
强化学习(四):探索策略与好奇心驱动学习
在几乎没有奖励反馈的环境中,智能体如何发现回报?从计数型方法到 ICM、RND、NGU——好奇心驱动探索的完整脉络与工程实践。
将一个全新的智能体放入《蒙特祖玛的复仇》中。要拿到第一分,它必须精确地完成一系列动作:向右走、跳过骷髅、爬上绳子、跳到平台并最终抓起钥匙——这一百个动作中任何一个出错都会导致失败。在拿到钥匙之前,环境给出的奖励始终为 0。
用教科书式的 DQN,设 $\varepsilon = 0.1$ ,随机探索凑齐这一百个动作的概率大约是 $0.1^{100} \approx 10^{-100}$ 。毫不意外,普通 DQN 在该游戏上始终得分为 0——不是得分极低,而是严格意义上的零分,每一轮 episode 都无法获得任何正向奖励。
这就是 稀疏奖励问题,揭示了一个根本局限:如果长期无法观测到非零奖励,再精妙的 Bellman 备份也无法有效更新价值函数。深度强化学习算法的效果几乎完全取决于其探索策略。接下来,我将从最简单的随机探索开始,逐步介绍 好奇心驱动学习 的方法——让智能体自动生成奖励,主动发现新事物。
你将学到什么#
- $\varepsilon$ -greedy、 Boltzmann 和 UCB 在高维环境中为什么会失效
- 计数方法 和通过密度模型实现的伪计数
- ICM (内在好奇心模块):在学习到的特征空间中用预测误差衡量新奇性
- RND (随机网络蒸馏):一种简单但能在大规模场景下有效的好奇心信号
- NGU (Never Give Up):用情景记忆解决惩罚遗忘的任务
- PPO + 好奇心的实际配方、超参数和常见失败模式
前置阅读: 第 1-3 部分 (MDP、 DQN、 Policy Gradient、 PPO 基础)
探索为什么这么难#
经典 ε-greedy:看似简单,问题在哪?#
每本强化学习入门书都会讲 $\varepsilon$ -greedy:以概率 $\varepsilon$ 随机选动作,否则选当前 Q 值最大的动作。公式本身不复杂,难点在于 schedule:随着训练推进,$\varepsilon$ 应该怎么衰减?

上图左侧展示了三种常见 schedule (线性、指数、阶梯式),右侧是线性衰减下 4 个可选动作的实际概率分布。有三点值得注意:
- 不同衰减方式的“探索预算”差异很大。 指数衰减把大部分随机动作集中在前 20k 步;线性衰减更均匀;阶梯式则像是给智能体安排了一个粗略的学习计划。
- 即使 $\varepsilon = 0.05$ ,仍有约 1/4 的随机动作会落在 greedy 动作上($1 - \varepsilon + \varepsilon/|\mathcal{A}|$ )。很多人以为 5% 的 ε 就意味着 5% 的 off-policy 行为,其实不然。
- 这些曲线完全没看状态: 探索只和训练步数有关。这正是其根本缺陷,也构成了后续探索方法的核心改进目标。
Boltzmann (softmax)探索:稍微改进的版本#
$$\pi_\tau(a \mid s) = \frac{\exp(Q(s,a)/\tau)}{\sum_{a'} \exp(Q(s,a')/\tau)}.$$温度 $\tau$ 取代了 $\varepsilon$ :当 $\tau \to 0$ ,策略趋于 greedy;当 $\tau \to \infty$ ,策略趋于均匀分布。

右侧那张图展示了策略熵 $H(\pi_\tau) = -\sum_a \pi_\tau(a) \log \pi_\tau(a)$ 随温度的变化。注意它饱和得非常快:$\tau = 2$ 时已经达到最大熵 $\ln |\mathcal{A}|$ 的 90%。这其实就是 PPO 和 SAC 中常用的 熵正则项(entropy bonus) 的本质——把 Boltzmann 探索包装成策略网络上的正则化项。
