变分自编码器 (VAE):从直觉到实现与调试
从零用 PyTorch 构建 VAE。涵盖 ELBO 目标函数、重参数化技巧、后验坍塌修复、beta-VAE,以及完整的训练流水线。
普通自编码器仅能压缩与重建,而变分自编码器(VAE)则具备生成能力——它学习到一个平滑且结构化的潜在空间,可以从中采样生成全新数据。将编码器从“输出一个向量”改为“输出一个分布”,这一步骤使模型从一个花哨的压缩器升级为带可优化似然下界的生成模型。
本文走完整条路径:先讲清楚自编码器为什么不能生成,再从 ELBO 推导出损失函数,接着拆解为什么必须用重参数化技巧让梯度走得通,然后给出可以直接运行的 PyTorch 实现,最后逐一分析每种你一定会遇到的失败模式并给出修复手段。
你将学到什么#
- 自编码器的潜在空间为什么不能采样, VAE 改了哪一步
- ELBO 目标函数:重建项与 KL 项是怎么从一个似然下界中自然落出来的
- 重参数化技巧:为什么直接采样会切断梯度,
mu + sigma * eps又是怎么救场的 - 一份完整的 PyTorch 实现:编码器、解码器、损失、训练循环、采样、插值
- 你迟早会遇到的失败模式:后验坍塌、采样模糊、 NaN 梯度——含诊断与修复
- 常用变体: beta-VAE、条件 VAE (CVAE)、层次化 VAE
- 什么时候用 VAE,什么时候改用 GAN 或扩散模型
前置知识#
- PyTorch 基础(
nn.Module、前向/反向传播、优化器) - 概率基础(均值、方差、高斯分布)
- 完整训练过神经网络的经验
为什么需要 VAE:自编码器与生成模型#

自编码器基线#
$$\mathcal{L}_{\text{AE}}(x) = \|x - g_\theta(f_\phi(x))\|^2.$$用作压缩或去噪没问题,但它所学习的潜在空间是确定性且缺乏结构的,具体表现为:
- 没法采样: 解码器只见过编码器输出的那些点。在空间里随便撒一个 $z$ ,大概率落进解码器从没拜访过的“洞”里,吐出来一坨垃圾。
- 插值很脆弱: 两张视觉相近的图可能映射到很远的位置;两张毫无关系的图反而挨在一起。在潜在空间中沿直线插值,中间结果往往缺乏语义连贯性。
- 没有概率解释: 没有先验、没有似然,更没法谈“这个生成样本到底有多可能”。
VAE 的改动:把潜在变量概率化#
$$q_\phi(z \mid x) = \mathcal{N}\!\left(\mu_\phi(x),\, \sigma^2_\phi(x)\, I\right).$$解码器定义似然 $p_\theta(x \mid z)$ ,再加上一个固定的先验 $p(z) = \mathcal{N}(0, I)$ 。
仅此改动,带来了三项关键能力提升:
- 能采样了: 从 $p(z)$ 抽一个 $z$ ,喂给解码器,就得到一张全新的 $\hat{x}$ 。
- 插值变平滑: 相似输入对应的编码分布彼此重叠,因此在潜在空间中沿直线插值,即可获得语义连贯的渐变效果。
- 结构被强制约束: 损失中的 KL 项会主动把聚合后的后验拉向先验,让整个空间被均匀填满。
ELBO 目标函数:损失从哪里来#
推导下界#
$$\log p_\theta(x) \;\geq\; \mathbb{E}_{q_\phi(z\mid x)}\!\left[\log p_\theta(x \mid z)\right] - D_{\mathrm{KL}}\!\left(q_\phi(z\mid x)\,\|\,p(z)\right).$$右边就是著名的证据下界(ELBO)。最大化它,等价于同时做两件事:
- 重建项 $\mathbb{E}_{q_\phi}[\log p_\theta(x \mid z)]$ :解码器要能从编码器抽出的 $z$ 里把 $x$ 还原回来。
- KL 项 $D_{\mathrm{KL}}(q_\phi(z\mid x)\,\|\,p(z))$ :编码器不能想跑哪儿跑哪儿,必须紧贴着先验。
为什么 KL 项是关键的承重墙#
去掉 KL 正则,会出现两个极端:
- 尖峰加空隙: 编码器把每个 $x$ 映到一个孤立的尖刺上,方差小得可怜。整个空间就是真空里的一串针——重建好看,生成无用。
- 解码器无视 $z$ : 解码器太强时会出现反方向的崩坏(也就是后面要讲的“后验坍塌”)。
KL 项强制不同输入的 $q_\phi(z\mid x)$ 重叠并覆盖先验。这种重叠正是平滑插值的来源,也正是先验能当作采样器使用的前提。
重参数化技巧#
问题:梯度穿不过随机采样#
要估算重建项,得先从 $q_\phi(z \mid x)$ 抽样 $z$ 再跑解码器。问题是采样是个随机节点,反向传播没法穿过“抽一个随机数”这一步——直接采样的话,编码器参数 $\phi$ 的梯度根本无定义。
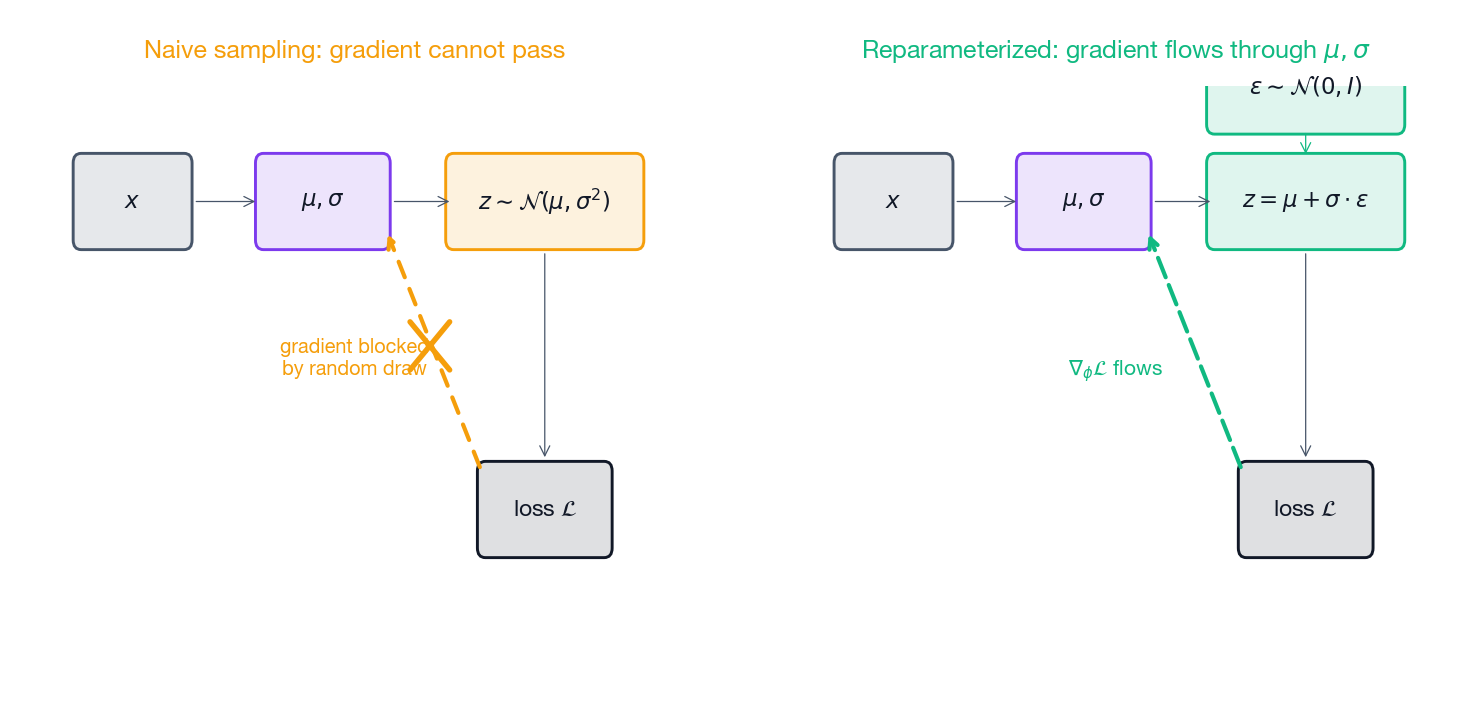
解决:把随机性挪到参数路径之外#
$$z = \mu_\phi(x) + \sigma_\phi(x) \odot \epsilon, \qquad \epsilon \sim \mathcal{N}(0, I).$$这下 $\epsilon$ 与参数无关,从 $\phi$ 到 $z$ 是一条全程可微的通路,梯度可以干干净净地顺着 $\mu$ 和 $\sigma$ 走。
| |
为什么预测 logvar 而不是 sigma? 两个理由,都是数值安全相关:
logvar不受约束,任意实数都合法;直接预测sigma必须额外保证 $\sigma > 0$ (比如套个softplus),又多了一个出错点。- KL 闭式解里本来就要用 $\log \sigma^2$
。直接预测它,可以避免
log(exp(...))来回折腾导致下溢。
完整的 PyTorch 实现#
下面这份代码是经典的“MNIST VAE”:全连接的编解码器、20 维潜空间和伯努利解码器。故意写得很短,方便阅读。
网络结构#
| |
损失函数#
| |
分别返回两项,多花一行代码也值得:分别监控这两项是排查问题最有用的工具。
训练循环#
| |
这循环中有三件事在实战中不要省:梯度裁剪、KL 退火和分别打印两项损失。读完下一节你就明白原因。
你迟早会撞上的失败模式#
下面这四种坑几乎人人都会遇到。每一节都会给出症状、根因和修复方法。
坑 1:后验坍塌#

症状: KL 项在前几轮直接掉到接近零,再也起不来;无论输入是什么,重建图都像训练集的“平均脸”;潜在空间随便走,输出毫无变化。
根因: 解码器太强,光靠 $\mu$ 就能重建;或者训练初期 KL 的压力盖过了重建信号。编码器发现只要把每个输入都映到 $\mu \approx 0,\ \sigma \approx 1$ ,就能用最便宜的方式满足 KL 项——也就是把 $x$ 直接忽略了。
有效的修复手段,按“够用程度”排序:
- KL 退火: 让 $\beta$ 从 0 出发,在前 10–20 轮里线性升到 1 (上面的训练循环就是这么做的)。给重建一段时间扎根,再让 KL 上桌。
- Free bits。 对那些 KL 已经足够小的维度停止施压,以免优化器将它们直接打死。
