
核方法(一):为什么需要它——从线性算法的天花板说起
线性算法没办法捕获非线性规律。核技巧让你既保留线性算法的优雅,又能建模非线性关系,而且完全不需要写出那个高维特征映射。这是核方法 8 篇系列的开篇。
我第一次想把逻辑回归扔到一对交错的螺旋数据上时,整整一个下午都在折腾正则化系数、换求解器、归一化输入,总觉得是哪里写错了。准确率始终徘徊在 50% 上下,跟掷硬币没区别。换句话说,模型什么都没学到。
模型没 bug。是数据本身就不是一条直线能描述的对象,无论怎么调 C、class_weight 或 tol,结局都不会变。一旦见过这种失败,你就会到处发现它:churn 预测里的非单调关系、深度学习之前的图像分类、任何带弯曲趋势的回归任务。线性算法存在一个硬天花板,要顶破它,你不能只换参数,得换"算法操作的对象"。

接下来这个系列一共 8 篇,是对核方法这套数学机制的一次慢而细的走读:它让你在保留线性算法的凸优化、闭式解、漂亮理论的同时,能建模任意非线性关系。第 1 篇(也就是本文)讲动机。我们暂时不写 Mercer 定理,不写 RKHS,先盯着失败模式看,再走一遍那条"显而易见但行不通"的弯路,最后把核技巧当作必然结果推出来,而不是当作魔法咒语。
线性的天花板#
很多常用的 ML 算法,本质上都是线性的。普通最小二乘拟一个超平面,逻辑回归用超平面分类,线性 SVM 找最大间隔超平面,PCA 投到子空间,岭回归、Fisher 判别都在同一片邻里。它们剥到底,问的都是同一个问题:$x$ 的哪个线性函数最能解释数据?
$$f(x) = w^\top x + b,$$决策边界是超平面 $\{x : w^\top x + b = 0\}.$ 这个几何对象很刚:边界是平的,只有一个法向量,把 $\mathbb{R}^d$ 切成两个半空间。如果真实的决策面是弯的,任何 $w$ 和 $b$ 的组合都无法还原它:模型类里根本就不含正确的函数。
形式一点说,假设类是 $\mathcal{F}_{\text{lin}} = \{f(x) = w^\top x + b : w \in \mathbb{R}^d, b \in \mathbb{R}\},$ 一个 $(d+1)$ 维的函数向量空间。它对加法和数乘封闭,但对"和非线性函数复合"不封闭。函数 $x \mapsto \sin(x_1) + x_2^2$ 不在 $\mathcal{F}_{\text{lin}}$ 里,无论你训多久,线性学习器也变不出它。优化器在好好干活,是结构本身到了极限。

上面这张图不用多解释。逻辑回归、线性 SVM、岭分类器,这三种最主流的线性分类器,面对同一份双螺旋数据,全都画出一条对角线,分错近一半样本,准确率离瞎猜只差几个百分点。
要点是:这不是优化失败。每个模型在自己的假设类里都已经到了全局最优。问题出在假设类。想做得更好,只能扩大这个类,给算法用上它原本表达不了的函数。
一个具体的实验:两个月亮上的逻辑回归#
用一个最小的数值实验把失败模式钉死。“双月牙"数据集是最干净的最小例子:$\mathbb{R}^2$ 上两个交错的半圆,只能被曲线分开。整个实验在 scikit-learn 里几行就能写完。
| |
跑下来大致打印:
LogisticRegression C=1.0 test acc = 0.873
LogisticRegression C=100.0 test acc = 0.875
LinearSVC C=1.0 test acc = 0.873
87% 听起来还行,直到你意识到常数预测器是 50%,而这份数据上贝叶斯最优分类器接近 100%。这 13 个点的差距就是模型错误设定的差距,是把假设类限制在半空间上要付的代价。把 C 从 1 拉到 100(正则化弱 100 倍)只换来 0.2%。再次确认:这不是正则化问题,不是求解器问题,也不是归一化问题,假设类本身就错了。
加数据救不了你#
很多人下意识觉得:再多采几千个样本不就好了?对非线性问题,这个直觉是错的。把螺旋数据加倍,你只是把同一条没用的直线估得更准而已,那条对角线该穿过两类还是穿过两类。把上面那张图的 $n$ 从 200 换成 10000 再跑一遍,准确率几乎不动。
诊断这一步很重要,它决定了你该往哪个方向修。高方差的模型多采点数据能救;偏置错误的模型,也就是假设类里压根没有真实函数的那种,必须扩大假设类才行。核方法就是一种系统化扩大假设类的办法。
经典的 bias-variance 分解写出来就是 $\mathbb{E}[(\hat{f}(x) - f^*(x))^2] = \text{Bias}(\hat{f}(x))^2 + \text{Var}(\hat{f}(x)) + \sigma^2.$ 数据变多让方差项缩到零,但偏置项动不了。如果真实函数 $f^*$ 不在你的类里,偏置就是一个固定正数,全世界的数据加起来也吃不掉它。
