2011 年,LinkedIn 工程团队正面临许多快速成长公司共有的难题:其单体应用已演变为一张由强耦合服务构成的复杂网络,每个服务都需同步调用另外约六个服务。一旦其中任一服务宕机,级联故障便会迅速蔓延至整个系统;而对某个服务做一次变更发布,则必须协调所有被它调用的服务所属团队。
他们的解决方案是 Apache Kafka —— 一个分布式事件日志系统,实现了生产者(Producer)与消费者(Consumer)的解耦。不再由服务 A 直接调用服务 B,而是服务 A 将事件写入 Kafka,服务 B 在就绪时再从中读取。若服务 B 宕机,事件将暂存于 Kafka 中;若服务 B 处理缓慢,它可按自身节奏消费。生产者无需知晓、也不必关心消费者的任何状态。
这种通过异步消息实现解耦的架构模式,是系统设计中最强大的工具之一。
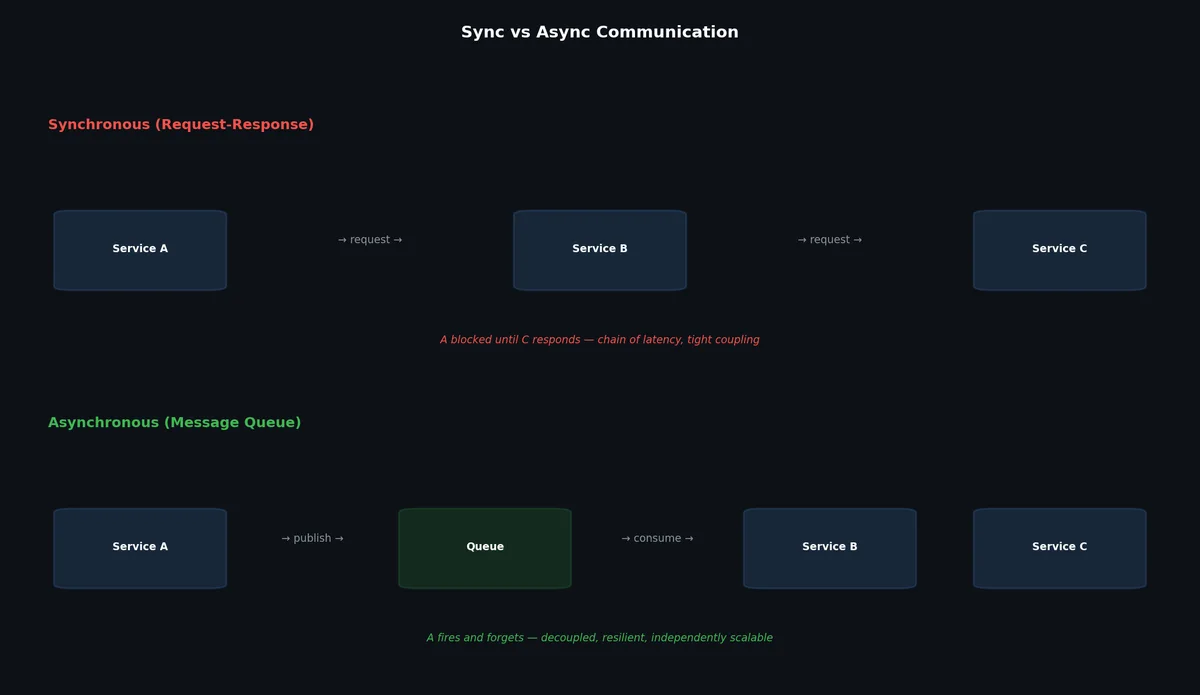
同步 vs 异步通信# 在同步系统中,调用方必须等待被调用方响应后才能继续执行。这种方式简单直观,适用于大量场景,但会带来强耦合。
1
2
3
4
5
6
7
同步(REST):
客户端 → 订单服务 → 支付服务 → 库存服务 → 通知服务
问题:
- 若支付服务耗时 5 秒,客户端需等待 5+ 秒
- 若通知服务宕机,整个订单流程失败
- 每个服务都必须承载上游所有服务带来的负载压力
而在异步系统中,调用方发送消息后即刻返回,被调用方则独立处理该消息。
1
2
3
4
5
6
7
8
9
10
11
异步(消息队列):
客户端 → 订单服务 → 消息队列
↓
支付服务(就绪时读取)
库存服务(就绪时读取)
通知服务(就绪时读取)
优势:
- 客户端获得即时响应(“订单已接受”)
- 各服务独立、按自身节奏处理
- 若通知服务宕机,消息将在队列中暂存,待其恢复后继续处理
何时使用异步通信# 建议在以下场景采用异步通信:
下游操作耗时较长(如支付处理、邮件发送) 下游服务不可靠(如第三方 API) 需要扇出(fan-out)至多个消费者 该操作对用户即时响应非必需 需吸收流量峰值(burst traffic) 建议保持同步通信的场景包括:
用户需要即时结果(如登录、搜索) 操作必须具备事务性(如扣减账户余额、权限校验) 当前延迟已足够低,且引入异步的复杂度不具合理性 系统中服务数量少于 3–4 个(此时引入消息队列的开销得不偿失) 消息队列基础概念# 所有消息队列系统均包含以下核心组件:
生产者(Producer) :向队列发送消息的应用程序。
消费者(Consumer) :从队列中读取并处理消息的应用程序。
代理(Broker) :存储和路由消息的服务器,可以是单节点或集群。
主题 / 队列(Topic / Queue) :消息的命名通道。生产者向主题写入,消费者从主题读取。
分区(Partition) :主题的子划分单元,用于实现并行处理。每个分区是一个有序、不可变的消息序列。
消费者组(Consumer Group) :一组协同消费同一主题的消费者。每个分区在组内仅分配给一个消费者,从而支持并行处理。
偏移量(Offset) :消费者在某一分区中的当前位置,用于追踪哪些消息已被处理。
Apache Kafka# Kafka 是一款为高吞吐、高持久性与高可扩展性而设计的分布式事件流平台。它将消息建模为追加式日志(append-only log),而非传统意义上的队列。
Kafka 集群由以下组件构成:
Broker :存储数据并响应客户端请求的服务器实例。生产环境集群通常包含 3–12+ 个 Broker。
Topic(主题) :组织消息的分类。每个 Topic 被划分为多个 Partition。
Partition(分区) :并行处理的基本单元。每个 Partition 是一个有序、只追加的日志,存储于单个 Broker 上(同时在其他 Broker 上保留副本)。
副本(Replication) :每个 Partition 可配置多个副本。其中一个为 Leader(负责所有读写请求),其余为 Follower(从 Leader 复制数据)。
ZooKeeper / KRaft :管理集群元数据、Broker 协调及 Leader 选举。自 Kafka 3.x 起,Kafka 正逐步弃用 ZooKeeper,转而采用内置共识协议 KRaft。
Kafka 如何存储数据# Kafka 的 Partition 以一系列段文件(segment files)形式存储于磁盘。每个段文件按顺序存放消息。新消息被追加到当前活跃段(active segment)。旧段根据时间或大小策略保留,并最终被删除或压缩(compacted)。
1
2
3
4
5
6
7
8
9
10
Topic: orders(3 个分区)
Partition 0: [msg0, msg1, msg2, msg3, msg4, ...] → Broker 1(Leader)
