
大模型工程(八):RAG 架构与落地
切分策略、dense vs sparse vs 混合检索、reranker 选型、2026 年长上下文 vs RAG 的取舍,以及 10 万文档以上才会冒头的失败模式。
RAG 是当前 LLM 应用中部署最广泛,却工程实践最不成熟的范式。2024 年流行的 Demo 套路,用 text-embedding-3-large 把所有内容向量化,扔进 pgvector,再取 cosine 相似度 top-5,在千篇量级文档和对答案容错率较高的演示场景下尚可应付;但一旦面对十万级真实业务文档,且客户对答案准确性有严格要求时,这套方案便难以为继。本章内容,正是我希望更多团队在构建第二代 RAG 系统前就能掌握的关键认知。
最早的 RAG 论文(Lewis et al., 2020 )将检索增强生成定义为一种混合模型:稠密检索器(DPR)与生成器(BART)联合训练,使检索目标直接优化端到端任务的准确率。而到了 2026 年,生产级 RAG 已与 Lewis 的原始设计相去甚远,现代系统普遍采用冻结的预训练嵌入模型、独立的重排序器(reranker),以及不与检索器联合训练的仅解码器(decoder-only)生成模型。尽管如此,其核心思想,将知识存储与推理能力解耦,不仅得以保留,更发展为主导范式。Gao et al. (2023) 的 RAG 综述 是对 2020 年后演进路径(“Naive RAG → Advanced RAG → Modular RAG”)最全面的梳理。

RAG 到底是什么#
检索增强生成(Retrieval-augmented generation)的核心逻辑是:在查询时,从外部语料库中检索相关文本片段,将其注入大语言模型的上下文窗口,从而生成有依据的答案。“增强”的部分体现在 prompt 模板中:
| |
真正的工程难点其实位于“增强”之前,即如何构建一个能精准召回相关文本块(chunk)的检索器。这涉及三大子系统:文本块切分(chunking)、嵌入(embedding)和排序(ranking)。
Chunking 是隐形杀手#


你如何将文档切分为文本块,直接决定了检索器理论上能够找到什么内容。常见的 chunk 大小包括 256、512 和 1024 tokens,主流策略如下:
- 固定大小(Fixed size):每 $N$ 个 token 切一刀。简单直接,但容易切断语义单元。
- 按句子切分(Sentence):在句子边界处分割。效果稍好,但往往过于碎片化。
- 递归字符切分(Recursive character):优先按 `
切,不行再试
,再不行用 . ` 等(LangChain 默认策略)。这是一个不错的基线方案。
- 语义切分(Semantic):对滑动窗口进行嵌入,在嵌入相似度显著下降处切分。效果更好,但计算成本更高。
- 晚期切分(Late chunking)(Günther et al., 2024 ):先用长上下文嵌入模型处理整篇文档(最长支持 8K–32K tokens),再对嵌入序列进行切分,每个 chunk 的嵌入都融合了周围文档的上下文信息。该方法最适合长文档,但需要支持长上下文的嵌入模型(如 Jina 或 BGE-M3)。
最佳策略取决于你的语料特性:代码应按函数或类切分,法律文本按条款划分,Markdown 按标题组织,PDF 则需单独解析表格和图片,避免打断正文流。我调试过的多数失败案例,根源往往是“文档在表格中间被截断”或“答案横跨两个 chunk,但任一 chunk 单独看都语义不全”。
建议通过合理性验证确定 chunk 大小:随机选取 20 个典型问题,在语料库中人工定位答案并统计其 token 数。若大多数答案可容纳于 512-token chunk,则选用 512;若多数需要 1500 tokens 上下文(如法律合同),则使用 1500 并配置 200-token 重叠。
| |
重叠(overlap)至关重要。若无重叠,一个起始于 chunk A 第 799 位、结束于 chunk B 第 821 位的句子会被截断;而设置 100-token 重叠后,两个 chunk 都能包含完整句子。
Late chunking:2024 年的突破#
朴素切分(naive chunking)对每个 chunk 独立嵌入,“Q3 营收增长 12%”这类片段缺乏所属公司和年份等关键上下文。晚期切分(late chunking)则反转流程:先将整篇文档输入长上下文嵌入模型,获得每个 token 的上下文化嵌入,再按 chunk 边界对 token 嵌入进行池化,生成最终 chunk 嵌入。如此一来,“Q3 营收增长 12%”的嵌入便能反映“Apple 2024 年第一季度财报”这一上下文。