线性的天花板出现在哪#
除了月牙数据,线性天花板还出现在出乎意料多的地方。简单列几种典型的"线性玩不转"的场景:
- XOR 类数据: 两个特征单独都没信息量,但联合起来有信息量,线性模型无法表示交互项。
- 基于距离的结构: 流形上的数据(瑞士卷、球面、同心圆),相似性由测地或径向距离决定,不能用一个法向量概括。
- 阈值效应: 输出依赖某个特征是否超过临界值;函数局部平坦再陡然跳变,被线性模型一平均就糊了。
- 乘性交互: 销量 = 价格 × 广告投入,而不是相加;收入 = 学历 × IQ 百分位。
- 周期信号: 电力需求有 24 小时周期,时间的线性函数不会回弯。
有趣的是,这些场景里大家用的算法本身(SVM、岭、PCA)都很好用,坏的是输入表示。所以正确的修法应该针对表示,而不是算法。
清单还能继续列下去:分段常数的生存曲线、有序类别的交互、跨区段变号的对数比。任何时候你发现自己要去找一个"魔法变换”,多半就找到了一个核本可以替你处理的地方,更干净,而且不用提前承诺一种具体的函数形式。
思考: 这也是为什么"特征工程"在深度学习之前会成为一门独立的手艺。每个 Kaggle 大佬的旧 playbook,分桶、目标编码、手工比例,本质上都是"不离开线性模型的舒适区,又要顶破线性天花板"的临时绕路。核方法就是同一个本能的有原理、有数学的版本。
XOR 失败的最小例子#
如果你怀疑线性天花板是不是数据病态导致的,看看最干净的不可线性分的问题:四个点上的 XOR。
| |
输出:
Predictions: [0 0 0 0] # 或 [1 1 1 1],取决于初始化
Accuracy: 0.5
四个点、两个特征,最好的线性分类器也只能到 50%。唯一的出路是加上能捕获交互的特征,比如 $x_1 \oplus x_2,$ 或者对核更友好的乘积 $x_1 \cdot x_2.$ 加一列,准确率立刻变 100%,其他什么都不用改。那一个缺掉的自由度,就是多项式展开(以及后来的多项式核)替你在所有特征对上免费补齐的东西。
笨办法:手工造特征#
输入空间太穷?那就把它撑富一点。这就是特征工程,一门又老又老实又偶尔很累的手艺:发明新列。多项式结构?把所有 $x_i x_j$ 都算出来加进去。周期性?加 $\sin(\omega t)$ 和 $\cos(\omega t).$ 阈值效应?加指示变量。
具体地,$x \in \mathbb{R}^d$ 的 $k$ 阶多项式展开 $\phi(x)$ 包含所有满足 $\sum_i a_i \leq k$ 的单项式 $x_1^{a_1} x_2^{a_2} \cdots x_d^{a_d}.$ 然后在 $\phi(x)$ 上跑你最喜欢的线性算法。分类器 $f(z) = w^\top z + b$ 在特征空间里是线性的,但回到原始 $x$ 空间就成了一条任意 $k$ 阶以下的多项式决策面。
这个思路能用。它有一段长长的、踏踏实实的成功史。但它有三个结构性问题,随着 $k$ 或 $d$ 增大,每一个都越来越扎手。
问题 1:组合爆炸#
$$N(d, k) = \binom{d + k}{k}.$$增长很快,列几个具体数字:
| $d$ | $k$ | $N(d, k)$ |
|---|---|---|
| 5 | 2 | 21 |
| 5 | 3 | 56 |
| 10 | 2 | 66 |
| 10 | 3 | 286 |
| 10 | 5 | 3{,}003 |
| 20 | 3 | 1{,}771 |
| 20 | 5 | 53{,}130 |
| 50 | 3 | 23{,}426 |
| 50 | 5 | 3{,}478{,}761 |
50 维输入 + 5 阶多项式,“丰富后"的表示已经接近 350 万维。每个样本是几百万长度的向量,每次预测都得过一遍,每个权重都吃掉一个自由度。

这张图把渐近行为画得很直观:$d = 50$ 时,特征数在六阶之前就冲过一百万,曲线还远没收手。
具体例子:$d = 10, k = 3$ 的显式多项式特征#
在爆炸里住一会儿。取 $d = 10$ 输入,让 sklearn 帮你展到 3 阶:
| |
输出:
原始形状: (5, 10)
展开形状: (5, 286)
前 12 个特征名:
['1' 'x0' 'x1' 'x2' 'x3' 'x4' 'x5' 'x6' 'x7' 'x8' 'x9' 'x0^2']
那个 286 就是表里的数,跟 $\binom{10 + 3}{3} = \binom{13}{3} = 286$ 严丝合缝。5 个样本是 11 KB float64。一百万个样本?光设计矩阵就 2.3 GB。而且才 3 阶。
