
优化理论(十二):离散与全局优化
当变量为整数或问题为具有多个局部极小值区域的非凸问题时,经典凸优化方法失效;本文综述了有效方法:基于分支定界的整数规划、线性规划松弛间隙分析、启发式算法分类(粒子群优化、遗传算法、螺旋优化、模拟退火),以及螺旋优化算法在约束均值-方差投资组合优化中的深入应用。
本系列的前十一篇文章聚焦于连续凸优化问题(或非凸问题的凸松弛形式)。而本文作为收官之作,将直面两类更具挑战性的问题:
- 离散优化:变量取整数值或组合值。可行域是由有限个(但数量呈指数级增长)点构成的集合。线性与凸优化工具不再直接适用,在整数格点上无法定义导数。
- 全局非凸优化:变量为连续型,但目标函数存在大量局部极小值,而我们追求的是全局最小值。Newton 法、L-BFGS 等方法仅能收敛至局部极小点。
这两类问题共享一个关键特征:在最坏情况下,任何可证明最优性的算法都具有指数时间复杂度。实践中,我们依赖两类策略应对:(a)借助智能剪枝机制(如分支定界)的精确算法;(b)可在多项式时间内找到高质量(未必最优)解的启发式算法。
本文内容涵盖:
- 回顾整数规划(Integer Programming, IP)及其核心求解框架,以线性规划(LP)松弛作为界(bounding)机制的分支定界法(Branch-and-Bound);
- 梳理主流启发式算法谱系,粒子群优化(PSO)、遗传算法(GA)、模拟退火(SA)、螺旋优化(SOA)等,并厘清各自适用场景;
- 展开一项完整案例研究:将螺旋优化算法(Spiral Optimization Algorithm, SOA) 应用于一个带约束的均值-方差投资组合问题,该问题建模为混合整数非线性规划(Mixed-Integer Nonlinear Program, MINLP)。
前十一篇我们一直假设变量是连续的、目标函数是凸的(或者至少是凸松弛)。这一篇我们正面迎接两类更难的问题:
- 离散优化:变量必须取整数或组合值。可行集是有限多个点(但数量是指数级),导数失去意义。
- 全局非凸优化:变量连续,目标函数有大量局部极小,而我们要的是全局最小。
牛顿法、L-BFGS 这些到这里都失效了,它们顶多收敛到某个局部最优。
我会先讲离散这边的标准答案:分支定界 + LP 松弛。然后转向连续非凸这边的几类启发式(粒子群、遗传、模拟退火、螺旋优化)。最后用一个具体例子收尾,带基数约束的均值-方差投资组合优化,把方法、调参、坦诚的局限性放在一起讲。
这篇是本系列收官:等读完,你应该能对一个新优化问题快速判断它属于哪一类,再决定要请哪一种工具上场。
你将学到什么#
- 整数规划的标准建模方式,以及分支定界法如何利用 LP 松弛提供上下界来系统剪枝搜索树;
- 割平面法(Cutting Planes)、Gomory 割平面,以及驱动现代商业 MIP 求解器的核心框架,分支割平面法(Branch-and-Cut);
- 启发式算法的分类体系:基于轨迹的方法(如 SA、禁忌搜索) vs 基于种群的方法(如 GA、PSO、SOA),并提供一套实用的选型决策准则;
- 当向一个二次规划(QP)引入基数约束(cardinality constraints)与最小买入约束(buy-in constraints)后,它如何升格为混合整数非线性规划(MINLP);
- SOA 的更新规则;为何旋转矩阵叠加几何衰减半径能自然实现有效的探索-利用权衡(exploration-exploitation trade-off);及其与 PSO、GA 的本质区别;
- 如何用二次惩罚项处理整数变量与箱型约束(box constraints),并深入剖析惩罚权重 $\rho$ 为何是最微妙的超参数;
- 来自已发表基准测试与样本外回测(out-of-sample backtest)的具体数值结果,并附有对实证证据支持/不支持哪些结论的专业评述。
前置知识#
第 08 篇 (拉格朗日对偶性)、第 09 篇 (内点法)中关于 LP/QP 求解器的讨论。其余内容自成体系,无需额外预备知识。
整数规划与分支定界法#
A.1 整数规划问题#
