
时间序列模型(一):传统统计模型
从一个统一的状态空间视角推导 ARIMA、SARIMA、VAR、GARCH、Prophet、指数平滑与卡尔曼滤波,配合 Box-Jenkins 工作流、ACF/PACF 识别与可运行的 Python 代码。
我第一次拿到一份"看起来像时间序列"的数据,是一份每小时的服务器 CPU 使用率。直觉告诉我应该可以用线性回归——把时间当作 x 轴,使用率当作 y 轴。我试了,效果一塌糊涂。问题不在于回归本身,而在于这种数据有自己的脾气:它有趋势、有周期、还有上一时刻对下一时刻挥之不去的影响。普通的回归把每个观测都当作独立样本,恰恰把"时间"这层信息扔掉了。
时间序列模型存在的意义就是把这层信息找回来。它不假装样本独立,而是直接建模"今天的值大概率长得像昨天"这件事。比如温度记录——今天 20°C,明天大概也在 18-22°C 之间,绝不会突变成 5°C。又比如股票价格——今天的价格 = 昨天的价格 + 一个小扰动,扰动本身才是随机的。这两类数据看起来都是一条曲线,但内在的"记忆结构"完全不同:温度是回归到均值,股价是随机游走。区分这两种结构,正是 ARIMA、GARCH 这一整套经典工具想做的事。
本章我会带你走一遍这套传统武器库。重点不是把每个公式背下来,而是建立一种判断力:拿到一份新数据,应该先看 ACF/PACF 还是先做差分?看到拖尾应该选 AR 还是 ARMA?什么时候经典模型已经够用,什么时候必须升级到深度学习?这些问题没有一个固定答案,但有一套可复用的诊断流程,下面我会一步步把它拆开。

