核方法:从理论到实战 (RKHS、常见核函数与超参数调优)
理解核技巧、RKHS 理论与实用核函数选择。涵盖 RBF、多项式、Matern、周期核,含 sklearn 代码与调优流程图。
你手上是非线性数据,工具箱里却只有线性算法。核技巧(kernel trick)让你把这套线性算法直接用在非线性数据上——而且全程不需要把高维特征映射写出来。这篇文章先讲直觉,再补数学,最后给一套能直接搬到生产里的工具箱。
你将学到
- 核技巧到底为什么能工作,又给你换来了什么
- 数学基础:正定核、RKHS、Mercer 定理
- 常见核函数:RBF、多项式、线性、Matern、周期核、sigmoid
- 超参数调优:网格搜索、随机搜索、边际似然
- 故障排查:过拟合、欠拟合、数值不稳定、尺度问题
- SVM、GP、Kernel PCA 的核函数选择决策树
前置知识
- 线性代数基础(内积、特征分解)
- 对 SVM 或高斯过程有概念性了解
- Python + scikit-learn
为什么核方法重要
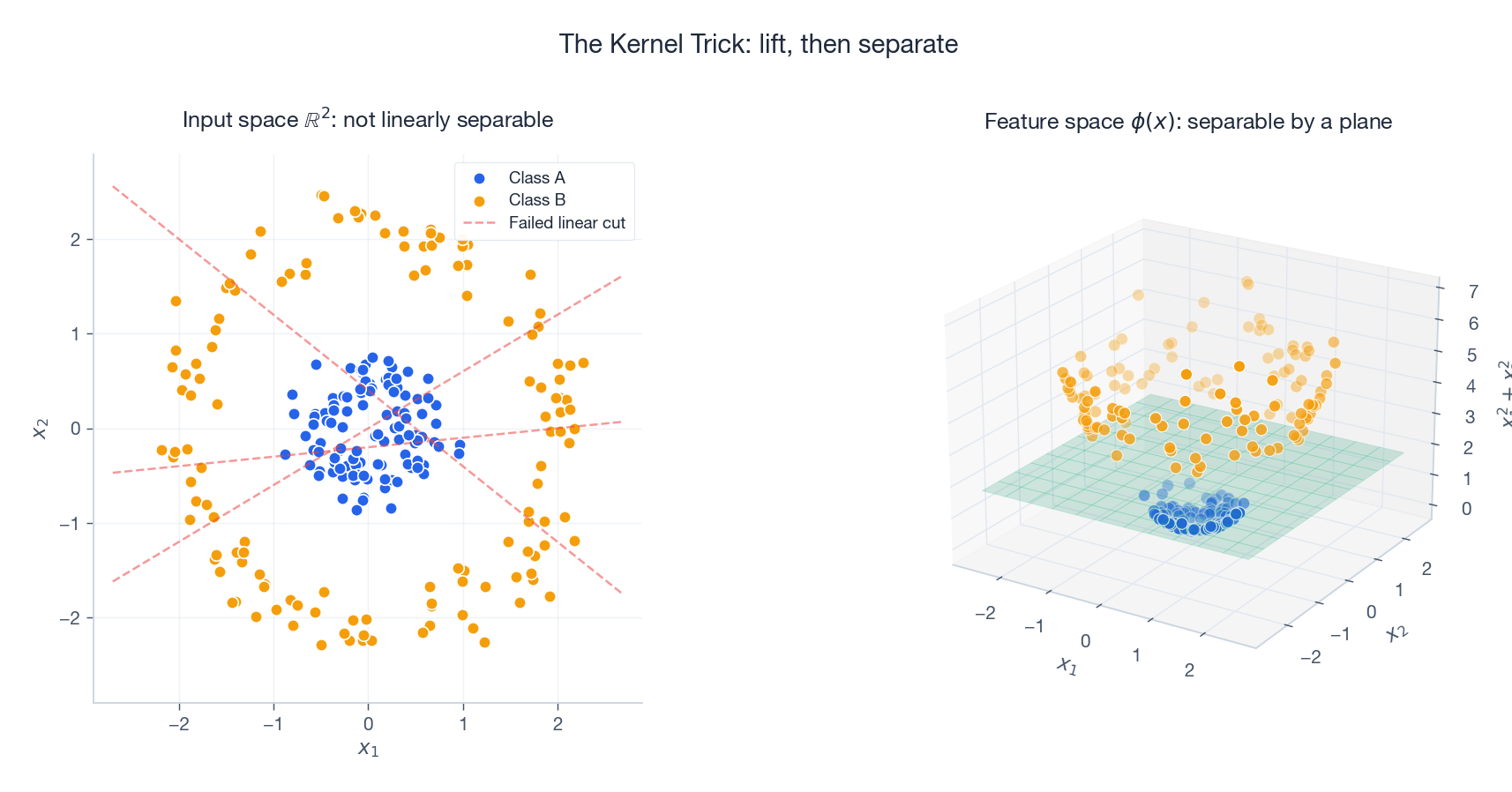
线性算法的天花板
意外地多的常用算法——线性回归、PCA、线性 SVM、岭回归、Fisher 判别——都只在线性可分或有线性结构的数据上表现良好。可现实数据基本都不配合。
最朴素的对策是手工造特征:加多项式项、交互项、对数变换、指示变量。这条路走得通,但有三个老大难:
- 繁琐。 需要领域知识反复试。
- 组合爆炸。 $d$ 个原始特征两两相乘就有 $\binom{d+2}{2}$ 个二阶特征,三阶更夸张。
- 存不下也算不动。 高维 $\phi(x)$ 既要存又要算,代价直接顶上来。
核技巧:把映射藏起来
关键观察来了。如果你的算法只通过内积 $\langle \phi(x_i), \phi(x_j)\rangle$ 接触数据,那干脆别算 $\phi$,直接选一个函数
$$K(x_i, x_j) = \langle \phi(x_i), \phi(x_j) \rangle$$让它直接吐出内积就行。算法在高维空间里能算出什么,现在照样能算出来,但 $\phi(x)$ 自始至终没出现过。
核技巧 把一个显式映射 $x \mapsto \phi(x)$ 换成了一个相似度函数 $K(x, y)$ 定义的隐式映射。
上面的图把这件事讲透了。在原始二维空间里,两类点是同心圆,没有任何直线能把它们分开。把每个点抬升一下,$\phi(x) = (x_1, x_2, x_1^2 + x_2^2)$,两层圆环就被抬到了不同高度——一个平面就把它们切开了。多项式核 $K(x, y) = (\langle x, y\rangle + 1)^2$ 对应的就是所有二阶多项式特征,但你只算一个内积,不必存下那 $O(d^2)$ 个新坐标。
