
计算机基础(六):深度解析与系统协作
系列收官篇。我们从单个组件抽身出来,看整台机器:CPU、缓存、内存、存储、IO、加速器是怎么连在一起的;为什么硬件感知的代码能快 100 倍;怎么读 perf 计数器;以及计算的下一站——chiplet、硅光、量子。
前五章里,我们逐一拆解了 CPU、缓存层级、存储、主板与显卡、网络和电源。每一部分单独看都很有意思,但计算机远不止是这些零件的简单堆叠。它是一个每纳秒都在协调“下一步该做什么”的精密系统。

本章正是要揭示这场持续不断的内部对话:我们将所有组件整合成一张全景图,从性能分析器的视角审视整台机器,回溯那个已延续 80 年、至今仍在塑造每颗芯片的设计张力,并最终展望 chiplet、光子互连以及悄然逼近的量子时代。
如果你只打算读完这个系列中的一章,那就选这一章。因为只有到这里,你的系统认知模型才算真正成型。
第一部分 —— 一张图看懂整台机器#
按下电源键的瞬间,一场精密编排的启动序列便悄然展开,直至关机才告终:主板上的 BIOS/UEFI 按序激活各路供电轨,CPU 从硬编码的复位向量处开始取指,内存控制器初始化 DRAM,启动盘加载操作系统内核,GPU 初始化显示引擎,网卡建立链路连接。短短几秒内,数十亿晶体管协同运作,将登录界面呈现在你眼前。
这台机器的内部结构可浓缩为下图所示的模块框图:

这张图中有几点尤为关键:
- 延迟梯度自左至右、自上而下逐级放大。 CPU 内部缓存响应在纳秒级,DRAM 约为几十纳秒,PCIe 总线及各类加速器则在几百纳秒到微秒之间,而存储与网络的延迟更是达到微秒乃至毫秒量级。五个数量级的延迟差异,竟共存于一块主板之上。
- PCIe 是系统的主干脊柱。 几乎所有位于 CPU 封装之外的设备,比如 GPU、NVMe SSD、网卡、USB 控制器,都通过 PCIe 进行通信。如今 CXL 正在扩展这条总线,赋予其缓存一致性语义,这才让“内存池化”在机架尺度上变得切实可行。
- 单一总线早已不复存在: CPU 封装内部,核心通过环形或网格互联;内存控制器与 IO 单元被拆分为独立芯粒(tile);GPU 则自带 HBM 高带宽内存。昔日那条共享的“高速公路”,如今已演变为一座由多重重叠网络构成的“城市”。
一旦你以这种视角看待机器,许多技术迷思便豁然开朗:“为什么我把 SSD 插到另一个 M.2 插槽后游戏变快了?”答案是那个插槽直连 CPU,而非绕道芯片组。“为什么 AI 负载离不开 HBM?”因为 GPU 需要 3 TB/s 的带宽,而 DDR5 最多只能提供 50 GB/s。“为什么小文件用 mmap 如此迅速?”因为文件早已驻留在 DRAM 的页缓存中,访问开销仅为纳秒级,而非微秒级的磁盘 I/O。
第二部分 —— 硬件感知的软件,性能可提升百倍#
硬件工程师花了五十年打造令人惊叹的机器,但大多数软件仍将其当作一台 1990 年代的 PC 来使用。弥合这一认知鸿沟,是性能工程中最具杠杆效应的能力。