本文要点#
- 平稳性是 ARIMA 家族的入场券,而差分正是获取它的核心手段。
- 学会像 Box-Jenkins 专家一样解读 ACF 和 PACF 图:通过“截尾”与“拖尾”的模式来判断 $p$ 和 $q$ 。
- 掌握完整的 ARIMA / SARIMA 框架,尤其是如何通过滞后-$s$ 算子将季节性融入模型。
- 将 VAR、GARCH、指数平滑、Prophet 和卡尔曼滤波 放在同一张图谱上理解——它们分别聚焦于均值动态、方差动态和状态空间递推。
- 明确一个决策准则:何时传统模型已足够,何时应转向本系列后续介绍的深度学习模型。
前置知识#
- 掌握基本的概率统计概念,如均值、方差、协方差和相关系数。
- 熟悉 NumPy 和
pandas的时间索引操作。 - VAR 与卡尔曼滤波部分涉及少量线性代数知识,主要是矩阵乘法和特征值。
为什么传统模型依然重要#
在深度学习时代来临之前,时间序列分析的工具箱其实已经相当完备:ARIMA 能有效捕捉线性自相关结构,SARIMA 引入了日历效应,VAR 将模型推广到多变量场景,GARCH 专门建模波动率,而卡尔曼滤波则通过状态空间框架将这些方法统一起来。这些传统模型具备三个深度模型难以免费提供的优势:
- 可解释性强:每个参数都有明确含义——例如“昨天的水平以权重 $\phi_1$ 影响今天”,“两个月前的冲击以权重 $\theta_2$ 衰减”。
- 不确定性校准可靠:置信区间直接来自极大似然估计,而非依赖 Dropout 等临时技巧。
