
大模型工程(四):SFT、DPO 与 RLHF
SFT、DPO、RLHF、RLAIF 各自具体在优化什么,奖励模型在哪里失败,KL 约束的作用,LoRA vs 全量微调那场争论,以及 2026 年生产里实际跑的 post-training 配方。
预训练得到的基座模型只能续写文本,而听懂指令、拒绝有害请求、维持人设等能力,则属于后训练阶段的任务。这里也正是论文宣称的效果与真正生产级模型之间差距最大的地方。本章将深入探讨各类后训练算法究竟在优化什么、为什么大多数奖励模型其实存在隐性缺陷,以及到 2026 年真正行之有效的实践方法。

四阶段技术栈#

现代 LLM 的后训练流程大致可分为四个阶段:
- SFT(监督微调,Supervised Fine-Tuning):在指令数据上训练,教会模型响应格式和基本的指令遵循能力。
- 偏好优化(DPO、IPO、KTO 或 RLHF):教会模型在两个合法回复中,人类(或其代理)更偏好哪一个。
- 在线强化学习(RLHF、RLAIF 或 RLVR —— 即使用可验证奖励的 RL):针对奖励模型或程序化检查器进行更激进的调优。对于非推理类模型,这一步通常是可选的,且在实践中越来越常被跳过。
- 专项阶段:包括工具调用 SFT、长上下文 SFT、安全红队测试、宪法 AI 过滤等。
目前,OpenAI、Anthropic 和 Google 仍普遍采用接近 “SFT → 偏好 DPO → RLHF/RLAIF” 的流程。而 DeepSeek-R1 [DeepSeek-AI, 2025] 与 o1 系列模型则引入了 RLVR(Reinforcement Learning with Verifiable Rewards,即使用可验证奖励的强化学习),将其作为主导信号,适用于数学、代码等可通过程序自动判断正确性的任务。这是 2024–2025 年后训练领域最重要的变革。
这一技术脉络有清晰的传承关系。最早提出可信“基于人类反馈的强化学习”(RL from Human Feedback)的是 [Christiano et al., 2017],他们将偏好学习应用于 Atari 游戏和连续控制任务。[Stiennon et al., 2020] 首次将其用于文本摘要。而 [Ouyang et al., 2022](即 InstructGPT)则是首个通过 SFT + RLHF 实现端到端指令微调的大语言模型,当今所有后训练技术栈几乎都源于此工作。2023–2025 年涌现的 DPO、IPO、KTO、RLVR 等方法,本质上都是对 InstructGPT 范式的不同变体。
SFT:比人们想象中更重要#
SFT 的核心做法是:向模型提供 10 万至 100 万条指令-回复对,并仅对回复部分计算 next-token prediction loss。这里的掩码很关键:模型不该去预测用户的问题,只学习如何生成助手的回答。
| |
SFT 的成败主要取决于两点:
数据质量远胜于数量: LIMA [Zhou et al., 2023] 的研究表明,1000 条精心筛选的样本就能媲美 5 万条普通数据。Tulu-3 混合数据集 [Lambert et al., 2024](AllenAI, 2024)经过严格筛选,仅保留约 20 万条样本。Qwen3 的 SFT 数据虽接近 100 万条,但也经过重度质量过滤。当数据质量足够高时,超过 10 万条后的收益会迅速趋于平缓。
格式必须高度一致: 如果一半 SFT 数据以 “Sure, I’ll help!” 开头,另一半没有,模型就会学到不一致的开场白使用习惯。如果训练数据大量使用 Markdown 标题,而实际推理时用户输入的是纯文本提示,输出就可能出现格式错配。因此,必须在预处理阶段强力标准化格式。
一个容易被忽视的失败模式是:若 SFT 数据中短回复占比过高,模型会变得不愿生成长文本。这是因为模型会从数据中学习回复长度的条件分布。如果你希望模型能写出 2000 字的文章,SFT 混合集中至少应包含 5%–10% 的长回复样本。我曾微调过一个 Qwen3-7B 模型,它始终无法生成超过 800 个 token 的输出,原因正是其 SFT 数据过度偏向问答形式,缺乏长文本示例。
SFT 数据来源与合成#
到 2026 年,生产环境中实际使用的 SFT 数据主要来自以下几类:
- 公开混合数据集:如 Tulu-3(AllenAI,93.9 万条)、OpenHermes-2.5(100 万条,混合 GPT-4 输出)、UltraChat(140 万条经筛选的 ChatGPT 对话 [Ding et al., 2023]),以及 Magpie [Xu et al., 2024](由已微调的聊天模型自我提示生成的合成指令)。
- 领域特定数据:从内部产品日志中脱敏提取(需用户授权并去除 PII)、由领域专家撰写(每条约 30–100 美元),或在特定领域种子提示上通过强教师模型蒸馏而来。
- 强教师模型合成:让 Claude 或 GPT-4 根据主题种子和少量示例生成(指令,回复)对。这已成为主流。2026 年绝大多数生产级 SFT 数据都是合成的。
