
计算机基础(四):主板、显卡与扩展
看懂主板布局、理清 CPU 直连与芯片组域的 PCIe 通道分配、理解 GPU 的 SIMT 执行模型、对比 DDR/GDDR/HBM 显存,以及挑对显示接口。
桌面主板是一种相当“诚实”的产品:CPU 提供的 PCIe 通道数量、哪些插槽直连 CPU、哪些经由芯片组、为支持 250 W 处理器配置的 VRM 相数,以及第二根 PCIe 长插槽为何实际仅支持 ×4,这些关键设计决策都清晰地写在 PCB 上。只要能读懂主板布局,你几乎就能预判用户会遇到的每一处性能瓶颈。本系列第四篇将系统讲解这套“读板”方法,并将同一分析视角延伸至显卡:GPU 架构设计的核心目标是让成千上万条计算通路持续获得数据供给,而缓存、调度器、Tensor Core 和 HBM 堆栈等组件均服务于这一目标。

系列导航#
计算机基础深度剖析系列(共 6 篇)
- CPU 与计算核心
- 内存与高速缓存
- 存储系统详解
- → 主板、显卡与扩展接口(PCIe、 GPU、显示输出、芯片组) ← 当前章节
- 网络、供电与实际问题排查
- 深度扩展与附录
第一部分 — 看懂主板设计#
主板不是简单的总线,而是一种分域架构:CPU 直连的高性能资源构成一个区域,其余外设则归入另一个由芯片组管理的区域,两者通过一条高速链路互联。CPU 直接掌控少量高性能资源,如 PCIe 通道和 DDR 内存通道,这些属于直连域;而其他部分都挂在另一个区域,由芯片组(Intel 称为 PCH,AMD 称为 FCH)管理,包括额外的存储插槽、USB 控制器、SATA 接口以及芯片组自身的 PCIe 通道。两个区域之间的通信依赖于一条链路:Intel 使用 DMI 4.0 ×8,单向带宽约 16 GB/s;AMD 则采用规格相近的 PCIe ×4 链路。这条链路是整块主板的关键瓶颈,因为所有挂载在芯片组上的设备都在争夺其带宽。

以下是五个值得关注的核心区域:
- CPU 插槽与 VRM 模块。LGA 1700 和 AM5 插槽在满载时功耗可达 250 W。围绕 CPU 的那一排 MOSFET 和电感就是 VRM 模块,负责将 EPS 8-pin 提供的 12 V 转换为 CPU 核心所需的 1.0–1.4 V。如果主板的 VRM 相数不足,无法满足高端 CPU 的需求,会导致长时间高负载下降频的问题,这也是许多差评的主要原因。
- DIMM 内存插槽。消费级主板通常支持双通道(A1/A2 + B1/B2)。若仅安装 A2 和 B2 插槽(通常为距 CPU 最远的两根),可启用双通道模式;但若仅安装 A1 和 A2,则系统将降为单通道,带宽减半。由于 DDR5 内存模组已集成电源管理集成电路(PMIC),主板无需再为内存提供多相供电,因此 DDR5 主板的内存供电相数明显少于 DDR4 时代。
- 第一根 PCIe 长插槽。这根插槽直接连接到 CPU 的 PCIe 根复合体,在 Z790/X670E 主板上支持 PCIe 5.0 ×16。显卡应该优先插在这里,因为它提供全带宽且无需经过芯片组。
- M.2_1 插槽。几乎总是直连 CPU (PCIe ×4),这是主板上速度最快的 NVMe 插槽。
- 芯片组及其下游设备。第二根 PCIe 长插槽、 M.2_2 插槽、 SATA 接口、后置 USB 接口、 Wi-Fi 模块和声卡等设备,全都位于 DMI 链路的芯片组一侧。
从这里可以得出两个实用结论。其一,第二根物理 ×16 插槽通常并非真正的 ×16,在 B760/B660 主板上,它通过芯片组以 ×4 模式运行,并与 USB 和 SATA 共享带宽。虽然可以安装第二张显卡并正常工作,但其带宽受限,实际性能明显低于第一插槽。其二,使用 M.2_2 插槽往往会禁用两个 SATA 接口,因为芯片组在这几条通道上做了多路复用。具体禁用哪些接口,主板说明书会有详细说明。
