
大模型工程(二):Tokenization 深度解析
BPE、SentencePiece、WordPiece 的差别,byte-level fallback,CJK token 膨胀问题,扩词表的真实代价,以及悄悄塑造每个模型行为的 chat template 特殊 token。
分词层常被忽视,却是在生产环境中我调试最多的地方,静默的质量下降、异常的成本激增、模型无法正确执行指令(通常源于 chat template 格式错误)。我希望在发布多语言产品前彻底掌握这一章的内容。

分词器到底在做什么#
分词器(tokenizer)做的事很简单:把字符串映射成一串整数 ID,反过来也能把 ID 还原成字符串。这两个方向都是确定性的,但通常不是双射,tokenizer.decode(tokenizer.encode(s)) 往返一遍可能会丢失空格、标准化 Unicode 或者合并重复标点,具体取决于算法。
主流方案有三类:
- WordPiece [Schuster & Nakajima, 2012; Wu et al., 2016] — BERT 在用。从前向后贪心最长匹配,并用
##标记子词的延续部分。 - BPE (Byte Pair Encoding) [Sennrich et al., 2016] — GPT-2/3/4、LLaMA、Qwen、DeepSeek 都在用。它迭代合并出现频率最高的相邻字符对,直到达到预设的词表大小。原始 BPE 算法源自 Philip Gage 1994 年一篇关于数据压缩的论文;Sennrich 等人将其适配到了神经机器翻译(NMT)任务中。
- Unigram (SentencePiece) [Kudo, 2018; Kudo & Richardson, 2018] — T5、mBART、XLM-R 在用。它从一个巨大的候选词表出发,通过 EM 算法逐步剪枝,以最大化序列在 unigram 语言模型下的似然。
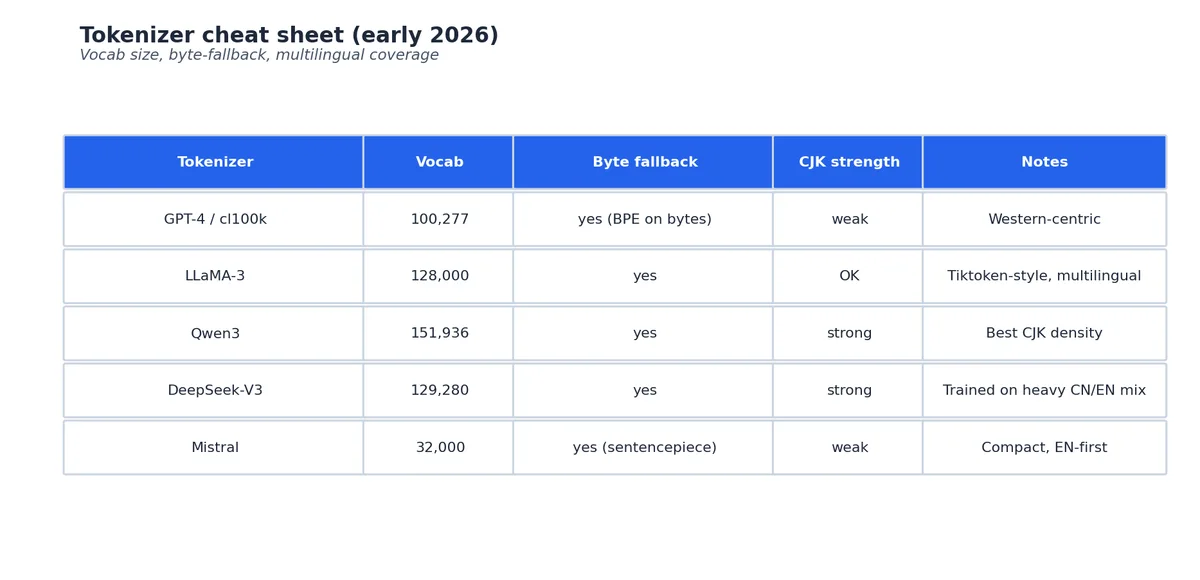
到 2026 年,几乎所有大型生成式 LLM 都采用 byte-level BPE [Radford et al., 2019] 或其 SentencePiece BPE 变体。“byte-level” 是关键所在:它的字母表是固定的 256 个字节,而非约 15 万个 Unicode 码点。因此,任何编码下的任意字符串都能被成功分词,不会出现 <UNK>(未知词)的情况。
这里有个细微但重要的区别值得厘清:BPE-on-characters(即 Sennrich 原始方案)的字母表是训练数据中出现的所有不同 Unicode 字符,在多语言数据中通常达数万个,长尾字符会被丢弃为 <UNK>。而 BPE-on-bytes(即 GPT-2 方案)的字母表严格限定为 256 个字节。任何 UTF-8 字符串都能被无损分解为字节序列并完成分词。代价是,一个未能被合并成单个 token 的汉字会占用 3 个字节(即 3 个 tokens),而非 1 个字符(1 个 token)。这正是我们稍后要深入剖析的 CJK token 膨胀问题的根源。
手动演示字节流上的 BPE#

下面用一个极小的语料库来具象化 BPE 算法:
| |
真实世界的 BPE 实现会将 list(w) 替换为字节序列 w.encode("utf-8"),并使用大得多的语料库(可达万亿级 token),但核心算法逻辑与此完全一致,就是这个循环重复运行数十万次。
“byte-level” 这一特性至关重要:GPT-2 著名地将 256 个字节重新映射到一个可打印的 Unicode 子集,以便人工检查,但其底层编码字母表仍然是 256 个符号。这意味着 没有任何输入会分词失败,根本不存在 out-of-vocabulary 的失败模式。
Tiktoken:OpenAI 的实际实现#
OpenAI 的 tiktoken 库是 byte-level BPE 的生产级参考实现。它在多个关键设计上与朴素 BPE 不同,而这些差异在大规模场景下影响显著。
