、功耗,甚至解释了为何 DRAM 必须定期刷新。

DRAM = 1 个晶体管 + 1 个电容(1T1C)。每个比特以电荷形式存储在微型电容中。写入时,拉高字线(word line),通过位线(bit line)向电容充放电;读取时,同样拉高字线,由感应放大器检测电容是否带电。现代工艺下,单个 DRAM 单元面积仅约 $6 F^2$ (F 为最小特征尺寸),因此一颗 DDR5 芯片能在几平方毫米内集成 16 Gb 数据。
但高密度的代价是两个棘手问题:
- 电容会漏电。存储的电荷在毫秒级内自然流失,因此 DRAM 必须每约 64 毫秒执行一次刷新,即重新读出并写回所有数据,仅为了“记住”已有内容。这不仅消耗带宽,还增加功耗。
- 读取具有破坏性。感应放大器在检测电平时会抽走电容电荷,因此每次读取后必须立即重写数据以恢复原值。
SRAM = 6 个晶体管构成的交叉耦合锁存器(6T)。比特以两个反相器互馈形成的稳定状态存储。只要供电不断,数据便永久保持,无需刷新,读取无破坏,访问速度可达亚纳秒级。代价是单比特面积约为 DRAM 的 20 倍。这正是 CPU 每核仅有 64 KB L1 缓存,而非 64 GB 的根本原因。
这一权衡塑造了整个内存层次:CPU 在对延迟极度敏感的位置(寄存器、L1/L2/L3)使用 SRAM;外一层采用 DRAM 以换取密度;再往外则是 Flash 和磁盘,它们以速度为代价,换取持久性与超大容量。
CPU 缓存:三层架构的桥梁#
即便 DRAM 延迟已优化至 100 纳秒,对 CPU 而言仍慢了 300 倍。为掩盖这一延迟,现代 CPU 在芯片内集成 SRAM,用于缓存热点数据。缓存并非单一结构,而是一个微型分层体系。
| 层级 | 共享方式 | 典型容量 | 延迟 | 存储介质 |
|---|---|---|---|---|
| L1(分为 L1-I 和 L1-D) | 每核独占 | 各 32–64 KB | ~1 ns / 4 周期 | SRAM |
| L2 | 每核独占(或双核共享) | 256 KB – 2 MB | ~4 ns / 12 周期 | SRAM |
| L3(LLC) | 所有核共享 | 8 – 96 MB | ~15 ns / 40 周期 | SRAM |
| DRAM | 芯片外 | 8–128 GB | ~100 ns | DRAM |
缓存命中率逐层叠加。若 L1 命中率 95%,L2 对 L1 未命中部分命中率 85%,L3 对剩余未命中部分命中率 70%,则平均延迟可大幅降低:
| |
相比每次都访问 DRAM,整体速度提升约 70 倍。缓存层次的核心目标,就是让 99% 的内存访问表现得如同 L1 访问,同时让系统“假装”拥有 32 GB 内存。
为何是三级而非两级或四级? 每增加一级,流水线就需多一次标签检查。两级会导致 L2 到 DRAM 的延迟跳跃过大(约 25 倍);四级则引入过多复杂性而收益有限。三级是当前技术下的经验最优解,尽管 AMD 已通过 3D V-Cache 技术将 L3 推至 96 MB,正在挑战这一边界。
虚拟内存:每个进程都有自己的地址空间#
此前讨论的均为物理地址,即 DRAM 中的实际位置。但在现代系统中,没有任何用户态进程能直接看到物理地址。程序运行在虚拟地址空间中,硬件在每次内存访问时自动完成虚拟到物理地址的转换。

转换以固定大小的页(page)为单位进行,通常为 4 KB。一个 64 位虚拟地址被拆分为:
- 虚拟页号(VPN):标识程序中的哪一页?
- 页内偏移(Offset):标识该页内的哪个字节?