1 2kl_per_dim = -0.5 * (1 + logvar - mu.pow(2) - logvar.exp()) kl_loss = torch.sum(torch.clamp(kl_per_dim, min=free_bits)) - 削弱解码器: 减小隐藏维度、增加 dropout;如果是自回归解码器,前几轮先去掉自回归捷径。
坑 2:采样质量差#
症状: 训练数据的重建看起来不错,但从 $z \sim \mathcal{N}(0, I)$ 采样出来的图就乱七八糟。
根因: 聚合后验 $\frac{1}{N}\sum_i q_\phi(z\mid x_i)$ 没有真正贴合先验 $p(z)$ ,先验里有大片解码器从没训练过的“洞”。
修复: 加大 $\beta$ (1.5–4 比较常见);扩大潜在维度($20 \to 64$ );训得更久;换更强的解码器(图像任务用卷积)。如果到这一步样本质量还不够“以假乱真”,那基本就是在告诉你:换 GAN 或扩散模型。
坑 3:重建模糊#
症状: 重建图像可以辨认,但平滑且缺乏细节;损失停在一个不上不下的位置。
根因: 像素独立的似然(伯努利或逐像素高斯)只惩罚单像素误差,最优解是条件均值——在不确定性下,均值天然模糊。
修复: 加感知损失(VGG 特征、LPIPS);自然图像换成离散 logistic 混合似然;或者改用层次化 VAE,让高层潜变量管理全局结构,低层潜变量管理细节。
坑 4: NaN 损失与梯度爆炸#
症状: 跑几百步以后损失变成 NaN,或者梯度范数突然飙升好几个数量级。
根因: 几乎一定是这几个里的某一个:logvar 没设上界, KL 里 exp(logvar) 溢出; BCE 的输入跑出了 [0, 1];学习率过大;某个 batch 里重参数化的 $\sigma$
下溢成 0。
修复:
| |
几个常用变体#
Beta-VAE:显式追求解耦#
$$\mathcal{L} = \mathbb{E}_{q_\phi}[\log p_\theta(x\mid z)] - \beta \cdot D_{\mathrm{KL}}(q_\phi(z\mid x)\,\|\,p(z)),$$做解耦实验时 $\beta \in [2, 10]$ 比较典型。代价也很直白:$\beta$ 越大,重建越糊。
条件 VAE:可控生成#
$$q_\phi(z \mid x, y), \qquad p_\theta(x \mid z, y).$$代码层面,把 one-hot 的 $y$ 拼到编码器输入上,再在送入解码器前拼到 $z$ 上即可。要生成指定类别,只需采样 $z \sim \mathcal{N}(0, I)$ ,再附上想要的标签。
层次化 VAE:多尺度潜变量#
把潜变量堆成 $z_1, z_2, \ldots, z_L$ ,让 $z_{l-1}$ 在 $z_l$ 的条件下生成。下层潜变量管局部细节,上层管全局语义。现代变体(NVAE、 Very Deep VAE)就是靠这一招把样本质量逼近扩散模型的。
实战经验#
输入归一化要匹配你用的似然#
BCE 期望像素落在 $[0, 1]$ ;高斯似然(MSE)则在零均值数据上更稳。
| |
潜在维度从小开始#
MNIST 这种规模,latent_dim = 20 是个合理起点。太小,重建被瓶颈卡死;太大,更容易后验坍塌,训练也变慢。
永远把重建项与 KL 项分开打印#

健康的训练曲线应该是:重建项单调下降,KL 项稳定在一个非平凡的值(每个活跃维度几个 nat)。如果 KL 一直贴在零,说明你在经历后验坍塌;如果 KL 爆掉,说明重建项被忽视。
