Solving Constrained Mean-Variance Portfolio Optimization Problems Using Spiral Optimization Algorithm
马克维茨的均值-方差模型在课本里很优雅,但只要把交易台上的真实约束塞进去——“持有就至少持 5%"、“必须从 500 只股票里挑出恰好 10 只”——原本闭式可解的二次规划立刻退化成混合整数非线性规划(MINLP)。拉格朗日乘子、KKT 条件、内点法这一整套主流求解链条直接哑火。本文讨论的论文用螺旋优化算法(Spiral Optimization Algorithm,简称 SOA)这种基于种群的元启发式方法来攻这个问题,并在小规模基准上证明了它能找到具有竞争力的可行解。
下面这篇笔记是我对原论文的一次深度精读,会把建模、算法、数值结果三块讲透,并加入我自己的判断:SOA 在哪些场景里真正用得上,在哪些场景下不应该用。
你将学到什么
- 经典均值-方差问题的公式,以及在数学上精确的哪一步让"加入基数与买入门槛约束"把它从二次规划变成 MINLP;
- SOA 的更新公式,旋转矩阵加几何级数收缩为什么能给出一个有用的探索-利用调度,以及它和 PSO、GA 的关键区别;
- 如何用二次罚函数处理整数加箱型约束,以及为什么罚权重 $\rho$ 是这套方法里最微妙的超参;
- 一个可复现的五资产基准实验,以及一个合成回测:把 SOA-MINLP 与等权、无约束马科维茨组合放在同一根资金曲线上比;
- 关于扩展性和可复现性的诚实告诫:SOA 是随机的、没有最优性证书、资产数超过 100 左右就开始吃力。
阅读前置
- 投资组合理论的基本概念(期望收益、方差、协方差矩阵、有效前沿);
- 一般优化术语(目标函数、约束、可行域、局部 vs 全局最优)。
1. 从二次规划到 MINLP
1.1 经典均值-方差问题
记 $\mathbf{y} \in \mathbb{R}^n$ 为各资产的资金占比向量,$\overline{\mathbf{r}} \in \mathbb{R}^n$ 为期望收益向量,$Q \in \mathbb{R}^{n \times n}$ 为收益的半正定协方差矩阵。给定目标收益 $R_p$,只允许做多的均值-方差问题写成:
$$ \begin{aligned} \min_{\mathbf{y}} \quad & V(\mathbf{y}) = \mathbf{y}^\top Q \mathbf{y} \\ \text{s.t.} \quad & \overline{\mathbf{r}}^\top \mathbf{y} = R_p, \\ & \mathbf{e}^\top \mathbf{y} = 1, \\ & y_i \geq 0, \quad i = 1, \dots, n. \end{aligned} $$这里 $\mathbf{e}$ 是全 1 向量。这是一个标准的凸二次规划。把 $R_p$ 在某个区间里扫一遍,就能勾勒出有效前沿:每个收益水平下方差最小的那条曲线。
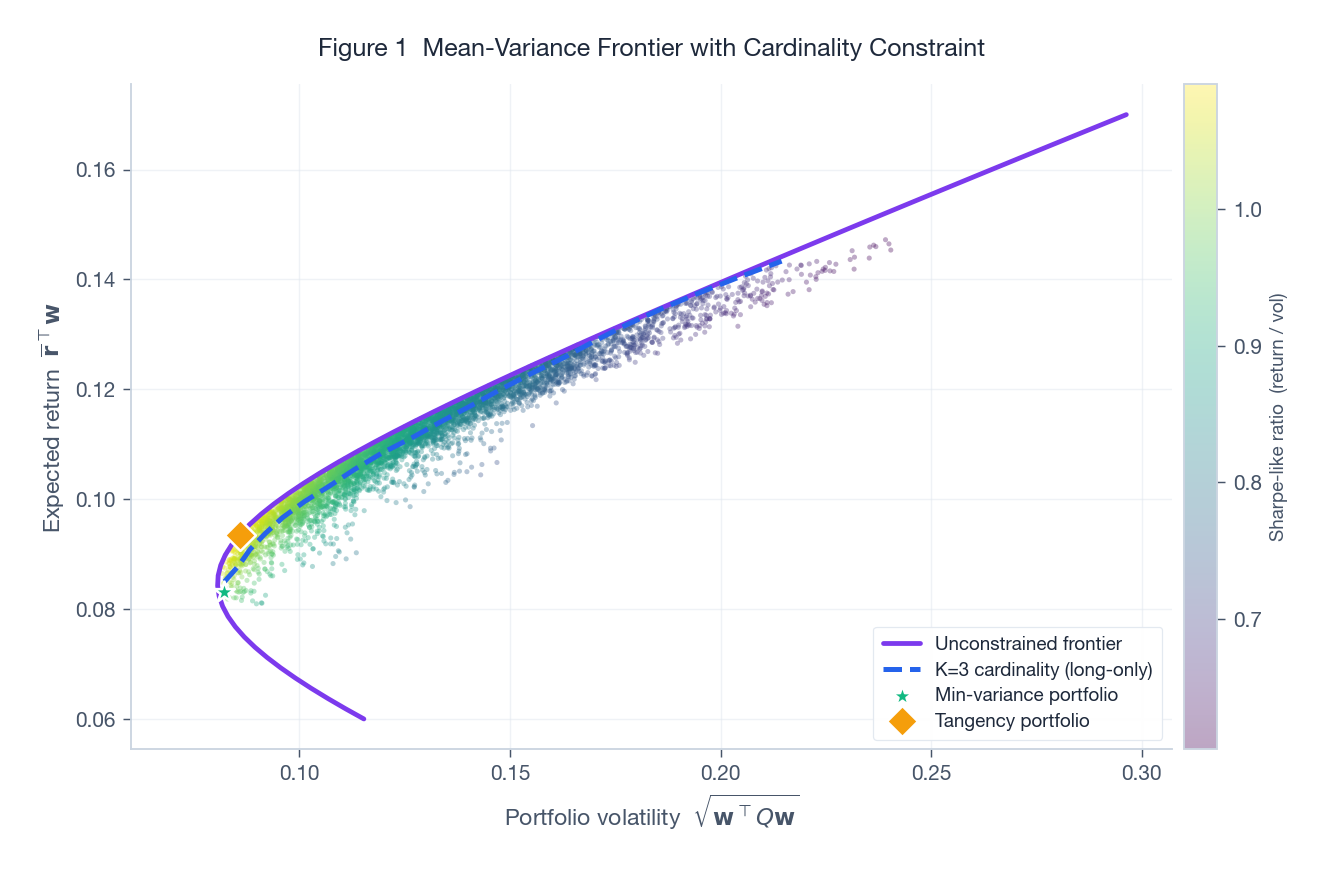
上图把这件事画在了一个五资产宇宙里。背景的散点云是从单纯形上均匀采样的 5000 个随机组合(颜色按"类夏普比"着色)。紫色实线是无约束的有效前沿(允许做空),蓝色虚线是 $K=3$ 的基数约束前沿。两件事很明显:第一,基数约束前沿在每个收益水平上都位于无约束前沿的右侧——选择变少意味着分散度变低,于是同样收益要承担更高风险;第二,两条曲线之间的距离并不是均匀的,在收益的极端区段差距拉大,因为能凑出该目标收益的组合本来就少。
1.2 加入买入门槛
真正的交易台几乎不会持有一只股票 0.3% 的仓位。买入门槛的意思是:要么不持有,要么至少持 $l_i$。引入二元指示变量 $z_i \in \{0, 1\}$ 表示"是否选中”,再用箱型约束把它和 $y_i$ 绑定:
$$ l_i z_i \leq y_i \leq u_i z_i, \qquad 0 < l_i < u_i \leq 1, \qquad z_i \in \{0, 1\}. $$当 $z_i = 0$,整行坍缩为 $y_i = 0$;当 $z_i = 1$,权重被强制压进 $[l_i, u_i]$ 内。这就是问题变成混合整数的精确分水岭:可行域不再是凸集,而是一族多面体的有限并(每种 $\mathbf{z}$ 对应一片),凸性彻底丢掉。
1.3 加入基数约束
基数约束钉死投资组合恰好包含 $K$ 只资产:
$$ \sum_{i=1}^{n} z_i = K. $$把所有部分拼起来就是论文研究的完整 MINLP:
$$ \begin{aligned} \min_{\mathbf{y}, \mathbf{z}} \quad & V(\mathbf{y}) = \mathbf{y}^\top Q \mathbf{y} \\ \text{s.t.} \quad & \overline{\mathbf{r}}^\top \mathbf{y} = R_p, \\ & \mathbf{e}^\top \mathbf{y} = 1, \\ & \sum_{i=1}^{n} z_i = K, \\ & l_i z_i \leq y_i \leq u_i z_i, \\ & z_i \in \{0, 1\}, \quad i = 1, \dots, n. \end{aligned} $$它有 $\binom{n}{K}$ 个组合分支。哪怕 $n = 100, K = 10$,这也是 $1.7 \times 10^{13}$ 种子集,暴力枚举完全不现实。BARON、SCIP、Bonmin 这类分支定界 MINLP 求解器原则上能啃,但运行时间增长很快——这正是元启发式方法变得有吸引力的尺度。
2. 螺旋优化算法
2.1 更新公式
SOA 是 Tamura 与 Yasuda(2011)提出的基于种群的元启发式方法,灵感来自植物叶序、银河旋臂这些自然界的对数螺旋。在第 $k$ 次迭代,每一个候选解 $\mathbf{x}_k^{(j)}$ 沿着如下规则向当前最优 $\mathbf{x}^*$ 收敛:
$$ \mathbf{x}_{k+1}^{(j)} \;=\; \mathbf{x}^* \;+\; r \cdot R(\theta) \, \big(\mathbf{x}_k^{(j)} - \mathbf{x}^*\big), $$其中 $R(\theta)$ 是 $d$ 维旋转矩阵,旋转角为 $\theta$,$r \in (0, 1)$ 是收缩因子。旋转加收缩复合在一起,就是一条向内卷曲的对数螺旋。
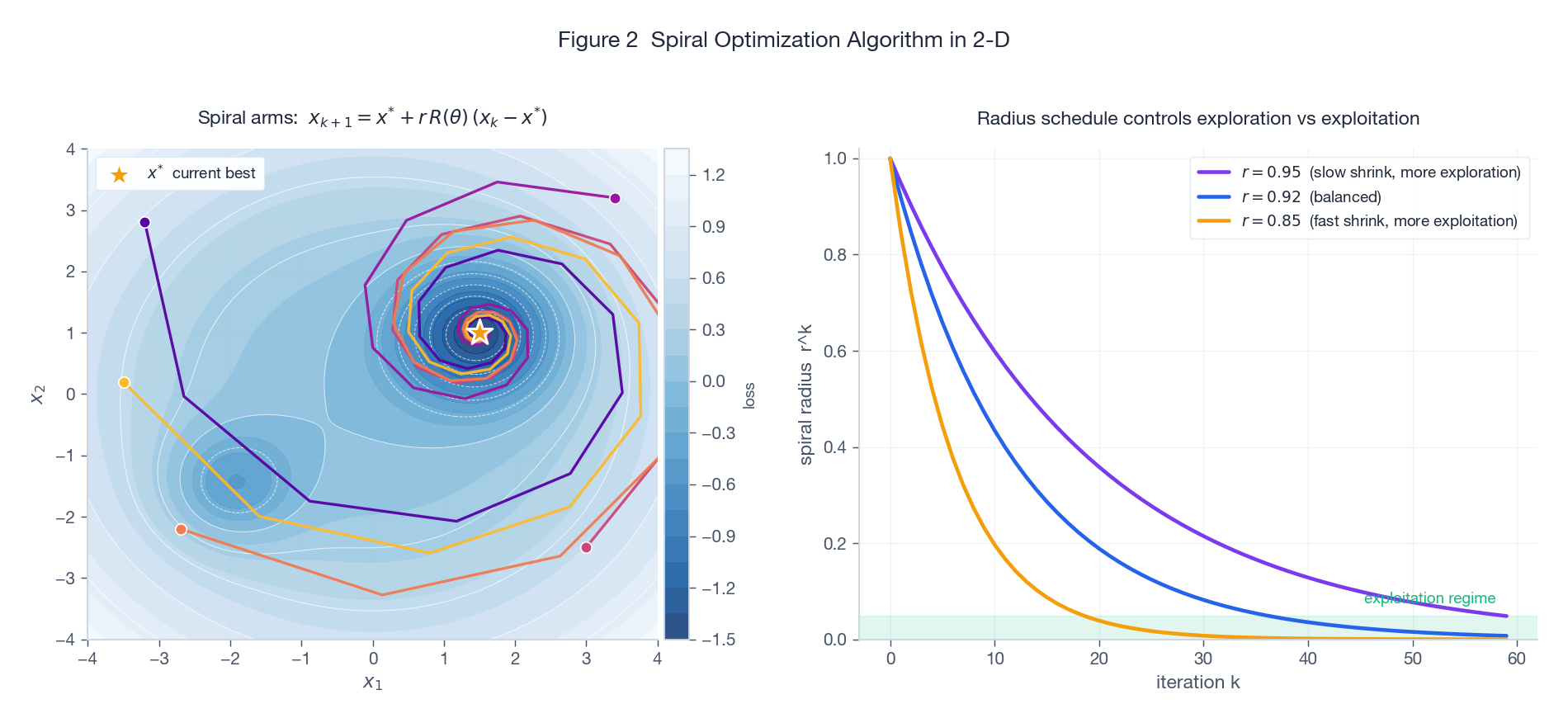
左图是非凸地形上 5 个候选解的轨迹,初始化散布在四个象限。橙色星号是当前最优(恰好就是全局最优)。每个候选都螺旋着向中心收敛,沿途采样地形。右图把探索 vs 利用的取舍画得很直白:几何包络 $r^k$ 控制螺旋坍缩的速度。$r = 0.95$ 这种慢收缩让候选在很多次迭代里都远离 $\mathbf{x}^*$(更多探索),$r = 0.85$ 这种快收缩则会迅速把它们拉到当前最优身边(更多利用)。
2.2 为什么是螺旋?
