
Linux(三):磁盘管理
Linux 磁盘从识别到上线的完整链路:用 lsblk 看清块设备、用 GPT 分区、用 ext4 / xfs 格式化、用 /etc/fstab 持久化挂载,用 LVM 在线扩容,并讲清 df 与 du 不一致、删了文件空间不回收等典型故障的真正成因。
生产环境中的磁盘问题几乎从来都不是靠一条命令就能解决的。你面对的是一整套分层的体系:最底层是块设备(物理硬盘或虚拟云盘),接着是分区表(MBR 或 GPT),中间可能还夹着一层 LVM(逻辑卷管理),用来将文件系统与具体磁盘解耦;再往上是文件系统驱动(如 ext4、xfs、btrfs),它为原始字节赋予了“文件”的意义;最后是挂载点,即应用通过目录树访问文件的实际路径。在我经历过的大多数线上故障中,只要能明确指出问题出在哪一层,事情就解决了一大半。

这篇文章会带你走完一个完整的操作流程:从识别新磁盘开始,到分区、格式化、持久化挂载,再到用 LVM 实现在线扩容,以及排查常见的故障模式。每一步都会深入讲解背后的原理,让你不仅明白内核在干什么,还能学会如何推理问题,而不是单纯地死记硬背命令。
文件系统层级:东西到底放在哪里#
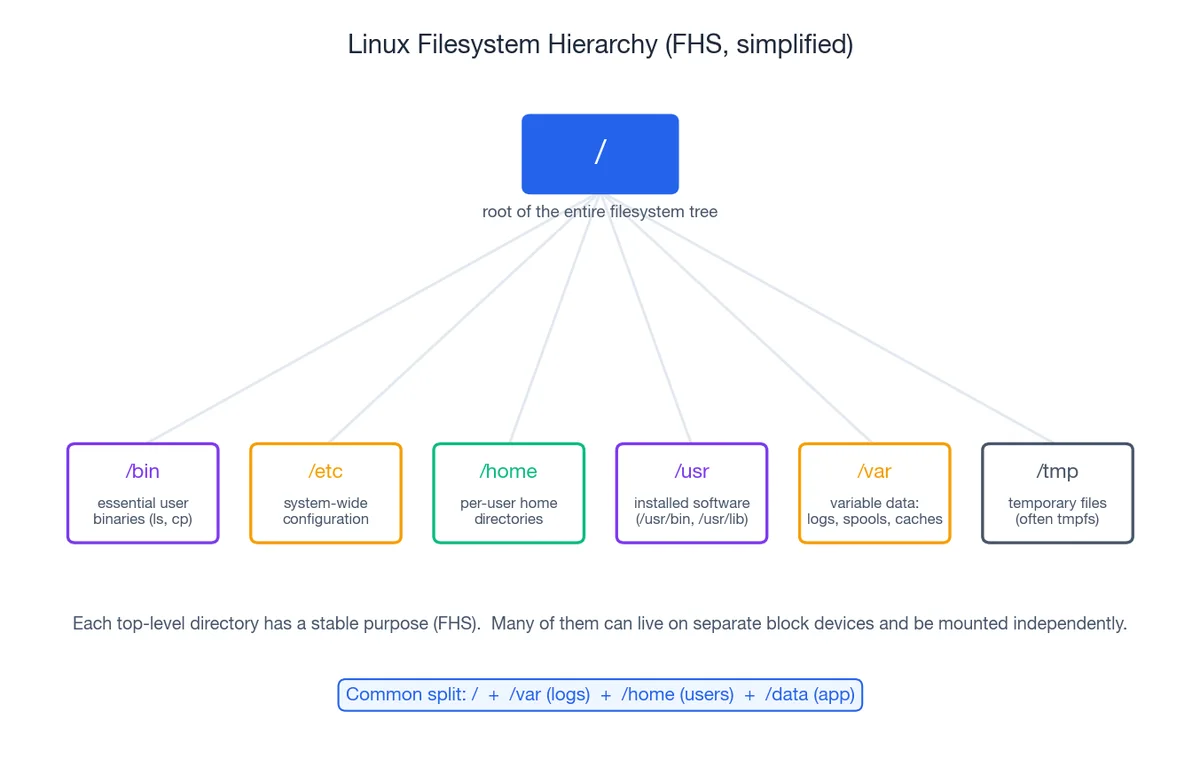
在 Linux 系统中,文件的组织遵循 Filesystem Hierarchy Standard (FHS) 标准。根目录 / 下的每个一级目录都有其特定的功能和用途。一旦你熟悉了这些约定,就能轻松判断哪些目录应该独立挂载到单独的存储设备上。
| 目录 | 作用 |
|---|---|
/ | 系统的根目录,整个文件系统的起点,操作系统的核心所在。 |
/bin、/sbin | 系统启动和运行所必需的关键命令工具。 |
/etc | 全局配置文件的存放地,通常以纯文本形式存在。 |
/home | 普通用户的个人目录,每个用户都有自己的专属空间。 |
/usr | 系统安装的软件和库文件,例如 /usr/bin 和 /usr/lib。 |
/var | 动态变化的数据,比如日志文件、邮件队列、软件包缓存以及部分数据库文件。 |
/tmp | 临时文件的存放点,大多数发行版会将其映射到内存中的 tmpfs。 |
/dev | 设备文件节点,例如 /dev/sda 和 /dev/null。 |
/proc、/sys | 内核提供的虚拟文件系统,用于暴露系统运行时的信息。 |
/mnt、/media | 传统上用于挂载额外存储设备或可移动介质的目录。 |
在实际生产环境中,常见的做法是将 /、/var、/home 和 /data 分别放置在独立的块设备上。这种设计背后有着明确的运维考量:如果 /var 被日志文件填满,根分区仍然有足够的空间供管理员登录并进行修复;而当 /data 需要扩容时,可以单独调整该分区,无需对系统盘做任何改动。这种布局既提升了系统的稳定性,也简化了后续的维护工作。
块设备与命名:磁盘在 Linux 里长什么样#
在 Linux 系统中,每块连接到内核的磁盘都会以块设备的形式出现在 /dev 目录下。这些设备的命名方式与其所使用的总线类型密切相关:
| 设备路径 | 含义 |
|---|---|
/dev/sda、/dev/sdb | SATA、 SAS 或 USB 硬盘(通过 SCSI 子系统) |
/dev/nvme0n1 | NVMe 固态硬盘,命名空间 1 |
/dev/vda | virtio 虚拟磁盘(KVM 或云主机环境) |
/dev/xvda | Xen 虚拟磁盘(早期 AWS 实例使用) |
/dev/sr0 | 光驱 |