操作系统为每个进程维护一张页表,将 VPN 映射到物理帧号(PFN)。每次 load/store 操作时,硬件执行以下步骤:
- 拆分虚拟地址为 VPN 和 Offset;
- 遍历页表查找对应 PFN;
- 拼接 PFN 与 Offset 得到物理地址;
- 将物理地址发往内存控制器。
此举一举四得:
- 隔离性:进程 A 无法意外或恶意访问 B 的内存,因其页表映射至不同物理帧;
- 大内存幻觉:页表可标记某页“不在内存”,触发缺页异常,由 OS 从磁盘加载,即交换(swapping);
- 共享:多个进程可通过映射相同物理帧共享库代码;
- 权限控制:页表项含读/写/执行位,由硬件强制执行,构成 OS 安全基石。
代价是:每次访问都需查页表,而页表本身也在内存中。x86-64 采用四级页表,一次 TLB 未命中最多需 4 次额外 DRAM 访问,耗时数百纳秒。这正是 TLB 存在的意义。
TLB:你可能没听过,但每个 CPU 都离不开的关键缓存#
TLB(Translation Lookaside Buffer,地址转换后备缓冲区)是一种极小、全相联的 SRAM 缓存,用于存储近期使用的 VPN → PFN 映射。每个 CPU 至少有一个 TLB(常分 L1 和 L2 两级),容量通常在 64 至 1024 条目之间。

当 CPU 发出虚拟地址时:
- TLB 命中(约 99%):翻译结果 1 周期内返回,CPU 直接访问缓存或 DRAM,开销几乎为零;
- TLB 未命中(约 1%):硬件(或某些架构下由软件)遍历页表。x86-64 最多需 4 次内存读取(100–400 纳秒),结果随后填入 TLB 供后续快速访问。
TLB 是虚拟内存可行的关键。99% 命中率下,平均翻译开销仅 ~1 纳秒;若无 TLB,则每次访问均需 ~100 纳秒。多数负载甚至察觉不到虚拟内存的存在。但 TLB 未命中也是某些负载性能骤降的元凶,如大规模随机工作集的应用(部分数据库、图算法、特定 ML 推理)。其实际性能往往比缓存未命中率暗示的更差。为此,大页(Huge Page,2 MB 或 1 GB)应运而生:单条 TLB 条目可覆盖 512 倍于 4 KB 页的内存,显著缓解 TLB 压力。
内存通道:为什么两条 8GB 比一条 16GB 更高效#
DRAM 通过内存通道(memory channels)连接 CPU。每通道是一条独立的 64 位数据路径,配有专属命令/地址总线。现代桌面 CPU 通常有 2 通道,服务器 CPU 则可达 4、8 甚至 12 通道。
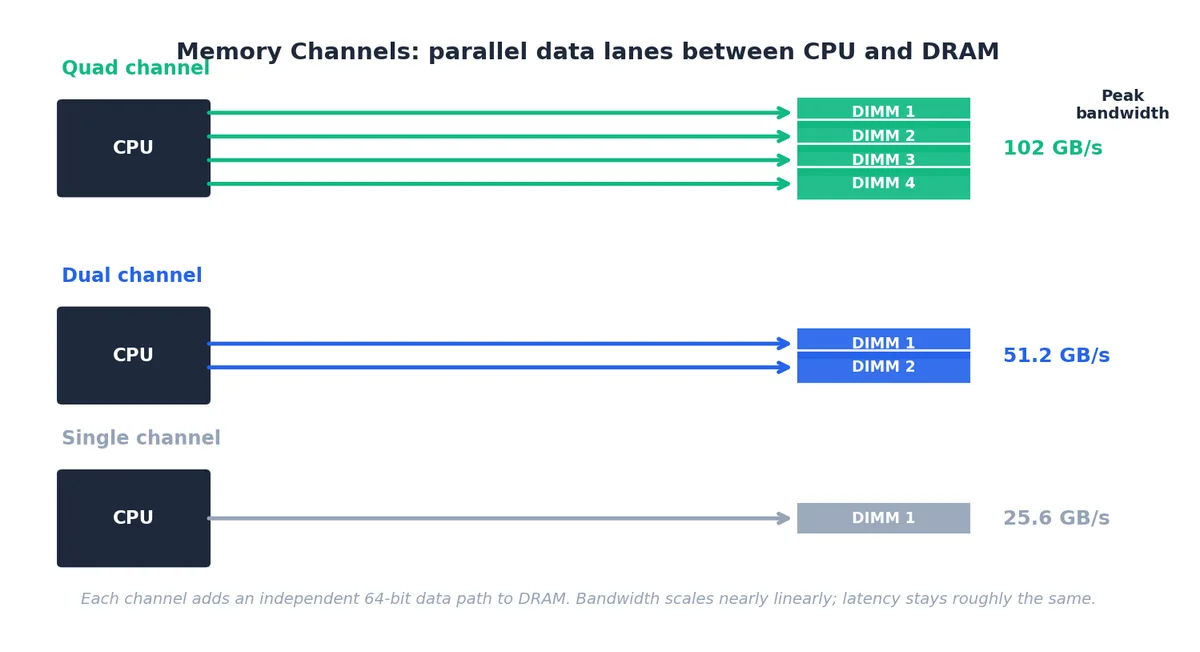
各通道可并行传输,因此峰值带宽近乎随通道数线性增长:
| 配置 | 通道数 | 单通道速率 | 总带宽 |
|---|---|---|---|