Broker 2(副本)
Partition 1: [msg0, msg1, msg2, ...] → Broker 2(Leader)
Broker 3(副本)
Partition 2: [msg0, msg1, msg2, msg3, ...] → Broker 3(Leader)
Broker 1(副本)
Kafka 生产者配置# 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
from kafka import KafkaProducer
import json
producer = KafkaProducer (
bootstrap_servers = [ "kafka1:9092" , "kafka2:9092" , "kafka3:9092" ],
value_serializer = lambda v : json . dumps ( v ) . encode ( "utf-8" ),
key_serializer = lambda k : k . encode ( "utf-8" ) if k else None ,
# 持久性设置
acks = "all" , # 等待所有副本确认
retries = 3 , # 发生临时故障时重试
retry_backoff_ms = 100 , # 重试间隔
# 批处理提升吞吐
batch_size = 16384 , # 批大小 16 KB
linger_ms = 10 , # 最多等待 10ms 填满一批
# 压缩
compression_type = "lz4" , # 压缩批次(lz4 性能优异)
)
# 发送订单事件
# Key 决定分区分配(相同 Key → 同一分区 → 保证顺序)
producer . send (
topic = "orders" ,
key = "user_123" ,
value = {
"order_id" : "ord_789" ,
"user_id" : "user_123" ,
"items" : [{ "product_id" : "prod_456" , "quantity" : 2 }],
"total" : 59.98 ,
"timestamp" : "2025-07-19T10:30:00Z" ,
},
)
producer . flush ()
key 参数至关重要。Kafka 对 key 进行哈希以确定目标分区。相同 key 的消息始终进入同一分区,从而确保该 key 下的消息严格有序。这对“某用户的所有事件必须按序处理”等场景尤为关键。
Kafka 消费者配置# 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
from kafka import KafkaConsumer
import json
consumer = KafkaConsumer (
"orders" ,
bootstrap_servers = [ "kafka1:9092" , "kafka2:9092" , "kafka3:9092" ],
group_id = "payment-service" ,
value_deserializer = lambda m : json . loads ( m . decode ( "utf-8" )),
# 偏移量管理
auto_offset_reset = "earliest" , # 若无已保存 offset,则从头开始读
enable_auto_commit = False , # 手动 commit,实现 at-least-once 语义
# 性能
max_poll_records = 500 , # 每次 poll 最多处理 500 条消息
fetch_max_wait_ms = 500 , # 最多等待 500ms 获取数据
)
for message in consumer :
order = message . value
try :
# 处理订单
process_payment ( order )
# 仅在成功处理后 commit offset
consumer . commit ()
except Exception as e :
logger . error ( f "处理订单 { order [ 'order_id' ] } 失败: { e } " )
# 不 commit → 消息将被重新处理
Kafka 消息保留策略# 不同于传统队列在消息被消费后即删除,Kafka 根据时间或大小策略保留消息:
1
2
3
4
5
6
# Kafka 主题配置
retention.ms : 604800000 # 7 天(默认值)
retention.bytes : -1 # 无大小限制(默认值)
cleanup.policy : delete # 删除过期段文件