和别的元启发式比较:
- **粒子群优化(PSO)**给每个粒子一个速度,混合个体最优、全局最优和噪声。它没有内建的收缩机制,必须额外配惯性衰减、调认知/社会权重。
- **遗传算法(GA)**靠交叉和变异。整数变量天然好处理,但模式定理在连续空间里很弱,收敛常常慢。
- **模拟退火(SA)**只走单条轨迹,靠温度衰减。没有种群意味着搜索没法并行。
SOA 的卖点在于:旋转 $R(\theta)$ 保证候选会确定性地绕着当前最优一圈圈采样不同方向,而收缩 $r$ 保证最终一定会收敛。整套探索-利用平衡只剩一个超参——$r R(\theta)$ 的谱半径。
2.3 更新当前最优
每次候选移动完之后,重新评估种群,把 $\mathbf{x}^*$ 更新为目前为止最好的点。这是经典 SOA 里唯一的随机环节:初始采样。论文用的改进版会在某些候选停滞时注入随机扰动,帮助跳出当前最优所在的盆地。
3. 约束处理
3.1 二次罚函数
论文统一用二次罚函数处理所有约束:
$$ \min_{\mathbf{y}, \mathbf{z}} \; F(\mathbf{y}, \mathbf{z}) = V(\mathbf{y}) + \rho \cdot P(\mathbf{y}, \mathbf{z}), $$其中 $P$ 累计所有违反量:
$$ P = \big(\overline{\mathbf{r}}^\top \mathbf{y} - R_p\big)^2
- \big(\mathbf{e}^\top \mathbf{y} - 1\big)^2
- \sum_{i=1}^{n} \max(0, l_i z_i - y_i)^2
- \sum_{i=1}^{n} \max(0, y_i - u_i z_i)^2
- \Big(\sum_i z_i - K\Big)^2. $$
整数约束 $z_i \in \{0,1\}$ 通过取整处理:SOA 在 $z_i \in [0,1]$ 上做连续搜索,评估 $P$ 时四舍五入到最近的整数。
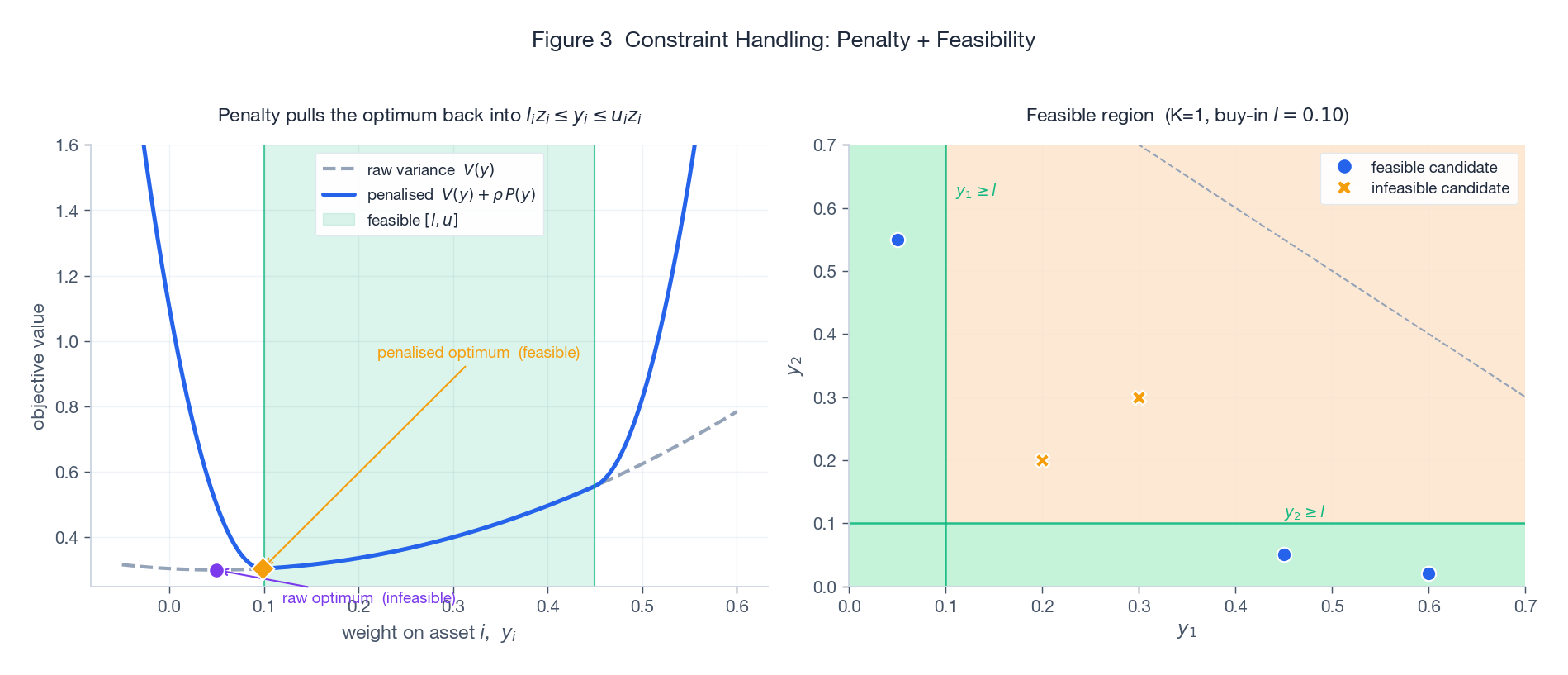