其中,Magpie 技术 [Xu et al., 2024] 尤其值得关注。其核心技巧是:仅向已微调的聊天模型输入 <|im_start|>user ,让它自行生成用户消息,再由它(或另一模型)生成对应的回复。这种方式无需人工设计种子提示,即可产出格式规范的指令数据。研究者用该方法生成了 400 万条样本,经筛选后保留 20 万条,其质量已能媲美人工精心策划的数据集。2025–2026 年的大多数 SFT 流水线中,多少都融入了 Magpie 风格的合成策略。
还需区分“指令遵循 SFT”与“聊天 SFT”。早期数据集(如 Alpaca、Self-Instruct)多为单轮短指令配短回复;而现代数据(如 Tulu-3、源自 ShareGPT 的混合集)则包含多轮对话和长回复。仅用单轮指令训练的模型在多轮对话中容易失效(忽略历史轮次);而仅用多轮对话训练的模型又难以准确执行简单命令。因此,必须在数据混合中取得平衡。
DPO:无需奖励模型的偏好优化#


经典的 RLHF 流程(InstructGPT [Ouyang et al., 2022])包含两个步骤:先在人类偏好数据上训练一个奖励模型,再用 PPO 算法对该奖励模型进行策略优化。这种方法虽然有效,但实现复杂:需要单独训练奖励模型、添加价值头(value head)、计算 GAE、做优势归一化、设置 KL 惩罚项,且训练过程极不稳定。
$$\mathcal{L}_{\text{DPO}} = -\mathbb{E}\left[\log \sigma\left(\beta \log \frac{\pi_\theta(y_w | x)}{\pi_{\text{ref}}(y_w | x)} - \beta \log \frac{\pi_\theta(y_l | x)}{\pi_{\text{ref}}(y_l | x)}\right)\right]$$其中 $y_w$ 是被选中的回复,$y_l$ 是被拒绝的回复,$\pi_{\text{ref}}$ 是冻结的 SFT 模型(作为参考策略),$\beta$ 控制策略允许偏离参考策略的程度。整个过程无需奖励模型,也无需 PPO;每个偏好对只需一次前向传播和一次反向传播。
| |
DPO 在 2026 年成为主流,主要有两个原因:其一,效果确实好。HuggingFace alignment-handbook 报告称,DPO 在 AlpacaEval 上与 PPO 表现相当,且在单位质量成本上更具优势;其二,其训练循环仅需前向传播,能无缝集成到 FSDP/LoRA 等高效训练框架中。
但在实践中也会遇到几个关键问题:
- $\beta$ 的调参至关重要。 若 $\beta$ 过低(如 0.01),策略会过度漂移,导致基座模型能力退化;若过高(如 1.0),则几乎无法学习。大多数生产环境将 $\beta$ 设在 0.1 到 0.3 之间。
- 参考模型漂移问题: 如果连续进行两次 DPO,第二次的参考模型就变成了第一次 DPO 后的模型,原始 SFT 模型丢失。因此,务必保存好 SFT checkpoint,并在每次偏好优化时都以其作为参考。
- 偏好数据质量影响显著: 合成偏好(例如 “GPT-4 选择了 A 而非 B”)虽易于生成,但会引入教师模型的偏见。建议至少在 20% 的数据中混入真实人类偏好,以防止模型性能崩溃。
DPO 推导细节:从 Bradley-Terry 到闭式解#
DPO 损失并非凭空而来,而是通过三个严谨步骤推导得出。理解这一过程有助于把握 DPO 对偏好数据的假设,以及如何解读 $\beta$ 的含义。
$$P(y_w \succ y_l \mid x) = \sigma(r(x, y_w) - r(x, y_l))$$这是 [Bradley & Terry, 1952] 提出的配对比较模型,最初用于棋手评级,如今已成为将成对偏好转化为标量奖励的标准假设。
$$\max_\pi \mathbb{E}_{x, y \sim \pi}[r(x,y)] - \beta \, \text{KL}(\pi \| \pi_{\text{ref}})$$ $$\pi^*(y \mid x) = \frac{1}{Z(x)} \pi_{\text{ref}}(y \mid x) \exp\!\left(\frac{1}{\beta} r(x, y)\right)$$ $$r(x, y) = \beta \log \frac{\pi^*(y \mid x)}{\pi_{\text{ref}}(y \mid x)} + \beta \log Z(x)$$ $$P(y_w \succ y_l \mid x) = \sigma\!\left(\beta \log \frac{\pi^*(y_w | x)}{\pi_{\text{ref}}(y_w | x)} - \beta \log \frac{\pi^*(y_l | x)}{\pi_{\text{ref}}(y_l | x)}\right)$$在此模型下最大化观测偏好的对数似然,即可得到 DPO 损失。整个 RLHF 流程由此简化为对数概率比值上的二元交叉熵:无需奖励模型,无需采样,也无需 PPO。