左侧是我们熟悉的软件栈:应用、框架、编译器、操作系统、驱动、指令集架构(ISA)、微架构、硅片。右侧则展示了当信息能在各层间自由流动、而非被密封隔离时,系统所能释放的巨大潜力。
图中的柱状数据来自一个经典实验:单核下对两个 1024×1024 的 FP32 矩阵做乘法。朴素的三重循环作为基线。若调整循环顺序,使内层步长为单位步长(unit-stride),缓存友好性即可带来约 3 倍加速;进一步分块(blocking)以适配 L1 缓存,性能提升至约 10 倍;引入 AVX2 向量指令后达 32 倍;再结合融合乘加(FMA)与循环展开,让乱序执行引擎有充足指令可调度,性能跃升至 58 倍;最后用 OpenMP 多线程并行,总加速比高达 400 倍。算法未变,理论计算量(FLOPs)也未变。这 400 倍的提升,完全源于清晰地告诉硬件你真正想要什么。
这正是本系列的核心洞见:CPU 不慢,内存也不慢,问题在于大多数软件根本没让机器全力运转。
以下几种模式值得牢记,因为它们无处不在:
- 步长比访问次数更重要: 一个每次仅访问 cache line 中一个字节的循环,开销比遍历整条 line 的循环高出 64 倍。
- 不可预测的分支,比多做一点工作更致命。 无分支代码或分支方向高度可预测的代码,往往胜过那些依赖“聪明捷径”的实现。
- 内存分配本身也是一种访存操作。 热点循环深处的一次
malloc,可能比循环本身的计算还要昂贵。 - 并发瓶颈本质是带宽问题,而非 CPU 问题。 八个线程争抢同一条 cache line,速度可能还不如单线程。
真正实用的工具并不炫酷:perf、vtune、flamegraph、valgrind --tool=cachegrind。它们能精准指出代码中真正的瓶颈所在,而那个位置几乎从来不是你最初猜测的地方。
第三部分 —— 计数器:机器如何告诉你它在做什么#
每颗现代 CPU 都内置一个性能监控单元(PMU),也就是一组用于统计微架构事件的小型寄存器。正是 PMU 让我们从“猜测”迈入“测量”的时代。
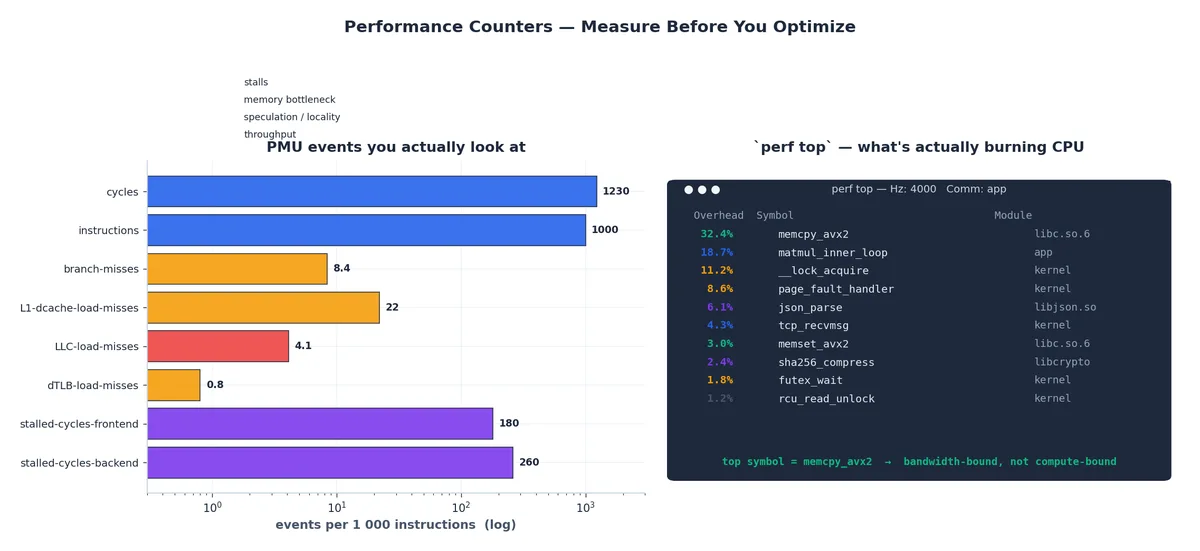
左图展示的是实际关注的事件,已归一化为每千条指令的发生次数;右图则是典型高负载下 perf top 的实时视图,显示哪些函数正在消耗 CPU 时间。
以下是常见事件的快速指南:
cycles与instructions可计算 IPC(每周期指令数)。现代 Intel/AMD 核心在无停顿情况下可达 3–4 IPC;若 IPC 仅为 0.3,说明核心大部分时间处于空闲,问题严重。branch-misses若超过每千条指令 5 次,通常意味着热点分支难以预测。有时可用__builtin_expect优化,但更多时候需重构数据布局,使分支走向趋于一致。L1-dcache-load-misses与LLC-load-misses可定位缓存问题所在层级。L1 未命中但命中 L2 仅损失几个周期;LLC 未命中打到 DRAM 则损失数百周期,一次 LLC 未命中约等于浪费一千条指令的时间。dTLB-load-misses表明工作集超出 TLB 覆盖范围,解决方法常是启用大页(huge pages):一个 2 MB 大页可覆盖 512 个 4 KB 小页。stalled-cycles-frontend与stalled-cycles-backend分别指示核心是在等待指令流(前端,通常因 I-cache 或分支预测)还是等待内存返回结果(后端,几乎总是内存带宽不足)。