| 单通道 DDR4-3200 | 1 | 25.6 GB/s | 25.6 GB/s |
| 双通道 DDR4-3200 | 2 | 25.6 GB/s | 51.2 GB/s |
| 四通道 DDR5-4800 | 4 | 38.4 GB/s | 153 GB/s |
| 12 通道 DDR5-4800(Sapphire Rapids) | 12 | 38.4 GB/s | 460 GB/s |
延迟并未改善,单次访问仍约 100 纳秒。真正提升的是可并发处理的独立请求数量,这对以下场景至关重要:
- 多核负载(每核需独立内存流量);
- GPU 类内存密集型任务(渲染、视频、科学计算);
- 大数组流式访问。
这也解释了为何 “2 × 8 GB 优于 1 × 16 GB”:单条内存仅能填充一通道,总带宽减半。在主流 Intel/AMD 桌面平台,通常需插入 A2 + B2 插槽以启用双通道。
ECC 内存:当宇宙射线变成故障报告#
DRAM 可靠但非完美。封装材料释放的 α 粒子、宇宙射线中的中子、电磁噪声均可导致位翻转。Google 2009 年的大规模实测发现,DRAM 错误率远高于厂商宣称,平均每 GB 每年发生一次可纠正错误,部分模块甚至高出数个数量级。
对游戏 PC,未检出的位翻转或许仅导致偶发崩溃;但对拥有数十亿记录的数据库,这意味着静默数据损坏并污染备份。
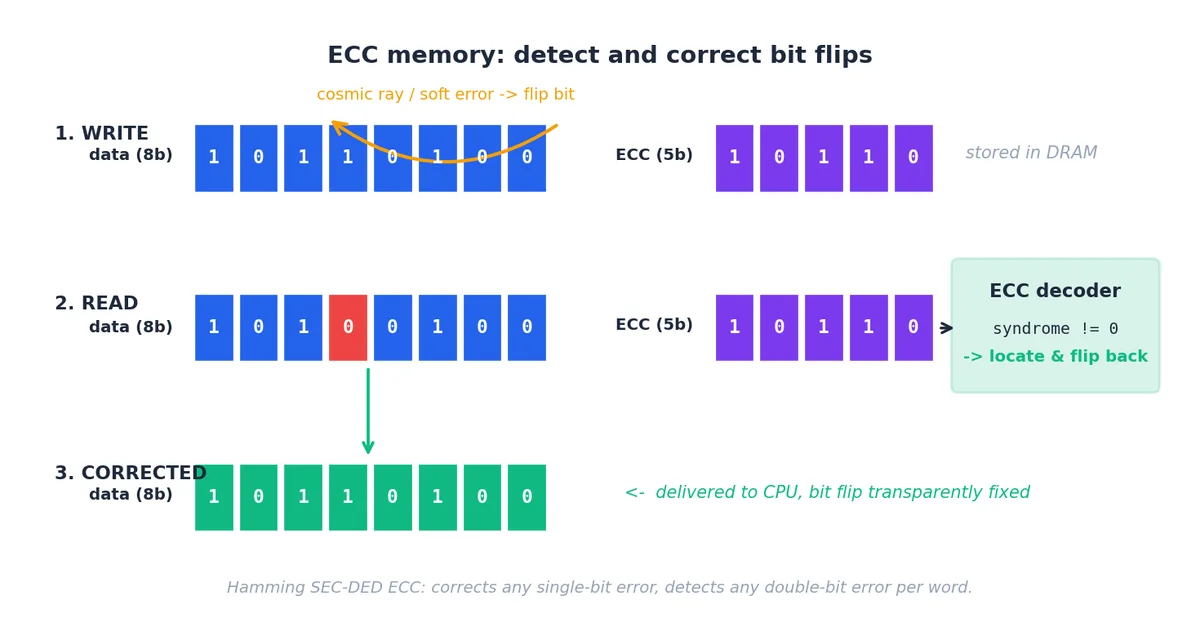
ECC 内存为每 64 位数据添加 8 位校验码,采用 Hamming SEC-DED 编码:
- SEC(单错纠正):任意单比特翻转可被检测并静默修复,CPU 始终看到正确数据;
- DED(双错检测):双比特翻转可被检测(但不修复),触发 OS panic 而非返回错误数据。
代价包括:
- 成本:硅面积增约 12%(72 位存 64 位),ECC DIMM 零售价高 30–50%;
- 性能:编解码引入微小延迟(现代控制器上可忽略);
- 兼容性:多数消费级 CPU(Intel Core、大部分 Ryzen)禁用 ECC;仅 Xeon、EPYC、Threadripper Pro、Apple Silicon 支持。
经验法则:若一位翻转会引发 bug 报告而非不便,就需 ECC。服务器、NAS、金融/CAD/科研工作站,必备;纯游戏台式机,通常不必。
DDR5 引入 on-die ECC,但仅保护芯片内部错误,无法覆盖 CPU 与芯片间的总线。要防护此段,仍需传统 ECC DIMM。
NUMA:内存也有“地界”#
当主板搭载双 CPU 插槽,或单 CPU 集成多 chiplet 时,内存访问变得非统一(NUMA)。每插槽拥有独立内存控制器及本地 DRAM。访问本地内存快;访问远程内存需经插槽间互连(Intel UPI、AMD Infinity Fabric)。