至此,$\beta$ 的物理意义也清晰了:它是隐式奖励的“逆温度”。低 $\beta$ (如 0.01)意味着微小的奖励差异就能引发大幅策略调整,模型会激进地从每条偏好中学习;高 $\beta$ (如 1.0)则使策略几乎无法偏离参考模型,偏好几乎不起作用。经验表明,0.1–0.3 是最佳区间,此时隐式奖励足够提供有效信号,又不至于引发灾难性漂移。
DPO 变体:KTO、IPO、ORPO、SimPO#
2024–2025 年间,DPO 衍生出多个变体,各自针对特定痛点进行了改进:
KTO(Kahneman-Tversky Optimization) [Ethayarajh et al., 2024] 放弃成对偏好,转而使用绝对的“好/坏”标签。其损失函数不对称(借鉴 Kahneman-Tversky 价值函数:人类对损失更敏感,因此惩罚坏回复的权重高于奖励好回复)。当你拥有大量非成对反馈(如生产环境中的点赞/点踩)但缺乏成对比较时,KTO 就特别有用。实证表明,在有成对数据时,KTO 与 DPO 表现相当;仅有点赞数据时,KTO 反而更优。
IPO(Identity Preference Optimization) [Azar et al., 2023] 将 sigmoid 损失替换为 MSE 损失,以缓解 DPO 在噪声偏好上的过拟合问题。DPO 的 sigmoid 在策略高度自信时会饱和,导致“赢下”某对数据后损失几乎不再提供梯度;而 IPO 的 MSE 能持续提供有效梯度。实践中,IPO 更稳定但收敛较慢,适合处理噪声较大的众包偏好数据。
ORPO(Odds Ratio Preference Optimization) [Hong et al., 2024] 将 SFT 与偏好优化合并为单一损失函数:SFT_loss(y_w) + λ · log(odds(y_w) / odds(y_l))。这种单阶段训练无需单独进行 SFT,特别适合资源受限场景(例如用 LoRA 微调 7B 模型)。在更低算力下,其效果已能与 SFT+DPO 相抗衡。
SimPO(Simple Preference Optimization) [Meng et al., 2024] 则直接抛弃参考模型,损失函数简化为 $-\log \sigma(\beta (\bar{r}_w - \bar{r}_l) - \gamma)$ ,其中 $\bar{r}$ 是长度归一化的对数概率,$\gamma$ 为间隔项(margin)。省去参考模型可使显存占用减半、训练速度加快。尽管报告称其效果有竞争力,但对长度归一化和 margin 设置极为敏感,容易配置失误。
选择建议:若有成对人类偏好数据 → 选 DPO;只有点赞/点踩数据 → 选 KTO;偏好数据噪声大 → 选 IPO;需单阶段训练 → 选 ORPO;显存紧张 → 选 SimPO。总体而言,DPO 仍是稳妥的默认选项。
RLHF 和 PPO:为何仍有人使用#

尽管 DPO 已在通用后训练中占据主导地位,几家前沿实验室在最终阶段仍坚持使用基于 PPO 的 RLHF,原因有三:
- 对抗性案例处理更强: PPO 能持续惩罚训练过程中新发现的任何失败模式,而 DPO 只能学习已有偏好数据覆盖的情形。
- 支持奖励塑形(Reward Shaping)。 可额外加入辅助奖励信号(如长度惩罚、格式合规性、拒绝行为校准等),这些难以融入成对偏好框架。
- 支持迭代式 RL: Anthropic 的宪法 AI(Constitutional AI, CAI)[Bai et al., 2022] 在概念上就是一种迭代式 RLAIF:生成回复 → 批评 → 偏好排序 → 重训练。
RLHF 的最小 PPO 循环如下:
| |
其中 KL 散度项至关重要。若省略该项,PPO 会“攻击”奖励模型,生成高奖励但语义混乱、毫无连贯性的文本。Anthropic 的《Sleeper Agents》论文 [Hubinger et al., 2024] 就记录了多种有趣的奖励黑客行为,例如“总是以 ‘Yes I can help with that!’ 结尾”,因为奖励模型错误地将这类合规开头与高奖励关联起来。
RLHF 实际问题:奖励作弊、模式崩溃、长度偏差#
每个基于 PPO 的 RLHF 训练都会遭遇三大生产级失败模式:
奖励作弊(Reward Hacking) [Skalse et al., 2022]。奖励模型是对文本的拟合函数,必然存在盲区,而策略会精准找到这些漏洞。典型表现包括:总是使用道歉语气(因标注者将道歉与“有帮助”关联)、以 “Certainly!” 或 “Of course!” 开头(前缀偏见)、拒绝处理边缘请求(因标注者偏好安全回答),或在回复中堆砌免责声明。解决方法是迭代修复:通过人工评估发现作弊行为,构造对抗性提示暴露漏洞,用新数据重训奖励模型,再重训策略。Anthropic 的 CAI 正是显式自动化了这一循环。
