论文精读:将大语言模型融入图结构会话推荐(LLMGR)
LLMGR 用混合编码层把 64 维 ID 映射到 4096 维 LLM 空间,两阶段 prompt tuning,冷启动 HR@20 提升 8.68%。
会话推荐(Session-based Recommendation, SBR)本质上是一个“短历史”问题:你只看到用户在一次会话中很短的一段点击序列(通常 3-20 次),就要预测下一个最可能点击的物品。难点在于工程现实,会话短、长尾多、冷启动多,仅依赖交互图(ID + 转移边)往往难以稳定训练:新物品几乎无交互边,长尾物品的边既稀疏又不可靠,用户随意点击还会引入噪声。
但真实系统中其实存在大量未被充分利用的文本侧信息:标题、描述、属性、评论。若能有效利用这些文本信息,理论上可直接缓解冷启动与长尾问题,新物品没有交互但有标题和描述,长尾物品交互少但语义信息依然存在。问题在于传统 GNN-SBR 很难把文本语义有效注入到会话图建模里:图模型擅长结构,而 LLM 擅长语义,两者的表示空间天然不兼容,简单拼接后难以稳定训练。
LLMGR 的做法是把大语言模型当作“语义引擎”,将文本转换为可与图节点对齐的表示,用混合编码层将语义和图结构统一到同一个表示空间,再通过两阶段提示调优策略,先让模型学会“这段描述对应哪个物品”,再让它学会“根据会话图预测下一跳”。在 Amazon Music、Beauty 和 Pantry 数据集上,相比最强 GNN 基线,HR@20 提升约 8.68%,NDCG@20 提升 10.71%,MRR@20 提升 11.75%,且提升主要集中在冷启动样本中,这是这篇论文最有说服力的一个数字。
你将学到什么#
- 为什么纯 GNN 会话推荐在冷启动 / 长尾上会崩
- LLMGR 架构: LLM 语义流 + GNN 结构流 + 混合融合层
- 两类提示设计:辅助的节点-文本对齐 + 主任务的下一跳预测
- 混合编码层:用一个线性映射 $W_p$ 把 64 维 ID 空间打到 4096 维 LLM 空间
- 为什么两阶段提示调优比一阶段联合训练更稳
- 在 Music/Beauty/Pantry 上按冷启动 / 暖启动分桶后的真实增益
- 上线时怎么避免每个请求都跑一次 LLM
前置知识#
- 会话推荐基础(SR-GNN、GC-SAN)
- LLM 微调基础(LoRA、提示调优)
- 推荐系统指标:HR@K、NDCG@K、MRR@K
论文信息#
一、为什么纯 GNN 会话推荐在稀疏场景里学不稳#
会话输入是一段很短的点击流 $s = [v_1, v_2, \dots, v_n]$ ,通常只有 3 到 20 次点击,目标是给下一跳打分或对候选集排序。让任何“只看 ID 和边”的模型都为难的,是这三件事:
- 序列短: 3-20 次点击里夹着大量探索噪声,要从这么少的点击中抽出稳定的意图信号,本身就难。
- 长尾占了大头: 大部分物品边很少,且仅有的边也不可靠; GNN 在这种边上学的是噪声。
- ID 没有语义: 同一个邻居关系到底意味着同类、互补还是替代?转移边本身分不清。
文本通常是救命稻草,新 SKU 没有交互,但有标题、描述、类目;长尾物品同理。但行业里最常见的做法“拼一个冻结的 BERT embedding 上去”几乎从不奏效,原因有两点:
- 空间不匹配。文本 embedding(768 或 4096 维)和图 embedding(64 维)几何完全不同。直接拼接,优化器没有任何理由去对齐它们。
- 领域不匹配。预训练编码器在 Wikipedia 和 CommonCrawl 上训练,不在购物意图上训练。“iPhone”和“充电器”在通用英语里不相关,但在零售里高度互补。
LLMGR 的贡献在于提供了一种真正能解决这种错配的方案。
二、架构: LLM 当语义引擎, GNN 当排序器#
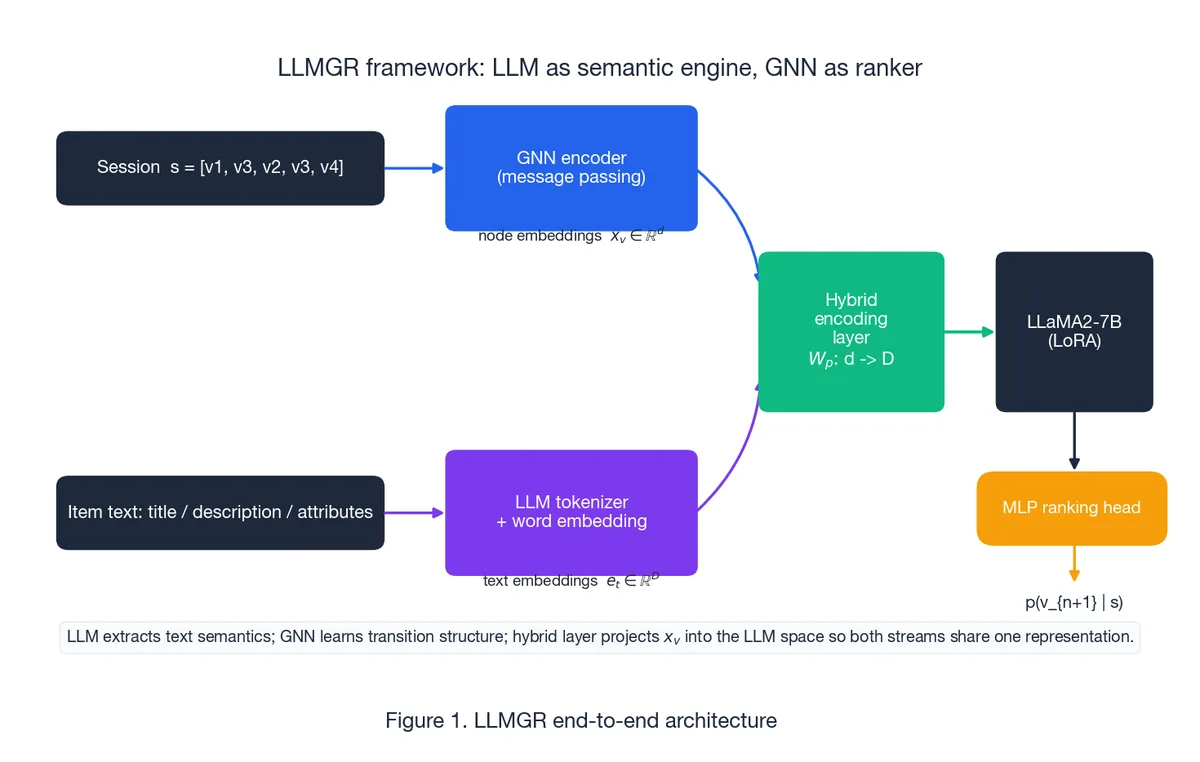
理解 LLMGR 最干净的方式,是把它看成一个双流模型,中间有一层融合,顶上是一个排序头。
一个常见但错误的思路是“让 LLM 直接生成下一个物品”。这条路走不通,原因很具体:
- 候选集太大: 几万个物品塞不进任何 token budget。
- 排序需要校准分数和负采样: 自由生成的输出给不了你一个校准的 $p(v \mid s)$ 。
- 在线成本: 每个请求都跑一次 7B 模型,延迟和成本都顶不住。
LLMGR 的赌注更务实:让 LLM 抽语义,让 GNN + MLP 头去做真正的排序。 推理时 LLM 不输出物品 ID,它只输出一个隐状态,由排序头去给候选集打分。
三、多任务提示:把 prompt 当成监督接口#

LLMGR 里的 prompt 不是给用户看的 UI,而是训练时的监督信号接口,通过设计不同的任务,逼模型学到我们真正想要的跨模态对齐。两类提示就把所有事情干完了。
辅助任务做的是节点-文本对齐:给模型一段描述和若干候选物品 ID,让它判断这段描述对应哪个 ID。这是把文本语义“锚定”到 ID 表示上的关键杠杆,没有它, LLM 没有任何理由把"Seagull Pro-G Guitar Stand"映射到 ID 空间里某个具体位置。
主任务做的是下一跳预测:模型拿到会话图(节点 + 有向边 + 最近一次点击)和候选集,输出一个隐状态,排序头把它转成 $p(v_{n+1} \mid s)$ 。
两个任务共享同一个 LLM、同一个混合编码层、同一个交叉熵损失。差别完全在于梯度承载的是哪种监督信号。
四、混合编码层:一个线性映射连接两个空间#

投影后的 ID 向量再和文本 token embedding 拼接,作为额外 token 送进 LLM。
这个设计有几条值得强调的性质:
- $W_p$ 是唯一的“桥参数”。 GNN 和 LLM 都保留各自原生权重,桥接全交给一个 $D \times d$ 的小矩阵,便宜训、便宜换。
- 融合是结构性的,不是统计性的。 在 LLM 自己的输入空间里拼接,让自注意力自己去学跨模态交互,比手工设计门控更灵活。
- 从 LLM 的视角,文本和 ID 是可互换的。 这正是“这段文本对应哪个 ID”这种辅助任务能写得出来的前提。
五、两阶段提示调优:先对齐,再学行为#

把辅助任务和主任务一起联合训练是不行的。 LLMGR 把训练拆成两段,而且这个拆分本身就是方法的核心。
第一阶段,语义落地(1 个 epoch)。 GNN 冻结,只更新混合层和 LLM (用 LoRA)。损失是辅助任务“这段文本对应哪个 ID”的交叉熵。这里冻结 GNN 是关键:如果 GNN 可以动,模型完全可以通过过拟合转移边来“绕过”对齐任务,文本通道就什么也学不到。