典型双路服务器上,本地访问约 80 纳秒,远程经 UPI 约 140 纳秒,慢 1.7 倍,且互连带宽有限。四路或八路系统中,最坏延迟比可达 3 倍以上。
实际影响包括:
- OS NUMA 感知:Linux 调度器尽量将线程绑定至其内存所在插槽,并优先分配本地内存(
numactl、mbind、set_mempolicy); - 分配器 NUMA 感知:glibc/jemalloc/tcmalloc 使用每线程 arena 保持分配本地化;
- 数据库 NUMA 感知:Postgres、MySQL、ClickHouse、Spark 均提供绑定选项;
- 忽视 NUMA 可致 30–60% 吞吐损失,即使负载本应随核心线性扩展。
即便单插槽现代 CPU 也存“类 NUMA”效应:AMD chiplet(CCD)架构中,跨 CCD 访问 L3 缓存数据需经 IO Die,延迟更高。核心启示普适,内存具有拓扑结构,优秀系统软件必尊重之。
DDR 代际演进:每一代的核心变化是什么#
每代 DDR 大致实现带宽翻倍、电压降低。真正关键的是如何实现。
| 代数 | 年份 | 每针速率 | 单通道峰值 | 电压 | 核心架构改进 |
|---|---|---|---|---|---|
| DDR | 2000 | 200–400 MT/s | 1.6–3.2 GB/s | 2.5 V | 时钟双沿传输 |
| DDR2 | 2003 | 400–800 MT/s | 3.2–6.4 GB/s | 1.8 V | 4n 预取(内部总线宽为 I/O 两倍) |
| DDR3 | 2007 | 0.8–2.1 GT/s | 6.4–17 GB/s | 1.5 V | 8n 预取、fly-by 拓扑 |
| DDR4 | 2014 | 1.6–3.2 GT/s | 12.8–25.6 GB/s | 1.2 V | Bank Group 提升并行度 |
| DDR5 | 2020 | 4.8–8.4 GT/s | 38.4–67.2 GB/s | 1.1 V | 每 DIMM 拆为两个 32 位子通道,on-die ECC,on-DIMM PMIC |
DDR5 最关键革新是将 64 位 DIMM 拆为两个独立 32 位子通道。外部看似双通道,内部实为四通道。这使 DDR5 对多核负载提升尤为显著,控制器可在单 DIMM 上并发处理两倍请求。
DDR6(标准化中)目标速率达 8.8–17.6 GT/s,并计划每 DIMM 支持四个子通道。
常见问题#
Q1. 缓存已将内存访问延迟降至“平均 ~1 ns”,为何内存速度仍重要?#
