
偏微分方程与机器学习(七):扩散模型与 Score Matching
从 PDE 视角统一理解扩散模型:热方程、Fokker-Planck、score matching、DDPM/DDIM、Latent Diffusion,配可视化。
扩散模型的输出端我们很熟悉:一张高质量图片。但训练目标乍看之下却很反直觉,先把数据加噪声加到完全是高斯,再学怎么一步步去噪。为什么这个绕远路的策略反而比直接学数据分布有效?

答案藏在偏微分方程里。前向加噪过程是一个热方程(或者更一般的 Fokker-Planck 方程),它有一个反向版本,只要我们知道每个时刻的 score(密度的对数梯度)。Score Matching 就是学这个 score 的标准方法。从这个角度看,DDPM、DDIM、Score-based SDE 不是几个独立的算法,而是同一个 PDE 故事的不同离散化。
这篇文章用 PDE 的视角把这条线串起来:从热方程出发,导出 score-matching loss,把 DDPM 训练目标推回这个统一框架,再讨论 DDIM 和 Latent Diffusion 是怎么在保持这套理论的同时把推理速度加上去的。配可视化。
你将学到什么#
自 2020 年起,扩散模型已成为生成式 AI 的主流范式。从 DALL·E 2 到 Stable Diffusion 再到 Sora,其生成质量与训练稳定性均超越了 GAN 和 VAE。这一成功背后是一套异常简洁的数学结构:扩散模型本质上是偏微分方程(PDE)的数值求解器。
- 添加高斯噪声对应于正向积分 Fokker–Planck 方程;
- 学习去噪等价于学习 score 函数 $\nabla\log p_t$ ;
- DDPM 是离散化的反向 SDE;DDIM 则是对应的概率流 ODE;
- Stable Diffusion 将这套机制搬到了低维潜空间中执行。
你将学到的内容:
- 热方程与高斯核,扩散过程的数学基础;
- 随机微分方程(SDE)与 Fokker–Planck 方程,概率密度如何演化;
- Score 函数、Score Matching(DSM/SSM)与 Langevin 动力学;
- DDPM 作为离散反向 SDE,DDIM 作为概率流 ODE;
- 潜空间扩散(Stable Diffusion)及其与科学计算的联系。
前置知识:多元微积分、基础概率论(高斯分布、贝叶斯)、神经网络基本原理。
热方程与扩散过程#
Fick 定律与扩散方程#
$$ \mathbf{J} = -D\,\nabla u, $$ $$ \frac{\partial u}{\partial t} = D\,\nabla^2 u. \tag{1} $$拉普拉斯算子衡量了 $u$ 的局部“曲率”:在凹陷处(热点),$\nabla^2 u < 0$ ,$u$ 下降;在凸起处(冷点),$u$ 上升。最终系统趋于均匀状态。
高斯核:基本解#
$$ G(\mathbf{x}, t) = \frac{1}{(4\pi D t)^{d/2}}\exp\!\left(-\frac{\|\mathbf{x}\|^2}{4Dt}\right). \tag{2} $$ $$ u(\mathbf{x}, t) = (G_t * u_0)(\mathbf{x}). $$扩散 = 用不断扩大的高斯核进行模糊。这正是扩散模型前向加噪过程的核心思想。
傅里叶视角:扩散作为低通滤波器#
$$ \hat u(\mathbf{k}, t) = \hat u_0(\mathbf{k})\,e^{-D\|\mathbf{k}\|^2 t}. $$高频成分(大 $\|\mathbf{k}\|$ )比低频成分指数级更快地衰减。扩散本质上是一个低通滤波器,精细结构最先消失,粗粒度结构最后留存。因此,反向的去噪过程必须重建高频信息;而这正是 score 网络所承担的任务。
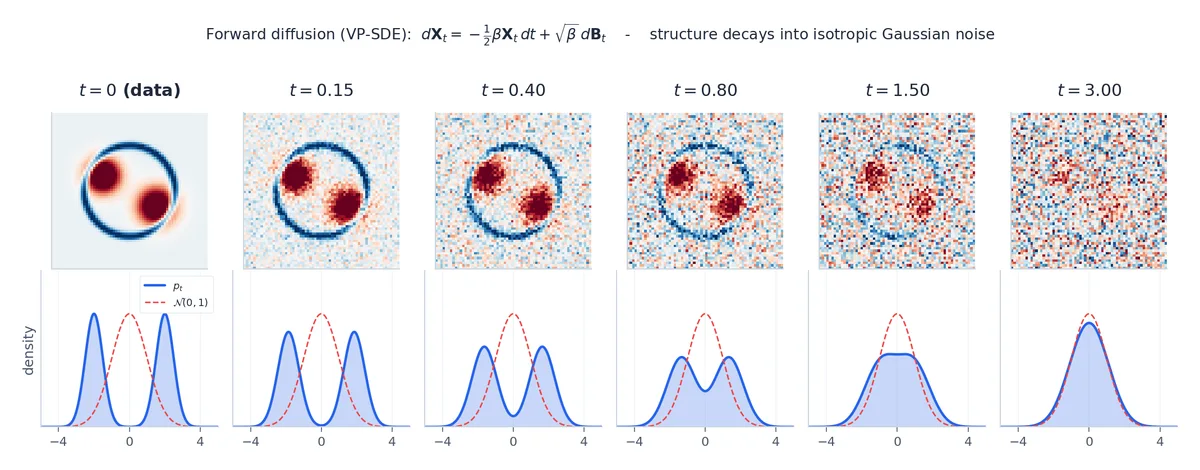
实现:观察扩散过程如何逐步摧毁数据结构
我们可以直接模拟前向扩散过程,并验证 $p_t$
确实收敛至标准高斯分布:
| |
在 $t=0$ 时,数据呈现出清晰的双月形结构(方差小、均值明显偏离原点);而到 $t=999$ 时,$\bar\alpha_T \approx 10^{-4}$ ,此时 $\mathbf{x}_T$ 已几乎完全退化为纯高斯噪声,整个前向过程就像一个低通滤波器,彻底抹去了所有原始结构信息。
