在设计 Agent 系统架构时,最关键的是确定 Agent 循环进程的运行位置。阿里云提供了三种主流方案及一个常被忽略的 ECI 方案。虽然选错方案不会导致系统崩溃(后续仍可迁移),但可能会多花几周时间搭建基础设施,并且每月浪费数千元算力。
本文将逐一分析这四种模式,并附带可直接运行的 Terraform 代码、成本拐点估算及实际运维中的典型问题。
四种模式#
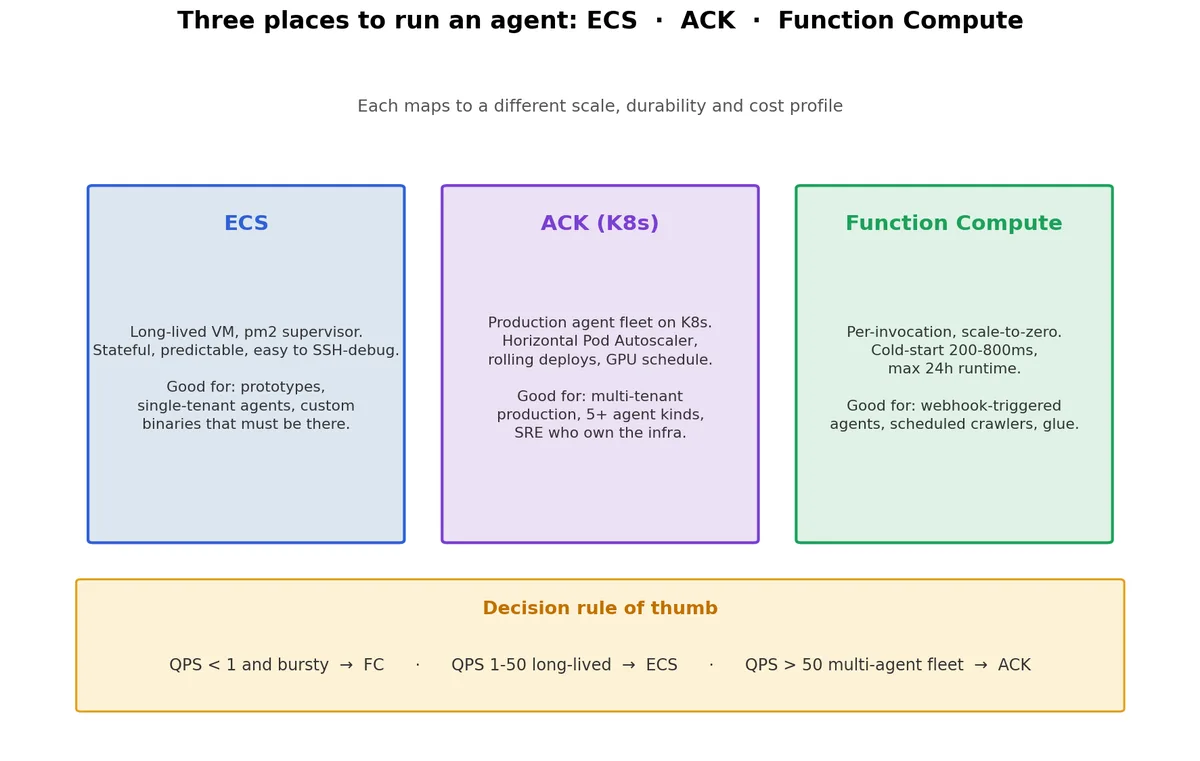

每种方案都有其优势:
- ECS 是 Linux 虚拟机,长期运行、有状态,调试时可通过 SSH 直接登录,非常方便,适合原型、单租户 Agent 或需要让机器“热着”缓存模型或本地状态的场景。
- ACK(容器服务 Kubernetes 版)是规模化生产的理想选择,支持多种 Agent、自动伸缩、滚动发布和 GPU 调度。只有同时运行三个以上 Agent 服务且团队中有熟悉 Kubernetes 的 SRE 时,才建议采用 ACK 方案。
- Function Compute (FC) 按次调用,缩容到零,冷启动时间为 200-800ms,单次调用硬上限为 24 小时,适用于 webhook 触发的 Agent、定时爬虫及突发性运行、其余时间空闲的任务。
- Elastic Container Instance (ECI) 是容易被忽略的方案,没有底层节点的容器,冷启动约需 5 秒,按实际运行秒数计费,无需管理节点池,最适合突发性批处理任务,每次运行 2-30 分钟,每小时运行几次。
前三种方案已覆盖大多数场景,而 ECI 则恰好填补了 FC 运行时长受限与 ECS 在突发性负载下资源闲置之间的空白。
成本交叉点#
以下是基于持续 QPS 的大致月度成本概况:

持续 QPS 低于 ~1 时,FC 占优,空闲时几乎不花钱;~1 到 ~30 之间,单台 ECS 更合适。超过这个值,ACK 的较高固定成本会被足够负载分摊,比硬塞到 ECS 上更便宜。ECI 的特殊之处在于:利用率低于 50% 时比 ECS 便宜,高于 50% 则更贵。
该成本模型较为粗略,实际费用会受实例规格、网络类型和 Agent 通信频率等因素影响,但整体成本变化趋势是可信的。我的决策规则如下:
突发流量 + 平均负载低 → Function Compute
稳态 + 中低负载 → ECS 配 pm2
多 Agent + 持续中高负载 → ACK
突发批处理,单次 2-30 分钟 → ECI
架构方案已明确,接下来将逐一详解四种模式及其对应的 Terraform 实现。
模式 1:使用 pm2 的 ECS#
80% 的 Agent 项目选择该方案即可。 ALB 后面挂一两台 ECS,每台跑个 pm2 作为 Python 或 Node Agent 进程的守护器。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| data "alicloud_images" "ubuntu" {
owners = "system"
name_regex = "^ubuntu_22_04_x64.*"
most_recent = true
}
data "alicloud_instance_types" "agent" {
cpu_core_count = 4
memory_size = 16
availability_zone = "cn-shanghai-l"
instance_type_family = "ecs.c7"
}
resource "alicloud_instance" "agent" {
count = var.agent_count
instance_name = "agent-${terraform.workspace}-${count.index + 1}"
image_id = data.alicloud_images.ubuntu.images[0].id
instance_type = data.alicloud_instance_types.agent.instance_types[0].id
availability_zone = "cn-shanghai-l"
vswitch_id = module.vpc.private_vswitch_ids[count.index % 3]
security_groups = [module.vpc.agent_runtime_sg_id]
system_disk_category = "cloud_essd"
system_disk_size = 80
system_disk_encrypted = true
system_disk_kms_key_id = module.vpc.kms_keys["memory"]
user_data = base64encode(templatefile("${path.module}/cloud-init.sh", {
repo_url = var.agent_repo_url
branch = var.agent_branch
gateway_url = "http://${alicloud_alb_listener.gateway.id}.alb.aliyuncs.com"
sls_project = alicloud_log_project.agents.name
sls_logstore = alicloud_log_store.agent_runs.name
role_name = alicloud_ram_role.agent.name