在长文档问答任务上的实测表明:相比采用相同边界的朴素切分,晚期切分可在不增加存储开销的前提下,将 NDCG 指标提升 5–15%,仅TEB 排名第一 |
| voyage-3-large | 1024 | ~70.5 | 闭源,高端商用 |
| jina-embeddings-v3 | 1024 | ~67.0 | 开源、多语言、原生支持 late chunking |
两个关键实践建议:
多语言支持至关重要。2022–2023 年的多数嵌入模型仅在英文上训练,在中文、日文或阿拉伯文上的检索效果显著下降。若你的语料包含多语言内容,务必选择多语言模型,BGE-M3 和 Qwen3-Embedding 是当前开源领域的佼佼者。
领域专用模型往往优于通用模型。一个在法律领域微调的小型嵌入模型,常能在法律语料上击败最先进的通用模型。如果你的语料具有强领域属性(如医疗、法律、代码或科研),应评估领域专用模型或自行微调。
自托管嵌入模型的成本正持续降低。单张 L4 GPU 上的 BGE-M3 可达约 3000 chunks/秒的吞吐量。对于少于 1000 万 chunks 的语料库,通常无需依赖托管服务。
关于维度的补充说明:高维嵌入(3K–4K)通常检索效果更优,但会增加存储开销和索引查询延迟。Matryoshka 表示学习(用于 text-embedding-3-large 和 Nomic 嵌入)通过训练使不同长度前缀(如 256、512、1024)均具备良好检索能力,允许你在部署时灵活权衡维度与性能,无需重新训练。对于 10 万文档规模的语料库,768–1024 维是性价比最高的选择。
向量索引:HNSW、IVF 与权衡#
获得嵌入后,需借助向量索引加速近邻搜索,避免暴力比对。当前主流算法分为两类:
HNSW(Hierarchical Navigable Small World, Malkov & Yashunin, 2018
)通过构建多层图结构实现高效检索:每个节点连接约 $M$
个最近邻,查询从顶层入口点开始,逐层贪婪下降并精炼候选集。召回率可通过 ef_search 调节(候选越多,召回越高,但查询越慢)。其索引构建较慢(O(N log N) 图构造)且内存占用高(约为嵌入存储的 1.5 倍),但在百万级规模下查询延迟可低于毫秒。
HNSW 已成为 pgvector、Milvus、Qdrant、Weaviate 等现代向量数据库的默认选项。针对 100 万至 1 亿向量的语料库,推荐参数为 M=16–32、ef_construction=200–400、ef_search=50–100,可在普通硬件上实现 >95% 召回率与 <5 ms 查询延迟。
IVF(Inverted File Index)则先通过 k-means 将嵌入聚类为 $K$ 个质心,查询时仅搜索最近几个质心对应的倒排列表。该方法内存效率高(无图结构开销),但召回-速度权衡不如 HNSW。FAISS 库以此为基础,衍生出 IVF-PQ(结合乘积量化进一步压缩)等高级变体。
FAISS(Johnson et al., 2017 )是行业标准实现库,提供 Flat、IVF、HNSW、IVF-PQ 等底层索引原语,并支持灵活组合。生产团队通常用 FAISS 处理离线批量任务(如重排序实验、训练数据构建),而在线服务则选用 Qdrant 或 pgvector 等高层向量数据库。
对于 10 万至 100 万向量的部署场景,索引选择影响甚微,pgvector 内置的 HNSW 已足够。当规模达到 1 亿以上时,决策重点转向内存预算与分片数量;而超过 100 亿向量,则需进入定制基础设施领域,依赖 Google 或 Meta 级别的工程能力。
密集型 vs 稀疏型 vs 混合型#

密集检索(Dense retrieval)(基于神经嵌入的 cosine 相似度)擅长捕捉语义相似性,但在精确匹配(如缩写、ID、罕见术语)上表现较弱。
$$ \text{BM25}(q, d) = \sum_{t \in q} \text{IDF}(t) \cdot \frac{f(t,d) \cdot (k_1+1)}{f(t,d) + k_1 \cdot (1 - b + b \cdot |d|/\text{avgdl})} $$其中 $k_1 \approx 1.5$ 、$b \approx 0.75$ 为标准参数。过去 30 年,BM25 一直是词法检索的主流算法,即便在密集嵌入兴起后仍未被取代,因为它在依赖特定 token 的查询(如产品 SKU、错误代码、命名实体)上仍是同类最佳。
