
大模型工程(五):推理优化核心技法
KV cache 力学、paged attention、continuous batching、speculative decoding、INT8/INT4/AWQ/GPTQ 量化,以及 vLLM、SGLang、TensorRT-LLM 的取舍。
真正的成本压力来自推理。以单个 70B 模型为例,支撑 1000 个并发用户、每秒生成 50 个 token 的 GPU 开销,约等于训练该模型的全部预算,只需运行约 3 个月。本章聚焦两个核心指标:首 token 延迟(TTFT)、token 间延迟(ITL),以及一个关键比率:每百万输出 token 消耗的 GPU 秒数。
训练是一次性资本支出(CapEx),成本可分摊至数百万次推理调用;推理则是持续发生的运营支出(OpEx),无法摊销。若 tokens-per-GPU-second 提升 50%,这一收益将在产品整个生命周期内日复一日地复利增长。正因如此,每个严肃的 LLM 团队至少配备一名全职推理工程师;过去五年里,开源社区也已迭代出四代推理引擎:FasterTransformer → DeepSpeed-Inference → vLLM → SGLang/TensorRT-LLM/llama.cpp。

两个特性截然不同的阶段#
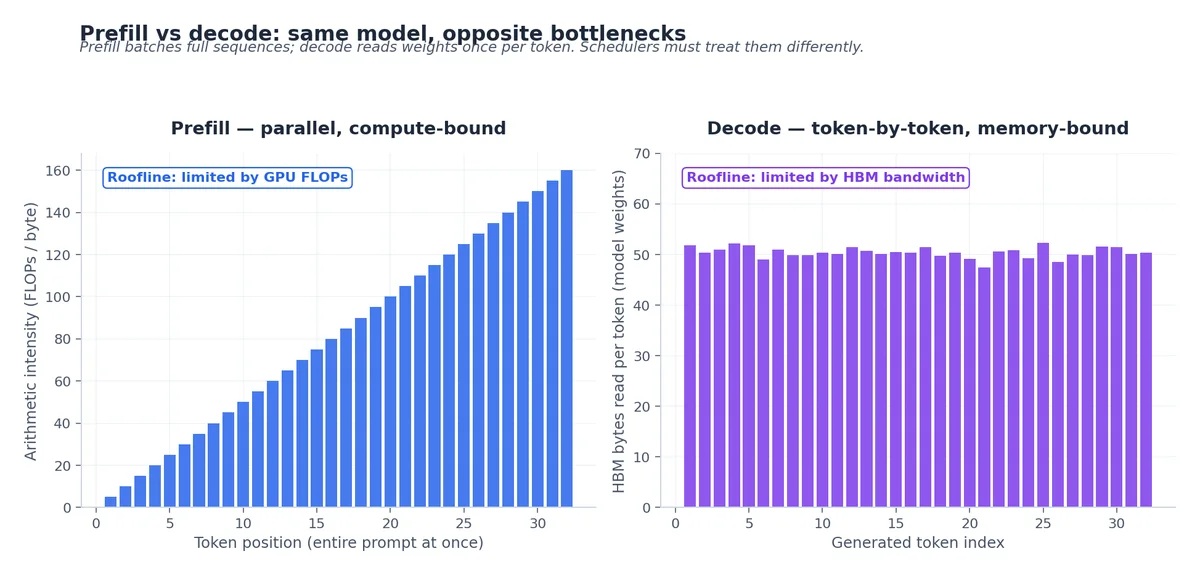
每次 LLM 推理调用都包含两个阶段:
- Prefill(提示词处理):将输入 token 并行送入模型,填满 KV 缓存。这是计算密集型(compute-bound)任务。以 70B 模型处理 4K token 的 prompt 为例,计算量约为 280 TFLOP,足以让一张 H100 在约 70 ms 内达到算力饱和。
- Decode(生成):逐个生成 token,每次均需基于缓存的 key 和 value 执行注意力计算。这是内存密集型(memory-bound)任务。每个 decode 步骤都要读取整个 KV 缓存(数 GB 规模),才能产出一个 token。
这种不对称性至关重要。Prefill 阶段天然适合跨用户批处理(相同 kernel,并行处理不同序列);而 Decode 阶段若采用朴素批处理(naive batching),效果通常很差,因为各用户处于不同的序列位置,难以对齐计算步。主流推理引擎的设计核心,正是围绕这一不对称性展开。
一条常用经验法则是:TTFT 主要由 prefill 阶段决定,而 ITL 则主要受限于 decode 阶段的内存带宽。要降低 TTFT,需提升计算吞吐(例如增加 SM 数量或启用张量并行);要降低 ITL,则需提高内存带宽(如使用 HBM3 而非 GDDR)或通过量化压缩参数规模,从而缓解带宽压力。
从算术强度的角度看,这一点更加清晰。对于 70B 模型处理 4K token 的 prefill:模型权重(BF16 下为 140 GB)仅加载一次,却作用于 4096 个 token,算术强度约为每字节参数读取对应 4096 FLOP。而在 decode 阶段,同样加载一次权重,却只处理一个 token,算术强度骤降至约 1 FLOP/字节。H100 在 BF16 下的峰值算力为 989 TFLOPS,HBM 带宽为 3.35 TB/s,其“平衡点”约为 295 FLOP/字节。Prefill(4096 FLOP/字节)远高于此,属于计算密集型;而 Decode(1 FLOP/字节)远低于此,属于内存密集型。这两个阶段对硬件的需求截然不同,若服务栈不加以区分处理,整体性能必然大打折扣。
KV 缓存:支撑长上下文的数据结构#
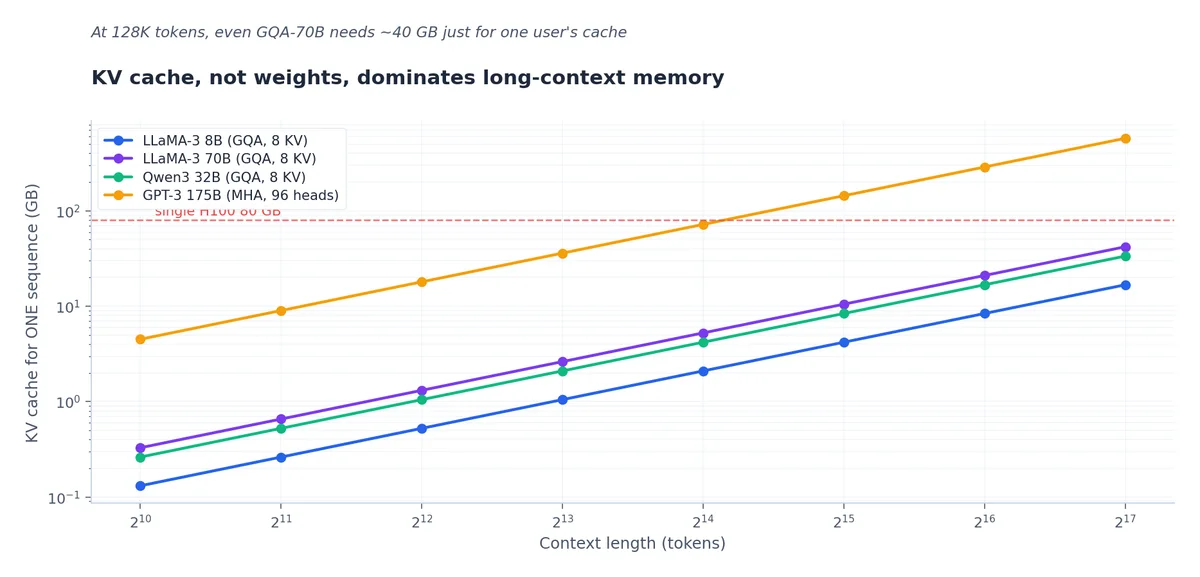
这是单个请求的开销。若有 50 个并发请求,总 KV 缓存将达到 430 GB,远超模型权重本身。此时真正的瓶颈并非模型参数,而是 KV 缓存。
