好厨师不会给每位客人做同一道菜。她会观察你进门时的状态,留意你点的酒,再瞥一眼你盯着黑板菜单的眼神,然后才决定今晚的招牌菜该是牛排还是烩饭——过去的到访记录固然重要,但只有契合当下心情的那部分才会被真正考虑。
早期的推荐模型却像个蹩脚的厨师:它把用户点击过的所有内容简单平均成一个向量,然后给所有人端上同一道菜。上周浏览的复古皮衣和半年前随手点过的手机充电器被赋予同等权重,完全无视你此刻正在看什么。
深度兴趣网络(Deep Interest Network, DIN) 让模型学会了“看人下菜碟”。它的核心思想出奇地简单:在为候选商品打分时,根据每个历史行为与 该 候选商品的相关性动态加权。同一个用户,面对不同商品会生成不同的表征——正如主厨会根据不同心情烹制不同菜肴。
本文将带你梳理从这一洞见衍生出的注意力机制 CTR 模型家族:DIN(目标注意力)、DIEN(基于 GRU + AUGRU 的兴趣演化建模)、DSIN(会话感知)和 BST(在行为序列上应用 Transformer)。我们将确保数学推导严谨、代码可运行、直觉清晰。
你将学到什么#
- 为什么对用户历史取平均会丢失关键信息,以及注意力机制如何解决这一问题
- DIN —— 使用 Local Activation Unit 实现目标注意力
- DIEN —— 结合 GRU + AUGRU 与辅助损失建模兴趣演化
- DSIN —— 捕捉会话级别的浏览模式
- BST —— 在行为序列与候选商品上应用 Transformer
- 工程实践技巧:Dice 激活函数、小批量感知正则化、序列截断
前置知识#
- 掌握 PyTorch 基础(模块定义、前向传播、损失计算)
- 熟悉 Embedding 技术(第 5 篇
)
- 了解 RNN/GRU 概念(非必需,但有帮助)
从平均池化到注意力机制#
平均池化的问题在哪里?#
假设一位用户点击了 5 部动作片、3 部爱情喜剧、2 部纪录片和 1 部恐怖片。当为一部新动作片打分时,那 5 次动作片点击理应占主导地位。但简单平均会将全部 11 次点击一视同仁——那个恐怖片离群点会把用户表征拉离推荐目标。
$$
\mathbf{v}_u = \frac{1}{T} \sum_{j=1}^{T} \mathbf{e}_{b_j}
$$其中 $\mathbf{e}_{b_j}$
是行为 $b_j$
的嵌入向量。该向量完全忽略候选商品:无论你是在评估动作片还是纪录片,用户的表征都一模一样。
注意力机制如何解决这个问题?#

$$
\alpha_j = \text{score}(\mathbf{e}_{b_j}, \mathbf{e}_i)
$$
$$
\mathbf{v}_u(i) = \sum_{j=1}^{T} \alpha_j \, \mathbf{e}_{b_j}
$$现在 $\mathbf{v}_u(i)$
依赖于 $i$
:推荐动作片时,动作类点击被突出;推荐爱情喜剧时,爱情类点击占主导。同样的历史,不同的解读。上图清晰展示了这一点:同一位用户的 10 次点击,面对两个候选商品,产生了两套截然不同的注意力分布。模型没变,问题变了。
如何选择打分函数?#
按表达能力由弱到强,有三种常见选择:
- 点积 —— $\text{score}(\mathbf{q}, \mathbf{k}) = \mathbf{q}^\top \mathbf{k}$
。计算廉价,但表达能力有限。
- 缩放点积 —— 除以 $\sqrt{d}$
以稳定数值范围,Transformer 即采用此法。
- 加性 MLP —— $\mathbf{v}^\top \tanh(\mathbf{W}_q \mathbf{q} + \mathbf{W}_k \mathbf{k} + \mathbf{b})$
。表达能力最强,DIN 正是选择了这一方案。
DIN 更进一步:它不仅拼接 $\mathbf{q}$
和 $\mathbf{k}$
,而是将四组信息一同输入 MLP:query、key、query−key 和 query⊙key。相减捕捉 差异,逐元素相乘捕捉 交互,MLP 在此基础上学习一个非线性的兼容性函数。
深度兴趣网络 (DIN)#
DIN 由阿里巴巴于 2018 年提出(Zhou et al., KDD'18),至今仍是基于注意力机制的 CTR 模型的奠基之作。其核心是 Local Activation Unit —— 一个小型 MLP,用于为每个历史行为与候选商品的相关性打分。