- 样本效率高:仅需几百个观测点即可有效建模,完全无需 GPU。
如果你的数据序列较短、趋势平滑,或具有清晰的日历结构(如周/月周期),传统模型往往能轻松胜过 LSTM,并且调试起来也直观得多。因此,请将本文所述方法视为必须超越的基线——在尝试更复杂的模型前,先确保你能击败它。
分解视角#
$$y_t = T_t + S_t + R_t,$$其中 $T_t$ 是缓慢变化的趋势,$S_t$ 是周期为 $s$ 的季节性成分,而 $R_t$ 是去除结构后应接近白噪声的残差。经典的加法分解正是这一思想的具体实现。
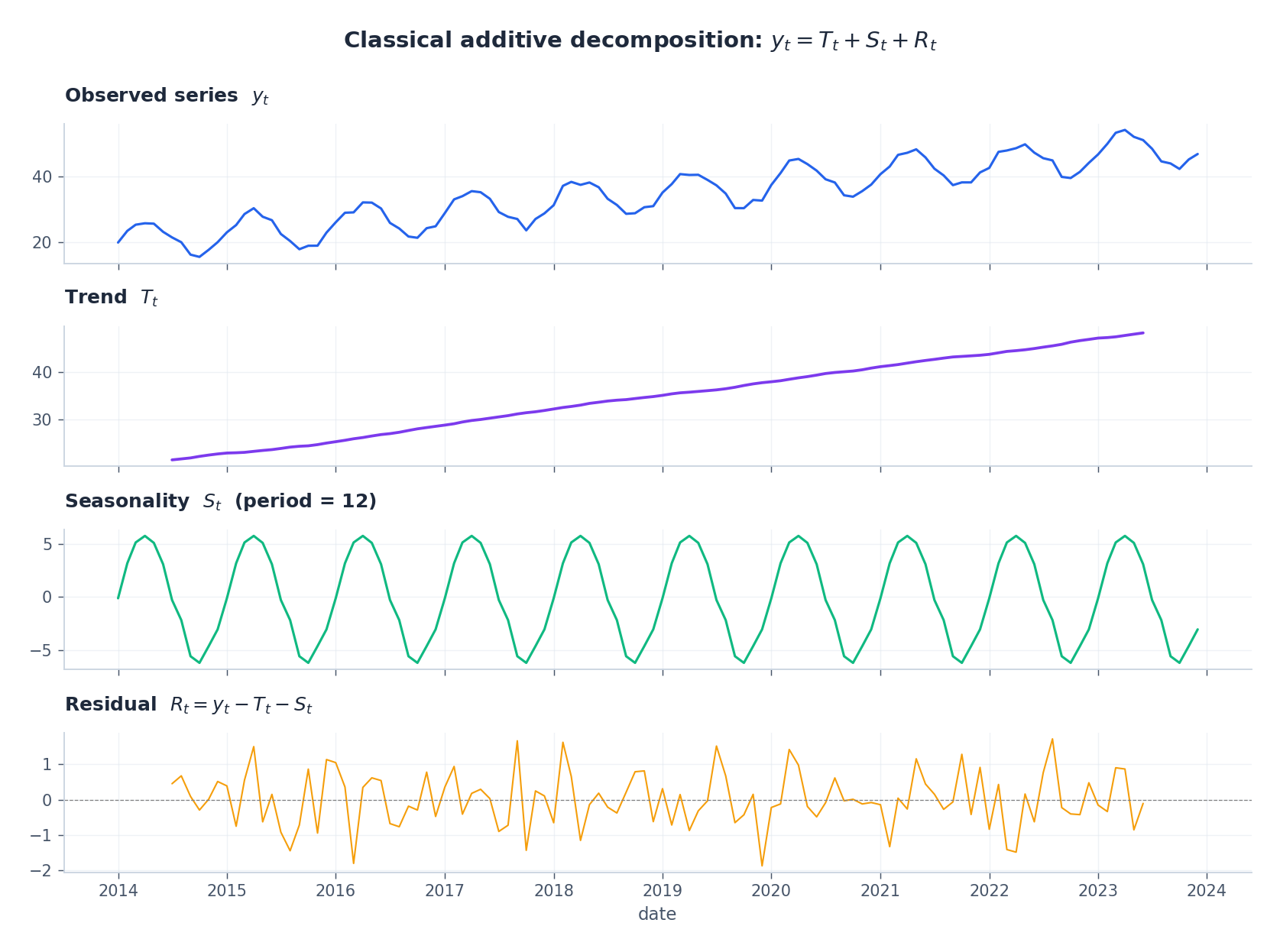
整个 ARIMA 方法论可以用一句话概括:对数据进行变换,直到剩余部分呈现平稳性,然后用带自相关误差的线性模型拟合。
平稳性的形式定义#
$$\mathbb{E}[y_t] = \mu, \qquad \mathrm{Var}(y_t) = \sigma^2, \qquad \mathrm{Cov}(y_t, y_{t-k}) = \gamma_k.$$然而,现实中的大多数序列并不平稳——它们可能呈现趋势、漂移,或方差随水平增长。对此,标准的应对策略有两种:
- 差分:$\nabla y_t = y_t - y_{t-1}$ 可消除线性趋势;$\nabla^2 y_t$ 则可处理二次趋势。
- 方差稳定化变换:如 $\log y_t$ 或 Box-Cox 变换,能有效抑制乘性增长。