# OR
cleanup.policy : compact # 按 key 保留最新值(适用于变更日志)
日志压缩(Log Compaction)对维护变更日志(changelog)特别有用:Kafka 为每个 key 仅保留最新值,丢弃旧值。这使得消费者可通过读取整个压缩后的主题重建完整状态。
RabbitMQ#
RabbitMQ 是基于 AMQP 协议的传统消息代理,专注于灵活的路由机制、基于确认(acknowledgment)的投递保障,以及细粒度的消息级功能。
RabbitMQ 采用与 Kafka 不同的模型:
Exchange(交换器) :接收生产者发来的消息,并依据路由规则将其分发至队列。共有四种 Exchange 类型。
Queue(队列) :存储消息直至消费者取走。消息在被确认(acknowledged)后即被删除。
Binding(绑定) :连接 Exchange 与 Queue 的规则,可选配路由键(routing key)匹配模式。
Exchange 类型# Direct Exchange(直连交换器) :将消息路由至 routing key 与 binding key 完全匹配的队列。
1
2
3
4
5
6
7
8
9
10
11
12
13
# 生产者向 direct exchange 发送消息,指定 routing key
channel . basic_publish (
exchange = "orders" ,
routing_key = "payment" , # 精确匹配
body = json . dumps ( order_data ),
)
# 队列 "payment_queue" 绑定至 exchange "orders",binding key 为 "payment"
channel . queue_bind (
queue = "payment_queue" ,
exchange = "orders" ,
routing_key = "payment" ,
)
Topic Exchange(主题交换器) :基于 routing key 的通配符模式匹配进行路由。
1
2
3
4
5
6
7
8
9
10
11
12
13
# Routing key: "order.created.us"
channel . basic_publish (
exchange = "events" ,
routing_key = "order.created.us" ,
body = json . dumps ( event ),
)
# 使用通配符的绑定规则
channel . queue_bind ( queue = "all_orders" , exchange = "events" , routing_key = "order.#" )
# 匹配: order.created.us, order.cancelled, order.created.eu
channel . queue_bind ( queue = "us_events" , exchange = "events" , routing_key = "*.*.us" )
# 匹配: order.created.us, user.registered.us
Fanout Exchange(扇出交换器) :忽略 routing key,将消息广播至所有绑定队列。
1
2
3
4
5
6
# 所有绑定队列均收到每条消息
channel . basic_publish (
exchange = "notifications" ,
routing_key = "" , # Fanout 忽略此字段
body = json . dumps ( notification ),
)
Headers Exchange(头交换器) :依据消息 header 属性(而非 routing key)进行路由。
RabbitMQ 消费者与确认机制# 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
import pika
import json
connection = pika . BlockingConnection (
pika . ConnectionParameters ( host = "rabbitmq.internal" )
)
channel = connection . channel ()
# 声明队列(幂等操作:若不存在则创建)
channel . queue_declare ( queue = "payment_queue" , durable = True )
def callback ( ch , method , properties , body ):
order = json . loads ( body )
try :
process_payment ( order )
