
核方法(八):深度核学习 vs 深度学习——选择指南与故障排查
深度核学习把神经特征提取和核方法结合。何时选核而非深网、超参调优手册、常见故障模式,以及一张最终的 5 步核方法决策流程图。
2026 年了,为什么还要读核方法?Transformer 不是已经把整个 ML 栈吃掉了吗?是也不是。Transformer 吃掉了头条,核方法吃掉的是角落:只有 200 个样本的场景、必须给出校准误差棒的场景、物理学家需要知道是哪个基函数贡献了这次预测的场景。本系列的最终篇就是这份"角落工程师手册":核方法什么时候真的能赢、出了问题怎么诊断、怎么把核挂在神经网络头顶上拿到两边的好处,以及为什么 NTK(Jacot et al., 2018)告诉我们深网在某个极限下其实就是一种核方法。两派的边界到 2026 年比任何时候都更模糊。
更直白点说:如果你过去七篇是为了"开眼界"读的,这一篇是为了"开工"读的。每个工程师都会在某天接到一个"$n$ 太小不能上深网、产品要求误差棒、模型要解释、又得明天上线"的需求。本篇就是为那个明天写的。

前七篇爬了一座很陡的山:线性天花板(第 1 篇 )、正定核(第 2 篇 )、RKHS(第 3 篇 )、核函数家族(第 4 篇 )、核算法(第 5 篇 )、高斯过程世界观(第 6 篇 )、大规模救命稻草(第 7 篇 )。这一篇是下山。我们要走到工程师每天真正在做决定的泥地里,最后用一张 5 步流程图和一张概念地图把整个系列收口。如果说前七篇是"为什么"和"怎么算",第 8 篇就是"怎么选"。而"怎么选"恰恰是工业界把核方法用错最频繁的环节。
深度核学习(DKL)#
核派和深度学习派以前互相听不懂对方在说什么。核方法不能从原始像素里学表示;深网不能在不付出昂贵代价的前提下给出校准的不确定性。深度核学习由 Wilson、Hu、Salakhutdinov、Xing 在 2016 年的 AISTATS 论文 Deep Kernel Learning 提出,就是把这两派接上的桥:让神经网络负责"长出可学的特征空间"这件深网最擅长的事,让核负责"在这个特征空间上做贝叶斯推断"这件核最擅长的事。
DKL 的核就是一个函数复合:
$$k_{DKL}(x, x') = k_{base}\bigl(g_\theta(x),\, g_\theta(x')\bigr).$$这里 $g_\theta : \mathcal{X} \to \mathbb{R}^d$ 是任意带参的特征提取器,一般是小 CNN 或 MLP,而 $k_{base}$ 是你熟悉的 RBF 或 Matern(第 4 篇 菜单上的任何一族都行)。这个复合仍然是正定的,因为 PD 核在与任意特征映射复合下封闭(第 2 篇 定理 4)。换句话说,DKL 不是"把核改造成新东西",而是"把核搬到一个被学出来的空间里"。RKHS 还是 RKHS(第 3 篇 ),只是底层度量从手工设计变成了从数据里训出来的。

DKL 为什么存在。 在原始 224x224 像素上放一个 RBF 核是没意义的:像素空间里的欧氏距离主要被光照和平移主宰,两张内容完全不同的猫的照片可能距离很近,而同一只猫不同光照下的照片可能离得很远。预训练 ResNet 的特征聪明得多:特征空间里的距离反映语义内容。DKL 说:与其用固定的预训练特征,不如同时学特征提取器和核,让梯度从 GP 边际似然反传穿过整个网络。这样核的"距离观"和数据的"语义观"在训练里被强迫对齐,而不是等运气。
训练目标。 对带 GP 头的 DKL,你优化的是负对数边际似然
$$\mathcal{L}(\theta, \phi) = \tfrac{1}{2} y^\top \bigl(K_{\theta,\phi} + \sigma^2 I\bigr)^{-1} y + \tfrac{1}{2} \log\bigl|K_{\theta,\phi} + \sigma^2 I\bigr| + \tfrac{n}{2}\log 2\pi,$$对网络权重 $\theta$ 和基础核参数 $\phi$ (长度尺度、信号方差、噪声方差)同时求导。梯度穿过核的求值反传到网络里,就像一个普通 loss 穿过最后一层 dense 一样。聪明之处在于:你只需要 autodiff 加 Cholesky 求解器,现代框架(GPyTorch、GPflow)让这件事变成 20 行脚本。边际似然的两项有自然的"奥卡姆剃刀"解读:第一项 $y^\top K^{-1} y$ 是数据拟合,第二项 $\log|K|$ 惩罚模型复杂度,所以即使你不加任何显式正则,DKL 在原理上仍然抗过拟合。这是 GP 区别于深度集成的根本优势之一。
DKL 能给你什么:
- 从原始输入学表示: 图像、音频、文本都进得来了,不再被困在"必须先有手工特征"的旧范式。
- 校准的不确定性: GP 头仍然给你 $\mathcal{N}(\mu(x), \sigma^2(x))$ 的预测,所以下游决策系统(贝叶斯优化、主动学习、安全关键控制)拿得到它需要的误差棒,而不是 softmax 出来的"伪概率"。
- 样本效率: 在 $n \sim 10^3$ -$10^4$ 标注样本的回归任务上,DKL 经常击败深度集成;这正好是工业界很多场景的真实区间。
注意事项。 DKL 不是免费午餐:
- GP 头仍然是训练 $O(n^3)$ 、内存 $O(n^2)$ 。$n > 5 \cdot 10^4$ 时必须用稀疏 / 诱导点变体(第 7 篇 ),或者干脆退回到深度集成。
