
核方法(四):常见核函数族——RBF、Matern、多项式、周期与更多
你真正会用到的几族核函数:RBF(高斯)、多项式、线性、Matern、周期、sigmoid。何时选哪个、超参直觉,以及核怎么组合。
你第一次在 sklearn 里写 SVC(kernel='rbf'),gamma 设了多少?'scale'?'auto'?滚动过那个默认值时你压根没看一眼。三个月后模型严重过拟合,Gram 矩阵看着像单位阵,你也不知道是哪个旋钮拧错了。大多数"核调参"的债,其实是选核的债,你为了错误的理由选了默认的核,再多 grid search 也救不回来。

前三篇把"为什么"和"理论"铺好了:线性方法到天花板(Part 1),正定核把你抬起来(Part 2),RKHS 让被抬起来的空间真的是个 Hilbert 空间(Part 3)。这一篇是菜单。六族核函数,每族对你的数据做了什么假设,以及文档里没写、但老司机都知道的那些经验规则。每一节都会给你数学定义、真正重要的那个超参、一段能跑的 sklearn 代码,以及用错了之后该预期出现的失败模式。
RBF(高斯)核:默认之王#
$$K(x, y) = \exp\!\left(-\gamma \,\|x - y\|^2\right) \quad \text{或等价地} \quad \exp\!\left(-\frac{\|x-y\|^2}{2\sigma^2}\right),$$就是 sklearn 里 'rbf' 实际算的东西。两种形式的换算是 $\gamma = 1/(2\sigma^2).$
教材里偏爱 $\sigma$
(长度尺度,和数据单位一致);库的代码偏爱 $\gamma$
(长度平方的倒数,越大代表越尖)。挑一个用一下午就习惯了。
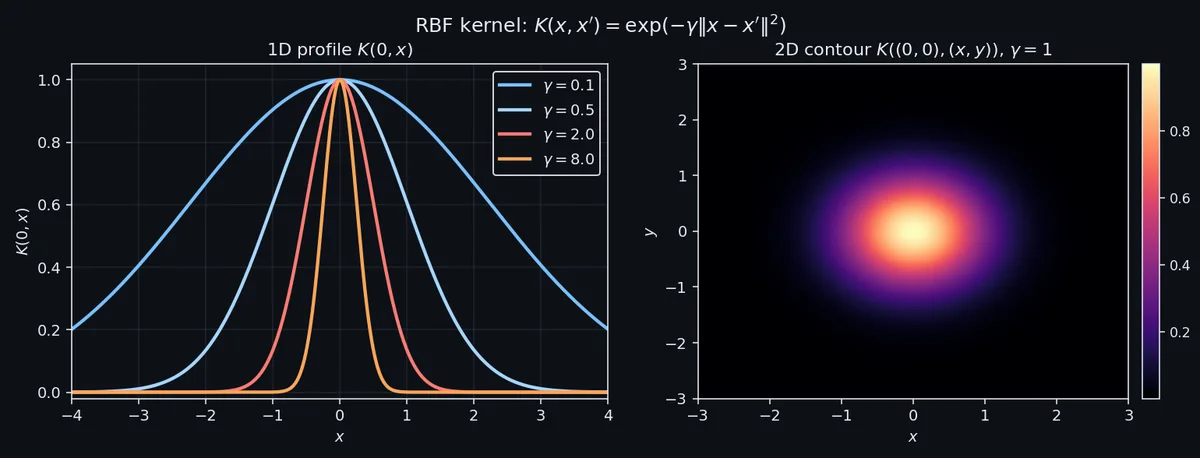
为什么它是默认。 三个性质共同让 RBF 成为"实在不知道选什么就选它"的核。第一,它是通用的:给足够数据和正确带宽,可以任意精度地逼近紧集上任意连续函数。第二,它无限可微,对应的函数类非常光滑。第三,特征空间是无穷维的,Mercer 展开里每个 $\lambda_k$ 都是正的,所以你怎么加数据都耗不尽它的表达力。
唯一的旋钮:$\gamma$ 。 RBF 调参几乎全在调 $\gamma$ 。太大,每个训练点变成孤岛;核矩阵接近单位阵;训练精度到 1,测试精度崩盘。太小,每两个点看着都一样;核近似常数;模型欠拟合到全局均值。这两种失败形态见过一次就能认出来,但"太大"和"太小"之间的窗口往往只跨一个数量级。
$$\sigma_0 = \mathrm{median}(\|x_i - x_j\|), \qquad \gamma_0 = \frac{1}{2 \sigma_0^2}.$$它管用是因为把核放在了数据距离分布的正中央:不至于宽到所有点看着都一样,不至于窄到所有点看着都不一样。然后在它两边各拉一个数量级做 log-grid,交叉验证选最优。
代码上中位数启发就三行:
| |
完整例子:RBF SVM 在 make_moons 上。 两月牙数据是非线性可分的标配玩具。线性 SVM 大概顶到 88% 准确率;RBF 一上来到 99% 以上。
| |
两个值得记住的观察:(1) 网格里赢出来的 $\gamma$ 几乎总是落在中位数启发种子的半个数量级内,所以网格搜三个数量级是浪费算力;(2) 赢出来的 $C$ 依赖噪声水平,低噪数据下 $C$ 想要大(margin 紧),高噪数据下 $C$ 想要小(margin 松)。