SDE 与 Fokker–Planck 方程#

热方程描述的是密度的确定性演化。但若想刻画单个样本路径,这正是扩散模型实际生成的对象,我们需要引入随机微分方程(SDE)。
布朗运动与 Itô SDE#
$$ d\mathbf{X}_t = f(\mathbf{X}_t, t)\,dt + g(t)\,d\mathbf{B}_t, \tag{3} $$其中 $f$ 称为漂移项(确定性驱动力),$g$ 是扩散系数(噪声强度)。
当前扩散模型文献中占主导地位的两种调度方案如下:
| 调度 | 漂移 $f(\mathbf{x}, t)$ | 扩散 $g(t)$ | 平稳分布 |
|---|---|---|---|
| 方差保持(VP) | $-\tfrac{1}{2}\beta(t)\,\mathbf{x}$ | $\sqrt{\beta(t)}$ | $\mathcal{N}(\mathbf{0},\,\mathbf{I})$ |
| 方差爆炸(VE) | $0$ | $\sqrt{d\sigma^2/dt}$ | 方差无界增长 |
DDPM 是 VP-SDE 的离散化;而 Song & Ermon(2019)提出的原始 NCSN 则对应 VE 的离散化。
Fokker–Planck 方程#
$$ \boxed{\;\frac{\partial p}{\partial t} \;=\; -\nabla\!\cdot\!\bigl(f\,p\bigr) \;+\; \tfrac{1}{2}\,g^2\,\nabla^2 p\;.} \tag{4} $$ $$ d\varphi(\mathbf{X}_t) = \bigl(f\!\cdot\!\nabla\varphi + \tfrac{1}{2}g^2\nabla^2\varphi\bigr)\,dt + g\,\nabla\varphi\!\cdot\!d\mathbf{B}_t. $$取期望后鞅项消失,再利用 $\mathbb{E}[\varphi(\mathbf{X}_t)] = \int \varphi\,p\,d\mathbf{x}$ 并分部积分(因 $\varphi$ 任意),即可导出 (4)。$\blacksquare$
一致性验证:在 (4) 中令 $f \equiv 0$ 且 $g^2/2 = D$ ,即得热方程 $\partial_t p = D\,\nabla^2 p$ 。可见 Fokker–Planck 方程正是带漂移项的热方程。
Kolmogorov 后向方程#
$$ \partial_s u + f\!\cdot\!\nabla u + \tfrac{1}{2}g^2 \nabla^2 u = 0, $$终端条件为 $u(T, \mathbf{x}) = g(\mathbf{x})$ 。前向方程推动密度向前演化,后向方程则将期望向后传播。二者共同构成 Feynman–Kac 对应关系,而前向 SDE 的时间反演,正是我们用来生成样本的关键工具。
基于 Score 的生成模型#

Score 函数#
$$ \mathbf{s}(\mathbf{x}) \;:=\; \nabla_{\mathbf{x}}\,\log p(\mathbf{x}). \tag{5} $$它具有三个重要性质:
- 无需归一化:$\nabla \log(p / Z) = \nabla \log p$ ,因此无需知道配分函数 $Z$ ;
- 高斯分布有解析解:若 $p = \mathcal{N}(\boldsymbol\mu, \sigma^2 \mathbf{I})$ ,则 $\mathbf{s}(\mathbf{x}) = -(\mathbf{x} - \boldsymbol\mu) / \sigma^2$ ;
- 期望为零:在温和正则条件下,$\mathbb{E}_p[\mathbf{s}(\mathbf{x})] = \mathbf{0}$ 。
几何上,score 是一个始终指向高概率区域的向量场,在低密度“山谷”中模长较大。

Score Matching#
由于真实密度 $p$ 未知,无法直接最小化 $\mathbb{E}_p\,\|\mathbf{s}_\theta - \nabla\log p\|^2$ 。目前有三种实用的替代方案:
$$ \mathcal{L}_{\text{ISM}}(\theta) = \mathbb{E}_p\Bigl[\,\tfrac{1}{2}\|\mathbf{s}_\theta(\mathbf{x})\|^2 + \mathrm{tr}\bigl(\nabla\mathbf{s}_\theta(\mathbf{x})\bigr)\Bigr]. $$但雅可比矩阵的迹在高维下计算代价高昂。
$$ \mathcal{L}_{\text{SSM}}(\theta) = \mathbb{E}_{\mathbf{v}, \mathbf{x}}\Bigl[\,\mathbf{v}^\top \nabla\mathbf{s}_\theta(\mathbf{x})\,\mathbf{v} + \tfrac{1}{2}(\mathbf{v}^\top \mathbf{s}_\theta(\mathbf{x}))^2\Bigr]. $$每样本只需一次 Hessian–向量乘积。
$$ \boxed{\;\mathcal{L}_{\text{DSM}}(\theta) = \mathbb{E}_{\mathbf{x}, \tilde{\mathbf{x}}}\Bigl[\bigl\|\mathbf{s}_\theta(\tilde{\mathbf{x}}) + \tfrac{\tilde{\mathbf{x}} - \mathbf{x}}{\sigma^2}\bigr\|^2\Bigr].\;} \tag{6} $$Vincent 证明:(6) 的最优解与匹配加噪分布 $p_\sigma = p * \mathcal{N}(0, \sigma^2 \mathbf{I})$ 的真实 score 一致。当 $\sigma \to 0$ 时,$p_\sigma \to p$ 。实践中通常在训练中对 $\sigma$ 进行退火。

实现:去噪分数匹配(Denoising Score Matching, DSM)
DSM 是驱动扩散模型训练的核心目标函数。下面是一个极简但功能完整的实现:
| |
在多个噪声尺度上进行退火至关重要:较小的 $\sigma$ 能在数据密集区域提供高精度的分数估计,但在低密度区域覆盖不足;而较大的 $\sigma$ 虽能实现更广的覆盖范围,却会导致分数估计失准。多尺度策略则兼顾了二者优势。
Langevin 动力学#
$$ \mathbf{x}_{k+1} = \mathbf{x}_k + \tfrac{\epsilon}{2}\,\mathbf{s}_\theta(\mathbf{x}_k) + \sqrt{\epsilon}\,\boldsymbol\eta_k,\qquad \boldsymbol\eta_k \sim \mathcal{N}(\mathbf{0}, \mathbf{I}). \tag{7} $$当 $\epsilon \to 0$ 且迭代步数 $k \to \infty$ 时,链收敛至目标分布 $p$ 。其中确定性项负责“利用”(沿 score 上坡),噪声项负责“探索”(跳出局部极大值)。
Anderson 的反向时间 SDE#
$$ \boxed{\;d\mathbf{X}_t = \bigl[\,f(\mathbf{X}_t, t) - g(t)^2\,\nabla\log p_t(\mathbf{X}_t)\,\bigr]\,dt + g(t)\,d\bar{\mathbf{B}}_t,\;} \tag{8} $$其中 $\bar{\mathbf{B}}_t$ 是反向时间的布朗运动,$p_t$ 是原过程在时刻 $t$ 的边际密度。该 SDE 中唯一依赖数据分布的部分就是 $\nabla\log p_t$ ,这正是 score 网络所学习的目标。从 $\mathbf{x}_T \sim \mathcal{N}(\mathbf{0}, \mathbf{I})$ 出发,沿时间倒推求解 (8),即可生成(近似)来自数据分布的样本。

从连续理论到 DDPM 与 DDIM#
DDPM:前向过程的闭式解#

这正是 VP-SDE 的 Euler–Maruyama 离散化形式。当 $T$ 足够大时,$\bar\alpha_T \to 0$ ,故 $\mathbf{x}_T \approx \mathcal{N}(\mathbf{0}, \mathbf{I})$ 。