region = "cn-shanghai"
}))
tags = {
Role = "agent-runtime"
App = "research-agent"
}
lifecycle {
create_before_destroy = true
ignore_changes = [user_data] # don't replace on every cloud-init bump
}
}
|
三点值得注意:
data 块用来选镜像和实例类型,而不是写死。ubuntu_22_04_x64 会解析到最新 patched 镜像;data.alicloud_instance_types.agent 会找到 4 vCPU 16 GiB 的 ecs.c7。当阿里云废弃某个镜像 SKU 时,下次 plan 会自动选新的。写死 ecs.c7.xlarge 直到该 SKU 在你可用区缺货前都能用,那时 Terraform 就会报错,由 data source 自动选择可用镜像,可实现平滑降级。system_disk_kms_key_id 把磁盘绑定到第 3 篇文章里的 memory CMK 上。静态加密不额外花钱,还省去了一堆合规麻烦。lifecycle { create_before_destroy = true } 意味着计划替换时会先创建新实例,挂到 ALB,排空旧实例,再销毁,零停机轮换。代价是短暂需要 2 倍容量,两台实例的集群没问题,到了 50 台就开始肉疼了。
真正能存活的 cloud-init#
大多数博客展示的 cloud-init 都是理想路径:apt-get install, git clone, pm2 start, 完事。此类 cloud-init 示例仅适用于演示环境。生产环境的初始化流程还需应对六类典型问题: DNS 解析竞争、公共软件源响应延迟、基于 RAM 的临时凭证存在时序依赖、启动盘快照可能意外暴露敏感信息、 root 用户与服务账户需严格权限隔离,以及 ALB 健康检查对初始化完成状态的依赖。
这是我实际运行的版本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| #!/bin/bash
set -euxo pipefail
# 1. Wait for network — DNS isn't always ready when cloud-init starts
for i in {1..30}; do
curl -sf https://mirrors.aliyun.com/ -o /dev/null && break
sleep 2
done
# 2. Use Aliyun apt mirror — public Ubuntu mirrors are painfully slow from cn-shanghai
sed -i 's|http://.*\.ubuntu\.com|http://mirrors.aliyun.com|g' /etc/apt/sources.list
apt-get update -y
apt-get install -y python3.11 python3.11-venv git curl ca-certificates jq nodejs npm
npm install -g pm2 uv
# 3. Fetch instance-role credentials from metadata BEFORE any tool that needs them
TOKEN_URL="http://100.100.100.200/latest/meta-data/ram/security-credentials/${role_name}"
TOKEN_JSON=$(curl -s --max-time 5 "$TOKEN_URL")
export ALICLOUD_ACCESS_KEY_ID=$(echo $TOKEN_JSON | jq -r .AccessKeyId)
export ALICLOUD_ACCESS_KEY_SECRET=$(echo $TOKEN_JSON | jq -r .AccessKeySecret)
export ALICLOUD_SECURITY_TOKEN=$(echo $TOKEN_JSON | jq -r .SecurityToken)
# 4. Pull secrets from KMS into tmpfs — they never hit disk, never appear in snapshots
mkdir -p /run/agent
mount -t tmpfs -o size=64M tmpfs /run/agent
python3 - <<'PY'
import os
from alibabacloud_kms20160120.client import Client as KmsClient
from alibabacloud_tea_openapi.models import Config
client = KmsClient(Config(
region_id='${region}',
access_key_id=os.environ['ALICLOUD_ACCESS_KEY_ID'],
access_key_secret=os.environ['ALICLOUD_ACCESS_KEY_SECRET'],
security_token=os.environ['ALICLOUD_SECURITY_TOKEN'],
))