因平均值掩盖尾部延迟。缓存未命中至 DRAM 仍需 ~100 ns,而工作集超出 L3 的负载(大型数据库、大数组、ML 模型)会持续触发未命中。更快 RAM(更高 MT/s、更低 CL)可降低未命中惩罚;双通道则加倍未命中处理速率。DDR4-3200 升级至 DDR4-3600 带来的 5–15% 游戏帧率提升,几乎全源于此。
Q2. 频率和 CL 时序,哪个更重要?#
看实际纳秒延迟:ns = CL × 2000 / MT/s。DDR4-3200 CL16 与 DDR4-3600 CL18 首字延迟均为 10 ns,后者带宽更高,显然更优;而 DDR4-3600 CL16(8.9 ns)则全面胜出。经验法则:频率提升利好带宽敏感负载,时序优化利好缓存未命中密集负载。多数用户推荐 DDR4-3600 CL16 或 DDR5-6000 CL30。
Q3. DDR5 带宽翻倍,为何感觉不到“快一倍”?#
因多数消费负载非带宽瓶颈,它们受限于延迟或计算能力。游戏通常在喂饱单通道 DDR4-3200 前就遇 CPU/GPU 瓶颈。DDR5 真正发力于:(1) 多核生产力(编译、编码、仿真);(2) 共享内存的核显;(3) 核心数持续增长的未来负载。若你已带宽受限,性能分析工具早已揭示。
Q4. “内存不足”到底发生了什么?#
内核按严重性依次采取三措施:
- 回收页缓存:OS 用空闲内存作文件缓存,压力上升时优先丢弃旧缓存页。代价:后续磁盘读错过缓存。
- 换出匿名页:无文件支持的页(堆、匿名 mmap)写入 swap。下次访问触发 major page fault,需从磁盘读回。代价:NVMe SSD 上约 ~10 ms/次,延迟尾部剧增。
- OOM killer:若 swap 亦不足,内核杀进程。Linux 选择大致与内存占用成正比。
故“8 GB 够用,我有 SSD”仅半对:SSD 可缓解 swap 痛苦,但无法掩盖你已跌出 DRAM 层的事实。
Q5. 为何多核系统中“缓存一致性”如此重要?#
每核有独立 L1/L2 缓存,但共享逻辑内存视图。若核 0 将 x=1 写入 L1,而核 1 缓存中仍有 x=0,硬件必须检测并使其他副本失效或更新。标准协议为 MESI(Modified, Exclusive, Shared, Invalid),由硬件实现并通过 L3/目录跟踪。
性能杀手是 伪共享(false sharing):两线程写入不同变量,但变量恰在同一 64 字节缓存行。任一写入均使对方缓存失效,尽管逻辑无共享。解决方法是将每线程热数据对齐至完整缓存行。此改动可在竞争计数器/无锁队列上带来 3–10 倍加速。
Q6. 什么是“内存序”?为何要关注?#
现代 CPU 为保持流水线繁忙,会大幅重排 load/store。只要单线程视角一致,硬件可任意重排。但跨线程时,一核所见写入顺序未必是另一核实际执行顺序。x86 提供较强模型(TSO,仅 store buffer 引入例外);ARM/PowerPC 则弱得多。故并发代码需用内存屏障、原子操作、acquire/release 语义,强制硬件按算法要求顺序发布写入。几乎所有“x86 正常、ARM 崩溃”的 bug,本质都是内存序问题。