数学基础
把核技巧从一个聪明的小动作升格为一套理论,靠的是三个结果:正定核(什么样的 $K$ 才算"合法的内积"?)、Mercer 定理(隐式特征空间长什么样?)、RKHS 构造(核方法到底是在什么函数空间上做优化?)。
正定核
一个对称函数 $K: \mathcal{X} \times \mathcal{X} \to \mathbb{R}$ 称为正定的,如果对任意有限点集 $\{x_1, \dots, x_n\}$ 和任意实向量 $c \in \mathbb{R}^n$,都有
$$\sum_{i,j=1}^n c_i c_j \, K(x_i, x_j) \;\geq\; 0.$$等价地,Gram 矩阵 $K_{ij} = K(x_i, x_j)$ 在任何采样下都半正定(PSD)。
为什么这个性质这么关键:正定核恰好就是某个希尔伯特空间里的内积函数。所以选一个正定核,等价于选一个隐式特征映射——只是你不必把它写出来。
Mercer 定理
如果 $K$ 在紧集上连续、对称、正定,那么它有谱分解
$$K(x, y) \;=\; \sum_{k=1}^{\infty} \lambda_k \, \phi_k(x) \, \phi_k(y), \qquad \lambda_k \geq 0,$$其中 $\phi_k$ 是正交归一化的特征函数,$\lambda_k$ 是非负特征值。隐式特征映射就是
$$\phi(x) \;=\; \big(\sqrt{\lambda_1}\,\phi_1(x),\; \sqrt{\lambda_2}\,\phi_2(x),\; \dots\big).$$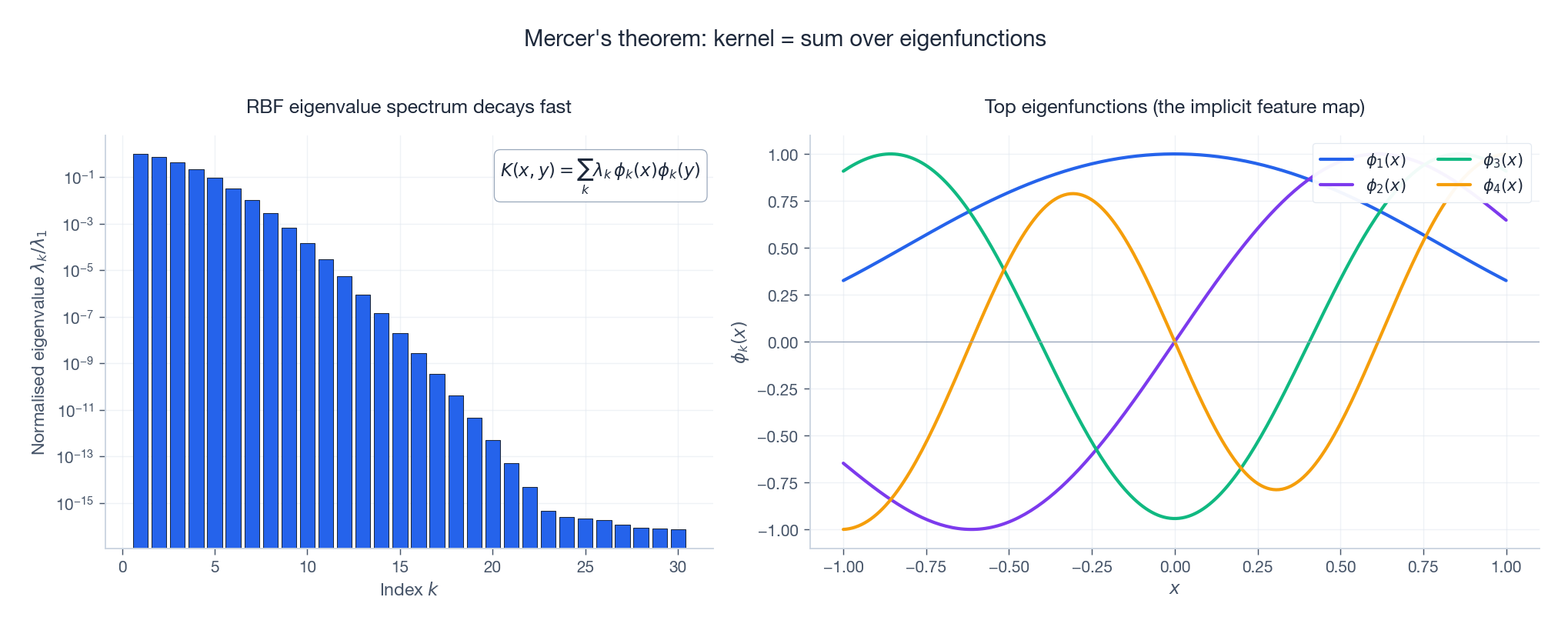
图里有两件事值得品一下:
- 特征值衰减很快。 少数几个分量就承载了核绝大部分"能量"。这正是 Nystrom、随机傅里叶特征这类低秩近似为什么能 work 的原因。
- 特征函数像傅里叶模式。 RBF 核在区间上的前几个特征函数,是越来越振荡的光滑波包——核相当于在"光滑函数基"上度量相似度。
对 RBF 核来说,谱是无穷的:每个 $\lambda_k > 0$。这就是大家口中那句"RBF 的特征空间是无穷维的"的真实含义。
再生核希尔伯特空间(RKHS)
Moore-Aronszajn 定理告诉我们:每个正定核唯一地对应一个函数希尔伯特空间 $\mathcal{H}_K$,满足两条性质:
- 每个 $f \in \mathcal{H}_K$ 都是函数 $\mathcal{X} \to \mathbb{R}$。
- 再生性。 对任意 $f \in \mathcal{H}_K$ 和 $x \in \mathcal{X}$,$f(x) = \langle f, K(x, \cdot) \rangle_{\mathcal{H}_K}$。