但 Boltzmann 和 ε-greedy 共享一个根本缺陷:其动作选择仅依赖当前 Q 值估计,完全不感知各状态区域的历史访问频次。面对两个均未访问过的状态,策略将输出完全相同的 softmax 动作分布。
UCB:理论漂亮,实际难用#
$$a_t = \arg\max_a \left[ \hat Q(a) + c \sqrt{\frac{\ln t}{N(a)}} \right].$$第一项负责利用,第二项负责探索——被选择次数越少的动作,其不确定性奖励越高。

观察上面这张图。$t = 50$ 时,橙色的 UCB bonus 占主导,所有臂看起来都值得一试,拉臂数被均匀分散。$t = 1000$ 时,最优臂 3 已经被拉了几百次, bonus 显著下降,但其他臂的 bonus 仍然较高,算法逐渐稳定在“主要拉 3,偶尔抽查其他”的模式。这才是合理的探索:其探索强度由实际交互数据动态调节,而非依赖预设的衰减 schedule。
那为什么我们不在所有任务里都用 UCB?因为 $N(s, a)$ 在高维状态空间里毫无意义。 Atari 一帧画面是 $84 \times 84 \times 4 = 28{,}224$ 个像素,智能体几乎不可能见到完全相同的两帧。$N(s, a) = 1$ 对任何遇到的 $(s, a)$ 都成立,这个 bonus 项就退化成一个常数。
Thompson 采样:贝叶斯版 UCB#
UCB 的近亲是 Thompson 采样:为每个臂维护一个奖励参数的后验分布,每一步从后验中抽样一个“假想世界”,然后选择在这个世界里最优的动作。对于 Bernoulli 臂 + Beta 先验,更新规则极其简单——成功就 $\alpha + 1$ ,失败就 $\beta + 1$ 。
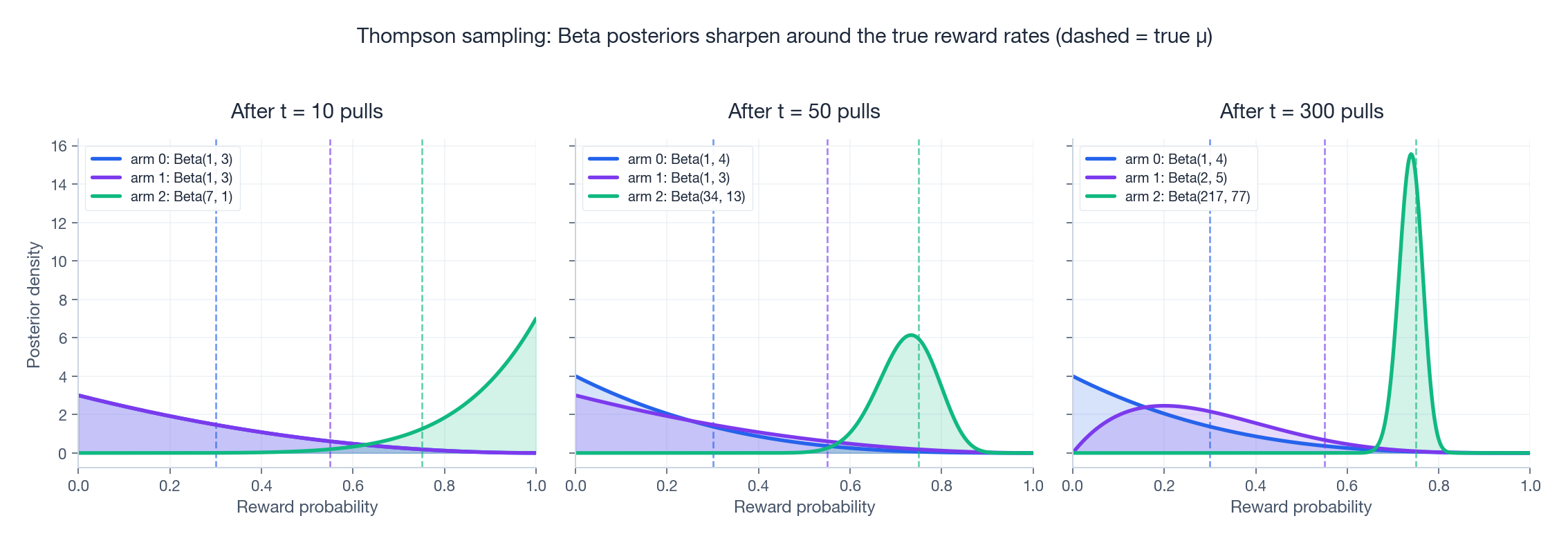
从图中可以看到后验分布逐渐向真实奖励率(虚线)收紧。 10 次后算法几乎没下结论; 300 次时,最优臂 2 ($\mu = 0.75$ )的后验已经是一根细峰,而表现差的臂仍保留了足够的方差,不会被立刻排除。 Thompson 采样在实践中往往与 UCB 持平甚至更好,推荐系统中的 contextual bandit 几乎全是它的天下。但把它直接搬到深度 RL 会遇到和 UCB 同样的问题:在 $10^{60}$ 维状态空间里维护一个后验是不现实的;Bootstrapped DQN、Bayes by Backprop 等贝叶斯深度 RL 方法只能部分还原这种思想。
深度 RL 中“探索难”的四个维度#
综合来看,深度 RL 里的探索难度来自四个方面:
- 奖励稀疏:成百上千个正确动作之后才有一次反馈,随机探索就像大海捞针。
- 状态空间组合爆炸: Atari 有 $256^{28224}$ 种可能帧,根本不可能统计访问次数。
- 局部最优陷阱:死胡同里的一枚硬币会让智能体永远忽略更难找到的大奖。
- 噪声电视问题:如果用朴素的“新奇性”信号,房间里一台播放静态雪花的电视会被当成“新内容”,智能体会盯着它看到训练结束。
现代探索方法的核心范式转变在于:探索策略不再依赖全局训练步数,而取决于智能体在当前状态下的局部经验。 婴儿的学习方式正是如此:他们倾向于探索新奇的刺激,而非重复已熟悉的事物。
好奇心的核心设计:内在奖励#

接着,用任何你喜欢的 RL 算法(DQN、 PPO、 IMPALA……)基于 $r^{\text{total}}$ 训练智能体。所有的设计重点都围绕一个问题展开:
怎么计算 $r^{\text{int}}_t$ ,让它对真正新奇的体验给出高奖励,对重复无聊的体验给出低奖励,还不用去数像素?