# 确认成功处理
ch . basic_ack ( delivery_tag = method . delivery_tag )
except Exception as e :
logger . error ( f "支付失败: { e } " )
# 否定确认(negative acknowledge)→ 重新入队重试
ch . basic_nack ( delivery_tag = method . delivery_tag , requeue = True )
# 预取(Prefetch):最多同时发送 10 条未确认消息
channel . basic_qos ( prefetch_count = 10 )
channel . basic_consume (
queue = "payment_queue" ,
on_message_callback = callback ,
auto_ack = False , # 手动确认
)
channel . start_consuming ()
Kafka vs RabbitMQ 对比# 特性 Apache Kafka RabbitMQ 模型 分布式日志(只追加) 消息代理(基于队列) 消息保留 消费后仍保留(按时间/大小策略) 确认后即删除 消息顺序 每个分区(per-partition)内严格有序 每个队列(per-queue)内严格有序 吞吐量 极高(集群可达百万级/秒) 高(单节点可达数万级/秒) 路由灵活性 主题 + 分区键(partition key) Exchange、routing key、模式匹配 消费模型 拉取式(pull-based,消费者主动轮询) 推送式(push-based,Broker 主动投递) 消息重放 支持(可从任意 offset 重读) 不支持(确认后消息即销毁) 扩展方式 增加分区(水平扩展) 增加队列 + 消费者 协议 自定义二进制协议 AMQP 0-9-1 最佳适用场景 事件流、日志、高吞吐流水线 任务队列、复杂路由、请求-响应 最不适用场景 复杂路由逻辑 事件重放、超大规模吞吐
选择 Kafka 当你需要 :事件重放能力、超高吞吐、消费者组、流式处理。典型场景包括审计日志、点击流分析、变更数据捕获(CDC)、实时分析。
选择 RabbitMQ 当你需要 :复杂路由、消息级确认、优先级队列、传统任务分发。典型场景包括邮件发送、图像处理、订单履约、后台作业。
投递语义保障(Delivery Guarantees)# 消息投递语义是系统设计的根本决策之一。
最多一次(At-Most-Once)# 消息被投递零次或一次。若消费者在处理完成前崩溃,该消息即丢失。
实现方式:在处理前自动提交 offset(Kafka)或自动确认(RabbitMQ)。
1
2
3
4
# Kafka:处理前自动 commit
consumer = KafkaConsumer ( "orders" , enable_auto_commit = True )
for msg in consumer :
process ( msg ) # 若此处崩溃,offset 已提交 → 消息丢失
适用场景:允许消息丢失(如指标采集、日志,近似值即可接受)。
至少一次(At-Least-Once)# 消息被投递一次或多次。若消费者处理完成后崩溃但尚未 commit,该消息将被重复投递。
实现方式:仅在成功处理后才 commit offset 或发送确认。
1
2
3
4
5
# Kafka:手动 commit,处理后执行
consumer = KafkaConsumer ( "orders" , enable_auto_commit = False )
for msg in consumer :
process ( msg ) # 先处理
consumer . commit () # 再 commit。若 process 与 commit 之间崩溃,消息将被重投。
适用场景:可容忍重复(或使处理逻辑幂等)。这是最常用的选择。
恰好一次(Exactly-Once)# 消息被投递且仅被处理一次。这是最难实现的语义,通常需借助事务机制。
Kafka 在其生态内支持恰好一次语义(producer transaction + consumer read_committed 隔离级别)。但真正的端到端(end-to-end)恰好一次,要求消费者侧的副作用(如数据库写入、API 调用)也纳入同一事务 —— 这在实践中往往难以实现。
因此,绝大多数系统采用 至少一次投递 + 幂等处理 。若重复处理同一消息产生相同结果,则重复本身无害。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def process_order_idempotently ( order ):
"""幂等地处理订单,优雅应对重复消息"""
order_id = order [ "order_id" ]