DIN 的工作原理#
给定用户行为序列 $[b_1, b_2, \ldots, b_T]$
和候选商品 $i$
:
- 嵌入 行为、候选商品、用户特征及上下文。
- 通过激活单元 打分 每个历史行为与候选商品的相关性。
- 对行为嵌入进行 加权求和,得到“激活后”的用户表征。
- 将该表征与其他特征 拼接,并通过 MLP 进行 CTR 预测。
$$
\text{score}(\mathbf{e}_{b_j}, \mathbf{e}_i) = \text{MLP}\big([\,\mathbf{e}_{b_j};\ \mathbf{e}_i;\ \mathbf{e}_{b_j} - \mathbf{e}_i;\ \mathbf{e}_{b_j} \odot \mathbf{e}_i\,]\big)
$$一个微妙但关键的细节:DIN 原论文并未使用 softmax。作者发现,允许权重之和不为 1 能保留兴趣的 强度 —— 拥有多个强相关行为的用户应生成更大的用户向量,而非与仅有弱相关行为的用户归一化到相同尺度。代码中我们将同时展示两种形式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
| import torch
import torch.nn as nn
import torch.nn.functional as F
class LocalActivationUnit(nn.Module):
"""DIN 的 Local Activation Unit。
使用一个小 MLP 消化四种交互视角:行为本身、候选本身、二者之差、
二者逐元素乘积,从而为每个历史行为与候选商品的匹配度打分。
"""
def __init__(self, embedding_dim, hidden_dims=(80, 40), use_softmax=False):
super().__init__()
# 输入 = [行为; 候选; 行为-候选; 行为*候选]
in_dim = embedding_dim * 4
layers = []
for h in hidden_dims:
layers += [nn.Linear(in_dim, h), nn.PReLU()]
in_dim = h
layers.append(nn.Linear(in_dim, 1))
self.mlp = nn.Sequential(*layers)
self.use_softmax = use_softmax
def forward(self, behaviors, candidate, mask=None):
"""
behaviors: (B, T, D) 历史行为嵌入
candidate: (B, D) 候选商品嵌入
mask: (B, T) 真实位置为 1,填充位置为 0
Returns:
user_repr: (B, D)
weights: (B, T)
"""
B, T, D = behaviors.shape
cand = candidate.unsqueeze(1).expand(B, T, D)
# 四种交互视角
feats = torch.cat([behaviors, cand, behaviors - cand, behaviors * cand], dim=-1)
scores = self.mlp(feats).squeeze(-1) # (B, T)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
if self.use_softmax:
weights = F.softmax(scores, dim=1)
else:
# DIN 默认:保留原始权重,不做归一化
weights = scores
if mask is not None:
weights = weights * mask
user_repr = torch.bmm(weights.unsqueeze(1), behaviors).squeeze(1)
return user_repr, weights
class DIN(nn.Module):
"""用于 CTR 预估的 Deep Interest Network。"""
def __init__(self, item_dim=64, user_dim=32, ctx_dim=16,