分区编号会附加在设备名后面;对于 NVMe 设备,分区号前还会额外加一个 p 来分隔,例如 /dev/sda1 和 /dev/nvme0n1p1。
在进行任何可能破坏数据的操作之前,建议先运行以下三条命令来了解当前的磁盘状态。
| |
其中,lsblk -f 是本文中最值得记住的一条命令,它不仅能展示块设备的层级结构,还能显示每个分区的文件系统类型、挂载点以及 UUID。如果只能记住一条命令,那就记住这个。
命名陷阱:为什么 /dev/sdb 可能会“变”#
Linux 中的磁盘名称是根据内核启动时枚举设备的顺序分配的。如果你插入或移除了某块磁盘、改变了 SCSI HBA 的探测顺序,或者在虚拟机环境中进行了实时迁移,原本的 /dev/sdb 很可能就会变成 /dev/sdc。因此,千万不要直接在 /etc/fstab 中使用 /dev/sdX 这样的设备名。取而代之的是使用更稳定的标识符来挂载磁盘:
- UUID,在格式化时生成,且在整个文件系统的生命周期内保持不变(例如
UUID=8f1c-...)。 /dev/disk/by-id/...,基于厂商信息和序列号生成,适合用来确认具体的物理磁盘。/dev/disk/by-label/...,格式化时设置的可读标签,方便人类识别。
分区表: MBR vs GPT#

分区表位于磁盘的起始位置,它的作用是告诉操作系统磁盘是如何划分的。在 Linux 中,支持两种分区表格式。
MBR (Master Boot Record) 是一种历史悠久的格式,最早出现在 IBM PC 上。它的分区信息存储在磁盘开头的一个 512 字节扇区内,因此其设计带来了一些固有的限制:
- 使用 32 位 LBA 寻址,最大支持容量为 2 TiB。
- 最多只能创建 4 个主分区。如果需要更多分区,则必须通过“扩展分区”来容纳“逻辑分区”,这种机制显得笨拙且不够直观。
- 分区表只有一份副本。如果磁盘的第一个扇区损坏,分区信息就会丢失。
GPT (GUID Partition Table) 是由 UEFI 规范定义的现代分区表格式,它彻底解决了 MBR 的种种不足:
- 支持 64 位 LBA 寻址,理论上容量几乎没有上限(可以达到 ZB 级别)。
- 默认支持最多 128 个分区,每个分区都可以用一个全局唯一标识符(GUID)命名。
- 在磁盘的开头存放一份主表头,在结尾存放一份备份表头,并且两份表头都带有 CRC32 校验和,能够检测并修复损坏。
- 在第一个扇区保留了一个“保护性 MBR”,使得不支持 GPT 的老旧工具会将其识别为一个“未知的大分区”,从而避免误操作覆盖数据。
除非有特殊需求(例如非常老的 BIOS 只能从 MBR 引导,或者需要与 32 位 Windows 系统双启动),否则建议直接使用 GPT。目前主流的 Linux 发行版和云平台默认都采用 GPT。
常用工具: fdisk、 gdisk 和 parted#
fdisk,传统上仅支持 MBR,但现代版本也兼容 GPT。gdisk,专为 GPT 设计,操作更直观。parted,同时支持 MBR 和 GPT,并提供非交互式的批处理模式,适合在脚本中使用。
以下是使用 fdisk 进行分区的典型交互流程:
| |
如果希望通过脚本实现同样的功能,可以使用 parted 的非交互模式:
| |
这里指定的起点 1MiB 并不是随意选择的,它确保分区对齐到 1 MiB 边界,以匹配现代硬盘的 4 KiB 物理扇区大小。如果分区未对齐,文件系统的一次 4 KiB 逻辑写入可能会导致两次物理读取和两次物理写入,这种性能损耗虽然隐蔽却十分致命。现代工具通常会自动处理对齐问题,但了解这一规则仍然非常重要。
文件系统:把分区变成“能用的东西”#