朴素实现会为每个请求分配一个大小为 max_context 的连续张量,这会带来两大问题:
- 内部碎片化:一个仅使用 1K token 的请求仍会预留 32K 的内存空间。
- 无法动态扩展:一旦超过
max_context,系统会在 decode 过程中直接 OOM。
在高负载下还会出现第三类问题:外部碎片化。由于请求异步到达与退出,空闲显存虽总量充足,却分散在多个不连续区域,无法满足新请求对连续内存的需求。在可变负载下持续运行数小时的服务器,仅外部碎片化就可能导致 20%–40% 的可寻址 KV 内存无法使用。这与上世纪 60 年代操作系统通过分页机制解决的问题如出一辙,解决方案也相同。
分页注意力#

vLLM 的杀手锏源自 2023 年的论文 Kwon et al. ,即 分页注意力(paged attention)。其核心思想是:将 KV 缓存按固定大小的 块(block) 分配(通常为 16 个 token 的容量),并通过每个请求专属的 块表(block table) 将逻辑位置映射到物理块,这与操作系统的虚拟内存机制高度相似。
| |
其优势显著:
- 近乎零浪费:每个请求仅最后一个块可能存在内部碎片,且最多浪费 15 个 token。
- 内存共享:具有相同前缀的请求(如系统 prompt、few-shot 示例、工具定义)可共享相同的物理块。这正是 prompt caching 的技术基础。
- 易于抢占:在内存压力下,可将请求的块换出至 CPU;待资源空闲时再换回。
原始论文在 LLaMA-13B 上的基准测试显示,vLLM 相比朴素的 Hugging Face Transformers 循环(即逐 token 手动调用 generate),服务吞吐量提升达 14–24 倍。这一优势至今依然成立,但实际生产环境中的收益高度依赖工作负载特征:对于 batch-1 的单流服务,提升接近 2 倍;对于高并发、混合长度的流量,5–10 倍更为典型;而 14–24 倍的数值,仅出现在与完全未做批处理的 HF 代码对比时。关键不在于具体倍数,而在于分页注意力将 KV 内存从硬性约束转变为可管理资源。
一个最小化用法如下:
| |
启用 enable_prefix_caching=True 后,系统会自动为重复的 prompt 前缀共享块。若 1000 个请求共用同一系统 prompt,这些请求的 prefill 速度可提升 5–50 倍。
块管理器:分页如何运作#
块管理器(Block Manager)是所有分页注意力引擎的核心。它维护一个物理 KV 块池(通常每个块大小为 16 tokens × 2 (KV) × 层数 × 头数 × head_dim 字节),管理空闲列表,并为新请求原子性地分配块。当请求需要扩展(进入下一 decode 步)时,管理器从空闲列表取出一个块,将其物理地址追加到请求的块表中,然后返回。在写时复制(copy-on-write)语义下,共享块采用引用计数:fork 序列(如用于并行采样、beam search 或推测回滚)会增加引用计数;释放则减少;仅当计数归零时才真正释放物理内存。
生产环境中,“驱逐至 CPU”路径至关重要。当 GPU 空闲块耗尽但新请求仍在排队时,调度器会选择一个“受害者”请求(通常按 FIFO 或最长运行时间策略),通过 PCIe 将其块复制到主机 pinned 内存,并释放 GPU 块。待内存空闲后,再将其换回。尽管驱逐开销真实存在(PCIe Gen5 ×16 带宽为 64 GB/s,换出并重载一个 8 GB 请求约需 100 ms),但此举能避免直接拒绝请求,从而保障延迟 SLO。
连续批处理#
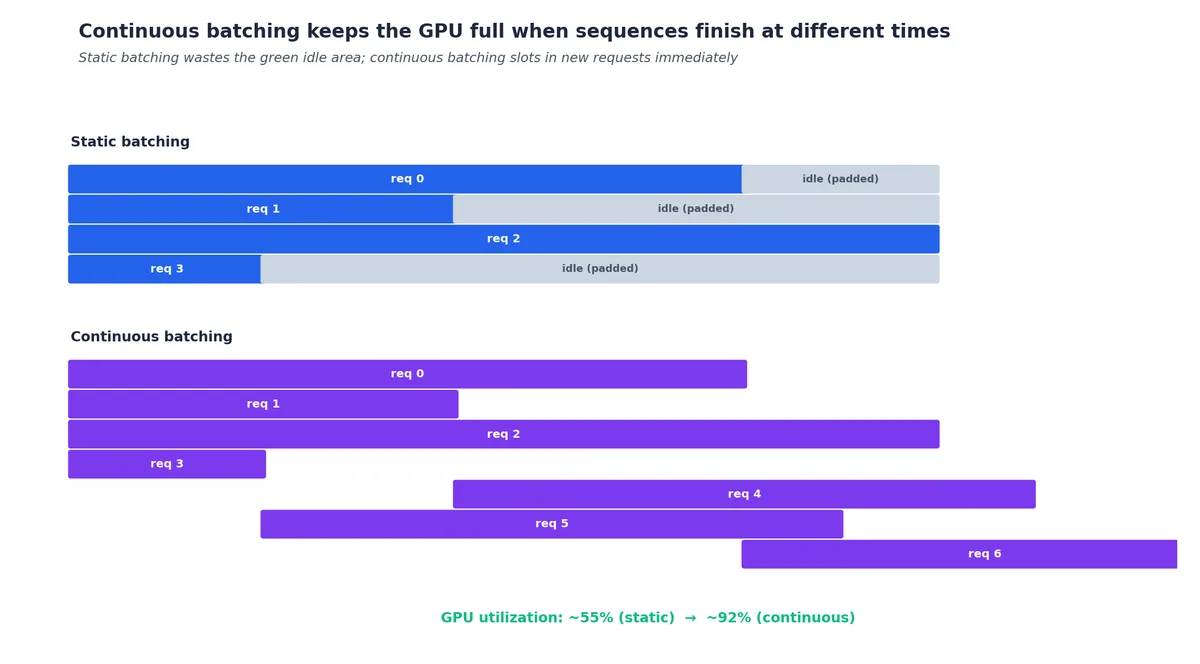