- 神经部分的表达力会淹没 GP 部分的正则化。如果 $g_\theta$ 有 1000 万参数而你只有 1k 标签,网络可以学到一个让每个点都远离其他点的表示,GP 退化成纯噪声,边际似然的奥卡姆剃刀也救不了这种结构性失衡。
- 超参耦合:基础核的长度尺度和编码器输出的尺度互相纠缠。常见故障模式是编码器把所有输入坍缩成一个小球(一切都"很像"),或者推到无穷远(一切都"完全不同")。两种坍缩在 Gram 矩阵上一眼可见,下文的诊断函数会拎出来。
DKL 实战#
用 GPyTorch 写一个最小可跑示例。它是带 PyTorch 反传的 GP 回归标准库,也是 Gardner et al. 2018 那篇 NeurIPS 论文之后社区默认的工具链。
| |
训练循环就是标准 PyTorch 循环,loss.backward() 把梯度灌到 GP 超参和网络权重里:
| |
两条踩坑后才会写到注释里的实战建议:
1. 编码器的学习率要比核超参的低。 核超参可解释、稳定;编码器过参化、容易飘。10 倍比例是个合理的默认:核超参在 $10^{-2}$ 量级、编码器在 $10^{-3}$ 量级。如果编码器先飘走,整个 GP 头会被反复迫使在不稳定的特征空间上重新拟合,loss 曲线会看起来像锯齿。
2. 显式归一化编码器输出。 不做归一化的话,编码器会把所有输入坍缩到一个极小的球里、或者推到无穷远。这两种失败模式都让 Gram 矩阵要么处处为 1(rank-1,没用),要么处处为 $e^{-\infty}$
(单位阵,也没用)。给编码器输出套一个 tanh,或者把它重新缩放到单位立方体,是工程上的标准做法。
DKL vs 端到端深网:什么时候真的赢。 实战经验里,DKL 相对纯深网的优势有三个明显窗口。其一,样本预算 $n \in [10^3, 5 \cdot 10^4]$ :太小则 GP-only 直接赢、不需要神经特征;太大则 $O(n^3)$ 吃不消,深度集成更划算。其二,下游需要校准不确定性:BO、主动学习、安全关键控制都是这一类——deep ensemble 也能给方差但校准度通常差一档,特别是在分布外。其三,输入是原始模态但任务又是回归:图像分类深网已经把方差性质做得很好;图像回归(年龄估计、生物年龄、分子性质预测)反而是 DKL 长期占优的区间。反过来,当 $n > 10^5$ 、任务是分类、且不需要解释性时,端到端深网几乎总是更简单的选择——不要为了"看着像贝叶斯"硬上 DKL。
另一个常被忽略的优势:DKL 在主动学习里几乎不可替代。 主动学习的核心是 acquisition function:给一个候选未标注样本 $x^\star$ ,问"标这个点对模型最有帮助吗"。GP 的后验方差 $\sigma^2(x^\star)$ 是这个问题的闭式答案;deep ensemble 也能近似算,但每加一个候选都要让所有 5-10 个网络做一次推理,吞吐量差 GP 一个数量级。在生物实验、材料筛选、人类标注这类"每个标签都要 100 美元 + 24 小时"的场景里,这个差距就是项目能不能跑完的差距。
对比表:DKL vs 纯深网 vs 纯 GP。 一张表把三者的取舍说完。
| 维度 | 纯 GP | DKL | 端到端深网 |
|---|---|---|---|
| 表示学习 | 无(手工特征) | 有(联合训练) | 有(联合训练) |
| 不确定性 | 闭式高斯 | 闭式高斯 | 外挂 |
| 训练开销 | $O(n^3)$ | $O(n^3)$ + 反传 | $O(n)$ per epoch |
| 适用 $n$ | $\leq 10^4$ | $10^3$ -$5 \cdot 10^4$ | $\geq 10^4$ |
| 适用模态 | 表格 / 已编码特征 | 任意(编码器适配) | 任意 |
| 超参手感 | 边际似然自动 | 需要分组学习率 | 学习率 + 一堆 trick |
| 调试难度 | 低(Gram 一眼可读) | 中(坍缩诊断) | 高(loss 不解释什么) |
读这张表的方式不是"找最优一列",而是"看你具体场景该挑哪一列"。三列各自有一个杀手锏:纯 GP 是"小数据 + 不确定性"的最简单方案,DKL 是"中等数据 + 原始模态 + 不确定性"的唯一干净答案,端到端深网是"大数据 + 不在乎不确定性"的默认选择。任何一列被用错地方,结果都会比另外两列任一个用对地方的差,选错列的代价比调错超参的代价大一个数量级,这也是为什么本系列把"怎么选"放在最后一篇压轴。
核方法 vs 深度学习:什么时候选哪个#
最清晰的心智模型是一张二维表格:训练集大小 × 特征维度。画一次以后就别再为这事吵架了。

这张表格有立场,但背后是五条 trade-off 轴,每条轴都对应核社区和深度学习社区争论了十年的某个具体点。
轴 1:数据量。 核方法内存 $O(n^2)$ 、计算 $O(n^3)$ 。$n = 10^3$ 时核求解只要毫秒级,且会在相同数据上击败从头训练的深网——核的归纳偏置(RBF 的光滑性、Matern 的可微类、周期核的季节性)在干活,而深网那几百万参数根本没数据可学。$n = 10^5$ 时核求解要几分钟(或者上 Nystrom / RFF 做近似,见第 7 篇 ),深网用 GPU 也是几分钟,两边持平。$n = 10^7$ 时核求解不可行,深网很舒服;这个区间属于深度学习。这条轴是最硬的:计算复杂度是物理定律,不会因为算法进步而消失。