分区本质上是磁盘上一段连续的字节区域。要想在其中存储带名字的文件,就需要对其进行格式化,即在分区上创建文件系统的元数据结构(如超级块、inode 表、空闲空间位图、日志等),以便内核的文件系统驱动能够识别和操作这些数据。

在 Linux 服务器上,你最常遇到的三种文件系统如下:
- ext4,Debian 和 Ubuntu 的默认选择,也是通用工作负载的稳妥之选。工具链成熟(如
fsck、tune2fs、e2label),故障模式清晰,性能表现稳定。 - xfs,RHEL 7 及其衍生版本的默认文件系统。专为大文件、高并发以及超大规模文件系统设计。不支持缩小分区,只能扩容或迁移。
- btrfs,采用写时复制(Copy-on-Write)技术,原生支持快照功能,对数据和元数据进行校验,并内置 RAID 0/1/10 支持。 openSUSE 和 Fedora Workstation 默认使用。由于复杂度较高,某些配置的历史表现不佳;在生产环境中,通常因其快照能力而被选用。
格式化分区#
| |
格式化完成后,运行 lsblk -f 可查看文件系统类型、标签以及 UUID。务必记下 UUID,后续配置 /etc/fstab 时会用到。
临时挂载#
| |
挂载是一个纯粹的运行时操作,不会对磁盘内容做任何修改。它只是告诉内核:“从现在开始,/mnt/data 下的路径由 /dev/sdb1 上的文件系统提供服务。”重启后,挂载关系会自动消失。
持久化挂载:/etc/fstab#

/etc/fstab 是用于持久化挂载配置的文件。系统启动时,systemd(或 init 脚本中的 mount -a)会读取该文件并挂载其中列出的所有文件系统。
挂载时务必使用 UUID,而不是设备路径 /dev/sdX:
| |
向 /etc/fstab 添加一行配置:
| |
这六列的含义分别是:
- 设备来源,可以是 UUID、标签或设备路径。
- 挂载点,必须是一个已存在的空目录。
- 文件系统类型,如
ext4、xfs、tmpfs、nfs等。 - 挂载选项,默认值为
defaults,可附加其他选项,例如noatime(避免更新访问时间,适合读多写少场景)、ro(只读)、nosuid、nodev、discard、_netdev等。 - dump,固定为
0(传统备份工具dump已被淘汰)。 - fsck 检查顺序,根分区
/设置为1,其他文件系统设置为2,跳过检查则设为0。
修改完配置后,务必先测试再重启。 如果 /etc/fstab 配置错误,系统可能无法正常启动,进入紧急模式。推荐的安全验证步骤如下:
| |
如果 mount -a 报错,请先修复配置,再重启系统。
卸载与“目标忙”问题#
| |
最常见的错误是 umount: target is busy,表示仍有进程占用挂载点下的文件描述符,或者将工作目录设置在挂载点中。定位占用进程的方法如下:
| |
找到相关进程后,可以选择终止或重启它们。如果实在无法解决,可以使用 umount -l /mnt/data 执行“懒卸载”,挂载点会立即从命名空间中移除,但实际释放会在最后一个文件描述符关闭后完成。不过,这种方式应谨慎使用,因为它可能会掩盖潜在的问题。
LVM:把文件系统从物理盘解耦出来#

在没有 LVM 的情况下,文件系统直接依附于分区之上。如果要扩展文件系统,就必须扩展分区,而这要求紧挨着分区之后有连续的空闲空间。然而,在生产环境中,这种情况几乎不可能满足。
LVM (Logical Volume Manager,逻辑卷管理器) 在物理磁盘和文件系统之间引入了一层抽象。它通过三个核心概念实现了灵活的存储管理。
- PV (Physical Volume,物理卷):被 LVM 管理的整块磁盘或某个分区。(命令:
pvcreate) - VG (Volume Group,卷组):由一个或多个 PV 组成的存储池。 VG 内部以固定大小的物理扩展(PE, Physical Extent,默认 4 MiB)为单位进行管理。(命令:
vgcreate、vgextend) - LV (Logical Volume,逻辑卷):从 VG 中划分出来的虚拟块设备。对内核而言, LV 和普通分区无异,你可以在其上创建文件系统。(命令:
lvcreate)
最关键的一点是:LV 在底层磁盘上不需要连续分布。 扩展 LV 只需从 VG 中分配更多的 PE,而这些 PE 可以来自任意 PV。这意味着,无需重新分区即可实现扩容。
构建 LVM 栈#
| |
随时可以通过以下命令查看当前 LVM 栈的状态。
| |
在线扩容:快速响应的最小停机方案#
假设 /data 的使用率已经达到 80%,告警声此起彼伏。借助 LVM,扩容可以在线完成,整个过程只需几秒钟:
| |
整个过程无需重启服务,也无需迁移数据。文件系统只是感知到底层块的数量增加了。
缩容:复杂且风险高#
- ext4 文件系统支持缩容,但必须离线操作:先卸载(
umount),然后运行e2fsck -f检查文件系统,接着用resize2fs <新尺寸>调整大小,最后用lvreduce缩减逻辑卷。顺序一旦出错,文件系统可能会被截断。 - xfs 文件系统完全不支持缩容。官方推荐的做法是“创建一个更小的逻辑卷,用
rsync -aHAX迁移数据,然后切换挂载点”。
经验之谈:规划时只考虑扩展,不要想着缩容。 初始容量可以保守一些,后续根据需求逐步扩展。
快照功能#
LVM 支持为逻辑卷创建写时复制(Copy-on-Write)快照。快照本身也是一个逻辑卷,初始时与原卷共享所有 PE;当原卷中的某些块发生变化时,变化前的内容会被复制到快照预留的空间中。
| |
快照的主要用途包括:
- 提供短时间的一致性视图(在快照上备份,同时允许线上文件系统继续写入)。
- 提供快速回滚的能力。
需要注意的是,快照并非真正的备份。
- 如果快照预留的空间耗尽,快照将失效。
- 如果底层卷组发生故障,原卷和快照会一同丢失。
看用量: df vs du,以及它们为什么对不上#
理论上应该给出相同结果的两条命令,却常常对不上。
df 是直接向文件系统询问占用情况:
| |
而 du 则是通过遍历目录树,将每个文件的大小累加起来:
| |
当 df 显示“已满”而 du 却找不到缺失的空间时,通常有以下三种经典原因。
进程仍持有已删除文件的句柄#
假设某个进程打开了 /var/log/app.log 并持续写入数周。后来有人删除了这个文件。虽然目录项已经消失(du 和 ls 都看不到它),但只要该文件的句柄仍然被某个进程占用,其对应的 inode 和数据块就不会被释放。进程继续写入,磁盘空间继续减少。
| |
解决方法是让相关进程关闭文件句柄:可以重启服务、发送 SIGHUP 信号(如果支持重新打开日志),或者使用 logrotate 的 copytruncate 模式(适用于不支持自动重开日志的进程)。
挂载点混淆#
你以为自己在操作数据卷,但实际上目标路径并未正确挂载,导致你正在往父文件系统写入数据。
| |
如果 findmnt 没有任何输出,说明 /data 只是根目录下的一个普通目录。
ext4 文件系统的保留块#
ext4 默认会为 root 用户保留 5% 的磁盘空间。这样设计是为了确保即使普通用户占满了磁盘,关键服务仍然能够正常运行。但在大容量存储设备上, 5% 的保留空间可能非常可观,这会导致 df 在普通用户还能写入之前就报告“已满”。