完整例子:用 RBF 跑 GP 回归。 同一个核也能驱动高斯过程回归。这里拟合一个带噪正弦;GP 同时返回后验均值和后验标准差,这就是它相对 SVM 的杀手锏。
| |
边际似然优化器学到 length_scale ~ 1.2 和 noise_level ~ 0.01,都接近真值。把 length_scale=0.05(远远过小)拿来重拟合,你会看到后验在每个训练点上插值得严丝合缝,而点与点之间的预测方差爆炸,这就是经典的"GP 过拟合"诊断信号。
sklearn 备注。 gamma='scale' 算出来是 $1 / (n_{\text{features}} \cdot \mathrm{Var}(X))$
,对做过标准化的特征是合理的。gamma='auto' 算出来是 $1/n_{\text{features}}$
,对任何数据都不合理,它完全忽略了数据的实际散布。不要用。
什么时候不要选 RBF。 我见到新手反复踩坑的三种场景。(1) 超高维稀疏数据,文本 TF-IDF、one-hot 类别,中位数距离已经没有信息量,因为成对样本本来就近似正交。线性赢。(2) 已知周期的时序。RBF 在时间索引上是糟糕的季节模型;核不知道第 366 天和第 1 天是相似的。用周期核。(3) 真正离散的输入,字符串、图、树。RBF 在拍平的表示上把让数据有意思的结构全扔了;用专用核。
多项式核#
$$K(x, y) = (\gamma\, \langle x, y \rangle + c)^d.$$多项式核显式地对应到所有不超过 $d$ 阶的单项式组成的特征映射。$d=2$ 时,就是两两乘积 $x_i x_j;$ $d=3$ 时是三元乘积;以此类推。特征空间是有限维的,$\binom{d_{\text{in}} + d}{d}$ ,很大但有界,不像 RBF 的无穷谱。

数值上可以验证:
| |
两个数到机器精度一致。这就是最简朴形式的"核技巧":一个 6 维的内积用 $O(d_{\text{in}}) = O(2)$ 时间算完,而不是 $O(6).$ 这里常数因子的赢看不出来,但到 $d=5$ 在 $\mathbb{R}^{100}$ 上时就要命了,那时显式特征映射有 9600 万维坐标。
KernelRidge(poly) vs Ridge(PolynomialFeatures)。 数学上等价,计算上不一样:
| |
$n < d_{\text{out}}$ 时核岭赢(这里 $d_{\text{out}} = \binom{8+2}{2} = 45,$ 所以显式特征赢);展开维度小的时候显式特征赢。粗略的临界公式是 $n^3 \approx n \cdot d_{\text{out}}^2;$ 越过这条线就换显式特征。
什么时候用它。 稀疏高维数据,你心里有指名道姓的交互要建模。两个范式场景:
- NLP 用 bigram 或 trigram。 word-count 向量上的 2 次多项式核,本质上是在数两个文档共享的词对个数。
- 基因组学的 epistasis。 成对 SNP 交互是很多 GWAS 分析的核心。
什么时候不要用。 稠密、低维、有光滑结构的数据。RBF 几乎每次都赢,中等阶数的多项式太僵硬,包不住连续决策边界;高阶多项式则疯狂震荡。
超参速记。
- 次数 $d$ 。 留在 $\{2, 3\}.$ 5 阶以上几乎肯定过拟合(单项式基的杠杆太高)。
- $\gamma$ 。 缩放内积。多项式核对特征量纲极其敏感,一定先做标准化,否则 $\gamma\langle x, y\rangle$ 在高阶项上会爆。