把 $d$ 升到 100、$k$ 升到 4,特征数变成 $\binom{104}{4} = 4{,}598{,}126.$ 单个样本(float64)36 MB,一万样本就是 360 GB,数据进不了内存,而你连一次矩阵乘法都还没做。
值得停一秒想想这些数字意味着什么。286 特征、$d=10$ 那个 case 是好的,一台普通笔记本毫秒级搞定。460 万特征、$d=100$ 的 case 是彻头彻尾的死局:光把数据加载一次,就能把一个中型 ML 团队共享集群的存储预算吃光。而后者完全不是什么稀奇问题,$d=100$ 对表格金融数据或传感器遥测来说就是小数据。“显而易见的修法"比表面算术暗示的早得多就会失效。
问题 2:维度灾难#
特征空间一大,问题不只是贵,而是统计上危险。泛化界大约和 $\sqrt{N(d, k) / n}$ 成正比,加几百万个特征但样本数没加,泛化误差就上天了。换句话说,你用方差换来了表达力。
具体说,$n = 1000$ 样本 + $N = 10^6$ 特征下,线性系统 $Xw = y$ 严重欠定:有无穷多个权重向量都能把训练集插值得完美。没有强正则化(以及对"哪些特征重要"的精心选择),你 100% 过拟合。
更细一点,从 VC 理论和 Rademacher 复杂度可以得到:一个 $D$ 维线性假设类在有界域上用 $\ell_2$ 正则训练时,最坏情况下泛化间隙的尺度是 $O(\sqrt{D / n}).$ 代进 $D = 3.5 \times 10^6,$ $n = 10^4,$ 这个界大概是 $\sqrt{350} \approx 19.$ 翻译过来就是"你训练集上的误差完全没意义”:表面上数据是拟合上了,但什么关于测试性能的东西都没保证。
问题 3:你得真的算出 $\phi(x)$ #
即便接受了统计风险、用上重正则化,你还得真的构造那个特征向量。每个训练样本把所有交叉项乘出来、存在内存里、再喂给算法,这是一笔实打实的工程成本。$N = 3.5 \times 10^6$ 的 float64 向量乘 10000 个样本,就是 280 GB 内存,远超大多数笔记本甚至服务器的承受范围。
当然有缓解手段:稀疏存储(对稀疏 $x$ 大多数乘积都是 0)、单精度(账单减半)、按需重新计算(拿时间换空间)。但这些都改不了底层的 scaling,只是把悬崖边再往后推一个常数倍,而不是不掉下去。
所以显式特征映射的路在小问题上能走,大问题上就崩。它思路是对的,但执行顺序错了:先把特征撑开再算,太亏。
思考: 这三个问题,组合爆炸、统计危险、工程开销,是 ML 里反复出现的母题。任何"先展开再拟合"的管线里(NLP 的 n-gram、视觉的体素网格、推荐系统的全对交互),都是同一组力量在作怪,也用同一组家族的修法:哈希技巧、低秩分解,以及核(如果你足够幸运,算法只需要内积的话)。
关键转折:算法只需要内积怎么办?#
下面是改变一切的那个观察。仔细看一眼线性算法到底怎么用它的输入。很多情况下,而且几乎是所有好用的情况,输入 $x$ 进入优化问题,只通过两两内积 $\langle x_i, x_j \rangle$ 出现。
$$\max_\alpha \;\; \sum_i \alpha_i - \tfrac{1}{2} \sum_{i, j} \alpha_i \alpha_j y_i y_j \, \langle x_i, x_j \rangle, \qquad 0 \leq \alpha_i \leq C.$$数据点 $x_i$ 本身没在任何地方单独出现,只有 $n \times n$ 的两两内积矩阵出现了。核 PCA、核岭回归、高斯过程回归、核 CCA、谱聚类,都是同样的结构:算法只通过一个相似度函数接触数据。
$$w^{*\top} x_* + b = \sum_i \alpha_i^* y_i \langle x_i, x_* \rangle + b$$的符号。所以训练和推理都只看内积,Gram 矩阵搭好之后,原始的 $x_i$ 一次都不用再碰。
那么设想你已经选好了一个增强后的特征映射 $\phi,$ 想把上面这些算法搬进特征空间。算法需要的是 $\langle \phi(x_i), \phi(x_j) \rangle,$ 不需要 $\phi(x_i)$ 或 $\phi(x_j)$ 单独的值。如果你能不显式构造高维向量就直接算出这个内积,那么你就拥有了一个高维模型的表达力 + 低维计算的代价的算法。
这正是核所做的事。
$$K(x, y) = \langle \phi(x), \phi(y) \rangle$$对某个映射 $\phi: \mathcal{X} \to \mathcal{H}$ 成立($\mathcal{H}$ 是希尔伯特空间)。核技巧就是把算法写成"只通过 $K(x_i, x_j)$ 接触数据"的形式,永远不显式碰 $\phi.$