再生性是 RKHS 理论威力的来源:在某点取值这个动作变成了一个有界的线性运算,由跟 $K(x, \cdot)$ 做内积给出。
实际后果就是大名鼎鼎的表示定理(representer theorem)。当你最小化一个正则化风险
$$\min_{f \in \mathcal{H}_K} \;\frac{1}{n}\sum_i L(y_i, f(x_i)) \;+\; \lambda \|f\|_{\mathcal{H}_K}^2,$$最优解 $f^*$ 一定落在由 $\{K(x_i, \cdot)\}_{i=1}^n$ 张成的有限维子空间里:
$$f^*(x) \;=\; \sum_{i=1}^n \alpha_i \, K(x_i, x).$$不管 $\mathcal{H}_K$ 是多么"无穷维",你永远只需要 $n$ 个系数 $\alpha_i$。这正是核 SVM、高斯过程能算得动的结构性原因。
核技巧实战
核 SVM
软间隔 SVM 的对偶问题是
$$\max_{\alpha} \;\sum_i \alpha_i \;-\; \tfrac{1}{2}\sum_{i,j} \alpha_i \alpha_j y_i y_j \,\langle x_i, x_j \rangle, \qquad 0 \leq \alpha_i \leq C.$$数据只通过内积 $\langle x_i, x_j\rangle$ 出现。把它替换成 $K(x_i, x_j)$,你就得到一个非线性分类器,优化问题、变量个数、求解器都不变。决策函数变成
$$f(x) \;=\; \sum_{i \in \mathrm{SV}} \alpha_i y_i \, K(x_i, x) + b.$$核 PCA
标准 PCA 对 $d \times d$ 协方差矩阵做特征分解。核 PCA 改对 $n \times n$ 中心化 Gram 矩阵做特征分解。前几个特征向量 $\alpha^{(k)}$ 给出投影
$$z_k(x) \;=\; \sum_{i=1}^n \alpha_i^{(k)} \, K(x_i, x),$$提取出非线性主成分,$\phi(x)$ 一次也不用具体化。
核岭回归
最小化 $\sum_i (y_i - f(x_i))^2 + \lambda \|f\|^2_{\mathcal{H}_K}$ 有闭式解
$$\hat{f}(x) = \mathbf{k}(x)^\top (K + \lambda I)^{-1} \mathbf{y},$$其中 $\mathbf{k}(x)_i = K(x_i, x)$。这同时也是协方差为 $K$、噪声方差为 $\lambda$ 的高斯过程的后验均值——核岭回归和 GP 回归本质上是同一件事。