混合检索(Hybrid retrieval) 结合两者优势后再融合。2026 年几乎所有生产级 RAG 系统均采用混合方案,相比纯密集检索,其在多数基准测试上可将 NDCG@10 提升 10–30%,而额外成本极低(BM25 计算廉价,且 chunk 数据已存在)。
融合方式至关重要。简单的加权求和(score = 0.5 * dense + 0.5 * bm25)需对分数归一化,且调参困难。当前主流方案是倒数排名融合(Reciprocal Rank Fusion, RRF)(Cormack et al., 2009
):
| |
RRF 在分数层面无需参数,经验常数 $k=60$ 表现稳健。具体流程为:分别运行密集与稀疏检索,各取 top-50 结果,经 RRF 融合后取 top-20,再送入重排序阶段。
RRF 之所以有效,在于它基于排名而非原始分数进行融合,因此不受 BM25(无界正数)与 cosine([-1, 1])分数分布差异的影响。无论底层检索器如何缩放置信度,任一检索器的 Rank-1 对最终得分贡献相同,这正是融合异构检索器所需的不变性。
重排序是被低估的英雄#


嵌入检索虽快,但精度有限(本质是有损压缩)。第二阶段的 cross-encoder 重排序器 通过联合编码 [query, candidate] 直接输出相关性分数,显著提升精度。
Cross-encoder 单次计算成本约为嵌入 cosine 的 100 倍,无法用于百万级 chunk 的初筛,但对 top-20 候选进行重排序则成本可控,且能稳定提升 5–15% 的质量。
推荐模型包括:
BAAI/bge-reranker-v2-m3(开源、多语言、约 6 亿参数、L4 GPU 上高效)cohere-rerank-v3(闭源、英文优化、$2/1K queries)jina-reranker-v2(开源、多语言、推理极快)
| |
完整流水线变为:嵌入/稀疏检索 top-50 → 重排序至 top-5 → 注入 LLM 上下文。重排序器是值得投入延迟预算的关键环节,其带来的质量提升远比微调 LLM prompt 更可靠。
晚期交互:ColBERT#

ColBERT 既保留了 token 级匹配能力(利于罕见词检索),又支持并行计算。ColBERTv2 与 PLAID(Santhanam et al., 2022)通过残差压缩和近似检索,使其在百万文档规模上具备可行性。BGE-M3 也内置了 ColBERT 风格组件,可免费使用。
在 2025–2026 年的生产系统中,晚期交互正逐步应用于高精度检索场景,当重排序 50 个候选仍不足,但全量 cross-encoding 成本过高时。2024 年提出的 ColPali 更将该原理扩展至视觉-语言模型,用于文档图像检索,证明 token 级匹配在 PDF/扫描件检索上显著优于“先 OCR 再嵌入”的传统流程。
Anthropic 的上下文检索与 GraphRAG#
2024 年两项进展进一步提升了 RAG 在生产级语料上的表现。
Anthropic Contextual Retrieval(2024)在嵌入每个 chunk 前,先 prepend 一段模型生成的 50–100 token 上下文,说明该 chunk 在文档中的位置(例如:“本 chunk 来自 Acme Corp 2023 年 Q3 财报,讨论供应链中断的部分”)。这些带上下文的 chunk 随后通过密集嵌入与 BM25 分别检索,经 RRF 融合后再重排序。Anthropic 报告称,其内部基准测试中检索失败率降低 49%,结合重排序后更达 67%。关键在于,上下文生成是一次性索引开销(非每次查询),却大幅提升了嵌入对检索任务的适配性。
GraphRAG(Microsoft Research, 2024 )则摒弃扁平 chunk 思路,在索引阶段提取实体与关系构建知识图谱,并聚类为多粒度社区。查询时,针对跨文档的“全局性”问题(如“该语料库的主要主题是什么?”),直接检索社区摘要而非原始 chunk。GraphRAG 在此类任务上显著优于朴素 RAG,但代价更高:图谱构建需在索引阶段调用 LLM(约 $1–10/1000 文档)。对于天然需跨文档聚合的语料,GraphRAG 代表当前前沿;而对于事实检索类查询,hybrid + rerank 仍在成本-质量比上占优。
