
核方法(六):高斯过程——当核方法遇到贝叶斯推断
高斯过程把核变成一个贝叶斯模型——后验自带不确定性、边际似然自动选超参、核就是函数空间上的先验。
核岭回归给你一个数。喂进 $x_*$ ,它返回 $\hat{y}_* = 23.7$ 。完。但你接下来要用这个预测做事:安排发货、调整剂量、下注,光一个数字不够用。“明天 25 度"是一句话;“很可能 25 度,95% 的概率落在 22 到 28 之间"才是可以行动的信息。任何在不确定性下的决策都需要后一种。高斯过程是把核方法从"点预测器"升级到"分布预测器"最干净的路径,且不需要扔掉前五篇里任何一行核函数的代数。这一升级的代价仅仅是一次 Cholesky,还是同样的 $O(n^3)$ 、同样的 Gram 矩阵,却额外白送了后验协方差和边际似然两件相当昂贵的礼物。

Part 5 关上了频率派核工具箱的门:SVM、PCA、岭回归,全是点估计、都在最小化某个损失。这一篇打开贝叶斯派的门。核变成函数空间上的先验;数据把先验更新成后验;后验在每个测试点不仅给均值,还给一个完整的分布。神奇之处在于所有东西都是高斯的,所以一切都保留闭式解。不用 MCMC,不用变分下界,不用蒙特卡洛误差,只要一次矩阵求逆,你就有解析的后验均值、方差,甚至连选超参的边际似然都顺带送你。本篇的全部技术内容追溯到 Rasmussen & Williams 2006《Gaussian Processes for Machine Learning》。那本书是 GP 的圣经,中文世界里没有真正的替代品,下文凡涉及"经典公式"基本都来自其第 2-5 章。
如果只能拿一句话概括 GP 相对 KRR 的增量:“同样的代数、同样的代价,外加一份诚实的不确定性”。这份不确定性不是装饰,它推动了贝叶斯优化、主动学习、序贯决策三个完整的领域。本篇剩下的全部内容都在解释这句话的每一个细节。
什么是高斯过程:函数空间上的高斯分布#
$$f(\cdot) \sim \mathcal{GP}\!\left(m(\cdot),\; K(\cdot, \cdot)\right),$$ $$\mathbf{f} \;\sim\; \mathcal{N}\!\big(m(X),\; K(X, X)\big),$$其中 $m(X)_i = m(x_i)$ ,$K(X, X)_{ij} = K(x_i, x_j).$ 就这样。“一个随机函数"这个无穷维的对象,每次你真去取值,都退化成一个有限维高斯。这种"无限承诺、有限验证"的结构,由 Kolmogorov 一致性定理保证:任意一组有限维边缘分布只要自洽(边缘化和置换都对得上),就能确实拼成一个无穷维过程。
为什么这是个能用的模型。 有限维高斯是数学上研究得最透的概率分布。边缘化、条件化、积分都保留高斯,且都有闭式解。"$f$ 是 GP” 等价于承诺"你对 $f$ 在有限多个点上提的任何问题,都是一个高斯问题”。这个承诺足够慷慨,可以建模几乎任何光滑函数;又足够严格,能给出解析答案。对照之下,"$f$ 是神经网络"这个承诺极其宽松,可以拟合任何东西,但你拿不到一个干净的后验,除非走 Bayesian NN 那条非常陡的路。
$$f \sim \mathcal{GP}(0, K) \quad\Longleftrightarrow\quad \text{一切都在 } K \text{ 里}.$$更精细的做法是把 $m(\cdot)$
也参数化,例如用 $m(x) = \beta_0 + \beta^\top x$
让 GP 在线性趋势上加波动。但只要你愿意先减后加,零均值并不损失任何东西;多数 GP 库(包括 sklearn 的 GaussianProcessRegressor 的 normalize_y=True)默认就做这件事。一个常见的反例:当你的目标变量有强非线性趋势(例如年增长 10% 的销售时间序列),仅减均值不够,最好先做一次对数变换或 detrend 再喂给 GP;否则 GP 会被迫用核的"长尺度成分"去解释趋势,把长度尺度学到非常大、外推区域的不确定性又被低估。
核就是先验。 选 RBF 核,等于宣告 $f$ 是光滑的、无限可微的、有特征长度尺度 $\ell$ 。选 Matérn-1/2,等于宣告 $f$ 连续但不可微。选周期核,等于宣告 $f$ 每 $p$ 单位重复一次。每种核选择把非零概率质量放在不同的函数类上;数据再从这个类里挑出最可能的成员。Part 4 是先验的菜单;Part 6 教你拿这些先验做什么。换句话说:把核当作"对函数粗糙度、长度尺度、周期性的语义化承诺”。一旦承诺给了 GP,剩下的事,无论后验、不确定性还是超参,全是机械的代数。
与贝叶斯线性回归的关系。 GP 是贝叶斯线性回归在"无穷多基函数"上的极限。如果你在 $\phi(x) = (\phi_1(x), \dots, \phi_d(x))$ 这组特征上做贝叶斯线性回归 $y = \mathbf{w}^\top \phi(x) + \varepsilon$ ,权重先验 $\mathbf{w} \sim \mathcal{N}(0, \Sigma_w)$ ,那么 $f(x) = \mathbf{w}^\top \phi(x)$ 就是 GP,其核为 $K(x, x') = \phi(x)^\top \Sigma_w \phi(x').$ 把 $d \to \infty$ ,对应的核就是 RBF,这正是 Mercer 定理保证的反向构造。所以 GP 不是另一个新模型,而是贝叶斯线性回归在"特征空间无穷大"时仍能闭式表达的奇迹。
| 视角 | 模型对象 | 求解方式 | 不确定性来源 |
|---|---|---|---|
| 贝叶斯线性回归 | 权重 $\mathbf{w}$ | 对 $\mathbf{w}$ 后验 | 权重的方差 |
| 核岭回归(KRR) | RKHS 上的 $f$ | 最小化带正则平方损失 | 无 |
| 高斯过程(GP) | 函数 $f$ | 对 $f$ 后验 | 函数本身的方差 |