常见核函数:理论与实战
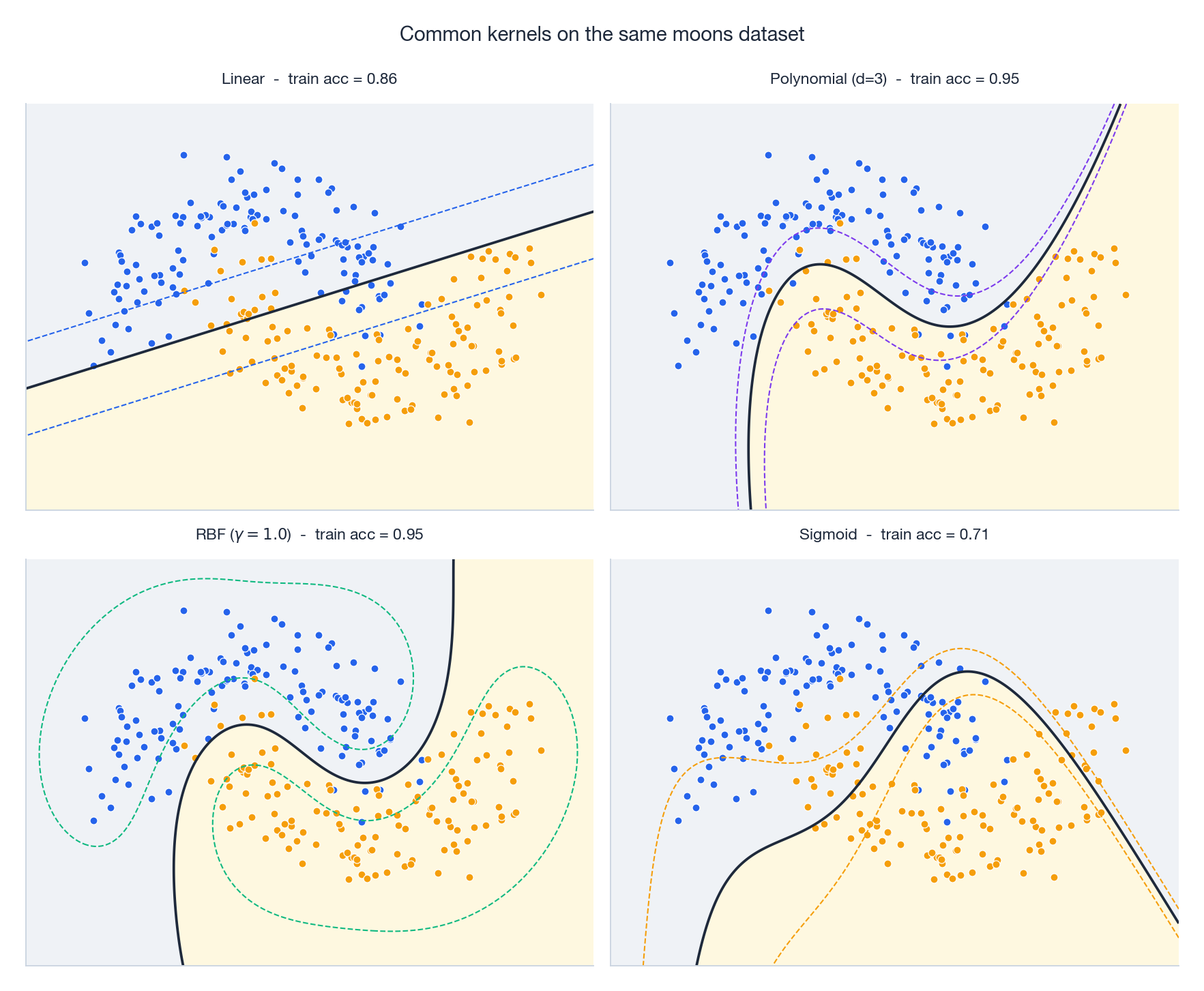
挑同一份数据,只换核,决策边界的"性格"就完全变了。线性核拐不了弯;多项式核按代数曲线弯;RBF 紧贴数据;sigmoid 经常调皮捣蛋。下面是日用手册。
1. RBF(高斯)核
$$K(x, y) = \exp\!\left(-\gamma \,\|x - y\|^2\right) \quad \text{或} \quad \exp\!\left(-\frac{\|x-y\|^2}{2\sigma^2}\right).$$(scikit-learn 用 $\gamma$,许多教科书用 $\sigma$,关系是 $\gamma = 1/(2\sigma^2)$。)
性质。 无穷维特征空间,无穷阶可微,万能逼近——只要数据够、带宽合适,可以逼近紧集上任意连续函数。
何时使用。 SVM、GP、核 PCA 的默认选择。任何你预期"光滑、局部"结构的场景。
超参数 $\gamma$(或 $\sigma$)。 这一个数控制了"影响半径",是你需要做的最重要的决定,没有之一。
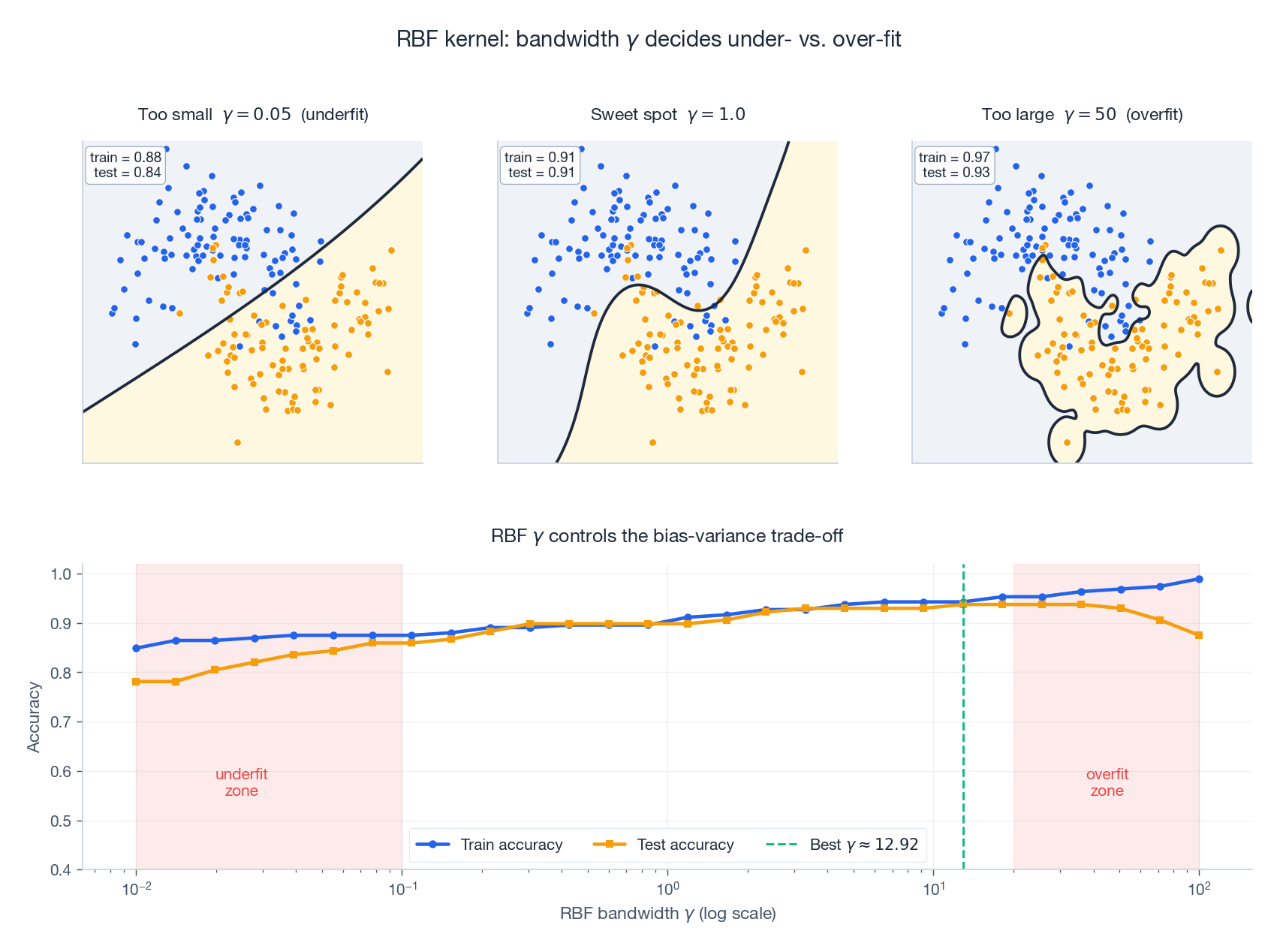
- $\gamma$ 太大($\sigma$ 太小):每个训练点只影响自己。Gram 矩阵几乎退化成单位矩阵;模型把训练集背了下来;测试精度垮掉。
- $\gamma$ 太小($\sigma$ 太大):所有点对所有点看起来都一样;核退化成常数;模型欠拟合。
- 甜点区。 在对数网格上做交叉验证找。一个不错的初值是中位数启发式:$\sigma \approx \mathrm{median}(\|x_i - x_j\|)$,相应地 $\gamma \approx 1/(2 \cdot \mathrm{median}^2)$。
2. 多项式核
$$K(x, y) = (\gamma\, \langle x, y \rangle + c)^d.$$性质。 有限维特征空间(所有不超过 $d$ 阶的单项式)。能显式捕捉到 $d$ 阶为止的交互。
何时使用。 稀疏高维且交互结构已知的数据(带 bigram 的文本分类、有上位效应的基因组学)。低维稠密数据上不要用——RBF 通常更强。
超参数。 $d$ 实战里取 2 或 3;五阶以上几乎一定过拟合。$\gamma$ 缩放内积(对特征量纲敏感,先归一化)。$c$ 控制低阶与高阶项的权衡:$c = 0$ 只保留最高阶单项式,$c = 1$ 把各阶混起来。
3. 线性核
$$K(x, y) = \langle x, y \rangle.$$最朴素的核。没有特征映射,每次求值 $O(d)$,等价于直接跑线性算法。
