
优化理论(七):二阶方法
二阶方法通过利用曲率突破 $\sqrt{\kappa}$ 瓶颈;我们证明牛顿法的局部二次收敛性,从割线条件与低秩更新导出 BFGS,详解适用于中等规模机器学习的 L-BFGS 双循环递推,分析带狗腿法求解的信任域子问题。
一阶方法在达到 $\epsilon$ -精度时,迭代次数的上界为 $O(\sqrt{\kappa})$ (见第 05 篇文章)。二阶方法通过引入曲率信息突破这一瓶颈:牛顿法具有二次局部收敛性,每步迭代使有效数字位数翻倍;而拟牛顿法在不显式计算 Hessian 矩阵的前提下,仍能保持大部分收敛速度。
代价在于每次迭代的计算开销:牛顿法每步需求解一个 $n \times n$ 线性方程组(复杂度 $O(n^3)$ );BFGS 方法需维护一个 $n \times n$ 矩阵(每步更新与存储均为 $O(n^2)$ );L-BFGS 则仅需 $O(mn)$ 内存(其中历史长度 $m$ 通常取 5–20)。
本文将给出各类算法的收敛性证明,从割线条件出发推导 BFGS 更新公式,逐行解析 L-BFGS 的双循环递归(two-loop recursion),并阐释信赖域方法(该方法使用相同的 Hessian 信息,但采用不同的全局化策略)。
上一篇结尾我们停在一阶方法的极限:要达到 $\epsilon$ -精度,迭代次数最少 $O(\sqrt{\kappa})$ 。这个 $\sqrt{\kappa}$ 是个硬墙,只要你只用一阶信息(梯度),就别指望更快。
二阶方法的想法很直接:既然每一步多花点时间算 Hessian,那就让每一步走得更聪明。结果是牛顿法的局部二次收敛,每次迭代有效数字位数翻倍,这种速度一阶方法做梦都达不到。
代价当然也很现实:每步要解一个 $n \times n$ 线性系统($O(n^3)$ );BFGS 维护一个 $n \times n$ 矩阵($O(n^2)$ );L-BFGS 妥协一下只存最近 $m$ 步信息,把内存压到 $O(mn)$ 。
本文按这个由贵到便宜的顺序走:先把牛顿法的几何讲清楚,再用割线条件推 BFGS,再把 L-BFGS 的双循环递推一行一行写出来,最后讲信赖域,它换了一种全局化的思路,但用的还是同一份 Hessian 信息。
你将学到什么#
- 牛顿法:从二阶泰勒展开推导其迭代格式,并在标准假设下证明其局部二次收敛性;
- 全局化策略:线搜索法(满足 Wolfe 条件)与信赖域法;
- 割线条件(secant condition)及其对拟牛顿更新的约束;
- BFGS 更新是唯一满足割线条件、对称性与正定性的秩-2 更新;附简明推导;
- L-BFGS 双循环递归:为何可在 $O(mn)$ 时间内计算 $H_k g_k$ ,且全程无需显式构造 $H_k$ ;
- 信赖域方法:子问题形式、柯西点(Cauchy point)、狗腿法(dogleg method),及其适用场景。
前置知识#
第 01 篇 –第 02 篇 (凸分析、光滑性、强凸性);线性代数熟练:矩阵求逆、秩-1 更新、Sherman–Morrison 公式。
牛顿法(Newton’s method)#
推导#
$$ f(x_k + d) \approx f(x_k) + \nabla f(x_k)^\top d + \tfrac{1}{2} d^\top \nabla^2 f(x_k) d. $$ $$ d_k^N = -[\nabla^2 f(x_k)]^{-1} \nabla f(x_k). $$此即牛顿方向。纯牛顿迭代公式为 $x_{k+1} = x_k + d_k^N$ 。