增广 Dickey-Fuller(ADF)检验提供了一种假设检验方法:原假设 $H_0$ 为“存在单位根”。若 $p$ 值足够小,便可认为(变换后的)序列是平稳的。
AR、MA 和 ARMA —— 三种记忆机制#
ARIMA 模型由两个基本构件组成。它们形式相似,但对“序列记住了什么”有着截然不同的诠释。
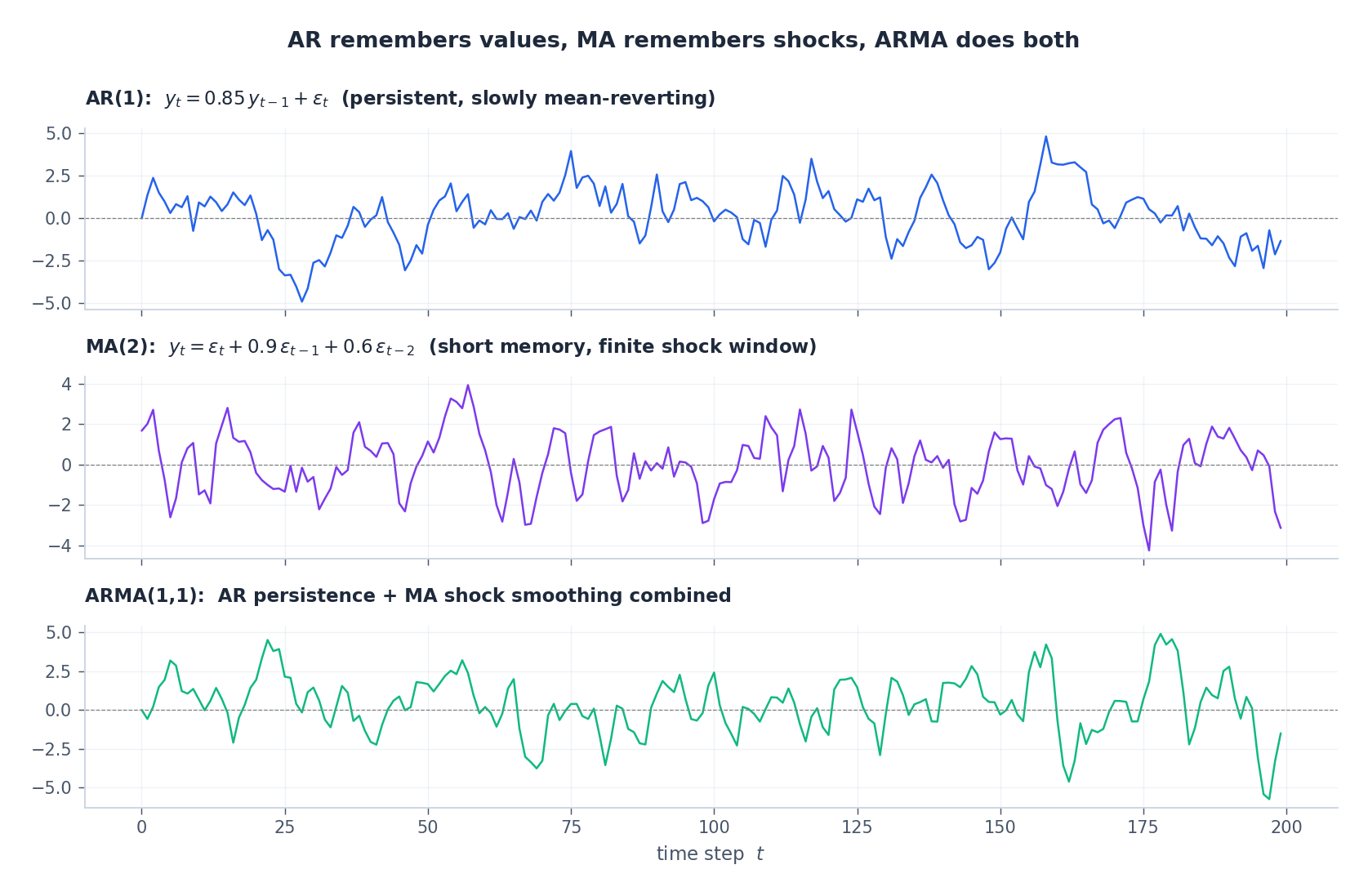
自回归模型:AR($p$ )#
$$y_t = c + \phi_1 y_{t-1} + \phi_2 y_{t-2} + \cdots + \phi_p y_{t-p} + \varepsilon_t.$$当前值是过去 $p$ 个观测值的线性组合,再加上一个白噪声冲击 $\varepsilon_t \sim \mathcal{N}(0, \sigma^2)$ 。持久性直接编码在系数 $\phi_k$ 中。例如,当 $\phi_1$ 接近 1 时,AR(1) 会产生一条非常平滑、缓慢向均值回归的轨迹。
移动平均模型:MA($q$ )#
$$y_t = \mu + \varepsilon_t + \theta_1 \varepsilon_{t-1} + \theta_2 \varepsilon_{t-2} + \cdots + \theta_q \varepsilon_{t-q}.$$当前值是最近 $q$ 个冲击的线性组合。其记忆窗口是有限的:超过 $q$ 步之前的事件对当前值没有直接影响。