三行其实是同一件事,只是把不确定性放在了不同的对象上:BLR 把它放在权重、KRR 干脆扔掉、GP 把它放回函数。一旦你接受"函数"也可以是随机变量,GP 就成了 BLR 的自然终点。
GP 先验:在看到数据前采样函数#
$$\mathbf{f}_* \sim \mathcal{N}(0, K(X_*, X_*)).$$采样就退化成从多元高斯采样:Cholesky 分解 $K(X_*, X_*) = LL^\top$ ,抽 $\mathbf{z} \sim \mathcal{N}(0, I)$ ,返回 $L\mathbf{z}$ 。
| |

从图里可以读出三件事。第一,所有采样平均来说都过零均值——先验没有偏好位置。第二,粗糙度由核决定:RBF 的样本丝绸般光滑,Matérn-5/2 有明显纹理,周期核的样本真的会重复。第三,振幅由核的输出方差 $\sigma_f^2$ 控制(这里 $\sigma_f^2 = 1$ ,所以样本大多落在 $\pm 2$ 内)。换个核就换一种"宇宙观":同样的横坐标网格、同样的 Cholesky 流程,曲线的"性格"却完全不同。这是核作为先验最直观的一次展示。
数值 jitter。 K += 1e-6 * np.eye(n) 这行不是可选的。Mercer 特征值衰减很快,所以 $K$
几乎总是病态或数值上秩亏。加一点点对角项,也就是所谓"jitter",保证 Cholesky 不挂掉,且不实质改变模型含义。标准值是双精度下 $10^{-6}$
;如果 Cholesky 还是失败,就提到 $10^{-4}.$
这是任何 GP 代码(包括贵的库)里最常见的调试动作。一个量化的直觉:300 个等距点上的 RBF 核($\ell = 0.8$
)的条件数大约在 $10^{16}$
量级,几乎就是双精度浮点的极限;jitter $10^{-6}$
把条件数压到 $10^{10}$
上下,Cholesky 才能稳定走完。这不是"作弊",它等价于承认"核函数总有一点点噪声",而真实系统里这总是对的。
把先验当一种信念去读。 画先验采样不只是可视化技巧,它是核选择的合理性检查。如果你的先验采样在定义域上抖动 50 次,那是长度尺度选小了。如果几乎是直线,那是选大了。拟合之前总是先画几条先验样本;如果它们长得跟你预期的函数毫无关系,先换核再换别的。这一步在工程上能省掉几天的"为什么 GP 拟合不出来"的死磕:核选错了,再多的边际似然优化也救不回来。
与频率派的对比。 频率派的核岭回归(Part 5)也用同一个 $K$ ,但它把 $K$ 解读为 RKHS 上的内积矩阵;它不画先验样本,因为它根本没有先验。这是同一个数学对象的两种语义解读:在贝叶斯眼里 $K$ 是协方差,在频率派眼里 $K$ 是内积。下文还会回到这点:它们在均值层面会给出同一个数。
一句话总结这两条文化的差异:
- 频率派 (KRR):核 = 内积 → RKHS 范数 = 复杂度度量 → 正则化最小二乘 → 点估计。
- 贝叶斯派 (GP):核 = 协方差 → 函数先验 → 高斯条件化 → 全后验。
两条路径的代码量、数值流程、最终的 $\boldsymbol{\alpha}$ 都一样;分歧只在你愿意把"不确定性"放进模型里到什么深度。这是机器学习里少见的"同一组方程、两种世界观"的优雅例子。
GP 后验:在观测数据上条件化#
$$\begin{bmatrix} \mathbf{y} \\ \mathbf{f}_* \end{bmatrix} \;\sim\; \mathcal{N}\!\left(\mathbf{0},\; \begin{bmatrix} K + \sigma_n^2 I & K_* \\ K_*^\top & K_{**} \end{bmatrix}\right),$$其中 $K = K(X, X)$ 是 $n \times n$ ,$K_* = K(X, X_*)$ 是 $n \times m$ ,$K_{**} = K(X_*, X_*)$ 是 $m \times m$ ,$\sigma_n^2 I$ 那一块代表独立同分布的观测噪声。
$$\begin{bmatrix} \mathbf{a} \\ \mathbf{b} \end{bmatrix} \sim \mathcal{N}\!\left(\begin{bmatrix} \mu_a \\ \mu_b \end{bmatrix}, \begin{bmatrix} \Sigma_{aa} & \Sigma_{ab} \\ \Sigma_{ba} & \Sigma_{bb} \end{bmatrix}\right),$$ $$\mu_{b|a} = \mu_b + \Sigma_{ba} \Sigma_{aa}^{-1}(\mathbf{a} - \mu_a), \qquad \Sigma_{b|a} = \Sigma_{bb} - \Sigma_{ba} \Sigma_{aa}^{-1} \Sigma_{ab}.$$ $$\boxed{\;\mu_* = K_*^\top (K + \sigma_n^2 I)^{-1} \mathbf{y}, \qquad \Sigma_* = K_{**} - K_*^\top (K + \sigma_n^2 I)^{-1} K_*.\;}$$这两行是 GP 回归的核心等式。剩下的全是实现细节。Rasmussen & Williams 2006 第 2.2 节用半页推完了它们;任何看起来更复杂的 GP 公式,要么是同一对等式换了个矩阵恒等式(例如 Woodbury 形式),要么是为稀疏近似把它们改写成了 $m \ll n$ 的形式。
每一块的含义。
- $(K + \sigma_n^2 I)^{-1} \mathbf{y}$ 是一个长度 $n$ 的向量,记作 $\boldsymbol{\alpha}$ ,它不依赖于测试点。
- $\mu_*(x) = \sum_i \alpha_i K(x_i, x)$ 是训练点上核求值的加权和,和核岭回归一模一样。