接下来,我会介绍三种答案,越往后越精妙。
计数型方法:计数还能用的时候#
$$r^{\text{int}}(s) = \frac{\beta}{\sqrt{N(s)}},$$它的理论保证与 UCB 完全一致。但问题是,在基于像素的环境中,几乎所有状态都满足 $N(s) = 0$ 。
$$\hat N(s) = \frac{\rho(s)\bigl(1 - \rho_{\text{new}}(s)\bigr)}{\rho_{\text{new}}(s) - \rho(s)},$$其中 $\rho_{\text{new}}$ 是在额外观察一次 $s$ 后模型的密度。这个方法假设 $\rho$ 是一个巨型计数器的经验分布,然后通过反推得到伪计数。使用强大的密度模型(如 PixelCNN 或神经自回归模型),它首次在《蒙特祖玛的复仇》上取得了非平凡的成绩。但这种方法也有明显缺陷:训练成本高、模型脆弱,而且噪声电视问题依然无解——随机像素噪声会被判定为低密度、高新奇性,从而获得高额奖励。现代系统逐渐放弃了伪计数,转向更稳健的预测误差方法。
ICM:用预测误差驱动好奇心#

Intrinsic Curiosity Module (ICM)(Pathak 等, ICML 2017)把“我见过这个状态吗?”换成“我能预测接下来会发生什么吗?”。背后的直觉很简单:
- 如果环境对我的动作反应 可预测,说明我已经理解了——内在奖励低。
- 如果反应让我 意外,说明我的模型还没学会解释它——内在奖励高。
直接预测原始像素是个坏主意:电视雪花完全不可预测,但毫无意义。 ICM 的聪明之处在于,它在一个 学到的特征空间 $\phi$ 中做预测,而这个特征空间只保留 智能体动作能影响的信息。

上图左侧展示了 ICM 的三个核心组件:
- 编码器 $\phi$ (CNN)将当前状态 $s_t$ 映射为特征向量 $\phi(s_t)$ 。
- 前向模型 $\hat f$ 根据当前特征和动作预测下一时刻的特征:$\hat\phi_{t+1} = \hat f(\phi(s_t), a_t)$ 。它的平方误差 $ r^{\text{int}}_t = \eta \,\bigl\| \hat\phi_{t+1} - \phi(s_{t+1}) \bigr\|^2 $ 就是内在奖励。
- 逆向模型 $g$ 根据连续两帧的特征预测动作:$\hat a_t = g(\phi(s_t), \phi(s_{t+1}))$ 。它的损失会反向传播到编码器 $\phi$ 。
第三步是关键。逆向模型只有在 $\phi$ 保留了“随动作变化的信息”时才能成功。静态背景、电视雪花等与动作无关的干扰会被过滤掉,因为它们对预测动作没有帮助。这些干扰一旦被去掉,前向模型就不会误把它们当成新奇性。
参考实现#
| |
实测效果#
在《蒙特祖玛的复仇》中, ICM + A3C 在 25M 帧内能达到约 6,600 分(vanilla DQN 永远是 0)。更令人惊讶的是,如果完全去掉外在奖励,只用 ICM 的内在奖励,智能体依然能学会在前几个房间穿梭、躲避敌人、捡起钥匙——因为这些行为能让它的前向模型保持忙碌。
ICM 的局限#
- 随机环境的问题: 如果环境中有一个真正随机的老虎机,前向模型永远无法预测结果,智能体会沉迷于拉杆。逆向模型可以过滤掉“与动作无关”的随机性,但“与动作相关”的随机性仍然会导致问题。
- 计算开销大: 除了策略网络,还要额外训练三套网络(编码器、前向、逆向),训练成本大约是 vanilla PPO 的 2 倍。
RND:简单到令人惊讶的替代方案#
Random Network Distillation (RND)(Burda 等, ICLR 2019)用一个简单的观察取代了 ICM 的整套前向和逆向机制:
蒸馏一个固定的随机网络。预测器误差大的地方,就是智能体还没充分探索的地方。
具体来说, RND 使用两个网络(架构图右半部分):
- 目标网络 $f$ :随机初始化权重,整个训练过程中保持冻结。
- 预测网络 $\hat f$ :通过梯度下降训练,目标是最小化观测状态上的误差 $\| \hat f(s) - f(s) \|^2$ 。
对于预测器见过多次的状态,训练会让误差降到接近零——奖励低。对于全新的状态,预测器从未接触过,输出是随机的,残差很大——奖励高。冻结的目标网络就像一个确定性哈希函数:结构相似的状态会映射到相似的目标,泛化能力自然就有了。
同样的方法还能解决噪声电视问题。随机雪花虽然视觉上差异很大,但在随机 CNN 看来,它们的结构高度相似。预测器只需几次更新就能匹配这些帧,奖励迅速衰减到零。 ICM 和 RND 解决“噪声电视”的方式完全不同: ICM 过滤特征, RND 利用随机映射的一致性。
参考实现#
| |
核心数据#
- 《蒙特祖玛的复仇》:平均得分 8,152 分——首个突破人类专家基准 7,385 分的算法。
- 《Pitfall!》: 70.4 分(之前最好成绩是 0 分)。
- 在一两年内, RND 是所有“硬探索”Atari 游戏中表现最强的方法。
让 RND 成功的两个关键技巧是:(i) 策略网络中有两个独立的价值头,分别估计 $r^{\text{ext}}$ 和 $r^{\text{int}}$ ,并使用不同的折扣因子;(ii) 使用滑动标准差对内在奖励进行逐环境归一化。如果不做归一化,内在奖励的尺度会失控,淹没外部奖励,导致训练崩溃。
NGU:永不放弃任何状态#
RND 有个隐含假设:一旦某个状态的预测误差降到零,这个状态就再也不会被视为新奇。大多数时候这没问题,但有两种重要场景会因此出问题:
- 钥匙-门任务。智能体死亡重生后,需要重新去捡钥匙。但 RND 已经认为钥匙的位置无聊了,智能体不会再回去拿。
- 回溯探索。探索完地图右半部分后,智能体必须从起点返回左半部分继续探索。起点已经被走过几千次, RND 不会奖励它再次穿过那里。
- 情景新奇性 $r^{\text{episodic}}$ :维护一个只记录当前 episode 的状态嵌入记忆库。如果当前状态在嵌入空间中距离记忆库中的所有状态都很远,奖励就会很大。关键点在于,这个记忆库会在每个新 episode 开始时清空。即使某个状态在整个训练过程中被访问过千百万次,在新的一局中仍然会被视为新奇。
- 生命周期新奇性 $r^{\text{lifetime}}$ :这是经典的 RND 信号,加了一个上限 $L$ 防止数值失控。
乘法确保了两者的高要求:一个状态既要“在本局新鲜”,又要“在全局尚未走腻”,才能获得高分。 NGU 还引入了一组并行训练的不同探索策略,以及一种定向探索机制,但情景-生命周期分解才是它的核心思想。
后续的 Agent57(Badia 等, 2020)在 NGU 基础上增加了一个元控制器,动态选择当前使用的探索策略。它是第一个在 全部 57 个 Atari 游戏 上都超越人类基线的单一算法。
关键得分对比#
| 游戏 | DQN (ε-greedy) | RND | NGU | 人类专家 |
|---|---|---|---|---|
| 蒙特祖玛的复仇 | 0 | 8,152 | 11,000+ | 7,385 |
| Pitfall! | 0 | 70 | 5,000+ | 6,464 |
| Private Eye | 0 | 8,800 | 69,000 | 69,571 |
直观对比:随机 vs 好奇#
在一个极小的问题上,直接看看“随机”和“好奇”两种探索方式到底有多大差别。