第二阶段,行为模式学习(每个数据集约 3 个 epoch)。 解冻 GNN。损失是主任务下一跳预测的交叉熵。第一阶段建立的语义 anchor 在联合优化中被保留下来,模型现在是在“已经落地的语义”基础上学转移结构,而不是用结构去顶替语义。
为什么必须拆? 一阶段联合训练时,模型还没学会“哪段文本对应哪个 ID”,行为噪声直接主导梯度,文本通道塌缩成噪声,模型退化成普通 GNN-SBR,冷启动的增益就消失了。论文 RQ3 的消融实验印证了这一点:去掉第一阶段后, Beauty 上 NDCG@20 下降 4.16%。
训练日程是有工程意图的,不是随便定的: 1 个 epoch 足够做语义对齐,因为文本到 ID 的映射是接近确定的;行为模式更嘈杂,需要更多轮次。
六、关键的数学#
会话图#
对点击流 $s = [v_1, \dots, v_n]$ ,构造 $G_s = (V_s, E_s)$ ,其中 $V_s$ 是去重后的物品集合,$E_s$ 包含每对相邻点击 $(v_i, v_{i+1})$ 形成的有向边。重复出现的物品在 $V_s$ 里只算一个节点,但它进出的所有边都保留。
GNN 消息传递#
$$t_v^{(l+1)} = f_{\text{agg}}\!\left(\{x_u^{(l)} : u \in N(v)\}\right), \qquad x_v^{(l+1)} = f_{\text{upd}}\!\left(x_v^{(l)}, t_v^{(l+1)}\right)$$经过 $L$ 层后,$x_v^{(L)}$ 汇集了 $L$ 跳邻居的信息。
图级读出#
$$z_s = f_{\text{readout}}\!\left(\{x_v^{(L)} : v \in V_s\}\right)$$常见选择: mean / max pooling,或注意力池化(通常给最后一次点击的节点最高权重)。
混合编码与排序头#
$$\tilde{x}_v = W_p\, x_v, \qquad H = \mathrm{LLM}\!\left([\tilde{x}_{v_1}, \dots, \tilde{x}_{v_n};\; e_{t_1}, \dots, e_{t_m}]\right)$$ $$p(v_{n+1} \mid s) = \mathrm{softmax}(W_o\, H)$$ $$\mathcal{L} = -\sum_{i} y_i \log p_i$$其中 $y$ 是真实下一跳的 one-hot 标签。
七、实验:论文报告了什么#

实验设置#
三个 Amazon 数据集,Music、Beauty、Pantry,选择标准是:(a) 物品文本丰富,(b) 购物意图差异大,(c) 长尾严重。标准预处理:剔除交互少于 5 次的用户和物品;用 leave-one-out 划分(最后一个物品做测试,倒数第二个做验证)。
基线覆盖了所有该有的方向:
- 马尔可夫 / 矩阵分解: FPMC
- CNN: CASER
- RNN: GRU4Rec、 NARM
- 注意力: STAMP
- GNN: SR-GNN、 GCSAN、 NISER、 HCGR
复现要点:
- 基础 LLM:LLaMA2-7B + LoRA,2 张 A100, DeepSpeed
- ID embedding 从预训练 GCSAN 引导而来, LLM 训练过程中不再修改,一个不起眼但很关键的工程 trick,避免在 LLM 内部从零学 ID embedding