Q7. 为何服务器需如此多内存通道?#
服务器 CPU 通常带宽受限。96 核 EPYC 运行内存数据库时持续拉取新数据,单通道远不能满足。12 通道 DDR5-4800 提供 ~460 GB/s,即便如此仍常成瓶颈。同理适用于 GPU,故 HBM(高带宽内存)将 8–12 层 DRAM 堆叠于硅中介层,提供 ~3 TB/s 带宽。
Q8. 如何诊断程序是否内存受限?#
Linux 上三快速信号:
perf stat -e cache-misses,cache-references,LLC-loads,LLC-load-misses ./prog,LLC miss 率 >10% 通常意味 DRAM 受限;perf stat -e dTLB-load-misses,iTLB-load-misses,高 TLB miss 暗示大页可助益;toplev(pmu-tools)top-down 分析,直接归因停顿至“后端/内存瓶颈”、“前端瓶颈”等,确认瓶颈是否真在内存。
若确为内存带宽瓶颈,可尝试:算法分块(blocking/tiling)适配缓存、NUMA 绑定、大页、预取提示,或极端情况下改用更友好数据布局(SoA vs AoS)。
下期内容预告#
在 《计算机基础(3):存储系统》 中,我们将继续追踪数据流向:深入 SSD 内部,控制器与 FTL 机制、SLC/MLC/TLC/QLC 权衡、NVMe 队列与 PCIe 通道、RAID 与纠删码,并探讨为何存储栈正成为系统中最迅猛演进的一层。敬请期待!
总结#
- 内存层次存在,因无单一技术兼具高速与高密度。SRAM 快而贵(缓存),DRAM 密而慢(主存),Flash/磁盘更密且持久。
- 一条 load 指令悄然穿越:寄存器 → L1 → L2 → L3 → 内存控制器 → 通道 → DRAM rank/bank/row/column,同时经 TLB 与页表完成地址转换。
- 缓存借时空局部性,将 DRAM 平均延迟从 100 ns 压至 ~1 ns。L1/L2/L3 命中率层层叠加。
- 虚拟内存赋予每进程独立地址空间,硬件保障隔离、共享与按需分页。TLB 使其开销可承受。
- DDR 代际演进持续翻倍带宽、降低电压。DDR5 核心创新在于每 DIMM 双子通道、on-die ECC 与 on-DIMM 电源管理。
- 通道数近乎线性提升带宽。务必启用双通道;高性能场景应插满所有通道。
- ECC 将静默损坏转为可记录事件。服务器必备,桌面可选。
- NUMA 表明内存具拓扑:本地快,远程慢。现代 OS/运行时高度重视,多插槽/chiplet 系统尤需关注。


