近端算子:从 Moreau 包络到 ISTA/FISTA 与 ADMM
系统讲解近端算子的理论与应用:凸分析基础、Moreau 包络、常见近端闭式解,以及 ISTA/FISTA、ADMM 等算法中的实际用法。
当目标函数带有不可导项(稀疏正则、TV 正则、指示函数)或约束难以直接处理时,“直接做梯度下降"常常会卡住:要么没有梯度,要么每一步都难以保证可行性。近端算子(proximal operator) 给出了一个工程化又漂亮的解决方式——把更新理解成"先按光滑部分走一步,再用一个带二次惩罚的最小化把解拉回到合理的结构上”。
本文从凸分析与子梯度的最小必要背景出发,逐步引出 Moreau 包络与近端映射的性质、常见近端的闭式解,并把它们放回到 ISTA / FISTA / ADMM、SVM 与稀疏优化这些具体算法里:为什么能工作、什么时候收敛得更快、实现时最容易错在哪里。
你将学到
- 凸分析最小必要工具:凸集、凸函数、子梯度
- 近端算子的定义、几何直觉、四条核心性质
- 三个��常用的闭式近端:软阈值、投影、二次缩放
- Moreau 包络:把非光滑函数"光滑化",并和近端的梯度关系
- ISTA:proximal gradient 的最小可用算法
- FISTA:动量加速到 $O(1/k^2)$
- LASSO 求解:从理论到一段可读的 Python 代码
- ADMM 简介与子梯度法的对比
- 常见踩坑:步长、Lipschitz 常数估计、收敛诊断
前置知识
- 多元微积分(梯度、链式法则)
- 线性代数基础(范数、内积、特征值)
- 一点点凸优化常识即可(梯度下降、强凸性)
凸分析基础
在进入近端算子之前,我们需要把"凸集 / 凸函数 / 子梯度"这三件套清理干净。它们是后续所有性质(非扩张、闭式解、收敛性)成立的前提。
凸集与凸函数
凸集:$C \subseteq \mathbb{R}^n$ 是凸集,当且仅当对任意 $x, y \in C$ 与 $\theta \in [0, 1]$,
$$\theta x + (1 - \theta) y \in C.$$直观地,任意两点之间的线段完全包含在 $C$ 内。
凸函数:$f : \mathbb{R}^n \to \mathbb{R} \cup \{+\infty\}$ 是凸的,当且仅当其有效域 $\mathrm{dom}\,f$ 是凸集,并且对任意 $x, y \in \mathrm{dom}\,f$ 与 $\theta \in [0, 1]$,
$$f\!\left(\theta x + (1 - \theta) y\right) \le \theta f(x) + (1 - \theta) f(y).$$几何上,函数图像上的弦不低于函数本身(“凹向上”)。
两条要记住的性质���
- 局部最小即全局最小:凸函数的任一局部最小点都是全局最小点。
- 支持超平面:凸集的任一边界点都存在支持超平面;凸函数的图像在任一点都存在切下方支撑(这就是子梯度的来源)。
子梯度与次梯度
可微凸函数在每点都有唯一梯度 $\nabla f(x)$。但 $|x|$、$\max(0, 1 - t)$(hinge)这种带"折点"的凸函数在折点处没有梯度——我们需要 子梯度。
定义:向量 $g \in \mathbb{R}^n$ 是凸函数 $f$ 在 $x$ 处的一个子梯度,当且仅当对任意 $y$,
$$f(y) \ge f(x) + \langle g,\, y - x \rangle.$$也就是说,$g$ 给出了一条过 $(x, f(x))$ 的下方支撑超平面。所有这样的 $g$ 构成的��合记作 $\partial f(x)$,称为 $f$ 在 $x$ 处的 次梯度(subdifferential)。
例子(绝对值函数):取 $f(t) = |t|$。
$$ \partial |t| = \begin{cases} \{+1\}, & t > 0,\\ \{-1\}, & t < 0,\\ [-1, +1], & t = 0. \end{cases} $$在 0 处子梯度集合是一个 区间,这正是后面"软阈值死区"的来源。
性质:
- 若 $f$ 在 $x$ 处可微,则 $\partial f(x) = \{\nabla f(x)\}$。
- $\partial f(x)$ 永远是凸集(且若 $f$ 闭凸,则在内部点上非空)。
- 最优性条件:$x^\star$ 是 $f$ 的最小点 $\Longleftrightarrow$ $0 \in \partial f(x^\star)$。这条比"梯度为零"更通用,是后面所有推导的核心。
近端算子
定义与几何直觉
对闭真凸函数 $f : \mathbb{R}^n \to \mathbb{R} \cup \{+\infty\}$ 与 $\lambda > 0$,近端算子(proximal operator) 定义为
$$ \mathrm{prox}_{\lambda f}(v) \;=\; \arg\min_{x \in \mathbb{R}^n}\left\{\, f(x) + \frac{1}{2\lambda} \|x - v\|_2^2 \,\right\}. $$这个 $\arg\min$ 在 $f$ 闭凸时唯一存在(强凸目标 + 闭凸约束)。
直觉:$\mathrm{prox}_{\lambda f}(v)$ 是在"想让 $f$ 小"和"想离 $v$ 近"之间做权衡。$\lambda$ 是惩罚强度的倒数:
- $\lambda \to 0$:不让你离开 $v$,$\mathrm{prox}_{\lambda f}(v) \to v$。
- $\lambda \to \infty$:自由最小化 $f$,$\mathrm{prox}_{\lambda f}(v) \to \arg\min f$。
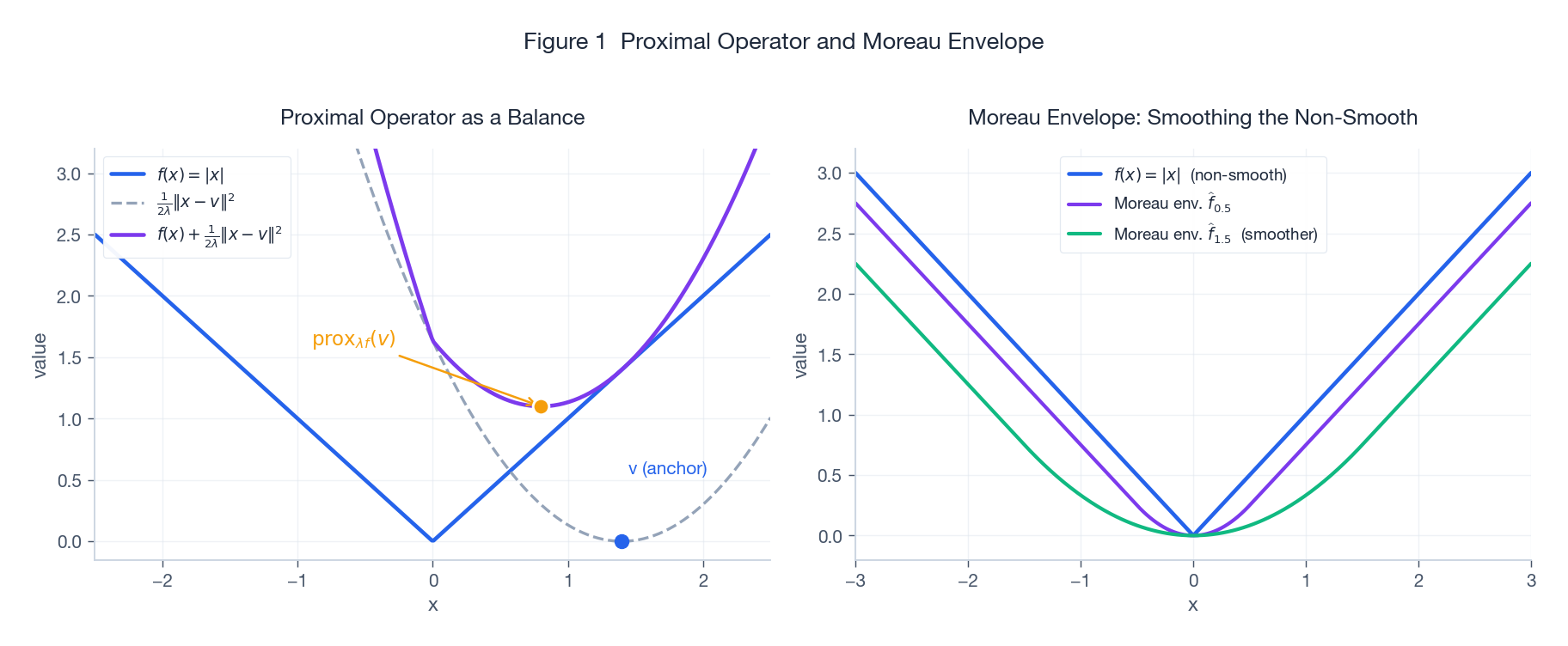
左图把这个权衡画出来了:蓝色的 $f$、灰色的二次惩罚、紫色的两者之和;橙点就是 $\mathrm{prox}_{\lambda f}(v)$。右图先按下不表,等讲到 Moreau 包络再回来看。
四条核心性质
下面四条是后续所有算法分析的"砖头"。
(1) 唯一性与最优性条件。$\mathrm{prox}_{\lambda f}(v)$ 唯一存在,并且 $x^\star = \mathrm{prox}_{\lambda f}(v)$ 等价于
$$\frac{1}{\lambda}(v - x^\star) \in \partial f(x^\star) \;\;\Longleftrightarrow\;\; v \in x^\star + \lambda\, \partial f(x^\star).$$(2) 不动点刻画。$x^\star$ 是 $f$ 的最小点 $\Longleftrightarrow$ $x^\star = \mathrm{prox}_{\lambda f}(x^\star)$。
(3) 非扩张(firmly non-expansive)。对任意 $u, v$,
$$\|\mathrm{prox}_{\lambda f}(u) - \mathrm{prox}_{\lambda f}(v)\|_2 \le \|u - v\|_2.$$更强的"firm"版本说 $\mathrm{prox}$ 是 $\tfrac{1}{2}$-平均映射——这是后面 ISTA / 不动点迭代收敛的主要工具。
(4) 可分离(separability)。若 $f(x) = \sum_i f_i(x_i)$,则
$$\bigl[\mathrm{prox}_{\lambda f}(v)\bigr]_i = \mathrm{prox}_{\lambda f_i}(v_i).$$这意味着 $\ell_1$、box 约束这些"逐分量函数"的近端可以完全并行计算——这是 LASSO 能在百万维里跑得动的根本原因。
三个最常用的闭式近端
$\ell_1$ 范数:软阈值算子
取 $f(x) = \|x\|_1 = \sum_i |x_i|$。由可分离性,问题降到一维:
$$\min_{x_i} |x_i| + \frac{1}{2\lambda}(x_i - v_i)^2.$$把 $|x_i|$ 写成 $x_i \ge 0$ 与 $x_i \le 0$ 两支求子梯度并令 $0 \in \partial(\cdot)$,得到 软阈值算子(soft-threshold):