如何确认你实际使用的 PCIe 插槽是否为 ×16#
你购买了一块标称支持 PCIe 5.0 ×16 的主板,但如何确认显卡实际运行在 ×16 电气规格下?在 Windows 系统上,最简单的方法是使用 GPU-Z。查看 Bus Interface(总线接口)字段,它会显示当前协商的带宽和代际信息,例如 PCIe x16 5.0 @ x16 5.0,这就表示插槽确实运行在 PCIe 5.0 ×16 模式下。
而在 Linux 系统中,可以通过命令 lspci -vv | grep -i lnk 来检查。输出中的 LnkCap 表示插槽的理论能力,而 LnkSta 则是实际协商后的结果。如果 LnkSta 显示的带宽比 LnkCap 更窄或者版本更低,那就说明某些下游因素导致了性能降级:延长线质量不佳、 BIOS 设置不当,或者插槽被错误使用。
第二部分 — PCIe 代际与通道分配#
PCIe 是一种通用扩展总线,其性能主要由两个参数决定:代际(决定了每条通道的带宽)和位宽(即聚合了多少条通道)。每一代 PCIe 几乎都会将单通道的传输速率翻倍。因此,一个 Gen 4 ×4 的 NVMe SSD 和一个 Gen 3 ×8 的设备在理论带宽上是相当的。

| 代际 | 年份 | 单通道(GB/s) | ×4 (NVMe) | ×16 (GPU) |
|---|---|---|---|---|
| PCIe 2.0 | 2007 | 0.5 | 2 | 8 |
| PCIe 3.0 | 2010 | 1.0 | 4 | 16 |
| PCIe 4.0 | 2017 | 2.0 | 8 | 32 |
| PCIe 5.0 | 2022 | 4.0 | 16 | 64 |
| PCIe 6.0 | 2025 | 8.0 | 32 | 128 |
表中的数据是单向传输的带宽;由于 PCIe 是全双工的,双向带宽还需要再乘以 2。不过,这里采用的是单向带宽的统计方式,因为工具如 GPU-Z 和 lspci 报告的也是这个值。
需要明确的关键点是:目前消费级显卡还远未达到 PCIe 4.0 ×16 的带宽上限。 比如 RTX 4090 在持续游戏负载下的平均带宽约为 22 GB/s,这远低于 Gen 4 的 32 GB/s 理论上限。相比之下, PCIe 5.0 的优势先体现在 NVMe SSD 上。一块 Gen 4 ×4 的硬盘已经能跑到 7 GB/s 的极限,而 Gen 5 直接把这一上限翻倍。如果你今天要在这两者之间做选择,建议优先为支持 Gen 5 的 NVMe 配置买单,而不是急于追求 Gen 5 显卡的支持。
CPU 提供的通道资源远比芯片组有限#
一颗普通消费级 CPU 通常只提供 20 条 PCIe 5.0 通道:其中 16 条分配给显卡插槽, 4 条留给主 M.2 接口。这已经是 CPU 直接连接设备的全部资源了。其他外设则需要通过芯片组连接,而芯片组会进一步扩展出更多 PCIe 4.0 通道(例如 Z790 芯片组通常能提供 20 条以上)。但问题在于,这些下游设备共享一条通往 CPU 的 DMI 链路,带宽上限仅为 16 GB/s。这种设计在日常使用中可能毫无压力,但一旦你在芯片组后端同时运行两块 NVMe 固态硬盘和一张 10 GbE 网卡, DMI 带宽就会迅速耗尽,导致所有设备性能同步下降。
这就是为什么工作站级平台(如 Threadripper 和 Xeon-W)价格如此昂贵的原因:它们直接从 CPU 提供 64 条甚至更多的 PCIe 通道,完全避免了共享瓶颈的问题。
不同设备对带宽的实际需求#