mlp_hidden=(200, 80), dropout=0.5):
super().__init__()
self.activation = LocalActivationUnit(item_dim)
in_dim = item_dim + item_dim + user_dim + ctx_dim
layers = []
for h in mlp_hidden:
layers += [nn.Linear(in_dim, h), nn.PReLU(), nn.Dropout(dropout)]
in_dim = h
layers += [nn.Linear(in_dim, 1)]
self.mlp = nn.Sequential(*layers)
def forward(self, user_feats, behaviors, candidate, ctx_feats, mask=None):
user_repr, attn = self.activation(behaviors, candidate, mask)
x = torch.cat([user_repr, candidate, user_feats, ctx_feats], dim=1)
logit = self.mlp(x).squeeze(-1)
return logit, attn
# 跑通性测试
model = DIN(item_dim=64, user_dim=32, ctx_dim=16)
B, T = 32, 20
logits, attn = model(
user_feats=torch.randn(B, 32),
behaviors=torch.randn(B, T, 64),
candidate=torch.randn(B, 64),
ctx_feats=torch.randn(B, 16),
mask=torch.ones(B, T),
)
print(logits.shape, attn.shape) # torch.Size([32]) torch.Size([32, 20])
|
训练目标与阿里的工业化技巧#
$$
\mathcal{L} = -\frac{1}{N} \sum_{i=1}^{N} \big[ y_i \log \sigma(\hat{y}_i) + (1 - y_i) \log(1 - \sigma(\hat{y}_i)) \big]
$$论文将大部分性能提升归功于以下三个技巧:
- Dice 激活函数 —— 一种数据自适应的 PReLU,其拐点随 batch 分布动态调整(见工业化技巧一节
)。
- 小批量感知正则化 —— 不对全部 embedding(数千万商品,本 batch 中绝大多数未出现)做 L2 正则,而仅正则当前 batch 中出现的 embedding,并按其频次加权。效果相近,计算成本却大幅降低。
- 梯度裁剪 —— 长行为序列在训练初期易导致梯度爆炸,裁剪可有效缓解。
深度兴趣演化网络 (DIEN)#
DIN 将历史视为无序行为集合,忽略了时间维度。但兴趣是流动的:上个月你在研究笔记本电脑,这周追逐配件,下周可能转向人体工学椅。
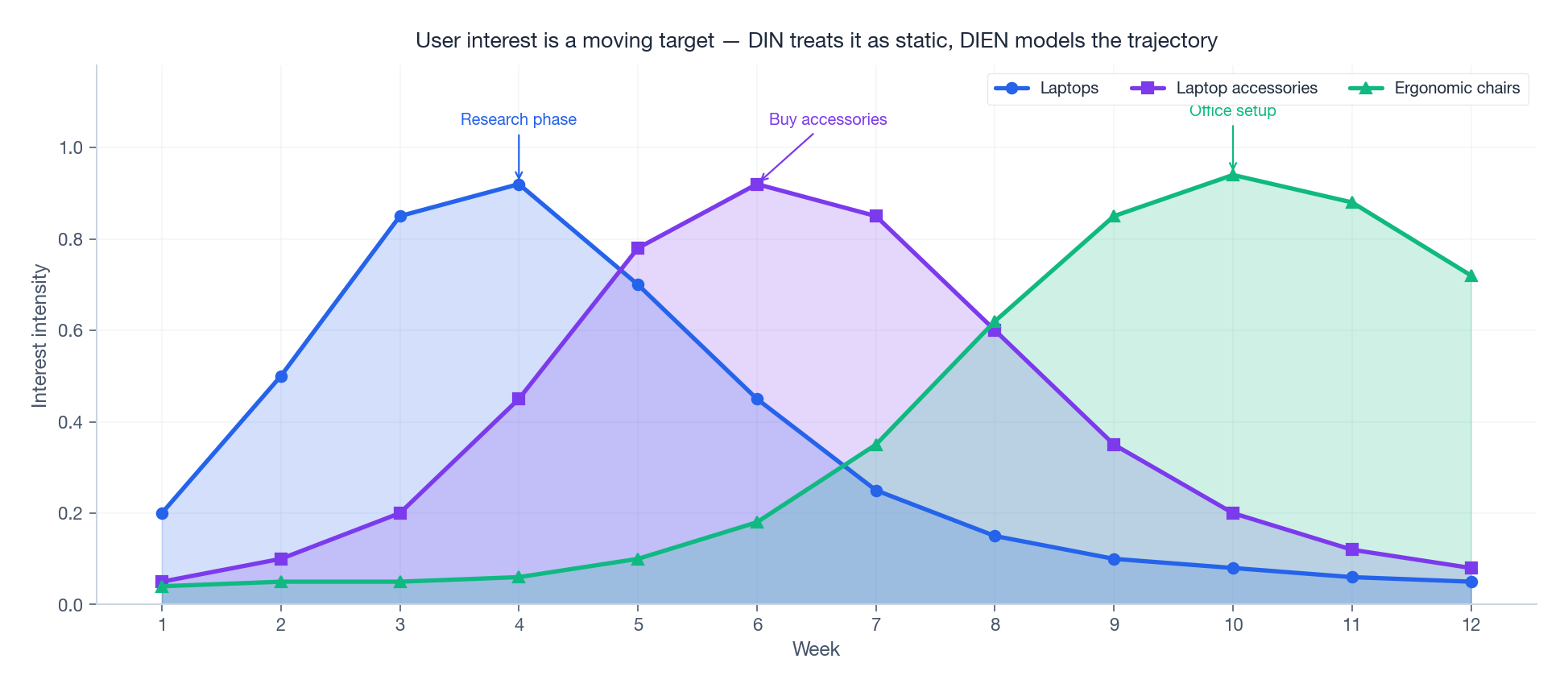
上图揭示了 DIN 无法捕捉的动态:用户“兴趣”并非单一向量,而是一条时序信号,各兴趣峰值按可预测顺序此起彼伏。DIN 只看到所有峰值的并集,而 DIEN(Zhou et al., AAAI'19)通过两层结构显式建模这一轨迹。
一张图看懂架构#

$$
\mathbf{h}_t = \text{GRU}(\mathbf{e}_{b_t}, \mathbf{h}_{t-1})
$$每个隐藏状态 $\mathbf{h}_t$
表示用户在时刻 $t$
的兴趣。
$$
\tilde{u}_t = a_t \cdot u_t \qquad \mathbf{h}'_t = (1 - \tilde{u}_t) \odot \mathbf{h}'_{t-1} + \tilde{u}_t \odot \tilde{\mathbf{h}}_t
$$可理解为:当过去兴趣高度相关时,让它驱动演化;无关时则冻结状态,避免噪声冲淡信号。图中箭头粗细正比于 $a_t$
:粗箭头推动信息前移,细箭头则基本保留前一状态。
辅助损失技巧#
$$