$$ \begin{aligned} \min_{x, z} \quad & c^\top x + d^\top z \\ \text{s.t.} \quad & A x + B z \leq b \\ & x \in \mathbb{R}^n_+, \quad z \in \mathbb{Z}^p_+. \end{aligned} $$整数变量 $z$ 的引入使该问题成为 NP-难问题:即使是纯 0–1 整数规划的可行性判定本身也是 NP-完全的(它可归约于 3SAT)。连续变量 $x$ 可用于建模产量、价格等量,而整数变量则刻画离散决策(例如“是否开设该设施?”、“是否选用该路径?”)。
最朴素的方法,枚举 $z$ 的全部 $2^p$ 种取值,并对每种取值求解一个线性规划(LP),在 $p > 30$ 时即已完全不可行。分支定界法(branch-and-bound)正是让大规模 MILP 在实践中可解的核心技术。
A.2 线性规划松弛#
$$ \min \, c^\top x + d^\top z \quad \text{s.t.} \quad A x + B z \leq b, \ x, z \geq 0. $$该 LP 提供了原 MILP 最优值的一个下界(任何 MILP 可行解也必为该 LP 的可行解)。利用多项式时间算法(如内点法,见第 09 篇文章)高效求解该松弛问题,是所有主流 MILP 求解器的基础模块。
若该 LP 松弛的最优解 $z^\star_{LP}$ 恰好为整数值,则问题已解决。否则,选取某个非整数分量 $z^\star_{LP, j} \notin \mathbb{Z}$ 进行分支(branching)。
A.3 分支定界法#
| |
三个核心剪枝机制:
- 界剪枝(pruning by bound):若某子问题的 LP 松弛下界已不优于当前已知最优整数解,则整个对应子树被剪除;
- 不可行剪枝(pruning by infeasibility):若某子问题的 LP 松弛无可行解,则其子树为空,直接剪除;
- 整数性剪枝(pruning by integrality):若某子问题的 LP 松弛解恰好为整数可行解,则该节点为叶节点,无需进一步分支。
在最好情形下,分支定界法能剪去绝大部分搜索树,仅需求解多项式数量级的 LP 即可找到最优解;而在最坏情形下,它仍需遍历全部 $2^p$ 个叶节点,这印证了该算法在最坏情况下的指数时间复杂度。
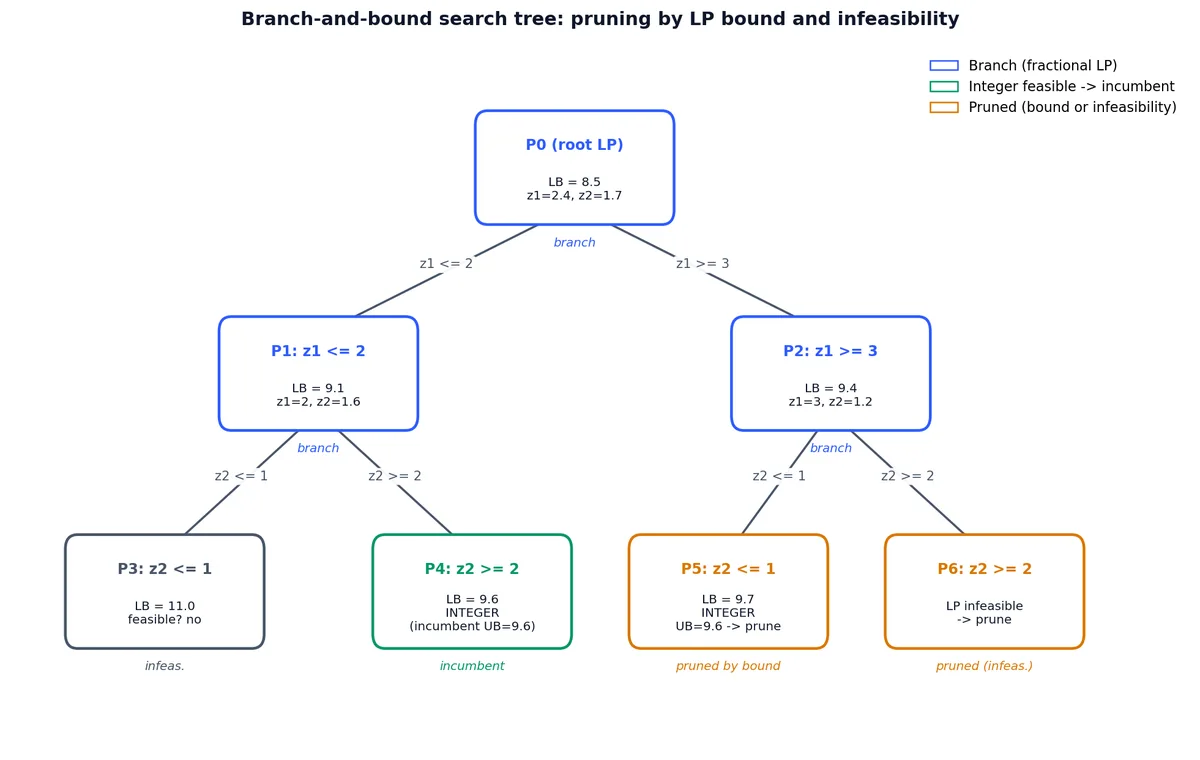
上图展示了一个包含两个整数变量的小型 B&B 运行。根节点 LP 的最优解为分数 $(2.4, 1.7)$ ,下界 $\text{LB}=8.5$ 。我们先在 $z_1$ 上分支,再在每个子节点中对 $z_2$ 分支。节点 P4 是整数可行解,成为当前最优解(incumbent),上界更新为 $\text{UB}=9.6$ ;节点 P5 也是整数可行解,但其目标值 $9.7$ 劣于当前最优解,被界剪枝;节点 P6 的 LP 不可行,被不可行性剪枝。诸多整个子树根本无需求解,这正是 B&B 在实践中快速高效的原因,尽管其最坏情况仍为指数。
A.4 割平面法#
一个割平面(cutting plane)是一类线性不等式 $\alpha^\top z \leq \beta$ ,它对所有整数可行解 $z$ 成立,但被当前 LP 松弛的最优解所违反。添加割平面可收紧 LP 松弛,提升下界,从而更早、更广泛地实施剪枝。
$$ \sum_k \mathrm{frac}(\bar a_{jk}) \cdot z_k \geq f_j $$(其中 $\bar a_{jk}$ 为单纯形表中的系数,$\mathrm{frac}(x) = x - \lfloor x \rfloor$ 表示小数部分。)
现代 MILP 求解器(如 Gurobi、CPLEX、SCIP)综合运用十余类割平面:Gomory 割、混合整数舍入割(MIR)、提升与投影割(lift-and-project)、团割(clique cut)、流覆盖割(flow cover cut)等。当前主流算法为分支割平面法(branch-and-cut):在每个搜索节点处,先尝试生成并添加被违反的割平面,再决定是否分支。