for name in ['rds-password', 'litellm-master-key']:
resp = client.get_secret_value(...)
open(f'/run/agent/{name}', 'w').write(resp.body.secret_data)
PY
chmod 600 /run/agent/*
# 5. Clone the agent runtime, install deps with uv (10x faster than pip)
mkdir -p /opt/agent && cd /opt/agent
git clone --depth 1 -b ${branch} ${repo_url} src
cd src && uv venv .venv && uv pip sync requirements.txt
cat > /opt/agent/src/.env <<EOF
LLM_GATEWAY_URL=${gateway_url}
SLS_PROJECT=${sls_project}
SLS_LOGSTORE=${sls_logstore}
EOF
# 6. Run as a non-root service account, not root
useradd -r -s /bin/false agent || true
chown -R agent:agent /opt/agent /run/agent
# 7. Bootstrap-done marker for the ALB health check to gate on
sudo -u agent pm2 start ecosystem.config.js
sudo -u agent pm2 save
echo "$(date -Iseconds)" > /run/agent/bootstrap-done
|
流程如下:

从 apply 到 pm2 status 显示 agent 为 online 大约 90 秒。第一次 apt-get install 最慢(~60s)。一旦获得稳定镜像,即可使用 Packer 打包,后续 ECS 实例便能跳过 apt 更新,启动时间缩短至约 25 秒。
实战建议: user_data 会记录在实例的 /var/log/cloud-init-output.log。 Agent 起不来时,先看这儿。开头的 set -euxo pipefail 让失败大声且可追踪,没它我曾花两小时调试一个静默失败的 pip install,结果发现是缺了 gcc。
模式 2:用于生产环境的 ACK#
一旦你有三种以上 Agent 并行运行,单 VM 的运维成本就占主导了, ECS 扩展性到头。 ACK 给你一个集群、一个调度器、一条升级路径,还有一个地方接自动伸缩和可观测性。

在阿里云上搞一个托管 K8s 集群的最小 Terraform 代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| resource "alicloud_cs_managed_kubernetes" "agents" {
name_prefix = "agents-${terraform.workspace}"
version = "1.30.1-aliyun.1"
cluster_spec = "ack.pro.small"
vpc_id = module.vpc.vpc_id
worker_vswitch_ids = module.vpc.private_vswitch_ids
pod_vswitch_ids = module.vpc.private_vswitch_ids
service_cidr = "172.21.0.0/20"
proxy_mode = "ipvs"
load_balancer_spec = "slb.s2.small"
enable_ssh = false
delete_protection = true
control_plane_log_components = ["apiserver", "audit"]
addons { name = "managed-arms-prometheus" }
addons { name = "logtail-ds" }
}
resource "alicloud_cs_kubernetes_node_pool" "agents" {
cluster_id = alicloud_cs_managed_kubernetes.agents.id
node_pool_name = "agent-workers"
vswitch_ids = module.vpc.private_vswitch_ids
instance_types = ["ecs.c7.xlarge"]
desired_size = 3
system_disk_category = "cloud_essd"
system_disk_size = 80
install_cloud_monitor = true
scaling_config {
enable = true
min_size = 2
max_size = 10
}
}
|
几点说明:
ack.pro.small 是托管控制平面 SKU。阿里云跑 master 节点;你只为 worker ECS 付费,控制平面每月约¥350,不含节点成本。除非有强理由,别选非托管 SKU。pod_vswitch_ids 是给 Terway 用的,阿里云原生 CNI。每个 Pod 拿到真实 VPC IP,没有 overlay 网络,安全组直接生效。这是默认正解; Flannel 会让网络调试变成噩梦。delete_protection = true 顾名思义,terraform destroy 杀不掉集群。每个生产集群都要设这个。addons 块 启用 ARMS Prometheus (第 7 篇)和 SLS 日志收集器。通过 Terraform 部署 意味着新集群自带监控 instrumentation。
真正的 Agent Pod 来自 Kubernetes Deployment manifest,通常由单独的 kubectl 步骤或 kubernetes Terraform provider 应用。我把集群放在这个 terraform 项目里,工作负载放在单独的 Helm chart 里,因为它们发布节奏不同。集群一季度变一次; Agent 镜像一天变十次。
模式 3:用于事件驱动代理的 Function Compute#
有些 Agent 不用常驻,有事才动,例如 webhook 触发、定时任务或 OSS 文件上传。这种情况下, FC (函数计算)几乎是完美的选择:闲置零成本,自动弹性,运行时全托管。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| resource "alicloud_fc_service" "agent" {
name = "agent-${terraform.workspace}"
description = "Event-triggered agent functions"
log_config {
project = alicloud_log_project.agents.name
logstore = alicloud_log_store.agent_runs.name
}
vpc_config {
vswitch_ids = module.vpc.private_vswitch_ids
security_group_id = module.vpc.agent_runtime_sg_id
}
role = alicloud_ram_role.fc_agent.arn
internet_access = false
}
resource "alicloud_fc_function" "scheduled_research" {
service = alicloud_fc_service.agent.name
name = "scheduled-research"
description = "Daily research agent run"
filename = "${path.module}/dist/scheduled-research.zip"
handler = "index.handler"
runtime = "python3.11"
memory_size = 1024
timeout = 600
ca_port = 8080
environment_variables = {
LLM_GATEWAY_URL = "http://${alicloud_alb_listener.gateway.id}.alb.aliyuncs.com"
}
}
resource "alicloud_fc_trigger" "daily" {
service = alicloud_fc_service.agent.name
function = alicloud_fc_function.scheduled_research.name
name = "daily-9am"
type = "timer"
config = jsonencode({
cronExpression = "0 0 9 * * *"
enable = true
payload = "{}"
})
}
|
这套配置下来: Python 3.11 环境, 1 GiB 内存, 10 分钟超时,跟栈里其他资源共用 VPC 和安全组,每天早上 9 点准时触发。不用维护服务器。成本大概每次调用 0.10 元,加上每 GB-秒 0.0001 元。每天跑 5 分钟的定时任务,一个月大概 3 块钱。同样的 Agent 要是跑在闲置的 ECS 上,一个月得 250 块左右。
有三个坑我踩过好几次:
- Cold start. 闲置后的第一次调用会比后面慢 200-800ms。对亚秒级 SLA 的 webhook 来说这是个问题;对定时任务无所谓。预留实例能解决,但那就违背了 FC 的初衷,既然都要 24/7 付费养着 warm 实例,不如直接上 ECS。
- VPC attachment 会让冷启动再慢 200-400ms,因为 FC 得给你的 VPC 挂 ENI。如果函数要走内网访问 RDS 或 OpenSearch,这代价值得;如果只调公网 API,直接把
vpc_config 块删了。 - 24-hour max runtime. 长循环任务不适合 FC。要么把循环拆成短步骤(步骤间状态存 OSS 或 Redis),要么迁移到 ECS/ECI。
这第三个坑,正好是 ECI 填补的空缺。
模式 4:用于突发批量代理的 ECI#
ECS、 ACK 和 FC 覆盖了大部分场景,但针对突发批量 Agent 任务,还有第四种模式:弹性容器实例(ECI)。 ECI 就像是“底层没有 Kubernetes 节点的容器”,阿里云直接在他们管理的裸金属集群上跑容器,你只为运行秒数付费。