- $c$ 。 自由常数。$c=0$ 只保留最高阶单项式(纯 $d$ 阶);$c=1$ 把 $0$ 到 $d$ 阶全混进去。默认 $c=1$ 几乎总是你想要的。
| 对比项 | 多项式-2 | RBF | 线性 |
|---|---|---|---|
| sklearn 别名 | 'poly', degree=2 | 'rbf' | 'linear' |
| 关键旋钮 | $d, \gamma, c$ | $\gamma$ | 只有 $C$ |
| 特征维度 | $\binom{d_{\text{in}}+d}{d}$ | $\infty$ | $d_{\text{in}}$ |
| 光滑度 | $d$ 阶可导 | $C^\infty$ | $C^\infty$ 但线性 |
| 擅长 | 已知交互 | 光滑稠密 | 高维稀疏 |
| 典型失败 | 高阶爆炸 | 单位阵 Gram | 欠拟合 |
一个调试反面教材。 我曾经为一个"类别交互"模型上的 polynomial-3 SVM 调了一个礼拜的参,怎么调都不收敛。最后的解药是标准化,其中一个特征的范围是 $[0, 10^4],$ 其余都是 $[-1, 1].$ 3 次方下那个特征的立方在核值里盖过其它项十二个数量级,Gram 矩阵实质上是 rank-1,QP 求解器原地打转。教训放之四海:在多项式核之前一定要标准化;核能看到尺度,哪怕它看不到含义。
线性核:核中的"无核"#
$$K(x, y) = \langle x, y \rangle.$$最平凡的核:没有特征映射,每次评估 $O(d),$ 等价于在原始数据上直接跑线性算法。为什么还要列它?因为对某些数据形态它就是正确答案,换成 RBF 除了调参痛苦你什么也得不到。
线性核合适的场景。
- 线性可分数据。 比你以为的常见,尤其当你已经做过特征工程之后。
- 超高维稀疏数据。 文本(TF-IDF、词袋)、基因表达矩阵、大规模 one-hot 类别。高 $d$ 下,随机单位向量近似两两正交,所以数据本身已经"足够散开",RBF 帮不上忙。
- 作为基线。 在任何非线性核之前,先跑一个线性 SVM 或线性岭回归。如果线性赢了,就拿下,训练更快、预测更快、解释更容易。
完整例子:LinearSVC vs SVC(kernel='linear') vs SGD。 三个 sklearn 类解的是同一个线性 SVM 优化问题,扩展性却天差地别。在 20-newsgroups 上跑一下(TF-IDF,约 11k 样本,约 130k 特征):
| |
普通笔记本上大概看到:SVC(linear) 90 秒,LinearSVC 4 秒,SGDClassifier 1.5 秒。基于核的路径(SVC)构造 $n \times n$
的 Gram 矩阵,付 $O(n^2)$
内存加 $O(n^2 d)$
时间;显式线性路径(LinearSVC、SGD)直接在稀疏特征矩阵上工作,每轮付 $O(\text{nnz})$
。
一个经验法则。 文本分类里,线性 SVM 在精度上常常打赢 RBF SVM,速度还快 100 倍。维度灾难这次站在你这一边;用上它。
超参速记。
- 只调 $C$ 。 没有 $\gamma,$ 没有 $d,$ 没有 $c.$ Log-grid $\{10^{-2}, 10^{-1}, 1, 10, 10^2\}$ 就完事。
- 总是标准化(或者
TfidfVectorizer已经给了单位范数行)。线性 SVM 只在优化器收敛之后才对特征尺度不变;尺度差会把收敛拖慢几个数量级。 LinearSVC的dual='auto'在 $n > d$ 时走原问题、$n < d$ 时走对偶。永远比 libsvm 的SVC(kernel='linear')快。