\mathcal{L}_{\text{aux}} = -\frac{1}{T-1}\sum_{t=1}^{T-1} \Big[ \log \sigma(\mathbf{h}_t^\top \mathbf{e}_{b_{t+1}}^+) + \log\big(1 - \sigma(\mathbf{h}_t^\top \mathbf{e}_{b_{t+1}}^-)\big)\Big]
$$通俗地说:若时刻 $t$
的隐藏状态能预测 $t+1$
时刻的真实点击(正样本),且无法预测随机负样本,则说明它捕捉到了真实兴趣。
总目标为 $\mathcal{L} = \mathcal{L}_{\text{ctr}} + \lambda \cdot \mathcal{L}_{\text{aux}}$
,其中 $\lambda$
通常取 $[0.1, 1.0]$
。
AUGRU 实现#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| class AUGRUCell(nn.Module):
"""更新门被注意力加权的 GRU 单元。"""
def __init__(self, input_dim, hidden_dim):
super().__init__()
self.W_ir = nn.Linear(input_dim, hidden_dim)
self.W_hr = nn.Linear(hidden_dim, hidden_dim)
self.W_iz = nn.Linear(input_dim, hidden_dim)
self.W_hz = nn.Linear(hidden_dim, hidden_dim)
self.W_in = nn.Linear(input_dim, hidden_dim)
self.W_hn = nn.Linear(hidden_dim, hidden_dim)
def forward(self, x_t, h_prev, a_t):
"""
x_t: (B, input_dim) t 时刻的兴趣(来自 GRU 层)
h_prev: (B, hidden_dim) 上一步演化后的状态
a_t: (B, 1) 相对候选商品的注意力权重
"""
r = torch.sigmoid(self.W_ir(x_t) + self.W_hr(h_prev))
z = torch.sigmoid(self.W_iz(x_t) + self.W_hz(h_prev))
n = torch.tanh(self.W_in(x_t) + r * self.W_hn(h_prev))
z_tilde = a_t * z # ← AUGRU 的关键改动
h_t = (1 - z_tilde) * h_prev + z_tilde * n
return h_t
class DIEN(nn.Module):
def __init__(self, item_dim=64, user_dim=32, ctx_dim=16,
hidden_dim=64, mlp_hidden=(200, 80), dropout=0.5):
super().__init__()
self.gru = nn.GRU(item_dim, hidden_dim, batch_first=True)
self.attn = LocalActivationUnit(hidden_dim, use_softmax=True)
self.augru = AUGRUCell(hidden_dim, hidden_dim)
in_dim = hidden_dim + item_dim + user_dim + ctx_dim
layers = []
for h in mlp_hidden:
layers += [nn.Linear(in_dim, h), nn.PReLU(), nn.Dropout(dropout)]
in_dim = h
layers += [nn.Linear(in_dim, 1)]
self.mlp = nn.Sequential(*layers)
def forward(self, user_feats, behaviors, candidate, ctx_feats):
# 第 1 层:兴趣提取
interest, _ = self.gru(behaviors) # (B, T, H)