| 设备 | 实际位宽 | 持续带宽 | 推荐插槽位置 |
|---|---|---|---|
| 现代显卡(RTX 4090 / RX 7900 XTX) | ×16 | 18–22 GB/s | 第一条全长插槽,直连 CPU |
| NVMe Gen 5 SSD | ×4 | 12 GB/s | M.2_1 插槽,直连 CPU |
| NVMe Gen 4 SSD | ×4 | 7 GB/s | 任意支持 ×4 的 M.2 插槽 |
| 10 GbE / 25 GbE 网卡 | ×4 (25G 需要 ×8) | 1.25–3.1 GB/s | 任意空闲的 ×4 或更高插槽 |
| 采集卡 / USB 4 扩展卡 | ×4 | 最高 5 GB/s | 任意空闲的 ×4 或更高插槽 |
| 声卡、 USB 2 集线器 | ×1 | <0.5 GB/s | 任意 ×1 插槽 |
总结:对于一台单显卡 + 双 NVMe 的游戏主机来说, B660/B650 主板的带宽已经绰绰有余。选择 Z790/X670E 并不是为了提升显卡性能,而是为了获得第二个直连 CPU 的 M.2 插槽、为 K 系列 CPU 提供更强供电能力的 VRM 相数,以及更丰富的后置 I/O 接口(如 USB 3.2 Gen 2×2 和 2.5 GbE)。
第三部分 — 从南北桥到 PCH:芯片组的瘦身之路#
2025 年你能买到的主板,上面的大芯片数量大概只有 2005 年的一半。这可不是为了省钱,而是因为高速功能模块逐渐被整合进 CPU 封装里,芯片组只剩下处理那些低速但繁杂的任务。
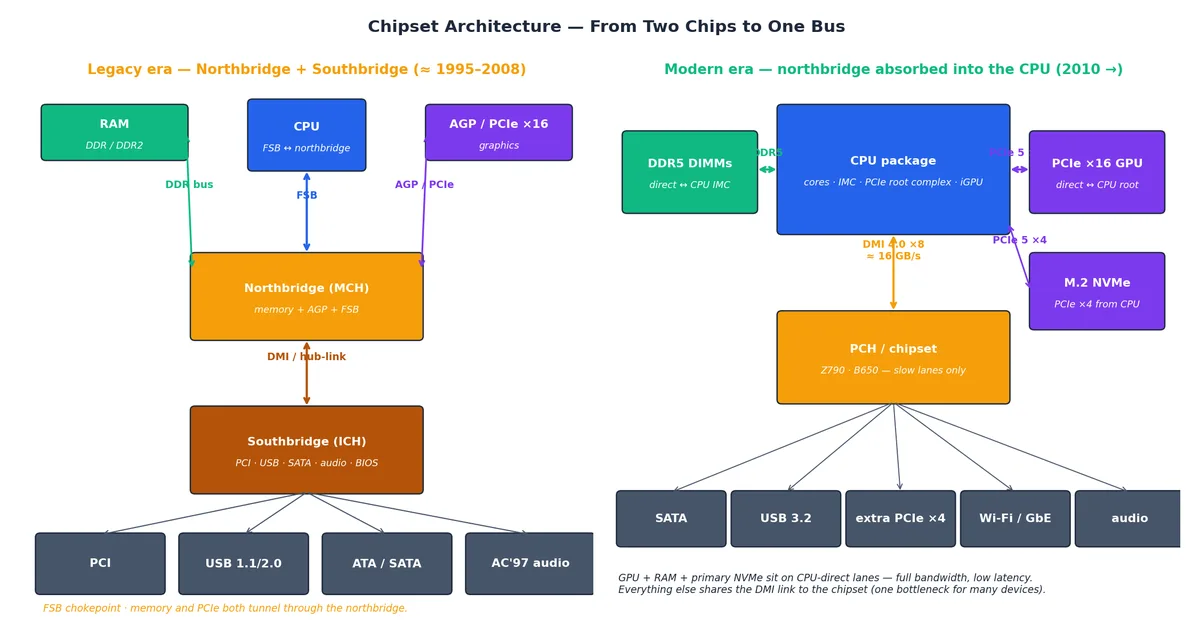
在早期设计中(左图), CPU 通过 前端总线(FSB) 连接到 北桥,北桥里集成了内存控制器和 AGP/PCIe ×16 链路;而 南桥 则通过一条较慢的 hub-link 挂在北桥下面,负责 USB、 SATA、 PCI 和音频等功能。当时,内存带宽受制于 FSB 的瓶颈,北桥发热量大到必须单独配一个散热片。
到了现代设计(右图), CPU 封装内部已经集成了 内存控制器(IMC)、PCIe 根复合体、核显(iGPU),以及一大块 L3 缓存。内存和显卡现在可以直接与 CPU 通信,不再需要中间商赚差价。芯片组(Intel PCH、 AMD FCH)的角色则被弱化为“分发中心”:它接收来自 CPU 的 DMI ×8 上行链路,然后将其扩展为一堆 PCIe 4.0 ×1/×4 通道、 SATA 接口、 USB 控制器和 Wi-Fi 模块。由于功耗极低,它通常连散热片都不需要,顶多加个薄薄的金属罩来提升颜值。
这种架构调整带来的好处显而易见:直连 CPU 的设备(如显卡、主 NVMe 固态硬盘、内存)能够享受满血带宽和最低延迟;同时,那些速度较慢但数量众多的外设也能在芯片组的管理下和谐共存。不过,代价是这些外设共享的带宽有上限。这也是“DMI 链路是主板上最重要的参数”这句话的由来。
第四部分 — 深入 GPU: SIMT、 Warp 与流式多处理器#
CPU 和 GPU 都是“处理器”,但它们的设计目标却截然不同。 CPU 的核心任务是尽可能快地完成单线程任务:缓存、分支预测、乱序执行、深度流水线等技术,都是为了这一目标而存在的。而 GPU 的设计哲学则是让成千上万条计算通路始终保持忙碌,即使某一条通路因为等待内存而暂时闲置也无妨。这种设计理念背后的核心架构模型被称为 SIMT (Single Instruction, Multiple Threads,单指令多线程)。

从底层到顶层, GPU 的架构可以这样理解:
- CUDA lane (NVIDIA)或流处理器 lane (AMD) 是一个浮点运算单元(ALU),每个时钟周期处理一次算术操作中的一个元素。
- Warp 是由 32 条 lane (NVIDIA)或 32–64 条 lane (AMD 称为 wavefront)组成的一个执行单元,这些 lane 以同步的方式执行同一条指令,但处理的数据各不相同。这就是 SIMT 的精髓所在: 32 条 ALU 只需要一个指令解码器。
- 流式多处理器(Streaming Multiprocessor, SM) 是 GPU 的核心组件,负责管理大量 warp 的并发执行。它配备了寄存器堆、 L1/共享内存以及一个 warp 调度器。调度器会在每个时钟周期选择一个就绪状态的 warp 执行;当某个 warp 因等待内存而停滞时,调度器会切换到其他 warp。这种机制被称为通过并行性隐藏延迟,也是 GPU 最核心的能力所在。
- GPU 芯片整体 将 40–144 个 SM 通过共享的 L2 缓存(现代芯片通常为 32–96 MB)连接在一起,并通过一条高带宽总线与片外内存通信。
在现代 SM 中,还集成了两类专用核心:
- Tensor 核心(NVIDIA)/ AI 加速器(AMD) 专门用于加速小规模矩阵乘加运算。一个 Tensor 核心每周期可以完成一次 $4 \times 4$ FP16 矩阵乘法(matmul),这正是 DLSS、 Stable Diffusion 和 LLM 推理在 RTX 显卡上比单纯依赖 CUDA 核心快得多的原因。
- RT 核心 则通过硬件加速光线与三角形、光线与包围盒的相交测试。如果没有 RT 核心,光线追踪任务将回退到通用着色器执行,性能会下降一个数量级。
在 GPU 的规格表中,那些令人眼花缭乱的数字,例如 RTX 4070 上的 “5888 个 CUDA 核心” 或 RTX 4090 上的 “16384 个核心”,其实只是 SM 数量乘以每个 SM 中的 lane 数。真正值得关注的是 SM 的数量,因为这才是决定有多少独立调度器能够帮你隐藏内存延迟的关键指标。
第五部分 — CPU 和 GPU:到底该选谁?#
一旦搞清楚了 SIMT 模型,你就不会再纠结“CPU 和 GPU 谁更快”这种问题了,而是会思考“这活儿到底是什么性质”。其实就看两个关键点:
- 任务独立性。这个任务能不能拆成一堆互不依赖的小块?像像素着色、矩阵乘法、稠密神经网络推理这类工作就很适合。但如果是树形遍历、逻辑复杂的分支判断,或者单文件压缩,那就不行。
- 任务规模。活儿够不够多,能不能摊平 GPU 的启动成本?调用一次 CUDA kernel 的端到端开销大约在 5–50 µs 左右。如果你的任务在 CPU 上跑完还不到 1 毫秒,硬塞给 GPU 反而会拖慢速度。

右边的图表展示了性能的交叉点。当任务量低于约 250 个独立单元时, 8 核 CPU 通常更快,因为 GPU 的启动开销占了大头;超过这个数量, GPU 的并行优势就开始显现,等到任务量达到几万甚至更多时, GPU 的速度能快上两个数量级。实际工作负载在这条曲线上的分布差异很大:
| 任务 | 单次任务量 | 最佳处理器 | 原因 |
|---|---|---|---|
| 编译一个 C++ 文件 | 1 个文件 | CPU | 分支复杂、串行处理、数据量小 |
| 渲染一帧游戏画面 | 200 万像素 × 着色操作 | GPU | 大规模均匀并行计算 |
| SQLite 单点查询 | 1 行 | CPU | 延迟敏感、分支判断多 |
| 训练一个神经网络 batch | 数百万次 FMA | GPU (Tensor 核心) | 高密度矩阵乘法 |
| 排序 1 万个整数 | 1 万 | 差不多, CPU 更常见 | 低于交叉点, CPU 通常更快 |