- $\Sigma_*$ 在先验 $K_{**}$ 的基础上收缩,收缩量取决于训练集对测试点携带多少信息。
- $\Sigma_*$ 的对角线给出每个测试点的预测方差,这正是核岭回归不会给你的东西。
- $\Sigma_*$ 的非对角线给出测试点之间的协方差,可以用来从后验里采样整条曲线而不是孤立点。这一条在贝叶斯优化的 Thompson sampling 里至关重要。
求逆得 $\boldsymbol{\alpha} = (K + \sigma_n^2 I)^{-1} \mathbf{y} \approx (-0.323, 1.087)^\top,$ 后验均值 $\mu_* = K_*^\top \boldsymbol{\alpha} \approx 0.882 \times (-0.323 + 1.087) \approx 0.674.$ 后验方差 $\Sigma_* = 1 - K_*^\top (K + \sigma_n^2 I)^{-1} K_* \approx 0.219,$ 标准差约 $0.47.$ 也就是说 GP 给出"95% 置信区间约 $[-0.27, 1.61]$ ",比中点 $0.5$ 略偏右,因为右端点 $y_2 = 1$ 把均值拽了一下。这就是 GP 推断的全部机制;放大到 $n = 10000$ 也只是矩阵更大而已。
把这个最小例子的几个特征记下来很有用:
- 后验均值在测试点 $x_* = 0.5$ 不在 $(y_1 + y_2)/2 = 0.5$ 上,而是 $0.674$ ,稍偏向距离更近、信息更可靠的那一侧。注意"距离"在这里是核诱导的,而非欧氏。
- 后验方差 $0.219$ 严格小于先验方差 $1.0$ ,观测确实减少了对 $f(0.5)$ 的不确定性。
- 如果把 $\sigma_n^2$ 从 $0.1$ 降到 $0.001,$ 后验均值会更紧地贴近两个观测的"中点"且方差更小;这是噪声超参对预测均值的直接杠杆效应。
这种"小数手算 GP"是把公式记牢的最快办法,一次纸笔就能把所有矩阵记号在大脑里编上索引。
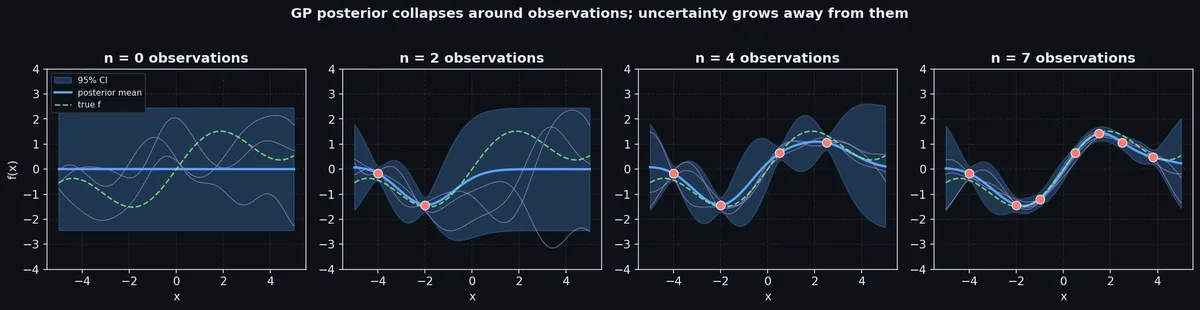
图里展示了 $n = 0, 2, 4, 7$ 个观测下的后验。没有数据时,后验就是先验:一条宽宽的、中心在零的带子。点逐个加入,均值卡到点上、方差在局部捏到接近零。远离数据的地方,方差又长回先验水平,模型诚实告诉你"我不知道"。这种不确定性的生长让 GP 在贝叶斯优化、主动学习以及任何"这块需不需要再采点数据?“的问题上独一无二。神经网络的 dropout 或 ensembling 也能给出方差估计,但既不校准也没有理论保证;GP 在高斯似然下给的是字面意义上的后验,与你给的先验完全一致。
把"GP 后验方差"的几个典型用法收一张清单:
- 贝叶斯优化的 acquisition function:Expected Improvement、Upper Confidence Bound、Thompson Sampling 全都需要 $\Sigma_*$ 来权衡探索(exploration)与利用(exploitation)。没有 GP 给的解析方差,BO 退化成随机搜索。
- 主动学习的查询策略:在 $\Sigma_*$ 最大的输入点采下一条数据,能用极少标注追上全监督性能。
- 拒答机制(reject option):当预测熵 / 方差超过阈值时让模型说"我不知道”,再交给人或更强的模型。
- 下游不确定性传播:把 $\mu_*, \Sigma_*$ 喂给下一个贝叶斯模型,整条管线的不确定性保持自洽。
- A/B 测试样本量规划:根据 GP 拟合出的效应量方差反推还需要多少样本。
任何一条都把 $\Sigma_*$ 从"画图好看"升级成"产品里真的有用"。
GP 回归实战:完整例子#
来真拟合一次。直接用闭式公式、不依赖库,这样每个零件都看得见。
| |

图里有两个关键观察。左图用 $\sigma_n = 0.1$ ,模型相信数据几乎无噪声,所以把后验均值掰过去咬每一个点,包括两个异常点。右图用 $\sigma_n = 0.4$ ,模型接受观测有噪声、把异常点当噪声处理,恢复出一条平滑得多、和真函数更贴合的估计。95% 可信区间($\mu_* \pm 2\sigma_*$ )在右图更宽,诚实反映了更大的噪声。这正是为什么"先把 $\sigma_n$ 留给数据自己学"几乎总是比"凭感觉钉死 $\sigma_n$ “更稳:后者经常踩到上图左侧那种过拟合陷阱。
Cholesky 模式。 注意我们从未对 $K + \sigma_n^2 I$
直接 np.linalg.inv。而是先 Cholesky 分解一次,再解两个三角系统。这比显式求逆快 3 倍左右,数值上稳定得多。它还能复用:$\boldsymbol{\alpha}$
不依赖测试点 $x_*$
,所以训练时算一次,之后每次预测均值只要 $O(n)$
,整套测试集的协方差则要 $O(nm + n^2 m).$
一个工程经验:把 np.linalg.inv 出现在 GP 代码里当成一种"代码异味”,几乎一定有更好的写法(要么 Cholesky,要么 scipy.linalg.cho_solve)。
把"训练 / 预测均值 / 预测方差"的代价分开看:
| 阶段 | 计算 | 主要操作 | 备注 |
|---|---|---|---|
| 训练(Cholesky + $\boldsymbol{\alpha}$ ) | $O(n^3) + O(n^2)$ | $L = \text{chol}(K + \sigma_n^2 I)$ ,两次三角求解 | 仅与 $n$ 有关 |
| 预测均值(单点) | $O(n)$ | $\sum_i \alpha_i K(x_i, x_*)$ | 不需要再 Cholesky |