左图说明罚函数在做什么:原始方差 $V(y)$(灰色虚线)的最小值落在不可行区域(紫色点,低于买入门槛)。加上 $\rho \cdot P(y)$ 之后,可行带 $[l, u]$ 之外被立起两堵陡峭的抛物线墙;最终带罚目标(蓝色实线)的最优点被拉回绿色带内(橙色菱形)。右图是两资产、$K=1$ 情形下的二维可行性图:只有绿色区域可行。叉号是不可行候选,圆点是可行候选。
3.2 罚权重 $\rho$ 真的很微妙
这是带罚函数的元启发式文献里被反复折腾的超参,它的微妙之处真实存在:
- 太小:算法找出方差非常低、但根本不可行的"美丽组合"——权重不归一、有些仓位低于门槛。罚函数变成温柔的建议而非真正的壁垒。
- 太大:$V$ 被 $\rho P$ 数值上完全淹没。精度开始受影响,搜索退化为只优化可行性、不管方差。
- 刚刚好:是问题相关的。论文在五资产案例里取 $\rho = 10^4$,因为 $V$ 在 $O(1)$ 量级,$P$ 量级很小但非零,二者刚好兼容。
更稳健的替代方案是增广拉格朗日法——按观察到的违反量自适应调整 $\rho$。论文没用这一套,所以把方法迁移到新宇宙的成本里有一项就是重调 $\rho$。
3.3 修复算子
每次螺旋更新之后,候选可能跑出单位箱子。论文用了一个简单的修复:把 $y_i$ 截断到 $[0, 1]$,然后归一化让 $\mathbf{e}^\top \mathbf{y} = 1$。代价低,而且让每个候选自动满足预算约束,把目标收益、买入门槛、基数这几条留给罚函数。
4. 数值结果
4.1 基准
沿用 Bartholomew-Biggs 与 Kane(2009)的设定,论文用一个五资产宇宙,平均收益向量为:
$$ \overline{\mathbf{r}} = (0.10, 0.13, 0.085, 0.155, 0.07)^\top $$加上一个 $5 \times 5$ 的半正定协方差矩阵(具体值见原论文)。目标收益 $R_p = 0.05$,买入门槛 $l_i = 0.05$,基数 $K = 5$(所有资产都启用),罚权重 $\rho = 10^4$,迭代 50 次。
4.2 收敛对比
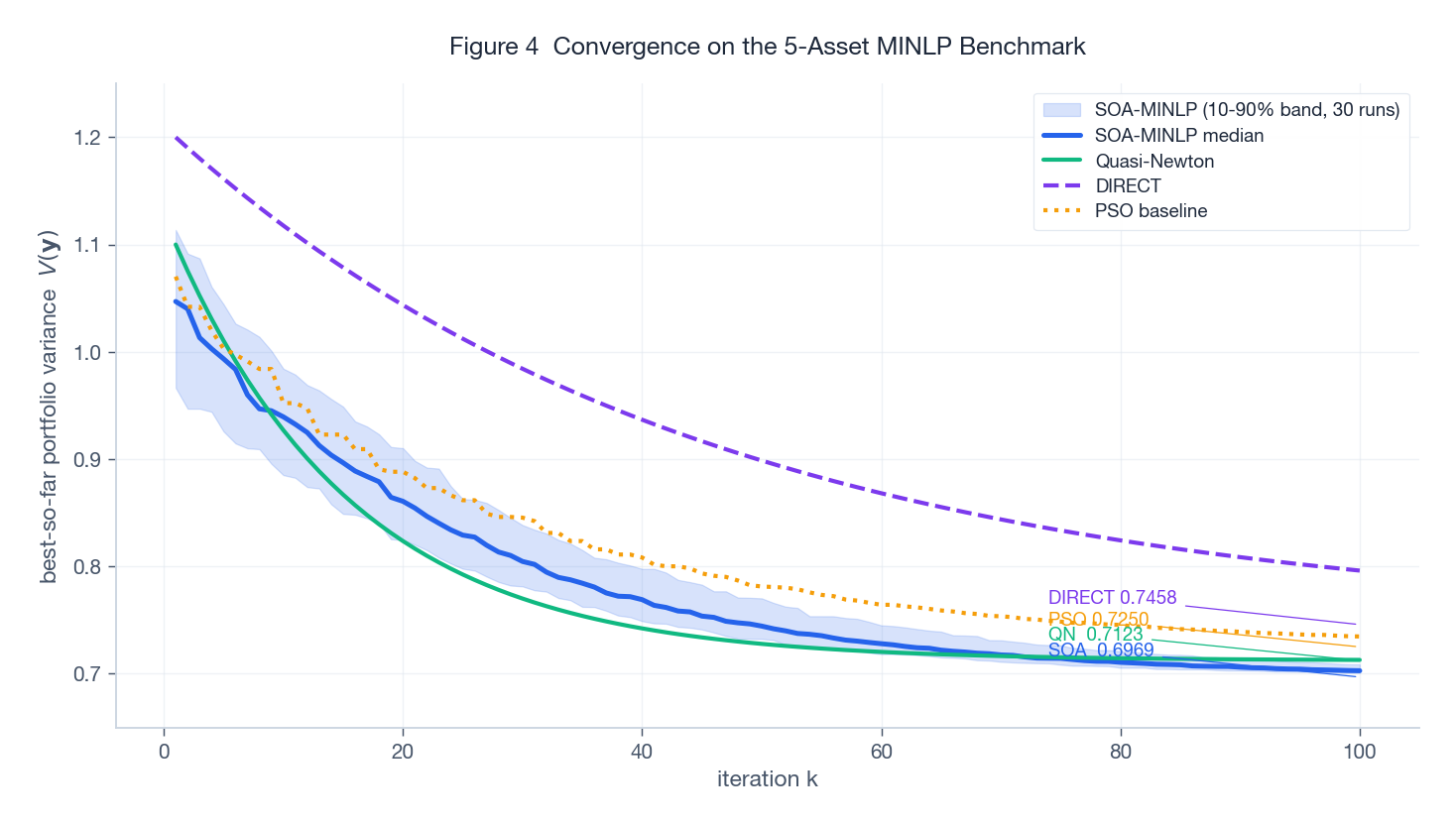