Pre-tokenization 正则表达式。 在执行 BPE 合并前,tiktoken 会先用如下正则表达式将文本切分为若干 chunks:
| |
该正则按空格、数字(限制为最多 3 位,以避免像 “9999999” 被合并为单个 token 的怪异行为)、缩写词以及连续的非字母数字字符进行分割。BPE 合并仅在这些 chunk 内部 发生,从而有效防止跨词边界产生无意义的多词 token,避免损害模型泛化能力。
Rust 实现与 BPE 缓存。 其热路径采用 “按 pre-token 编码” 策略:先用正则分割输入字符串,再对每个 chunk 利用缓存的 merge 表执行 BPE 合并。Tiktoken 的 Rust 核心会对 pre-tokens 进行哈希并缓存合并结果,使得高频词(如 “the”、“and”)的编码复杂度降至 O(1)。其吞吐量在单核上处理英文约为 3 MB/s,处理 CJK 文本约为 1.5 MB/s。
词表文件格式: Tiktoken 将词表存储为以 token ID 为键、base64 编码的字节串为值的结构。若想查看 cl100k_base 中 token 12345 的真实含义,只需解码其 base64 内容即可看到原始字节。许多 token 是不可打印的(如连续空格、CJK 字符的片段),因为该词表本质上是字节级而非字符级的。
cl100k_base 分词器(用于 GPT-3.5/4)包含 100,256 个 tokens,而 o200k_base(用于 GPT-4o、GPT-4o-mini、o1)则扩展至 199,997 个。这次从 100K 到 200K 的扩容主要服务于多语言覆盖,o200k 合并了更多 CJK 字符序列,并将英文的 tokens-per-word 从 1.3 降至 0.93。
词表大小:成本与质量的调节旋钮#

词表大小 $V$ 是预训练阶段选定的关键超参数,它在 embedding 表的 FLOPs 与内存开销 和 每篇文档所需的序列长度 之间进行权衡。
以一个 $d_{\text{model}} = 4096$ 的 7B 级别模型为例,具体数据如下:
| 词汇 | 嵌入参数 | 绑定的 LM 头 | 总嵌入 | 令牌/英文单词 |
|---|---|---|---|---|
| GPT-2 | 50,257 | tied | 206 M | 1.3 |
| LLaMA-2 | 32,000 | untied | 262 M | 1.4 |
| Qwen2.5 | 151,936 | tied | 622 M | 0.95 |
| GPT-4o | 200,000 | tied | 819 M | 0.93 |
| Qwen3 | 152,064 | tied | 623 M | 0.95 |
更大的词表意味着每篇文档所需的 token 数更少,从而在按 token 计费的场景下降低推理成本;但同时也会增大 embedding 层和 softmax 的计算开销。目前大多数现代模型的词表规模已稳定在 100K–200K 区间。Qwen 和 GPT-4o 所采用的范围,在多语言覆盖能力和避免 embedding 表主导模型参数之间取得了不错的平衡。
词表增大究竟带来了什么变化?合并操作次数随之增加,使得更长的常见子词(如完整的低频词、常用短语)能获得独立的 token。对于英文,词表超过约 50K 后边际收益迅速递减;而对于 CJK 语言,这一收益至少可持续到 200K。
词表大小与模型质量之间的实证缩放关系已有研究。[Tao et al., 2024] 发现,在固定训练预算下,存在一个最优词表大小,且该最优值 随模型规模增长而增大:小模型偏好小词表(< 32K),大模型则偏好大词表(> 100K)。其直观解释是:大模型能更好地摊销 embedding 参数的成本,并从序列长度压缩中获益更多。他们推导出缩放律 $V_{\text{opt}} \propto N^{0.65}$ ,其中 $N$ 为非 embedding 参数量。据此,70B 模型的最优词表大小约为 200K,而 1B 模型则在 32K 左右。
Llama 3 分词器的 128K 词表决策#