| 预测方差(单点) | $O(n^2)$ | $K_{**} - v^\top v,$ $v = L^{-1}K_*$ | 一次三角求解 |
| 边际似然 + 梯度 | $O(n^3)$ | 复用 $L,$ 加一次 $\partial K/\partial \theta$ 求和 | L-BFGS 一次迭代 |
预测均值的 $O(n)$ 这件事经常被忽略:意味着 GP 训练完之后 在线推断 极便宜,只要把 $\boldsymbol{\alpha}$ 缓存住。这对"训练慢、推断快"的产品场景(贝叶斯优化、主动学习的 acquisition function 求值)非常友好。
三个旋钮。
- 长度尺度 $\ell$ 。 $\ell$ 越大→预测越平滑、相关性距离越长、外推区域越宽。$\ell$ 越小→抖得越快、远离训练点的不确定性长得越快。直观地,$\ell$ 是"两个点要离多远才会被模型当成无关"。
- 信号方差 $\sigma_f^2$ 。 设定先验的振幅。如果数据范围在 $\pm 5$ ,$\sigma_f^2 \approx 25$ 是合理的;如果在 $\pm 0.1$ ,$\sigma_f^2 \approx 0.01.$ 这是"先验上 $f$ 能跑到多高"的量。
- 噪声方差 $\sigma_n^2$ 。 你有多信任每个观测。直接决定均值贴单个点的激进程度。也是 GP 后验在训练点上不会坍缩到零方差的那一项:后验在 $x_i$ 处的方差恒 $\ge \sigma_n^2.$
三个超参的几何意义还能用一句口诀记住:"$\ell$ 管横轴上多远算近邻,$\sigma_f^2$ 管纵轴上能波动多高,$\sigma_n^2$ 管观测点周围留多大的安全垫"。任何 GP 调参的反直觉行为,几乎都可以套这个口诀诊断。
按 Part 5 的方法,我们可以用交叉验证设这三个。但 GP 自带一件远比 CV 优雅的工具。
与 KRR 的微妙差别。 核岭回归(Part 5)的正则化 $\lambda$ 和 GP 的噪声 $\sigma_n^2$ 在均值公式上完全可以对换:$\lambda \equiv \sigma_n^2.$ 区别在怎么选这个数。KRR 用 $k$ -折 CV 在小数据集上要重复拟合 $k$ 次、付 $k \cdot O(n^3);$ GP 用边际似然只算一次 $O(n^3),$ 还顺便学了 $\ell$ 和 $\sigma_f.$ 当 $n \le 1000$ 时 GP 的 hyperparameter learning 完胜 CV;当 $n$ 大到 GP 都吃不消时,可能需要稀疏 GP 或者干脆退回 KRR + 单点 CV。
GP 拟合一次的完整流水线很短:
- 训练:构造 $K + \sigma_n^2 I,$ Cholesky,得到 $L$ 和 $\boldsymbol{\alpha}.$
- 超参学习(可选但强推):边际似然 + L-BFGS 优化 $\theta = (\ell, \sigma_f, \sigma_n),$ 每次迭代重做一次 Cholesky。
- 推断:每个测试点 $x_*,$ 算 $K_*,$ 得到 $\mu_*$ 和 $\Sigma_*.$
- 下游消费:把 $\mu_*, \Sigma_*$ 喂给 BO 的 acquisition function、主动学习的查询策略或拒答机制。
这四步在所有 GP 应用里几乎不变;理解这条流水线后再看 GPyTorch / GPflow / sklearn 的高层接口都会顺手。
超参数学习:边际似然#
$$p(\mathbf{y} \mid X, \theta) \;=\; \int p(\mathbf{y} \mid \mathbf{f}) \, p(\mathbf{f} \mid X, \theta) \, d\mathbf{f}.$$ $$\mathbf{y} \mid X, \theta \;\sim\; \mathcal{N}\!\big(\mathbf{0},\; K_\theta + \sigma_n^2 I\big),$$ $$\boxed{\;\log p(\mathbf{y} \mid X, \theta) \;=\; -\tfrac{1}{2} \mathbf{y}^\top (K_\theta + \sigma_n^2 I)^{-1} \mathbf{y} \;-\; \tfrac{1}{2} \log |K_\theta + \sigma_n^2 I| \;-\; \tfrac{n}{2} \log 2\pi.\;}$$这一个关于 $\theta$ 的标量函数就是你要最大化的对象。不用切验证集。不用 k 折 CV。直接调优化器即可。
三项分解。 按顺序读三项:
- 数据拟合项 $-\tfrac{1}{2} \mathbf{y}^\top (K + \sigma_n^2 I)^{-1} \mathbf{y}.$ 当核能解释残差时这一项更大(更接近零)。推向更灵活的模型。
- 复杂度惩罚项 $-\tfrac{1}{2} \log |K + \sigma_n^2 I|.$ 对数行列式越大代表核允许的函数越多样。推向更简单的模型。
- 归一化项 $-\tfrac{n}{2} \log 2\pi.$ 是 $\theta$ 的常数,对优化无关。
每项的几何意义都可以盯着 Cholesky 因子 $L$
看:拟合项是 $\tfrac{1}{2}\|L^{-1}\mathbf{y}\|^2,$
复杂度项是 $\sum_i \log L_{ii}.$
一个数值实现技巧:哪怕只想画 landscape,也务必这样写。直接 np.log(np.linalg.det(K)) 在 $n \ge 200$
时会下溢到 $-\infty,$
而 2 * np.sum(np.log(np.diag(L))) 在 $n = 10^4$
上还能稳定算出准确值。