另一场革命来自 连续批处理(continuous batching)(Yu et al., Orca, OSDI 2022 ,由 vLLM 推广)。传统静态批处理(static batching)需等待批次中最慢的序列完成后才启动下一批,面对变长输出(这几乎是常态),会导致大量 GPU 时间空转。
连续批处理则在每个 decode 步骤中,立即移除已完成的序列,并接纳新的等待请求。只要队列中有任务,GPU 运行的序列数就不会低于 max_batch_size。
以 1000 个输出长度在 50–2000 token 之间的 prompt 为例:
- 静态批处理:总耗时 ≈ 最长输出(2000 token)所需时间(最坏情况主导)。
- 连续批处理:总耗时 ≈ 所有输出的平均值。
该优化与分页注意力形成协同效应:中途加入新序列仅需分配新 KV 块,无需重新分配整个张量。
Orca 的迭代级调度#
Orca 论文提出的两项机制至今仍被广泛采用。迭代级调度(iteration-level scheduling) 将批处理边界与请求边界解耦:每个 Transformer 迭代独立调度,因此一个在第 500 步完成的请求不会阻塞另一个需 1500 步的请求。选择性批处理(selective batching) 则通过允许注意力算子按每序列形状操作,而线性层(不依赖位置信息)统一批处理,来应对 prefill/decode 的不匹配问题。现代引擎进一步融合二者:vLLM 和 SGLang 均支持“分块预填充(chunked prefill)”,即在单次前向传播中交错执行一个请求的 prefill 与其他请求的 decode,即便 decode 队列稀疏,也能维持 GPU 利用率在 90% 以上。
调度决策至关重要:何时在批处理中途接纳新请求?朴素做法是立即接纳,但这可能引发严重问题,若在 decode 进行时插入一个 32K token 的 prefill,单次迭代延迟将剧增(因其 FLOP 量约为单个 decode 步的 100 倍)。生产级调度器通常会限制每次迭代的“计算预算”,并将长 prefill 拆分为多个 chunk,与 decode 步骤交错执行。这一隐藏的权衡旋钮,直接决定了系统在高负载下的 TTFT p99 是 500 ms 还是 5 秒。
推测解码#


这是一个巧妙且如今已成为标配的技术。由于 decode 阶段通常是内存密集型的,每一步都需读取整个模型权重才能生成一个 token,若能一次性验证 N 个 token,效率将大幅提升。
推测解码(speculative decoding,Leviathan et al., 2023 )的核心思路是:使用一个草稿模型(draft model)(小型、快速,如 1B 模型)预先生成 $k$ 个 token;目标模型(即实际要服务的 70B 模型)则在单次前向传播中验证这些 token:它接收提议的前缀,并行计算 $k+1$ 个位置的概率分布。与目标模型 argmax 匹配的 token 予以保留;首个不匹配的 token 及其后续全部丢弃,并从此处重新采样。
从数学上看:若草稿模型的准确率为 $\alpha$ ,且 decode 为内存密集型(即 $k+1$ 个 token 的前向传播成本与单 token 相近),则期望加速比为 $(1 - \alpha^{k+1})/(1 - \alpha)$ 。当 $\alpha=0.7$ 、$k=4$ 时,加速比可达 2.5 倍。
实践中,草稿模型通常由目标模型蒸馏而来。目前主要有三类方案:
- 双模型对(Draft-target two-model pairs):即 Leviathan 原始方案,由小型蒸馏模型提议,目标模型验证。质量高,但需维护两个同步的 checkpoint,运维成本高。