| 4K H.265 视频编码 | 每帧 | GPU (专用 NVENC) | 固定功能硬件加速,连着色器都不需要 |
总结一下:CPU 擅长处理小规模、分支多、延迟敏感的任务; GPU 则适合大规模、均匀分布、吞吐量优先的工作;至于那些专门设计的固定功能模块(比如视频编码器、显示引擎、网卡),它们能在特定领域直接碾压通用处理器。系统设计的核心能力,就是根据任务特性,把每块工作放到最适合它的地方去跑。
第六部分 — 内存带宽: DDR、 GDDR 和 HBM 的差异#
如果你无法为一颗拥有 18,000 个 ALU 的 GPU 提供足够的数据,那么这颗 GPU 再强大也是无用武之地。正因如此,高端 GPU 在芯片面积的分配上,内存控制器和缓存几乎占据了与计算单元相同的比例。同时,这也解释了为什么 CPU 和 GPU 在内存技术的选择上走上了不同的道路。

这三种内存技术分别针对不同的优化目标:
- DDR (DDR4、 DDR5) 更注重容量、模块化设计(DIMM)以及单 bit 成本。 CPU 选择 DDR 是因为大多数 CPU 工作负载对延迟非常敏感,同时需要大容量内存支持,通常在 64–192 GB 之间。带宽方面,桌面级双通道配置大约能达到 50–100 GB/s,而服务器级别的 12 通道配置则可达到 300–500 GB/s。
- GDDR (GDDR6、 GDDR6X) 可以看作是 DDR 的“高速版表亲”,但它直接焊接在显卡 PCB 上,并使用超宽总线(例如 RTX 4070 使用 256-bit, RTX 4090 则是 384-bit)。每针脚的数据传输速率可达 16–24 Gb/s,整体带宽高达 450–1,000 GB/s。不过,由于显卡 PCB 上能容纳的 GDDR 芯片数量有限,其容量上限通常在 12–24 GB 左右。
- HBM (HBM2e、 HBM3、 HBM3e) 将 8–16 层 DRAM 芯片通过硅通孔(TSV)垂直堆叠在一起,并放置在紧邻 GPU 的硅中介层上。每个堆栈提供 1024-bit 总线,而一颗 GPU 通常会配备 4–6 个堆栈。这种设计让整体带宽达到了 2–5 TB/s(如 H100 和 MI300 系列),但代价是封装成本大幅增加,且单堆栈容量受到限制。
图中的拓扑结构对比有助于直观理解带宽差距的来源: DDR 信号需要在长距离、高损耗的 PCB 走线上传输,因此每根针脚的切换速度较慢;而 HBM 信号仅需在硅中介层上移动几毫米,切换速度快得多,而且每个堆栈有 1,024 根针脚。根据公式 带宽 = 频率 × 位宽, HBM 在这两个关键指标上都占据优势。
实际应用的经验法则:游戏显卡倾向于使用 GDDR, AI 加速器则更青睐 HBM。两者的分界点通常出现在企业级推理卡上。当模型大小超出 24 GB 的 GDDR 容量时,无论你是否愿意,最终都会转向 HBM。
第七部分 — 显示接口: DP、 HDMI、 USB-C#
如今,把显卡渲染的像素传输到显示器上,有三种主流选择。这些接口并不是可以随意互换的,每种接口的设计初衷和适用场景都不同。很多时候,你随手从抽屉里拿出的那根线,反而成了性能的瓶颈。

| 接口 | 有效带宽 | 主流模式 | 适合场景 |
|---|---|---|---|
| HDMI 2.0 | 14.4 Gb/s | 4K@60 Hz HDR10 | 电视、游戏主机、投影仪 |
| DisplayPort 1.4 | 25.9 Gb/s | 4K@120 Hz / 8K@60 Hz (DSC) | 高刷新率 PC 显示器 |
| HDMI 2.1 | 42.6 Gb/s | 4K@144 Hz、 8K@60 Hz、 eARC、 VRR | 新一代电视、 PS5/XSX |