为什么 SGD 路径有时能赢坐标下降。 SGDClassifier 配 loss='hinge' 解的是和 LinearSVC 同一个原问题,但用的是随机梯度更新。当 $n$
极大(百万级文档)时,SGD 的单步代价是 $O(\text{一个样本的 nnz})$
,而不是 $O(\text{所有样本的 nnz})$
,所以走一遍数据就可能比一轮完整坐标下降还快。代价是对超参敏感,alpha、learning_rate、max_iter 都要管,在几万量级的中等 $n$
上 LinearSVC 还是更快而且更准。SGD 是等到 LinearSVC 装不下时才换的,不是一开始就上的。
Matern 核:高斯过程的标配#
$$K_\nu(r) = \frac{2^{1-\nu}}{\Gamma(\nu)} \left(\frac{\sqrt{2\nu}\, r}{\ell}\right)^{\!\nu} \! \mathcal{K}_\nu\!\left(\frac{\sqrt{2\nu}\, r}{\ell}\right), \qquad r = \|x - y\|,$$其中 $\mathcal{K}_\nu$ 是第二类修正贝塞尔函数,$\Gamma$ 是伽马函数。看着吓人;实践中没人手算这个,因为它有一个可调的光滑度参数 $\nu,$ 以及三个能闭式简化的特例:
- $\nu = 1/2:$ 指数核,$K = \exp(-r/\ell).$ 样本路径连续但处处不可导。用来建模粗糙函数。
- $\nu = 3/2:$ 一阶可导。地统计学默认。闭式 $K = (1 + \sqrt{3}r/\ell)\exp(-\sqrt{3}r/\ell).$
- $\nu = 5/2:$ 二阶可导。GP 回归的常用配置。闭式 $K = (1 + \sqrt{5}r/\ell + 5 r^2/(3\ell^2))\exp(-\sqrt{5}r/\ell).$
- $\nu \to \infty:$ 回到 RBF。无限光滑。

为什么用 Matern 而不是 RBF。 RBF 的无限光滑对几乎所有真实函数都过强。股价、传感器读数、地质测量,没有一个是无限可微的。Matern-$5/2$ 的样本路径有二阶导但没有三阶导,更贴合现实。GP 回归经典的失败模式,“后验过度自信、长度尺度爆炸、超参优化器发散”,经常把 RBF 换成 Matern-$5/2$ 就好了。
三句话定 $\nu$ 。
- 如果你怀疑底层函数有尖角或突变(金融收益、分段边界),用 $\nu = 1/2.$
- 如果函数是"物理性"的(温度、地形、传感器漂移),用 $\nu = 5/2$ ,二阶导存在,三阶不存在。
- $\nu = 3/2$ 只在有具体理由时用(它是地统计学的标配,其它领域不常见)。
完整例子:在带噪数据上比较 Matern 和 RBF。 用同一段噪声 1D 函数同时拟合两种核,比较样本外表现。
| |
在这种"粗糙但不锯齿"的数据上,Matern-$5/2$ 一般比 RBF 的 MSE 低 5-15%,预测方差也更校准。在真正光滑的数据上(解析函数、流体仿真),RBF 微胜一筹。“默认 Matern-$5/2,$ 用边际似然验证"几乎不会出错。
sklearn 接口。 sklearn.gaussian_process.kernels.Matern(length_scale=1.0, nu=1.5)。注意 nu 是构造时固定的参数,不会被 fit() 学习。你根据领域知识从 $\{1/2, 3/2, 5/2\}$