轴 2:输入维度与结构。 100 维的、列与列之间光滑的表格数据是核的地盘。224x224 的 RGB 图像是深网的地盘,因为像素距离没意义。中间情形又回到核的地盘:从预训练模型免费拿到的 100 维 ResNet 特征,在冻结特征上挂一个小核头,标注数据稀缺时经常击败整网微调。这就是迁移学习里的核模式:在大语料上预训练大模型 → 冻结 → 在冻结特征上放一个小核头。CLIP 时代之后这个模式更普遍:CLIP / DINO / SigLIP 给你的图像 embedding 拿来就能跑 GP,省下整网微调的算力,下游只要几百个标注样本。
轴 3:不确定性需求。 这是核社区永远护住的护城河。高斯过程把完整预测分布 $\mathcal{N}(\mu(x), \sigma^2(x))$ 作为同一组方程的闭式输出,和均值是同一份计算(第 6 篇 )。深网必须外挂不确定性:MC dropout、深度集成、贝叶斯神经网络。这些都能用,但都没有 GP 干净。MC dropout 在分布外明显欠校准,深度集成需要 5-10 倍训练成本,贝叶斯神经网络的变分近似总是有偏。如果你的下游系统(贝叶斯优化、主动学习、安全关键控制、科学发现)关心校准性,就先用 GP,除非有非常硬的理由才离开它。
轴 4:可解释性。 核 SVM 有支持向量,模型能指着具体训练点说"这就是我为什么这样预测"。线性核有可读的权重。多项式核有可命名的显式特征交互(第 4 篇 )。ARD(自动相关性决定)核给你每个特征的长度尺度,本身就是一个特征重要性排序。深网是一堆 1000 万浮点数加上运气好时的 SHAP 图。在受监管行业(医疗、金融、法律)里,“模型说了什么 + 为什么这么说"是合规要求,不是 nice-to-have;这个差距很关键。
轴 5:理论保证。 核方法有完整理论:Mercer 分解、表示定理(第 5 篇 )、Rademacher 复杂度泛化界、收敛速率。深网有 NTK 理论(Jacot, Gabriel, Hongler, NeurIPS 2018)描述无限宽极限,以及 NNGP 理论(Lee et al., ICLR 2018)描述无限宽随机初始化网络的先验分布,这两条线本身都是核理论。但对人们实际训练的有限宽网络,理论基本是经验性的。如果你要给应用数学期刊投稿、或者要给监管机构写合规报告,核方法更友好。
这两派并不互斥,DKL 就是最干净的综合。诚实的总结:深度学习赢了"原始模态 + 海量数据"区间;核方法赢了"中等数据 + 结构 + 不确定性"区间;DKL 赢了"想同时要两边的好处、又能负担 GP 成本"区间。 这三个区间之间的边界,正在被 NTK / NNGP 等理论结果和 CLIP 类预训练 embedding 这类工程结果反复磨平,下文最后会回到这一点。
还有一条经常被忽视的"轴 6”:部署成本。 这条轴在论文里几乎没人提,但在工业界是头号 deal-breaker。一个 ResNet-50 推理一次要 4 GB GPU 显存、25 ms 延迟;一个在同样任务上训出来的精确 GP,推理时只需要存 $n_{\text{train}}$ 个支持点和一个 Cholesky 因子(几十 MB CPU 内存),推理 1 ms。如果你的预测服务部署在边缘设备、低算力服务器、或者按延迟收费的 serverless 平台上,这条轴可以一票否决前五条加起来的所有结论。核方法是少数几种"训练贵、推理便宜"的现代 ML 模型,这个性质在合适的场景里值很多钱。
超参数调优实战手册#
核方法的超参数比深网少得多,通常 2 到 5 个,但这些少数超参是乘性的,调错了就是灾难。实战中有三种调参套路,按问题规模和不确定性偏好选。
交叉验证(默认)#
干活老将。选 5 折或 10 折 CV split,在对数网格上扫超参,按精度(分类)或负 MSE(回归)打分。
| |

两条不显眼但最省时间的规矩。
永远用对数尺度。 $\gamma$ 、$C$ 、长度尺度、信号方差全都是正的乘性参数,意味着它们对模型行为的影响是按倍数算的,不是按差值算的。从 $0.01$ 到 $100$ 的线性网格把 99% 的点花在 $\geq 1$ 的区间里。对数网格用 12 个点就能覆盖六个数量级,这是数量级上的胜利,不是百分之几的优化。
永远塞在 Pipeline 里。 如果你先 scaler.fit(X) 然后在缩放后的数据上跑 CV,你就把测试折的统计量泄露进训练折了。正确写法是 Pipeline([scaler, model]),scaler 在每一折里独立重新拟合。这种"漏水 CV"和"干净 CV"的精度差通常是 1-3%,正好就是你打算发表为头条结果的那个差距,而审稿人很可能不会替你抓出来。
边际似然(有 GP 的时候)#
对高斯过程,边际似然(把隐函数积掉后训练数据的概率)给你一个闭式可导目标,自动平衡拟合与复杂度。你直接对所有核超参做对数边际似然的梯度下降。没有嵌套 CV,没有网格,没有 50 次重训。
| |
输出会给你逐维的长度尺度(ARD),而这些逐维长度尺度本身就是一个可解释的特征重要性排序:长度尺度小的特征重要,长度尺度大的特征基本被忽略。这是经典 ML 里更漂亮的结果之一:比 permutation importance 更原理化,比 SHAP 更便宜。
贝叶斯优化(每次评估很贵的时候)#