模式崩溃(Mode Collapse)。策略变得高度确定性,所有回复听起来千篇一律。症状是训练过程中策略熵急剧下降(可达数个数量级)。根源在于 PPO 找到了某个高奖励输出并不断复用。修复手段包括:增大 KL 惩罚系数(如将 $\beta_{\text{kl}}$ 从 0.01 提升至 0.05)、在损失函数中加入熵奖励项、或采用多样化 rollout(对每个提示以高温度采样多个回复)。
长度偏差(Length Bias)。RLHF 策略系统性地生成比 SFT 策略更长的回复。这是因为人类标注者往往偏好稍长的回答(认为更详尽),奖励模型捕捉到这一倾向并加以放大。结果是:聊天模型的平均回复长度从 200 token 暴涨至 800 token,但实际质量并未提升。解决方案包括:在奖励中显式减去长度惩罚项,或在策略梯度中使用长度归一化的对数概率。[Singhal et al., 2024] 的研究详细量化了这一现象,指出约 1.5 分的 AlpacaEval 提升实际上应归因于长度增加,而非真正的能力进步。
宪法 AI:RLAIF 谱系#
Anthropic 的 Constitutional AI(CAI)[Bai et al., 2022] 是当前主流的 RLAIF(基于 AI 反馈的强化学习)方案,包含两个阶段:
第一阶段:监督式 CAI: 使用 SFT 模型对红队提示生成回复;再由批评模型(通常为同一模型配合不同提示)依据一组宪法原则(如“回复不得有害、非法或不道德”)进行批评;最后让模型根据批评修改回复,并在(提示,修订后回复)对上进行训练。由此得到的模型无需人类偏好数据即可与宪法对齐。
第二阶段:RLAIF: 对同一提示生成两个回复,由 AI 判断哪个更符合宪法;基于这些 AI 偏好训练奖励模型;最后用 PPO 对策略进行优化。
其巧妙之处在于:宪法本身可编辑并重新应用,无需重新收集人类数据。这比传统 RLHF 成本低得多,也支持对宪法内容本身的快速迭代。但缺点是模型会继承 AI 评判者的偏见:若评判者存在盲点,策略也会照单全收。
2024–2026 年,CAI 的演进方向是 基于规则的奖励(Rule-Based Rewards, RBR) [Mu et al., 2024](OpenAI 提出)。不再使用学习得到的奖励模型,而是编写一组显式规则(如“回复不超过 200 词”、“不得包含医疗建议”、“应引用来源”),并让 LLM 对合规性进行评分。这种方法比黑盒奖励模型更易调试、更易更新,可作为学习型奖励的有效补充。
RLVR:可验证奖励的强化学习#
DeepSeek-R1 [DeepSeek-AI, 2025](2025 年 1 月发布)的推理能力几乎完全来自 RLVR:在数学问题上训练,奖励信号直接来自“最终答案是否匹配标准答案?”,由程序自动验证,而非学习得到的模型。没有奖励模型,也就没有奖励作弊。
这种方法之所以可行,是因为数学和代码存在客观的 ground truth。模型生成长链式思维(Chain-of-Thought),最后提取答案,再由检查器(如 Python 解释器、SymPy、单元测试)判断对错:正确得 +1 分,错误得 0 或 -1 分。在此基础上运行 PPO 或 GRPO。
$$A_i = \frac{r_i - \text{mean}(r_1, ..., r_G)}{\text{std}(r_1, ..., r_G)}$$相比 PPO,GRPO 更简洁,特别适合可验证奖励场景。
DeepSeek-R1 的训练方案值得详述,因为它代表了 2025–2026 年推理模型的主流范式:
- Cold-start SFT:使用少量(约 1 万条)高质量 CoT 格式示例,教会模型基本回答结构。
- R1-Zero 纯 RL 阶段:在海量数学/代码问题上纯用 RLVR + GRPO。无 SFT 数据,无奖励模型,仅有可验证奖励。R1-Zero 由此涌现,展现出惊人能力,但输出常不可读(混杂多语言、出现奇怪 token)。
- 拒绝采样 SFT:用 R1-Zero 生成回复,仅保留正确且格式规范的样本,在此过滤集上训练新模型。
- 最终 RL 阶段:继续使用 GRPO,混合可验证奖励与少量通用行为奖励模型。
R1-Zero 最令人震撼之处在于,它在无人教导的情况下自发发现了链式思维推理。纯可验证奖励的强化学习教会了模型:一步步思考是有回报的。这是首个广泛公开的基础 LLM 通过纯 RL 涌现出推理行为的实例。
当前前沿模型(如 Qwen3-Reasoning、GPT-5-thinking、Claude-4.5-thinking、Gemini-3-Thinking)均采用 RLVR 式训练作为推理能力的核心驱动力:基座模型做 SFT,通用行为用 DPO,再专门针对数学/代码/逻辑任务高强度刷 RLVR 以获得推理能力。这也解释了为何“thinking”系列模型在数学和代码上显著更强,但在普通对话中提升有限。
DPO、PPO 与 GRPO:怎么选后训练优化器#
上面这三个优化器并不能互相替换,而这个选择恰恰是对一次后训练的成本与行为影响最大的单一决策。把它们分清楚最干净的两条轴是:离线还是在线、有没有 critic。