绝妙之处在于:对很多有用的 $\phi,$ 函数 $K$ 都有便宜的闭式(一般是 $O(d)$ ),而显式构造 $\phi$ 本身是 $O(N(d, k)).$ 第 2 篇会精确告诉你哪些 $K$ 才算合法的核(答案是正定函数,靠 Mercer 定理)。这里先信这件事,看看核技巧能换来什么。

这张图把核技巧最朴素的几何内容画了出来。原始平面上,两个同心环没法被任何直线分开。用 $\phi(x) = (x_1, x_2, x_1^2 + x_2^2)$ 把每个点抬一下:内环在某个高度,外环在另一个高度,一个平面就把它们切开了。核 $K(x, y) = (\langle x, y \rangle + 1)^2$ 对应的就是这种类型的"抬升”;你只算一个点积,整个 3D(其实更高维)的特征空间就免费送上。
这个构造之所以配得上"技巧"两个字,是因为大多数数学修法都要用一种货币去支付:更多内存、更多算力、更多参数、更多数据。核技巧哪样都不付。把线性模型换成核模型,代码上就是一行的事,用 kernel="rbf" 取代 kernel="linear",就悄无声息把算法接到了一个函数类上,这个类在 RBF 的情形下在任何紧集的连续函数空间里都是稠密的。你没写特征映射,没存特征映射,没付 $O(N)$
的内存或时间。你只改了一个超参,就换来了一个全新的假设宇宙。这在数学里少见,在工程里更少见。
核岭 vs 岭:双月牙上的正面对决#
不演了,直接跑一遍。同一份数据,同样的训练/测试切分,两个回归器:
| |
典型输出:
Ridge test acc = 0.872
KernelRidge test acc = 0.997
| 模型 | 假设类 | 测试准确率 | 训练时间 (n=1400) |
|---|---|---|---|
| Ridge | $x$ 的仿射函数 | 0.872 | 0.001 s |
| KernelRidge (RBF) | $\mathcal{H}_K$ 里的函数 | 0.997 | 0.18 s |
12 个准确率点,两个数量级的算力,没写一行特征工程。核把活全干了。
两件事值得在数字里多看一秒。第一,约 200 倍的慢并不致命,$n = 1400$ 上两个模型都眨眼就拟合完,核版本也远在一秒以内。第二,准确率从 87% 到 99.7% 在绝对值上很惊人,但回过头看也不意外:我们专门挑了一份线性模型啃不动的数据,任何能让模型弯起来的核都会把缺口补上。真正有趣的问题,第 3、4 篇会处理,是该挑哪个核、它的超参数怎么权衡偏置和方差。
一个具体例子:二次核#
$$K(x, y) = (x^\top y + 1)^2.$$ $$ \begin{aligned} K(x, y) &= (x_1 y_1 + x_2 y_2 + 1)^2 \\ &= (x_1 y_1)^2 + (x_2 y_2)^2 + 1 + 2 x_1 y_1 x_2 y_2 + 2 x_1 y_1 + 2 x_2 y_2 \\ &= x_1^2 y_1^2 + x_2^2 y_2^2 + 1 + 2 x_1 x_2 \, y_1 y_2 + 2 x_1 y_1 + 2 x_2 y_2. \end{aligned} $$ $$\phi(x) = \big(1,\; \sqrt{2}\,x_1,\; \sqrt{2}\,x_2,\; x_1^2,\; x_2^2,\; \sqrt{2}\,x_1 x_2\big) \in \mathbb{R}^6.$$ $$ \phi(x)^\top \phi(y) = 1 + 2 x_1 y_1 + 2 x_2 y_2 + x_1^2 y_1^2 + x_2^2 y_2^2 + 2 x_1 x_2 \, y_1 y_2. $$逐项核对每一个#
值得慢下来,把 $K(x,y)$ 的项和 $\phi(x)^\top\phi(y)$ 的项一对一摆出来。$\phi$ 的 6 个分量记为 $\phi_0, \dots, \phi_5,$ 配对 $\phi_i(x)\phi_i(y)$ :
| $i$ | $\phi_i(x)$ | $\phi_i(x)\phi_i(y)$ | 对应 $K(x,y)$ 的项 |
|---|---|---|---|
| 0 | $1$ | $1$ | 常数 $1$ |
| 1 | $\sqrt{2}\,x_1$ | $2\,x_1 y_1$ | 交叉项 $2 x_1 y_1$ |
| 2 | $\sqrt{2}\,x_2$ | $2\,x_2 y_2$ | 交叉项 $2 x_2 y_2$ |
| 3 | $x_1^2$ | $x_1^2 y_1^2$ | 平方项 |
| 4 | $x_2^2$ | $x_2^2 y_2^2$ | 平方项 |
