
大模型工程(十二):生产落地与监控
服务栈选型细化、给 LLM 做 autoscaling、延迟预算、prompt+completion 成本跟踪、多模型路由、FrugalGPT 级联、第一天就要的可观测性,以及能用的 on-call 模式。
这是最后一章。前面的章节涵盖了模型构建、提示工程、检索和评估,而本章聚焦于如何在不烧钱的前提下维持系统稳定运行。生产环境中的 LLM 服务更像一个高流量 Web 服务,而非传统机器学习服务——每次请求都会产生成本,且响应时间甚至可能长达两分钟。
本章会比之前更侧重具体数字。在生产环境中,一个功能究竟是盈利还是烧钱,往往取决于那些无人追踪的 2–5 倍成本差异。最实用的技能是能快速估算 LLM 工作负载的成本。以下数据基于 2025 年底至 2026 年初的市场情况,请在实际部署前核对最新定价。

端到端的服务栈#
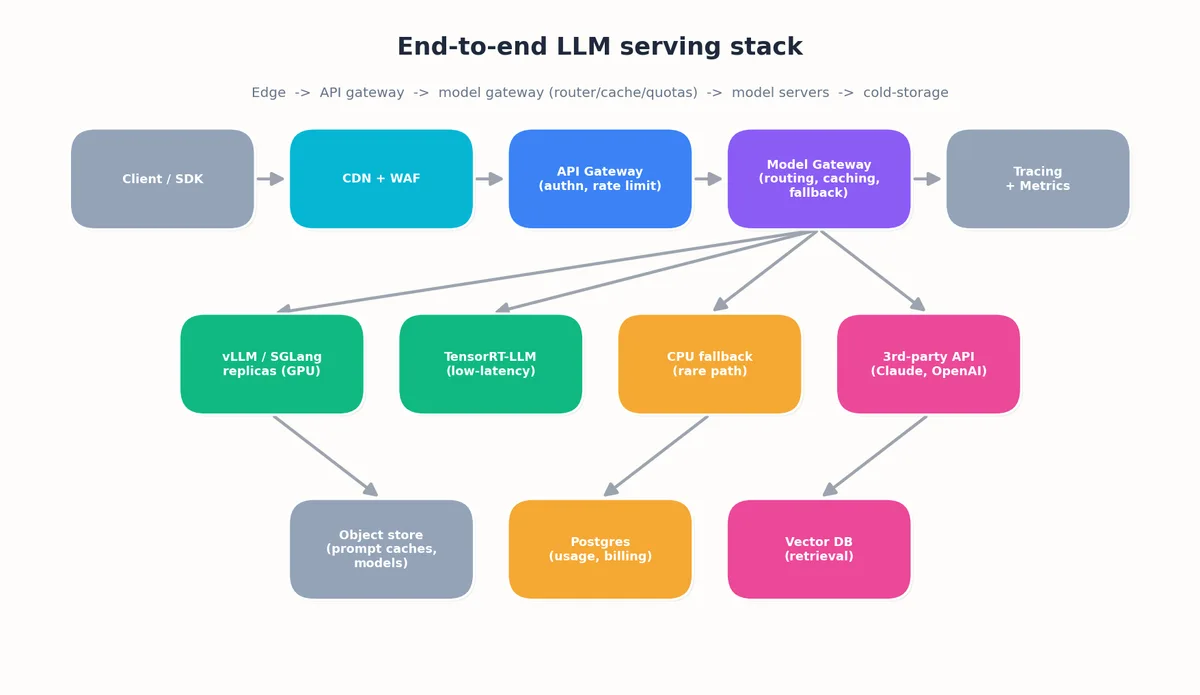
一个生产级 LLM 应用栈通常包含以下层级:
| |
其中大部分工程工作集中在应用服务器(App Server)和 LLM 网关(LLM Gateway)。前者负责业务逻辑,后者则将多个模型封装成统一的服务接口。
从项目第一天起,就应将 LLM 网关设计为独立服务。它的核心价值包括:
- 多模型路由:根据分类器结果,将部分请求发送给小而快的模型,其余请求交给大而慢的模型。
- 降级机制(Fallback):当主提供商返回 5xx 错误时,自动重试备用提供商。
- 成本追踪:记录每个请求的 prompt tokens、completion tokens、所用模型及对应美元成本。
- Prompt 缓存封装:即使底层提供商支持缓存,应用代码也不应关心缓存键的生成逻辑。
- A/B 测试:将可配置比例的流量导向新模型变体。
- 配额与熔断:当单个用户消耗成本显著超标时,自动终止其请求。
从零搭建这样一个网关大约需要几周时间。目前已有多个开源方案覆盖了大部分需求:
- LiteLLM:纯 Python 代理,集成 100 多家提供商,提供开箱即用的 OpenAI 兼容端点,并内置不错的成本追踪功能——是最快上手的选择。
- OpenRouter:托管式网关,通过单一 API 接入所有提供商,并内置模型市场。虽然单 token 成本略高于直连提供商,但能自动处理故障转移和价格套利。
- Cloudflare AI Gateway:部署在 CDN 边缘的托管代理,提供缓存、限流和分析能力。成本低廉且运维简单,但牺牲了一定灵活性。
- BentoML / Bento Cloud:更重型的框架,适合同时需要在网关后托管自训练模型的场景。
- Portkey、Langfuse Gateway:新兴方案,在可观测性方面表现突出。
建议尽早选定一个方案,但也要预留未来切换的可能性。网关是少数存在真实供应商锁定风险的组件(你会围绕其接口编写大量代码),因此务必保持接口简洁。
自建 vs 托管 API#
这是一个经典决策。截至 2026 年,实际情况如下:
使用托管 API 的场景:
- 需要前沿模型质量(如 GPT-5、Claude-4.5、Gemini-3),但缺乏 GPU 资源自行托管;
- 月调用量低于约 10 亿 tokens——在此规模下,托管通常更便宜;
- 对延迟要求宽松(TTFT > 500 ms 可接受);
- 无法投入专职工程师维护 GPU 运维。
选择自建的场景:
- 月调用量超过 10 亿 tokens,且开源模型能满足质量要求(如 Qwen3-32B+、LLaMA-3.3-70B+);
- 有严格的数据驻留合规要求;
- 需要持续稳定的 <100 ms TTFT;
- 存在特定的微调需求。
盈亏平衡点大致在月调用量 10 亿 tokens(对应 Qwen3-32B 级别负载)。低于此阈值时,计入工程人力成本后,托管 API 通常更经济;高于此阈值时,租用或自购 GPU 的自建方案可节省 3–10 倍成本。