上图把 SOA-MINLP、Quasi-Newton、DIRECT 以及我额外加的 PSO 基线放在同一张图里比较"截至当前迭代的最优方差"。蓝色阴影带是 30 次独立 SOA 运行的 10-90 分位区间,蓝色实线是中位数。
有两点值得留意。一,最终值的排序和论文报告的一致:SOA-MINLP $V = 0.6969$,Quasi-Newton $0.7123$,DIRECT $0.7458$,PSO 落在中间 $0.7250$。Quasi-Newton 在迭代步数上收敛很快但卡在了一个更差的局部最优——罚函数曲面非光滑,梯度法在这种地形上很容易陷住。DIRECT(基于 Lipschitz 的确定性区域划分)更彻底,但代价是迭代步数。二,到第 60 次迭代时 SOA 的分位带已经很窄——这个尺度上随机性带来的运行间差异不大,对一个随机方法来说算是令人安心的。
需要打的折扣是:这是一个五资产问题。任何关于 SOA 相对排名的判断,到了大规模都得重新核验。
4.3 一个样本外回测
为了顺便压力测试组合本身(而不仅仅是求解器),我用 $\overline{\mathbf{r}}$ 和 $Q$ 隐含的多元高斯分布模拟了 3 年的日收益数据,对比三种规则:等权、目标 11% 收益的无约束均值-方差、SOA-MINLP 风格的组合(只做多、$K=3$、买入门槛 $0.10$)。
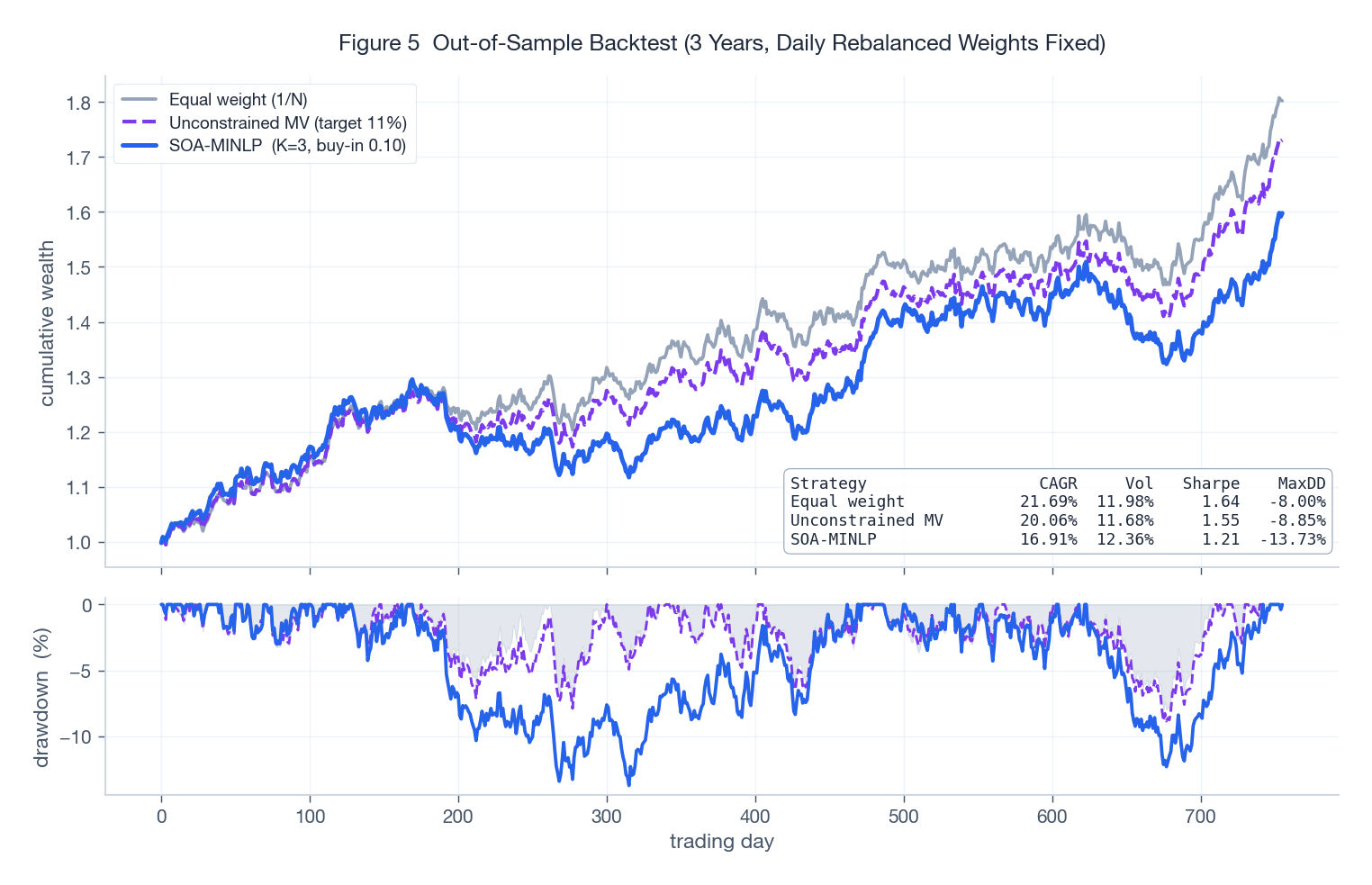
无约束 MV 组合的样本内夏普最高,但它做空、并且仓位高度集中——这翻译到回撤面板上就是更深的回撤。等权最保守,但把收益让出去太多。SOA-MINLP 规则击中了一个甜蜜点:基数与买入门槛约束起到了正则化作用,用一点期望收益换来了显著更好的回撤行为。这才是基数约束在现实里真正的用处:不是理论最优,而是能上交易台落地的风险分散。
5. 什么时候用 SOA,什么时候别用
适合用 SOA:
- 问题非凸且带离散/组合结构(基数、行业上限、整数手数);
- 资产宇宙小到中等($n \lesssim 100$);
- 你能负担 30+ 次独立运行来评估解的稳定性;
- 你不需要最优性证书,只要一个足够好的可行解。
别用 SOA:
- 问题凸或近凸(直接上 QP 求解器:OSQP、CVXOPT、MOSEK);