$$ \bigl[\mathrm{prox}_{\lambda \|\cdot\|_1}(v)\bigr]_i \;=\; \mathrm{soft}_\lambda(v_i) \;=\; \mathrm{sign}(v_i) \cdot \max\!\bigl(|v_i| - \lambda,\, 0\bigr). $$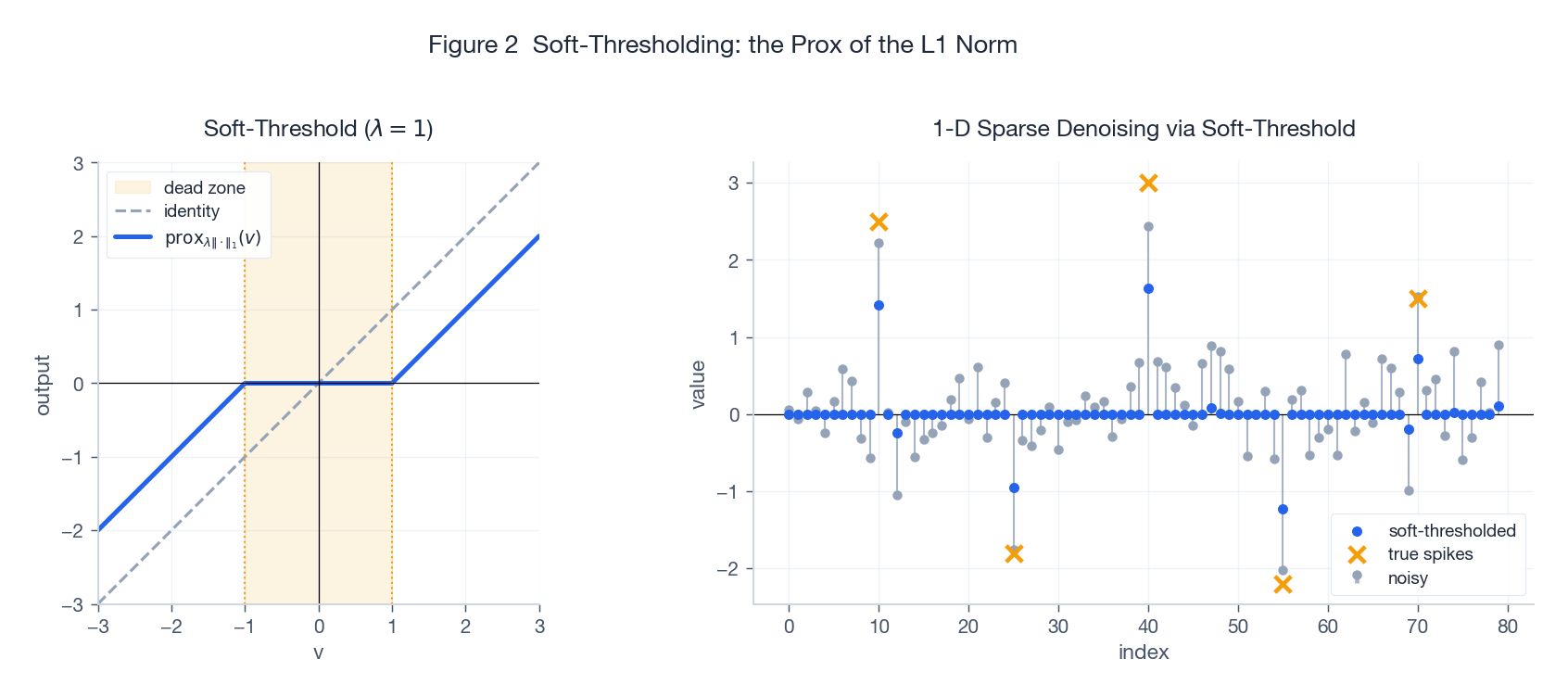
- 左图:$|v| \le \lambda$ 的"死区"内输出全部归零,外面则把 $v$ 朝零方向收缩 $\lambda$ 个单位(不是简单截断!)。
- 右图:把含噪信号经一次软阈值,小幅噪声被压成精确零,大尖峰被保留并轻度收缩——这就是 LASSO 把不重要的特征系数推到精确零的机制。
实现要点:软阈值是逐分量、$O(n)$ 的,可向量化。Numpy 一行:np.sign(v) * np.maximum(np.abs(v) - lam, 0.0)。
指示函数:投影算子
凸集 $C$ 的指示函数
$$\iota_C(x) = \begin{cases} 0, & x \in C, \\ +\infty, & x \notin C, \end{cases}$$是凸函数。它的近端就是投影算子:
$$\mathrm{prox}_{\lambda \iota_C}(v) = \arg\min_{x \in C} \tfrac{1}{2}\|x - v\|_2^2 = P_C(v).$$注意结果不依赖 $\lambda$(因为 $\iota_C$ 的取值要么 $0$ 要么 $+\infty$)。这使得"投影梯度法"成为"近端梯度法"的特例——硬约束就是无穷大的惩罚。
常见投影:
- $\ell_2$ 球 $\{x : \|x\|_2 \le r\}$:$P(v) = v \cdot \min(1, r / \|v\|_2)$。
- $\ell_\infty$ 球 $\{x : \|x\|_\infty \le 1\}$:$P(v)_i = \mathrm{clip}(v_i, -1, 1)$。
- 非负象限 $\mathbb{R}^n_{+}$:$P(v) = \max(v, 0)$(即 ReLU)。
- 单纯形 / $\ell_1$ 球:需要排序,$O(n \log n)$ 的算法存在但稍长。
平方范数:线性缩放
取 $f(x) = \tfrac{1}{2}\|x\|_2^2$。一阶条件 $x + \tfrac{1}{\lambda}(x - v) = 0$ 给出闭式解
$$\mathrm{prox}_{\lambda f}(v) = \frac{v}{1 + \lambda}.$$这就是把 $v$ 朝原点做线性收缩,对应于岭回归正则的更新形式。
更一般的二次型 $f(x) = \tfrac{1}{2}x^\top Q x + b^\top x$($Q \succeq 0$)有
$$\mathrm{prox}_{\lambda f}(v) = (I + \lambda Q)^{-1}(v - \lambda b),$$需要解一个线性系统;当 $Q$ 是稀疏 / 结构化矩阵时仍然实用。
没有闭式解时怎么办
不是所有 $f$ 都有闭式近端。常见处理:
- 半光滑牛顿 / Newton-CG 解一阶最优条件。
- 对偶问题求 $\mathrm{prox}$:很多复合函数的近端可以转化为对偶问题(参考 Moreau 分解,下文)。
- 嵌入到 ADMM 内层:用 ADMM 把"难近端"拆成两个"容易近端"。
Moreau 包络:把非光滑变光滑
定义与图像
对闭真凸函数 $f$ 与 $\lambda > 0$,Moreau 包络 定义为
$$\widehat{f}_\lambda(x) \;=\; \min_{y \in \mathbb{R}^n}\left\{ f(y) + \frac{1}{2\lambda}\|y - x\|_2^2 \right\}.$$注意它和近端的区别:包络取的是最小值(一个标量),近端取的是最小化点(一个向量)。两者在同一个最小化问题里出生,所以关系紧密。