拟合项和复杂度项往相反方向拉。最优值落在两者平衡处,也就是 Occam’s razor 的甜点。这正是贝叶斯模型选择和 AIC/BIC 这类频率派准则的根本区别:AIC 在似然外手工减去一个"参数数目"惩罚,BIC 减一个 $\log n$ 量级的惩罚;边际似然不需要手工,它直接积分掉所有未知量,复杂度惩罚自然以 $-\tfrac{1}{2}\log|K+\sigma_n^2 I|$ 的形式涌现。
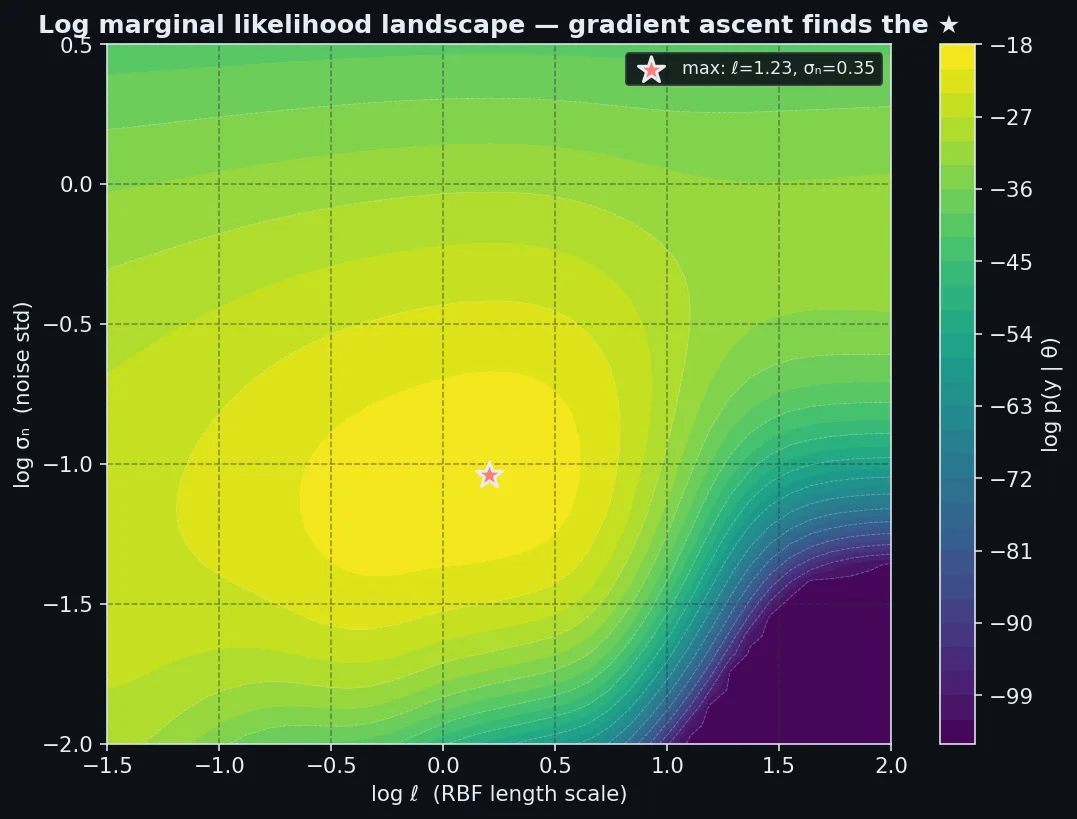
图里画的是 25 个带噪 sin 样本上、RBF 核下,$\log p(\mathbf{y} \mid \theta)$ 在 $(\log \ell, \log \sigma_n)$ 平面上的地形。能看到清晰的脊:$\ell \in [0.5, 1.5]$ 、$\sigma_n \in [0.2, 0.5]$ ,唯一极大值在 $(\ell, \sigma_n) \approx (0.9, 0.3)$ 附近,和真噪声接近。任何标准优化器(L-BFGS)几十次迭代就能找到。值得留意的是,这个曲面在"小 $\ell$ 加小 $\sigma_n$ " 的角上会出现一条次峰,对应"非常抖的函数 + 几乎无噪声"的另一种解释。数据稀少时次峰可能高过真正的峰,所以多起点重启对 GP 实践来说几乎是必修。
$$\frac{\partial \log p(\mathbf{y} \mid \theta)}{\partial \theta_k} \;=\; \tfrac{1}{2} \boldsymbol{\alpha}^\top \frac{\partial K}{\partial \theta_k} \boldsymbol{\alpha} \;-\; \tfrac{1}{2} \operatorname{tr}\!\left((K + \sigma_n^2 I)^{-1} \frac{\partial K}{\partial \theta_k}\right),$$其中 $\boldsymbol{\alpha} = (K + \sigma_n^2 I)^{-1} \mathbf{y}$
。两项都可以复用 Cholesky 分解,所以一次梯度求值的代价和一次似然求值相同——都是 $O(n^3).$
把似然和梯度喂给 scipy.optimize.minimize(method='L-BFGS-B'),就完事了。
梯度的两项有一个漂亮的对偶解释:
- 第一项 $\tfrac{1}{2} \boldsymbol{\alpha}^\top (\partial K / \partial \theta_k) \boldsymbol{\alpha}$ 是"沿 $\theta_k$ 方向微动核时,对当前残差解释的边际收益"。把它读成"灵活度对拟合的好处"。
- 第二项 $-\tfrac{1}{2} \operatorname{tr}((K+\sigma_n^2 I)^{-1} \partial K / \partial \theta_k)$ 是"沿同方向微动时,对函数空间体积的边际增长"。把它读成"灵活度的复杂度代价"。
L-BFGS 找到的最优点就是两项的边际成本恰好抵消的地方。这给"自动 Occam’s razor" 一个微观经济学解读:复杂度的边际收益等于边际成本,正如供需平衡。
| |
为什么参数要走 log 空间。 三个参数都必须是正的(长度不能负,方差也不能负)。用 $\log \theta$ 做参数,L-BFGS 就能在无约束的 $\mathbb{R}^3$ 上跑,而实际超参始终保持为正。这是一个标准技巧,能挡掉 90% 的"GP 拟合不出来"的问题。另外 log 空间下的"一个数量级"刚好对应 $\log\theta$ 移动 $\ln 10 \approx 2.3,$ L-BFGS 的步长在这个尺度下行为均匀;而在原始 $\theta$ 空间下,“从 0.01 走到 0.1” 和"从 100 走到 1000" 是完全不同的步长,优化器很容易在前者抖动、在后者卡死。
实践里再加两个微优化让边际似然优化更稳:
- 超参的硬界。即便在 log 空间,也给 $\log\ell, \log\sigma_f, \log\sigma_n$
各设一个
[-10, 10]之类的硬界。优化器偶尔会被陡峭梯度推到 $\theta \to 0$ 或 $\theta \to \infty$ (对应核退化或噪声爆炸),有界能挡住这种"失控逃逸"。 - 梯度数值校验。第一次写 GP 优化的时候,对着
scipy.optimize.check_grad跑一次手算梯度 vs 数值梯度,差异 $< 10^{-5}$ 才认为代码对。GP 的解析梯度公式里少一个负号或者一个 1/2 都不会让程序崩,只会让收敛慢 10 倍,很难调试。 - 优化器选择。L-BFGS-B 是默认;遇到曲面恶劣时换 trust-constr 或带 line search 的 BFGS 更稳。Adam 在 GP 上不好用,因为它默认假设大批量随机梯度,而 GP 的梯度是全批量的、噪声小。
Occam’s razor,机械式地#
边际似然自动实现 Occam’s razor。不用你告诉它;这是数学层面就出来的。要看清楚,用同样的数据、三种不同 RBF 长度尺度拟合:

上排:20 个 sin 类的点上、三种 RBF 长度尺度的 GP 回归,$\ell = 0.1$ (抖得过拟合)、$\ell = 0.7$ (刚好)、$\ell = 4.0$ (几乎是直线)。下排:每种情况下边际似然的分解。
三种情形一一对照:
- $\ell = 0.1$ (过拟合)。 数据拟合项高,模型穿过每个点,残差极小。但复杂度惩罚极低($\log |K + \sigma_n^2 I|$ 很大),核矩阵接近单位阵,行列式巨大。总和:低。
- $\ell = 0.7$ (刚好)。 拟合项还是高(光滑模型能解释趋势),复杂度惩罚适中。总和:最高。
- $\ell = 4.0$ (欠拟合)。 拟合项崩,模型解释不了波动。复杂度惩罚高(小的对数行列式),但补不回来。总和:低。