DPO 是离线的、监督式的。 它在固定偏好集上训练,只需两次前向(策略和冻结的参考模型),无 rollout、无奖励模型。算力约等于再做一次 SFT,外加参考模型前向的 30%–50%。它的软肋在于:DPO 把一整条补全打上同一个偏好标签,所以一条总体不错的回答里若藏着一步糟糕的推理,整条仍被当成统一的 “chosen”。偏好集里没有的东西它也学不到。它适合单轮的有用性、风格、语气和安全,也就是生产对齐里的大头。
PPO 是在线的、带 critic 的。 它采样新鲜补全,用学习型奖励模型打分,再借助价值网络通过 GAE 算逐 token 优势。这种逐 token 的信用分配才是它真正的长处:当正确性取决于长序列里某一具体步骤时,PPO 能精确奖励那一步。代价在工程上:显存里要装四个模型(策略、参考、奖励、critic),且超参出了名地敏感。
GRPO 是在线的、不带 critic 的。 它保留 PPO 的新鲜 rollout,但删掉价值网络,用每个 prompt 下 $G$ 条采样补全的组均值充当基线。这省下了 PPO 花在 critic 上的那一半显存,也少了一个要调的网络,代价是把 rollout 生成量乘上了组规模($G=8$ 到 $16$ )。GRPO 在可验证奖励上最出彩,比如数学、代码、结构化输出,这些场景里程序化检查器能给出干净的标量。它不是 DPO 的替代品:没有标量奖励函数,组内相对归一化就无从归一。
由此得出的 2026 年默认配方是:通用行为用 DPO,因为工程便宜、基准也有竞争力;推理能力用 GRPO-on-RLVR,因为可验证奖励配上免 critic 的优化器,是通往链式思维最省的路;PPO 则留给那种你手里有高质量奖励模型、想把它留在回路中、且确实需要逐 token 信用分配的场合。多数开源指令模型交付的是 DPO 版本,推理变体则在其上叠一层 GRPO。
LoRA 对比全量微调:实证证据#

这场争论似乎永无止境。到 2026 年,实际情况是这样的:
- 针对窄任务的 SFT(如风格迁移、单一领域):LoRA 更胜一筹。效果相当,但显存占用仅为全量微调的十分之一,训练更快,且便于合并或切换。大多数任务使用 rank 16–64 即可满足需求。
- 若需从根本上扩展模型能力(如支持长上下文、新增语言):必须采用全量微调。LoRA 无法对模型的基础表示进行足够深入的调整。
- DPO 场景:LoRA 表现良好。因为 DPO 本身并不需要对模型做剧烈改动。
- RL(PPO/GRPO):前沿实验室普遍默认使用全量微调。尽管 2025 年的一些研究(如 LoRA-RL)表明,经过精细调参后 LoRA 可以媲美 PPO,但其训练过程较为脆弱,稳定性不足。
最初的 LoRA 论文 [Hu et al., 2021] 就已证明:在 GPT-3 175B 上使用 rank-8 的适配器,在 GLUE 基准上的表现与全量微调相差不到 0.5%,而可训练参数仅占 0.01%。其核心直觉是:微调所产生的权重更新本质上是低秩的;为每个权重矩阵叠加一个 rank-$r$ 的低秩矩阵,就能捕捉到大部分有效变化。
关于 LoRA 局限性的实证证据主要来自 2024 年的几项研究:
- [Biderman et al., 2024](LoRA Learns Less and Forgets Less)指出,LoRA 比全量微调更能保留基座模型的原始能力(即灾难性遗忘更少),但学习新任务的速度较慢。对于与预训练分布差异较大的任务(例如用通用基座模型进行医疗推理),LoRA 在任务专用评估上通常落后全量微调 5–10%。
- [Liu et al., 2024](DoRA)将 LoRA 的更新分解为“幅度”和“方向”两个分量,并证明分别优化这两个部分,能在相同 rank 下稳定超越标准 LoRA。
- [Hayou et al., 2024](LoRA+)发现,若为 B 矩阵设置比 A 矩阵高得多的学习率(通常高出 16 倍),能持续优于 vanilla LoRA。
当前的最佳实践是三者结合:DoRA + LoRA+ + 对所有线性投影层应用 LoRA,而不仅限于 QKV。
使用 PEFT 快速配置 LoRA:
| |
两个关键实战建议:
- 应对所有线性投影层应用 LoRA,而不仅是 QKV。原始 LoRA 论文仅针对 QKV 投影;但后续工作(如 QLoRA [Dettmers et al., 2023] 和 LongLoRA)表明,对 MLP 层也应用 LoRA 对最终质量至关重要。
- DoRA(weight-Decomposed LoRA) 在相同 rank 下始终优于标准 LoRA,且几乎不增加额外计算开销。只要你的训练框架支持,就应优先使用。
QLoRA [Dettmers et al., 2023] 值得单独强调。它将 LoRA 与基座模型的 4-bit 量化相结合:冻结的基座权重以 NF4(4-bit normalized float)格式存储,计算则在 BF16 精度下进行。这样一来,一个 70B 模型仅需 48 GB 显存(而非 140 GB),单张 80 GB 的 H100 即可完成训练。在大多数任务上,其性能与全量 BF16 微调相差不到 0.5%。到 2026 年,QLoRA 已成为在消费级硬件或单 GPU 环境下微调前沿大模型的标准方案。