回到 Figure 1 右图:紫色和绿色就是 $f(x) = |x|$ 在 $\lambda = 0.5$ 与 $\lambda = 1.5$ 下的 Moreau 包络(即 Huber 函数),它把 $|x|$ 在原点处的"折角"磨成了光滑的圆弧——并且 保持了原函数的最小值与最小化点。
三条关键性质
(1) 同最小值与最小点。
$$\inf_x f(x) = \inf_x \widehat{f}_\lambda(x), \qquad \arg\min f = \arg\min \widehat{f}_\lambda.$$(2) $\widehat{f}_\lambda$ 是 $\tfrac{1}{\lambda}$-光滑的凸函数。即使 $f$ 处处不可导,$\widehat{f}_\lambda$ 也处处可微,且其梯度是 $\tfrac{1}{\lambda}$-Lipschitz。
(3) 梯度公式(核心):
$$\nabla \widehat{f}_\lambda(x) \;=\; \frac{1}{\lambda}\bigl(x - \mathrm{prox}_{\lambda f}(x)\bigr).$$为什么这条最重要:它把"对包络求梯度下降"转化为"算一次近端"——这正是后面 ISTA 的算法核心。
简短推导:设 $y^\star = \mathrm{prox}_{\lambda f}(x)$,则一阶最优 $0 \in \partial f(y^\star) + \tfrac{1}{\lambda}(y^\star - x)$,即 $\tfrac{1}{\lambda}(x - y^\star) \in \partial f(y^\star)$。代入包络的定义并对 $x$ 求导(包络定理 / Danskin 定理),即得 $\nabla \widehat{f}_\lambda(x) = \tfrac{1}{\lambda}(x - y^\star)$。
Moreau 分解
一条很有用的"对偶恒等式":对任意闭真凸函数 $f$ 与凸共轭 $f^*$,有
$$v = \mathrm{prox}_{\lambda f}(v) + \lambda \cdot \mathrm{prox}_{f^* / \lambda}(v / \lambda).$$实际意义:如果 $f$ 的近端难算但 $f^*$ 的近端容易(或反过来),就用对偶端做计算。比如 nuclear norm 的近端要做 SVD 的软阈值,可以借这条公式与谱范数的投影互换。
Proximal Gradient:ISTA
适用结构
考虑 复合优化 问题:
$$\min_{x \in \mathbb{R}^n} F(x) \;=\; g(x) + h(x),$$其中
- $g$:凸、可微、梯度 $L$-Lipschitz(“光滑部分”),
- $h$:凸、可能不可微,但 $\mathrm{prox}_{\lambda h}$ 容易算(“非光滑部分”)。
LASSO 是最经典的例子:$g(x) = \tfrac{1}{2}\|Ax - y\|_2^2$ 光滑,$h(x) = \mu \|x\|_1$ 用软阈值。
ISTA 迭代
ISTA(Iterative Shrinkage-Thresholding Algorithm) 把"对 $g$ 走一步梯度 + 对 $h$ 做一次近端"组合:
$$ \boxed{\;x_{k+1} \;=\; \mathrm{prox}_{\eta h}\!\bigl(x_k - \eta \nabla g(x_k)\bigr).\;} $$理解角度:把 $g$ 在 $x_k$ 处做二次上界 $\widetilde{g}(x; x_k) = g(x_k) + \langle \nabla g(x_k), x - x_k \rangle + \tfrac{1}{2\eta}\|x - x_k\|_2^2$,然后 $x_{k+1} = \arg\min_x \widetilde{g}(x; x_k) + h(x)$ 恰好就是上面那个近端。这就是 majorization-minimization 视角。