里挑一个 $\nu$
;length_scale 和噪声方差由数据学。
| 对比项 | Matern-$1/2$ | Matern-$3/2$ | Matern-$5/2$ | RBF (Matern-$\infty$ ) |
|---|---|---|---|---|
| 可导性 | 0 阶 | 1 阶 | 2 阶 | $\infty$ |
| 样本路径 | 连续锯齿 | 一阶光滑 | 二阶光滑 | 解析 |
| 典型场景 | 金融、尖角 | 地统计 | GP 默认 | 光滑物理 |
sklearn nu | 0.5 | 1.5 | 2.5 | 直接用 RBF |
| 长度尺度作用 | 同 RBF $\ell$ | 同上 | 同上 | 同上 |
一个微妙的坑:噪声 vs 光滑度的混淆。 当你把 RBF 换成 Matern-$1/2$
拟合突然变差时,常见元凶是你把测量噪声吸收成了核粗糙度。Matern-$1/2$
在说函数本身就糙;WhiteKernel 在说函数光滑、但你透过噪声观测。单次采样下两者看着可能一模一样,但外推时完全不同,Matern-$1/2$
给的是锯齿预测,“光滑+噪声"模型给的是平滑置信预测加噪声包络。拿不准时两个都拟合并比较边际似然;sklearn 用 gp.log_marginal_likelihood(gp.kernel_.theta) 返回这个值。
周期核与谱核#
$$K(x, y) = \exp\!\left(-\frac{2 \sin^2(\pi \|x - y\| / p)}{\ell^2}\right),$$捕捉严格周期性,周期为 $p.$ 两个距离恰为 $p$ 的输入,$K = 1$ (完全相关);距离为 $p/2$ 时 $K$ 取最小值。参数 $\ell$ 控制单个周期内周期性绑得多紧。

什么时候用。 任何你知道周期的场景:温度(年)、用电负荷(日 + 周)、零售销量(周 + 年)、音频音高跟踪、EEG 节律。
谱混合核是它的推广:频域里一组高斯的求和,对应到输入域里一个复杂、可能准周期的核。Wilson–Adams 2013 的论文证明它能自动发现未知的周期。当你怀疑有周期但不知道周期长度时很有用。
完整例子:Mauna Loa CO2。 这是组合核的经典演示。1958 年起的大气 CO2 记录有三个明显成分,平滑的长期趋势、年度季节循环、短期测量噪声,以及第四个不那么明显的(来自厄尔尼诺一类事件的中期十年尺度抖动)。我们用四个核的和拟合,看看优化器学到了什么。
| |
优化器学到的长期 RBF 长度尺度在 50 年量级(趋势平滑),周期成分周期恰好 1 年,年度循环衰减长度在 100 年量级(循环能持续),噪声约 0.2 ppm(匹配测量精度)。20 年外推得到的就是著名的 Rasmussen–Williams 图:自信延续的上升趋势,继续走的年度循环,亚线性变宽的不确定带,因为模型学到了结构,不是死记数据。
值得注意的是,四个核里换掉任意一个,拟合都肉眼可见地恶化。去掉 k_seas 模型无法外推季节性。去掉 k_med 残差会有系统性的十年偏差。去掉 k_long 趋势会乱走。每个核编码了一个先验,而这个先验是字面意义上的,直接从核表达式里读出来。
周期核超参速记。
periodicity通常应该_bounds='fixed'。 知道周期(1 天、1 年)就设上再冻结。让优化器自己找会找到伪周期。- 乘上一个 RBF。 纯