场景很明确。你有个 Agent 每次运行 2-30 分钟,每小时跑几次,经常并行。 FC 上限 24 小时但冷启动对批量任务不友好; ECS 浪费(突发间隙都在付费闲置); ACK 又多了 K8s overhead。 ECI 卡在中间:冷启动约 5s,无闲置成本,不用管节点池。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| resource "alicloud_eci_container_group" "research_batch" {
container_group_name = "research-batch-${formatdate("YYYYMMDDhhmm", timestamp())}"
security_group_id = module.vpc.agent_runtime_sg_id
vswitch_id = module.vpc.private_vswitch_ids[0]
cpu = 4
memory = 16
restart_policy = "OnFailure"
ram_role_name = alicloud_ram_role.agent_eci.name
containers {
name = "research"
image = "registry-vpc.cn-shanghai.aliyuncs.com/agents/research:${var.image_tag}"
image_pull_policy = "IfNotPresent"
cpu = 4
memory = 16
commands = ["python", "-m", "research_agent"]
args = ["--session-id", var.session_id]
environment_vars {
key = "LLM_GATEWAY_URL"
value = module.gateway.url
}
volume_mounts {
name = "scratch"
mount_path = "/scratch"
}
}
volumes {
name = "scratch"
type = "EmptyDirVolume"
}
image_registry_credential {
server = "registry-vpc.cn-shanghai.aliyuncs.com"
user_name = "agent-puller"
password = data.alicloud_kms_secret.acr_pull.secret_data
}
lifecycle {
create_before_destroy = false # ECI is single-shot
ignore_changes = [container_group_name] # timestamp-suffixed name drifts
}
}
|
生产环境踩过的坑:
- 镜像仓库必须用
registry-vpc endpoint,别用公网的。公网走 NAT 要收流量费; VPC endpoint 免费且更快。我有次没注意,一周烧了 200 块流量费。 restart_policy = "OnFailure" 别设成 "Always"。 ECI 设计就是一次性的;设成 "Always" 成功了他也重启,跟批量任务的需求正好相反。EmptyDirVolume 是容器组级别的临时存储,跟 Kubernetes 的 emptyDir 一样。别在这存不可复现的东西,输出写 OSS 或 RDS。ram_role_name 让容器能从实例元数据获取凭证,跟 ECS 模式一样。环境变量里别放 AK/SK。
alicloud_eci_container_group 资源有个烦人的毛病:改 containers[*] 不一定触发干净的重建,因为 API 部分是 merge 机制。生产环境的批量任务,我用 Terraform 部署 一次容器组,运行时规格用 ignore_changes 忽略,然后由 orchestrator 直接调 ECI API 触发新运行,复用 Terraform 配好的 role 和 SG。把 Terraform 这边当作模板,而不是执行器。
成本粗算: 4 vCPU / 16 GB 的 ECI 大概 0.96 元/小时,按秒计费,最低 1 分钟。跑 8 分钟的研究任务大概 0.13 元。每天 100 次 = 13 元/天 = 390 元/月。同样的负载要是跑在常驻 ECS 上,闲置也得 250-400 元/月。利用率低于 50% 选 ECI;高于这个数, ECS 或 ACK 更划算。
实际案例:混合模式#
我交付过的生产级 Agent 栈,最后基本都是混合架构:
- ECS 跑常驻对话 Agent,内存里持 session 状态
- ACK 跑 worker 集群,处理三四种不同 Agent 的后台任务
- FC 接 webhook 和日常定时任务
- ECI 跑那些耗时 5-20 分钟、一天跑几十次的批量任务
Terraform 让这事变得很简单,同一个项目里四个 module,共用第 3 篇文章里的 VPC 和安全组。关键技能是知道哪种负载配哪种模式,而不是背熟所有资源语法。
选择合适的实例大小#
经常有人问: Agent 运行时选哪个 ecs.* 系列?我的默认配置:
| 工作负载 | 实例族 | 原因 |
|---|
| 会话代理,无 GPU | ecs.c7 | 令牌化 + LLM 调用的 I/O 导致 CPU 限制 |
| 内存密集型(大上下文) | ecs.r7 | 每 vCPU 更多内存 |
| 批处理/计划任务,有突发流量 | ecs.c7a (AMD) | 约便宜 15%,每核心稍慢 |