步长:$\eta \le 1 / L$,其中 $L$ 是 $\nabla g$ 的 Lipschitz 常数。对 LASSO,$L = \|A\|_2^2$(最大奇异值平方),用幂法估两三步即可。
收敛速度:对凸 $F$,
$$F(x_k) - F^\star \le \frac{\|x_0 - x^\star\|_2^2}{2\eta k} = O(1 / k).$$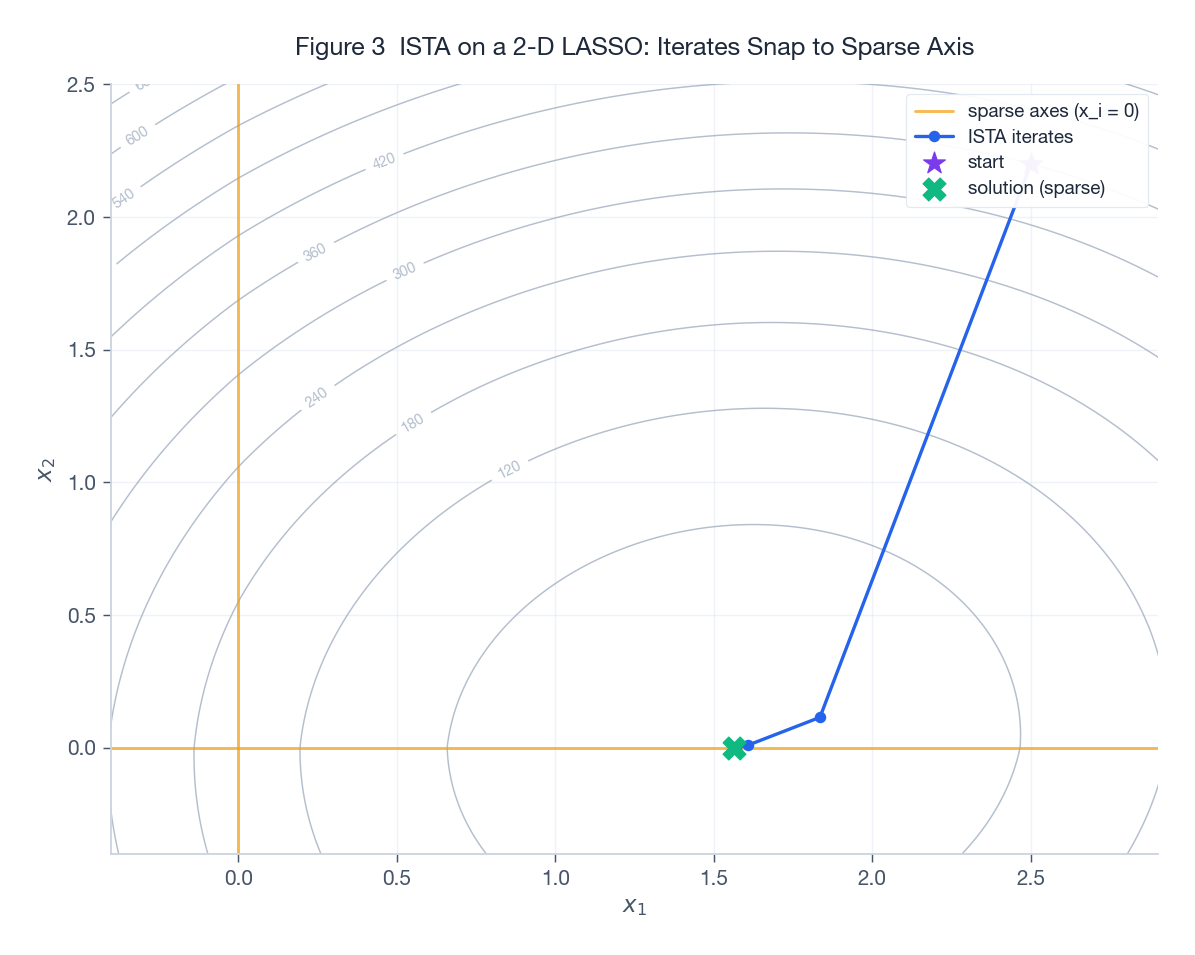
Figure 3 在二维 LASSO 上跑 ISTA:灰色等高线是目标函数,橙线是稀疏轴 ($x_2 = 0$)。从右上角的紫星出发,ISTA 的迭代(蓝色折线)逐步靠近最优解,并在最后精确落到 $x_2 = 0$——这正是软阈值带来的稀疏诱导效果。
加速:FISTA
算法
ISTA 的 $O(1/k)$ 在大规模问题上偏慢。FISTA(Beck & Teboulle, 2009)借鉴 Nesterov 动量,在 ISTA 的基础上做了"在外推点处求梯度"的微小修改:
$$ \begin{aligned} y_k &= x_k + \frac{t_{k-1} - 1}{t_k}\bigl(x_k - x_{k-1}\bigr), \\ x_{k+1} &= \mathrm{prox}_{\eta h}\!\bigl(y_k - \eta \nabla g(y_k)\bigr), \\ t_{k+1} &= \frac{1 + \sqrt{1 + 4 t_k^2}}{2}. \end{aligned} $$初值 $t_0 = 1$,$x_0 = x_{-1}$。
收敛速度:$F(x_k) - F^\star \le \dfrac{2 \|x_0 - x^\star\|_2^2}{\eta (k + 1)^2} = O(1/k^2)$。
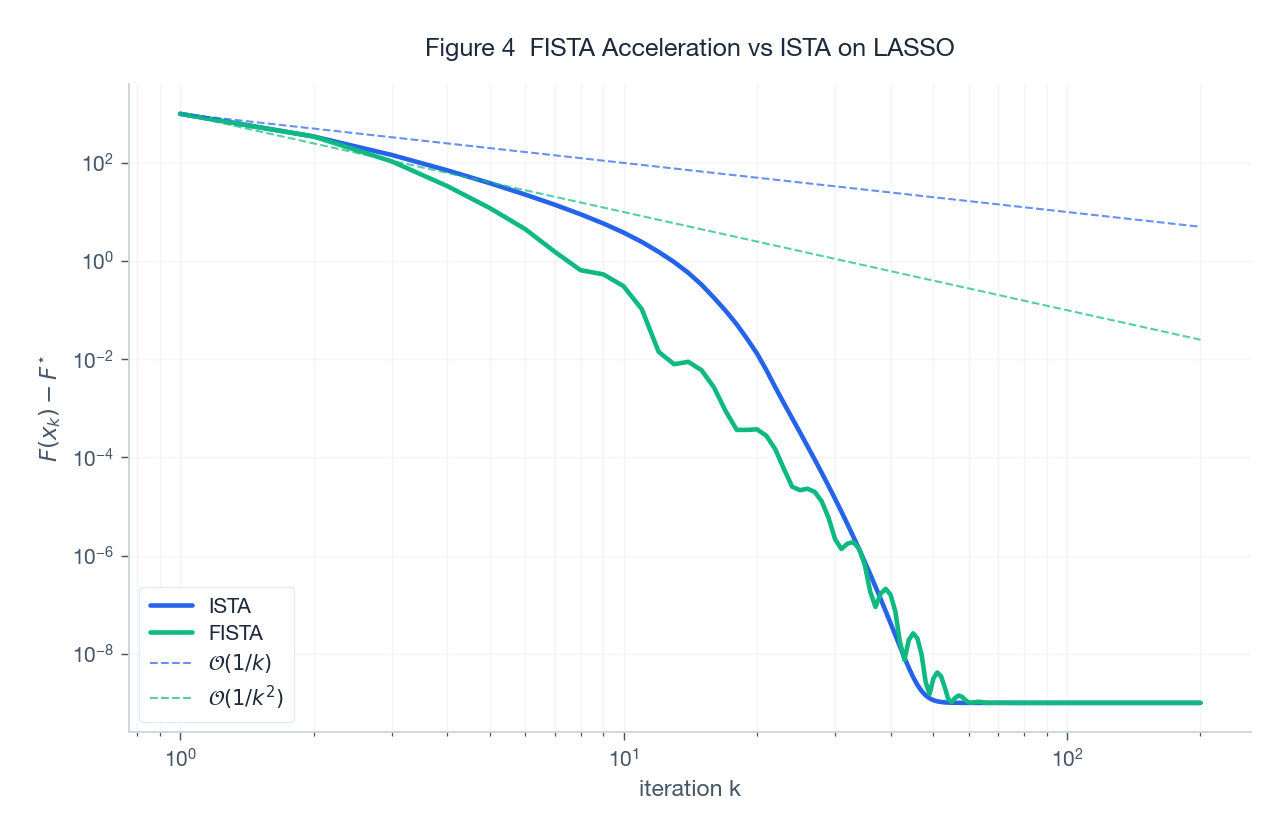
Figure 4 在 60 维 LASSO 上把 ISTA 与 FISTA 的次优间隙画在双对数轴上。两条理论参��虚线($1/k$ 与 $1/k^2$)几乎和实线平行——加速效果是真的,并且在前 50 次迭代里 FISTA 就比 ISTA 快了大约一个数量级。
实现注意
- 重启(restart):FISTA 的 $t_k$ 序列单调增长,遇到目标函数振荡时会"过度外推"。简单的修复是 function restart:若 $F(x_{k+1}) > F(x_k)$,把 $t_k$ 重置为 $1$。在实践中这条小技巧常常带来 2-3 倍的额外加速。
- 强凸时:若 $g$ 还有 $\mu$-强凸性,存在 APGD 等变体能达到线性收敛 $(1 - \sqrt{\mu/L})^k$。
- inexact prox:若 $h$ 的近端只能近似算,FISTA 仍能保持加速率,前提是近似误差以 $1/k^{3/2}$ 速率衰减。
应用:求解 LASSO
问题与解的几何
LASSO:
$$\min_x \;\tfrac{1}{2}\|Ax - y\|_2^2 + \mu \|x\|_1.$$关键现象:随着正则强度 $\mu$ 增大,越来越多的系数被精确推到零。这就是 LASSO 同时做"拟合"和"特征选择"的能力。
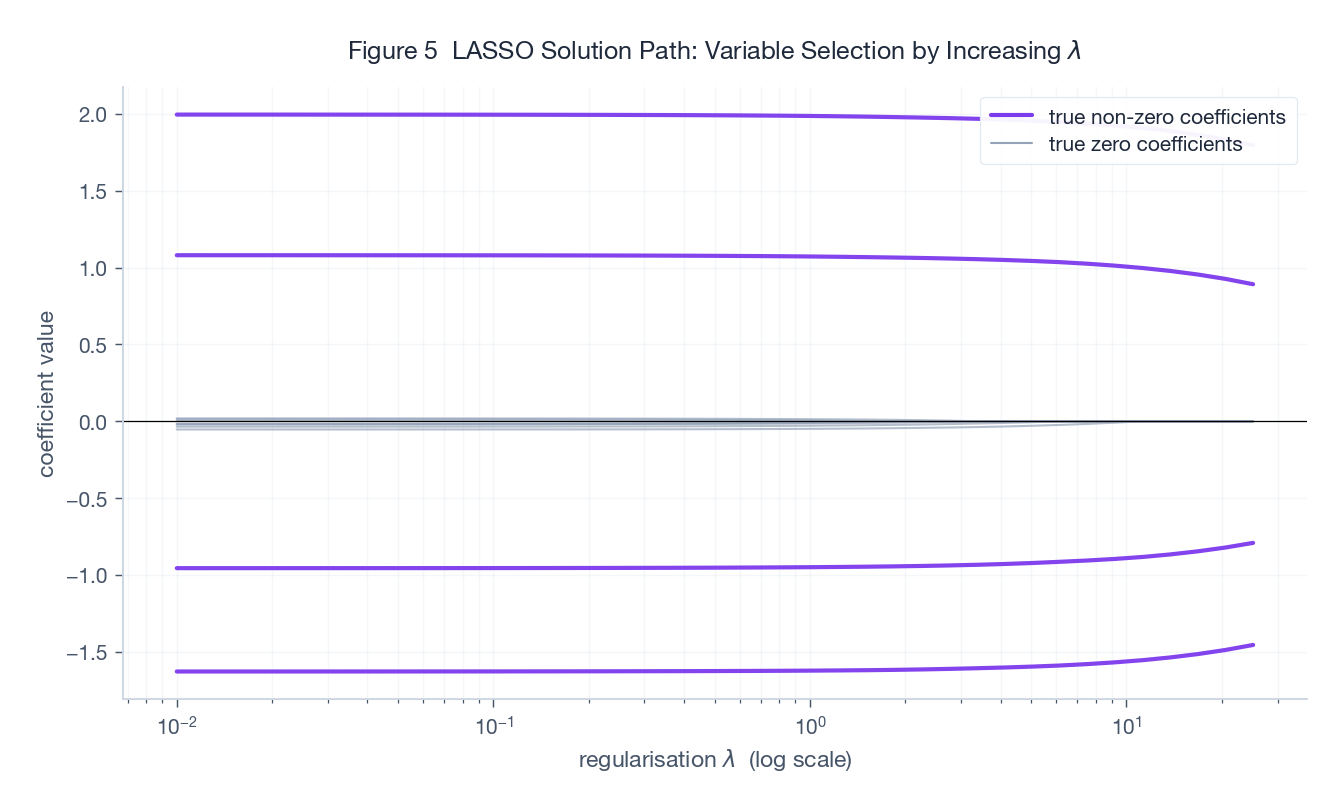
Figure 5 是经典的 LASSO 解路径:横轴是 $\mu$(对数刻度),纵轴是各特征系数。紫色实线是真实非零的 4 个特征,灰色虚线是真实为零的 8 个特征。可以看到:
- 当 $\mu$ 很小时,所有系数都非零(接近最小二乘解)。
- 当 $\mu$ 增大时,灰色(无关)特征最先被压成零;紫色(有关)特征最后才退出。
- 选择合适的 $\mu$(通常用交叉验证),就能得到稀疏且预测好的模型。
一段可读的 ISTA / FISTA 实现
| |
实现要点:
- $L = \|A\|_2^2$ 用幂法估算更便宜(避免做完整 SVD)。