左图展示 LP 松弛的几何含义:LP 最优解(琥珀色五角星)位于多面体的某个分数顶点上,而整数规划(IP)的最优解(紫色圆点)是松弛区域内部某个绿色整数格点。右图加入一条割平面 $z_1+z_2\le 4$ (橙色直线):原本的分数顶点被切掉(紫色 ×),所有绿色整数点仍被保留,而新的 LP 顶点恰好是整数点,仅凭 LP 松弛就已解出了原 IP。实际求解器中单一割平面很少能一步到位,但每一条割都会收紧下界,使 B&B 能更激进地剪枝。
A.5 实践中可求解的问题规模#
| 问题规模 | 现代求解器能否实际求解? |
|---|---|
| 0–1 整数规划,100 个变量 | 可以,耗时数秒至数分钟。 |
| 0–1 整数规划,1000 个变量 | 通常可以,耗时数分钟至数小时。 |
| 混合整数规划,10,000 个变量 | 有时可行,高度依赖问题结构。 |
| 混合整数规划,≥ 100,000 个变量 | 通常需采用分解方法(如 Bender 分解、列生成)。 |
前沿持续推进:1990 年代被视为不可解的问题,如今已成为常规任务,这得益于算法层面(割平面、预处理等)带来的约 $10^{12}$ 倍加速,以及硬件层面带来的约 $10^6$ 倍加速。
难解问题的启发式方法#
当分支定界法(branch-and-bound)过于缓慢,或问题本身是非线性的(MINLP),启发式方法便成为默认选择。它们以牺牲最优性保证为代价,换取可接受的计算时间。
B.1 启发式方法分类#
| 类别 | 典型算法 | 优势 |
|---|---|---|
| 轨迹类(Trajectory) | 爬山法(Hill climbing)、模拟退火(SA)、禁忌搜索(Tabu search) | 简单、内存开销低、适用于组合优化问题 |
| 种群类(Population) | 遗传算法(GA)、粒子群优化(PSO)、螺旋优化(SOA)、差分进化(DE) | 可并行化、易于跳出局部极小值 |
| 构造类(Constructive) | 贪心算法(Greedy)、蚁群算法(ACO)、贪婪随机自适应搜索过程(GRASP) | 逐步构建可行解 |
| 混合类(Hybrid) | 模因算法(Memetic algorithms)、大规模邻域搜索(LNS) | 融合局部搜索与全局搜索能力 |

上图是启发式(metaheuristic)文献中的标准分类。轨迹类(单状态)开销低,适合组合优化问题;种群类并行携带多个候选解,是连续多峰问题的天然选择;构造类逐步拼接可行解,在序列结构强的问题上占优;混合类则将外层全局搜索与内层的局部搜索或精确求解器结合。
模拟退火(Simulated Annealing, SA):在解空间中执行随机游走,总是接受改进的移动,同时以概率 $e^{-\Delta f / T}$ 接受劣解移动。温度参数 $T$ 随时间衰减,高温阶段侧重探索(exploration),低温阶段侧重开发(exploitation)。理论上,若 $T$ 衰减足够缓慢(如 $T_k \propto 1/\log k$ ),SA 可以以概率 1 收敛至全局最优;实践中则需精心设计退火调度(cooling schedule)。
遗传算法(Genetic Algorithm, GA):维护一组候选解(种群);通过交叉(crossover)与变异(mutation)操作组合个体;依据适应度保留优质后代。天然适用于二元变量与类别型决策变量。但其性能对算子(如选择、交叉、变异策略)的设计高度敏感。
$$ v_i \leftarrow w v_i + c_1 r_1 (p_i^{\text{best}} - x_i) + c_2 r_2 (p^{\text{global best}} - x_i). $$其中 $w$ 为惯性权重,$c_1,c_2$ 为学习因子,$r_1,r_2 \sim \text{Uniform}(0,1)$ 。PSO 在具有多个吸引盆(basin)的连续优化问题上表现强劲。