组合模型:ARMA($p$ , $q$ )#
$$\phi(B)\, y_t = \theta(B)\, \varepsilon_t,$$ $$ \phi(B) = 1 - \phi_1 B - \cdots - \phi_p B^p, \qquad \theta(B) = 1 + \theta_1 B + \cdots + \theta_q B^q. $$ARMA 的优势在于简洁性:一组较小的 $(p, q)$ 即可模拟 MA($\infty$ ) 或 AR($\infty$ ) 的自相关结构。为保证平稳性,$\phi(B) = 0$ 的所有根必须位于单位圆外;为保证可逆性,$\theta(B)$ 也需满足相同条件。
从 ARMA 到 ARIMA#
$$\phi(B)\, (1-B)^d\, y_t = \theta(B)\, \varepsilon_t.$$实践中,$d = 1$ 足以处理线性趋势,$d = 2$ 可应对曲率变化;极少需要 $d > 2$ 。
ACF 和 PACF —— 模型识别的显微镜#
如何确定 $p$ 和 $q$ ?两张诊断图通常就足够了。
- 自相关函数(ACF):$\rho_k = \mathrm{Corr}(y_t, y_{t-k})$ 。
- 偏自相关函数(PACF):在剔除 $y_{t-1}, \ldots, y_{t-k+1}$ 的线性影响后,$y_t$ 与 $y_{t-k}$ 的相关性。
Box-Jenkins 提出的识别规则如下:
| 过程 | ACF | PACF |