DDPM 损失 = 加权 DSM#
$$ \mathcal{L}_{\text{DDPM}}(\theta) = \mathbb{E}_{t,\,\mathbf{x}_0,\,\boldsymbol\epsilon}\Bigl[\,\bigl\|\boldsymbol\epsilon_\theta(\mathbf{x}_t, t) - \boldsymbol\epsilon\bigr\|^2\Bigr]. \tag{10} $$ $$ \nabla_{\mathbf{x}_t} \log q(\mathbf{x}_t \mid \mathbf{x}_0) = -\frac{\boldsymbol\epsilon}{\sqrt{1 - \bar\alpha_t}}, $$因此网络实际上在学习一个缩放后的 score:$\mathbf{s}_\theta(\mathbf{x}_t, t) = -\boldsymbol\epsilon_\theta(\mathbf{x}_t, t)/\sqrt{1 - \bar\alpha_t}$ 。(10) 正是 (6) 在权重 $w(t) = 1$ 下的特例。
实现:一个完整的 DDPM 训练循环
下方是一个面向二维数据的极简但可直接运行的 DDPM 实现。核心思想很清晰:我们训练的是一个 $\boldsymbol\epsilon$
-预测器(而非直接预测分数函数),损失函数则简单地采用预测噪声与真实噪声之间的均方误差(MSE)。
| |
这个训练循环出人意料地简洁:随机选一个时间步 → 按该步加噪 → 预测所加的噪声 → 反向传播更新参数。真正的复杂性其实藏在模型结构(此处是简单的多层感知机;对图像任务则通常采用带注意力机制的 U-Net)和噪声调度策略中。
噪声调度策略:线性 vs 余弦
$\beta_t$
的选择,其重要性远超直觉判断:
| 调度方式 | 公式 | 特性 | 最适用场景 |
|---|---|---|---|
| 线性(Linear) | $\beta_t = \beta_{\min} + t(\beta_{\max} - \beta_{\min})/T$ | 早期噪声增长剧烈 | DDPM(Ho 等,2020) |
| 余弦(Cosine) | $\bar\alpha_t = \cos^2(\frac{t/T + s}{1+s}\cdot\frac{\pi}{2})$ | 噪声衰减更平缓 | 改进版 DDPM(Nichol & Dhariwal,2021) |
| Sigmoid | $\bar\alpha_t = \sigma(-a + 2a \cdot t/T)$ | 中段下降更陡峭,首尾趋于平缓 | Stable Diffusion 3 |
线性调度存在明显的容量浪费问题:前几百步中,$\bar\alpha_t$ 仍非常接近 1(即数据几乎未被加噪),模型不得不花费大量训练步数去学习预测近乎为零的噪声。而余弦调度则能更均匀地将“信息含量”分布在各个时间步上,使训练更高效、生成质量更稳定。
DDIM:概率流 ODE#
$$ \boxed{\;\frac{d\mathbf{x}}{dt} = f(\mathbf{x}, t) - \tfrac{1}{2}\,g(t)^2\,\nabla\log p_t(\mathbf{x}).\;} \tag{11} $$这就是概率流 ODE。其边际分布之所以一致,是因为 (8) 和 (11) 对应的密度 $p_t$ 都满足同一个 Fokker–Planck 方程 (4)。使用高阶 ODE 求解器(如 Heun、RK4、DPM-Solver)沿时间反向求解 (11),构成了 DDIM 及其后续方法的基础。其优势在于:确定性(相同噪声输入 → 相同输出图像)、支持更大步长(25–50 步 vs 1000 步)、严格可逆(可将图像编码回其潜噪声)。

实现:DDIM 采样
DDIM 将原本随机的反向扩散步骤替换为确定性的常微分方程(ODE)步骤,从而大幅减少采样所需的迭代次数:
| |
DDIM 仅需 1/20 的模型调用次数,即可生成质量相当的样本。核心区别在于:
- DDPM 在每一步都引入全新的随机噪声(对应随机微分方程,SDE);
- DDIM 则完全不添加额外噪声(对应确定性常微分方程,ODE)。