实战案例:32B 基座模型的生产级后训练#
下面我详细拆解一套真实可行的方案:一个生产团队如何从 Qwen3-32B-Base 出发,交付一个指令微调后的 32B 模型。
SFT 阶段(8 张 H100,约 3 天)
- 数据:20 万条混合样本,包括 6 万条 Tulu-3 通用指令、8 万条基于 Claude 生成的 Magpie 风格合成数据、3 万条领域专属语料,以及 3 万条长文本回复(平均 5K tokens)。
- 配方:全量微调,BF16 精度,FSDP 并行,学习率 5e-6(低于预训练阶段,以避免灾难性遗忘),余弦退火调度,训练 3 个 epoch,batch size 为 1M tokens。
- 损失函数:标准交叉熵(CE),并对用户输入部分进行掩码(response masking)。
- 评估指标:AlpacaEval、MT-Bench、IFEval,以及自定义的领域评估集。
DPO 阶段(8 张 H100,约 1 天)
- 数据:3 万组偏好对,包含 1.5 万条 UltraFeedback、5 千条 Anthropic HH,以及 1 万条合成数据(由 Claude 在高温度下对模型自身不同输出进行评判生成)。
- 配方:LoRA(rank=64,节省显存和时间,因 DPO 不需大幅改动模型),β=0.1,学习率 5e-7,训练 1.5 个 epoch。
- 评估:Arena-Hard、MT-Bench,以及与纯 SFT 模型的成对人工/AI 评判对比。
可选安全强化阶段(8 张 H100,约 6 小时)
- 数据:3 千组拒绝偏好,针对精心策划的红队攻击提示集。
- 配方:在 DPO 模型基础上继续 DPO 训练,β 提高至 0.3(施加更强约束),训练 1 个 epoch。
可选推理能力 RLVR 阶段(32 张 H100,约 2 天完成 1K GRPO 步骤)
- 数据:5 千道数学题 + 3 千道编程题,均具备可程序化验证的答案。
- 配方:GRPO 算法,每条 prompt 生成 $G=8$ 条响应,KL 散度惩罚系数 β=0.04,最大序列长度 8K。
总计成本:租用 H100 集群约花费 1 万美元即可获得一个完整后训练的模型。该成本大致随模型规模线性增长:70B 模型约为 2.5 倍,7B 则约为 0.3 倍。
常见陷阱#
在生产环境中,以下五个问题最为常见:
1. 参考模型未真正冻结。这是一个隐蔽的 DPO bug:若将 ref_model 和 policy_model 设为同一个 Python 对象,梯度更新会同时影响两者。结果,“参考”log-probs 在每一步都发生变化,导致损失函数失去意义,训练过程悄无声息地产生一个更差的模型。正确做法是在计算参考 log-probs 时调用 model.eval() 并包裹 with torch.no_grad():,或直接加载一个独立的冻结模型。
2. SFT 损失未进行掩码。若在 [user_msg, assistant_msg] 序列上训练时未掩码用户消息部分,模型会学会预测用户输入,从而损害其对话能力。务必对非助手回复部分进行掩码。
3. SFT 与 DPO 数据的聊天模板不一致。例如,SFT 数据使用 <|im_start|>...<|im_end|> 格式,而 DPO 数据却是纯文本。这会导致 DPO 阶段训练模型偏好不含聊天标记的文本,进而破坏实际聊天行为。所有后训练阶段必须统一使用相同的聊天模板。
4. 合成偏好数据仅依赖单一裁判模型。若所有偏好均由同一个强模型(如 Claude)生成,训练出的模型会继承其特定偏见,比如冗长回复、固定话术或特定拒绝模式。建议至少混合三个不同裁判(如 Claude、GPT-4 和一个强开源模型),并根据裁判间的一致性进行加权。
5. 评估集污染。从网络爬取的 SFT 数据常包含 MMLU 等评测题。模型“死记硬背”这些题目后,评估分数虚高,但实际部署效果并无提升。务必在训练前对 SFT 数据进行去污染处理(例如通过 13-gram 与评测集比对)。LIMA 论文曾指出,约 30% 的常用 SFT 混合数据集存在显著的 MMLU 污染。
生产现实:前沿实验室到底在交付什么#
公开文献中描述的后训练流程通常是“SFT → DPO →(可能)RL”,但前沿实验室的实际做法要复杂得多:
SFT-DPO 迭代循环。Anthropic 的 CAI 方法就是迭代式的;OpenAI 的后训练同样包含多个 SFT-DPO 周期,并在周期之间生成新的合成数据。第一轮后得到的更强模型能产出更高质量的偏好数据,从而推动第二轮改进,如此循环往复。前沿模型通常经历 4–6 轮此类迭代。