一个常见误区是 GPU 利用率不足。例如,一个 4×H100 集群若长期仅以 30% 利用率运行,其单 token 成本反而会高于 OpenAI API。目标应是维持 70% 以上的持续吞吐量。
2025–2026 年流行的一种实用混合模式是:用自建的小型开源模型处理大部分低成本流量,仅将最难的 5–10% 请求路由至托管的前沿 API。这样既能享受自建的大部分成本优势,又能在关键场景保留前沿模型的质量。路由决策由一个轻量级分类器完成(详见下文“多模型路由”部分)。
多模型路由与 FrugalGPT#

Chen 等人在 2023 年发表的论文《FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance》中正式提出了“先路由、后级联”的模式。其核心洞见是:大多数 LLM 查询其实很简单,小型廉价模型即可胜任;只有少数查询真正需要前沿模型。如果能高效区分这两类请求,就能在几乎不损失质量的前提下,将成本降低 5–10 倍。
FrugalGPT 提出了三种策略:
- Prompt 适配:压缩提示、移除冗余上下文、批量处理相关请求;
- LLM 级联:先尝试最便宜的模型,让其输出置信度信号,若置信度低则回退到更昂贵的模型;
- 模型路由:通过一个预训练的分类器,在请求初期就选择合适的模型。
其中,级联模式在生产中最常被采用。伪代码如下:
| |
难点在于如何获取可靠的置信度信号。可行方案包括:
- 自报置信度:直接询问模型“请对你的回答给出 1–5 分的置信度”。该信号与正确性仅有微弱相关性,且噪声较大;
- 基于 Logprob:利用答案片段的 logprob 值。效果尚可,但前提是能控制采样过程;
- 采样一致性:对廉价模型采样 3–5 次,若结果一致则采纳,否则升级处理;
- 任务专用验证器:例如代码任务检查“是否通过公开测试”,数学任务判断“答案是否在合理范围内”。
Hu 等人(2024)提出的 RouteLLM 方法,则是在离线偏好数据上训练一个 (query, best-model) 分类器,用于预测最优模型。经 RouteLLM 训练的路由器在 MT-Bench 上能达到 GPT-4 95% 的质量,成本仅为 26–44%。
在实际生产中,路由决策往往简化为两个问题:“这个查询是否简单?”(若是,走廉价路径)和“是否属于已知的高难度模式?”(若是,走高性能路径)。中间地带则使用默认模型。一个包含 50 条规则的启发式分类器就能捕获 80% 的成本节省;而学习型路由器最多可提升至 90%。
缓存层级#
三层缓存至关重要,且效果叠加:
- 提供商侧 Prompt 缓存(见第九章):针对重复 prompt 前缀复用 KV Cache,由 Anthropic、OpenAI、DeepSeek、Google 等提供,可使缓存部分成本降低 90%;
- 应用侧语义缓存:当两个用户查询语义相似时,直接返回缓存答案。常用工具包括 GPTCache(基于 FAISS 的原始实现)、Redis Semantic Cache、MemCache + 自定义 embedding 查找等。在 FAQ 类场景中命中率达 30–70%,但在开放式聊天中几乎为零;
- 确定性函数的结果缓存:若 LLM 输出用于下游流程(如分类、信息抽取),且输入完全相同,则直接缓存输出结果(以输入哈希为键),避免重复调用。
GPTCache 值得重点关注。其工作流程是:用小型 embedding 模型对每个用户查询进行嵌入,与缓存库计算余弦相似度,若超过阈值(通常为 0.95)则返回缓存答案。阈值是一个可调参数——越高则假阳性越少,但命中率也越低。例如,在客服机器人回答常见问题的场景中,设为 0.92 即可节省约 50% 成本;而在代码生成等高度个性化的任务中,语义缓存几乎无效。
这种组合性至关重要:Prompt 缓存降低单次调用成本,语义缓存减少调用次数,二者效果相乘。
LLM 负载的自动扩缩容#