| USB-C / Thunderbolt 4 (DP-Alt) | 最高 40 Gb/s | 4K@144 + 100 W 供电 + USB 数据 | 单线笔电扩展坞 |
| DisplayPort 2.1 (UHBR 20) | 77.4 Gb/s | 4K@240 Hz 无损、 8K@120 Hz | 2025 年后旗舰显示器 |
三条黄金法则帮你搞定 95% 的实际选择:
电视 → HDMI 2.1
ARC/eARC 可以通过同一根线将音频回传到回音壁或功放, VRR 消除游戏画面撕裂, ALLM 自动切换到低延迟的游戏模式。这些都是 DisplayPort 无法实现的功能。高刷新率 PC 显示器 → DisplayPort
DisplayPort 提供更高的单通道速率,支持原生多流传输(一根线连接两台菊花链显示器),并且兼容更广泛的 G-Sync 和 FreeSync 技术。正因如此,大多数高端游戏显示器都会配备一个 HDMI 2.1 和三个 DP 接口。笔电扩展坞 → USB-C / Thunderbolt 4
这种配置可以用一根线同时传输 DP 1.4 视频信号、 USB 3 数据以及最高 100 W 的电力。这是唯一一个对线材本身有严格要求的场景:务必购买经过认证的 Thunderbolt 线,而不是普通的手机充电用 USB-C 线。
最常见的错误是用一根老旧的 HDMI 线连接到新的 HDMI 2.1 接口,然后疑惑为什么无法开启 4K@120 Hz。问题往往出在线材上,而不是接口本身。选购时请注意包装上的标识:HDMI Ultra High Speed Certified,只有正品才会明确标注这一认证。
第八部分 — 集显与独显:什么时候选择真的重要?#
集成显卡(iGPU)位于 CPU 封装内部,与 CPU 核心共享系统 DDR 内存。而独立显卡(dGPU)则是单独的扩展卡,配备了专属的 GDDR 显存,并通过独立的 PCIe 总线运行。两者之间的性能差距主要由显存带宽和着色器单元数量决定,而在这两方面,独显的优势几乎是压倒性的。
| 工作负载 | 集显(Intel UHD 770 / AMD 780M) | 独显(RTX 4060) |
|---|---|---|
| 办公、网页浏览、视频播放 | 流畅 ✅ | 性能过剩 |
| 4K H.264/HEVC 解码 | 硬件加速 ✅ | 硬件加速 |
| 英雄联盟 / CS2 / 无畏契约(1080p) | 60–120 FPS ✅ | 200–400 FPS |
| 赛博朋克 2077 (1080p 高画质) | 12–18 FPS ❌ | 75 FPS ✅ |
| Stable Diffusion XL | 慢到无法接受 | 1.5 秒/迭代 ✅ |
| DaVinci Resolve 4K 剪辑 | 时间轴卡顿 | 流畅 ✅ |
选择其实很简单,答案是二选一。如果工作内容与 3D 渲染或 AI 无关,集显完全够用,没必要为独显额外花钱。但如果涉及到 3A 游戏、光线追踪、机器学习或 3D 创作,集显就力不从心了。即使是目前最强的 AMD 780M 集显,性能也只相当于五年前的 GTX 1650。
显示器插主板上会出什么问题?#
如果你的电脑装了独立显卡(dGPU),显示器的连接线一定要插在独显的输出接口上,而不是主板上的接口。如果误插到主板上,系统会默认使用集成显卡(iGPU)进行渲染,而独立显卡则会被晾在一边完全闲置。一个很明显的迹象是,在运行需要高负载的游戏时,用 GPU-Z 查看 GPU Load,你会发现它只停留在 0–5%,而不是应有的 90% 以上。