| 小模型的 GPU 推理 | ecs.gn7i | T4 级别,阿里云上最便宜的 GPU |
| 预训练/大规模微调 | 使用 PAI-DLC,而非 ECS | 不要重复造轮子 |
别选突发型 ecs.t6 系列跑 Agent 运行时,持续负载下 CPU 积分耗尽,延迟直接崩盘。拿来跑 terraform apply 的堡垒机倒是没问题。
当 alicloud_pai_* 不存在时(及其回退方案)#
如果你要交付一个自己做训练或托管定制 LLM 的 Agent,第一反应肯定是用 Terraform 起 PAI-EAS。现实情况是:截至 alicloud provider 1.230 版本, PAI 资源覆盖还很薄。只有 alicloud_pai_workspace 和几个相关资源,完整的 EAS 服务部署不是一等公民,没有 alicloud_pai_eas_service 能让你在 HCL 里声明式地定义模型服务 endpoint。
我用的实际 fallback 方案,按优先级排序:
Fallback 1: provision the workspace, run EAS via API. Terraform 管 workspace 和 IAM;命令式工具(eascmd 或 EAS Python SDK)管运行时规格。
1
2
3
4
5
6
7
8
9
10
| resource "alicloud_pai_workspace" "agents" {
workspace_name = "agents-${terraform.workspace}"
description = "PAI workspace for agent inference"
env_types = ["prod"]
display_name = "Agents"
}
output "pai_workspace_id" {
value = alicloud_pai_workspace.agents.id
}
|
Makefile target 接着调 eascmd create eas-service.json, JSON 里填镜像、 processor、实例类型和弹性配置。这就很诚实:稳定底层用声明式,变动运行时用命令式。
Fallback 2: ROS for the EAS bits. ROS (阿里云原生 IaC)往往比 Terraform provider 更早支持某些资源。可以通过 alicloud_ros_stack 从 Terraform 调用 ROS:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| resource "alicloud_ros_stack" "eas_serving" {
stack_name = "eas-serving-${terraform.workspace}"
template_body = file("${path.module}/eas-service.ros.json")
parameters {
parameter_key = "WorkspaceId"
parameter_value = alicloud_pai_workspace.agents.id
}
parameters {
parameter_key = "ImageUrl"
parameter_value = "registry-vpc.cn-shanghai.aliyuncs.com/agents/qwen-server:${var.model_version}"
}
timeout_in_minutes = 30
}
|
eas-service.ros.json 是 ROS 模板,阿里云版的 CloudFormation,暴露了 alicloud Terraform provider 还没有的 EAS 属性。 Terraform 管栈, ROS 管深层云资源,你在一个 terraform plan 里就能看完所有变更。
Fallback 3: write your own provider. 别干。我试过一回,两周的 Go 工作量,结果一个月后官方 provider 发布了我需要的资源,我还得永远维护一个 fork。阿里云团队每月都在发新的 alicloud provider 资源;你最好等他们跟上,别自己背债。
任何"Terraform 还没有”的情况,通用原则是:Terraform 管稳定底层,轻量工具管变动部分。 RAM 角色、 VPC、 KMS、 OSS,交给 Terraform。全新资源、 beta API,null_resource + local-exec,嵌入 ROS,或者单独 orchestrator。等 provider 跟上了,再用 terraform import 把 null_resource 块迁移成正式资源。
实战建议: alicloud_ros_stack 真的被低估了。当 alicloud Terraform provider 滞后时, ROS 往往领先四分之一季度。在 Terraform 里嵌入 ROS 模板,能两头吃香。
下一步#
第 5 篇文章补充存储层,向量库、关系型数据库、对象存储、备份,也就是我们刚才 部署 的所有东西需要连接的地方。 ECS 实例、 ACK Pod、 FC 函数和 ECI 容器,直到有了存放记忆的地方,否则都是无用之功。
然后第 6 篇在所有计算资源前构建 LLM 网关,第 7 篇接入可观测性和成本告警,第 8 篇把所有东西缝合成一个 terraform apply。