训练一个模型要几小时(大数据集、大核、复杂管线)时,网格搜索把评估浪费在明显糟糕的区域。贝叶斯优化在超参空间上拟合自己的 GP,用 acquisition 函数(期望改进、UCB)挑下一个点。一路是 GP,工作原理也确实就是这件事的合适工具,这也是 Frazier 2018 那篇 tutorial 把整个领域讲清楚的核心 insight。
| |
30 步贝叶斯优化经常持平或击败 100 个网格点。BO 的缺点是序列化:网格搜索是 embarrassingly parallel,BO 是串行的,但在单机上 BO 赢。如果你有 8 块 GPU,混合策略(前 16 个点用拉丁超立方采样并行评估、之后 14 个点用 BO 串行精修)通常是真正的最优解。
故障排查:核方法的 4 大病灶#
核方法的失败方式有四种特征鲜明的形态。如果你能从症状里把它们辨认出来,几分钟就能修;辨认不出来,几天就过去了。
病灶 1:过拟合#
症状。 训练精度接近 1.0;测试精度直线下滑。Gram 矩阵看着接近对角阵,每个训练点只跟自己像。学习曲线上训练 loss 单调下降、验证 loss 在某一刻折返向上。
原因。 $\gamma$ 太大(RBF 带宽太小);多项式阶数过高;SVM $C$ 太大(正则化不够);GP 噪声方差钉在零;自定义核没归一化导致 $K(x, x) \gg K(x, x')$ 。
修法。 把 $\gamma$
减半,直到训练精度和测试精度收紧。多项式阶数封顶在 3(第 4 篇
反复强调过的)。$C$
缩小一个数量级。给 GP 加一点噪声项,通常 WhiteKernel(noise_level=0.01) 是个安全的起点。多搞点训练数据——过拟合的核是"饿坏了"的核,加 30% 数据经常比调任何超参都管用。
病灶 2:欠拟合#
症状。 训练和测试精度都卡在低位。模型对每个输入预测都接近边际均值。GP 后验方差几乎处处等于先验方差,证明模型没从数据里学到东西。
原因。 用线性核处理非线性问题;RBF $\gamma$ 离谱地小;$C$ 离谱地小;用了多项式核但阶数只有 1。
修法。 沿着表达力阶梯往上爬:线性 → 多项式 → RBF → DKL。$\gamma$
乘 10,直到预测开始有变化。$C$
乘 10。验证核确实在响应输入差异,打印 $K(x_1, x_2)$
两个不同训练点的值,确认它不是只等于 $K(x_1, x_1)$
。中位数启发(第 4 篇
)是 $\gamma$
的一个合理种子,从那里开始扫描比从 sklearn 默认 'scale' 开始更靠谱。
病灶 3:数值不稳#
症状。 GP 拟合报"矩阵奇异"或"Cholesky 失败"。核 PCA 返回负特征值(理论上不该出现的负数往往是浮点误差被放大的征兆)。SVM 求解器在最大迭代步用完后仍然报"未收敛"。
原因。 Gram 矩阵秩亏或病态。最常见:训练集里有重复或近重复点;自定义核其实不是正定的(第 2 篇 的 Mercer 条件就是为此存在的);$\gamma$ 极端到让非对角项被推到机器零;数据没标准化导致条件数爆表。
修法。
- 加抖动:
K = K + 1e-6 * np.eye(n)。单一最有效的修法。等价于给 GP 加一个噪声项,把核矩阵从奇异边缘拉回来。 - 标准化特征: 基于距离的核在特征尺度不同时会塌掉。
StandardScaler是 30 秒能修的 90% 的核数值问题。 - 去掉近重复行再拟合。
np.unique加一个小容差就够,不需要复杂的去重算法。 - 用 float64。 除非你完全清楚自己在做什么,否则不要用 float32 训 GP:Cholesky 在 float32 上对条件数 $> 10^6$ 的矩阵基本不工作。
- 验证自定义核的正定性:
np.all(np.linalg.eigvalsh(K) >= -1e-8)。这条断言是新核上线前的硬门槛,没过别提交。
病灶 4:训练太慢#
症状。 $10^4$ 样本上的 SVM 跑几小时。GP 回归在几千样本之后就死。还没开始训练内存就爆。这不是"机器不够好",是 $O(n^2)$ 内存 / $O(n^3)$ 计算的物理上限。
原因。 $O(n^2)$ 内存、$O(n^3)$ 计算不是手误。$50\,000 \times 50\,000$ 的 float64 核矩阵是 20 GB;Cholesky 在它上面要跑 $\sim 10^{14}$ 次浮点运算,单线程几小时起步。
修法。
- 能用线性核就用:
LinearSVC和 SGD 轻松扩展到百万级,因为它们直接在原始特征空间求解、不构造 Gram 矩阵。 - 非线性核用 Nystrom 近似:
sklearn.kernel_approximation.Nystroem(第 7 篇 )。挑 $m \sim 100$ -$1000$ 个 landmark 把 $O(n^3)$ 降到 $O(nm^2)$ 。 - 平移不变核用随机傅里叶特征:显式 $D$ 维特征,误差按 $1/\sqrt{D}$ 衰减。$D = 1000$ 通常已经足够把 RBF SVM 在百万样本上跑出 95% 的精度。
- 稀疏 / 诱导点 GP(
gpytorch.models.ApproximateGP):GP 扩展到 $10^5$ 及以上,配合 GPU 还能再上一个数量级。 - $n \gtrsim 10^5$ 且输入是原始图像 / 音频 / 文本:切换到深度学习,或上 DKL。这是流程图第五步明确允许的"承认核方法在这个区间不是最优"的退出口。