ExpSineSquared强制无限远都严格周期,对真实数据太僵。RBF * ExpSineSquared给的是准周期核,允许周期慢慢漂移。 - 盯紧
ExpSineSquared里的长度尺度 $\ell$ 。 小 $\ell$ 表示尖锐的周期结构(距离 $p/2$ 时函数差异巨大);大 $\ell$ 表示平滑的正弦循环。sklearn 默认length_scale=1.0在标准化数据上是合理的。
Sigmoid 核:一个警告#
$$K(x, y) = \tanh(\gamma\, \langle x, y \rangle + c).$$仿照神经网络激活函数构造,sigmoid 核有一个致命缺陷:它不总是正定的。 只有在 $\gamma$ 和 $c$ 的某些区间里 Gram 矩阵才保持 PSD;区间外,SVM 求解器会失败、kernel PCA 返回负特征值、GP 回归会悄悄出错。
用代码验证的反例。 生成 50 个随机 5D 点,在几组不同的 $(\gamma, c)$ 下计算 Gram 矩阵:
| |
只有第一组安全地 PSD。其它的负特征值大到足以让 libsvm 的 QP 求解器崩,而你不会得到一条清楚的报错,你会得到一个"训练完"但预测全是垃圾的模型。理论上的 PSD 区域(Lin & Lin 2003)大致是 $\gamma > 0$ 加 $c \le 0,$ 但即使那里也是有条件的、不是无条件的。
如果你在 2002 年的论文里看到 sigmoid 核,好的,深度学习之前它确实作为"神经网络核"流行过一阵。在 2026 年,你想要神经网络风格的非线性,就训一个神经网络。这里列出 sigmoid 核主要是为了你在遗留代码里能认出它,并知道要警惕。
核组合:用加法和乘法搭积木#
关于核真正神奇的事实是,PSD 性质对几种自然运算是封闭的:
- 求和。 $K_1 + K_2$ 是 PSD。把数据建模为有两个独立的结构来源。两个核各自的决策边界相加。
- 乘积。 $K_1 \cdot K_2$ 是 PSD。建模两个结构来源之间的交互。两个核都得高,乘积才高。
- 缩放。 $c \cdot K$ ($c > 0$ )是 PSD。只是改变方差。
- 复合。 对任意 $\phi,$ $K(\phi(x), \phi(y))$ 是 PSD。
这意味着你可以像搭乐高一样搭核,匹配你对数据结构的先验知识。

经典例子重访:Mauna Loa CO2。 上面已经写过那个四核 CO2 求和。这里再把语法应用到一个新例子,把模式钉牢。设想要做门店日销量预测。你的数据有:
- 长期上升趋势(连锁在扩张),
- 周内循环(周末高峰),
- 年内循环(圣诞高峰),
- 短期促销爆发,
- 噪声。
核自动写得出来:
| |
这种组合式视角,是 GP 比神经网络可解释得多的原因,你的核结构直接告诉你模型被允许拟合什么样的结构。
| 操作 | 核形式 | 含义 | 例子 |
|---|---|---|---|
| 求和 | $K_1 + K_2$ | 独立可加成分 | 趋势 + 季节 |
| 乘积 | $K_1 \cdot K_2$ | 交互,两核都得高 | 随时间衰减的季节 |
| 缩放 | $c \cdot K$ | 改输出方差 | 信噪权衡 |
| 输入扭曲 | $K(\phi(x), \phi(y))$ | 新特征表示 | 在 log-价格上的 RBF |
常见组合坑。 即便懂了语法,三件事还是会出问题。第一,参数爆炸:四核之和、每核两个超参,要联合优化八个参数,n_restarts_optimizer=2 经常不够,加到 5 或 10,接受墙钟代价。第二,不可识别:两个长度尺度差异巨大的 RBF 之间可以以优化器分辨不出的方式互相交换能量,尤其当一个长度尺度远超数据范围时;用手挑的值把长程那个冻起来。第三,缺边界:sklearn 默认在 $[10^{-5}, 10^5]$