几何解释:牛顿法用局部二次模型近似目标函数 $f$ ,并直接跳转至该二次模型的极小点。若 $f$ 本身即为二次函数,则牛顿法一步收敛。

局部二次收敛性#
$$ \|x_{k+1} - x^\star\|_2 \leq \frac{L}{2 \mu} \|x_k - x^\star\|_2^2. $$ $$ x_{k+1} - x^\star = x_k - x^\star - [\nabla^2 f(x_k)]^{-1} \nabla f(x_k). $$ $$ \nabla f(x_k) = \nabla f(x_k) - \nabla f(x^\star) = \int_0^1 \nabla^2 f(x^\star + t(x_k - x^\star)) (x_k - x^\star) \, dt. $$ $$ x_{k+1} - x^\star = [\nabla^2 f(x_k)]^{-1} \int_0^1 [\nabla^2 f(x_k) - \nabla^2 f(x^\star + t(x_k - x^\star))] (x_k - x^\star) \, dt. $$定理:设 $f$ 二阶连续可微,其 Hessian 矩阵 $\nabla^2 f$ 是 $L$ -Lipschitz 连续的(即 $\|\nabla^2 f(x) - \nabla^2 f(y)\| \leq L \|x - y\|$ ),且在驻点 $x^\star$ 处满足 $\nabla^2 f(x^\star) \succeq \mu I$ 。则当初始点 $x_0$ 足够接近 $x^\star$ 时,牛顿法满足如下收敛界:
被积函数的范数满足 $\| \cdot \| \leq L (1 - t) \|x_k - x^\star\|_2$ ;积分后得其范数上界为 $\frac{L}{2} \|x_k - x^\star\|_2^2$ 。再结合当 $x_k$ 充分接近 $x^\star$ 时 $\|[\nabla^2 f(x_k)]^{-1}\| \leq 1/\mu$ ,即可得证。$\blacksquare$
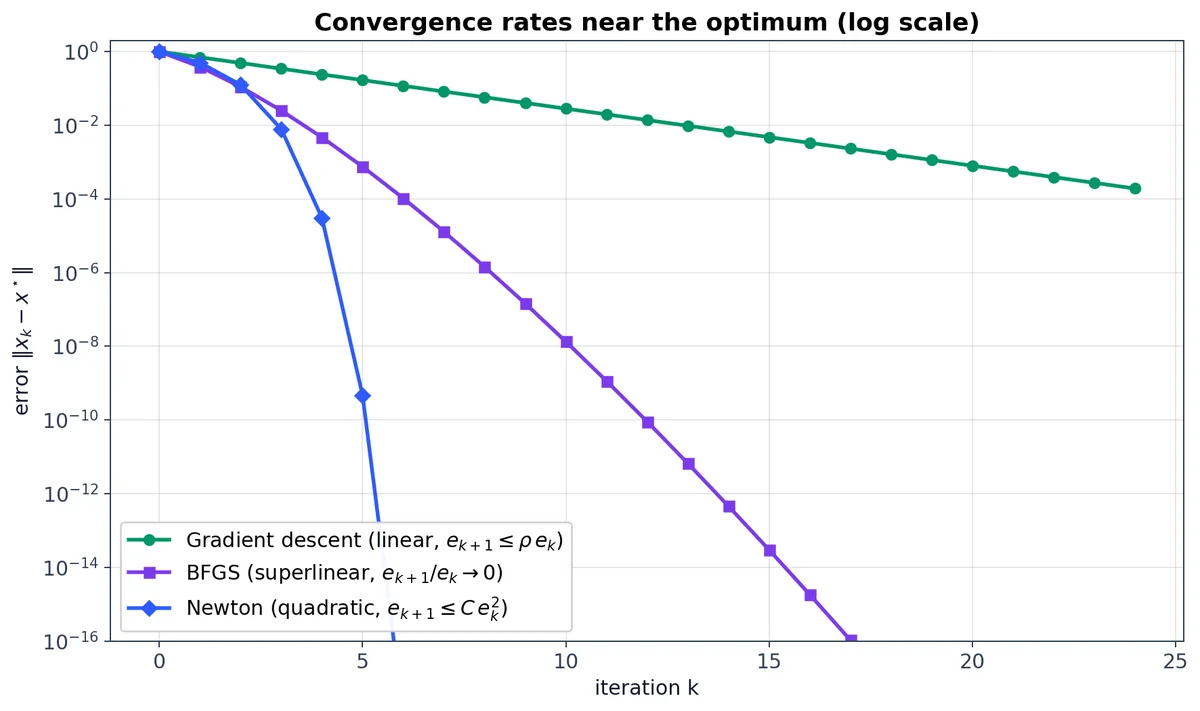
“有效数字位数倍增”现象在此具象化:若 $\|x_k - x^\star\| = 10^{-3}$ ,则 $\|x_{k+1} - x^\star\| \leq C \cdot 10^{-6}$ ,进而 $\leq C^2 \cdot 10^{-12}$ ,依此类推。从误差 $10^{-3}$ 收敛至 $10^{-12}$ 仅需 2 次迭代,而一阶方法则需约 $\log(10^9) / \log(\sqrt{\kappa})$ 次迭代。
关键难点:全局化(Globalization)#
上述收敛定理仅保证牛顿法在 $x^\star$ 的邻域内具有快速收敛性。远离 $x^\star$ 时,牛顿方向甚至可能不是下降方向(尤其当 $\nabla^2 f \not\succ 0$ ),且步长过大导致发散。
标准解决方案是阻尼牛顿法(damped Newton):取 $x_{k+1} = x_k + \alpha_k d_k^N$ ,其中步长 $\alpha_k$ 通过线搜索选取,使其满足Wolfe 条件:
- 充分下降条件(Armijo 条件):
$f(x_k + \alpha d_k) \leq f(x_k) + c_1 \alpha \nabla f(x_k)^\top d_k$ ,通常取 $c_1 = 10^{-4}$ ; - 曲率条件(Curvature condition):