螺旋优化(Spiral Optimization Algorithm, SOA):与 PSO 类似,但每个粒子不再直奔最优位置,而是沿一条对数螺旋线(logarithmic spiral)向当前最优解(incumbent)收敛,且螺旋半径按几何级数收缩。我们将在下文的案例研究中详述该算法。
B.2 启发式方法选型指南#
| 若你的问题是…… | 建议尝试…… |
|---|---|
| 二元型 / 组合型(如旅行商问题 TSP、调度问题) | 模拟退火(SA)、禁忌搜索(Tabu)、遗传算法(GA) |
| 连续型且存在多个局部极小值(多峰) | 粒子群(PSO)、差分进化(DE)、协方差矩阵自适应进化策略(CMA-ES)、螺旋优化(SOA) |
| 混合整数型(含连续变量) | 混合策略(如 GA 外层整数决策 + LP 内层连续优化) |
| 凸问题但规模极大 | 勿用启发式;应选用内点法(IPM)或随机梯度下降(SGD) |
| 黑箱函数(无梯度信息、目标函数评估代价高昂) | 贝叶斯优化(Bayesian Optimization)、遗传算法(GA) |
文献中的核心共识是:不存在一种启发式方法能在所有问题上全面胜出。为特定问题选择合适的方法是一门技艺(craftsmanship)。若该问题需反复求解,值得投入数周时间调参与定制;否则,直接采用你最熟悉的优化库(如 scipy.optimize、DEAP 或 pyswarms)中已实现的成熟版本即可。
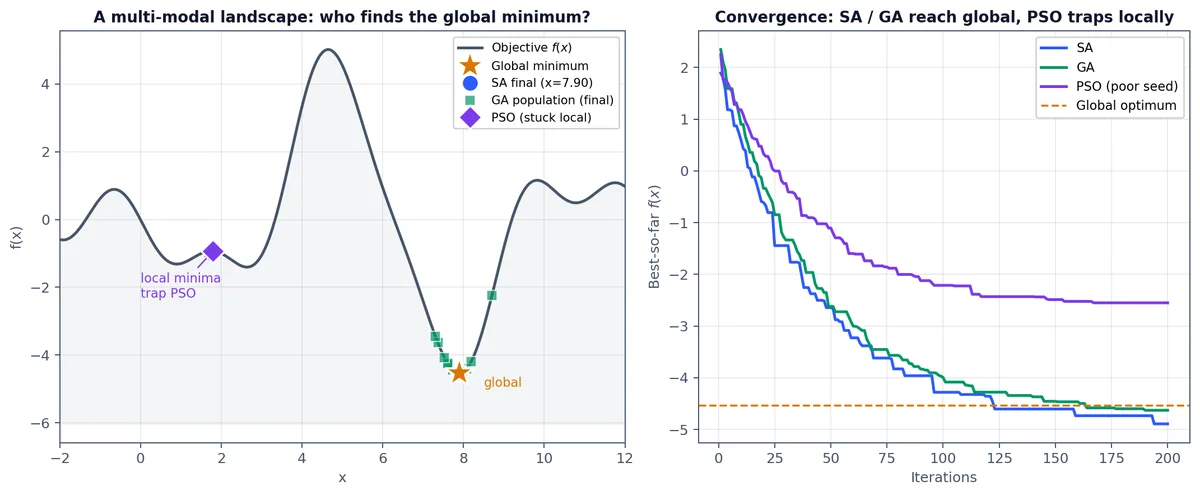
一维多峰目标函数上的玩具示例。左图展示函数地貌与各方法在固定预算后的最终位置:SA(蓝色)与 GA(绿色种群)都接近了琥珀色星所在的全局低谷,而 PSO(紫色菱形)被左侧一个浅局部最优困住,因为所有粒子都过早向初期发现的那个盆地收敛。右图绘出迭代过程中的历史最优值:SA 与 GA 逐渐逼近全局最优值(虚线琥珀色),PSO 则停滞在一个较差的值上。重点不在于 PSO 本身差,换个随机种子与惯性调度后,它同样能找到全局最优,而是没有任何方法能全面胜出,且随机种子间的方差不容忽视。这正是为什么生产环境中总是运行 30 次以上独立重启。
案例研究 —— 螺旋优化算法(SOA)求解均值-方差投资组合问题#
本文余下部分将深入剖析如何将 SOA 应用于金融领域一个真实的混合整数非线性规划(MINLP)问题:带实际交易约束的均值-方差投资组合优化。
马科维茨(Markowitz)均值-方差模型形式简洁优美,但一旦加入真实世界的交易限制,例如“若配置某只股票,则持仓比例不得低于 5%”、“必须且仅从标普 500 成分股中精选 10 只股票”,原本封闭可解的二次规划(QP)便悄然蜕变为一个混合整数非线性规划(MINLP)。此时,标准求解范式(拉格朗日乘子法、KKT 条件、内点法等)全部失效。本案例研究即采用螺旋优化算法(SOA),一种基于种群的元启发式方法,来应对这一挑战,并证实:在梯度类方法完全失效的区域,SOA 仍能高效寻得高质量、满足所有约束的可行解。
从二次规划到混合整数非线性规划(MINLP)#
经典均值-方差问题#
$$ \begin{aligned} \min_{\mathbf{y}} \quad & V(\mathbf{y}) = \mathbf{y}^\top Q \mathbf{y} \\ \text{s.t.} \quad & \overline{\mathbf{r}}^\top \mathbf{y} = R_p, \\ & \mathbf{e}^\top \mathbf{y} = 1, \\ & y_i \geq 0, \quad i = 1, \dots, n, \end{aligned} $$其中 $\mathbf{e}$ 表示全 1 向量。该问题是一个凸二次规划(QP)。当在某一区间内连续扫描 $R_p$ 时,所得到的最优解轨迹即构成有效前沿(efficient frontier):即对每个目标收益率水平,实现最小方差的所有投资组合的集合。