|---|---|---|
| AR($p$ ) | 拖尾(平滑衰减) | 在滞后 $p$ 后截断 |
| MA($q$ ) | 在滞后 $q$ 后截断 | 拖尾 |
| ARMA($p$ , $q$ ) | 拖尾 | 拖尾 |
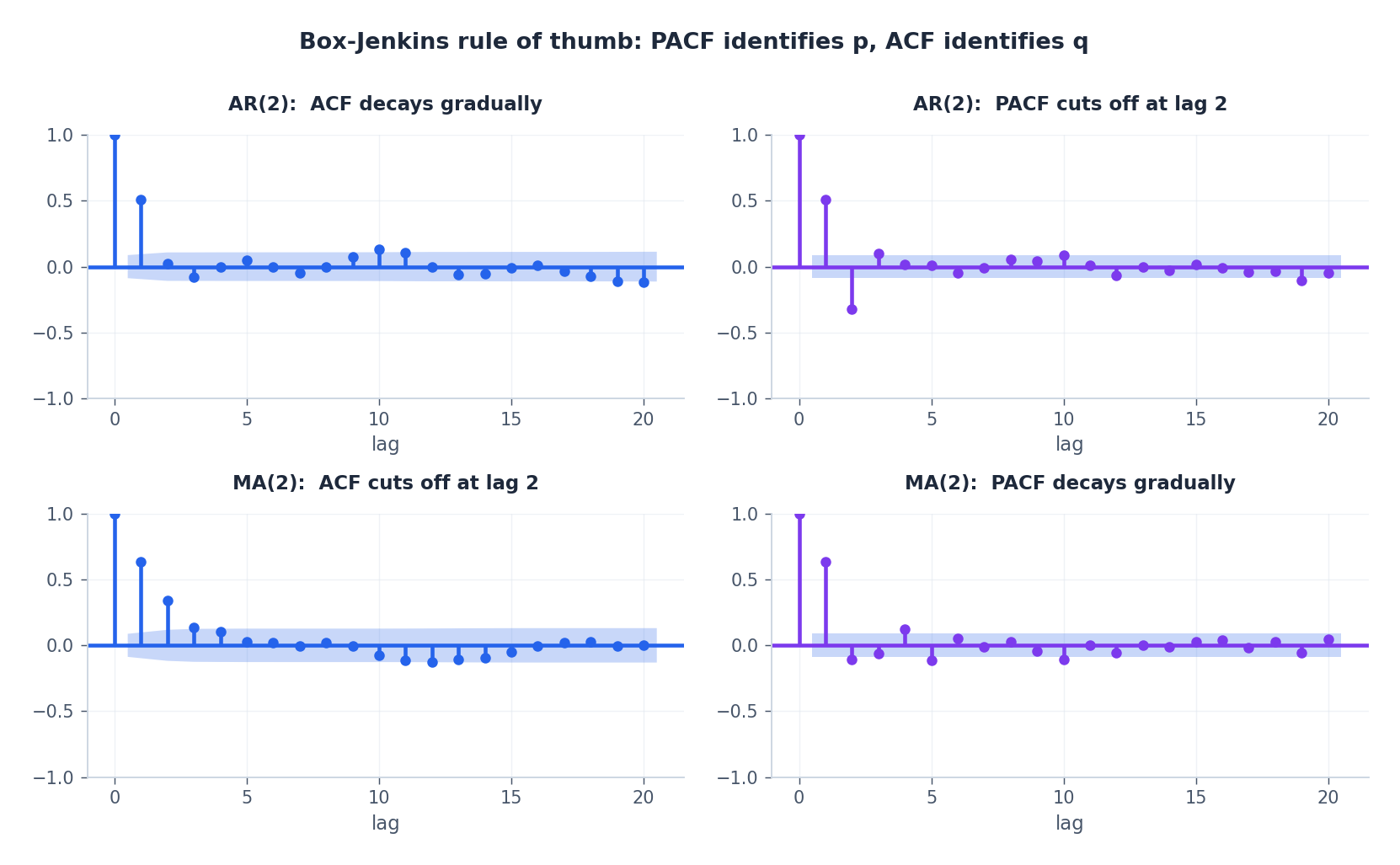
当两张图均无清晰截断点时,很可能面对的是 ARMA 过程。此时最稳妥的做法是对 $(p, q)$ 进行网格搜索,并选择使信息准则最小的组合。
AIC 与 BIC#
$$ \mathrm{AIC} = -2\,\ell(\hat{\theta}) + 2k, \qquad \mathrm{BIC} = -2\,\ell(\hat{\theta}) + k\log n, $$其中 $\ell$ 为最大化对数似然值,$k$ 为自由参数数量,$n$ 为样本量。BIC 对复杂度的惩罚更重,因此在样本量较小时更为稳妥。
Box-Jenkins 工作流#
ARIMA 并非一次性拟合,而是一个由 Box 与 Jenkins 于 1970 年形式化的迭代循环。如今所有主流统计预测工具(包括 auto.arima)本质上都是对这一流程的自动化。
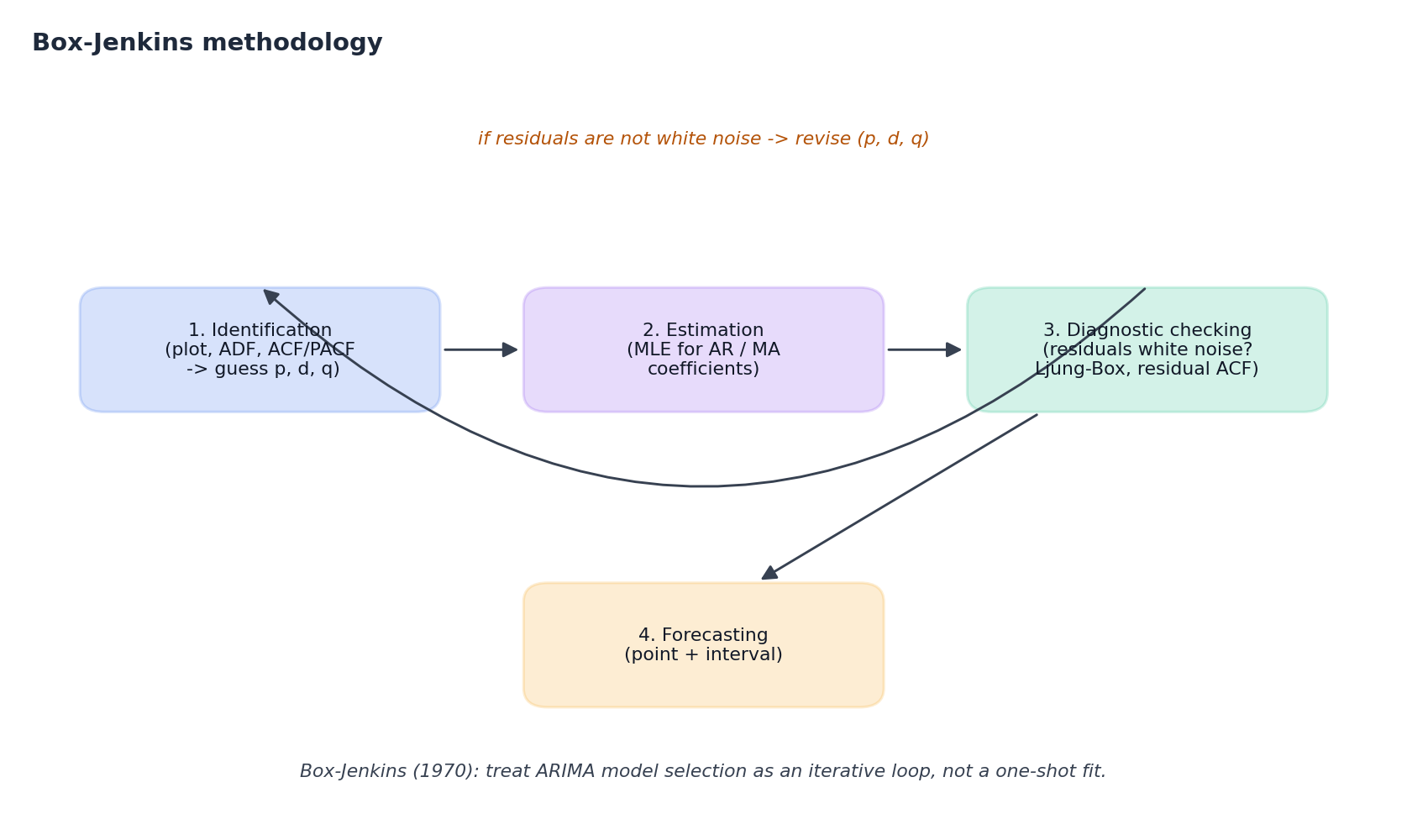
- 识别:绘制序列图,用 ADF 检验平稳性,分析 ACF/PACF,提出候选 $(p, d, q)$ 。
- 估计:通过极大似然或条件最小二乘法拟合模型。主流库均可自动完成。