$\nabla f(x_k + \alpha d_k)^\top d_k \geq c_2 \nabla f(x_k)^\top d_k$ ,对牛顿类方法通常取 $c_2 = 0.9$ 。
一旦迭代点 $x_k$ 进入 $x^\star$ 的邻域,单位步长 $\alpha_k = 1$ 即满足 Wolfe 条件,算法自动切换至二次收敛阶段。

当 Hessian 矩阵不定时#
若 $\nabla^2 f(x_k) \not\succeq 0$ ,牛顿方向可能指向上升方向。常见修正策略包括:
- 修正 Cholesky 分解(Modified Cholesky):对 $\nabla^2 f$ 加上最小的对角扰动矩阵 $E$ ,使得 $\nabla^2 f + E \succ 0$ ;所得方向仍是下降方向,且尽可能贴近原始牛顿方向;
- 信赖域法(Trust region)(见第 4 节 ):显式限制步长大小,并在信赖域内优化方向;该方法天然适用于处理不定 Hessian;
- 三次正则化(Cubic regularization)(Nesterov & Polyak, 2006):改而最小化模型
$\nabla f^\top d + \tfrac{1}{2} d^\top \nabla^2 f \, d + \tfrac{M}{6} \|d\|^3$ 。该方法具备全局收敛性,且可收敛至二阶临界点(即梯度为零、Hessian 半正定的点)。
拟牛顿法:割线方程#
牛顿法需要计算并存储 Hessian 矩阵 $\nabla^2 f$ ,其存储代价为 $O(n^2)$ ,每步求逆代价高达 $O(n^3)$ 。拟牛顿法仅利用梯度差构造 Hessian 近似 $B_k \approx \nabla^2 f(x_k)$ ,从而隐式捕捉 $\nabla f(x_k) - \nabla f(x_{k-1})$ 中所蕴含的曲率信息。
割线条件#
$$ \nabla f(x_{k+1}) - \nabla f(x_k) = A (x_{k+1} - x_k). $$ $$ B_{k+1} s_k = y_k. \tag{Sec} $$任何拟牛顿更新都应满足此条件:新近似矩阵 $B_{k+1}$ 必须能复现最近一步中观测到的曲率。
BFGS:标准拟牛顿更新#
BFGS(Broyden–Fletcher–Goldfarb–Shanno)更新是满足以下四条性质的、对 $B_k$ 的唯一秩-2 更新:
- 满足割线条件 (Sec);
- 对称性:$B_{k+1} = B_{k+1}^\top$ ;
- 若 $B_k$ 正定且 $y_k^\top s_k > 0$ (该条件在步长满足曲率 Wolfe 条件时恒成立),则 $B_{k+1}$ 保持正定;
- 在满足 (Sec) 和对称性的约束下,使加权 Frobenius 范数 $\|B_{k+1} - B_k\|$ 最小化。
此即实际编程中采用的形式。
一句话解释 BFGS 为何有效#
若 $B_k$ 已在已遍历方向 $s_0, \ldots, s_{k-1}$ 上较好地逼近了 $\nabla^2 f$ ,则 BFGS 更新既保留了这些历史信息,又融入了新方向 $s_k$ 。当应用于二次函数且经历 $n$ 个线性无关步长后,BFGS 可精确重构真实 Hessian 矩阵,此后行为与牛顿法完全一致,这一性质称为 有限步终止性(finite termination property)。