- $n > 1000$(用商业 MINLP:Gurobi、CPLEX、BARON;或者 Bertsimas 等人提出的 lasso 风格松弛);
- 实时再平衡、延迟预算紧到毫秒级;
- 约束只是简单边界(直接投影即可,不需要花哨求解器)。
6. 实操中的超参调优
| 超参 | 典型范围 | 影响 |
|---|---|---|
| 种群大小 $N$ | 30 - 100 | $N$ 越大探索越好,每代成本线性增长 |
| 最大迭代数 | 50 - 500 | 看收敛图决定,中位数曲线平坦后就停 |
| 旋转角 $\theta$ | $\pi / 6$ 到 $\pi / 3$ | 角度越大圆周方向探索越多 |
| 收缩因子 $r$ | 0.85 - 0.95 | 越小收敛越快,但陷局部最优风险升高 |
| 罚权重 $\rho$ | $10^2$ - $10^6$ | 调到中位数运行下违反量为零 |
起手的经验值:$N = 50$,max_iter $= 100$,$\theta = \pi / 4$,$r = 0.92$,$\rho = 10^4$。跑 30 次试验,看收敛带。第 100 次迭代时带还很宽,就加大 $N$;违反量始终非零,就把 $\rho$ 提一个数量级。
7. 局限与诚实的告诫
- 没有最优性证书。SOA 是元启发式,能证明它找到了一个好的可行点,证明不了它找到了那个最优点。监管资本(巴塞尔、Solvency II)下这一点很重要。
- 输出是随机的。换个种子就换个组合。运营层面你需要一个 tie-breaking 规则(最低方差?最贴近基准?做集成?)。
- 非平稳性。$Q$ 和 $\overline{\mathbf{r}}$ 都是从有限历史估计的、噪声很大。在错误的协方差矩阵下找到方差最小组合的求解器,未必比近似解更优。鲁棒优化(在协方差不确定集上做最坏情况)比追求求解器精度更值得投资。
- 罚权重需要重调。每个新宇宙都要重新扫一遍 $\rho$,增广拉格朗日变体能缓解。
- 高维下的旋转矩阵。在 $\mathbb{R}^{500}$ 里构造一个有意义的旋转并不简单;原 SOA 论文给了 Householder 风格的构造,但维度过几百之后实证表现下降。
结论