- Medusa(Cai et al., 2024 ):在目标模型上额外添加 4–5 个预测头,每个头基于相同的骨干激活预测 $t+1, t+2, t+3, \dots$ 位置。无需独立草稿模型,加速 2–3 倍且无质量损失,仅需在基础模型上额外训练数天。
- EAGLE / EAGLE-2(Li et al., 2024 ):基于倒数第二层隐藏状态和前一 token 构建自回归头。EAGLE-2 引入动态树状验证机制,每步探索多条草稿分支,在多数工作负载上可达 3–4 倍加速,是当前自回归推测的 SOTA 方案。
| |
需注意:推测解码仅在目标 GPU 处于内存密集型状态时有效。大批次场景下,权重加载成本被摊销至所有序列,系统转为计算密集型,此时推测解码无益。而单流低延迟服务恰为内存密集型,收益显著。
关于正确性还有一个精妙细节:验证步骤实际执行的是针对目标分布的拒绝采样(rejection sampling)。若 token $t$ 的草稿概率为 $p_d(t)$ ,目标概率为 $p_t(t)$ ,则接受概率为 $\min(1, p_t(t)/p_d(t))$ ;若拒绝,则从正比于 $\max(0, p_t(t) - p_d(t))$ 的修正分布中采样。该机制严格保证输出分布与目标模型完全一致,无论草稿质量如何。因此,推测解码是无损的:草稿越差,仅意味着接受率越低,而非输出质量下降。这也是团队上线时无需进行质量回归测试的原因,根本不存在质量退化风险。
量化:INT8、INT4、FP8#
推理量化指将 bf16 权重转换为 INT8 / INT4 / FP8,以节省显存和带宽。通常仅量化权重,有时也包括激活值。
INT8 仅权重量化#
最简单。对每个权重矩阵按输出通道进行量化:$w_q = \text{round}(w / s)$ ,其中 $s$ 为每通道缩放因子。推理时,在矩阵乘法前即时反量化为 bf16。
显存占用减半(16 位 → 8 位),困惑度损失通常低于 0.5%,且无需校准,堪称白捡的性能红利。
INT4:GPTQ 与 AWQ#
INT4 量化难度更高。简单四舍五入会导致 2%–5% 的困惑度损失。目前有效的算法主要有两种:
GPTQ(Frantar et al., 2022 ):Optimal Brain Quantization(OBQ)的扩展,使其适用于十亿参数模型。逐列量化权重矩阵,每量化一列后,利用 Cholesky 分解的 Hessian 逆矩阵更新剩余未量化列以补偿误差。本质上是对每列求解一个结构化最小二乘问题。计算成本较高:单张 A100 上量化 70B 模型需数小时,峰值显存约等于小规模校准集(通常 128 样本 × 2048 token)上单层激活值的大小。
AWQ(Lin et al., 2023 ):观察到约 1% 的权重为“显著权重”(salient weights,即大激活值流经的权重)。通过每通道缩放因子 $s$ 保护这些权重免受量化噪声影响,等价于量化前将输入激活乘以 $s$ 、权重除以 $s$ 。该操作在全精度下无影响,但能重塑量化误差分布,随后即可均匀量化。相比 GPTQ 更快(无需 Hessian 求解,仅需搜索缩放因子),多数模型上质量略优,且对 MoE 架构更友好。
SmoothQuant(Xiao et al., 2022 ):与 GPTQ/AWQ 正交,专注于激活量化。其挑战在于激活值常存在异常通道(少数通道幅值高达其他通道的 100 倍),会严重破坏 INT8 量化效果。SmoothQuant 通过每通道缩放将激活幅值迁移至权重侧,使双方均可量化至 INT8。通常作为 INT8 W8A8 量化的预处理步骤。
GPTQ 与 AWQ 均可在 LLaMA 类模型上实现 INT4 仅权重量化,困惑度损失低于 1%。对于 MoE 模型,路由机制使校准复杂化,不同专家看到的激活分布差异巨大,统一缩放因子难以保护低频专家。当前最佳实践是 per-expert AWQ。