| 5 | $\sqrt{2}\,x_1 x_2$ | $2\,x_1 x_2 y_1 y_2$ | 交互项 |
$\phi$ 里那些 $\sqrt{2}$ 不是装饰,正是它们让内积把交叉项的系数翻成 2。去掉它们等式立刻不成立。
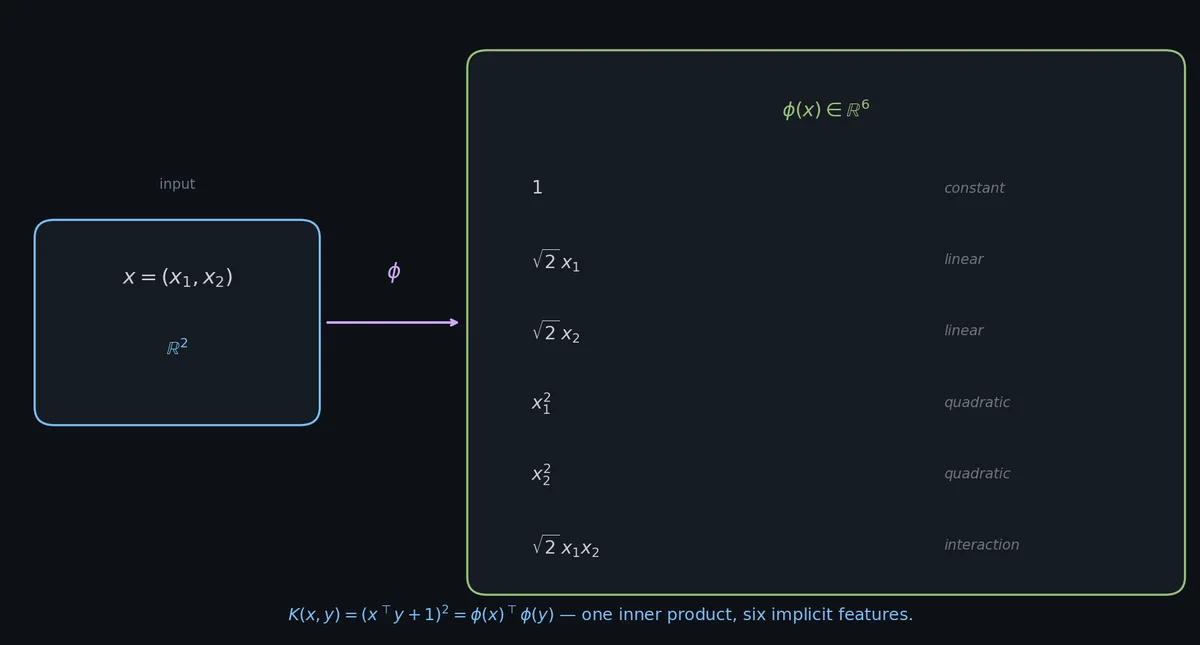
所以当你把简单闭式 $K(x, y) = (x^\top y + 1)^2$ 塞进核 SVM 时,SVM 实际上是在一个 6 维多项式特征空间里干活:一个常数项、两个线性项、两个平方项、一个交叉项。SVM 在 $\mathbb{R}^6$ 里找一个超平面,投回原 $\mathbb{R}^2$ 就是一条圆锥曲线(椭圆、抛物线、双曲线,或者一对直线)。
算 $K(x, y)$ 的代价是 $\mathbb{R}^2$ 上一个点积加一个平方,大约三次乘法和两次加法。而显式算 $\phi(x)^\top \phi(y)$ 是六次乘法五次加法,外加先构造 $\phi(x), \phi(y)$ 的开销。这个例子里省得不多,是因为特征空间还小。但你换成 $x \in \mathbb{R}^{500}$ 和 $K(x, y) = (x^\top y + 1)^5,$ 节省立刻变得惊人。
圆锥曲线那个对应关系也值得停一秒:$\mathbb{R}^6$ 里的 SVM 超平面用 6 个权重 + 1 个 bias 参数化,恰好是平面上一条一般二次曲线所需的自由参数数。核并没有在形而上意义上免费给你表达力,它给的是手工精心设计模型本就要指定的那个 7 维圆锥族的访问权,只是不用你提前承诺哪一条。模型自己挑数据想要的那条圆锥。
数值验证#
用五行 NumPy 验证一下这个等式:
| |
输出:
K(x,y) = 1.4884000000000004
phi(x).phi(y) = 1.4884000000000004
机器精度下完全一致,符合预期。同样的把戏可以放大:$K(x,y) = (x^\top y + 1)^k$ 对应一个 $\binom{d+k}{k}$ 维的多项式特征映射,而你一次都不用把它写出来。
到底省多少#
$d$ 维上的 $k$ 阶多项式核 $K(x, y) = (x^\top y + c)^k,$ 一次求值需要:
- $\mathbb{R}^d$ 上一个内积:$d$ 次乘法 + $d - 1$ 次加法。
- 加常数 $c$ :一次加法。
- 算 $k$ 次幂:快速幂下 $\log_2 k$ 次乘法,朴素就是 $k - 1$ 次。
总计 $O(d + \log k),$ 主导项是点积。对比显式路线的 $O\!\left(\binom{d+k}{k}\right).$
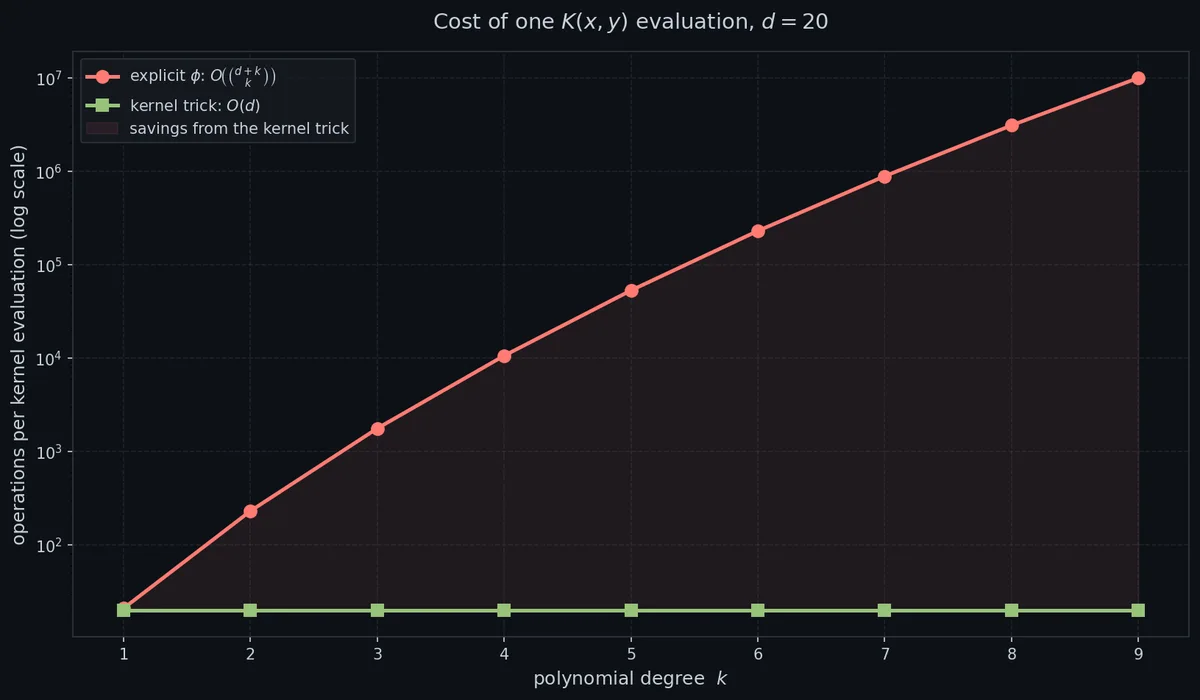
$d = 20$ 时,核技巧在 5 阶上能省 5 万倍,到 8 阶就是百万倍量级。而且这还是保守数字,真实应用里 $d$ 经常是几百几千。
值得就"训练一整个算法"再补一句,不只是单次 $K(x,y)$ 。$n$ 个训练点上的核 SVM 要 $n(n+1)/2$ 次核求值来搭 Gram 矩阵。$n = 5{,}000$ 时大概 1250 万次求值。$d = 100,$ 5 阶多项式核,每次求值约 100 次浮点运算,整个 Gram 矩阵大约 $10^9$ flops,现代 CPU 一秒以内。显式特征路线则要构造并存 $5{,}000$ 条长度 $\binom{105}{5} \approx 9.6 \times 10^7$ 的向量,float64 下约 3.8 TB。差距不是细微的。
警告:核没法救你 $n$ 大#
漂亮的算术后头要补一句冷的:核方法单对便宜,但样本数上是平方甚至立方。大多数核算法都要构造 $n \times n$ Gram 矩阵 $K_{ij} = K(x_i, x_j).$ 这个矩阵有 $n^2$ 个元素,大部分操作(矩阵-向量乘、特征分解)至少 $O(n^2),$ 常常 $O(n^3).$
两种方案的渐近开销对比:
| 方案 | 构造特征 | 训练(线性/核) | 单点预测 |
|---|---|---|---|
| 显式 $\phi$ + 线性模型 | $O(n \cdot N)$ | $O(n N^2 + N^3)$ | $O(N)$ |
| 核技巧 + 对偶算法 | $O(n^2 d)$ 构 Gram | $O(n^3)$ 求逆 | $O(n d)$ |
所以核技巧是把"$d$ 大"的灾难换成了"$n$ 大"的灾难。$n$ 上百万时,朴素核方法跑不动,要靠 Nystrom、随机傅里叶特征这些近似手段,第 6 篇会讲。$n$ 在中小规模(比如 5 万以下)时,核方法跟深度网络可以打得有来有回,尤其当核的归纳偏置跟数据结构对上时常常更胜一筹。