这背后的原因其实很简单:显示器的输出接口是由硬件线路直接决定的。主板上的 HDMI 接口实际上是与 iGPU 相连的,而不是独显。虽然有些主板的 BIOS 提供了类似 Intel 的“iGPU Multi-Monitor”功能,或者通过 DDU 驱动实现类似 Optimus 的方案,可以把 iGPU 的输出通过 dGPU 转发出来,但这种机制主要适用于笔记本电脑,在台式机上往往不太稳定,容易出问题。所以,最简单的原则就是:只要装了独显,显示器就一定要接到独显上。
第九部分 — VRM、电源接口与性能的极限#
现代 K 系列 Intel CPU 在 PL2 加速模式下功耗可达 253 W, Ryzen 9 7950X 在 PPT 下更是高达 230 W,而 RTX 4090 的持续功耗为 450 W,瞬时峰值甚至能达到 600 W。这些功率需求显然不是单靠主板上的 24-pin ATX 接口能够满足的。主板需要将 PSU 提供的 12 V 转换为 CPU 所需的 1.0–1.4 V,而显卡则通过独立的供电线缆直接使用 12 V。负责为 CPU 转换电压的核心组件是 VRM(电压调节模块),其相数决定了它在不过热的情况下能稳定提供多少功率。
| CPU | TDP / PL2 | 推荐 VRM | 典型主板档次 |
|---|---|---|---|
| i3 / Ryzen 3 | ≤65 W | 6+2 相 | H610 / A620 |
| i5 / Ryzen 5 (非 K) | 65–125 W | 10+2 相 | B760 / B650 |
| i7-13700K / R7 7700X | 125–180 W | 14+2 相 | 中端 Z790 / X670 |
| i9-13900K / R9 7950X (超频) | 250–300 W | 18+2 相,带散热片 | 旗舰 Z790 / X670E |
如果将一颗高端 CPU 搭配入门级 VRM,就会遇到装机中最隐蔽的问题:系统可以正常启动,跑分测试在前 30 秒看起来也正常,但随着 VRM 中 MOSFET 温度逐渐超过 100 ℃, CPU 开始逐步降频。这也是为什么评测人员会专门测量 VRM 温度:它是区分一款“账面参数相似”的 130 美元主板和 250 美元主板的关键指标。
相比之下,显卡的供电逻辑要简单得多,因为它完全绕过了主板。通过显卡的供电接口类型,就能大致判断其功耗范围:
| 显卡功耗 | 接口 | 代表型号 |
|---|---|---|
| ≤75 W | 无(仅 PCIe 插槽供电) | GTX 1650 |
| 75–150 W | 6-pin × 1 | RTX 3050 |
| 150–225 W | 8-pin × 1 | RTX 4060 Ti |
| 225–300 W | 8-pin × 2 | RTX 4070 Ti |
| ≥300 W | 12VHPWR (16-pin) × 1 | RTX 4080 / 4090 |
忘记插显卡供电线的后果很严重:要么主板发出蜂鸣声无法开机,要么虽然能启动,但显卡被强制限制在 75 W 功耗下运行,性能低到连一些游戏都无法正常启动。因此,在开机之前,务必仔细检查所有供电接口是否插好。
第十部分 — 真正影响性能的几个 BIOS 设置#
BIOS 中有成百上千个选项,但真正能让用户感受到性能提升的,其实只有四个。
XMP / EXPO (Intel / AMD)
内存条上标注的规格可能是“DDR5-6000”,但默认情况下它会运行在 JEDEC 标准频率(例如 DDR5-4800),除非你启用内存模组上的超频配置文件。开启 XMP 或 EXPO 后,在 CPU 性能瓶颈的游戏中可以轻松获得 5–15% 的免费性能提升。如果开启后系统无法正常启动(POST 失败),可以通过清空 CMOS 恢复默认设置,然后尝试切换到更低一级的配置文件,或者手动将频率降低一档再试。Resizable BAR / Smart Access Memory