什么时候该用长上下文而非 RAG#
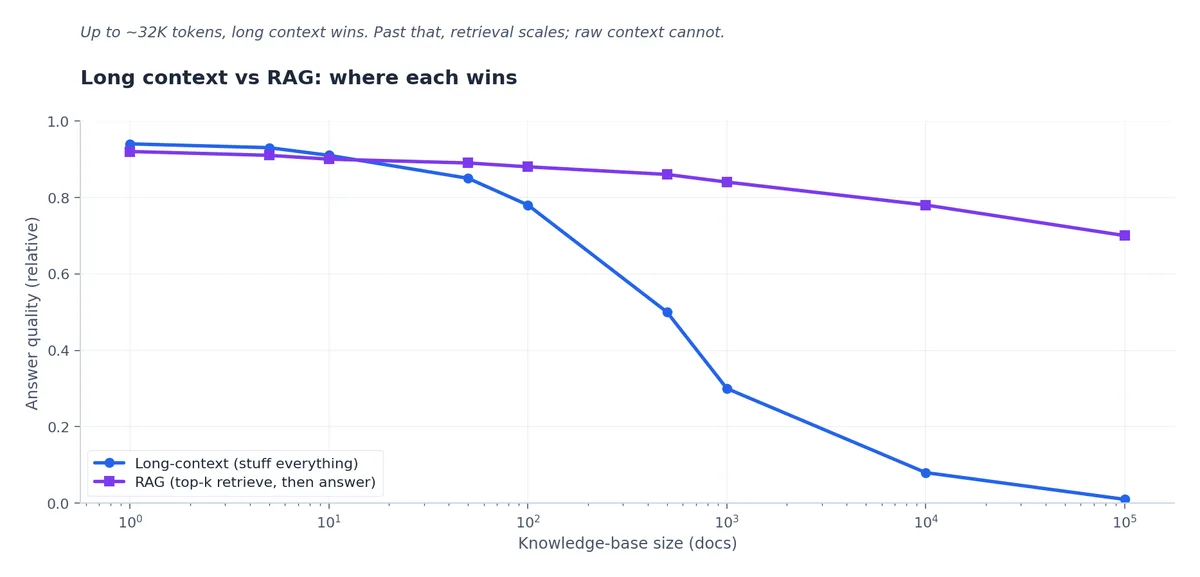
第 6 章 已介绍过长上下文技术,此处提供生产环境的决策矩阵:
| 属性 | RAG 胜出 | 长上下文胜出 |
|---|---|---|
| 语料库大小 | 大(>1M tokens) | 小(<200K tokens) |
| 查询延迟预算 | <2s | 5–30s 可接受 |
| 单次查询成本 | $0.001–0.05 \| $ 0.10–2.00 | |
| 来源归属 | 重要 | 不需要 |
| 问题局部性 | 是(定位单一事实) | 否(综合全文) |
| 更新频繁 | 是 | 否(每次变更需重填充) |
2024 年曾流行“长上下文杀死 RAG”的说法,但从成本角度看显然站不住脚。以 Claude-4.5-Sonnet 定价($3/Mtok input)计算,100K-token prompt 仅输入成本就达 $ 0.30/query;而 RAG 通常只需 $0.001–0.01/query(含嵌入与 LLM 成本)。对日均 100 万查询的产品而言,二者日成本分别为 $ 300 与 $3000–10000。
更合理的方案往往是两者结合:先用 RAG 定位候选 chunk,再将候选集与合成 prompt 一同送入长上下文模型。这正是多数“2026 生产级 RAG”系统的实际架构。
万+ 文档规模下的失败模式#
嵌入漂移(Embedding drift):语料格式在三个月后变更(新模板、新词汇),导致新文档因向量分布偏移而难以被召回。防御措施:每月在 held-out 测试集上评估检索质量,当 MTEB 类指标漂移 >5% 时,重新嵌入整个语料库。
Chunk 边界切割:连贯答案被拆至两个 chunk,任一 chunk 单独均无意义。症状表现为:答案明确存在于语料中,但检索召回率低。防御手段包括:设置 100–200 tokens 重叠、采用尊重文档结构(章节、段落)的切分策略,并抽样验证“chunk 是否能独立成义”。Late chunking 通过让嵌入携带上下文信息,部分缓解此问题。
查询分布漂移:用户开始提出未预料的问题,导致基于旧查询类型训练的重排序器性能下降。防御方案:记录查询日志,每周抽样并人工标注,每季度重训重排序器。
热门 chunk 主导(Hot chunks dominating):少数 chunk(如退货政策 FAQ)因嵌入靠近聚类中心,被无关查询频繁召回。防御方法:对过度检索的 chunk 施加惩罚(BM25 的 IDF 天然具备此特性;密集检索需显式引入多样性机制如 MMR)。
仅含元数据的 Chunk:如“4.2.1 节”这类 chunk 语义匹配广泛但无实质内容。防御策略:过滤内容密度过低的 chunk(如字母数字字符 <100 或独特非停用词 <5)。
因 ingestion bug 导致的重复 Chunk:曾遇一案例,30% chunks 因脚本重复运行而近似重复。Top-K 检索返回同一内容的多个副本,LLM 误判为多方确认而自信输出错误答案。防御措施:在 ingestion 阶段去重(MinHash、SimHash 或 normalize+hash)。
嵌入更新滞后(Embedding stale-vs-document update lag):源文档已更新,但嵌入未重算,导致检索返回旧版本。防御方案:为每文档维护 content_hash,仅当 hash 变化时重索引,并将索引-源新鲜度纳入 SLO 监控。
重排序器过度自信(Reranker overconfidence):Cross-encoder 重排序器输出的分数未经校准,在跨域场景下高分未必更准。防御建议:避免基于绝对分数设阈值,而应关注单次查询内的相对排名。
评估:不测量就等于白做#
我见过太多团队在无评估集的情况下上线 RAG,随后耗费数周调整 prompt 与 chunk 大小,却无任何指标证明改进有效。务必先构建评估集,哪怕仅有 50 个问题。人工标注黄金标准 chunk 与答案,然后追踪以下指标:
- Retrieval recall@k:检索器是否返回了包含答案的 chunk?
- Reranking precision@k:重排序后 top-k 中,含答案 chunk 的比例?
- Answer faithfulness:答案是否严格基于检索内容(而非 LLM 先验知识)?
- Answer correctness:是否与黄金答案一致?