LLaMA-2 使用的是一个主要在英文数据上训练的 32K SentencePiece BPE 分词器。而 LLaMA-3 则跃升至 128K(确切地说是 128,256),以 tiktoken 的 cl100k_base 为起点,在 Meta 自有的预训练混合数据上重新训练。Llama 3 论文 [Dubey et al., 2024] 给出了这一决策的理由:
- 多语言覆盖范围比 LLaMA-2 分词器高出 4 倍;
- 在整个预训练语料库上,平均序列长度缩短约 15%;
- 对于 7B 以上的模型,序列缩短所节省的计算量远超 embedding 表带来的额外开销。
以 70B 模型为例,其 embedding 表(128K × 8192 = 1.05B 参数,权重绑定)仅占总参数量的 1.5%,几乎可以忽略不计。但对于 1B 模型,同样的 embedding 表将占据全部参数,这也是为何小型开源模型(如 Phi-4-mini、Qwen3-0.5B)通常采用较小词表(50–64K),以维持合理的 embedding 与非 embedding 参数比例。
LLaMA-3 还在词表末尾预留了 28 个特殊 token(<|reserved_special_token_0|> 至 <|reserved_special_token_27|>)。这些是为未来微调需求预留的占位符,Meta 的 Llama-3-Instruct 模型就利用了其中几个作为 chat template 的标记,而无需重新训练 embedding 表。这种做法非常值得借鉴:在构建词表时,应提前预留数百个 token 供下游任务专用。
CJK token 膨胀问题#


我在开发一款中文产品时,曾因这一问题遭遇严重困扰。GPT-3.5 的分词器(cl100k_base,100K 词表)将英文字符串 “Hello, how are you?” 分为 6 个 tokens,而其中文等价物 “你好,你今天怎么样?” 却被分成了 17 个 tokens。
这一现象由三个因素共同导致:
- UTF-8 编码成本: 一个典型汉字占用 3 个 UTF-8 字节,而 ASCII 字符仅占 1 个。在 BPE 合并前,这已在字节层面造成了 3 倍的 token 劣势。
- 合并频率不足: BPE 优先合并最高频的字符对。历史上,中文预训练数据在 OpenAI 语料库中占比很小,导致中文字符对的合并机会较少。
- 缺乏词边界标记: 英文 BPE 受益于前导空格约定(如
Ġhello);而中文没有类似的天然分隔符。
针对中文句子 “你好,请帮我用 Python 写一个快速排序”,不同分词器的 token 消耗对比如下:
| Tokenizer | Tokens |
|---|---|
| GPT-2 | 47 |
| cl100k_base (GPT-3.5/4) | 24 |
| o200k_base (GPT-4o) | 18 |
| LLaMA-2 (32K) | 39 |
| LLaMA-3 (128K) | 21 |
| Qwen2.5 (152K) | 14 |
如果你按 token 计费(确实如此,所有 API 都这样),这意味着 对于相同的中文 workload,Qwen2.5 的 token 成本比 GPT-4o 低 1.7 倍,这甚至还没考虑每 token 的单价差异。Qwen3 更是降至 13。对于中文重度产品,务必选择在中文数据上训练过的分词器,而非仅仅跟随 hype 模型附带的那个。
你完全可以用五行代码自行验证:
| |
在最终选定模型前,务必用你的真实 prompt 运行此测试。结果往往会与 “谁在 MMLU 上表现最好” 大相径庭。
实战案例:算算中文产品的成本账#
以典型的中文客服机器人场景为例:用户消息平均 80 个汉字,模型回复平均 200 个汉字,系统 Prompt 平均 600 个汉字,日均对话量 100 万轮。
| 分词器 | 会话令牌数 | 每日令牌数 | 每月成本 @ $1/1M |
|---|---|---|---|
| cl100k_base | (600 + 80 + 200) × 24/14 ≈ 1509 | 1.51 B | $45,300 |