上图展示了在五资产 universe 下的几何结构。图中散点云由在单纯形上均匀采样的 5,000 个随机投资组合构成(颜色按类夏普比率着色)。紫色曲线为无约束的有效前沿(允许卖空),虚线蓝色曲线则为满足基数约束 $K=3$ 的前沿。两个直观观察结论如下:(i)在任意收益率水平下,基数约束前沿均位于无约束前沿右侧(选择更少 → 分散化程度更低 → 风险更高);(ii)二者之间的差距在 $R_p$ 上并非均匀分布:在极端收益率处,该差距显著扩大,因为仅有极少数资产组合能够实际达到这些高/低目标收益。
引入买入阈值(buy-in threshold)#
$$l_i z_i \leq y_i \leq u_i z_i, \qquad 0 < l_i < u_i \leq 1, \qquad z_i \in \{0, 1\}.$$当 $z_i = 0$ 时,整行约束退化为 $y_i = 0$ ;当 $z_i = 1$ 时,则强制 $y_i \in [l_i, u_i]$ 。这正是问题严格转变为混合整数规划(MIP)或混合整数非线性规划(MINLP)的数学临界点:可行域此时成为有限个凸多面体(每个 $\mathbf{z}$ 取值对应一个)的并集,整体不再具有凸性。
加入基数约束(cardinality constraint)#
$$\sum_{i=1}^{n} z_i = K.$$ $$ \begin{aligned} \min_{\mathbf{y}, \mathbf{z}} \quad & V(\mathbf{y}) = \mathbf{y}^\top Q \mathbf{y} \\ \text{s.t.} \quad & \overline{\mathbf{r}}^\top \mathbf{y} = R_p, \\ & \mathbf{e}^\top \mathbf{y} = 1, \\ & \sum_{i=1}^{n} z_i = K, \\ & l_i z_i \leq y_i \leq u_i z_i, \\ & z_i \in \{0, 1\}, \quad i = 1, \dots, n. \end{aligned} $$该问题具有 $\binom{n}{K}$ 个组合分支。即便在中等规模下(如 $n = 100,\, K = 10$ ),分支总数已达 $1.7 \times 10^{13}$ ,远超暴力枚举的可行范围。尽管基于分支定界(branch-and-bound)的 MINLP 求解器(如 BARON、SCIP、Bonmin)可尝试求解,但其实际运行时间随问题规模迅速增长;正因如此,在该尺度下,元启发式算法(metaheuristics)开始展现出显著吸引力。
螺旋优化算法(Spiral Optimization Algorithm, SOA)#
更新规则#
$$\mathbf{x}_{k+1}^{(j)} \;=\; \mathbf{x}^* \;+\; r \cdot R(\theta) \, \big(\mathbf{x}_k^{(j)} - \mathbf{x}^*\big),$$其中 $R(\theta)$ 是一个 $d$ 维旋转矩阵,旋转角为 $\theta$ ;$r \in (0, 1)$ 是收缩因子。旋转与收缩的复合操作刻画了一条向内收敛的对数螺线。

左图展示了五个初始分布在非凸目标函数四个象限中的候选解的演化轨迹。琥珀色星号标记当前最优解(此处恰好为全局最小值)。每个候选解沿螺线向内运动,并在过程中持续采样目标函数值。右图则显式揭示了 探索(exploration)与开发(exploitation) 的权衡:几何包络 $r^k$ 控制着螺线坍缩的速度。缓慢收缩($r = 0.95$ )使候选解在较长时间内远离 $\mathbf{x}^*$ (更强的探索能力),而快速收缩($r = 0.85$ )则迅速将其拉向当前最优解(更强的开发能力)。
为何特别选用“螺线”?#
相较于其他元启发式算法:
- 粒子群优化(PSO) 通过速度更新每个粒子,该速度是其个体历史最优与全局最优的加权混合,并叠加随机噪声。该速度本身不具备内在收缩机制;通常需额外设计惯性权重衰减策略,并精细调节认知权重与社会权重。
- 遗传算法(GA) 依赖交叉与变异操作。其天然适用于整型变量,但在连续空间中,模式定理(schema theorem)效力较弱,收敛速度往往较慢。