| |
FP8(及 H100/H200 硬件路径)#
H100 及更新 GPU 配备 FP8 Tensor Core,吞吐量达 BF16 的 2 倍。FP8 推理已成为现代主流路径:权重以 FP8 存储,计算时激活值转为 FP8,累加使用 FP32。质量损失可忽略(<0.1%),因 FP8 动态范围优于 INT8。
FP8 有两种格式:E4M3(4 位指数,3 位尾数)用于激活与权重,范围较小但精度高;E5M2(5 位指数,2 位尾数)用于梯度与 KV 缓存,范围更大但精度较低。硬件将反量化缩放融合进矩阵乘法,因此无“INT4 反量化开销”;FP8 是 H100/H200 上的极致性能路径。
尽管困惑度损失极小,FP8 仍需校准。标准流程为:在 128–512 个校准样本上收集激活统计量,计算 per-tensor 或 per-token 缩放因子,并存入 checkpoint。运行时基于实际 batch 计算的 per-token 缩放因子能以微小延迟代价换取最佳质量。NVIDIA TransformerEngine 与 vLLM 的 --quantization fp8 均已实现该方案。
需注意:FP8 依赖硬件支持。INT4/INT8 可在任意 GPU 上运行,而 FP8 仅限 H100/H200/B200。若部署于 A100,INT8/INT4 是唯一选择。
KV 缓存量化#
这是显存消耗的另一半。将 KV 缓存压缩至 INT8 可节省 2 倍显存;INT4 在精细 per-token 校准下仅损失 1%–2% 质量。vLLM 与 SGLang 均支持 FP8 KV 缓存;INT4 KV 仍属研究前沿,但 FlashInfer 已提供相关 kernel。
FP8 KV 缓存是 2026 年的主力方案:以低于 0.1% 的质量损失将显存减半(同等 GPU 上并发请求翻倍)。Per-token 缩放几乎无额外开销,因缩放因子可在线计算。INT4 KV 则需更谨慎处理,AWQ 利用的 per-channel 显著性结构不适用于 KV(其为数据而非参数)。当前最佳实践是 per-token-per-head 缩放结合异常值保留:约 1% 的通道保持高精度,其余激进量化。
SGLang 与 RadixAttention#
vLLM 的前缀缓存仅支持完全相同的前缀共享。SGLang(Zheng et al., 2024 )通过 RadixAttention 将其泛化:构建一棵包含所有活跃 KV 块的基数树(radix tree),每条从根到叶的路径代表一个 token 序列。新请求在树中查找最长匹配前缀,共享对应块,仅计算后缀部分。
为何这比 vLLM 的精确前缀缓存更重要?因为智能体(agent)工作负载常发生分支。例如,ReAct 智能体可能发起 5 个工具调用子查询,它们共享相同的系统 prompt + 工具定义 + 对话历史,但后缀不同。线性前缀缓存能让每个子查询匹配共享根节点,却无法促进子查询间的相互共享;而 RadixAttention 可以。
SGLang 论文报告的收益:相比 vLLM 的等效前缀缓存,在智能体与结构化输出工作负载上吞吐量提升 5 倍,普通聊天场景提升约 1.5 倍。对于无共享前缀的流量,收益则大幅缩小。
其实现大致如下:维护一棵以 token ID 为键的基数树,节点持有 KV 块引用。新请求到来时,沿树尽可能深地匹配输入前缀,增加所有经过节点的引用计数,为未匹配后缀分配新块;请求完成后减少引用计数;显存压力升高时,按 LRU 策略驱逐子树。该数据结构的开销相比节省的资源可忽略不计。
TensorRT-LLM 特性#
NVIDIA 的 TensorRT-LLM 是第三大主流引擎,其差异化优势包括:
- 编译内核(Compiled kernels):每个模型均针对特定 GPU、batch size 配置及序列长度编译为 TensorRT 引擎。编译耗时 10–30 分钟,生成的引擎在支持的工作负载上比 vLLM 的运行时编译版本快 1.1–1.3 倍。
- 插件模型(Plugin model):注意力(FMHA、分页 FMHA、FlashAttention-3 路径)、MoE 路由及量化等自定义 kernel 以插件形式暴露。该模型虽比 vLLM 更脆弱,但支持更激进的算子融合。
- 飞行中批处理(In-flight batching):即 TensorRT-LLM 版的连续批处理,配备 NVIDIA 调优的调度器。
- 深度 FP8 集成:TransformerEngine FP8 为一等公民。在 H100 上使用 FP8 时,TensorRT-LLM 通常以 5%–15% 的优势领跑吞吐量。
- 转换痛苦(Painful conversion):每个新模型架构均需定制 Python 构建脚本,新模型支持通常比 vLLM 滞后数周至数月。
若你在 NVIDIA 硬件上大规模服务固定的一组知名模型,且具备足够工程资源,TensorRT-LLM 是优选。否则,vLLM 的运维简洁性几乎总是胜出。
2026年的服务框架选型#
当前主要有三大选项:
- vLLM:事实上的开源标准。社区最活跃,新模型与特性支持最快。分页注意力、连续批处理、推测解码、前缀缓存等均开箱即用,默认配置已足够优秀。除非有特殊理由,否则首选它。
- SGLang:2024 年新秀,在结构化生成(受限 JSON、正则表达式)、前端缓存(基于 RadixAttention 的 prompt 树共享)及高分支智能体场景下表现更佳。对于共享前缀的工作负载,TTFT 更低。
- TensorRT-LLM:NVIDIA 官方框架。在支持的模型上,H100 的裸吞吐量最高(得益于编译内核与融合的 FlashAttention 路径),但模型转换繁琐,新模型支持滞后。若你拥有 NVIDIA 支持且需榨取极致吞吐,可选它。
vLLM 0.6+ 与 SGLang 均已支持推测解码、FP8、AWQ/GPTQ、MoE、multi-LoRA、函数调用约束解码等主流特性,差距正快速缩小。建议默认选用 vLLM,仅当工作负载重度依赖结构化输出或智能体时,再切换至 SGLang。
以下为笔者在 2025 年末实测的单卡 H100 上 FP8 精度 Qwen3-32B 的纯吞吐数据:
| 引擎 | 吞吐量 (tok/s) | TTFT p50 (ms) | ITL p50 (ms) |
|---|---|---|---|
| vLLM 0.6 | 7400 | 95 | 13 |
| SGLang 0.4 | 7800 | 72 | 14 |
| TensorRT-LLM | 8900 | 88 | 11 |
对大多数业务而言,这些差异属于噪声范畴。框架选择应主要基于开发体验。
服务端的并行模式#
以 BF16 精度运行完整的 70B 模型需 >140 GB 显存,单张 H100(80 GB)无法容纳。解决方案涉及三个正交维度,张量并行(TP)、流水线并行(PP)与序列并行(SP),其组合方式与训练场景(第四章)不同。
张量并行(TP)#
将每个权重矩阵切分至多张 GPU。经典 Megatron-LM Shoeybi et al., 2019 方案:QKV 投影采用列并行(每卡负责部分注意力头),注意力输出投影采用行并行(后续执行 all-reduce),两个 FFN 矩阵乘法则分别采用列并行与行并行。每个 Transformer 层需两次 all-reduce。
服务场景下,节点内 TP(NVLink,双向带宽 ~600–900 GB/s)可行;跨节点 TP(InfiniBand,单链路 ~50 GB/s)会因 all-reduce 通信引入不可接受的延迟。通常上限为 TP ≤ 8(单节点内)。