上手前的 5 项预检#
新核项目开跑之前花 5 分钟过一遍这五项,能省下后续 50% 的 debug 时间。这是经验值,未必精确,但方向对。
- 数据是否标准化?
StandardScaler或RobustScaler,几乎所有距离类核的隐含假设。 - 是否在 Pipeline 里? 不在的话 CV 必漏水,结果不可信。
- Gram 矩阵热图长啥样? 不画就开始调参等于闭着眼睛开车。
- 超参种子是中位数启发还是 sklearn 默认? 后者基本等于"我不在乎"。
- 打算用什么验证不确定性是不是校准的? 没答案就别承诺给下游"误差棒",否则信任债迟早爆。
这五项任意一项答不上来,先把它答上来再去 fit 模型。
诊断:从 Gram 矩阵读病灶#
Gram 矩阵会在任何指标之前先告诉你出了哪种病灶。瞄一眼热图、画一条特征值谱、看一下条件数,三件事都是 5 行代码,却比任何一个 dashboard 都更早把问题暴露出来。
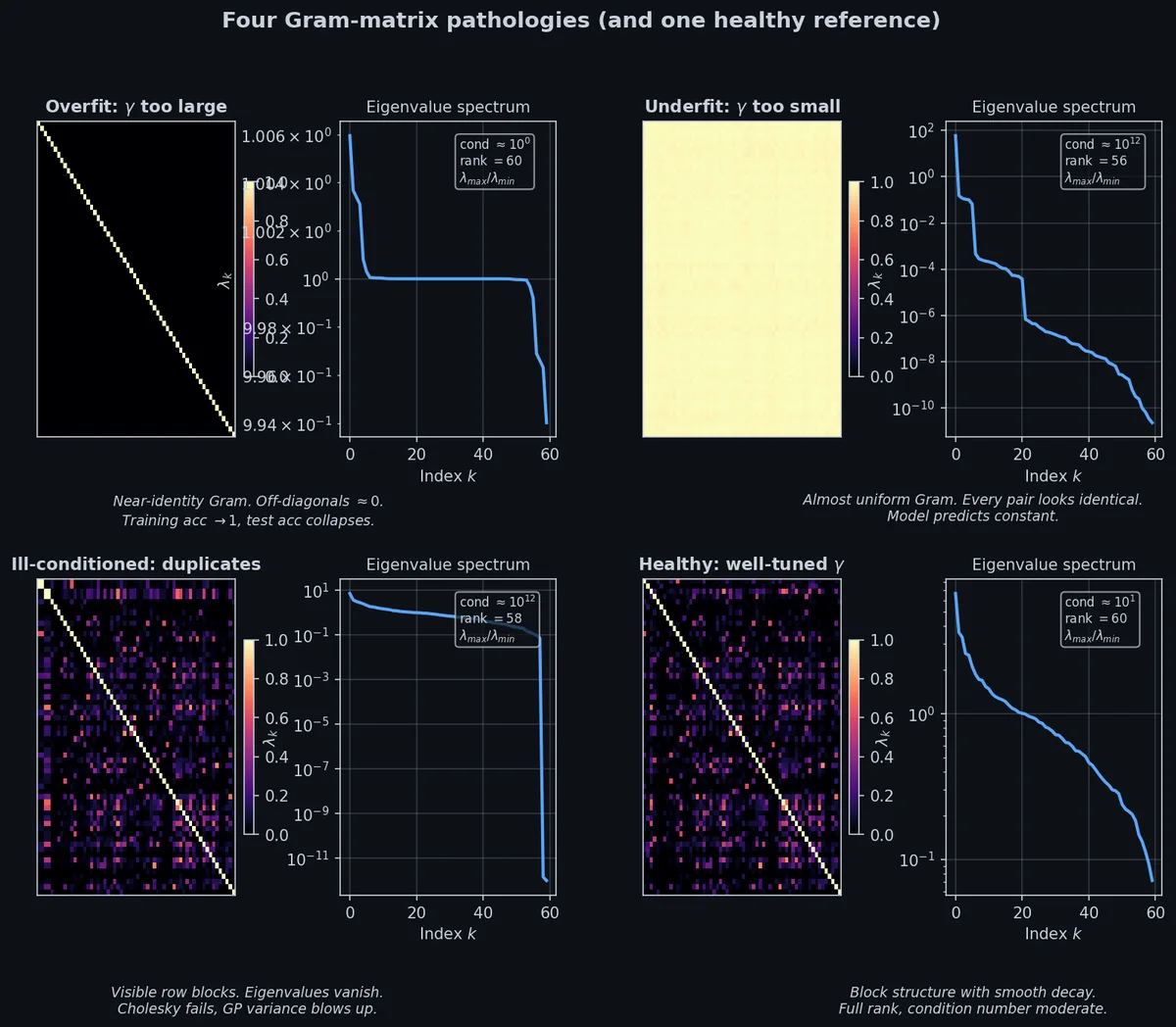
视觉速查表。
- 接近单位阵的 Gram(对角亮、非对角暗):$\gamma$ 太大,过拟合。特征值谱:所有特征值都接近 1,没有衰减。直觉解释:每个训练点只跟自己像,所以 GP 退化成"逐点查表",完全没有泛化能力。
- 接近均匀的 Gram(处处亮):$\gamma$ 太小,欠拟合。特征值谱:一个巨大的特征值,其余很小,是 rank-1 行为。直觉解释:所有点看着都一样,GP 只能预测全局均值。
- 可见的行条纹(某些行看起来和别的行完全一样):输入有近重复,病态。特征值谱:陡然跌到零。直觉解释:Cholesky 试图把一个秩亏矩阵分解,自然崩溃;这种 case 加 jitter 是治标,去重是治本。
- 带块结构的光滑渐变(且块结构与标签对得上):健康。特征值谱:几何衰减。直觉解释:核找到了类间结构,块对应类内紧凑、类间分散,几何衰减说明前几个主成分就抓住了大部分方差,这是你想看到的形态。
一个 10 行的诊断函数能省你一百次时间:
| |
在第一次模型拟合之前、每次超参变更之后、自定义核实现之后都跑一遍。这个函数是我所有 GP / SVM 项目里第一个加进去的脚手架,比 wandb 还早。
核方法的现代相关性#
核方法不是遗产,它在 2026 年仍然是活跃的研究前沿。核社区仍在推进的四个方向:
小数据区间。 很多科学和工业任务只有 $n < 10^3$ 的标注样本,将来也不会有更多:蛋白质性质预测、材料发现、临床结局预测、半导体良率建模。深网在这里直接散架;核方法和 GP 是干活的主力。2020 年代见证了对物理信息核的大量投入:把守恒律烤进核函数里,比如让 $k(x, x')$ 强制满足拉普拉斯算子在某种边界条件下的等变性。这类核相当于把"我们已经知道物理是这样的"作为强先验,把"只剩下未知系数得从数据里学"作为弱后验,比让深网"从零学物理"省下 100 倍样本。再加上 active learning 这条线,把"哪个实验最值得做"也交给 GP 算 acquisition function,整个小数据 pipeline 在 2026 年已经是一个相当成熟的范式,远比"小数据 → 上 XGBoost" 这种民间默认靠谱。
贝叶斯优化。 每一次超参扫描、每一次神经架构搜索、每一次化学优化,只要用了 optuna、scikit-optimize、BoTorch、Ax,背后都在用高斯过程。BO 是 GP 在深度学习时代的杀手级应用:核方法在调核方法,一路调到 GPT。说得更夸张点:每次有人 fine-tune 一个 LLM,他用的那套学习率 / batch size / warmup 步数,很可能就是某个内部 BO 服务用 GP 跑出来的。人类调参时代真正结束的标志,是 GP 接管。这条线还有个值得记住的小细节:BO 通常用 Matern $\nu = 5/2$
而不是 RBF,因为超参地形在边界处经常不连续可导,Matern 比 RBF 鲁棒一档。
科学 ML。 PDE 求解器的代理模型、气候 emulator、分子动力学都依赖 GP,因为他们需要校准的不确定性,而手上没有几百万次模拟可供训练。深度算子网络和傅里叶神经算子在抢地盘,但 GP 在样本效率上仍然是要击败的那条基线,尤其是在 emulator 必须给"这个预测可不可信"的下游决策里,深网外挂的不确定性始终欠校准。一个具体的例子是天体物理里的引力波参数推断:LIGO 团队用 GP 代理替代昂贵的数值相对论模拟,整个流水线的 likelihood 评估从单次几秒降到毫秒级,做 MCMC 推断时这是 10^4 倍的真实加速比,而且不确定性是闭式的,可以直接进 posterior。
神经切线核(NTK)与 NNGP。 Jacot、Gabriel、Hongler 在 NeurIPS 2018 的论文证明:无限宽神经网络用梯度下降训练的行为完全等价于一个特定(可计算)核函数的核方法,这个核就叫 NTK。同期 Lee et al. 在 ICLR 2018 的 Deep Neural Networks as Gaussian Processes 给出了配套结论:无限宽随机初始化网络的输出分布就是一个均值为 0 的 GP,其协方差核可由网络架构递归算出,这就是 NNGP。两条结果合在一起说的是:深度学习在某个理想极限下,本身就是核方法。 这是现代 ML 理论里最让人惊讶的结果之一:“深度学习赢核方法"和"深度学习就是核方法"在这个极限下变成了同一句话。