# 幂等性检查:是否已处理?
if db . query ( "SELECT 1 FROM processed_orders WHERE id = %s " , order_id ):
logger . info ( f "订单 { order_id } 已处理,跳过" )
return
# 执行处理
db . execute (
"INSERT INTO processed_orders (id, status) VALUES ( %s , 'processing')" ,
order_id ,
)
payment_result = charge_payment ( order )
db . execute (
"UPDATE processed_orders SET status = 'completed' WHERE id = %s " ,
order_id ,
)
事件溯源(Event Sourcing)# 事件溯源是一种架构模式:不直接存储当前状态,而是将所有状态变更记录为一系列不可变事件;当前状态通过重放(replay)全部事件推导得出。
传统方式 vs 事件溯源# 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
传统方式(基于状态):
账户表:{ id : "acc_123" , balance : 150 . 00 }
存入 $ 50 : UPDATE accounts SET balance = 200 . 00 WHERE id = 'acc_123'
→ 原余额( 150 . 00 )丢失
事件溯源:
事件日志:
1 . AccountCreated { id : "acc_123" , initial_balance : 0 }
2 . Deposited { id : "acc_123" , amount : 100 . 00 }
3 . Deposited { id : "acc_123" , amount : 50 . 00 }
4 . Withdrawn { id : "acc_123" , amount : 30 . 00 }
5 . Deposited { id : "acc_123" , amount : 50 . 00 }
当前状态 = 重放所有事件 = $ 0 + $ 100 + $ 50 − $ 30 + $ 50 = $ 170 . 00
→ 完整的审计轨迹被永久保留
事件溯源的优势# 完整审计轨迹 :每次变更均被记录且不可篡改时间点查询(Temporal Queries) :例如,“昨天下午 3 点账户余额是多少?”事件重放 :可从头重建状态,或基于历史事件构建新的投影(projection)调试便利 :通过重放至故障点前的事件,可精准复现任意 Bug复杂性高 :需编写更多代码、部署更多基础设施、理解更多抽象概念存储开销 :事件日志持续增长(尽管压缩可缓解)最终一致性 :读模型(Read Model)是异步构建的投影,因此滞后于写操作Schema 演进困难 :事件格式变更需配套版本控制与迁移策略CQRS(命令查询职责分离)# CQRS 将写模型(Commands)与读模型(Queries)彻底分离。它天然适配事件溯源。
1
2
3
4
5
6
7
8
9
写侧(Command):
客户端 → 命令处理器 → 事件存储(Kafka)
“创建订单” → 校验 → 存储 OrderCreated 事件
读侧(Query):
事件存储 → 事件处理器 → 读数据库 → 客户端
OrderCreated 事件 → 更新反范式化视图 → 查询返回极快响应
写模型将事件持久化至可靠的事件存储(如 Kafka、EventStoreDB);读模型订阅事件流,并维护专为查询优化的反范式化视图(denormalized views)。不同读模型可针对不同查询模式定制 —— 搜索索引、报表数据库、实时仪表盘均可消费同一份事件流。
CQRS 的权衡# 优势 :读写可独立伸缩、查询模型高度优化、与事件溯源天然契合。
代价 :写模型与读模型间存在最终一致性、数据冗余、运维多个数据库带来的复杂性。
死信队列(Dead Letter Queues, DLQ)#
当一条消息经多次重试仍无法被成功处理时,不应无限阻塞队列。死信队列(DLQ)是一个专用队列,用于暂存这些失败消息以便人工排查。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# RabbitMQ DLQ 配置
channel . queue_declare (
queue = "orders" ,
durable = True ,
arguments = {
"x-dead-letter-exchange" : "dlx" ,
"x-dead-letter-routing-key" : "orders.dead" ,
"x-message-ttl" : 60000 , # 消息 60 秒后过期
},
)
# 死信队列
channel . queue_declare ( queue = "orders_dlq" , durable = True )
channel . queue_bind ( queue = "orders_dlq" , exchange = "dlx" , routing_key = "orders.dead" )
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 带重试与 DLQ 逻辑的消费者
MAX_RETRIES = 3
def callback ( ch , method , properties , body ):
retry_count = ( properties . headers or {}) . get ( "x-retry-count" , 0 )
try :
process_order ( json . loads ( body ))