- 模拟退火(SA) 采用单条带温度衰减的马尔可夫链轨迹。缺乏种群结构,因而无法实现搜索过程的并行化。
SOA 的核心优势在于:旋转操作 $R(\theta)$ 确保候选解围绕当前最优解进行确定性的多方向环绕(即系统性地采样 不同 方向),而收缩因子 $r$ 则从理论上保障算法最终收敛。探索–开发的平衡由此简化为单一超参数的调控:矩阵 $r R(\theta)$ 的谱半径。
当前最优解的更新#
每次所有候选解完成移动后,整个种群被重新评估,$\mathbf{x}^*$ 更新为迄今为止所观测到的最优解。这是经典 SOA 中唯一的随机性来源,初始采样。部分改进变体(包括本文所采用的版本)会对停滞不前的候选解注入随机扰动,以助其跳出当前最优解所在吸引域。
约束处理#
二次罚函数#
$$\min_{\mathbf{y}, \mathbf{z}} \; F(\mathbf{y}, \mathbf{z}) = V(\mathbf{y}) + \rho \cdot P(\mathbf{y}, \mathbf{z}),$$ $$ P = \big(\overline{\mathbf{r}}^\top \mathbf{y} - R_p\big)^2 \,+\, \big(\mathbf{e}^\top \mathbf{y} - 1\big)^2 \,+\, \sum_{i=1}^{n} \max(0, l_i z_i - y_i)^2 \,+\, \sum_{i=1}^{n} \max(0, y_i - u_i z_i)^2 \,+\, \Big(\sum_i z_i - K\Big)^2. $$整数约束 $z_i \in \{0,1\}$ 通过舍入(rounding) 实现:SOA 在连续区间 $z_i \in [0,1]$ 上搜索,仅在计算罚函数 $P$ 时将 $z_i$ 四舍五入至最近整数。

左图展示罚函数在单维权重切片上的作用:原始方差 $V(y)$ (灰色虚线)的最小值位于不可行区域(紫色点,低于买入阈值)。加入 $\rho \cdot P(y)$ 后,在可行带 $[l, u]$ 外形成陡峭的抛物型壁垒;最终的带罚目标函数(实心蓝色曲线)的最优解被“拉入”绿色可行带内(琥珀色菱形)。右图展示两个资产、基数约束 $K=1$ 下的二维可行性图:仅绿色区域可行。叉号表示不可行候选解,圆点表示可行解。
罚权重 $\rho$ 的微妙性#
这是元启发式+罚函数类文献中被调整最频繁的超参数,其选取确实极具挑战性:
- 过小:算法可能找到方差极低但不可行的投资组合(如权重和不为 1,或持有低于阈值的头寸)。此时罚项仅是软性提示,而非硬性壁垒。
- 过大:$V$ 相对于 $\rho P$ 变成数值意义上的舍入误差;数值精度恶化;优化过程实质上退化为仅追求可行性,完全忽略方差目标。
- 恰到好处:高度依赖具体问题。本文在五资产案例中取 $\rho = 10^4$ ,之所以可行,是因为 $V = O(1)$ ,而 $P$ 虽小但非零。
一种更鲁棒的替代方案是增广拉格朗日(augmented Lagrangian)方法,它根据迭代过程中观测到的约束违反程度动态调整 $\rho$ 。本文未采用该方法,因此当将该方法迁移至新资产池时,重新调优 $\rho$ 是不可避免的开销。
修复算子(Repair Operators)#
每次螺旋更新后,候选解可能漂移出单位超立方体 $[0,1]^n$ 。本文采用一种简单的修复策略:先将每个 $y_i$ 截断至 $[0,1]$ 区间,再重新归一化,确保 $\mathbf{e}^\top \mathbf{y} = 1$ 。该操作计算成本极低,且能保证每个候选解天然满足预算约束(budget constraint),从而将罚函数的负担仅留给目标收益、买入阈值及基数约束。
数值实验结果#
基准测试设定#
$$\overline{\mathbf{r}} = (0.10, 0.13, 0.085, 0.155, 0.07)^\top$$协方差矩阵 $Q$ 为 $5 \times 5$ 的半正定矩阵(具体数值见原文)。目标收益 $R_p = 0.05$ ,最小买入比例(buy-in)约束 $l_i = 0.05$ ,基数约束 $K = 5$ (即全部资产均被选中),罚因子 $\rho = 10^4$ ,最大迭代次数为 50。