因此,对 DDIM 而言,相同的初始噪声总能生成完全一致的输出,这一确定性特性使其天然支持潜在空间插值(latent-space interpolation)与反演(inversion)。
统一视角#
| 方法 | 过程 | 典型步数 | 是否确定性 | 优势 |
|---|---|---|---|---|
| DDPM | 反向 SDE (8) | ~1000 | 否 | 多样性好、训练简单 |
| DDIM | 概率流 ODE (11) | ~25–50 | 是 | 速度快、可精确反演 |
| DPM-Solver | 高阶 ODE | ~10–20 | 是 | 更快、保真度不变 |
| EDM(Karras et al.) | 连续、精细预条件 | ~30 | 可调 | 当前 SOTA 质量 |
PDE → 扩散模型全景图#
将上述内容整合:

评分网络架构:U-Net#
在图像生成任务中,评分网络 $\boldsymbol\epsilon_\theta(\mathbf{x}_t, t)$ 采用经典的 U-Net 结构,即一种带跳跃连接(skip connections)的编码器-解码器架构。其核心设计要点如下:
- 时间条件注入(Time conditioning):对时间步 $t$ 使用正弦位置嵌入(sinusoidal positional embedding),再经线性层投影后,逐层加到每个残差块(ResBlock)的输入上(思路类似于 Transformer 中的位置编码方式)。
- 空间分辨率变化:编码器在每一级均进行 $2\times$ 下采样(典型设置为 4 级下采样,例如对 64 像素图像:64 → 32 → 16 → 8)。
- 自注意力机制(Self-attention):仅在 16×16 和 8×8 分辨率层级插入自注意力模块;更高分辨率(如 32×32 或 64×64)下引入自注意力计算开销过大,故不采用。
- 交叉注意力机制(Cross-attention,用于条件控制):CLIP 或 T5 提取的文本嵌入,通过交叉注意力模块注入到与自注意力相同的两个分辨率层级(即 16×16 和 8×8)。
- 归一化与激活函数:全网络统一使用 Group Normalization(组归一化) + SiLU 激活函数(而非 BatchNorm,因其在不同噪声水平下表现不稳定,易与扩散过程中的噪声动态产生冲突)。
该架构可概括为如下流程:

图:U-Net 评分网络。左侧编码器逐层下采样、右侧解码器逐层上采样,绿色虚线是跨层跳跃连接,把高频细节直接送过去。时间步 $t$ 经过正弦嵌入 + MLP 后,加到每个 ResBlock 的输入上。
典型图像生成模型的参数量约为 1 亿至 9 亿(相比之下,我们此前介绍的二维玩具示例仅约 100 万参数)。其中,跳跃连接至关重要:若移除它们,细粒度空间细节会在瓶颈层中严重丢失,导致模型无法重建高频信息,而这恰恰是扩散过程最先抹除、也必须最后恢复的关键内容。
潜空间扩散:一张图理解 Stable Diffusion#
在像素空间对 $512 \times 512$ 图像进行扩散计算开销巨大:每次 U-Net 前向需处理约 $8 \times 10^5$ 个浮点数。潜空间扩散(Rombach et al., 2022)首先训练一个类 VAE 的自编码器 $(\mathcal{E}, \mathcal{D})$ ,将图像映射到约 $8\times$ 更小的潜变量 $\mathbf{z}_0 = \mathcal{E}(\mathbf{x})$ ,然后在整个扩散过程中仅在潜空间操作。最终通过一次前向传递完成解码:$\hat{\mathbf{x}} = \mathcal{D}(\mathbf{z}_0)$ 。
各类条件信息(文本、类别标签、深度图、ControlNet 姿态等)通过交叉注意力机制注入 U-Net。

计算开销节省约为 $f^{2d}$ ,其中 $f$ 为空间下采样因子(通常为 8),$d=2$ ,即约 64 倍。正是这一架构创新,使扩散模型得以走向消费级应用。
无分类器引导(Classifier-Free Guidance)#
当前扩散模型中最实用、影响最深远的技术当属无分类器引导(Ho & Salimans,2022)。其核心思想非常简洁:在训练阶段,以概率 $p_{\text{uncond}} \approx 0.1$ 随机丢弃条件信号(例如文本提示);而在推理阶段,则将带条件与不带条件的预测结果进行加权组合:
$$\hat{\boldsymbol\epsilon}(\mathbf{x}_t, t, c) = \boldsymbol\epsilon_\theta(\mathbf{x}_t, t, \varnothing) + w\,\bigl[\boldsymbol\epsilon_\theta(\mathbf{x}_t, t, c) - \boldsymbol\epsilon_\theta(\mathbf{x}_t, t, \varnothing)\bigr], \tag{12}$$其中 $w > 1$ 称为引导尺度(guidance scale)。当 $w = 1$ 时,退化为标准的条件生成模型;而文本到图像任务中,$w = 7$ –$15$ 是典型取值范围。
| |
为何有效?
引导机制本质上放大了「模型在给定提示下生成的内容」与「模型无条件生成的内容」之间的差异。这会将采样结果推向那些在该条件下异常高概率出现的区域,从而得到更紧凑、更贴合提示的输出,代价是牺牲部分多样性。从数学角度看,该方法近似于从分布 $p(x|c)^w \cdot p(x)^{1-w}$
中采样,即对原始条件分布进行了锐化(sharpening)。
| 引导尺度 $w$ | 效果 | 典型应用场景 |
|---|---|---|
| $w = 1$ | 无引导,即标准条件生成 | 注重多样性的任务 |
| $w = 3$ –$5$ | 轻度引导 | 创意探索、风格微调 |
| $w = 7$ –$10$ | 强引导 | 文本到图像生成(DALL-E、Stable Diffusion 等) |
| $w > 15$ | 过度饱和,易出现伪影 | 通常过高,不推荐使用 |
与科学计算的联系#
基于 score 的扩散不仅是一种生成建模技巧,更是从任意(可能难以处理的)概率分布中采样的通用工具。对 PDE 社区而言,以下两个方向尤为相关:
PDE 约束下的条件生成:训练一个条件 score 模型 $\mathbf{s}_\theta(\mathbf{x}, t \mid \mathcal{C})$ ,其中 $\mathcal{C}$ 编码了 PDE 残差或边界条件。反向采样生成的场在分布意义上满足约束。这构成了扩散后验采样(diffusion posterior sampling)的基础(Chung et al., 2023),适用于断层成像、超分辨率、去模糊等反问题。
贝叶斯推断的代理采样器:许多贝叶斯反问题需从后验 $p(\theta \mid \mathbf{y}) \propto p(\mathbf{y}\mid\theta)\,p(\theta)$ 中采样。若能基于模拟生成的 $(\theta, \mathbf{y})$ 数据对训练 score 模型,则可通过条件反向采样替代传统 MCMC。
核心思想是:只要你需要从高维、多峰分布中采样,且能够负担前向动力学的模拟,扩散模型的整套流程就适用。
练习题#
练习 1: 证明热方程是 Fokker–Planck 方程在 $f \equiv 0$ 、$g^2 / 2 = D$ 时的特例。
解: 代入 (4):$\partial_t p = -\nabla\!\cdot\!(\mathbf{0}\cdot p) + D\nabla^2 p = D\nabla^2 p$ 。$\blacksquare$
练习 2: 解释为何 DDPM 损失等价于(加权)score matching。
解: 由 (9),$q(\mathbf{x}_t\mid\mathbf{x}_0) = \mathcal{N}(\sqrt{\bar\alpha_t}\,\mathbf{x}_0, (1-\bar\alpha_t)\mathbf{I})$ ,故 $\nabla_{\mathbf{x}_t}\log q = -\boldsymbol\epsilon/\sqrt{1-\bar\alpha_t}$ 。预测 $\boldsymbol\epsilon$ 即预测缩放后的 score,(10) 正是 (6) 在 $w(t)=1$ 下的形式。$\blacksquare$
练习 3: 为何 DDIM 能使用远少于 DDPM 的步数?