- TP=2 张 H100(同节点,NVLink):吞吐量约为单卡的 1.7–1.9 倍(非 2 倍,因 TP 引入通信开销)。
- 若需长上下文,可选 TP=4(KV 缓存亦随 TP 切分)。
- 单卡 H100 + INT4 量化:吞吐量低于 TP=2,但成本更低。
一行命令即可部署:vllm serve Qwen/Qwen3-72B --tensor-parallel-size 2。
流水线并行(PP)#
将模型层切分至多张 GPU(如 GPU 0 负责层 0–19,GPU 1 负责 20–39 等),激活值沿流水线传递。经典问题是流水线气泡(pipeline bubble):流水线末端 GPU 空闲等待前端,反之亦然。服务场景下,PP 会引入与流水线深度 × 每层耗时成正比的 TTFT 延迟;现代引擎通过微批次(micro-batching)(将 batch 切分为小批次背靠背流过流水线)来摊销该开销。
PP 是跨节点并行的标准方案。典型 200B+ 模型部署采用“节点内 TP + 跨节点 PP”策略。多数对延迟敏感的团队会限制在单节点内,PP 气泡的影响真实存在。
序列并行(SP)#
当序列极长时,单层激活值可能超出单卡显存。序列并行沿 token 维度切分,并通过环形或全对全通信处理注意力 all-reduce。该技术主要用于 512K+ 上下文场景,此时即使启用 TP,单层激活缓冲仍超限。绝大多数生产服务无需此方案。
数学分析:何时采用何种并行?#
粗略估算,TP 每层成本为 $2 \cdot \text{params}/\text{TP} / \text{HBM-BW} + 2 \cdot \text{batch} \cdot \text{seq} \cdot \text{hidden} / \text{NVLink-BW}$ 。第一项随 TP 线性下降,第二项上升,存在最优平衡点(H100 上通常为 TP=2 至 TP=4)。超过 TP=8 后,all-reduce 开销主导,收益递减。具体而言,70B 模型在 TP=2 时吞吐量约 1.85 倍,TP=4 约 3.2 倍,TP=8 约 5.5 倍。
PP 的延迟成本对单 batch 查询约为 $\text{depth} \cdot \text{time-per-layer}$ 。在微批次与稳态队列下,吞吐量趋近于 $\text{batch} / (\text{time-per-stage})$ 。PP 对吞吐友好,但对延迟不利。
我的实际部署建议#
- 7B 级模型:单卡 L40S 或 4090,FP8,vLLM,16K 上下文,80% 利用率下每百万输出 token 成本约 $0.10–$ 0.15。
- 32B 级模型:单卡 H100(AWQ INT4)或双卡 L40S(FP8)。两者皆可:H100 单 token 更快,L40S 每小时成本更低,按 $/Mtok 决策。
- 70B 级模型:双卡 H100(FP8)。INT4 虽省 30% 成本,但 ~1% 的质量损失在生产环境往往不可接受。
- 200B+ MoE:属独立优化问题(见第十二章)。
可观测性:关键监控指标#
生产环境中,真正重要的并非“tokens/sec”(这是单 batch 指标),而是负载下的分位数延迟。最小化监控看板应包含:
- TTFT p50 / p95 / p99(ms):从请求接收到首 token 输出的时间。p99 反映用户体验,p50 用于宣传。
- ITL p50 / p95 / p99(ms):稳态下的 token 间延迟。尖峰通常意味着抢占或内存压力。
- 不同并发下的吞吐量(tok/s):测试并发 1、8、32、128、512,绘制曲线;拐点即为 FLOP 或内存带宽饱和点。
- 队列深度与等待时间:请求是否因引擎处理不过来而堆积?