这项功能允许 CPU 一次性将 GPU 的全部显存(VRAM)映射到地址空间中,而不是像传统方式那样以 256 MB 为单位分段加载。对于那些需要处理大量纹理的游戏(如《赛博朋克 2077》和《极限竞速:地平线》),这项功能可以带来 2–8% 的帧率提升。要启用它,需要同时打开“Above 4G Decoding”和“Re-Size BAR”选项,并确保你的显卡支持该功能(如 RTX 30/40 系列或 RX 6000/7000 系列)。CPU 功耗限制(Intel 的 PL1/PL2, AMD 的 PPT/TDC/EDC)
大多数主板默认会对 CPU 的功耗进行限制,这意味着 CPU 在高负载下只能维持 28–56 秒的加速状态(Boost),随后便会降回基础频率。如果你移除这些限制(或将 PL1 和 PL2 设置为相同值),只要散热条件允许, CPU 就可以一直保持加速状态。这种调整在长时间编译或渲染任务中通常能带来 10–20% 的性能提升。风扇曲线
很多主板默认的风扇策略更倾向于静音,但这会导致温度逐渐升高,最终触发降频保护。如果你将风扇曲线调整为“在 75°C 时达到 80% 转速”,虽然噪音可能会略微增加几 dB,但可以有效避免因过热导致的降频问题,从而让 CPU 长时间保持高频运行。
其他 BIOS 设置(如 Secure Boot、虚拟化、 SATA 模式等)更多是与系统正确性相关,对性能几乎没有影响。如果你需要用到 Docker、 WSL2、 VMware 或 Android Studio 等工具,记得开启虚拟化功能;否则,建议保留默认设置即可。
总结#
主板可以看作是由一条链路连接起来的两个区域:一个是以满速运行显卡、主 NVMe 和内存的小型 CPU 直连区域,另一个是通过共享 DMI 总线扩展出所有其他设备的芯片组区域。读懂 PCB 布局后,就能轻松分辨每个插槽属于哪个区域。
PCIe 每一代的单通道带宽都会翻倍,因此 Gen 4 ×4 的 NVMe 固态硬盘速度和 Gen 3 ×8 差不多。目前消费级显卡还没有完全用满 PCIe 4.0 ×16 的带宽;而 Gen 5 真正发挥优势的地方在于 SSD。
GPU 的强大之处在于并行计算: SIMT 模型让每个 warp (线程束)中的 32 条通道同时执行同一条指令,而 SM (流式多处理器)通过每周期切换不同的 warp 来隐藏内存延迟。 CPU 更适合处理小规模、分支密集、对延迟敏感的任务,而 GPU 则擅长大规模、均匀分布、吞吐量优先的工作负载。选择硬件时,应该根据实际需求来决定,而不是凭直觉或习惯。
内存技术也在分化: DDR 主要服务于 CPU (注重容量和低延迟), GDDR 面向游戏显卡(注重带宽,容量适中), HBM 则专为 AI 加速器设计(高带宽,封装在芯片上)。显示接口同样各有侧重:电视和主机常用 HDMI 2.1, PC 高刷新率显示器偏向 DisplayPort,而笔记本扩展坞则青睐 USB-C/Thunderbolt。
如果你使用独立显卡,那么显示器的连接线一定要插到显卡上,而不是主板上。 VRM 的相数必须能够满足 CPU 的持续 TDP (热设计功耗),否则系统会因为供电不足而悄然降频。开启 XMP/EXPO 和 Resizable BAR 是无需额外成本的性能提升方式,至于 BIOS 中的其他设置,则更多是为了调优服务,而不是一键解决所有问题的灵丹妙药。
下一篇:第五篇,网络、电源与实战排障。