- 收敛诊断用相对位移而非梯度范数(梯度在折点处不存在)。
- 如果做 path(多个 $\mu$ 的解),按 $\mu$ 从大到小用 warm start:上一个 $\mu$ 的解作为下一个的初值,能大幅加速。
子梯度方法 vs Proximal 方法
子梯度法是处理非光滑的"原始"工具:
$$x_{k+1} = x_k - \eta_k g_k, \quad g_k \in \partial F(x_k),$$但收敛率只有 $O(1/\sqrt{k})$,并且需要小步长 $\eta_k = O(1/\sqrt{k})$ 才能保证收敛。
对比表:
| 方法 | 适用结构 | 速率 (凸) | 实现难度 | 备注 |
|---|---|---|---|---|
| 子梯度法 | 任意凸 $F$ | $O(1/\sqrt{k})$ | 低 | 无脑可用,但慢 |
| ISTA | $g$ 光滑 + $h$ 易算 prox | $O(1/k)$ | 低 | LASSO 标配 |
| FISTA | 同 ISTA | $O(1/k^2)$ | 中 | 大规模首选 |
| ADMM | $\min g(x) + h(z)$ s.t. $Ax + Bz = c$ | $O(1/k)$(一般凸) | 中 | 可拆分的复合问题 |
实践建议:能用 proximal 就别用子梯度——只要 $h$ 能拆出来且近端可算,proximal 系列在实际问题上常常能快几个数量级。
ADMM 简要
当问题里有两个非光滑项,或者有线性等式约束时,单纯的 ISTA / FISTA 不够用。ADMM(Alternating Direction Method of Multipliers) 把问题写成
$$\min_{x, z}\; g(x) + h(z) \quad \text{s.t.}\quad Ax + Bz = c,$$并交替更新:
$$ \begin{aligned} x_{k+1} &= \arg\min_x\; g(x) + \tfrac{\rho}{2}\|Ax + Bz_k - c + u_k\|_2^2, \\ z_{k+1} &= \arg\min_z\; h(z) + \tfrac{\rho}{2}\|Ax_{k+1} + Bz - c + u_k\|_2^2, \\ u_{k+1} &= u_k + Ax_{k+1} + Bz_{k+1} - c. \end{aligned} $$这两个子问题里通常各只涉及 一个 非光滑项,于是各自能用 prox 算掉。
LASSO 的 ADMM 形式:把约束改写为 $x = z$,则 $x$-更新是岭回归的解析解,$z$-更新就是软阈值——干净利落。
ADMM 的优势:
- 适合两个非光滑项叠加(如 $\ell_1 + $ 全变分)。
- 天然适合分布式(共识 ADMM)。
- 对一般凸问题也是 $O(1/k)$,但常数比 ISTA 小。
ADMM 的代价:需要选 $\rho$,需要求解一个线性子问题(对 $x$)。
收敛性:实战层面
ISTA / FISTA 要诊断什么
- 目标函数是否单调下降(ISTA)/ 是否在重启后严格下降(FISTA)。
- $\|x_{k+1} - x_k\|$ 是否衰减到指定容差——这是非光滑情形下最常用的诊断。
- 稀疏模式是否稳定:从某次迭代起,活跃集(非零位置)不再变化,说明已经接近最优。
常见踩坑
- 步长设错:$\eta > 1/L$ 会发散。如果 $L$ 估不准,用 回溯线搜索:每次把 $\eta$ 翻倍尝试,直到不满足充分下降条件就回退。
- 没有 warm start 跑 path:每个 $\mu$ 都从零起步会浪费大量迭代。
- 把 $\lambda$ 和 $\eta$ 弄混:注意 $\mathrm{prox}_{\eta \cdot \mu \|\cdot\|_1}$ 的阈值是 $\eta \mu$,不是 $\mu$ 也不是 $\eta$。
- 直接对 hinge / $\ell_1$ 用梯度下降:会卡在折点附近抖动。要么用 prox,要么用次梯度(慢但能动)。
习题
习题 1:常见近端的闭式解