| o200k_base | (600 + 80 + 200) × 18/14 ≈ 1131 | 1.13 B | $33,930 |
| Qwen3 | 880 × 13/14 ≈ 817 | 0.82 B | $24,510 |
(换算系数基于前述测得的 CJK 字符 token 比率。)同样的负载、同样的 token 单价,仅因分词器选择不同,月账单就能从 4.5 万美元降至 2.4 万美元。若业务规模更大,年节省额可达七位数。
反过来看,如果产品用户 100% 使用英文,LLaMA-3 的 128K 词表相比 LLaMA-2 的 32K 也能带来收益,更大的词表能将更多多词短语合并为单个 token(例如 “in order to” 从 4 个 token 变为 1 个)。虽然英文上的提升幅度(5–15%)远小于中文(2–3 倍),但仍是实实在在的优化。
为代码定制的 Tokenizer#
代码是一种独特的“方言”,有着截然不同的分词需求。其缩进风格(4 空格、8 空格、Tab)、括号密度以及标识符长度分布,都与自然语言文本大相径庭。在通用网页文本上训练的分词器,往往无法有效合并常见的代码模式。
StarCoder [Li et al., 2023] 采用了一个专为代码设计的 49,152 词表分词器,其训练数据来自 6 TB 的代码语料库 The Stack。在一个典型的 1 KB Python 文件上的对比结果如下:
| Tokenizer | Tokens |
|---|---|
| GPT-2 | 384 |
| cl100k_base | 287 |
| StarCoder | 218 |
| DeepSeek-Coder | 215 |
StarCoder 相比 cl100k_base 减少了 24% 的 token 数,因为它显式合并了如 def 、 return、import 、if __name__ == "__main__": 等常见模式。DeepSeek-Coder 的分词器更进一步,引入了显式的缩进 token,4 个空格是一个 token,8 个空格是另一个。几乎所有代码预训练模型都会采用这类专用分词器,因为其成本节省具有复利效应:代码通常占预训练数据的 8–15%,且在推理阶段的 token 消耗尤为密集。
FIM (fill-in-the-middle) tokens。 代码补全模型需要在光标位置插入代码,而非仅支持追加。FIM 训练 [Bavarian et al., 2022] 引入了三个特殊 token,<|fim_prefix|>、<|fim_suffix|>、<|fim_middle|>,用于教会模型根据前缀和后缀预测中间缺失的部分。如今所有现代代码 LLM(如 GitHub Copilot、Codeium、Cursor 的本地模型)都采用了 FIM。代码补全所用的 chat template 与对话式模板完全不同,属于另一套独立的后训练范式。
词表扩展:通常不要这么做#
一个常见的冲动是:“我想在中文上微调 LLaMA-3,但它的分词器对中文效果不好,不如我直接添加 5 万个中文 tokens。” 这种做法几乎总是错误的。
向预训练模型添加新 token 意味着:
- 在 embedding 表中新增行,需从零初始化或通过对现有子词 embedding 取平均得到;
- 在 LM head 中新增行(若未绑定),同样为随机初始化;
- 模型必须通过微调学习如何使用这些新 token。
新 embedding 需要数量级更多的训练数据才能达到与原始 token 相当的水平。多篇论文(如 [Cui et al., 2023] Chinese-LLaMA、[Faysse et al., 2024] CroissantLLM)指出,要完全整合一个扩展后的词表,通常需要 500–2000 亿 tokens 的持续预训练。若训练数据不足,你得到的模型虽然能高效分词中文,但生成的中文质量反而会低于原始模型。