LLM 服务的自动扩缩容比无状态 Web 服务困难得多,原因有三:
- 模型加载耗时数分钟:一个搭载 70B 模型的新 vLLM 实例需 2–4 分钟完成权重加载和预热。若流量峰值仅持续 10 分钟,靠扩容响应显然太慢;
- GPU 按小时计费,而非按请求:为应对 5 分钟的流量尖峰而启动新实例,会导致其余 55 分钟资源闲置;
- 连续批处理(Continuous Batching)的负载非线性:vLLM 服务器在 50% 和 90% 负载下的延迟表现差异巨大,其安全运行点远低于传统 CPU 服务的推荐值。
实用策略包括:
- 定时预热:若流量在每天 9 点规律性激增,则提前 10 分钟扩容;
- 保守扩容,激进缩容:在 GPU 利用率达 60% 时扩容,降至 30% 时缩容(与常规 Web 服务策略相反);
- 缓冲降级:当自建服务达到容量上限时,将溢出流量自动切至托管 API。虽单位成本更高,但能吸收突发流量而不浪费资源;
- 多模型保底:即使在低峰期,也至少保留每个模型的一个在线副本,避免高昂的冷启动开销;
- 带背压的队列:服务器过载时,通过 per-user 公平调度器排队请求,并返回带
Retry-After头的 429 响应,而非让所有用户的延迟崩溃。
vLLM 支持 --max-num-seqs(最大并发请求数)和 --max-num-batched-tokens(每步最大 token 吞吐量)。应根据延迟目标而非吞吐最大化来调整这些参数。
延迟预算拆解#

面向用户的聊天产品,其典型延迟预算如下:
| Component | Budget (ms) | Notes |
|---|---|---|
| Network in | 50 | 地理距离决定 |
| API gateway / auth | 10 | 应极快 |
| 应用服务器逻辑 | 50 | RAG 嵌入、工具调度 |
| RAG retrieval | 100 | 向量库 + 重排序器 |
| LLM gateway overhead | 5 | 仅路由开销 |
| LLM TTFT (队列 + 预填充) | 300 | 模型自身耗时 |
| Network out | 50 | 同入网 |
| 首 Token 总耗时 | ~565 ms | 目标低于 1 秒 |
| LLM ITL (解码) | 25 | 每 token,维持 40 tok/s |
| Network buffering | 20 | 平滑传输 |
最关键的两个指标是 TTFT(Time To First Token)和 ITL(Inter-Token Latency)。TTFT 决定了用户感知的“是否响应”,ITL 则影响流式输出后的阅读速度。2026 年的行业经验如下:
- 聊天:TTFT < 800 ms 视为“即时”,< 2 秒尚可接受;
- 语音交互:TTFT 必须 < 300 ms 才能实现自然对话;
- 代码补全:TTFT > 200 ms 用户就会放弃;
- 批量/智能体任务:TTFT 可放宽至 5–30 秒,用户能够容忍。
首 token 输出后,用户看到流式响应,通常可接受 5–10 秒内 40–60 tok/s 的速度。总响应时间取决于输出长度:例如 200 tokens 以 40 tok/s 生成需 5 秒,加上 600 ms TTFT,端到端约 5.6 秒。
如何分配延迟预算:
- 重排序(Reranking):投入 50–100 ms 非常值得(见第八章);
- 推测解码(Speculative Decoding):可降低 ITL 50–100 ms(见第五章),回报率高;
- 工具调用:一个 200 ms 的工具调用会阻塞模型。应尽可能并行化,并激进缓存;
- 推理/思考:思考型模型会在首 token 前增加 1–10 秒延迟,仅用于真正需要深度推理的任务。