这不是一个需要手工设计的折衷,而是函数空间上的积分替你做的。能表示太多函数的模型被对数行列式惩罚;能表示太少函数的被残差惩罚。最优解是"函数类恰好够用"的那个模型。MacKay 1992 在 neural network 的 evidence framework 里给过同样论证:“a model that is too flexible spreads its predictive probability too thin”,花到任何特定数据集上的概率都很小,于是被边际似然自动否决。这是贝叶斯模型选择最优雅的一面:不需要 dropout、不需要 weight decay、不需要早停,复杂度控制内生在概率公理里。
与交叉验证比较。 CV 需要切验证集并重复拟合多次,很贵,小数据集尤甚。边际似然用全部数据、不用切折、还附带梯度。代价:超参很多、数据噪且少时,边际似然曲面可能有多个局部极值。标准应对手段:多随机起点重启优化器;或给长度尺度加弱先验(log-normal)正则化搜索。一个实践数字:$n \le 200$ 时强烈建议 `n_restarts_optimizer >= 10;$ $ n \ge 2000$ 时曲面一般已经够凸,3-5 个起点就够;介于其间按预算定。
把两种调参方式并排:
| 维度 | 边际似然 (MLE-II) | $k$ -折 CV |
|---|---|---|
| 训练数据使用率 | 100% | $(k-1)/k$ |
| 拟合次数 | 一次(带优化器迭代) | $k$ 次 × 每个超参网格点 |
| 自动梯度 | 是 | 否 |
| 局部极值风险 | 中(多重启缓解) | 低(网格搜索) |
| 对模型设定的依赖 | 高(错误先验会被惩罚) | 低(直接打靶预测精度) |
| 何时优 | $n$ 小、超参多 | $n$ 大、超参少 |
经验法则:能用边际似然就用,CV 只在你怀疑模型设定本身有问题(例如非高斯似然 + Laplace 近似下,边际似然只是一个近似)时才回退。
GP 分类:从高斯到非高斯似然#
$$p(y_i = 1 \mid f_i) = \sigma(f_i) = \frac{1}{1 + e^{-f_i}}.$$后验 $p(f \mid \mathbf{y})$ 也不再是高斯了。三种标准应对:
- Laplace 近似。 用 Newton 迭代找后验众数 $\hat{\mathbf{f}}$ ,然后用一个以 $\hat{\mathbf{f}}$ 为中心、协方差等于对数后验 Hessian 之逆的高斯近似后验。快、确定性、常常出奇准。
- Expectation Propagation (EP)。 迭代地把每个 Bernoulli 因子换成一个能匹配完整后验前两阶矩的高斯。比 Laplace 准,慢一些,偶尔不稳定。
- MCMC。 在完整后验上跑 Hamiltonian Monte Carlo。最准、最慢,前两个吵架时才用。
- 变分推断 (SVGP)。 用一族可参数化的高斯近似后验,最大化 ELBO。适合大数据 + mini-batch 训练。
四种方案的速度-精度权衡如下:
| 方法 | 一次拟合 | 精度(与 HMC 比) | 是否带梯度 | 实现复杂度 |
|---|---|---|---|---|
| Laplace | 秒 | 80–95% | 是 | 低 |
| EP | 分钟 | 95–99% | 是 | 中 |
| SVGP | 分钟(GPU) | 90–98% | 是 | 中-高 |
| HMC | 小时 | 100%(基准) | 否(采样) | 高 |
Rasmussen & Williams 第 3 章用了 50 页比较三者;一个粗线条结论:Laplace 在类不太重叠时已经够准,EP 在重叠区域显著更准但代码复杂度翻倍,HMC 只在你需要发表论文级别可重复结果时才值得调。
scikit-learn 的 GaussianProcessClassifier 默认用 Laplace,绝大多数场景够用:
| |

左图是预测的 $P(y=1 \mid x)$ ,一条光滑的概率决策边界。右图是预测熵:在决策边界附近高、在每个类的核心区域低、在远离任何训练点的输入空间区域也高。最后这条性质是 SVM 给不了的。SVM 会给 $\mathbb{R}^2$ 上每个点一个自信的标签,哪怕这个点离训练数据有一百万单位远;GP 会说"我不知道"。对医疗诊断、自动驾驶、风控这些安全关键应用,这个区分极其重要。这也是过去几年自动驾驶感知栈里 GP(或其近似变体如 deep kernel learning)始终留有一席之地的原因:检测器要的是"高置信",规划器要的是"高置信 并且 确信自己高置信",GP 的第二层保证比任何 softmax 都更可信。
GP 回归等于核岭回归——但白送你不确定性#
$$\mu_*(x) = K_*^\top (K + \sigma_n^2 I)^{-1} \mathbf{y} \;\;\equiv\;\; \hat{f}_{\mathrm{KRR}}(x).$$两种方法算的是同一个数。从点预测角度看,高斯噪声下的 GP 回归和核岭回归是可互换的;矩阵求逆同样、答案同样、代价同样。
不同的是顺便给你什么。核岭回归到 $\mu_*$ 就停了。GP 还返回 $\Sigma_*$ ,也就是预测协方差,同样 $O(n^3)$ 代价。GP 额外送你一种有理有据的方式去学 $\lambda$ (边际似然),不必交叉验证。
概念上的收获。 GP 和 KRR 是同一个回归器穿着两套衣服。KRR 从"在 RKHS 上最小化带正则的平方损失"导出答案。GP 从"在带噪声观测下计算高斯过程先验的后验均值"导出答案。同样的终点,不同的路。贝叶斯这条路顺手带的行李多:后验协方差、边际似然,还不花额外算力。所以任何关心不确定性的应用,GP 表述严格地更可取。