模拟的 perf top 面板揭示了一个初学者最常见的意外:顶部符号几乎从不是你的业务逻辑,而是 memcpy、锁操作或页错误处理程序。真实程序在成为计算瓶颈之前,早已受限于带宽与同步开销。 这并非代码之过,而是现代硬件的本质特征。
一套屡试不爽的工作流如下:
- 在紧凑循环中复现慢速场景;
- 运行
perf stat -d ./app,观察 IPC、缓存未命中率、分支未命中率; - 执行
perf record -g ./app && perf report,定位热点函数; - 用
perf annotate查看该函数的反汇编,找出采样堆积的指令行; - 提出假设,修改一处,回到第 2 步验证。
大多数性能优化,不过是坚持不跳过第 4 步而已。
第四部分 —— 冯·诺依曼瓶颈:从过去到今天#
1945 年,冯·诺依曼提出了一种架构:CPU、内存、连接两者的总线,且指令与数据共享同一地址空间。这一设计通用而优雅,却也埋下了与生俱来的限制,深刻塑造了此后八十年的计算发展。

左图展示了经典困境:系统仅有一条总线。CPU 执行的每条指令、加载的每个操作数、写回的每个结果,都必须经由此总线。1990 至 2000 年代,CPU 主频飞速提升,而 DRAM 速度却停滞不前,“内存墙”由此形成,成为性能的主要瓶颈。如今,一次完全错过缓存、直达 DRAM 的加载操作,相当于浪费 CPU 约 300 条指令的执行时间。
右图则呈现了五十年来的应对之道:
- 多级缓存:将更小更快的内存副本置于芯片内部。L1 命中延迟低于 1 纳秒,整个缓存体系是 3 GHz 核心得以存在的前提。
- 硬件预取器:检测到线性内存访问模式后,提前加载后续数据。
- 乱序执行:在等待慢速内存操作时,继续执行其他独立指令。
- SIMD:单条指令完成 8 或 16 次浮点运算,摊薄内存访问成本。
- SMT(超线程):提供两条指令流,确保核心始终有事可做。
- 哈佛架构分离 L1:指令与数据缓存分开,前后端可并行取指与访存。
- HBM:将 DRAM 堆叠于计算芯片之上,实现 TB/s 级带宽。
- 存内计算(Compute-in-Memory):最激进的方案,是直接在内存阵列中完成运算,避免数据移动。
综合效果令人震撼:原始 DRAM 延迟二十年来几乎未变(仍约 80 纳秒),但经过优化的程序所感受到的有效延迟已接近 2 纳秒,因为绝大多数访问被缓存拦截、被预取提前加载,或被乱序执行隐藏。我们并未击穿内存墙,而是巧妙地绕开了它。
理解这一点会彻底改变你的编程思维:纸面上最优的算法,可能因内存跳转频繁而在真实硬件上表现糟糕;看似冗余的算法(多算几次、重复加载),反而因缓存友好而飞快运行。 现代性能优化,本质上是一场披着计算外衣的内存游戏。