计算下列函数的近端 $\mathrm{prox}_{\lambda f}$:
(a) $f(x) = \|x\|_1$。
解:由可分离性 + 一维子梯度分析,
$$\bigl[\mathrm{prox}_{\lambda f}(v)\bigr]_i = \mathrm{sign}(v_i)\max(|v_i| - \lambda, 0).$$(b) $f(x) = \iota_{B_\infty}(x)$,其中 $B_\infty = \{x : \|x\|_\infty \le 1\}$。
解:投影到 $\ell_\infty$ 球,逐分量截断:
$$\bigl[\mathrm{prox}_{\lambda f}(v)\bigr]_i = \min\bigl(\max(v_i, -1),\, 1\bigr).$$注意结果不依赖 $\lambda$。
(c) $f(x) = \tfrac{\beta}{3}\|x\|_3^3$($\beta > 0$)。
解:可分离,对每个分量解 $\beta x_i |x_i| + \tfrac{1}{\lambda}(x_i - v_i) = 0$。设 $v_i \ge 0$,则 $x_i \ge 0$,化简得 $\lambda \beta x_i^2 + x_i - v_i = 0$,
$$\bigl[\mathrm{prox}_{\lambda f}(v)\bigr]_i = \mathrm{sign}(v_i) \cdot \frac{-1 + \sqrt{1 + 4\lambda\beta |v_i|}}{2\lambda\beta}.$$这是少有的 $\ell_p$($p > 2$)有闭式近端的例子。
习题 2:Moreau 包络的可微性
证明:闭真凸函数 $f$ 的 Moreau 包络 $\widehat{f}_\lambda$ 处处可微,并且
$$\nabla \widehat{f}_\lambda(x) = \frac{1}{\lambda}\bigl(x - \mathrm{prox}_{\lambda f}(x)\bigr).$$思路:
- 因为 $\mathrm{prox}_{\lambda f}(x)$ 由唯一最小化点定义,记 $y(x) = \mathrm{prox}_{\lambda f}(x)$。由近端的非扩张性,$y(x)$ 关于 $x$ 是 1-Lipschitz 连续的。
- 一阶最优条件给出 $\tfrac{1}{\lambda}(x - y(x)) \in \partial f(y(x))$。
- 用包络定理(Danskin / Berge)对 $\widehat{f}_\lambda(x) = f(y(x)) + \tfrac{1}{2\lambda}\|y(x) - x\|^2$ 求 $x$ 的微分,内部对 $y$ 的偏导项因一阶最优条件而消失,剩下 $\nabla_x \tfrac{1}{2\lambda}\|y - x\|^2 \big|_{y = y(x)} = \tfrac{1}{\lambda}(x - y(x))$。
由于 $y(x)$ 1-Lipschitz,$\nabla \widehat{f}_\lambda$ 也是 $\tfrac{1}{\lambda}$-Lipschitz——这是 Moreau 包络"自动 1-光滑"的来源。
习题 3:SVM 的近端为什么不"好用"
考虑线性 SVM 的目标 $f(w) = \sum_i \max(0, 1 - y_i x_i^\top w) + \tfrac{\lambda}{2}\|w\|_2^2$。
(a) 给出 $f$ 在 $w$ 处的一个子梯度。
解:对 hinge $\ell_i(w) = \max(0, 1 - y_i x_i^\top w)$,
$$ \partial \ell_i(w) = \begin{cases} \{0\}, & y_i x_i^\top w > 1, \\ \{- y_i x_i\}, & y_i x_i^\top w < 1, \\ [-y_i x_i, 0], & y_i x_i^\top w = 1. \end{cases} $$总子梯度 $\partial f(w) \ni \sum_i g_i + \lambda w$,其中 $g_i \in \partial \ell_i(w)$。