上搜 length_scale,对标准化数据是 OK 的,但你的原始输入跨秒到年时就荒唐了;数据尺度异常时一定要显式设 length_scale_bounds。
核选择决策树#
最常被问的问题是"第一个应该试哪个核?“下面这棵决策树覆盖了 90% 的实践。

第 0 步:始终先跑一个线性基线。 如果线性已经够用,事就成了。
第 1 步:判断你的数据形态。
- 空间型 / 光滑且稠密。 坐标、传感器读数、图像特征。→ RBF 或 Matern-$5/2.$
- 带季节性的时序。 时间序列、音频、天气。→ RBF(趋势)+ 周期(循环)+ 白噪声的和。
- 高维稀疏。 文本、one-hot、基因表达。→ 线性。
- 已知交互。 NLP n-gram、GWAS epistasis。→ 多项式 2 或 3 阶。
- 类别 / 结构化。 字符串、树、图。→ 专用核(字符串核、图核、树核),它们各自是一个独立话题。
- 混合。 部分列空间型,部分类别型。→ 搭一个按列求和的核。
第 2 步:用对数网格交叉验证选超参。 中位数启发当 $\gamma_0;$ SVM 的 $C \in \{0.1, 1, 10, 100\};$ GP 回归优化边际似然。
第 3 步:出问题了,去读 Gram 矩阵。 像单位阵,说明 $\gamma$ 太大;一片亮,说明 $\gamma$ 太小。矩阵比模型早一步告诉你哪里错了。
七个具体场景。 让决策树用得起来,下面是七个日常任务里我会优先伸手的那个核:
| 场景 | 首选核 | 次选 | 原因 |
|---|---|---|---|
| 分类两月牙 / 玩具 2D | RBF + 中位数 $\gamma$ | Matern-$5/2$ | 光滑、稠密、无先验 |
| 分类 20-newsgroups | TF-IDF 上的线性 SVM | RBF(很少赢) | 稀疏、高维 |
| 表格数据回归房价 | 线性岭 → poly-2 | RBF(小心用) | 混合数值、$n$ 中等 |
| 预测每小时用电 | 求和:RBF + 周期-24h + 周期-168h + 白噪声 | 谱混合 | 已知多尺度周期 |
| 贝叶斯优化 | Matern-$5/2$ | RBF | 粗糙、优化器需要不确定性 |
| 空间地统计 | Matern-$3/2$ | 指数核 | 连续但不无限光滑 |
| 分类蛋白质序列 | 字符串核 | 谱核 | 离散、结构化 |
决策树的目的不是每次都选到最优核,没有任何决策树能做到。目的是别让你在 RBF + grid search 上耗几周,而数据形态从第一天起就在喊"用线性"或"用核之和”。
接下来#
Part 5 把这份核函数菜单变成真正的算法:核 SVM、核 PCA、核岭回归。我们会看到为什么本篇里每个核算法都共享同一副骨架(Part 3 的 representer 定理再次发威),$O(n^3)$ 这个把经典核方法困在 ~10k 样本规模的实际代价,以及标准的几种突围打法,Nystrom 近似、随机傅里叶特征、inducing points。Part 4 和 Part 5 合起来,你就有了"拟合什么"和"怎么拟合"的完整图景。
本文是 核方法 系列的第 4 篇,共 8 篇。 上一篇: 第 3 篇 — RKHS 理论 · 下一篇: 第 5 篇 — 核 SVM / 核 PCA / 核岭回归