何时使用。 数据本身线性可分,或者高维稀疏数据(文本、基因表达),或者作为基线对比。文本场景下线性 SVM 经常碾压 RBF——这里维度高反倒是优势:高维空间中的随机点彼此近似正交。
4. Sigmoid 核
$$K(x, y) = \tanh(\gamma\, \langle x, y \rangle + c).$$模仿神经网络激活的形式,但并不总是正定——只在某些 $\gamma, c$ 范围里成立。现代实践基本已经放弃它:想要神经网络风格的非线性,那就训练神经网络。这里列出来主要是为了让你在老代码里能认出它。
5. Matern 核(高斯过程)
$$K_\nu(r) = \frac{2^{1-\nu}}{\Gamma(\nu)} \left(\frac{\sqrt{2\nu}\, r}{\ell}\right)^{\!\nu} \! K_\nu\!\left(\frac{\sqrt{2\nu}\, r}{\ell}\right), \qquad r = \|x - y\|.$$Matern 核的平滑度参数 $\nu$ 可调:
- $\nu = 1/2$:指数核,样本路径连续但处处不可微。适合粗糙函数。
- $\nu = 3/2$:样本路径一阶可微。
- $\nu = 5/2$:二阶可微。贝叶斯优化里最常用的设置。
- $\nu \to \infty$:退化为 RBF(无穷光滑)。
何时使用。 高斯过程回归里几乎总是优先于 RBF。RBF 那种"无穷光滑"对真实函数来说强得不真实;Matern $\nu = 5/2$ 是最稳的默认值。
6. 周期核(时间序列)
$$K(x, y) = \exp\!\left(-\frac{2 \sin^2(\pi \|x - y\| / p)}{\ell^2}\right).$$捕捉严格周期性,周期为 $p$。常用做法是把它和 RBF 或线性核加在一起,建模"趋势 + 季节性"。
何时使用。 有季节性的时间序列(温度、电力负荷、销量),音频音高跟踪,任何有已知周期分量的信号。
超参数调优
交叉验证(首选方案)
把数据切成 $k$ 折,用 $k-1$ 折训练、剩 1 折验证,平均得分。挑平均验证得分最好的那组超参数。
| |
超参数空间维度更高时,随机搜索比网格搜索更省样本:
| |
边际似然(高斯过程)
GP 回归里可以通过最大化对数边际似然来调超参 $\theta$:
$$\log p(\mathbf{y} \mid \theta) = -\tfrac{1}{2} \mathbf{y}^\top (K_\theta + \sigma^2 I)^{-1} \mathbf{y} \;-\; \tfrac{1}{2} \log |K_\theta + \sigma^2 I| \;-\; \tfrac{n}{2}\log(2\pi).$$这条路有原理性优势(不需要单独划验证集),而且式子能拆成"拟合项 + 复杂度惩罚 + 常数"——奥卡姆剃刀直接从数学里掉出来。需要警惕的是:数据噪声大、超参数多时,边际似然优化也会过拟合,加上一些弱先验(比如对长度尺度加对数正态先验)能稳很多。
诊断:看 Gram 矩阵
核矩阵本身就是一面镜子,直接告诉你超参数是不是合理。
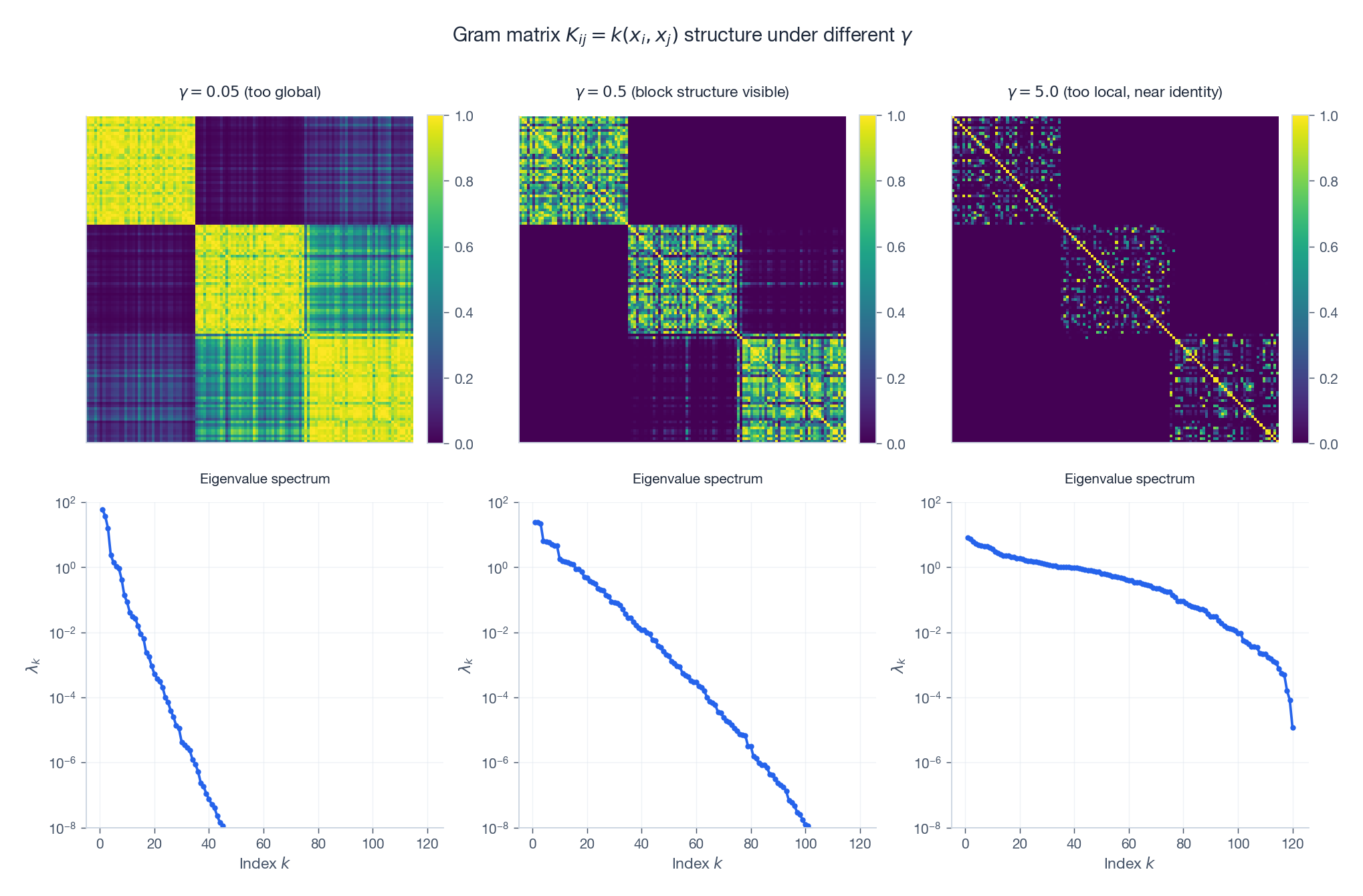
三个高斯簇上 RBF 核的三种状态(行按簇号排过序):
- $\gamma$ 太小。 矩阵均匀偏亮——所有点对看起来都差不多。特征值谱被一个模式主导。欠拟合。
- $\gamma$ 在甜点区。 三个清晰的对角块浮现出来,每个簇一块。谱呈现明显的三阶台阶。核"看见"了簇结构。
- $\gamma$ 太大。 矩阵塌缩成单位阵。谱平坦。每个点都是孤岛,泛化无从谈起。
开发期两行代码即可检查:
| |
故障排查
问题 1:过拟合
症状。 训练精度接近 1.0;测试精度差很多;Gram 矩阵看着接近对角阵。
原因。 RBF $\gamma$ 太大(带宽太小)、多项式阶数过高、SVM $C$ 太大(正则化不够)。
修法。 减小 $\gamma$;降低多项式阶数;减小 $C$;加大 GP 噪声方差;加更多训练数据。
问题 2:欠拟合
症状。 训练和测试精度都不行。预测几乎是常数。
原因。 用线性核处理非线性数据;RBF $\gamma$ 太小;SVM $C$ 太小。
修法。 沿表达力阶梯往上走:线性 → 多项式 → RBF;增大 $\gamma$;增大 $C$。
问题 3:数值不稳定
症状。 GP 拟合报"奇异矩阵";核 PCA 出现负特征值;SVM 求解器不收敛。
原因。 Gram 矩阵秩亏或病态。常见诱因:重复点、自定义核非 PSD、$\gamma$ 极小。
修法。
- 加抖动:
K = K + 1e-6 * np.eye(n)。 - 标准化特征——基于距离的核(RBF、Matern)对量纲极其敏感。
- 去掉近重复行。
- 核矩阵用 64 位浮点。
- 自定义核要验 PSD:
np.all(np.linalg.eigvalsh(K) >= -1e-8)。
问题 4:训练太慢
症状。 $10^4$ 样本上 SVM 跑几小时;GP 回归过几千就跑不动。
原因。 核方法是 $O(n^2)$ 内存、$O(n^3)$ 计算(矩阵分解)。
修法。
- 能用线性核就用:
LinearSVC/ SGD 能轻松扩展到百万级。 - Nystrom 近似(