更务实的做法是:直接选用其分词器已在目标语言上充分训练的基础模型。例如,中文选 Qwen3,东南亚语言选 Sea-LION 或 Sailor,非洲语言选 BLOOM [Scao et al., 2022]。词表扩展应仅在没有合适基础模型时才考虑。
当词表扩展不可避免时(例如,需向基础模型添加领域特定的医学术语),以下实践有助于缓解问题:
将新 embedding 初始化为其子词分解的均值。 例如,对于新 token “tachycardia”,可将其 embedding 初始化为现有 BPE 片段(“tachy”、“card”、“ia”)对应 embedding 的均值。[Hewitt, 2021] 的研究表明,相比随机初始化,此方法在少量训练后可带来 3–5 个困惑度点的提升。
在 warmup 阶段冻结模型其余部分。 先仅训练新 embedding 数百步,再解冻整个模型。这能避免模型其他部分因补偿随机的新 embedding 而破坏已有知识。
对 embedding 层也应用 LoRA。 PEFT 支持在 embed_tokens 上使用 LoRA。结合 warmup 技巧,能在极低数据成本下获得词表扩展的大部分收益。
无分词器方案:ByT5、MEGABYTE、MAMBA-byte#
有两个值得关注的新方向,但目前尚未成为主流。
ByT5 [Xue et al., 2022] 直接在 UTF-8 字节上训练 T5 模型,完全摒弃了分词器。其词表仅为 256(字节)加 3 个特殊 token。ByT5-large 在多语言基准上能媲美 mT5-large,尽管其序列长度显著更长。代价在于序列长度:一段用 BPE 表示为 100 个 token 的中文段落,在 ByT5 中会变成 600 个字节。训练时每步更慢,但每字节的样本效率更高;推理时响应速度也更慢。ByT5 在多语言 NER 和噪声文本任务中找到了 niche,因为在这些场景中分词器不匹配往往是质量瓶颈。
MEGABYTE [Yu et al., 2023] 采用分层方式处理长字节序列:一个“patch”模型将字节分组为 8–16 字节的块,并对每个块运行小型 Transformer;随后一个“global” Transformer 在 patch 表示上进行建模。这使得计算复杂度近似为 patch 数量的 O(n²),而非单个字节的 O(n²),从而使字节级建模在长达百万字节的序列上变得可行。
MAMBA-byte [Wang et al., 2024] 将 Mamba 状态空间架构直接应用于字节流。其线性时间递推特性使得大规模字节级训练变得可行。据报道,MAMBA-byte 350M 在 ARC-Easy 和 PIQA 上能匹敌基于 BPE 的基线模型,但在需要精确词级推理的任务(如 MMLU、HumanEval)上表现下降。
展望 2026 年的生产环境:byte-level BPE 仍是默认选择。当前的研究热点集中在更优的合并算法(贪心 vs 边际似然)以及针对文档的动态词表选择。
Chat Template 是分词器的状态#

Chat template 是一个 Jinja 模板字符串,用于将消息列表转换为单一的可分词字符串。以 LLaMA-3 为例:
| |
其中四个高亮的 token,<|start_header_id|>、<|end_header_id|>、<|eot_id|>,以及 <|begin_of_text|>,都是 独立的特殊 token,每个都对应一个唯一的 ID。它们被定义在分词器的 added_tokens.json 中,也是模型在后训练阶段学会识别的对话轮次边界标记。
我见过两种典型的生产事故:
事故一:以纯字符串方式构建 prompt。 有人这样写:
| |
这看似能用,实则不然。模型在后训练阶段从未见过这种格式,虽然可能仍会生成内容,但其指令遵循和安全行为会严重退化,因为那些触发其训练行为的对话 token 根本不存在。务必始终使用 tokenizer.apply_chat_template(messages)。