对非二次函数 $f$ ,BFGS 具备 超线性收敛性:$\|x_{k+1} - x^\star\| / \|x_k - x^\star\| \to 0$ 。其严格证明(Dennis & Moré, 1974)较为精巧;直观理解是:当迭代点 $x_k \to x^\star$ 时,割线条件迫使 $B_k$ 在算法实际使用的那些方向上,渐近逼近 $\nabla^2 f(x^\star)$ 。
L-BFGS:有限内存法#
当 $n = 10^6$ 时,标准 BFGS 方法仅存储近似 Hessian 矩阵的逆 $H_k$ 就需要 $10^{12}$ 个浮点数(约 8 TB)。L-BFGS(“有限内存” BFGS)仅保留最近的 $m$ 对向量 $(s_i, y_i)$ ,通常取 $m = 5$ 至 $20$ ,并在需要时通过 双循环递推(two-loop recursion) 动态重构作用 $H_k g$ 。
双循环递推#
给定:
- 当前梯度 $g = \nabla f(x_k)$
- 历史信息 $\{(s_i, y_i)\}_{i = k-m}^{k-1}$ ,其中 $\rho_i = 1 / (y_i^\top s_i)$
- 初始 Hessian 逆近似 $H_k^0$ (常用选择为 $H_k^0 = (s_{k-1}^\top y_{k-1} / y_{k-1}^\top y_{k-1}) I$ ,即单位矩阵的标量倍数)
该递推以 $O(mn)$ 时间复杂度计算 $H_k g$ :
| |
每个循环各访问每对 $(s_i, y_i)$ 一次;总计算量为 $4mn$ 次内积加一次向量缩放,完全规避了 $O(n^2)$ 级别的矩阵更新。

双循环递推的来源#
将(BFGS)公式递归展开,将 $H_k$ 表示为初始近似 $H_k^0$ 与历史对 $(s_i, y_i)$ 的函数。第一循环从 $i = k-1$ 递减至 $i = k-m$ ,逐层消去最右侧因子 $(I - \rho_i y_i s_i^\top)$ 对 $g$ 的作用;再乘以 $H_k^0$ 得到中间结果。第二循环则按相反顺序(即 $i = k-m$ 到 $k-1$ )施加左侧因子 $(I - \rho_i s_i y_i^\top)$ 。由于 $\alpha_i$ 在左右两个因子中对称出现,因此可在两轮中复用。(详见 Nocedal & Wright,《Numerical Optimization》,算法 7.4,含完整推导。)
实用的 L-BFGS 实现要点#
- 初始 $H_0$ 的选取:标准做法是令 $H_0 = \gamma_k I$ ,其中 $\gamma_k = (s_{k-1}^\top y_{k-1}) / (y_{k-1}^\top y_{k-1})$ ;该选择具有尺度不变性。
- 内存大小 $m$ :$m = 5$ 是稳健的默认值;若问题曲率信息丰富且收益显著,可增至 $m = 20$ 。但 $m$ 过大并无益处,因过早的历史曲率对已失去相关性。
- 跳过失效对:若 $y_k^\top s_k \leq \epsilon \|s_k\| \|y_k\|$ (例如 $\epsilon = 10^{-8}$ ),则曲率条件不满足,加入该对会破坏正定性,应跳过。
- 线搜索策略:L-BFGS 必须配合满足 Wolfe 条件的线搜索,以确保始终有 $y_k^\top s_k > 0$ ;仅使用纯 Armijo 回溯法可能导致 BFGS 更新失效。
L-BFGS 是众多机器学习任务的默认求解器:PyTorch 中的 torch.optim.LBFGS、scikit-learn 中中等规模问题的 LogisticRegression、SciPy 的 minimize 函数族等均内置支持。对于能装入内存、噪声不大的优化问题,L-BFGS 在性能上显著优于一阶方法。