对于延迟敏感路径,务必实测各环节耗时。实际情况往往出人意料:我曾见过一个“慢”功能,LLM 仅耗时 200 ms,但 RAG 重排序器却花了 1.2 秒;另一个案例中,LLM 表现正常,但下游 JSON 序列化竟耗时 800 ms。优化前务必先做链路追踪。
从第一天起跟踪成本#

按请求粒度核算成本是不可妥协的底线。没有它,你将无法:
- 定位单个用户或功能引发的成本膨胀;
- 开展成本与质量的 A/B 测试;
- 在账单到来前预测支出;
- 在失控的智能体循环花掉 1000 美元前及时拦截。
每个请求至少应记录以下字段:
| |
按用户、功能、模型维度聚合数据,并设置告警:
- 单个用户 1 小时内支出超过中位数的 10 倍;
- 某功能单次调用成本周环比翻倍;
- 新模型的单次有效对话成本高于旧模型,尽管质量相当。
不妨做一道算术题。假设产品日均调用 1 万次 LLM,平均 4K 输入 + 500 输出 tokens,使用 Claude-4.5 Sonnet:
- 单次调用:$4 \cdot 4 + 15 \cdot 0.5 = 16 + 7.5 = 23.5$ thousand-tok-cents = $0.0235;
- 日成本:$235;
- 月成本:$7050。
现在启用 Prompt 缓存(4K 输入中有 3K 命中缓存):
- 单次调用:$4 \cdot 1 + 0.30 \cdot 3 + 15 \cdot 0.5 = 4 + 0.9 + 7.5 = 12.4$ thousand-tok-cents = $0.0124;
- 月成本:$3720,节省 $ 3330(47%)。
再叠加 30% 的语义缓存命中率:
- 月成本:$3720 \cdot 0.7 = $ 2604,总节省 $4446(63%)。
最后引入级联路由,60% 请求由 Qwen3-32B 处理(自托管,输入 $0.10/Mtok + 输出 $ 0.30/Mtok):
- 便宜路径单次:$0.10 \cdot 4 + 0.30 \cdot 0.5 = 0.55$ thousand-tok-cents = $0.00055;
- 混合月成本:$0.6 \cdot 7000 \cdot 0.00055 + 0.4 \cdot 7000 \cdot 0.0124 = $ 2.31 + $34.72 ... 每日。乘以 30 天 = $ 1110/月,比基线便宜 84%。
这些节省是复利效应。若无显式成本追踪,所有优化都将隐形。
超越成本的可观测性#

除标准可观测性(链路追踪、日志、指标)外,还需关注 LLM 特有指标:
- 分模型延迟与错误率;
- 自托管服务的每副本 token 吞吐量(此处下降常预示模型加载问题);
- 质量漂移:对 1% 请求采样,运行评估集评分流程,绘制通过率随时间变化曲线;
- Prompt 注入检测率:按用户统计注入尝试频率;
- 拒绝率:模型拒绝请求的比例。突变通常意味着攻击或模型退化;
- 缓存命中率:Prompt 缓存与语义缓存。命中率下降可能源于模板变更或流量分布偏移。
2026 年主流工具包括:
- Langfuse(开源):最适合 LLM 链路追踪,免费额度充足,易于自托管;
- Helicone:托管型 LLM 可观测平台,内置成本追踪,开箱即用;
- Phoenix (Arize):开源方案,专注 RAG 质量指标;
- OpenLLMetry:基于 OpenTelemetry,可集成至现有可观测栈(如 Datadog、Grafana);
- Datadog + 自定义仪表盘:若已使用 Datadog 且追求统一视图,此方案可行。
最经济有效的方案是:结构化记录每个请求,写入 ClickHouse 或 Snowflake,并构建仪表盘。无需托管产品也能获得 80% 的价值,但必须有纪律地记录关键字段。
行之有效的 On-call 模式#

以下是我凌晨 3 点会被叫醒的典型事件及应对预案:
LLM 提供商 5xx 错误激增:先查提供商状态页。若有备用提供商,立即切换。若主提供商 5 分钟内恢复则无需操作;若持续更久,联系客户经理。同时检查切换是否导致备用提供商成本飙升(有时贵 2 倍)。
P99 延迟 > 30 秒:通常由失控的工具调用或卡住的请求引起。检查是否被单一用户/功能主导。通常通过终止卡住请求并收紧超时即可解决。
成本激增:$/小时 突然上涨 10 倍。几乎总是某个用户的智能体失控所致。立即限流并排查根因。典型案例是智能体无步数限制地递归调用自身。
拒绝率突增:模型一夜之间多拒绝 30% 请求。要么是模型更新导致退化,要么遭遇协同攻击。应立即回滚模型并调查。
RAG 质量下降:事实一致性分数下跌 10%。通常因 embedding/index 版本不匹配,或新内容格式变化。需检查数据摄入管道。
自托管 GPU OOM:KV Cache 耗尽。应扩容或降低每请求 max_tokens。切勿盲目重启——下一批请求仍会 OOM。
提供商弃用通知:依赖的模型版本将在 90 天后移除。立即安排迁移测试,A/B 对比至少 2 周,并记录差异。
一份好的应急预案可将平均恢复时间(MTTR)从 30 分钟缩短至 3 分钟。务必在事发前写好预案。
值得命名的常见故障模式#
以下是非穷尽的生产事故清单:
- 提供商区域宕机:整个可用区(AZ)失效。缓解措施:网关层实现多区域故障切换;对托管 API,保持备用提供商待命。
- 限流级联:提供商对某客户限流后,应用激进重试耗尽全局配额。缓解:网关前实施 per-user 限流;重试采用指数退避加抖动;为每个提供商设置熔断器。
- Prompt 模板退化:看似无害的系统提示变更导致 Prompt 缓存失效(见第九章),账单一夜翻三倍。缓解:CI 中加入缓存感知的 diff 检查;缓存命中率下降时告警。
- 模型弃用突袭:OpenAI 宣布 gpt-4-turbo-0613 将在 60 天后退役,但评估集从未在替代模型上验证。缓解:订阅提供商弃用通知;每季度进行迁移演练。
- 静默质量漂移:托管模型收到未文档化更新,在特定用例上性能退化。缓解:每周用评估集测试生产流量样本;对比历史基线;下降超 5% 时告警。
- 智能体循环失控:智能体调用工具出错后反复重试,最终自相矛盾并累积 $500 费用。缓解:设置每对话步数上限;设置每对话成本上限;单会话成本超 $ X 时告警。
迁移实战手册#
模型迁移是最被低估的生产技能。有效流程如下:
- Shadow 流量 3–7 天:新模型接收请求副本但不返回结果,仅用于离线质量对比;
- Canary 1% 流量 3–7 天:新模型服务 1% 真实流量,监控延迟、错误率、成本、拒绝率、满意度。无退化则继续;
- 分阶段放量(5% → 25% → 50% → 100%),耗时 1–2 周,每步均需满足 SLA;
- 切换后保留旧模型热备 30 天,回滚只需一次配置变更;
- 30 天稳定运行后才下线旧模型。
跳过 shadow + canary 是“上线新模型后客诉激增”的最常见原因。这是流程纪律问题,而非技术问题。
不同部署形态的成本(2025 年末粗略数据)#
| Setup | $/Mtok input \mid$ /Mtok output | Notes | |
|---|---|---|---|
| Claude-4.5-Sonnet API | $3 \mid$ 15 | 高质量 | |
| GPT-4o API | $2.50 \mid$ 10 | 高质量 | |
| Qwen3-Max API | $1.40 \mid$ 5.60 | 高质量,更便宜 | |
| Gemini-2.5-Pro API | $2.50 \mid$ 10 | 高质量,长上下文 | |
| DeepSeek-V3 API | $0.14 \mid$ 0.28 | 便宜,擅长数学/代码 | |
| Self-host Qwen3-32B FP8 (1xH100) | $0.10 \mid$ 0.30 | 70% 利用率 | |