ch . basic_ack ( delivery_tag = method . delivery_tag )
except Exception as e :
if retry_count < MAX_RETRIES :
# 重新发布,增加重试计数
ch . basic_publish (
exchange = "" ,
routing_key = "orders" ,
body = body ,
properties = pika . BasicProperties (
headers = { "x-retry-count" : retry_count + 1 },
delivery_mode = 2 , # 持久化
),
)
ch . basic_ack ( delivery_tag = method . delivery_tag )
else :
# 达到最大重试次数 → 通过 negative ack 发往 DLQ
logger . error ( f "消息经 { MAX_RETRIES } 次重试仍失败: { e } " )
ch . basic_nack ( delivery_tag = method . delivery_tag , requeue = False )
# RabbitMQ 会通过 dead letter exchange 自动路由至 DLQ
反压(Backpressure)# 当消费者处理速度跟不上生产者发送速度时,即发生反压。若不加以控制,队列将无限增长,内存耗尽,最终导致系统崩溃。
反压应对策略# 生产者限流(Producer Throttling) :当队列深度超过阈值时,生产者主动降速。
1
2
3
4
5
6
7
8
9
10
MAX_QUEUE_DEPTH = 100000
def produce_with_backpressure ( producer , topic , message ):
# 通过 Kafka Admin API 或监控系统获取队列积压量(lag)
lag = get_consumer_lag ( topic )
if lag > MAX_QUEUE_DEPTH :
logger . warning ( f "消费者积压 { lag } 超过阈值,对生产者限流" )
time . sleep ( 1 ) # 简单限流
producer . send ( topic , message )
消费者扩容(Consumer Scaling) :当 lag 上升时,动态增加消费者实例数。在 Kafka 中,消费者数量上限为分区数。
消息丢弃(Message Dropping) :系统过载时,丢弃低优先级消息。可使用优先级队列,优先丢弃最低优先级消息。
有界队列(Bounded Queues) :设定队列最大容量。当队列满时,可选择阻塞生产者(同步反压)或拒绝新消息(负载削峰)。
实战案例:订单处理流水线# 以下是一个完整的事件驱动式订单处理系统。
架构概览# 系统按如下阶段处理订单:
订单服务(Order Service) :接收用户订单,校验有效性,发布 OrderCreated 事件支付服务(Payment Service) :消费 OrderCreated,完成扣款,发布 PaymentCompleted 或 PaymentFailed库存服务(Inventory Service) :消费 PaymentCompleted,锁定库存,发布 InventoryReserved 或 OutOfStock通知服务(Notification Service) :消费所有相关事件,向用户发送邮件/推送通知分析服务(Analytics Service) :消费所有事件,更新仪表盘与业务报表数据流向:
1
2
3
4
5
6
7
8
用户下单
→ 订单服务校验并发布至 Kafka 主题 "orders"
→ 支付服务从 "orders" 读取,执行支付
→ 发布至 "payments" 主题
→ 库存服务从 "payments" 读取,锁定库存
→ 发布至 "inventory" 主题
→ 通知服务从 "payments" 读取,发送收据邮件
→ 分析服务从 "orders" 读取,更新指标
实现代码# 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# order_service.py — 接收并校验订单
from kafka import KafkaProducer
import json
import uuid
from datetime import datetime
producer = KafkaProducer (
bootstrap_servers = [ "kafka:9092" ],
value_serializer = lambda v : json . dumps ( v ) . encode (),
key_serializer = lambda k : k . encode (),
acks = "all" ,
)
def create_order ( user_id : str , items : list ) -> dict :
order_id = str ( uuid . uuid4 ())
# 校验订单
if not items :
raise ValueError ( "订单至少需包含一项商品" )
total = sum ( item [ "price" ] * item [ "quantity" ] for item in items )
# 构造订单事件
event = {
"event_type" : "OrderCreated" ,
"order_id" : order_id ,
"user_id" : user_id ,
"items" : items ,
"total" : total ,
"currency" : "USD" ,