信赖域方法(Trust-region methods)#
线搜索法(line search)分两步:先问「朝哪个方向走?」,再问「走多远?」;而信赖域方法则同时回答这两个问题:在当前点 $x_k$ 周围的信赖域内,什么是最优的步长?
子问题(The subproblem)#
$$ m_k(d) = f(x_k) + g_k^\top d + \tfrac{1}{2} d^\top B_k d. $$ $$ d_k^\star = \arg\min_{\|d\|_2 \leq \Delta_k} m_k(d), $$ $$ \rho_k = \frac{f(x_k) - f(x_k + d_k^\star)}{m_k(0) - m_k(d_k^\star)}. $$若 $\rho_k$ 接近 1,说明模型精度高,可扩大信赖域;若 $\rho_k$ 过小甚至为负,则模型失真严重,应缩小信赖域并拒绝该步。标准调整策略为:当 $\rho_k < 0.25$ 时将 $\Delta_k$ 缩小为原来的 $1/4$ ;当 $\rho_k > 0.75$ 且步长恰好落在信赖域边界上时,将 $\Delta_k$ 扩大为原来的 $2$ 倍。
子问题的求解#
精确求解需采用 Moré–Sorensen 算法:寻找 $\lambda \geq 0$ ,使得 $(B_k + \lambda I) d = -g_k$ ,且满足互补松弛条件 $\lambda (\|d\|_2 - \Delta_k) = 0$ 。该算法精确但计算开销大。
两种常用廉价近似如下:
$$ d_k^C = -\tau \frac{\Delta_k}{\|g_k\|_2} g_k, \quad \tau = \begin{cases} 1 & \text{若 } g_k^\top B_k g_k \leq 0, \\ \min\left(\dfrac{\|g_k\|_2^3}{\Delta_k\, g_k^\top B_k g_k},\; 1\right) & \text{否则}. \end{cases} $$柯西点至多提供柯西下降量(Cauchy decrease),与梯度下降相当,但始终有定义,鲁棒性强。
狗腿法(Dogleg):当 $B_k \succ 0$ 时,计算无约束牛顿步 $d_k^N = -B_k^{-1} g_k$ 和最速下降步 $d_k^{SD} = -\dfrac{g_k^\top g_k}{g_k^\top B_k g_k} g_k$ 。狗腿路径定义如下:
- 若 $\|d_k^N\|_2 \leq \Delta_k$ :直接取 $d_k = d_k^N$ ;
- 若 $\|d_k^{SD}\|_2 \geq \Delta_k$ :取 $d_k = -\Delta_k \dfrac{g_k}{\|g_k\|_2}$ (即截断的柯西方向);
- 否则:取连接 $0$ 、$d_k^{SD}$ 与 $d_k^N$ 的分段线性路径中位于信赖域边界上的点,得到一个长度缩减的拟牛顿步。
狗腿路径是一条从原点出发、经 $d_k^{SD}$ 再至 $d_k^N$ 的“折线”。该路径上的模型函数值单调递减,因此最优可行解必位于路径与信赖域边界的交点处(若 $d_k^N$ 在域内,则即为其本身)。

收敛性#
采用柯西下降策略的信赖域方法,在 $B_k$ 一致有界等温和假设下,具有全局收敛性,即 $\|\nabla f(x_k)\| \to 0$ ,收敛至驻点。当 $B_k = \nabla^2 f(x_k)$ 且迭代点充分接近严格极小点时,信赖域方法继承牛顿法的二次收敛速率。