具体到内存预算,Gram 矩阵就把故事讲完了。对称 $n \times n$ float64 矩阵存上三角占 $8n^2 / 2$ 字节,所以:
| $n$ | Gram 内存(float64) | 32 GB 机器上的状态 |
|---|---|---|
| 1{,}000 | 4 MB | 无所谓 |
| 10{,}000 | 400 MB | 没问题 |
| 50{,}000 | 10 GB | 紧但能撑 |
| 100{,}000 | 40 GB | 得 out-of-core 或者 64+ GB 机器 |
| 1{,}000{,}000 | 4 TB | 不近似就别想 |
$n$ 上 $5 \times 10^4$ 之后,“整张 Gram 留在内存里"就不再现实。这正是近似那条文献线起作用的地方:Nystrom 和随机傅里叶特征都是构造一个有效秩 $m \ll n$ 的低秩代理 Gram,拿一点精度换 $O(nm)$ 内存和 $O(nm^2)$ 训练时间。第 6 篇整篇都在讲这个取舍。
思考: $n$ 对 $d$ 的取舍是 ML 系统设计里最深的实务张力。核、transformer 的 self-attention、高斯过程都带这种 $O(n^2)$ 味道,它们都索引数据点的两两对,现代所有的加速(Nystrom、Performer、稀疏 GP、FlashAttention)都是在绕同一个矩阵的聪明办法。在核的语境里第一次遇到这个取舍,是最干净的地方。
收支平衡点在哪#
换个更实务的看法:给定 $d$ 和 $k,$ 数据集到多大时,显式特征路线会比核路线便宜?比较两个主导项,存特征的 $n \cdot N(d, k)$ 对上 Gram 矩阵的 $n^2$ ,平衡点大约在 $n \approx N(d, k).$ 几个数字:
| $d$ | $k$ | $N(d, k)$ | 平衡点 $n$ | 小 $n$ 时的结论 |
|---|---|---|---|---|
| 5 | 3 | 56 | $\sim 56$ | 两条路都行 |
| 10 | 4 | 1{,}001 | $\sim 1{,}000$ | 1k 之内核赢 |
| 20 | 5 | 53{,}130 | $\sim 53{,}000$ | 核大胜 |
| 100 | 3 | 176{,}851 | $\sim 180{,}000$ | 核大胜 |
真实场景里 $d$ 经常是几百,$k \geq 3$ 才能捕捉到有意思的结构,所以平衡点舒舒服服地高过任何正常数据集大小,核就是该选的。例外是非常高 $n$ 、不高 $d, k$ 的场景(web 规模上对 hashed 特征跑线性模型),这时显式特征加 SGD 反而胜出。
为什么核方法重要#
抛开机械层面,看看这整套构造到底给了你什么。
(1) 不用显式特征也能拿到表达力: 任何对应到 $\phi: \mathbb{R}^d \to \mathbb{R}^m$ ($m \gg d$ )的核(RBF 核对应的甚至是无穷维),都让线性算法用上一个大得多的假设类,工程成本只是挑一个闭式 $K$ 而已。
(2) 凸优化、闭式解: 因为算法在特征空间里还是线性的,凸性和全局最优解的保证全都还在。核 SVM 是凸二次规划,核岭有闭式解,高斯过程回归有闭式后验。没有鞍点,没有学习率调度,没有热启动。
(3) 一个统一框架: 同一个核 $K$ 可以插进很多算法:分类用核 SVM,回归用核岭,降维用核 PCA,聚类用谱聚类,双视图对齐用核 CCA,贝叶斯回归和贝叶斯优化用高斯过程。相似度只设计一次,到处复用。
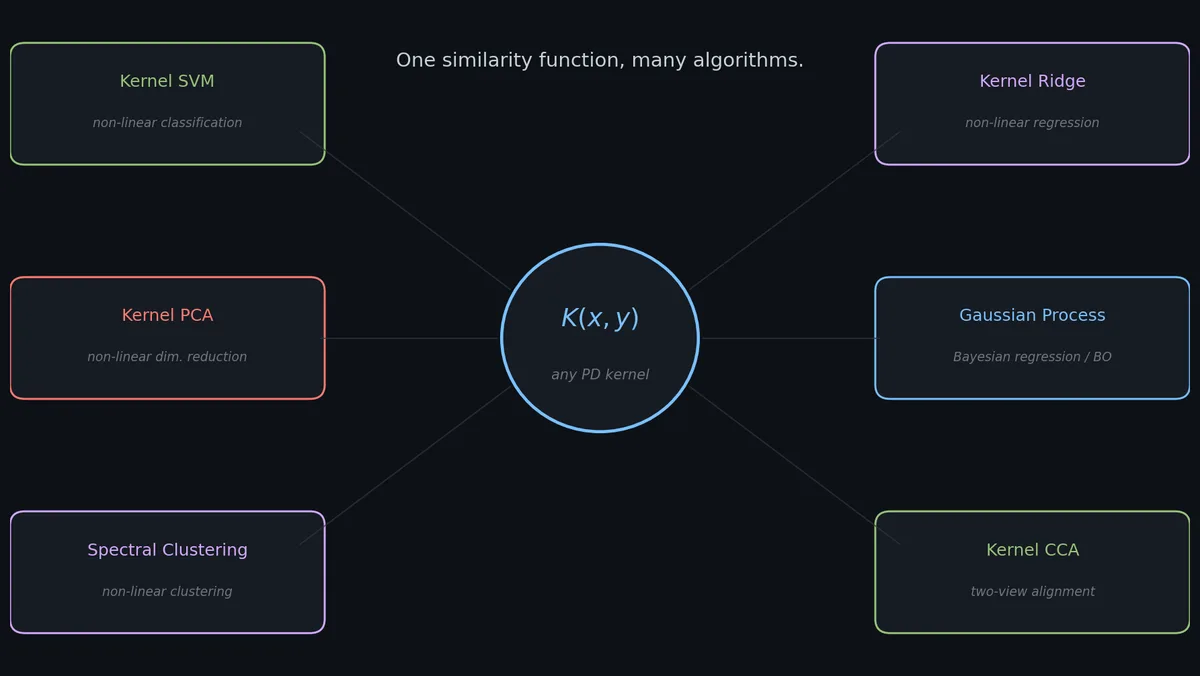
(4) 扎实的理论基础: 再生核希尔伯特空间(RKHS)构造给了你一整套关于"模型在拟合什么"的泛函分析图景:泛化界、样本复杂度、函数空间范数。其他模型类很少有这么干净的理论。
(5) 用核来编码领域偏置: 核本质上是个相似度函数。选对了核,你就编码了强先验:RBF 核说"相似输入应该有相似输出”,周期核说"输出以周期 $p$ 重复",字符串核说"两条蛋白序列共享许多子序列就相似"。这是工程师把领域知识灌进通用算法的操作杆。
(6) 模块化与可组合: 核可以组合。核之和还是核(正定性留到第 2 篇证),核之积也是,限制到子集还是。所以一个异构输入(一组:向量+字符串+图)上的核,可以由向量上的多项式核、字符串上的 spectrum 核、图上的 Weisfeiler-Lehman 核加起来构造。上层算法不在乎,它只看见一个相似度矩阵。这种可组合性是核世界里对应神经网络层堆叠的东西。