"timestamp" : datetime . utcnow () . isoformat (),
}
# 发布至 Kafka(key = user_id,确保用户维度有序)
producer . send ( "orders" , key = user_id , value = event )
producer . flush ()
return { "order_id" : order_id , "status" : "accepted" }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
# payment_service.py — 处理支付
from kafka import KafkaConsumer , KafkaProducer
import json
consumer = KafkaConsumer (
"orders" ,
bootstrap_servers = [ "kafka:9092" ],
group_id = "payment-service" ,
value_deserializer = lambda m : json . loads ( m . decode ()),
enable_auto_commit = False ,
auto_offset_reset = "earliest" ,
)
producer = KafkaProducer (
bootstrap_servers = [ "kafka:9092" ],
value_serializer = lambda v : json . dumps ( v ) . encode (),
key_serializer = lambda k : k . encode (),
acks = "all" ,
)
def run ():
for message in consumer :
event = message . value
if event [ "event_type" ] != "OrderCreated" :
consumer . commit ()
continue
order_id = event [ "order_id" ]
user_id = event [ "user_id" ]
# 幂等性检查
if is_already_processed ( order_id ):
consumer . commit ()
continue
try :
# 向支付网关发起扣款
charge_result = payment_gateway . charge (
user_id = user_id ,
amount = event [ "total" ],
currency = event [ "currency" ],
idempotency_key = order_id ,
)
# 发布成功事件
producer . send ( "payments" , key = user_id , value = {
"event_type" : "PaymentCompleted" ,
"order_id" : order_id ,
"user_id" : user_id ,
"payment_id" : charge_result [ "payment_id" ],
"amount" : event [ "total" ],
"timestamp" : datetime . utcnow () . isoformat (),
})
mark_as_processed ( order_id , "completed" )
except PaymentFailedError as e :
# 发布失败事件
producer . send ( "payments" , key = user_id , value = {
"event_type" : "PaymentFailed" ,
"order_id" : order_id ,
"user_id" : user_id ,
"reason" : str ( e ),
"timestamp" : datetime . utcnow () . isoformat (),
})
mark_as_processed ( order_id , "failed" )
producer . flush ()
consumer . commit ()
故障处理机制# 该流水线在各环节均具备容错能力:
支付失败 :PaymentFailed 事件触发向用户发送通知,订单状态设为 "payment_failed",且不锁定库存。库存不足 :OutOfStock 事件触发支付退款(补偿事务)及用户通知。消费者崩溃 :至少一次投递保障消息被重试;幂等性检查防止重复扣款。Kafka Broker 故障 :副本因子(replication factor)设为 3,确保零数据丢失;客户端自动重连存活 Broker。监控指标# 1
2
3
4
5
6
7
8
# 每个消费者需重点监控的关键指标
metrics = {
"consumer_lag" : "分区落后消息数" ,
"processing_rate" : "每秒处理消息数" ,
"error_rate" : "每秒失败消息数" ,
"processing_latency_p99" : "处理延迟 99 分位数" ,
"dlq_size" : "死信队列中消息数" ,
}
消费者积压(consumer lag)是最关键指标 :若 lag 持续上升,说明消费者处理不及;若 lag 稳定,说明系统负载均衡;若 lag 下降,说明消费者正在追赶此前的流量高峰。
下一步# 消息队列解耦了各个服务,但一个更根本的问题是:究竟该如何界定“一个服务”的边界? 下一篇文章将坦诚探讨单体架构与微服务之争——微服务何时真正带来收益、何时反而成为负担,以及如何运用领域驱动设计(DDD)科学地划分服务边界。