- 优化器: AdamW, batch size 16, cosine schedule, weight decay 1e-2
- 第一阶段 1 个 epoch,第二阶段每个数据集 3 个 epoch
主结果(RQ1)#
相比最强基线(通常是 GCSAN 或 HCGR), LLMGR 报告:
| 指标 | 相对提升 |
|---|---|
| HR@20 | +8.68% |
| NDCG@20 | +10.71% |
| MRR@20 | +11.75% |
NDCG 和 MRR 涨得比 HR 更多,是 LLMGR 的典型签名:它不只是命中得更多,而是把对的东西排到了更靠前的位置。
可移植性(RQ2)#
把“语义模块”(LLM + 混合层 + 多任务调优)嫁接到 GRU4Rec、 STAMP、 GCSAN 上,三者都涨。平均增益:Music ~8.58%,Beauty ~17.09%。 Beauty 涨得更多,跟 Beauty 的文本多样性更高(品牌、成分、功能)一致,LLM 有更多东西可挖。
消融(RQ3)#
去掉辅助任务(即跳过第一阶段):
- Music HR@20 下降 2.04%
- Beauty NDCG@20 下降 4.16%
NDCG / MRR 比 HR 跌得更多,说明辅助任务在干它该干的事,提升的是排序质量,不是命中数量。
冷启动(RQ4)——真正的卖点#
LLMGR 的价值主张就是稀疏性,所以冷启动这一刀必须看。按交互次数分桶:暖启动(50+ 次) vs 冷启动(5-10 次)。
两个结论:
- 冷启动增益是暖启动增益的好几倍。 收益不是均匀的,它确实集中在文本语义能救命的地方。
- 三个数据集都呈这个模式: 排除了最无聊的解释(“LLMGR 只是恰好把 Music 学得更好”)。
可解释性(RQ5)#
论文展示了一些定性案例,辅助任务确实把描述相近的物品对齐到了相近的 ID。这不是指标,但它正面回答了“LLM 是不是真的在学正确的事”,答案是肯定的。
八、工程视角:怎么把它真正用上线#
别让 LLM 上线路#
prompt 是训练时的监督信号,不该出现在在线路径上。部署模式应该是:
- 每个物品离线跑一次: 用 LoRA 微调后的 LLM 把目录跑一遍,把投影后的文本表示存进向量库。
- 每个请求在线轻量处理: 轻量 GNN 编码会话,向量库取出文本表示,混合层融合, MLP 头排序。在线无 LLM forward。
- 物品变动时重跑: 新物品入库时跑一次,描述更新走定时刷新。
如果某个切片确实需要在线 LLM 推理(比如长 prompt 的个性化重排),蒸馏到小模型,或保持 LoRA adapter 常驻。
文本要先洗#
营销话术让所有东西看起来都很像,“Best Choice! Top Quality! Limited Offer!“是噪声,会伤排序。在 LLMGR 看到描述之前:
- 去 HTML 和营销模板
- 抽出结构化字段(品牌、类目、关键属性)放在前面
- 描述太长就截断或摘要,控制 token 预算
永远做分桶评估#
整体指标可以掩盖一切。 LLMGR 的全部意义在冷启动桶;如果你只看整体 HR,你根本分不清增益是来自头部物品(基线本来就处理得好)还是来自尾部(你真正掏钱买的那块)。按交互次数分桶分别报指标。如果增益不在冷启动桶里, LLMGR 就没赚到它的成本。