把 NTK 和 NNGP 摆在一起看更有意思。NNGP 描述的是先验,即一个随机初始化、还没训练的无限宽网络在函数空间里的分布;NTK 描述的是训练动态,即这个网络在梯度下降下如何从先验走到后验。两者都是核,但角色完全不同:NNGP 核 $K_{NNGP}$ 决定"网络相信什么”,NTK 核 $K_{NTK}$ 决定"网络怎么学"。Lee et al. 2019 的后续工作进一步证明,在 NTK 区间训练到收敛的无限宽网络,其预测函数等价于以 $K_{NTK}$ 做核岭回归,所以一个看起来非常"深度学习"的训练流程,在数学上等价于一个非常"经典"的核回归。
NTK 还提供了"懒训练(lazy training)“的清晰直觉:在 NTK 区间里,网络权重几乎不动,所有学习都发生在最后一层上面的有效核里。每一层的权重相对其初始化的变化都是 $O(1/\sqrt{\text{width}})$ ,宽度趋于无穷时这个变化趋于零,所以网络的特征图基本被初始化锁死,只有最后的线性读出在动——也就是说网络"看上去在做表示学习”,实际上是在固定的 RKHS 里做核岭回归。这解释了过参化深网为何能不过拟合:复杂度被这个 RKHS 的有效维度而不是参数数量限制住,所以"参数比样本多 100 倍但泛化良好"在 NTK 区间里不矛盾,只是核岭回归的标准事实。
实战意义大于算法意义——有限宽网络并不真的是 NTK,特别是带 batch norm、weight decay、数据增广、residual connection 这些工程 trick 的现代网络早就出了 lazy regime,权重的变化是 $O(1)$ 而不是 $O(1/\sqrt{\text{width}})$ 。但理论是两派之间最干净的桥之一:它告诉你深度学习的"魔法"在某个极限下是可以被完全解构的核方法,而真正让现代深网超越 NTK 的,恰恰是那些把它推出 lazy regime 的工程 trick。这反过来也是个有用的诊断——如果你发现你的深网在做 feature collapse 或者完全不学到有用特征,可能是它无意中陷入了 NTK 区间,加大学习率或减弱正则就能跳出来。
带核的保形预测。 在任意基预测器(包括核模型)之上做分布无关的不确定性量化,是 2026 年最干净的非贝叶斯校准区间方法:Vovk 和合作者推动了二十多年,最近五年才算被主流接受。保形预测和 GP 不是对手而是互补:GP 给你校准良好的高斯区间但依赖正态假设,保形预测给你分布无关的覆盖率保证但区间通常更宽,做安全关键系统的时候经常两个一起上。
跨越 8 篇的实用决策清单#
把整个系列的"什么时候怎么做"压缩成一份可以塞进 README 的清单。这不是流程图:流程图是按问题路径走的,清单是按你手上正在做的事走的。
正在选核(第 4 篇
)。 表格 + 没特别想法 → RBF。时间序列有季节性 → Periodic + Matern + WhiteNoise。文本 / 高维稀疏 → 线性。图 / 字符串 / 分子 → 专用核。需要可微类控制 → Matern $\nu = 5/2$
起步。已知低阶交互 → 多项式 $d \in \{2, 3\}$
配合 StandardScaler。
正在调参(本篇)。 默认 → CV + 对数网格。有 GP → 边际似然 + 梯度下降。评估很贵 → 贝叶斯优化。永远在 Pipeline 里做 scaling。永远先看 Gram 矩阵热图,再去看准确率。
正在 debug(本篇)。 训练精度高、测试精度低 → 缩小 $\gamma$ 、$C$ 。两边都低 → 放大 $\gamma$ 、$C$ 、爬表达力阶梯。“矩阵奇异” → 加 jitter、标准化、去重、上 float64。训练太慢 → 线性核 / Nystrom / RFF / 诱导点 GP。
正在扩规模(第 7 篇 )。 $n < 10^4$ → 精确 GP / 精确 SVM 没问题。$10^4 \leq n < 10^5$ → Nystrom 或 RFF + 线性求解器。$10^5 \leq n < 10^7$ → 诱导点 GP / KISS-GP。$n \geq 10^7$ → DKL 或纯深网。
正在做不确定性(第 6 篇 )。 需要校准的预测区间 → 精确 GP > 稀疏 GP > deep ensemble > MC dropout > 单网络。需要分布无关保证 → 保形预测包在任何上述之上。
正在写文档 / 给评审讲解。 把"为什么这个项目选 RBF 而不是 Matern"、“为什么超参用对数网格而不是线性”、“为什么 Gram 矩阵热图是这个形状"写进 README。核方法的选择是可论证的,这是它相对深网最大的工程优势,别浪费它。
把这五张小卡片合起来,差不多就是 8 篇的全部实战内涵。如果哪天你接手一个核项目、却不知道从哪一项开始问,把这五卡片打印出来逐项过一遍,它们覆盖了 80% 的常见踩坑场景。
五步核方法决策流程#
把整个系列压缩成一张能塞进单屏的流程图。

文字版的流程图:
第一步:界定问题。 任务是否线性可分(线性 baseline 是不是已经能用)?是 → 上线性核,又快又可解释,文本这类稀疏高维数据上很难被超越。不要为了"看上去更高级"换核:线性赢的时候硬上 RBF 是最常见的过度工程化。否 → 继续。