- KV 缓存利用率(%):是否临近抢占阈值?
- 前缀缓存命中率(%):低命中率说明 prompt 工程产出的 prompt 缺乏共享性。
- GPU SM 与 HBM 带宽利用率:来自
dcgm-exporter或nvidia-smi dmon。若两者均 <70%,说明有余量;若 HBM 达 95% 而 SM 仅 40%,则为内存瓶颈,应考虑量化。
务必明确设定 SLO。典型生产目标:TTFT p95 < 500 ms,ITL p95 < 50 ms,错误率 < 0.1%。超出即视为事故。
成本核算#
核心指标是**每百万输出 token 成本($/Mtok-out)**。以自托管 vLLM 在单卡 H100 上服务 FP8 精度的 Qwen3-32B 为例(按需 $ 2.50/hr,1 年预留 $1.20/hr,3 年预留 $ 0.80/hr):
- 并发 32 时吞吐量:~7400 tok/s
- 预留 hourly 成本:$1.20/hr = $ 0.00033/sec
- $/Mtok-out = $ 0.00033 / 7400 × 10⁶ ≈ $0.045
对比 2026 年中 API 定价:
- Claude-4.5-Sonnet:$15/Mtok output
- GPT-5:$12/Mtok output
- DeepSeek-V3.2:$1.10/Mtok output
- Qwen3-Max API:$0.80/Mtok output
自托管开源模型与前沿 API 之间 30–300 倍的成本差距,正是团队选择自托管的根本原因。但需注意:月用量 <1 亿 token 时,工程成本会抵消节省;月用量 >10 亿 token 时,节省占绝对主导,自托管成为必然选择。
一个易被忽视的细节:API 中输入 token 通常比输出便宜 5–10 倍(因其更易批处理且无需自回归)。自托管时,输入虽仍便宜,但差距缩小至 3–5 倍(因两阶段均在自有硬件上运行)。假设输入输出成本相等的成本模型,会在两个方向上产生误导。
总结#
推理包含两个不对称阶段(prefill 与 decode),而现代服务栈,分页注意力 + 连续批处理 + 推测解码 + 量化 + FP8 硬件,存在的意义,正是让这两个阶段中最糟糕的部分变得可容忍。vLLM 是合理的默认选择;量化(INT8 必用,预算紧时用 INT4,H100+ 用 FP8)基本等于免费性能;推测解码在低 batch 低延迟场景可带来 2–3 倍加速,但在高吞吐场景收益甚微。2026 年的成本格局强烈支持在规模化场景下自托管开源模型。
下一章:长上下文。RoPE scaling、YaRN、NTK-aware 插值、ALiBi、注意力汇(attention sinks),以及为何多数“1M 上下文”宣称在实际检索任务中不堪一击。
参考文献#
- Kwon et al., “Efficient Memory Management for Large Language Model Serving with PagedAttention,” SOSP 2023. The original vLLM paper.
- Yu et al., “Orca: A Distributed Serving System for Transformer-Based Generative Models,” OSDI 2022. Continuous batching + iteration-level scheduling.
- Zheng et al., “SGLang: Efficient Execution of Structured Language Model Programs,” NeurIPS 2024. RadixAttention.
- Leviathan et al., “Fast Inference from Transformers via Speculative Decoding,” ICML 2023.
- Cai et al., “Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads,” ICML 2024.
- Li et al., “EAGLE-2: Faster Inference of Language Models with Dynamic Draft Trees,” 2024.
- Lin et al., “AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration,” MLSys 2024.
- Frantar et al., “GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers,” ICLR 2023.
- Xiao et al., “SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models,” ICML 2023.
- Shoeybi et al., “Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism,” 2019.
- vLLM project documentation
- SGLang project documentation
- NVIDIA TensorRT-LLM repository
大模型工程 12 篇
- 01 大模型工程(一):Transformer 到 MoE
- 02 大模型工程(二):Tokenization 深度解析
- 03 大模型工程(三):预训练的规模之道
- 04 大模型工程(四):SFT、DPO 与 RLHF
- 05 大模型工程(五):推理优化核心技法 当前
- 06 大模型工程(六):长上下文与 RoPE、YaRN
- 07 大模型工程(七):Function Calling 实战
- 08 大模型工程(八):RAG 架构与落地
- 09 大模型工程(九):生产级 Prompt 工程
- 10 大模型工程(十):LLM-as-Judge 与评估
- 11 大模型工程(十一):安全与 Alignment
- 12 大模型工程(十二):生产落地与监控