sklearn.kernel_approximation.Nystroem):选 $m \ll n$ 个 landmark,得到一个显式的 $m$ 维特征映射。 - 随机傅里叶特征用于平移不变核(RBF、Matern):显式映射维度 $D$,误差按 $1/\sqrt{D}$ 衰减。
- 稀疏 / 诱导点 GP(
gpytorch、GPy):把 GP 扩展到 $10^5$ 量级。 - $n \gtrsim 10^5$ 且结构复杂时,切到深度学习。
核函数选择决策树
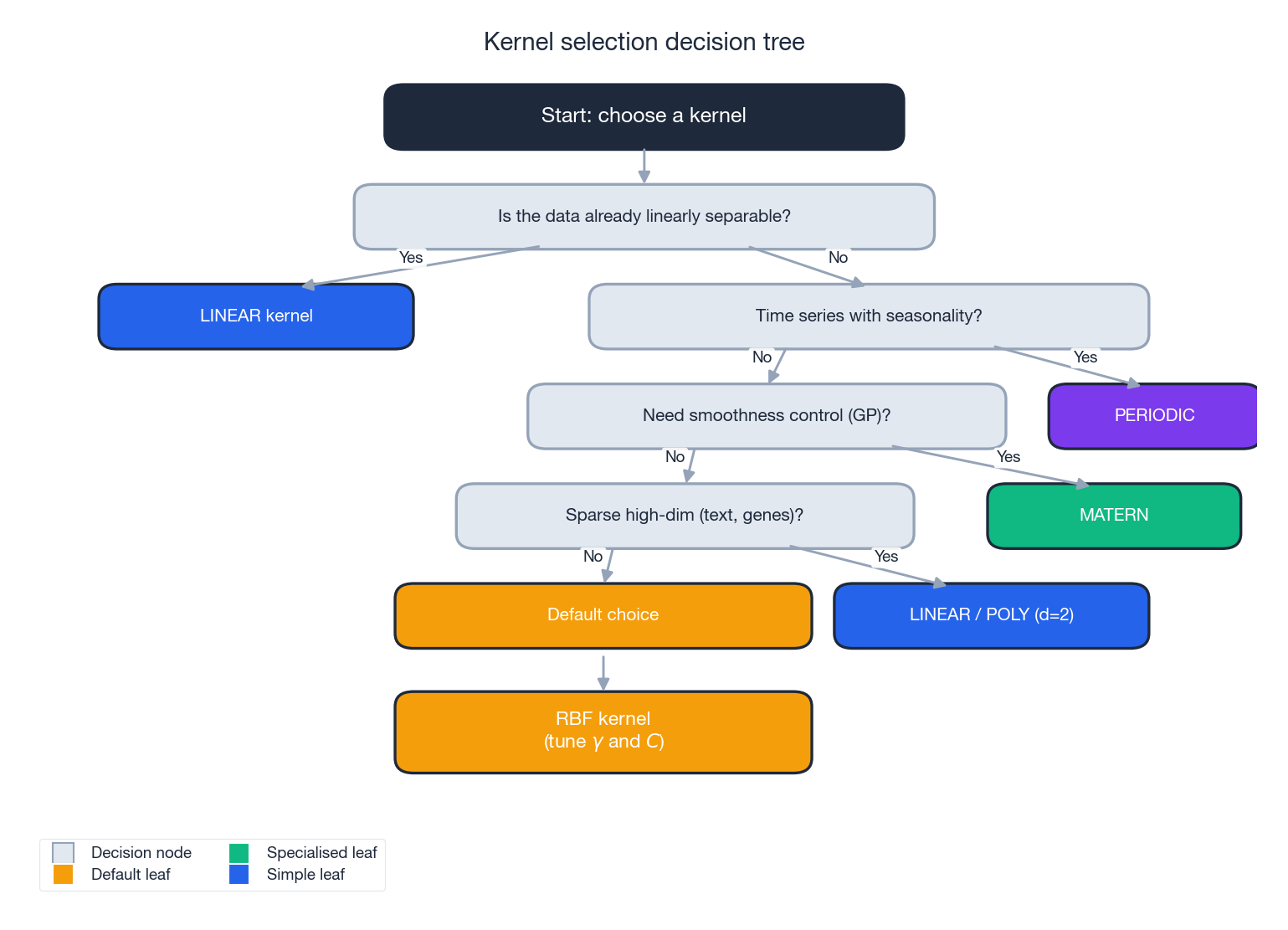
走这条路:
- 数据已经线性可分? 用线性核。又快又可解释,对稀疏高维数据通常很难被超越。
- 季节性强的时间序列? 用周期核(通常和某个光滑核加在一起)。
- 需要细粒度地控制函数光滑度(典型场景是 GP)? 用 Matern,$\nu$ 在 $\{1/2, 3/2, 5/2\}$ 里挑。
- 稀疏、高维、有已知交互(文本、基因组)? 先试线性,不行再上 $d = 2$ 的多项式。
- 以上都不是。 默认 RBF,在对数网格上调 $\gamma$ 和 $C$。
实战建议
1. 一定要标准化特征。 RBF 和 Matern 是基于距离的;以"百万"为单位的特征会碾压以"小数"为单位的特征。每次都把 StandardScaler(重尾分布换 RobustScaler)放在核模型前面。
2. 在对数尺度上搜超参。 $\gamma$、$C$、$\sigma$ 这类超参数是乘性作用的。线性网格会把预算大半浪费在某一段窄区间里;对数网格用同样的点数能覆盖好几个数量级。
3. 用 Pipeline 搭模型。 Pipeline([scaler, kernel_model]) 能保证 scaler 在每折训练数据上单独 fit,而不是在整份数据上 fit——否则你就把测试集的统计量泄露进了训练。
4. 核可以组合。 有效核的和与积仍然是有效核。Matern * Periodic + WhiteNoise 是"光滑 + 周期 + 噪声"的标准配方。
5. 自定义核要做 sanity check。
| |
核方法 vs 深度学习
| 维度 | 核方法 | 深度学习 |
|---|---|---|
| 数据量 | 小数据出色($n < 10^4$) | 需要大数据($n \gtrsim 10^5$) |
| 可解释性 | 高(RKHS、支持向量) | 低(基本是黑盒) |
| 超参数 | 少(核参数 + 正则) | 多(架构、优化器、调度等) |
| 可扩展性 | 差($O(n^2)$ 内存、$O(n^3)$ 计算) | 好(小批量、GPU) |
| 理论 | 强(RKHS、Mercer、表示定理) | 多半经验性 |
| 不确定性 | GP 原生提供 | 需要外挂(集成、MC dropout、BNN) |