(b) 论证 $\mathrm{prox}_{\alpha f}(0)$ 的求解难度与原 SVM 问题相当。
解:按定义,
$$\mathrm{prox}_{\alpha f}(0) = \arg\min_w \;\sum_i \max(0, 1 - y_i x_i^\top w) + \tfrac{1}{2}\!\left(\lambda + \tfrac{1}{\alpha}\right)\|w\|_2^2.$$这本身就是一个 SVM 问题,只是正则系数从 $\lambda$ 变成了 $\lambda + 1/\alpha$。结论:对整个 SVM 目标做近端没有意义——这告诉我们近端方法只在能"拆分"出易处理的非光滑项时才有优势。SVM 的实战做法是把 hinge 放在 $g$ 还是 $h$ 里要看具体算法(dual coordinate ascent / Pegasos / SDCA 各有取舍)。
习题 4:投影梯度是 ISTA 的特例
证明:约束优化 $\min_{x \in C} g(x)$($g$ 光滑,$C$ 闭凸)等价于复合优化 $\min_x g(x) + \iota_C(x)$,并写出对应的 ISTA 迭代。
解:把 $h = \iota_C$,$\mathrm{prox}_{\eta h}(v) = P_C(v)$。代入 ISTA:
$$x_{k+1} = P_C\!\bigl(x_k - \eta \nabla g(x_k)\bigr).$$这正是 投影梯度法——它只是 ISTA 在 $h = \iota_C$ 时的特殊形式。同理,加上动量就得到了"加速投影梯度"。
总结
近端算子的价值在于一个非常具体的目标:把"不可导 / 带约束"这件事从主优化里隔离出去,换成一次小型子问题。在这个视角下:
- $\ell_1$ 的勒贝格不可微 → 软阈值;
- 凸约束 → 投影;
- Moreau 包络 → 把整个非光滑函数当成可微对象。
工程上要记住的最少一组事:
- ISTA:$x_{k+1} = \mathrm{prox}_{\eta h}(x_k - \eta \nabla g(x_k))$,$\eta \le 1/L$,$O(1/k)$。
- FISTA:在外推点处做 ISTA 步,再用 $t_k$ 序列更新动量;$O(1/k^2)$,常做 function restart。
- LASSO:直接套 FISTA + 软阈值 + warm start over $\mu$,是工业界 $\ell_1$ 求解的默认方案。
- ADMM:当出现两个非光滑项 / 等式约束时,按变量拆分、交替更新。
把这些工具放在手边,下次再看到目标函数里冒出 $\|\cdot\|_1$、$\iota_C$、TV、nuclear norm 时就不会发慌——它们都只是"等待一次近端"。
进一步阅读
- N. Parikh, S. Boyd. Proximal Algorithms. Foundations and Trends in Optimization, 2014.(最权威的参考综述)
- A. Beck, M. Teboulle. A Fast Iterative Shrinkage-Thresholding Algorithm for Linear Inverse Problems. SIAM J. Imaging Sciences, 2009.(FISTA 原文)
- S. Boyd 等. Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers. FnTML, 2011.(ADMM 综述)
- L. Condat 等. Proximal Splitting Algorithms for Convex Optimization: A Tour of Recent Advances. SIAM Review, 2023.(最新综述,含 PDHG / Condat-Vu)