- 诊断检验:检查残差是否为白噪声:
- Ljung-Box 统计量 $Q = n(n+2)\sum_{k=1}^h \hat{\rho}_k^2 / (n-k)$ 应无法拒绝 $H_0$ 。
- 残差 ACF 应落在 $\pm 1.96/\sqrt{n}$ 的置信带内。
- QQ 图与 Jarque-Bera 检验用于验证正态性(这对预测区间至关重要)。
- 预测:仅当残差“干净”时,才生成点预测与区间预测。
ARIMA 的代码实现#
使用 statsmodels 的一个忠实而简洁的实现示例:
| |
对留出尾段的预测效果如下:
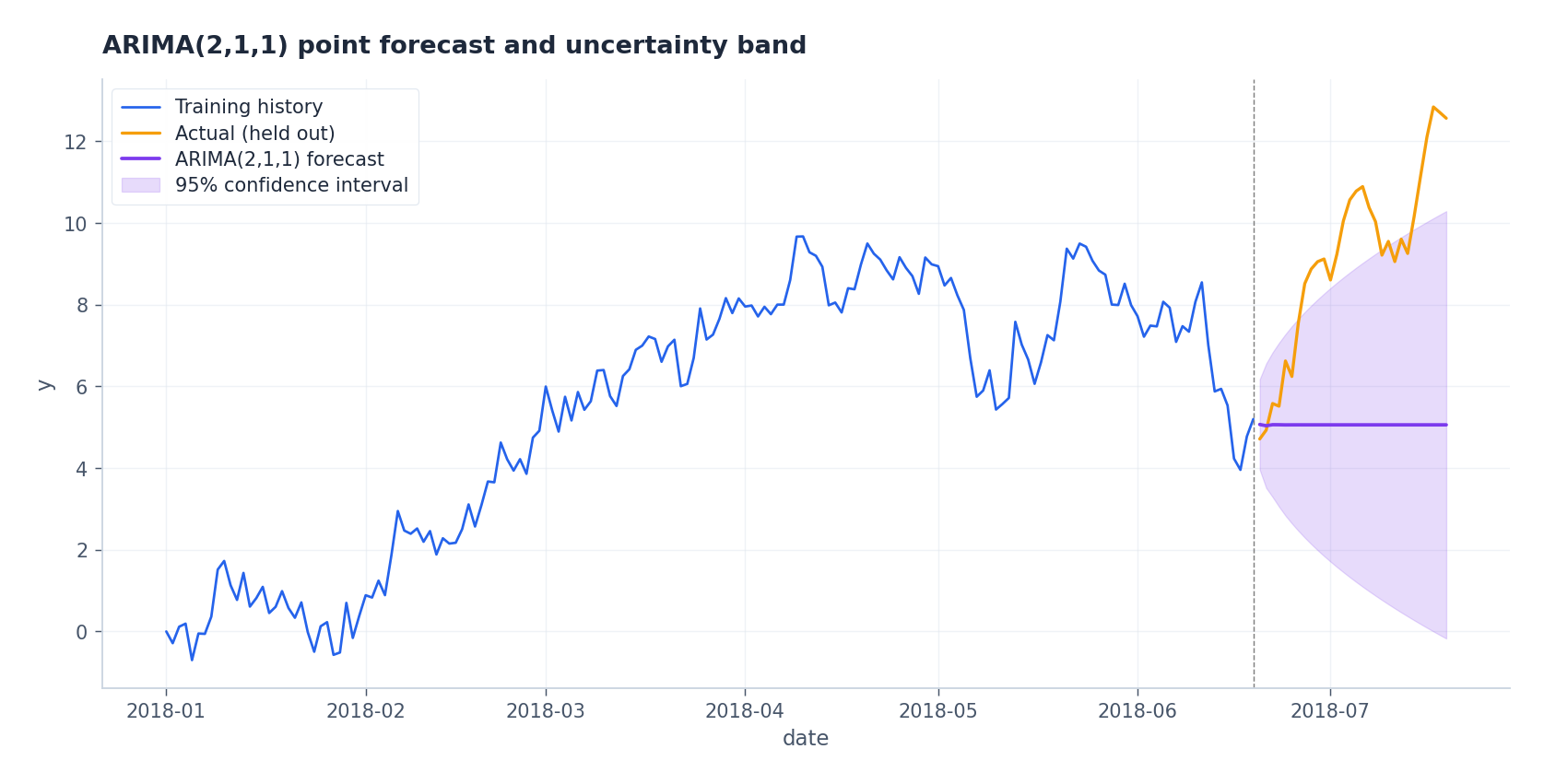
季节性:SARIMA#
$$\Phi(B^s)\, \phi(B)\, (1-B)^d (1-B^s)^D y_t \;=\; \Theta(B^s)\, \theta(B)\, \varepsilon_t.$$这里需进行两类差分:常规差分 $(1-B)$ 处理趋势,季节差分 $(1-B^s)$ 处理周期性。随后,在常规滞后和 $s$ 的整数倍滞后上分别添加 AR/MA 项。
| |
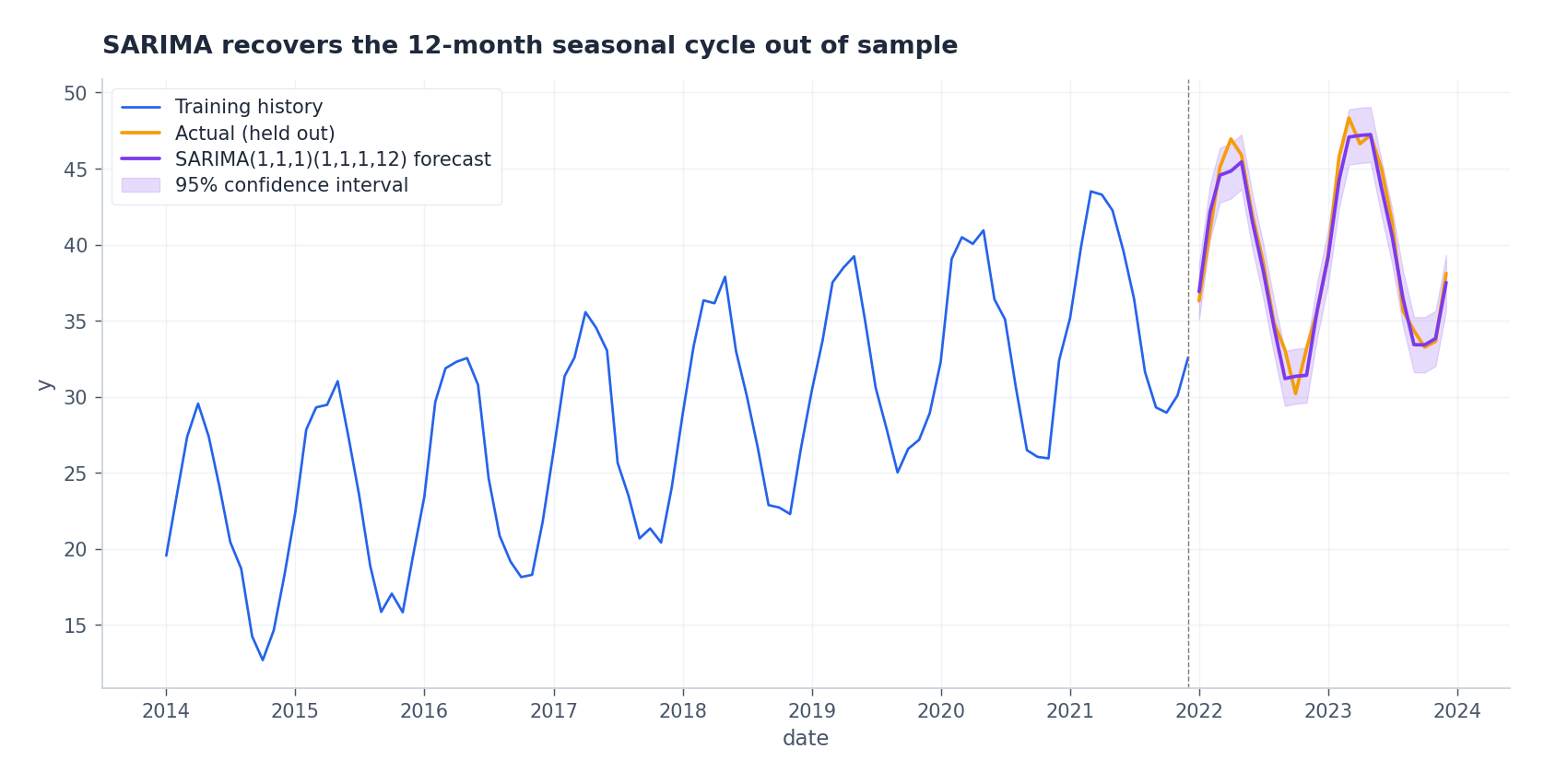
季节部分识别速查表:对季节差分后的序列,在滞后 $s, 2s, 3s, \ldots$ 处观察 ACF/PACF。判断截尾或拖尾的规则与非季节情形一致。
超越 ARIMA:家族其他成员#