第二步:辨认数据类型。 强季节性时间序列?用 Periodic 核 + RBF(趋势)+ WhiteNoise(残差)。模式 Matern * Periodic + WhiteNoise 是 GP 社区的标准配方,第 4 篇
第 4 节给过最小可跑示例。图、字符串、分子图这类离散结构?用专用核(graph kernel、string kernel、Tanimoto kernel)。把它们拍平成欧氏向量会丢掉让数据有意思的全部结构。
第三步:精细控制平滑度。 做 GP 回归并且关心函数的可微类?用 Matern,$\nu \in \{1/2, 3/2, 5/2\}$ 。没特别理由时默认 $\nu = 5/2$ :二阶连续可导,是大部分物理信号的甜蜜点。$\nu = 1/2$ 给你 Ornstein-Uhlenbeck 过程,适合金融时间序列那种"有规则但不光滑"的轨迹;$\nu \to \infty$ 退化成 RBF,对应假设数据无限可微。
第四步:高维稀疏且有已知交互。 文本、n-gram、基因-基因交互、GWAS。先线性;如果需要显式建模二阶交互,用 2 或 3 阶的多项式核,永远不要更高。多项式核对特征量纲极其敏感,第 4 篇 那个"忘了标准化导致 SVM 调一周不收敛"的故事就是反面教材。
第五步:默认 + 扩规模。 RBF 核,用对数网格交叉验证(如果是 GP 就用边际似然)。$n \sim 10^4$ 以上时,SVM 切到 Nystrom 或 RFF,概率模型切到稀疏 / 诱导点 GP(第 7 篇 )。$n \sim 10^6$ 以上且是原始模态时,切到深网或带深度编码器的 DKL。这一步是本系列里第一次承认"核方法在某些区间真的不够用”,但你已经按顺序排除了所有更便宜、更可解释的选项。
打印这张流程图贴墙上,以后代码评审里别再为核选择吵架。
系列概念地图#
这 8 篇的内容不是一堆独立话题,它构成一张从理论指向实践的有向图。

- 第 1-4 篇(理论 + 目录): 核方法是什么、为什么存在。线性天花板动机化核技巧;Mercer 和 RKHS 给它一个严格的家;核函数目录就是真正的菜单。第 1 篇是"为什么",第 2 篇是"凭什么",第 3 篇是"在哪里",第 4 篇是"怎么挑",四篇连起来是一个完整的开局。
- 第 5-7 篇(算法): 怎么用核做计算。表示定理把无限维优化压成有限维线代;GP 把整个画面升到贝叶斯空间;Nystrom 和 RFF 把你从 $O(n^3)$ 里救出来。第 5 篇覆盖经典核算法的核心,第 6 篇打开贝叶斯视角,第 7 篇负责工程现实。没有第 7 篇,前两篇在 $n > 10^4$ 时就只能停在纸面。
- 第 8 篇(综合): 怎么做决定。DKL 搭桥到深网;决策流程把菜单变成流程;概念地图把 8 篇拼回一张图。第 8 篇唯一不教新核函数、新算法,它只教"怎么把前 7 篇变成肌肉记忆"。
三条线索贯穿全 8 篇。
线索 A:理论驱动实践。 正定性不是脚注:第 5-7 篇里每一个算法存在的理由都是 Gram 矩阵有合适的谱性质。跳过数学,你就跳过了诊断;这也是为什么本篇的故障排查章节大半是在"读 Gram 矩阵"。
线索 B:核是一个建模决定,不是数值技巧。 选 RBF 而非 Matern 是关于数据所属光滑度类的一种表态。选 Periodic + RBF 是关于时间结构的一种表态。核方法把这些建模选择摆在明面上;深网经常把它们藏在架构选择里(“我用 ResNet 而不是 ViT"也是一种归纳偏置声明,只是没人逼你写下来)。
线索 C:前沿是混合的。 DKL、NTK、NNGP、GP 增强的 BO、物理信息核,最活跃的研究在混核与深网,而不是站队。下一个十年的 ML 会继续模糊这条界限:等到 NTK 类理论能覆盖现代有限宽网络的那一天,“核 vs 深网"这场争论就会被改写成"什么核 vs 什么核”。
常见误区与回答#
写完 8 篇收到的几条最常见的提问,集中回答一次,省得再单独回复:
Q:核方法真的还值得在 2026 年学吗? A:值得。原因不是它能解决 GPT 解决不了的问题(确实有,但少),而是它教会你的思考方式:把模型选择拆成"先验 + 似然 + 求解器”,对你之后用任何 ML 工具都有用。即使你余生再也不用核方法,学过 GP 之后看深网会更清醒。
Q:DKL 和 transfer learning 有什么区别? A:transfer learning 通常是"冻结预训练特征 + 训一个小分类头",最后还是个深网;DKL 是"冻结或微调编码器 + 训一个 GP 头",最后是个带表示学习的 GP。前者的预测是 softmax,后者的预测是高斯分布,区别在不确定性,不在表示学习。
Q:NTK 既然这么强大,能不能直接用 NTK 替代深网? A:能但通常不划算。NTK 在小数据 ($n < 5000$ ) 上经常击败有限宽深网,但 NTK 是 $O(n^3)$ 求解器,扩规模能力比深网差远了。NTK 主要价值是理论工具:给你一个分析深网为何泛化的可计算 baseline,不是生产工具。
Q:为什么我用 RBF SVM 在自己的数据上跑不过 XGBoost? A:90% 的概率是你没标准化、$\gamma$ 没扫对、或者数据本身就是 XGBoost 擅长的"高维 + 类别变量"组合。剩下 10% 是数据确实更适合树模型,这种 case 也存在,别和它较劲。
Q:sklearn 的 'rbf' 默认 gamma 是 'scale',为什么本文还要推中位数启发?