事故二:对渲染后的模板使用 add_special_tokens=True 进行分词。 这会导致 BOS token 被重复添加。模型会看到 <|begin_of_text|><|begin_of_text|>,从而产生异常行为。正确做法是使用 tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True),它知道何时该添加特殊 token。
Chat template 也是 function calling 能够工作的基础。Qwen3 的 chat template 在 JSON 工具调用周围使用了 <tool_call>...</tool_call> 标签,模型也经过相应训练。Mistral 则使用 [TOOL_CALLS]。OpenAI 的格式则完全不依赖特殊 token,而是通过消息载荷中的 JSON 实现。第七章将全面讲解 function calling。
常见陷阱#
以下五个分词陷阱是我个人耗费最多时间调试的:
1. 训练与推理阶段混用分词器。 训练时用 HuggingFace 的 tokenizer.json,推理时为了“提速”改用 tiktoken。即使 BPE 合并规则相同,特殊 token 的处理方式也可能存在细微差异。结果往往是:模型输出的特殊 token 在推理层未被正确剥离,或推理层请求了模型从未见过的 token。务必在训练和推理阶段使用 完全相同 的分词器文件。
2. 输入端的空白符标准化。 多个分词器(尤其是基于 SentencePiece 的)会将前导空格替换为 ▁(U+2581)。如果你执行 tokenizer.decode(tokenizer.encode(s)),结果中的空格数量会因分词器变体而异。这在链式 pipeline 中尤为致命:将“模型 A 的输出摘要”传给模型 B 时,空白符的偏移可能导致质量下降。
3. 将 token 误认为字符。 一个常见错误是:设置 max_tokens=200 以为表示“200 个字符”。实际上,在 Qwen3 上处理中文时,200 个 token 约等于 200–260 个字符;处理英文时,则约等于 800–1200 个字符。长度预算必须基于模型的 token 来规划,而非字符或字节数。
4. 在特殊 token 内部截断。 将一个 10 万 token 的 prompt 截断至 32K 时,如果截断逻辑基于字节操作,可能会将 </s> 这样的特殊 token 从中切断。模型会看到一个损坏的特殊 token,要么忽略它,要么生成无意义内容。务必在 token 边界处截断,绝不能在已分词流的字节或字符内部截断。
5. 停止 token 不匹配。 OpenAI 兼容 API 接受 stop=["</s>"],但 </s> 在模型词表中未必是单个 token。如果它被 BPE 拆分为多个 token,停止字符串检测就必须在每步生成后扫描解码后的文本,这不仅速度慢,在流式传输边界还容易出现竞态条件。现代服务框架(如 vLLM、SGLang)通过 EOS token ID 匹配结合滚动字符串检测来处理此问题,但自研服务器常在此处出错。
生产现实:分词器在服务栈中的角色#
服务框架将分词器视为每个请求的第一站和最后一站。其热路径如下:
- 接收请求 → 对 prompt 分词 → 将 token ID 推送至调度器
- 生成下一个 token ID
- 反分词为文本 → 流式返回给客户端
三个生产约束塑造了其实现:
分词吞吐量: vLLM 和 SGLang 使用 Rust 编写的分词器(HuggingFace 的 tokenizers 库),相比 Python 的 transformers AutoTokenizer 有约 10 倍的速度提升。在 1000 RPS、500-token prompts 的负载下,Python 分词可能占满一个 CPU 核心,而 Rust 实现仅需其一小部分资源。
流式反分词: 逐个生成 token 并立即反分词需要缓冲,因为 BPE token 可能是不完整的 UTF-8 序列(尤其在 CJK 场景下)。vLLM 的反分词器会缓存最近的 tokens,尝试解码,并只输出到最后一个完整 UTF-8 边界为止的文本。这会给流式输出增加 1–2 个 token 的延迟。