成本 / 质量旋钮#
LLaMA2-7B + LoRA + 2 张 A100 不便宜。如果成本敏感:
- 换更小的 LLM (1B 量级),接受一点质量回落
- LLMGR 只用在冷启动 / 长尾,头部继续用传统 GNN
- 文本表示按更慢的节奏刷新
九、 常见问题#
为什么不直接让 LLM 生成下一个物品?#
因为会话排序是一个需要校准分数、候选集巨大、对延迟和成本极其敏感的问题。生成式输出给不出在几万候选物品上校准的 $p(v \mid s)$ ,而且延迟 / 成本顶不住生产环境。让 LLM 抽语义、让 GNN + MLP 排序,既拿到了好处,又避开了坏处。
这是不是就是"BERT embedding + GNN"换个壳?#
这是该做的关键对照实验。 LLMGR 的主张是:多任务 prompt + 分阶段对齐才是让文本信号“真正落到正确的 ID 上、并在稀疏中保持稳定”的关键,不是“任何编码器都行”。具体说:
- 辅助任务逼模型学到“这段文本对应哪个 ID”,简单拼接 BERT embedding 学不到这个。
- 两阶段把对齐和行为学习分开,避免行为噪声淹没对齐信号。
- 7B LLM 的语义先验明显强于 BERT,尤其在长尾上 transfer 优势更明显。
如果你认真做的"BERT + GNN"基线就能追上 LLMGR,那 LLMGR 在你这边不值这个成本,直接跑一遍验证。
两阶段真的必要吗?#
RQ3 消融说必要,而且失败模式有清晰的诊断信号:跳过第一阶段时, NDCG/MRR 跌得比 HR 更多。这正是“打到了正确的邻域但没排好”的签名,也正是文本语义没对齐时该出现的情况。
是否存在能 work 的一阶段方案(联合训练 + 加权损失、课程学习),论文没测。
LLMGR 适合什么场景?#
适合:
- 物品文本丰富(标题、描述、属性、评论)
- 长尾严重,或新物品上线频繁
- 已有 GNN-SBR,不想推倒重来
不适合:
- 物品文本只是 SKU 编号
- 交互数据足够稠密,冷启动不是瓶颈
- 成本盘子吃不下一个 LoRA 微调的 7B 模型
十、 LLMGR 不适合的几类场景#
这套架构不是万能。三类场景里它会输给更简单的基线:
- 纯 ID 推荐 + 丰富行为日志。 当你有几年点击日志、每个 item 有上百次曝光、 item 标题就是 SKU 码这种没有语义的字符串时,一个朴素的 SR-GNN 跑 ID 已经很能打。 LLM 只能 embed
"商品 8472",对齐训练变成一场烧参数的仪式。 - 超长会话(>50 item)。 GNN 在长会话上还没等 LLM 特征进来就先过平滑了。论文的实验集中在平均 10 个 item 以下的会话;到 100 时头-尾差距塌掉,这种场景里基于 Transformer 的排序器(BERT4Rec)通常更稳。
- 总延迟预算小于 10 ms。 光消息传递就吃掉 5-10 ms, LLMGR 已经没有余量做跨 region 的 embedding 查询或特征拼接。这种场景老老实实用 Two-Tower 吧,上线路径就是一次点积。
LLMGR 真正吃下的甜区是论文里那一类:短的匿名会话、 catalogue 有描述文本、长尾很重。出了这个圈, LLMGR 的优势会很快缩小。