A:'scale' 算的是 $1 / (n_{\text{features}} \cdot \mathrm{Var}(X))$
,对做过标准化的特征是合理的;但它把所有特征视为同质,忽略了数据真实的成对距离分布。中位数启发直接看成对距离的中位数,对实际"点之间多远"做了一次回应,所以作为初值更靠谱。两者差距通常半个数量级以内,足够触发"过拟合"和"欠拟合"的切换。
Q:DKL 和 transformer 加 GP 头有什么区别? A:没有本质区别,transformer 就是一个特殊的 $g_\theta$ 。论文里的 DKL 一般指 CNN/MLP 编码器,但同样的方程可以套在任何可微的编码器上,包括 BERT、CLIP、DINO。这条线在 2024-2025 年是个活跃方向:用预训练的 vision/language encoder 当编码器,下游接 GP 头做小数据回归,AISTATS 2025 上已经有几篇相关 paper。
接下来#
8 篇之旅到这里走完了。接下来怎么走,取决于把你拉进来的是哪个方向。
专攻贝叶斯优化: Rasmussen 和 Williams 第 5 章;Frazier 2018 年的 A Tutorial on Bayesian Optimization(arXiv:1807.02811);BoTorch 文档。每次你用 Optuna 或 Ax 调深度学习超参,其实已经在做这件事了,现在你知道底下的核是什么。
科学 ML 与物理信息核: Raissi、Perdikaris、Karniadakis 的 Physics-Informed Neural Networks 以及后续基于 GP 的 PDE 求解器工作。地球科学社区已经搭出了气候模型的大规模 GP emulator,分子模拟社区也在用 GP 做势能面拟合。
更深的核理论: Steinwart 和 Christmann Support Vector Machines(2008);Berlinet 和 Thomas-Agnan Reproducing Kernel Hilbert Spaces in Probability and Statistics(2004)。这是参考教科书,不是周末读物,但你引用过的每一条定理的权威来源都在这里。
NTK / NNGP 与深核之桥: Jacot、Gabriel、Hongler Neural Tangent Kernel: Convergence and Generalization in Neural Networks(NeurIPS 2018);Lee 等 Deep Neural Networks as Gaussian Processes(ICLR 2018);Arora 等 On Exact Computation with an Infinitely Wide Neural Net(NeurIPS 2019)。这是两派之间的 Rosetta Stone,读完会觉得"核 vs 深网"这个对立本身被解构了。
实战高斯过程: GPyTorch tutorials(ExactGP、ApproximateGP、DeepKernelLearning 示例)和 GPflow 的入门 notebook。两个都很好,看你 PyTorch 还是 TensorFlow 偏好。如果你只能选一个学,从 GPyTorch 入手,因为它和 PyTorch 完全融合,下游接 DKL、接 deep ensemble 比较、接现代 sampler 都不别扭。
保形预测: Angelopoulos 和 Bates 的 A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification(arXiv:2107.07511)。这是 2026 年市面上把保形预测讲得最清楚的入门,配合本系列的 GP 章节读,你会拿到一套"贝叶斯 + 非贝叶斯"的双保险不确定性工具箱。
一个挑战。 找一个你目前用 XGBoost 或小神经网络解的项目。把它重新框成一个核问题:用 5 步流程图选一个核,跑诊断函数,对数网格调参。对比一下结果。会是三种情形之一:更好、更差、差不多,而三种情形里你都会学到余下的 ML 实践不会教你的东西。
核方法不是机器学习的过去。核方法是机器学习里那部分知道自己在干什么的人。
一段冷静的收尾#
最后写几句不带任何修辞的总结,给从第 1 篇一路读到这里的人。
核方法值得学,但不值得当成万能。 它在某些区间是无可争议的最优工具:小数据、结构化、需要校准、需要解释,但在另一些区间被深网完胜。把核方法当成"老派但优雅"的一种工具,和 XGBoost、ResNet、Transformer 并列在你的工具箱里,比硬要把它包装成"深度学习已经过时"或者"核方法已经过时"都更接近实情。
理论的回报是间接的。 你不太可能在生产代码里直接证一遍 Mercer 定理或者写出 NTK 的递归公式。但你会在 Gram 矩阵热图上一眼看出"这个核是过拟合",会在调 SVM 的时候不再瞎试 100 个 grid 点,会在和深度学习同事讨论时知道 NTK / NNGP 是同一回事的两种说法。这些都是理论训练出来的直觉,不是经验试出来的。第 1-3 篇看起来"和实战没关系"的那部分,其实在每一次实战里默默节省你的时间。
贝叶斯视角是真正的杠杆。 GP 把"我对函数的先验信念"和"数据告诉我的后验信念"分开写在两行公式里,这件事在深度学习范式里没有对应物。一旦你习惯了这种"先验 + 似然 = 后验"的思考方式,回头看深网会发现它把太多归纳偏置藏在架构里、藏在初始化里、藏在数据增广里,这些归纳偏置都真实存在,只是没人逼你写下来。学完 GP 之后,你会开始要求自己(和别人)把它们写下来。
写代码这件事不会消失。 核方法不像 LLM 那种"调 API 就能用"的工具:sklearn 的 RBF SVM 是 5 行,但要让它真的在你的数据上 work 通常需要 50 行的诊断、scaling、CV、超参 grid 加在一起。本篇的诊断函数、Pipeline 模板、Gram 矩阵热图是这 50 行的标配。把它们沉淀进你的项目模板,下一个核项目你会从第 3 行开始而不是第 -50 行。
最后一句私货。 这 8 篇的写作动机其实很简单:我自己被核方法节省过太多次时间,但每次看新人入门都得指给他们 4-5 本不同的教材,没一本是"从动机到代码到诊断到决策"一口气讲完的。所以我把脑子里那条线写下来。如果它在你某个真实的项目里救过你哪怕一次时间,这 8 篇就值了。系列写到这里,我自己也学到了不少。很多东西落到纸面上才知道之前理解得有多潦草,比如 NNGP 和 NTK 我之前一直混着用,写第 8 篇时才被迫把它们分开。这就是为什么"写下来"是最好的学习方式,不只是对你,对我也是。
参考文献#
- Wilson, Hu, Salakhutdinov, Xing. Deep Kernel Learning (AISTATS, 2016)。DKL 原始论文。
- Rasmussen 和 Williams. Gaussian Processes for Machine Learning (MIT Press, 2006)。GP 圣经;免费 PDF。
- Hofmann, Scholkopf, Smola. Kernel Methods in Machine Learning (Annals of Statistics, 2008)。综合性 survey。
- Jacot, Gabriel, Hongler. Neural Tangent Kernel: Convergence and Generalization in Neural Networks (NeurIPS, 2018)。NTK 论文。
- Lee, Bahri, Novak, Schoenholz, Pennington, Sohl-Dickstein. Deep Neural Networks as Gaussian Processes (ICLR, 2018)。NNGP 论文,深网无限宽极限的 GP 视角。
- Frazier. A Tutorial on Bayesian Optimization (2018)。BO 的标准入门。
- Gardner, Pleiss, Bindel, Weinberger, Wilson. GPyTorch: Blackbox Matrix-Matrix Gaussian Process Inference with GPU Acceleration (NeurIPS, 2018)。本篇所有 GP 示例下面跑的那个库。
- Angelopoulos, Bates. A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification (2021)。保形预测的标准入门,配 GP 章节读最香。
- Wilson 等. Stochastic Variational Deep Kernel Learning (NeurIPS, 2016)。DKL 大规模化的关键后续工作,把诱导点 GP 接进了 DKL。
- Vovk, Gammerman, Shafer. Algorithmic Learning in a Random World (Springer, 2nd ed. 2022)。保形预测的奠基性专著;写作风格密但严谨。
本文是 核方法 系列的第 8 篇(最终篇),共 8 篇。 上一篇: 第 7 篇 — 大规模核方法(Nystrom + RFF)
系列完结 — 完整目录见 核方法系列 。