两张图都展示了同一个智能体从白色星号出发,在 25x25 的 GridWorld 中走 1500 步的轨迹。蓝色智能体是均匀随机游走;紫色智能体按照 $1/\sqrt{N(s')}$ 的概率从邻居中选择下一步——这是最简单的基于计数的好奇心奖励。同样是 1500 步,随机游走只覆盖了 65.6% 的网格,最喜欢的格子踩了 19 次;而好奇心驱动的智能体覆盖了 80%,最多重访次数只有 11。右图用对数尺度的访问分布进一步说明了这一点:好奇心让分布头部更平(没有过度访问的格子),尾部更高(没有被忽略的格子)。
把这个效应放大到 $10^8$ 帧、状态空间大如系外行星的 Atari 游戏里,就能明白为什么好奇心是 0 分和 11000 分之间的关键。

这张图在更大规模上讲了同一个故事。 Vanilla DQN 始终停留在 0 分——它一次奖励都没找到。从 count-based 到 ICM、 RND 再到 NGU,每一代好奇心方法都缩短了“首次拿到奖励”的时间,同时提高了渐进得分。 NGU 是第一个突破人类专家虚线的方法。
实用配方: PPO + 好奇心在生产环境中的应用#
超参数起始值建议#
| 参数 | 推荐初始值 | 备注 |
|---|---|---|
| 内在奖励系数 $\beta$ | 0.01 | 如果奖励极其稀疏,可以调到 0.1 |
| 奖励归一化 | 必须开启,分别对 $r^{\text{ext}}$ 和 $r^{\text{int}}$ 归一化 | 不然 RND/ICM 可能会压过任务奖励 |
| 折扣因子 $\gamma_{\text{int}}$ | 0.99 | 通常比 $\gamma_{\text{ext}}$ 小一点,鼓励局部探索 |
| 双价值头 | 是 | 每种奖励一个头,效果始终优于混合 |
| 帧跳过 / 堆叠 | 4 / 4 | Atari 标准配置 |
| 梯度裁剪 | 0.5 | ICM/RND 的梯度可能有厚尾分布 |
训练进度的预期表现#
使用 PPO + RND 在 Montezuma’s Revenge 上,单张现代 GPU:
| 帧数 | 预期里程碑 |
|---|---|
| 10M | 稳定通过第一个房间(≈100 分) |
| 30M | 拿到钥匙并开门(≈400 分) |
| 100M | 平均回报 6000+,偶尔达到 8000+ |
如果跑完 20M 帧还没突破第一个里程碑,最常见的问题依次是:没对 $r^{\text{int}}$ 归一化、用了单价值头、$\beta$ 设置得太低。
方法选择指南#
| 场景 | 推荐探索策略 | 原因 |
|---|---|---|
| 奖励密集,低维观测 | $\varepsilon$ -greedy 线性衰减 | 成本低,够用 |
| 连续控制(MuJoCo、机器人) | SAC 熵奖励或参数噪声 | 平滑动作空间需要平滑探索 |
| 单个稀疏奖励 Atari 游戏 | PPO + RND | 简洁与性能的最佳平衡 |
| 需要反复访问同一状态的稀疏奖励任务 | NGU | 情景记忆适合处理“重复做某事” |
| 全 Atari、追求研究级 SOTA | Agent57 / Go-Explore | 当前顶尖方法,但工程复杂度高 |
总结与展望#
探索问题是将玩具级强化学习升级为通用智能的关键瓶颈。随机探索的扩展性极差——不是因为数学错误,而是因为可能状态的宇宙空间远远超出了均匀采样能覆盖的范围。
所有现代进展背后的统一思想:
将好奇心视为可学习的奖励: 操作性地定义"新奇性"——作为低访问计数、高预测误差、大蒸馏残差或与情景记忆的距离——然后让智能体在任务奖励之外最大化它。
我们看到了四种具体实现:
- 基于计数 / 伪计数 — 在表格 MDP 中优雅,在像素中脆弱。
- ICM — 在学习到的、动作相关的特征空间中的预测误差。