收敛性对比#

该图展示了 SOA-MINLP、拟牛顿法(Quasi-Newton)、DIRECT 及本文额外引入的粒子群优化(PSO)基线方法在迭代过程中“迄今最优”方差(best-so-far variance)的变化趋势。蓝色阴影带表示 30 次独立 SOA 运行结果的 10%–90% 分位区间;实心蓝线为中位数曲线。
有两点值得注意:
第一,最终方差值排序与原文报告一致:SOA-MINLP 达 $V = 0.6969$
,拟牛顿法为 $0.7123$
,DIRECT 为 $0.7458$
,PSO 居中,为 $0.7250$
。拟牛顿法在迭代次数上收敛最快,但因罚函数导致的目标曲面非光滑,梯度类方法易陷入次优局部解;DIRECT 是一种基于 Lipschitz 常数的确定性分区搜索方法,探索更彻底,但代价是所需迭代次数显著增加。
第二,至第 60 次迭代时,SOA 的分位带已明显收窄,表明在此阶段各次运行间差异很小,这对一种随机性算法而言是令人安心的稳健性表现。
需注意的是:本实验仅针对五资产问题。所有关于 SOA 相对性能优势的结论,都应在更大规模问题上重新验证。
样本外回测#
为检验 投资组合策略本身(而不仅是求解器性能),我们依据 $\overline{\mathbf{r}}$ 与 $Q$ 所隐含的多元高斯分布,模拟了三年(约 750 个交易日)的日度收益,并对比三类配置规则:等权组合、无约束均值-方差组合(目标收益设为 11%),以及一类 SOA-MINLP 风格组合(仅做多、$K=3$ 、buy-in $= 0.10$ )。

无约束均值-方差组合在模型内具有最高的夏普比率,但其依赖卖空且持仓高度集中,导致实际回撤(下图)显著高于 SOA-MINLP 组合。等权组合最为保守,却显著牺牲了预期收益。SOA-MINLP 规则则实现了良好平衡:基数与 buy-in 约束起到了正则化作用,在略微降低预期收益的同时,大幅改善了回撤表现。这正是基数约束的实践价值所在,它不追求理论最优,而是提供一种 可在真实交易台落地执行的风险分散机制。
SOA 的适用场景:何时使用,何时规避#
推荐使用 SOA 的情形:
- 问题本质非凸,且含有离散或组合结构(如基数约束、行业敞口限制、整数手数等);
- 资产数量处于中小规模($n \lesssim 100$ );
- 可承受 30 次以上独立运行以评估解的稳定性;
- 不需要最优性证明(optimality certificate),仅需一个高质量可行解。
应避免使用 SOA 的情形:
- 问题为凸或近似凸(此时应选用 QP 求解器:OSQP、CVXOPT、MOSEK);
- $n > 1000$ (建议采用商业 MINLP 求解器:Gurobi、CPLEX、BARON;或采用 Bertsimas 等人提出的 Lasso 类松弛方法等专用技术);
- 需在严苛延迟约束下实现实时再平衡;
- 约束仅为简单变量边界(此时直接投影即可,无需复杂优化器)。
实践中的超参数调优指南#
| 超参数 | 典型取值范围 | 影响说明 |
|---|---|---|
| 种群规模 $N$ | 30 – 100 | $N$ 越大,探索能力越强;单次迭代计算成本呈线性增长 |
| 最大迭代次数 | 50 – 500 | 依据收敛曲线判断;当中位数曲线趋于平稳即停止 |
| 螺旋角 $\theta$ | $\pi / 6$ 至 $\pi / 3$ | $\theta$ 越大,横向(圆周方向)探索越充分 |
| 收缩系数 $r$ | 0.85 – 0.95 | $r$ 越小,收敛越快,但陷入局部最优风险越高 |
| 罚权重 $\rho$ | $10^2$ – $10^6$ | 调整至中位数运行中约束违反量为零 |
经验启动配置(Rule of Thumb):
$N = 50$
,max_iter $= 100$
,$\theta = \pi / 4$
,$r = 0.92$
,$\rho = 10^4$
。