# 计算与候选商品的注意力权重
_, attn = self.attn(interest, candidate) # (B, T)
# 第 2 层:用 AUGRU 演化兴趣
B, T, H = interest.shape
h = torch.zeros(B, H, device=behaviors.device)
for t in range(T):
h = self.augru(interest[:, t, :], h, attn[:, t:t+1])
final_interest = h # (B, H)
x = torch.cat([final_interest, candidate, user_feats, ctx_feats], dim=1)
return self.mlp(x).squeeze(-1), interest # interest 用于辅助损失
|
实际部署中,逐时间步的 Python 循环会被自定义 CUDA kernel 替代,但概念上正是如此。
深度会话兴趣网络 (DSIN)#
用户行为常呈爆发式:午饭时花十五分钟浏览笔记本,晚上回来扫一眼耳机,次日早晨又看跑鞋。每个爆发内部主题连贯,而爆发间的间隔往往标志着心境切换。

DSIN(Feng et al., IJCAI'19)显式建模这一结构。上图展示了将九次行为划分为三个会话的完整流程:
- 会话切分 —— 当行为间隔超过 30 分钟(原论文阈值)时切分会话。
- 会话内自注意力 —— 在每个会话内,多头自注意力捕捉局部模式(本次爆发中哪些物品相互关联)。
- 会话间 Bi-LSTM —— 跨会话使用双向 LSTM 建模兴趣漂移。
- 目标注意力 —— 最后,基于候选商品对会话向量加权。
直觉在于:会话是模型的“思维单元”。将三十次点击视为无差别整体,会丢失其分属三个连贯片段的事实;而将每次点击视为独立时间步,又忽略了同会话内点击的主题一致性。会话恰是居中的合适粒度。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| class DSINSessionLayer(nn.Module):
"""会话内自注意力 → 平均池化 → 会话向量。"""
def __init__(self, embed_dim, num_heads=4):
super().__init__()
self.attn = nn.MultiheadAttention(embed_dim, num_heads, batch_first=True)
def forward(self, session_behaviors, mask=None):
# session_behaviors: (B, S, D)
attended, _ = self.attn(session_behaviors, session_behaviors, session_behaviors,
key_padding_mask=mask)
return attended.mean(dim=1) # (B, D)
def split_sessions(timestamps, gap_seconds=1800):
"""按时间间隔将行为序列切分为多个会话区间。"""
sessions, start = [], 0
for i in range(1, len(timestamps)):
if timestamps[i] - timestamps[i - 1] > gap_seconds:
sessions.append((start, i))
start = i
sessions.append((start, len(timestamps)))
return sessions
|
何时选用哪个模型#
| 模型 | 关键创新 | 最佳适用场景 |
|---|
| DIN | 在扁平行为列表上应用目标注意力 | 历史较短、无明显时序结构 |
| DIEN | GRU + AUGRU + 辅助损失 | 历史较长、兴趣平滑演化 |
| DSIN | 会话内自注意力 + 会话间 Bi-LSTM | 浏览模式具有清晰会话边界 |
| BST | 在行为序列与候选上应用 Transformer | 历史较长、需并行化推理 |
行为序列变换器 (BST)#
到 2019 年,Transformer 已席卷 NLP。阿里淘宝团队提出:何不直接将其用于行为序列?