解: DDIM 求解的是光滑的确定性 ODE (11),可采用高阶多步法(Heun、RK4、DPM-Solver);而 DDPM 求解 SDE,其强收敛阶仅为 $\mathcal{O}(\sqrt{\Delta t})$ ,需极小步长才能保证精度。$\blacksquare$
练习 4: 将扩散解释为低通滤波器,并说明为何“噪声先破坏高频内容”。
解: 傅里叶模式演化为 $\hat p(\mathbf{k}, t) \propto \exp(-D\|\mathbf{k}\|^2 t)$ ,故高频(大 $\|\mathbf{k}\|$ )衰减更快。由于高频对应细节,精细结构最先消失,粗结构则持续更久。$\blacksquare$
练习 5: 对一维 OU 过程 $dX_t = -\tfrac12 \beta X_t\,dt + \sqrt\beta\,dB_t$ (平稳分布为 $\mathcal{N}(0,1)$ ),推导 Anderson 反向 SDE 的漂移项。
解概要: 在平稳态下 $p_t(x) = \mathcal{N}(x;0,1)$ ,故 $\nabla\log p_t(x) = -x$ 。代入 (8):漂移 $= -\tfrac12\beta x - \beta(-x) = \tfrac12\beta x$ ,即反向过程具有远离原点的正向均值回归,恰好抵消了 OU 过程向原点收缩的趋势。$\blacksquare$
下一步#
本章给的几个核心想法(PDE 残差作为损失、函数空间上的算子、Wasserstein 几何、辛结构、score、扩散)在后面的章节里会反复出现。如果某一段卡住了,建议先记下问题继续往下读,下一章往往会从另一个角度把它再讲一遍。
如果你想验证自己读懂了,最直接的练习是把本章的方程在一个最小例子上跑通:一维热方程、单摆、二维高斯混合。代码不长,但能让公式从“看着对”变成“在我电脑上确实是对的”。
参考文献#
[1] Song, Y., et al. (2020). Score-based generative modeling through stochastic differential equations. arXiv:2011.13456 .
[2] Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. NeurIPS. arXiv:2006.11239 .
[3] Song, J., Meng, C., & Ermon, S. (2021). Denoising diffusion implicit models. ICLR. arXiv:2010.02502 .
[4] Song, Y., & Ermon, S. (2019). Generative modeling by estimating gradients of the data distribution. NeurIPS. arXiv:1907.05600 .
[5] Karras, T., Aittala, M., Aila, T., & Laine, S. (2022). Elucidating the design space of diffusion-based generative models (EDM). NeurIPS. arXiv:2206.00364 .
[6] Lu, C., et al. (2022). DPM-Solver: a fast ODE solver for diffusion models. NeurIPS. arXiv:2206.00927 .
[7] Rombach, R., et al. (2022). High-resolution image synthesis with latent diffusion models. CVPR. arXiv:2112.10752 .
[8] Anderson, B. D. O. (1982). Reverse-time diffusion equation models. Stochastic Processes and their Applications, 12(3), 313–326.
[9] Hyvärinen, A. (2005). Estimation of non-normalized statistical models by score matching. JMLR.
[10] Vincent, P. (2011). A connection between score matching and denoising autoencoders. Neural Computation.
[11] Chung, H., et al. (2023). Diffusion posterior sampling for general noisy inverse problems. ICLR. arXiv:2209.14687 .
本文是 PDE 与机器学习 系列的第 7 篇。下一篇:第 8 篇 —— 反应扩散系统与 GNN 。上一篇:第 6 篇 —— 连续归一化流 。