先运行 30 次试验并观察收敛带:若第 100 次迭代时带宽仍较宽,可增大 $N$
;若约束违反持续存在,则将 $\rho$
提升一个数量级。
局限性与坦诚的注意事项#
- 无最优性保证: SOA 是一种元启发式算法。你可证明它找到了一个高质量的可行解;但无法证明它找到了 全局最优解。这一点在受监管资本要求(如巴塞尔协议、偿付能力 II)背景下尤为关键。
- 随机性输出: 不同随机种子下的两次运行会产生不同的投资组合。在实际操作中,你需要明确的“平局打破”规则(例如:选择方差最低者?最接近基准者?或采用集成策略?)。
- 非平稳性: 协方差矩阵 $Q$ 和期望收益向量 $\overline{\mathbf{r}}$ 均基于有限历史数据估计,本身带有噪声。若某求解器在 错误的 协方差矩阵下找到了方差最小的投资组合,其实际表现未必优于另一求解器在该噪声模型下找到的近似最优解。相较求解器精度的极致提升,鲁棒优化(即在协方差不确定性集合上考虑最坏情形)往往更具现实意义。
- 惩罚系数 $\rho$ 需重新调优。 每次更换资产池(universe)均需重新进行参数扫描。增广拉格朗日类变体可在一定程度上缓解该问题。
- 高维空间中的旋转矩阵构造困难。 在 $\mathbb{R}^{500}$ 中构造具有实际意义的旋转矩阵并非易事;原始 SOA 论文建议采用 Householder 变换构造,但实证表明,当维度超过数百时,其性能显著下降。
总结#
本文提出了一个聚焦且可辩护的主张:一种带二次惩罚项的改进型 SOA 算法,在一个小规模基准测试中,对处理基数约束(cardinality constraints)与买入门槛约束(buy-in constraints)的能力,可与拟牛顿法(Quasi-Newton)及 DIRECT 算法相媲美。然而,我从中得出的推论更为审慎:SOA 并非大规模场景下商用 MINLP 求解器(如 Gurobi)的替代方案;但它确实在一类特定区间内颇具实用价值,即资产池规模尚不足以支撑 Gurobi 许可证成本,却又过于受限而无法直接套用标准二次规划(vanilla quadratic programming)的情形。进一步地,基数约束与买入门槛约束绝非学术上的奇思妙想:如前述回测所示,它们能实质性地降低样本外风险(out-of-sample risk)。方法论层面的核心启示在于:约束条件的设计,往往比求解器本身的精度更为关键,一个满足恰当约束的“良好”投资组合,即便由一个“普通”求解器得到,通常也优于一个在错误约束下由“完美”求解器所得的所谓“最优”组合。
参考文献#
- Markowitz, H. (1952). Portfolio Selection. Journal of Finance, 7(1), 77–91.
- Tamura, K., & Yasuda, K. (2011). Spiral Dynamics Inspired Optimization. Journal of Advanced Computational Intelligence and Intelligent Informatics, 15(8), 1116–1122.
- Kania, A., & Sidarto, K. A. (2016). Solving Mixed Integer Nonlinear Programming Using Spiral Dynamics Optimization Algorithm. AIP Conference Proceedings, 1716.
- Bartholomew-Biggs, M., & Kane, S. J. (2009). A Global Optimization Problem in Portfolio Selection. Computational Management Science, 6(3), 329–345.
- Bertsimas, D., & Cory-Wright, R. (2022). A Scalable Algorithm for Sparse Portfolio Selection. INFORMS Journal on Computing.