| |
注意:仅在不承载操作系统的卷上执行此操作。
inode 耗尽#
某些工作负载可能会创建大量小文件(如缓存、邮件队列或构建产物),导致文件系统的字节空间尚有剩余,但 inode 已经耗尽。此时,df -i 会显示 IUse% 达到 100%,而 df -h 却显示还有充足的可用空间。唯一的解决办法是删除无用文件,或者以更高的 inode 密度重新格式化文件系统(mkfs.ext4 -N <数量>)。相比之下, xfs 文件系统动态分配 inode,几乎不会遇到这个问题。
inode、硬链接、软链接:理解文件系统行为的钥匙#
在每个 Unix 文件系统的核心,都有一个关键的数据结构,inode。它保存了一个文件的所有元数据信息:文件类型、所有者、权限、大小、时间戳、链接数,以及指向实际数据块的指针。但需要注意的是, inode 并不存储文件名。文件名实际上是存放在目录中的,而目录本质上也是一个文件,其内容是一组 (文件名 → inode 编号) 的映射关系。
这种设计上的“解耦”很好地解释了许多文件系统的特性:
硬链接:这是指向同一个 inode 的另一个目录条目(通过命令
ln src dst创建)。两个名字的地位完全平等,没有“主次”之分。删除其中一个名字时, inode 的链接计数会减一;只有当链接计数降为零时,文件的实际数据才会被释放。需要注意的是,硬链接无法跨越不同的文件系统,并且按照惯例,也不能为目录创建硬链接。软链接(符号链接):这是一个特殊的小文件,内容是一个路径字符串(通过命令
ln -s src dst创建)。软链接有自己的 inode,因此它可以跨越文件系统。不过,如果目标文件被删除,软链接就会变成“悬空”的无效链接。文件重命名:在同一文件系统内重命名文件,实际上只是修改了目录条目,而不会触及 inode 或数据块。这就是为什么重命名操作是原子性的,并且几乎瞬间完成。
“文件删了,磁盘空间没释放”:这种情况通常是因为虽然目录条目被删除,导致链接计数降为零,但仍有某个进程持有该文件的文件描述符(这会被视为对 inode 的引用)。在这种情况下,文件的实际数据会一直保留,直到所有相关的文件描述符都被关闭。这也是为什么有时
df和du的结果会出现不一致的原因。
| |
/dev 下的特殊文件#
并非所有 /dev 目录下的设备节点都直接对应硬件。其中一些是纯粹的内核抽象,但它们在日常使用中非常常见:
/dev/null,俗称“无底洞”,写入它的任何内容都会被丢弃;读取时则会立即返回 EOF。常用来屏蔽不需要的输出,例如:command > /dev/null 2>&1。/dev/zero,提供源源不断的零字节流,适合用来预分配空间或擦除数据。比如,可以用它快速创建一个 1 GiB 的文件:dd if=/dev/zero of=test.bin bs=1M count=1024。/dev/random和/dev/urandom,这两个文件提供随机数生成的熵源。绝大多数情况下,你应该优先使用urandom;至于/dev/random,它在早期 Linux 内核中会因为熵不足而阻塞,但这在现代密码学场景中已经不再是一个问题。
| |
端到端清单:从一块新盘到可用空间#
将一块刚接入的硬盘转化为可用存储空间的标准流程如下:
确认新设备
使用lsblk -f查看,应该能看到一块未分区且没有文件系统的空设备,比如/dev/sdb或/dev/nvme1n1。确保它没有任何子分区或文件系统。是否使用 LVM?尽早决定
如果这块存储未来可能需要扩容,建议一开始就将其纳入 LVM 管理。后期再加 LVM 需要停机操作,成本较高。分区(可选)