| Self-host LLaMA-3.3-70B FP8 (2xH100) | $0.30 \mid$ 0.90 | 70% 利用率 | |
| Self-host Qwen3-235B-A22B (8xH100) | $0.50 \mid$ 1.50 | 70% 利用率 | |
| Open-router 池化小模型 | $0.15 \mid$ 0.50 | 最便宜 | |
| Anthropic Batch API (50% 折扣) | $1.50 \mid$ 7.50 | 24 小时 SLA | |
| OpenAI Batch API (50% 折扣) | $1.25 \mid$ 5 | 24 小时 SLA |
输出成本通常比输入高 3–5 倍,因为输出是串行解码(内存受限)。对于生成长文本的应用(如摘要、报告、代码),切换至输出成本更低的模型,往往比优化模型本身更有效。
Batch API 的 50% 折扣(适用于 24 小时 SLA 任务)是最被低估的成本杠杆。若工作负载可容忍次日完成(如隔夜报告、批量内容审核、评估集生成),使用批处理可直接减半支出。迁移通常只需一行 API 变更。
打造高性价比生产级 LLM 产品的最终方案#
若我在 2026 年年中启动一个生产级 LLM 产品,会采取以下策略:
- 前 6–12 个月默认使用托管 API,根据延迟、质量和语言需求选择提供商;
- 从第一天起构建 LLM 网关,即使初期只包装单一提供商,未来也必然需要它;
- 精确追踪每次请求成本至小数点后四位(如 $0.0001),每周汇总分析;
- 在迭代 Prompt 前,先构建包含 200 个问题的评估集;
- 只要涉及外部知识,就叠加检索 + 重排序层;
- 激进实施缓存策略:提供商侧 Prompt 缓存、应用层语义缓存、确定性流程结果缓存;
- 当单次 Prompt 无法满足用户需求时,引入工具调用;
- 将 60–80% 的简单查询路由至廉价模型,仅将难题交给前沿模型;
- 当月 token 用量突破 10 亿且流量稳定时,再考虑自建;
- H100 上使用 FP8 量化,A100/L40s 上使用 AWQ-INT4;
- 任何可接受 24 小时 SLA 的任务,一律使用 Batch API;
- 提前部署安全栈(safety stack),不要等问题发生后再补救。
做到这些,足以支撑产品上线并持续增长,同时避开那些拖垮多数 LLM 产品的技术债。
总结#
这十二章完整覆盖了构建现代 LLM 产品的全流程:
- 架构
- 分词
- 预训练
- 后训练
- 推理优化
- 长上下文
- 函数调用
- RAG
- Prompting
- 评估
- 安全
- 生产落地
若只记住三点:数据质量决定一切(第三、四章),分词与 KV Cache 是成本大头(第二、五章),没有评估集和成本追踪就别想上线(第十、十二章)。其余皆为执行细节。
延伸阅读推荐:NLP 系列 深入讲解基础理论,Aliyun Bailian 系列 展示特定云平台上的实践模式,Aliyun PAI 系列 则聚焦阿里云上的训练-服务基础设施。
感谢读到这里。去构建一些真正能跑起来的东西吧。
大模型工程 12 篇
- 01 大模型工程(一):Transformer 到 MoE
- 02 大模型工程(二):Tokenization 深度解析
- 03 大模型工程(三):预训练的规模之道
- 04 大模型工程(四):SFT、DPO 与 RLHF
- 05 大模型工程(五):推理优化核心技法
- 06 大模型工程(六):长上下文与 RoPE、YaRN
- 07 大模型工程(七):Function Calling 实战
- 08 大模型工程(八):RAG 架构与落地
- 09 大模型工程(九):生产级 Prompt 工程
- 10 大模型工程(十):LLM-as-Judge 与评估
- 11 大模型工程(十一):安全与 Alignment
- 12 大模型工程(十二):生产落地与监控 当前