BST(Chen et al., DLP-KDD'19)将行为序列与候选商品视为单一 token 序列,并在其上运行 Transformer 编码器。多头自注意力使每个行为既能关注其他行为,也能关注候选商品,位置嵌入则编码时间顺序。
$$
\mathbf{Z} = \text{TransformerBlock}\big(\,[\mathbf{e}_{b_1} + \mathbf{p}_1,\, \ldots,\, \mathbf{e}_{b_T} + \mathbf{p}_T,\, \mathbf{e}_i + \mathbf{p}_{T+1}]\,\big)
$$随后将 $\mathbf{Z}$
与侧特征拼接并送入 MLP。在淘宝日志上,BST 相比 WDL 基线带来约 7.5% 的 AUC 提升。值得注意的是,BST 并未显式设计“目标注意力”步骤——它不需要,因为 [历史, 候选] 的自注意力已让候选直接访问所有行为,同时也让行为间相互关联,这是 DIN 从未建模的能力。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| class BST(nn.Module):
def __init__(self, item_dim=64, max_len=50, num_heads=8, num_layers=2,
user_dim=32, ctx_dim=16, mlp_hidden=(1024, 512, 256), dropout=0.2):
super().__init__()
self.pos_embed = nn.Embedding(max_len + 1, item_dim)
encoder_layer = nn.TransformerEncoderLayer(
d_model=item_dim, nhead=num_heads,
dim_feedforward=item_dim * 4, dropout=dropout,
batch_first=True, activation='relu',
)
self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
in_dim = item_dim * (max_len + 1) + user_dim + ctx_dim
layers = []
for h in mlp_hidden:
layers += [nn.Linear(in_dim, h), nn.PReLU(), nn.Dropout(dropout)]
in_dim = h
layers += [nn.Linear(in_dim, 1)]
self.mlp = nn.Sequential(*layers)
def forward(self, user_feats, behaviors, candidate, ctx_feats, mask=None):
# 将候选拼接到行为序列末尾
seq = torch.cat([behaviors, candidate.unsqueeze(1)], dim=1) # (B, T+1, D)
pos = torch.arange(seq.size(1), device=seq.device)
seq = seq + self.pos_embed(pos).unsqueeze(0)
z = self.transformer(seq, src_key_padding_mask=mask) # (B, T+1, D)
flat = z.reshape(z.size(0), -1)
x = torch.cat([flat, user_feats, ctx_feats], dim=1)
return self.mlp(x).squeeze(-1)
|
这些技巧到底能带来多少收益?#

数据源自 DIN/DIEN/DSIN/BST 原论文在 Amazon Books CTR 基准上的结果(经归一化处理)。两点值得关注:
- 从 sum/avg pooling 到 DIN 的跃升最大。引入注意力是单次改动中效果最显著的优化。后续改进均为渐进式:DIEN 在 DIN 基础上提升零点几个百分点,DSIN 略高,BST 则视数据集而定,大致与 DSIN 持平或略优。
- AUC 提升看似微小,但在大规模场景下意义重大。淘宝上 0.005 的 AUC 提升可转化为数个百分点的 CTR 增长及数亿美元的 GMV 增量。这正是团队持续优化“噪声级”指标的原因。
除精度外,各模型成本特性各异:DIN 推理成本最低(注意力仅为每个行为增加一个 MLP);DIEN 的序列化 AUGRU 最慢;BST 在 GPU 上快但显存占用高;DSIN 的实时会话切分则是运维难点。
实用建议:从 DIN 开始。它以 20% 的工程投入捕获 80% 的收益。当行为序列长且话题顺序重要(如订阅产品、有明确演进路径的兴趣)时,考虑 DIEN;当会话边界清晰频繁(如短视频、电商浏览)时,DSIN 更优;若希望统一模型且服务栈已适配 Transformer,则选 BST。
真正能提升效果的工业化技巧#
Dice —— 数据自适应激活函数#

$$