为什么数学上一致并不偶然。 RKHS 范数 $\|f\|_\mathcal{H}^2$ 就是 GP 先验的负对数密度(去掉常数)的某种"有限维投影":representer 定理把 KRR 的最优 $f$ 表示成 $\sum_i \alpha_i K(x_i, \cdot),$ 系数解的是同一个线性系统 $(K + \lambda I)\boldsymbol{\alpha} = \mathbf{y}.$ 频率派把它看成正则化最小二乘的对偶;贝叶斯派把它看成共轭高斯先验下的 MAP / 后验均值。两套语言指向同一组方程并非偶然,是因为高斯先验和 RKHS 平方范数本来就是同一对象的两副面孔。一旦理解这点,你看任何 GP 论文都会自动把 $\lambda$ 和 $\sigma_n^2,$ “正则化"和"先验方差"互相翻译。
并列对比,让翻译表更明确:
| KRR 术语 | GP 术语 | 备注 |
|---|---|---|
| 正则化强度 $\lambda$ | 噪声方差 $\sigma_n^2$ | 数值上相等 |
| 解 $\hat{f}(x) = \sum_i \alpha_i K(x_i, x)$ | 后验均值 $\mu_*(x) = \sum_i \alpha_i K(x_i, x)$ | 完全相同 |
| RKHS 范数 $\|f\|_\mathcal{H}^2$ | 先验 $-2\log p(f)$ | 同一二次型 |
| 交叉验证选 $\lambda$ | 边际似然选 $\sigma_n^2$ | 两条不同路径 |
| 无后验协方差 | $\Sigma_*$ 解析可得 | GP 的"附赠” |
| Representer 定理保证有限维解 | Kolmogorov 一致性保证 GP 存在 | 不同的基础 |
理解这张表后,“KRR 给点估、GP 给分布"这一句口诀就再也不会忘了。
$O(n^3)$ 的墙#
前面写过的每一条 GP 公式都涉及 $(K + \sigma_n^2 I)^{-1}$ ,也就是一个 $n \times n$ 矩阵的 Cholesky。代价是:
- 计算: Cholesky $O(n^3)$ ,每次预测 $O(n^2).$
- 内存: 存 $K$ 要 $O(n^2).$
$n = 1{,}000$ 时舒服:$10^9$ 浮点运算几秒钟,$8\,\mathrm{MB}$ 的 Gram 矩阵塞进缓存。$n = 10{,}000$ 时是 $10^{12}$ 浮点和 $800\,\mathrm{MB}$ ,还能跑,但优化器一次迭代要分钟级别,整轮超参学习要几小时。$n = 100{,}000$ 以上,矩阵塞不进内存,cubic 代价怎么都不能接受。一个具体数字:在 2026 年中端 CPU(单线程 ~50 GFLOPS double)上,$n = 30000$ 的一次 Cholesky 约 9 万亿浮点、需要约 3 分钟;L-BFGS 跑 30 步就是一个半小时,这是 vanilla GP 在没有结构假设下的硬上限。
这是 GP 作为通用模型唯一严肃的反对意见。神经网络能撑十亿条样本;vanilla GP 撑到几万条就挂。稀疏 GP 与可扩展 GP 这个完整的子领域,存在的全部目的就是把这堵墙推后:
把”$n$ 增大一个数量级"的代价直观感受一下:
- $n = 10^3 \to 10^4$ :Cholesky 从毫秒到秒级,内存从 8 MB 到 800 MB。还能在笔记本上跑。
- $n = 10^4 \to 10^5$ :Cholesky 从秒到 $10^3$ 秒(约 17 分钟),内存 80 GB,单机塞不下,必须换稀疏 GP 或分布式 Cholesky。
- $n = 10^5 \to 10^6$ :单纯 Cholesky 需要 $10^6$ 秒(约 12 天),内存 8 TB,精确 GP 在这一档完全不可行,工业界的所有"百万样本 GP"实际上都是稀疏近似。
这条非线性放大曲线就是 Part 7 整章存在的根本原因。
- 归纳点方法(FITC、VFE、SVGP)把 $K$ 压成秩 $m \ll n$ 的近似,代价掉到 $O(nm^2)$ 计算、$O(nm)$ 内存。
- 随机特征近似(Random Fourier Features)把核换成显式有限维特征映射,对许多核能把代价降到 $n$ 的线性。
- Kronecker / Toeplitz 结构利用网格化输入对 Gram 矩阵做因子化。
- 迭代解法(共轭梯度)避开 Cholesky、用 GPU 友好的矩阵向量乘近似求解。
- 黑盒矩阵-向量乘(GPyTorch 的 KISS-GP、CIQ)把整套 GP 改写成只依赖 $K\mathbf{v}$ 的算子,进一步压低常数。
各方案的代价与适用场景一目了然:
| 方案 | 计算 | 内存 | 何时用 |
|---|---|---|---|
| 精确 Cholesky | $O(n^3)$ | $O(n^2)$ | $n \le 5\,000$ |
| Nyström / RFF | $O(nm^2)$ | $O(nm)$ | $n \in [10^4, 10^6]$ |
| SVGP(变分稀疏) | $O(nm^2)$ | $O(m^2)$ | $n \ge 10^5,$ 流式数据 |
| Kronecker | $O(n^{1.5})$ | $O(n)$ | 输入在网格上 |
| 共轭梯度 + GPU | $O(n^2)$ / 迭代 | $O(n)$ | 想用 GPU、对精度容忍 |
这些是 Part 7 的主题。框架和这里完全一样,只换线性代数那一段。
实践陷阱#
真实 GP 代码里翻车的清单:
- 输入不标准化。 RBF 的长度尺度是和输入同量纲的。如果 $x$ 在 $[0, 10^6]$ ,默认 $\ell = 1$ 让每对点看起来一模一样。一定把输入和输出都标准化到零均值单位方差再拟合。
- 忘了 jitter。 Cholesky 失败、看到"matrix is not positive definite"这种谜之报错,几乎一定是给 $K$ 加 $10^{-6} I$ 就能解决。