第五部分 —— 异构计算:为任务选择合适的工具#
几十年来,“计算机”几乎等同于 CPU,所有负载都得支付相同的架构税。这一时代已然终结。到 2026 年,一台笔记本 SoC 将集成 CPU、GPU、NPU、视频编解码单元与安全区;数据中心机架则同时部署 CPU、GPU、TPU、FPGA 与 SmartNIC。 关键问题不再是“你的 CPU 有多快”,而是“你是否把任务放对了地方”。

左图展示了现代 SoC 的真实结构:专用芯粒各司其职:CPU 处理控制流,GPU 擅长稠密浮点运算,TPU 专精 INT8 矩阵乘,NPU 负责低功耗端侧 AI。它们通过一致性互连共享 HBM 内存池。CXL 更将这一互连延伸至跨封装场景,使不同插槽的加速器可直接共享内存,无需软件中转。
右图则量化了性能与能效的权衡:横轴为峰值吞吐(TFLOPS/TOPS,对数刻度),纵轴为能效(TOPS/W,同样对数)。关键结论包括:
- 支持 AVX-512 的现代 CPU:提供数 TFLOPS 算力,能效约 0.1 TOPS/W,适合分支密集、低延迟任务,但矩阵乘效率极低。
- 数据中心 GPU(如 H100):峰值约 67 TFLOPS,能效 2.5 TOPS/W,通用性强,足以训练任意神经网络,已成为训练默认选择。
- TPU v5p:吞吐约为 CPU 的 7 倍,能效高 1.5 倍,但前提是负载必须符合大规模脉动阵列矩阵乘的模式。
- 移动端 NPU 能效领先 CPU 80 倍,这正是手机能实时语音识别而不耗尽电池的原因。
- 定制 ASIC 站在前沿:吞吐与能效最大化,灵活性趋近于零,适用于比特币挖矿、视频编码、包处理等固定任务。
图中虚线“专用化前沿”是一条真实曲线:每向专用化迈进一步,吞吐与能效提升,通用性则下降。 没有免费午餐,只有一份菜单,优秀工程在于明智选择。
实用建议很简单:先分析,再选硬件,最后定算法。 把分支密集的图遍历放到 GPU 上,或在 CPU 上跑 BERT,都是典型资源错配。
第六部分 —— 从比特到系统:一段完整的旅程#
跳出技术细节,回顾本系列走过的路径:每章构建一块认知拼图,本章则将其完整拼合。

- 第一章 比特、字节与 CPU。 从基础出发:比特是两种状态,字节是八比特;ASCII 表示英文,UTF-8 覆盖全球。继而深入 CPU:核心、线程、主频、Intel 与 AMD 差异、32 位系统为何无法使用 4 GB 内存。
- 第二章 内存与缓存: 梳理 DDR 代际、双通道优势、三级缓存体系、命中率意义,以及为何增加通道数比提升频率更有效。
- 第三章 存储系统: 从 HDD 盘片磁头,到 NAND 闪存(SLC 至 QLC),再到 SATA 与 NVMe 对比;讨论 RAID 级别,以及从 DRAM 到 Glacier 的存储分层金字塔。
- 第四章 主板与 GPU。 聚焦芯片组、PCIe 通道与代际、M.2 插槽布线、VRM 相数,以及 GPU 内存层级与 SM/CUDA 架构如何支撑大规模并行。