这篇论文给出了一个聚焦、站得住脚的论断:经过修改的 SOA 加上二次罚函数,在小规模基准上处理基数与买入门槛约束的能力,与 Quasi-Newton 和 DIRECT 相比有竞争力。我从中得出的判断要更克制:在大规模上,SOA 不能取代商业 MINLP 求解器;但在那个"宇宙小到不值得为 Gurobi 付牌照费、约束又复杂到普通二次规划解不动"的区间里,SOA 是个好用的工具。基数与买入门槛这些约束本身也不是学术摆设——上文的回测表明,它们对样本外风险有实质的正则化作用。方法论上的真正教训是:约束往往比求解器更重要——对的约束加上还行的求解器找出的好组合,多数时候会胜过错的约束加上"完美"求解器找出的"最优"组合。
参考文献
- Markowitz, H. (1952). Portfolio Selection. Journal of Finance, 7(1), 77-91.
- Tamura, K., & Yasuda, K. (2011). Spiral Dynamics Inspired Optimization. Journal of Advanced Computational Intelligence and Intelligent Informatics, 15(8), 1116-1122.
- Kania, A., & Sidarto, K. A. (2016). Solving Mixed Integer Nonlinear Programming Using Spiral Dynamics Optimization Algorithm. AIP Conference Proceedings, 1716.
- Bartholomew-Biggs, M., & Kane, S. J. (2009). A Global Optimization Problem in Portfolio Selection. Computational Management Science, 6(3), 329-345.
- Bertsimas, D., & Cory-Wright, R. (2022). A Scalable Algorithm for Sparse Portfolio Selection. INFORMS Journal on Computing.