融合多个专用专家模型。前沿后训练常会分别训练若干专用变体(如代码专家、安全专家、指令遵循专家、对话风格专家),再通过权重平均或插值进行融合。[Wortsman et al., 2022](ModelSoup)证明,对微调后的权重取平均,所得模型性能优于任一单独微调版本。另一种变体是并行训练多个 LoRA 适配器,推理时动态合并。
持续后训练。生产模型绝非“训练一次,永久部署”。Anthropic、OpenAI 和 DeepMind 均基于生产遥测数据进行持续后训练:用户点赞/点踩信号用于更新奖励模型,高质量交互样本被加入 SFT 数据池,模型每周或每月重新训练。你今天使用的 “Claude 4.5” 实际上是自初始发布以来历经数十次后训练迭代的产物。
深度集成红队测试。到 2026 年,后训练已无法与安全对齐割裂。红队不断生成新型对抗性提示,模型被训练以拒绝这些攻击,红队再据此设计更难的攻击,形成闭环。Anthropic 会在模型卡中披露部分细节,而 OpenAI 和 Google 则大多内部保密。最终产出的模型在保持通用帮助性的同时,对特定攻击模式展现出越来越强的抵抗力。
指令微调模型的生产级配方#
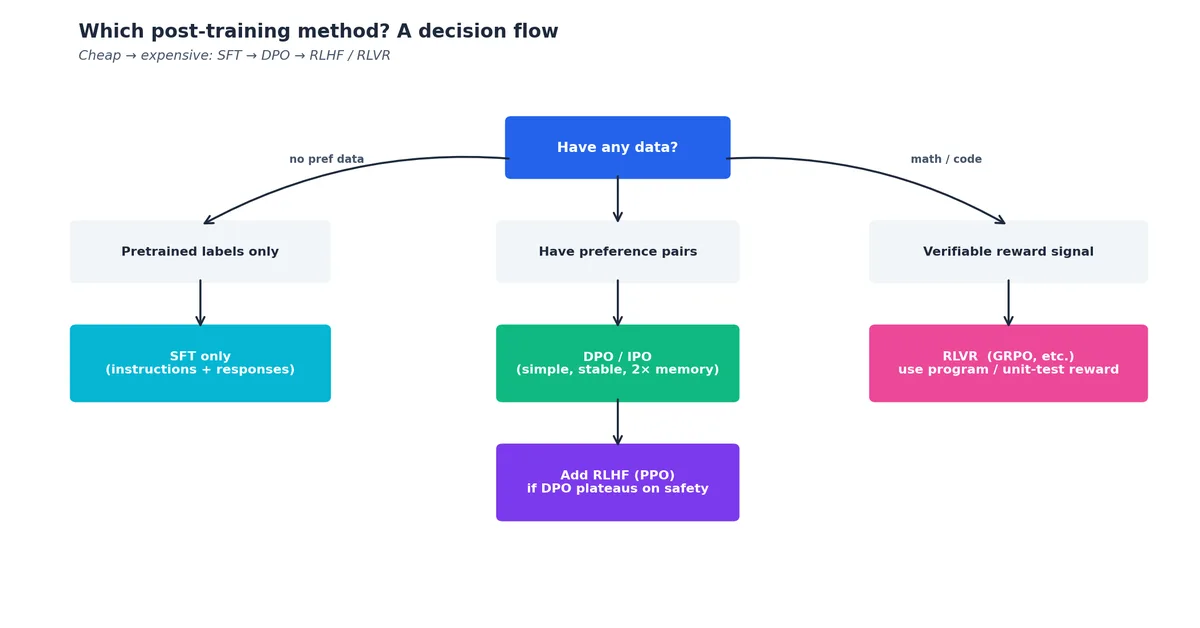
如果我在 2026 年要交付一个模型,会采用如下配方:
- 选择最强的开源基座模型(如 Qwen3-32B-Base、LLaMA-3.3-70B-Base 或 DeepSeek-V3-Base,视预算而定)。
- SFT 阶段:使用 5–20 万条精心筛选的样本,混合通用指令(Tulu-3、OpenHermes)、领域专属数据及数千条长文本示例。若预算充足则全量微调;否则采用 LoRA(rank=64)。
- DPO 阶段:使用 1–5 万组偏好对,混合 Anthropic HH、UltraFeedback 及部分由强裁判模型生成的合成偏好。设置 β=0.1,训练 1–2 个 epoch。
- 可选安全强化:收集 1–5 千组针对红队提示的拒绝偏好,再进行一轮 DPO,β 提高至 0.3 以增强拒绝能力。
- 可选推理能力强化:若数学或代码能力至关重要,则在数千道可验证问题上运行 RLVR(使用 GRPO),训练 1–2K 步。
这套方案足以让模型达到生产级助理的基本水准。后续工作则聚焦于评估(第十章)与部署优化(第五、十二章)。
2024–2026 研究前沿#
在当前 “SFT → DPO → RLVR” 共识之后,以下几个方向值得关注:
Online DPO [Guo et al., 2024]。传统 DPO 依赖固定离线偏好数据集,而 Online DPO 持续采样新回复,由人类或 AI 进行排序后立即用于训练。这种方法结合了 DPO 的稳定性与 PPO 的适应性。多篇 2025 年论文报告,Online DPO 能以更低算力在标准基准上媲美甚至超越 PPO。
用于推理的过程奖励模型(PRM)。不再仅奖励最终答案,而是对推理链中每一步的正确性给予奖励。[Lightman et al., 2023] 证明 PRM 在数学任务上优于仅依赖结果的奖励模型。主要挑战在于获取步骤级标注;近期研究转而使用 LLM 作为裁判对每一步进行打分。
自博弈与自我批评。SPIN [Chen et al., 2024](Self-Play Fine-Tuning)通过迭代训练,使模型偏好自身生成的优质回复而非劣质回复,全程无需外部偏好数据。效果出人意料地好,通常在 3–4 轮内即可达到性能平台期。
长度控制训练。2024–2025 年的多项研究通过长度归一化奖励或策略 log-probs,显式缓解长度偏差问题。[Singhal et al., 2024] 表明,此举能消除大部分看似来自 RLHF 的收益(实则源于回复变长),从而揭示出更小但更真实的质量提升。
测试时后训练。[Akyürek et al., 2024] 等人提出,可在推理阶段基于少量样本进行即时微调(类似 in-context learning,但涉及权重更新)。对于高风险应用场景,“先用用户前 10 个示例进行后训练,再生成回复”正逐渐成为一种可行范式。
总结#
SFT 的重要性常被低估,其效果对数据质量的敏感度远高于数据量。DPO 已取代 PPO 成为大多数偏好学习任务的首选,但当你需要持续适应新出现的失败模式时,PPO 仍是更合适的工具。RLVR(基于可验证奖励的强化学习) 是 2024 年后推理能力突破的关键。在生产场景中,LoRA 在多数微调任务中占据优势;但在前沿实验室的后 DPO 强化学习阶段,全量微调仍是主流。
下一章讲推理优化:KV cache 机制、paged attention、continuous batching、speculative decoding、量化技术(INT8/INT4/AWQ/GPTQ),以及 vLLM、SGLang 与 TensorRT-LLM 的选型对比。
参考文献#
- Bradley, R., & Terry, M. (1952). Rank analysis of incomplete block designs: I. The method of paired comparisons. Biometrika.