后两项可用 LLM-as-judge 评估(详见第 10 章 );前两项为纯检索指标,易于计算且对调试最具指导性。
对于更大规模评估集(>500 问题),RAGAS(RAG Assessment,2023 开源)与 TruLens 等工具可基于 LLM-as-judge 自动化四指标 pipeline。它们是合理起点,但其指标可能被 prompt 调优“欺骗”,人工标注的黄金子集仍是唯一完全可信的信号。
生产架构建议#
针对 2026 年典型的 10 万–100 万文档 RAG 部署:
- 存储:Postgres + pgvector 存储向量与元数据;搭配
pg_trgm或 Elasticsearch 支持 BM25。单区域写入,查询使用读副本。 - 嵌入器:索引阶段用 L4 GPU 自托管 BGE-M3(一次性开销);查询嵌入调用 Cohere 或 OpenAI API(低延迟、免运维)。
- 检索:混合密集 + BM25,RRF 融合,取 top-50 候选。
- 重排序:L4 GPU 自托管 BGE-reranker-v2-m3(或简化使用 Cohere Rerank API),top-50 → top-5。
- 生成器:通用场景用 Claude-4.5-Sonnet 或 Qwen3-Max;成本敏感场景用自托管 Qwen3-32B。
- 评估:维护 100–200 个人工标注问题,每次部署必跑,若 recall@10 或 faithfulness 下降 >5% 则告警。
- 监控:记录每条查询的检索结果、生成内容、延迟与成本;抽样 1% 供人工复核。
该 pipeline 在多数负载下可实现 <1s p95 延迟与 <$0.01/query 成本,单 Postgres 实例可扩展至约 1000 万文档,并具备优雅降级能力。
Query 侧改写与 agentic retrieval(2026)#
上面所有内容都在优化索引侧,即文档如何变得可被检索。而 2026 年前沿的另一半在查询侧:用户原始的提问往往是个糟糕的检索 key,最高质量的系统也不再把检索当成一次性的前向传播。
HyDE(Hypothetical Document Embeddings)。简短、模糊的 query 与冗长技术 chunk 之间存在词汇错配,直接嵌入效果很差。HyDE 的做法是先让 LLM 虚构出一篇看似合理的答案文档,再用这篇假想文档(而非原始 query)去做嵌入检索。生成的文本捕捉到了好答案的语义形态,其向量因而更接近真实的答案 chunk。实测 zero-shot 检索:在 DL-19 上 nDCG@10 达到 61.3,而 Contriever 基线仅 44.5,仅多一次 LLM 调用、无需标注数据,就逼近了 fine-tuned 检索器的质量。最适合 query 简短而文档密集的专业语料。
Multi-query rewriting(多查询改写)。不再只用一个 query,而是生成多个改写版本,分别检索后对并集做 RRF 融合,从而为含糊或表述不全的问题扩大召回面。朴素做法会失效,因为 LLM 生成的改写常常高度雷同;DMQR-RAG(Li et al., 2024 )显式最大化各改写之间的多样性,在 AmbigNQ 上报告 Hits@5 为 88.1,而普通改写仅 81.1。在多轮对话里,改写器真正的活儿是在检索发生之前,先结合对话历史把代词和省略的上下文补全。
Iterative / agentic retrieval(迭代式/智能体检索)。相比线性的「retrieve → rerank → generate」流水线,最大的转变是把何时停止检索的控制权交给模型本身。Self-RAG 训练生成器输出 reflection token,自行判断是否需要检索、每段召回内容是否相关、以及自己的草稿是否被证据支撑。CRAG(Corrective RAG,Yan et al., 2024 )则加了一个轻量的检索评估器:当召回集置信度偏低时,触发 query 分解与 web-search 回退,而不是硬用薄弱上下文生成,在 PopQA/Biography/PubHealth 上较朴素 RAG 提升 4–15%。Adaptive RAG 按 query 复杂度路由:一个小分类器把简单事实类 query 直接送去生成(不检索),中等的走单步检索,困难的多跳问题进入迭代循环,这是 2026 年从业者在混合负载下平衡成本与精度的共识做法。