分词器缓存: 许多服务系统会对不变的系统 prompt 进行分词结果缓存。Anthropic 的 prompt caching 功能部分基于此,每个请求的前约 1000 个 tokens 会被预分词并在具有相同前缀的请求间复用。结合 KV-cache 前缀共享,这能将聊天应用在长系统 prompt 下的首 token 延迟降低 50–70%。
字符级和视觉 Tokenizers 怎么样?#
最近有两个技术动向值得了解,不过都还没成为主流。
纯字符级/字节级方案:代表工作是 ByT5、MEGABYTE、MAMBA-byte。干脆跳过 BPE 合并步骤,直接在原始字节上训练。好处是简单,没有分词 bug,也没有中文词汇膨胀的问题。代价是序列长度:一段中文如果用 BPE 是 100 个 token,变成字节就是 600 个。就算用了亚二次方注意力的优化,成本依然很高。MEGABYTE [Yu et al., 2023] 的做法是分层处理字节块。很有前景,但在通用规模上还没法跟主流方案竞争。
视觉 Tokenizers:把文本渲染成图片,再用视觉方式分词。代表工作是 Donut [Kim et al., 2022] 和 PIX2STRUCT [Lee et al., 2023]。主打的是统一文本 - 视觉建模,让你不用再纠结选哪种分词器。目前还不适合通用 LLM 负载,但在 OCR 密集的场景里很有意思。
展望 2026 年的生产环境:byte-level BPE 依然是默认选项。真正有趣的工作集中在更好的合并算法(greedy 还是 marginal-likelihood)以及针对文档的动态词表选择。
2024-2026 研究前沿#
在 byte-level BPE 成为共识之后,接下来会发生什么:
学习型分词(Learned tokenization)。 [Yu et al., 2024] (SpaceByte) 展示了可以把分词器和语言模型一起端到端训练,让模型自己决定子词单元。效果能匹配 BPE,而且不需要手写正则规则。虽然还没上线生产,但已经对 BPE 构成了 credible threat。
动态词表(Dynamic vocabularies)。 针对文档的词表适配,比如分词器知道自己在处理 Python 代码,就切换到针对代码优化的合并表。早期的工作([Provilkov et al., 2020] BPE-dropout, [Kudo, 2018] subword regularization)探索了训练时的随机分词;2024-2025 这一波则在探索推理时的确定性但上下文感知的分词。
多模态 Tokenizers (Multimodal tokenizers)。 处理文本、图像、音频和视频的模型需要统一分词方案。目前的主流做法(LLaVA, Qwen-VL, Gemini)是用独立的视觉 encoder 处理图像,然后把 vision tokens 插入文本流。下一代会不会转向所有模态统一的分词器还是个未知数。[Team, 2024] (Chameleon) 展示了早期融合的全模态分词是可行的。
核心建议与后续#
分词这东西,平时无感,一出问题就要命:选错分词器,中文负载成本直接翻倍;跳过 chat template,指令遵循能力下降;盲目扩展词表,微调后的模型反而不如基座。所以在选模型前,务必用你的实际 prompt 测一下 token 数量。一定要通过 apply_chat_template 使用模型官方的 chat template。除非你有几千亿的训练 token 可以挥霍,否则别随便扩展词表。
下一章:大规模预训练(pretraining at scale)。数据混合、去重、那个安静的 200B token 悬崖(大多数开放数据集到这里就不再有提升了)、FSDP 对比 ZeRO-3,以及当你把 LLaMA 风格的训练任务从 8 张卡扩展到 8000 张卡时,到底会出什么乱子。
参考文献#
- Schuster, M., & Nakajima, K. (2012). Japanese and Korean voice search. ICASSP.