\text{Dice}(x) = p(x) \cdot x + (1 - p(x)) \cdot \alpha x, \qquad p(x) = \sigma\!\left(\frac{x - \mathbb{E}[x]}{\sqrt{\text{Var}[x] + \epsilon}}\right)
$$拐点随数据分布动态调整。右图展示了三个均值不同的 batch:Dice 的拐点随之漂移,而 PReLU 的始终钉在零点。不同层、不同分布、不同有效激活——免费获得。
1
2
3
4
5
6
7
8
9
10
| class Dice(nn.Module):
def __init__(self, dim, eps=1e-8):
super().__init__()
self.alpha = nn.Parameter(torch.zeros(dim))
self.bn = nn.BatchNorm1d(dim, eps=eps, affine=False)
def forward(self, x):
x_norm = self.bn(x)
p = torch.sigmoid(x_norm)
return p * x + (1 - p) * self.alpha * x
|
小批量感知正则化#
$$
\mathcal{L}_{\text{reg}} = \frac{\lambda}{2} \sum_{j \in \mathcal{B}} \frac{n_{j,\mathcal{B}}}{n_j} \|\mathbf{e}_j\|^2
$$其中 $n_{j,\mathcal{B}}$
是 item $j$
在 batch $\mathcal{B}$
中的计数,$n_j$
是其全局计数。效果相当,成本却低数个数量级。
变长序列处理#
真实用户历史长度差异巨大。我们 pad 至固定最大长度,并用 mask 标记有效部分:
1
2
3
4
5
6
7
8
| def pad_and_mask(sequences, max_len, pad_value=0):
padded, masks = [], []
for seq in sequences:
seq = seq[-max_len:] # 只保留最近的行为
pad_len = max_len - len(seq)
padded.append([pad_value] * pad_len + list(seq))
masks.append([0] * pad_len + [1] * len(seq))
return torch.LongTensor(padded), torch.FloatTensor(masks)
|
在注意力中,将 masked 位置设为 $-10^9$
再做 softmax,即可将其权重压至零。
大规模服务优化#
面对百万 QPS:
- 离线预计算并缓存 item embedding。item 表相对静态,每晚重算即可。
- 截断至最近 N 条行为。N = 50–100 通常已捕获大部分信号,成本大降。
- 量化。FP16 或 INT8 可将模型体积压缩 2–4 倍,AUC 几乎无损。
- 批量推理。GPU 在 batch size ≥ 64 时效率最高。
- 用自定义 CUDA 算子替换 AUGRU 的 Python 循环。若 DIEN 必须上线,此步关键。
常见问题#
为何 DIN 用目标注意力而非自注意力?
目标注意力回答“哪些历史行为与 当前 候选相关?”,而自注意力仅关注历史内部关系(如“笔记本和手机同属电子产品”)——虽有用,却不依赖候选,而这恰是推荐的核心。BST 后来证明,Transformer 可同时兼顾两者。
为何 DIN 不用 softmax?
作者发现 softmax 会抹去兴趣 强度。拥有多个强匹配的用户与仅有一个弱匹配的用户,归一化后向量可能相同。去掉 softmax 后,用户向量的模长本身即反映兴趣强度。
辅助损失真有用吗?
确实有用,尤其在长序列上。无辅助损失时,GRU 易退化为平凡状态——虽能降低 CTR 损失,却未表征兴趣。DIEN 论文称,仅辅助损失在 Amazon 数据集上就带来约 0.3% AUC 提升。
计算成本如何?
注意力复杂度为 $O(T^2 \cdot d)$
——$T \le 100$
时尚可接受,更长则难处理。长历史常用策略包括:截断(最常见)、稀疏/线性注意力、两阶段检索(如 SIM 硬搜索 → DIN)。
如何处理冷启动用户?
回退至用户画像(人口统计、地理位置、设备)和品类先验。基于内容的 item embedding(来自标题、图片)在行为稀疏时亦有帮助。
注意力权重是否可解释?
基本可解释,但有前提。它能显示模型在某次推荐中依赖哪些历史行为,利于调试与建立信任。但 softmax 归一化后的权重是 相对值——高权重仅表示相对序列中其他行为更高,并非绝对相关性强。
深度兴趣网络为推荐系统带来了一个持久理念:并非所有历史行为同等重要,模型应在每次推荐时动态判断哪些行为真正关键。
后续工作皆围绕此展开:
- DIN —— 按候选相关性加权行为。
- DIEN —— 建模兴趣如何随时间演化。
- DSIN —— 将行为分组为会话并尊重其结构。
- BST —— 交由 Transformer 自行挖掘一切模式。
好厨师不会给每位客人做同一道菜。有了 DIN,好的推荐系统亦不再如此。