- 第五章 网络、电源与散热。 分析网卡速率、RDMA、OSI 模型实践、PSU 功率与 80 PLUS 认证、风扇曲线与温控降频,以及整机装配清单。
- 第六章 全景与未来: 整合所有内容:跨层优化、性能计数器、冯·诺依曼故事、异构计算趋势,以及未来方向。
每块都是整体的一部分,但单独一块不成系统。真正的系统,就是你面前这台机器。 当你能同时看清这六块拼图,硬件的神秘感便烟消云散。
第七部分 —— 未来趋势:Chiplet、光子互连与量子计算#
媒体熟知的摩尔定律,即单芯片晶体管数每两年翻倍,已然终结。晶体管虽仍在缩小,但经济性、良率与物理极限已无法支撑无限增大的单片芯片。那么,未来何在?三条路径已然显现。
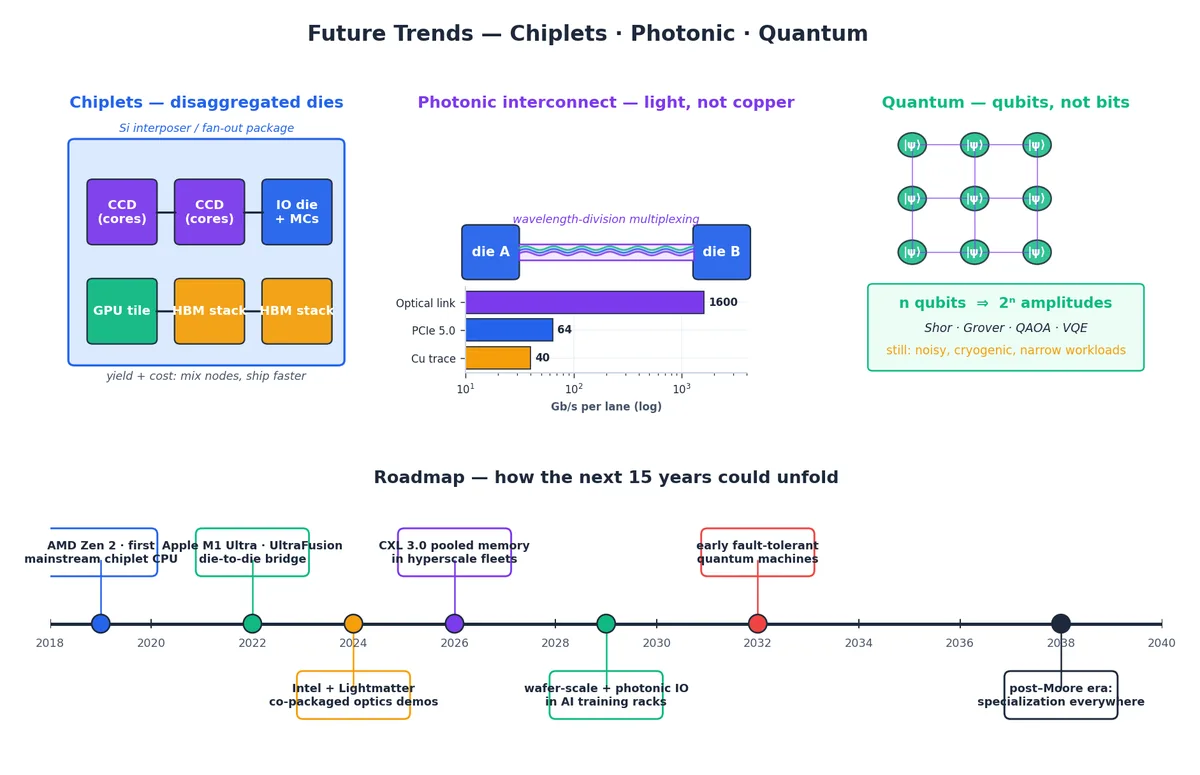
Chiplet:封装内多芯粒集成。 不再追求一颗完美大芯片(如 600 mm²),而是将功能拆分为多个小芯粒,各自采用最适合的工艺制造。AMD 2019 年 Zen 2 首秀此技:计算芯粒(CCD)与 IO 芯粒通过 Infinity Fabric 互联。苹果 M1 Ultra 用 UltraFusion 桥接两颗 M1 Max。Intel Meteor Lake 则在同一封装内集成 CPU、GPU、SoC 与 IO 芯粒。优势在于残酷的经济现实:600 mm² 单片良率极低;六个 100 mm² 芯粒良率高、可混搭、可跨工艺节点。代价是互连:芯粒间需低延迟、高带宽通信,这正是 UCIe(Universal Chiplet Interconnect Express)等标准变得紧迫的原因。
光子互连,以光代铜: 铜线在每通道几十 Gb/s 时信号完整性崩溃,而光不受此限。共封装光学(Co-packaged optics) 将微型激光器与波导紧贴计算芯粒,波分复用使单根光纤承载数十通道。早期用于解决“逃逸问题”,也就是将数据高速移出 GPU 封装,以喂饱跨数千加速器的 AI 训练集群。Lightmatter、Ayar Labs 与超大规模云厂商正推进此技,首批商用部署预计 2024–2026 年落地。到 2030 年,光子互连很可能成为高端芯片对外通信的标配。
量子计算:qubit 而非 bit。 量子比特(qubit)不是更快的比特,而是全新对象。n 个 qubit 可同时表示 $2^n$ 个振幅,量子算法通过干涉引导振幅走向答案。对某些特定问题,比如大数分解(Shor)、无序搜索(Grover)、某些化学与优化问题,可获指数或平方级加速。当前硬件噪声大、需极低温、规模小。业界竞相追逐 2032 年左右的里程碑,即容错量子计算:足够 qubit 与纠错能力,可在真实输入上运行著名算法。它不会取代你的笔记本,但将接管今日无法解决的特定计算任务。
图底将三条路径纳入统一时间轴。大局观是:未来十五年计算发展不会是一次飞跃,而是众多小步,全部指向专用化:定制硅片、定制互连、定制物理,并通过深度理解底层硬件的软件将其无缝整合。
收尾 —— 如何将这些知识用起来#
至此,你已通览机器全貌。养成以下习惯,可让这份认知在未来多年持续复利:
- 遇性能问题,先测再猜: 一次
perf stat或火焰图,可省去数日错误直觉带来的徒劳。 - 细读你手中硬件的数据手册: 缓存大小、内存通道数、PCIe 布线皆在其中,足以解释你观察到的多数现象。
- 维护并迭代一个系统心智模型。 每遇新技术,比如 CXL、光子 IO、MI300 chiplet,都将其嵌入第一部分的系统图中。找到位置,即得理解。
- 动手构建压榨硬件的项目: 简易数据库、小型光线追踪器、自制 profiler。当某次修改让你的 IPC 从 0.3 飙至 2.8,那种顿悟无可替代。
计算机硬件不是零件清单,而是八十年间数万工程师打磨出的人类史上最复杂机器之一。 理解其运作原理,是你能掌握的最具杠杆效应的知识之一。
感谢你一路读完本系列。期待下一程再见!
,计算机基础系列 · 完,
附录 —— 这周可做的三件事#
本系列反复强调:测量即杠杆: 以下三个实验,各耗时不足一小时,做完你将获得此前没有的数字。
测量你机器的“内存墙”#
| |
首次运行测试大块连续数据流,反映 DRAM 持续带宽;第二次随机访问 64 字节 cache line,测量延迟受限吞吐。两者比值即为你的内存墙,通常为 5 倍至 20 倍。这一差距正是缓存局部性至关重要的根本原因。
观察分支预测器的学习过程#
| |
相同数据,排序后运行通常快 1.4–1.8 倍。因 CPU 分支预测器可轻松学习“前半段永不满足、后半段恒满足”的规律,而非对抗随机噪声。这正是 Mike Acton “数据导向设计”演讲核心思想的微型体现。
测量你机器的实际 PCIe 带宽#
| |
PCIe Gen4 x16 理论带宽 32 GB/s,实际通常为 24–28 GB/s。若测得值仅一半,可能是插在 Gen3 插槽或仅 x8 通道。主板手册中的芯片组拓扑图会标明各插槽规格,多数主板仅有一个直连 CPU 的 x16 插槽。
附录 —— Cache Line 与机器学习工作负载#
现代 CPU 的 cache line 均为 64 字节。这一数字能解释 ML 流水线中的诸多现象:
float32张量:每 cache line 容纳 16 个浮点数。按(B, C, H, W)行优先遍历可命中已加载数据;若跨 batch 维度列优先遍历,则每次均 miss。- 卷积网络采用
channels_last内存格式后,相同模型训练速度可提升 2–3 倍,因卷积核能连续读取 channel 数据,高效利用 cache。 torch.compile与 XLA 通过算子融合,尽量让张量在 ops 间保留在 cache 中。收益不在理论 FLOPs,而在避免每次 DRAM 访问的 80 纳秒延迟。- 256 KB 激活块可放入 L2,24 MB 权重层则不能。这正是 FlashAttention 将注意力矩阵切分为 L2 大小块的原因:算法未变,内存流量已优化。
若你只记住一句话:数学运算几乎免费,数据搬运才是成本。 此理在 CPU 成立,在 GPU 更甚,也是专用 AI 芯片存在的根本原因。