信赖域方法特别适用于 Hessian 矩阵非凸(不定)的问题(其模型天然容许不定性),以及对解精度要求极高的场景(此时每一步的质量比单步计算成本更重要)。
二阶优化方法的选择#
| 方法 | 单步计算代价 | 内存占用 | 在极小点 $x^\star$ 附近的收敛速率 | 适用场景 |
|---|---|---|---|---|
| 牛顿法(完整) | $O(n^3)$ | $O(n^2)$ | 二次收敛 | 小规模问题($n$ 较小)、Hessian 精确可得、需处理不定情形 |
| BFGS | $O(n^2)$ | $O(n^2)$ | 超线性收敛 | 中等规模($n \sim 10^3$ –$10^4$ )、梯度质量良好 |
| L-BFGS | $O(mn)$ | $O(mn)$ | 超线性收敛 | 大规模问题($n \sim 10^4$ –$10^7$ )、机器学习默认选择 |
| 信赖域法 | $O(n^3)$ (精确) | $O(n^2)$ | 二次收敛 | Hessian 不定、对解精度要求极高 |
| 高斯–牛顿法 | $O(n m^2)$ | $O(n^2)$ | 关于残差的二次收敛 | 非线性最小二乘问题($f = \frac{1}{2} \mid r(x)\mid^2$ ) |
在参数量达百万级的机器学习任务中,二阶方法通常并不适用,原因有三:(a)梯度为带噪声的随机估计;(b)内存受限;(c)无需高精度解,验证误差往往在优化间隙(optimization gap)仍较大时便已停止下降。因此,SGD 类方法占据主导地位。
而在经典科学计算领域,如物理仿真、参数估计、凸域上的信号恢复,L-BFGS 与信赖域牛顿法是核心工具。它们能在合理墙钟时间内达成梯度下降无法企及的解精度与稳定性。
总结#
二阶方法通过利用曲率信息,突破了 $\sqrt{\kappa}$ 的收敛速率瓶颈,但代价是每次迭代的计算开销更高。其方法谱系如下:
- 牛顿法(Newton),收敛快,但计算昂贵、数值脆弱,需配合全局化策略(如线搜索或信赖域);
- BFGS 方法,复用牛顿法的曲率近似,计算成本约为牛顿法的一半,且需存储完整的 $n \times n$ 近似 Hessian 矩阵(全内存);
- L-BFGS 方法,BFGS 的低存储版本,内存复杂度为 $O(mn)$ ($m \ll n$ ),已成为大规模优化的现代默认选择;
- 信赖域法(Trust region),对不定 Hessian 矩阵鲁棒性强,并天然限制步长,提升稳定性。
下一篇文章(08)将转向带约束优化,借助拉格朗日对偶性建模;其中所用的牛顿类求解器可直接推广至增广系统(augmented system),核心思想一脉相承。
参考文献#
- Nocedal & Wright,《数值优化》(第 2 版),第 3 章(线搜索)、第 4 章(信赖域)、第 6 章(BFGS)、第 7 章(L-BFGS),该领域的标准参考;
- Boyd & Vandenberghe,《凸优化》,§9.5 (阻尼牛顿法)与 §9.6 (自协调函数);
- Nesterov & Polyak,《牛顿法的三次正则化及其全局性能》,Mathematical Programming 108, 2006,面向非凸问题的现代牛顿变体;
- Liu & Nocedal,《面向大规模优化的有限内存 BFGS 方法》,Mathematical Programming 45, 1989,L-BFGS 的奠基性论文。