- RND — 随机网络的蒸馏误差;简单到尴尬,有效到惊人。
- NGU / Agent57 — 情景新奇性和终身新奇性相乘,适用于惩罚遗忘的任务。
探索问题远未解决。当前方法仍需要大约 $10^8$ -$10^9$ 环境帧;而人类大脑只用几小时就能解决蒙特祖玛的复仇。活跃的研究方向包括技能发现、语言引导的探索以及从人类演示中学习探索策略。
下一篇: 第 5 部分 介绍 基于模型的强化学习与世界模型 — 学习环境的可微分模拟器,使智能体能够在每次真实交互中"梦想"成千上万条想象轨迹。
参考文献#
- Pathak, D., Agrawal, P., Efros, A. A., & Darrell, T. (2017). Curiosity-driven exploration by self-supervised prediction. ICML. arXiv:1705.05363
- Burda, Y., Edwards, H., Storkey, A., & Klimov, O. (2019). Exploration by random network distillation. ICLR. arXiv:1810.12894
- Badia, A. P., Sprechmann, P., Vitvitskyi, A., et al. (2020). Never Give Up: learning directed exploration strategies. ICLR. arXiv:2002.06038
- Badia, A. P., Piot, B., Kapturowski, S., et al. (2020). Agent57: outperforming the Atari human benchmark. ICML. arXiv:2003.13350
- Bellemare, M. G., Srinivasan, S., Ostrovski, G., Schaul, T., Saxton, D., & Munos, R. (2016). Unifying count-based exploration and intrinsic motivation. NeurIPS. arXiv:1606.01868
- Ecoffet, A., Huizinga, J., Lehman, J., Stanley, K. O., & Clune, J. (2021). First return, then explore. Nature, 590, 580-586. arXiv:2004.12919
- Auer, P., Cesa-Bianchi, N., & Fischer, P. (2002). Finite-time analysis of the multi-armed bandit problem. Machine Learning, 47, 235-256.
强化学习 12 篇
- 01 强化学习(一):基础与核心概念
- 02 强化学习(二):Q-Learning 与深度 Q 网络(DQN)
- 03 强化学习(三):Policy Gradient 与 Actor-Critic 方法
- 04 强化学习(四):探索策略与好奇心驱动学习 当前
- 05 强化学习(五):Model-Based 强化学习与世界模型
- 06 强化学习(六):PPO 与 TRPO —— 信任域策略优化
- 07 强化学习(七):模仿学习与逆强化学习
- 08 强化学习(八):AlphaGo 与蒙特卡洛树搜索
- 09 强化学习(九):多智能体强化学习
- 10 强化学习(十):离线强化学习
- 11 强化学习(十一):层次化强化学习与元学习
- 12 强化学习(十二):RLHF 与大语言模型应用