把潜在空间画出来#
二维潜空间(或更高维做 PCA/t-SNE 之后),按类别给 $\mu(x)$ 上色画散点图。你应该看到的是有重叠但仍可分的若干类簇,并且大致铺满先验。

| |
既要采样,也要在样本之间走#
下面这两个工具函数你会反复用到:
| |
一段干净的潜在插值,是证明你的 VAE 训练成功的最有说服力的可视化。

VAE 与其他生成模型的对比#

| 模型 | 潜在空间 | 训练 | 生成质量 | 可解释性 |
|---|---|---|---|---|
| VAE | 显式、平滑 | 稳定(ELBO) | 凑合,偏糊 | 高(常常解耦) |
| GAN | 隐式 | 不稳定(对抗) | 锐利、逼真 | 低(常见模式坍塌) |
| 扩散模型 | 隐式(按步) | 稳定(去噪) | 当前最佳 | 中(迭代采样) |
| 自回归 | 无 | 稳定(似然) | 高,但慢 | 低(顺序生成) |
适合用 VAE 的场景: 下游任务需要显式潜在表示;想要训练稳定、不搞对抗博弈;关心解耦或可解释性。
别用 VAE 的场景: 目标是照片级真实(用 GAN 或扩散);只要序列上的似然(用自回归)。
总结:VAE 五步走#
- 编码器输出 $\mu_\phi(x)$ 与 $\log \sigma^2_\phi(x)$ ,不再是单个确定的编码。
- 重参数化: $z = \mu + \sigma \odot \epsilon$ ,$\epsilon \sim \mathcal{N}(0, I)$ ——梯度顺利通过。
- 解码器从 $z$ 重建 $\hat{x}$ 。
- 损失 = 负 ELBO: 重建 + $\beta$ · KL。
- 采样: $z \sim \mathcal{N}(0, I) \to$ 解码器 $\to \hat{x}$ 。
最影响结果的几个超参: 潜在维度(从 20 起步)、$\beta$ (默认 1.0,追解耦时调大)、学习率(Adam 1e-3,配 10–20 轮 KL 退火,梯度裁剪 1.0)。
早晚会踩的坑: 后验坍塌(用 KL 退火或 free bits)、采样模糊(加大潜在维度或感知损失)、 NaN 损失(钳制 logvar、裁剪梯度)。
参考文献#
- Kingma, D.P. & Welling, M. (2013). Auto-Encoding Variational Bayes . VAE 的原始论文。
- Higgins, I. et al. (2017). beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework .
- Doersch, C. (2016). Tutorial on Variational Autoencoders . 推导细致的入门教程。
- Sohn, K., Lee, H. & Yan, X. (2015). Learning Structured Output Representation using Deep Conditional Generative Models . CVAE 论文。
- Vahdat, A. & Kautz, J. (2020). NVAE: A Deep Hierarchical Variational Autoencoder . 把 VAE 样本质量推到能与 GAN 对抗的层次化版本。
- Kingma, D.P. & Welling, M. (2019). An Introduction to Variational Autoencoders . 全面的综述专著。