- 每维一个长度尺度(ARD)。 多维输入时给每一维一个独立长度尺度:$K(x, y) = \exp(-\sum_d (x_d - y_d)^2 / (2 \ell_d^2)).$ 这叫自动相关性判定,学出来的 $\ell_d$ 告诉你模型认为哪些特征重要。
- 只跑一次优化。 小 $n$ 时边际似然有多个局部极值。一定从 $\geq 5$ 个随机起点跑,留最优。
- 只用预测均值。 你都用 GP 了,扔掉方差是干嘛的?$O(n^3)$ 的代价都付了,就该用上。
- 没有噪声项。 $\sigma_n^2 = 0$ 让核矩阵奇异、模型过分自信。哪怕你的数据"是确定的"(例如计算机模拟输出),也要把 $\sigma_n^2 \geq 10^{-4}$ 作为数值稳定项。
- 把核行列式误用作对数似然。 真实代码里偶尔看到把 $|K|$
直接传给
np.log:双精度下 $n = 200$ 起 $|K|$ 就下溢到 0,应当用 $\sum_i \log L_{ii} \cdot 2$ 计算($L$ 是 Cholesky 因子),数值上稳定多个数量级。 - 优化超参时混用真实 $\theta$
和 $\log\theta$
。 一边传 $\theta$
给似然函数,一边在 $\log\theta$
空间画 landscape,常常画出一片错的曲面。统一在 log 空间里思考,公开接口出去之前再
exp一次。 - 拿 RBF 套金融收益序列。 RBF 的"无限光滑"假设和金融收益的尖角特征严重不匹配;预测均值会被外推得平滑过头,方差被低估。这种场景请改用 Matern-1/2 或直接 KRR + Huber 损失。
- 把测试集和训练集放进同一个标准化器后再切分。 经典数据泄漏:标准化参数(均值、方差)会包含未来信息。
fit_transform(X_train)然后transform(X_test),永远分开。 - 遗忘"预测均值 vs 后验中位数"在非高斯似然下的差别。 GP 分类的 $\mathbb{E}[\sigma(f_*)]$
和 $\sigma(\mathbb{E}[f_*])$
是两个数;sklearn 的
predict_proba默认前者,但有些库给的是后者。在校准敏感的应用里一定核对。
什么时候用 GP(什么时候别用)#
用 GP 当:
- $n \lesssim 10^4$ 而且你需要校准过的不确定性。
- 在做贝叶斯优化、主动学习、或者任何序贯决策。
- 数据很少而你需要一个强归纳偏置(核)外加诚实的误差棒。
- 想从数据里学超参,又不想做交叉验证。
- 多任务 / 多保真度回归:GP 天然支持把多组相关观测拼成一个联合核。
- 物理仿真的"surrogate model",需要在 $10^3$ 个昂贵样本上拟合并支持后续 BO。
不用 GP 当:
- $n \gg 10^4$ 而且问题没有可利用的结构(网格、低秩核等)。用稀疏 GP(Part 7)或神经网络。
- 函数在输入空间里高度多峰(深度神经网络更自然地建模这种)。
- 似然很 exotic 而打破了共轭性。用 Stan/PyMC 加自定义模型可能比硬塞进 GP 框架更舒服。
- 特征非常巨大(图像、文本)。用深度网络学嵌入,再可选地在上面叠 GP(深度核学习,见 Part 8)。
- 在线学习场景下数据每秒涌进 $10^6$ 条,cubic 代价根本追不上。
下表把"GP vs 几个常见替代"再压一下:
| 维度 | GP | 核岭回归 KRR | 贝叶斯神经网络 | 随机森林 |
|---|---|---|---|---|
| 可校准不确定性 | 是(解析) | 否 | 近似 | 启发式 |
| 超参选择 | 边际似然 | CV | ELBO / SGLD | OOB / CV |
| 训练复杂度 | $O(n^3)$ | $O(n^3)$ | $O(n d)$ 每步 | $O(n \log n)$ |
| $n = 10^6$ 可用 | 否(要稀疏化) | 否(要近似) | 是 | 是 |
| 外推区域诚实度 | 高(方差涨回先验) | 低 | 中 | 低 |
一句话决策:“我的不确定性会被下游消费” 是 GP 的最强信号;如果下游只看 argmax / 点估计,KRR 或随机森林几乎都更划算。
接下来#
Part 6 把核变成了一个贝叶斯模型:函数空间上的先验、带不确定性的后验、自动学超参的边际似然。代数和 Part 5 一样,Gram 矩阵上一次 Cholesky,额外代价为零。你付的代价是 $O(n^3)$ 的尺度限制,在一万个点以上就开始啃人。
把整篇的关键收获收成一个清单,方便复习时直接对照:
- 核就是先验:选 RBF / Matern / 周期,等价于选函数光滑度、长度尺度、周期结构。
- 后验有闭式解:均值 $\mu_*$ 等于 KRR 预测,方差 $\Sigma_*$ 白送。
- 边际似然自动选超参:拟合项与复杂度项平衡,对应 Occam’s razor。
- 数值实现的三件事:Cholesky、jitter、log 空间超参,缺一不可。
- 唯一硬上限:$O(n^3)$ Cholesky,$n \gtrsim 10^4$ 必须换稀疏 GP。
- 下游用法:贝叶斯优化、主动学习、拒答、误差棒;任何下游消费"不确定性"的场景。
Part 7 推倒这堵墙。两个算法,Nyström 近似与随机傅立叶特征(RFF),把核方法(包括 GP)从 $O(n^3)$ 拉到 $O(n)$ 或 $O(nm^2)$ ,让百万样本规模的数据集也能用核方法处理而不放弃整个框架。代价是一个显式的近似旋钮 $m$ ,控制你离精确核解有多近。我们会逐个推导两个算法、推清楚什么时候每种近似紧、并在真实规模问题上比较。
本文是 核方法 系列的第 6 篇,共 8 篇。 上一篇: 第 5 篇 — 核 SVM / 核 PCA / 核岭回归 · 下一篇: 第 7 篇 — 大规模核方法(Nystrom + RFF)