- Christiano, P., Leike, J., Brown, T., et al. (2017). Deep reinforcement learning from human preferences. NeurIPS.
- Stiennon, N., Ouyang, L., Wu, J., et al. (2020). Learning to summarize from human feedback. NeurIPS.
- Hu, E., Shen, Y., Wallis, P., et al. (2021). LoRA: Low-rank adaptation of large language models. arXiv:2106.09685 .
- Bai, Y., Kadavath, S., Kundu, S., et al. (2022). Constitutional AI: Harmlessness from AI feedback. arXiv:2212.08073 .
- Wortsman, M., Ilharco, G., Gadre, S., et al. (2022). Model soups: Averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. ICML.
- Skalse, J., Howe, N., Krasheninnikov, D., & Krueger, D. (2022). Defining and characterizing reward hacking. NeurIPS.
- Ouyang, L., Wu, J., Jiang, X., et al. (2022). Training language models to follow instructions with human feedback (InstructGPT). NeurIPS.
- Rafailov, R., Sharma, A., Mitchell, E., et al. (2023). Direct preference optimization: Your language model is secretly a reward model. NeurIPS.
- Zhou, C., Liu, P., Xu, P., et al. (2023). LIMA: Less is more for alignment. NeurIPS.
- Dettmers, T., Pagnoni, A., Holtzman, A., & Zettlemoyer, L. (2023). QLoRA: Efficient finetuning of quantized LLMs. NeurIPS.
- Ding, N., Chen, Y., Xu, B., et al. (2023). Enhancing chat language models by scaling high-quality instructional conversations (UltraChat). EMNLP.
- Azar, M., Rowland, M., Piot, B., et al. (2023). A general theoretical paradigm to understand learning from human preferences (IPO). AISTATS 2024.
- Lightman, H., Kosaraju, V., Burda, Y., et al. (2023). Let’s verify step by step. ICLR 2024.
- Hubinger, E., Denison, C., Mu, J., et al. (2024). Sleeper agents: Training deceptive LLMs that persist through safety training. arXiv:2401.05566 .
- Ethayarajh, K., Xu, W., Muennighoff, N., et al. (2024). KTO: Model alignment as prospect theoretic optimization. ICML.
- Hong, J., Lee, N., & Thorne, J. (2024). ORPO: Monolithic preference optimization without reference model. EMNLP.
- Meng, Y., Xia, M., & Chen, D. (2024). SimPO: Simple preference optimization with a reference-free reward. NeurIPS.
- Lambert, N., Morrison, J., Pyatkin, V., et al. (2024). Tulu 3: Pushing frontiers in open language model post-training. arXiv:2411.15124 .
- Xu, Z., Jiang, F., Niu, L., et al. (2024). Magpie: Alignment data synthesis from scratch by prompting aligned LLMs with nothing. arXiv:2406.08464 .
- Liu, S., Wang, C., Yin, H., et al. (2024). DoRA: Weight-decomposed low-rank adaptation. ICML.
- Hayou, S., Ghosh, N., & Yu, B. (2024). LoRA+: Efficient low rank adaptation of large models. ICML.
- Biderman, D., Portes, J., Ortiz, J., et al. (2024). LoRA learns less and forgets less. COLM.
- Singhal, P., Goyal, T., Xu, J., & Durrett, G. (2024). A long way to go: Investigating length correlations in RLHF. COLM.
- Mu, T., Helyar, A., Heidecke, J., et al. (2024). Rule-based rewards for language model safety. arXiv:2411.01111 .
- Chen, Z., Deng, Y., Yuan, H., et al. (2024). Self-play fine-tuning converts weak language models to strong language models (SPIN). ICML.
- Guo, S., Zhang, B., Liu, T., et al. (2024). Direct language model alignment from online AI feedback. arXiv:2402.04792 .
- Akyürek, E., Damani, M., Qiu, L., et al. (2024). The surprising effectiveness of test-time training for few-shot learning. arXiv:2411.07279 .
- DeepSeek-AI. (2025). DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv:2501.12948 .
大模型工程 12 篇
- 01 大模型工程(一):Transformer 到 MoE
- 02 大模型工程(二):Tokenization 深度解析
- 03 大模型工程(三):预训练的规模之道
- 04 大模型工程(四):SFT、DPO 与 RLHF 当前
- 05 大模型工程(五):推理优化核心技法
- 06 大模型工程(六):长上下文与 RoPE、YaRN
- 07 大模型工程(七):Function Calling 实战
- 08 大模型工程(八):RAG 架构与落地
- 09 大模型工程(九):生产级 Prompt 工程
- 10 大模型工程(十):LLM-as-Judge 与评估
- 11 大模型工程(十一):安全与 Alignment
- 12 大模型工程(十二):生产落地与监控