(7) 模型类的可解释性: 因为核显式编码了一个相似度函数,你可以把它看出来、画出来、对着领域知识做 sanity check。“transformer 第 17 层到底表征了什么"没有等价物,至少没有能在一行里写完的等价物。在审计模型不可妥协的场合(受监管行业、科学发表),核提供了一种少有的其他表达力模型能匹敌的机理透明度。
(8) 样本效率: 给你泛化界的同一套 RKHS 理论也告诉你:要学一个给定复杂度的函数需要多少样本。对光滑目标函数,核方法能达到 minimax 最优样本复杂度,意思是没有任何估计器(无论模型类)能在渐近意义上做得更好。深度学习在这个区域没有可比的理论;核是"我最少能用多少样本"的金标准。
真实落地案例#
几个真在生产里靠核跑的系统:
- SVM 做文本分类(21 世纪初的垃圾邮件过滤): 词袋表示上跑核 SVM 是深度学习之前的生产主力。Joachims 的 SVMlight 撑起了企业邮件过滤;TF-IDF + 线性核到今天仍是任何新系统要打的强 baseline。后来 string-subsequence 核又把同样的思路推广到字符级特征。
- 高斯过程做贝叶斯优化(超参调优): Google Vizier、SigOpt、Facebook 的 Ax 都用 GP 回归加精心挑选的核来建模一个昂贵黑盒函数(训练模型、跑 A/B 测试)的损失曲面。核的平滑性假设正是让贝叶斯优化样本高效的关键,典型的 GP-BO 循环 20-50 次昂贵评估就收敛,随机搜索同样目标要几千次。
- 核 PCA 做工业监控里的异常检测: 正常运行落在一个低维非线性流形上时,核 PCA 能挑出离开流形的点。半导体晶圆工厂的过程控制、旋转机械故障检测都在用,漏报一个异常的成本(毁掉一批晶圆、烧毁涡轮)足以抵掉 $O(n^2)$ 的核代价。
- 生物信息里的字符串核: spectrum 核和 mismatch 核给 SVM 一种"不做对齐就能比较 DNA / 蛋白序列"的天然手段。一些 Pfam 家族分类器和远缘同源检测器就是这么搭的;核里编码的"两条序列共享许多短子串就相似"恰好是该领域的正确归纳偏置。
- 高斯过程在地统计学和贝叶斯模型校准里: “kriging”,也就是 GP 回归在矿业里的原名,仍是矿石品位插值的标准工具,同一套机制也撑着气候模型和物理模拟里的不确定性量化。一个尊重地形特征的定制核(比如沿地质走向各向异性的 Matérn 核)经常能把通用黑盒方法打趴下。
深度学习的时代里,“核方法还有什么用"这个问题被问过无数次。诚实的答案有几条:第一,小样本上核还是赢,深度网络会过拟合。第二,通过高斯过程能给出可解释的不确定性,对贝叶斯优化、主动学习、任何"模型得知道自己不知道什么"的任务都是无价的。第三,也是这个系列最看重的一条:它本身就是一段漂亮的数学,把"非线性建模"到底是什么这件事讲清楚了。理解核方法是任何严肃 ML 教育里承重的一块基石,哪怕你日后大部分时间都在训 transformer。
什么时候不要用核#
案例的反面,也得诚实列几条"别折腾了”:
- $n$ 上百万且有 GPU 预算: $O(n^2)$ 的 Gram 矩阵直接致命。两层 MLP 或者表格 GBDT 分钟级就训完,朴素核方法甚至连 Gram 都构不出来。
- 高维稀疏数据 + web 规模 $n$ : 线性模型 + 哈希技巧(Vowpal Wabbit、FTRL)统治这块。你这种场景想要的"核"就是线性核,那干脆别走核形式了。
- 需要逐点在线更新: 核方法也能在线化(passive-aggressive、对偶上的投影 SGD),但 维护开销重、存储还在涨。神经网络处理得优雅多了。
- 真正想要的是深层复合: 卷积、注意力、循环。是有深层核类比(CKN、NTK),但你都到这一步了,已经放弃了大部分简洁性,应该问问自己为什么没直接训那个网络。
知道什么时候不该上核,是一半的功夫。另一半是认出那些核仍然是真正正确工具的场景:中小数据、有结构先验、不确定性重要的任务,贝叶斯优化、地统计、计算生物、低数据科学 ML。
粗暴一点的经验法则:你的数据集如果能以浮点方阵的形式塞进内存,核方法至少值得跑一遍实验。如果塞不进去,那你要么在线性模型 + 哈希的世界里,要么在深度学习的世界里,核方法只会以它的近似形态出现。
思考: 最近的"神经正切核”(NTK)这条线证明了无限宽神经网络的行为完全等同于一个特定核(闭式、可计算)下的核方法。这不是巧合,而是一个深刻陈述:用梯度下降训出来的、线性于特征的模型,是过参化神经网络的自然极限。核不是 1990 年代的古董,而是现代深度学习理论里最重要结果之一最自然的表达语言。
思考题#
留几道小题,往下走之前先把上面的内容内化一遍。前三道是短小的纸笔练习,后两道走得稍远一点。