如果不走 LVM,可以使用 GPT 分区表(通过fdisk或parted工具)。但如果选择 LVM,则可以直接跳过分区步骤,对整块硬盘执行pvcreate,这样更简洁,也省去了分区层的复杂性。格式化文件系统
根据需求选择合适的文件系统:- 普通用途选择 ext4;
- 处理大文件或需要高并发 I/O 的场景选择 xfs。
挂载并验证
执行以下命令挂载并检查:1mount /dev/sdb1 /mnt/data && df -h /mnt/data确保挂载成功并且空间显示正常。
配置持久化挂载
编辑/etc/fstab文件,添加一条基于 UUID 的挂载记录,然后运行sudo mount -a测试配置是否正确。重启验证
在正式依赖这块存储之前,务必在维护窗口内重启一次系统,验证挂载是否能够自动生效。
如果能熟练掌握这套流程,大多数磁盘相关的问题都能从容应对,而不是手忙脚乱。下面的故障排查部分也会从“救火指南”变成一份随手查阅的参考文档。
排障手册#
“磁盘空间不足”但刚刚删了几 GB 的日志文件#
这种情况几乎总是因为某个进程仍然持有已删除文件的句柄,导致空间未被释放。
| |
找到对应的进程后,可以选择重启该进程,或者发送信号让它重新打开日志文件以释放资源。
“重启后挂载失败”#
以下是常见的原因,按发生频率从高到低排列:
/etc/fstab文件中配置的 UUID 错误。可以通过blkid命令核对正确的 UUID。- initramfs 中缺少必要的文件系统驱动(虽然少见,但在最小化安装中使用 btrfs、 zfs 或 xfs 时可能会遇到)。
- 启动顺序问题:尝试挂载依赖于 LVM、 RAID 或网络的路径时,这些子系统尚未就绪。对于网络文件系统,可以添加
_netdev挂载选项; LVM 和软件 RAID 通常由 initramfs 自动处理。
通过以下命令可以复现启动时的挂载过程并排查问题:
| |
“性能突然下降”#
排查性能问题时,建议从底层逐步向上分析,而不是从上层猜测:
| |
- 如果
await高而%util低,通常表明底层存储性能较差(例如网络存储延迟高或云盘拥塞)。 - 如果
%util高但队列深度较低,可能是单线程频繁调用 fsync 导致的负载瓶颈。 - 如果
vmstat显示%wa高且磁盘本身正常,则可能是系统在进行交换操作,建议检查内存使用情况:1 2free -h swapon --show
文件系统突然变为只读#
当内核检测到文件系统存在无法安全写入的损坏时,会将其自动重新挂载为只读模式。首先查看内核日志以获取更多信息:
| |
- 如果底层磁盘存在问题(例如
smartctl -a /dev/sda显示有重映射扇区或介质错误),建议尽快更换硬盘。 - 如果是文件系统本身损坏,需要先卸载文件系统,然后使用相应的离线修复工具进行修复:
- ext4 文件系统:
e2fsck -fy /dev/sdb1 - xfs 文件系统:
xfs_repair /dev/sdb1
- ext4 文件系统:
注意:如果数据非常重要,请务必先创建快照或使用 dd 命令备份磁盘镜像。
命令速查表#
遇到问题时可以随时打开参考的简明指南。
探索与检查#
| |
分区管理#
| |
文件系统格式化与检查#
| |
挂载与持久化配置#
| |
LVM 操作#
| |
故障诊断#
| |
凌晨三点救命的两条建议#
- 执行任何可能破坏数据的操作之前,务必先运行
lsblk -f确认目标。 这一步只需一秒,却能帮你避免“格式化错磁盘”这种灾难性错误。 - 每次修改完一个层级后,确保上一层能够正确识别变化后再继续操作。 层级顺序为:块设备 → 分区 → LVM → 文件系统 → 挂载。如果某一层突然“消失”,立即停下来排查原因,不要强行推进。