- Wu, Y., Schuster, M., Chen, Z., et al. (2016). Google’s neural machine translation system. arXiv:1609.08144 .
- Sennrich, R., Haddow, B., & Birch, A. (2016). Neural machine translation of rare words with subword units. ACL.
- Kudo, T. (2018). Subword regularization: Improving neural network translation models with multiple subword candidates. ACL.
- Kudo, T., & Richardson, J. (2018). SentencePiece: A simple and language independent subword tokenizer and detokenizer. EMNLP demo.
- Radford, A., Wu, J., Child, R., et al. (2019). Language models are unsupervised multitask learners (GPT-2). OpenAI.
- Provilkov, I., Emelianenko, D., & Voita, E. (2020). BPE-Dropout: Simple and effective subword regularization. ACL.
- Hewitt, J. (2021). Initializing new word embeddings for pretrained language models. blog post.
- Bavarian, M., Jun, H., Tezak, N., et al. (2022). Efficient training of language models to fill in the middle (FIM). arXiv:2207.14255 .
- Xue, L., Barua, A., Constant, N., et al. (2022). ByT5: Towards a token-free future with pre-trained byte-to-byte models. TACL.
- Kim, G., Hong, T., Yim, M., et al. (2022). OCR-free document understanding Transformer (Donut). ECCV.
- Scao, T., Fan, A., Akiki, C., et al. (2022). BLOOM: A 176B-parameter open-access multilingual language model. arXiv:2211.05100 .
- Cui, Y., Yang, Z., & Yao, X. (2023). Efficient and effective text encoding for Chinese LLaMA and Alpaca. arXiv:2304.08177 .
- Li, R., Allal, L., Zi, Y., et al. (2023). StarCoder: May the source be with you. arXiv:2305.06161 .
- Lee, K., Joshi, M., Turc, I., et al. (2023). Pix2Struct: Screenshot parsing as pretraining for visual language understanding. ICML.
- Yu, L., Simig, D., Flaherty, C., et al. (2023). MEGABYTE: Predicting million-byte sequences with multiscale Transformers. NeurIPS.
- Faysse, M., Fernandes, P., Guerreiro, N., et al. (2024). CroissantLLM: A truly bilingual French-English language model. arXiv:2402.00786 .
- Tao, C., Liu, Q., Dou, L., et al. (2024). Scaling laws with vocabulary: Larger models deserve larger vocabularies. NeurIPS.
- Wang, J., Gangavarapu, T., Yan, J., & Sabuncu, M. (2024). MambaByte: Token-free selective state space model. COLM.
- Yu, L., Simig, D., Wang, X., et al. (2024). SpaceByte: Towards deleting tokenization from large language modeling. NeurIPS.
- Team, Chameleon. (2024). Chameleon: Mixed-modal early-fusion foundation models. arXiv:2405.09818 .
- Dubey, A., Jauhri, A., Pandey, A., et al. (2024). The Llama 3 herd of models. arXiv:2407.21783 .
大模型工程 12 篇
- 01 大模型工程(一):Transformer 到 MoE
- 02 大模型工程(二):Tokenization 深度解析 当前
- 03 大模型工程(三):预训练的规模之道
- 04 大模型工程(四):SFT、DPO 与 RLHF
- 05 大模型工程(五):推理优化核心技法
- 06 大模型工程(六):长上下文与 RoPE、YaRN
- 07 大模型工程(七):Function Calling 实战
- 08 大模型工程(八):RAG 架构与落地
- 09 大模型工程(九):生产级 Prompt 工程
- 10 大模型工程(十):LLM-as-Judge 与评估
- 11 大模型工程(十一):安全与 Alignment
- 12 大模型工程(十二):生产落地与监控