题 1: 取 $x, y \in \mathbb{R}^3$ 和三次核 $K(x, y) = (x^\top y)^3.$ 用多项式定理展开 $(x_1 y_1 + x_2 y_2 + x_3 y_3)^3,$ 写出显式特征映射 $\phi: \mathbb{R}^3 \to \mathbb{R}^?.$ $\phi(x)$ 一共多少个分量?(提示:数一下 3 在 3 个非负整数里的有多少种和式分解。)
题 2: 设 $K_1, K_2$ 都是核(都有特征映射表示)。证明 $K(x, y) = K_1(x, y) + K_2(x, y)$ 也是核,用 $\phi_1, \phi_2$ 构造它的特征映射就行。(这是"加法封闭性"里容易的一半;难的那半,也就是证明它正定,是第 2 篇的活。)
题 3: RBF 核是 $K(x, y) = \exp(-\gamma \|x - y\|^2).$ 证明 $K(x, x) = 1$ 对任意 $x$ 都成立,且 $x \neq y$ 时 $0 < K(x, y) \leq 1.$ 这关于隐式特征映射 $\phi$ 的几何说了什么?特别地,在隐式希尔伯特空间里 $\|\phi(x)\|$ 等于多少?
题 4(选做,稍难): 对 $x, y \in \mathbb{R}^d$ 上的多项式核 $K(x, y) = (x^\top y + 1)^k,$ 数一下隐式特征映射 $\phi$ 的分量个数。验证你的公式在 $d = k = 2$ 时给出 $6$ (和上面的具体例子一致),并解释为什么它恰好等于 $\binom{d + k}{k}.$
题 5(实操向): 把上面"核岭 vs 岭"的实验改一下:让 $n$ 从 $500$ 增到 $10{,}000,$ 记录两个模型的训练耗时,画在同一张图上。你机器上多大的 $n$ 让核岭过 10 秒?多大的 $n$ 会爆内存?跟上面的复杂度表对比一下。
接下来#
这一篇讲了核方法为什么存在。第 2 篇会告诉你哪些函数才有资格当核:正定函数的理论和 Mercer 定理,并回答这里被一笔带过的两个问题:对任何"合理的"特征映射 $\phi,$ 对应的 $K$ 是否总存在?反过来,每个 $K$ 是否一定对应某个 $\phi?$
短答案是:是的。长答案是 20 世纪泛函分析最优雅的几个定理之一。下篇配图慢讲。
一瞥 RBF 核#
$$K_{\text{RBF}}(x, y) = \exp(-\gamma \|x - y\|^2).$$把 $\exp$ 做泰勒展开就能看到,这个核对应的是一个无穷维特征映射,它隐式地包含所有阶数的所有多项式,按阶乘加权。塞进核 SVM 里,一行代码就让你拥有一个在任何紧集的连续函数空间里都稠密的函数类。
$\gamma$ 控制相似度随距离衰减的速度。$\gamma$ 大 → 只有非常近的点才算相似 → 模型非常灵活、易过拟合。$\gamma$ 小 → 几乎所有点都相似 → 非常平滑、易欠拟合。第 3 篇会专门花一整篇讲怎么理解和挑 $\gamma.$ 这里只需感受到:一个闭式相似度函数上的一个超参,就给了你一个完全可调的旋钮,从"几乎线性"一路转到"训练集每个点都被精确插值",中间任何分寸都能拿到。
剩下七篇的路线图#
给个上下文知道往哪走:
- 第 2 篇 — 数学基础: 正定函数、Mercer 定理、核与特征映射的等价性。给这套机制开许可证的那块纯数学。
- 第 3 篇 — RBF 核: 为什么高斯核是"默认通用",带宽参数 $\gamma$ 到底在控什么,怎么挑。
- 第 4 篇 — 再生核希尔伯特空间: 几何与泛函分析的图景。核方法到底在哪个空间里拟合函数?
- 第 5 篇 — 核 SVM、核岭、核 PCA: 三大经典算法,从头用核技巧推一遍。
- 第 6 篇 — 近似:Nystrom 与随机傅里叶特征: 怎么把核方法推过 $O(n^2)$ 这堵墙。
- 第 7 篇 — 高斯过程: 同一套数学的贝叶斯面孔,加上主动学习、贝叶斯优化的应用。
- 第 8 篇 — 现代联系: NTK、深度核学习、以及核在大模型时代里的位置。
有时间就按顺序读,每篇都基于上一篇。如果只读三篇,挑第 2、5、7 篇,分别覆盖理论、经典算法、最活跃的现代应用。
收尾的一个想法#
如果让这篇文章只留下一件事带走,那就是核技巧暗示的操作顺序。处理非线性的朴素思路是"先算一个高维表示,再在它上面跑线性算法"。核技巧说"把线性算法写成对偶形式,让内积悄悄去访问那个高维表示,但永远不构造它"。这种反转:算法先行、表示隐式,才是值得带走的概念动作。计算数学里最漂亮的几个结果都有这个味道:FFT(别算多项式系数,算值)、自动求导(别符号展开梯度,传播它)、随机 SVD(别构造矩阵,sketch 它)。在一个地方看见了这个模式,你就会在到处都开始发现它。
本文是 核方法 系列的第 1 篇,共 8 篇。 下一篇: 第 2 篇 — 核方法的数学基础:正定核与 Mercer 定理