代价是每条 query 的延迟和额外 LLM 调用,所以我把这些都收在 Adaptive-RAG 路由后面:只对真正需要的问题才付 HyDE/多查询/迭代的开销。另外,2026 年的评估工具(RAGAS、DeepEval、Braintrust)反复强调一点:在一个过期索引上拿到 0.95 的 faithfulness,给出的仍是错误的业务答案,context 的新鲜度与血缘才是第五个评估维度,而不只是 precision/recall。
总结#
Chunking 是最被低估的调节旋钮,chunk 大小必须匹配答案的实际分布位置。若语料为多语言,务必选用多语言嵌入模型;若有领域模型,则优先使用。始终采用 hybrid(dense + sparse + RRF)方案,并坚持重排序。长上下文适用于小语料与综合任务;其余场景 RAG 在成本与新鲜度上更具优势。在启动第二轮迭代前,务必先建立评估集。2024 年的新进展(Contextual Retrieval、GraphRAG、late chunking)虽拓展了技术边界,但基础原则依然适用。
下一章:生产规模的 prompt 工程。涵盖 Chain-of-thought、self-consistency、prompt 缓存经济学,以及 jailbreak/injection 威胁模型。
参考文献#
- Lewis et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” NeurIPS 2020. RAG 领域的开山之作。
- Gao et al., “Retrieval-Augmented Generation for Large Language Models: A Survey,” 2023.
- Khattab & Zaharia, “ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT,” SIGIR 2020.
- Robertson et al., “Okapi at TREC-3,” NIST 1995. BM25 算法的原始论文。
- Malkov & Yashunin, “Efficient and Robust Approximate Nearest Neighbor Search Using HNSW Graphs,” IEEE TPAMI 2018.
- Cormack et al., “Reciprocal Rank Fusion Outperforms Condorcet and Individual Rank Learning Methods,” SIGIR 2009.
- Microsoft Research, “GraphRAG: Unlocking LLM Discovery on Narrative Private Data,” 2024.
- Anthropic, “Introducing Contextual Retrieval,” 2024.
- Günther et al., “Late Chunking: Contextual Chunk Embeddings Using Long-Context Embedding Models,” 2024.
- Santhanam et al., “ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction,” NAACL 2022.
- Johnson et al., “Billion-scale similarity search with GPUs (FAISS),” 2017.
- BGE-M3 model card
- RAGAS evaluation framework
大模型工程 12 篇
- 01 大模型工程(一):Transformer 到 MoE
- 02 大模型工程(二):Tokenization 深度解析
- 03 大模型工程(三):预训练的规模之道
- 04 大模型工程(四):SFT、DPO 与 RLHF
- 05 大模型工程(五):推理优化核心技法
- 06 大模型工程(六):长上下文与 RoPE、YaRN
- 07 大模型工程(七):Function Calling 实战
- 08 大模型工程(八):RAG 架构与落地 当前
- 09 大模型工程(九):生产级 Prompt 工程
- 10 大模型工程(十):LLM-as-Judge 与评估
- 11 大模型工程(十一):安全与 Alignment
- 12 大模型工程(十二):生产落地与监控