用核方法的情形:数据中小规模、需要校准良好的不确定性(GP)、看重可解释性(SVM 的支持向量)。
用深度学习的情形:数据规模大、需要从原始信号(图像、音频、文本)里学表示、要拼可扩展性。
这两条路并不互斥。**深度核学习(Deep Kernel Learning)**就是用神经网络做特征提取、上面套 GP——在合适的场景里能拿到两边的好处。
总结:核方法的五步流程
- 选核家族。 线性可分 → 线性核;否则默认 RBF;GP 用 Matern;季节性时间序列用周期核。
- 标准化特征。 RBF / Matern / 周期核必须做。
- 对数网格调参。 交叉验证 $\gamma$、$C$、多项式阶数、长度尺度。
- 看诊断信号。 画 Gram 矩阵;接近对角 → 过拟合(减小 $\gamma$);接近均匀 → 欠拟合(增大 $\gamma$)。
- 不够用就扩规模。 $n \to 10^6$ 用线性核;非线性用 Nystrom / 随机特征;概率模型用稀疏 GP;结构主导时切深度学习。
关键超参数一览。
- RBF. $\gamma$(带宽)、$C$(正则化)。
- 多项式. $d$(阶数,最好 $\leq 3$)、$\gamma$、$c$。
- Matern. $\nu$(平滑度,没特别理由就钉在 $5/2$)、$\ell$(长度尺度)。
常见坑。
- 忘了标准化特征(RBF 会"沉默地"把精度跌到比随机猜还差)。
- 用 sigmoid 核(很多时候不正定,换别的)。
- $\gamma$、$C$ 在线性网格上搜(90% 的搜索预算被浪费)。
- 在 CV 之前把 scaler fit 在整份数据上(测试信息泄露进训练)。
延伸阅读
- Hofmann, Scholkopf, Smola. Kernel Methods in Machine Learning (Annals of Statistics, 2008)。经典综述。
- Rasmussen and Williams. Gaussian Processes for Machine Learning (MIT Press, 2006)。免费 PDF;GP 圣经。
- Scholkopf and Smola. Learning with Kernels (MIT Press, 2002)。教科书级别的系统讲解。
- Rahimi and Recht. Random Features for Large-Scale Kernel Machines (NeurIPS, 2007)。随机傅里叶特征原始论文。
- Wilson and Adams. Gaussian Process Kernels for Pattern Discovery and Extrapolation (ICML, 2013)。时间序列上的谱混合核。