前述思想可沿四个方向自然延伸。它们并非孤立体系,而是对 ARIMA 在特定维度上的专门化。
VAR —— 多元动态#
$$\mathbf{y}_t = \mathbf{c} + A_1 \mathbf{y}_{t-1} + A_2 \mathbf{y}_{t-2} + \cdots + A_p \mathbf{y}_{t-p} + \boldsymbol{\varepsilon}_t.$$矩阵 $A_k$ 的每个元素 $(A_k)_{ij}$ 表示变量 $j$ 在滞后 $k$ 时对变量 $i$ 当前值的边际影响。这使得 VAR 在宏观经济学中广受欢迎,因为Granger 因果性(“除 $y$ 自身历史外,$x$ 是否有助于预测 $y$ ?”)正是其核心问题。
但需注意:对于 $K$ 个变量和滞后阶数 $p$ ,模型包含 $K + pK^2$ 个自由参数。当 $K = 10, p = 4$ 时,参数已达 410 个,而观测可能仅数百。因此,高维场景下常采用贝叶斯 VAR 或因子模型等正则化变体。
GARCH —— 方差动态#
$$ \sigma_t^2 = \omega + \alpha\, \varepsilon_{t-1}^2 + \beta\, \sigma_{t-1}^2, \qquad \varepsilon_t = \sigma_t\, z_t,\quad z_t \sim \mathcal{N}(0, 1). $$$\alpha$ 项使昨日的大冲击推高今日方差(即“ARCH 效应”),$\beta$ 项赋予方差持续性。平稳性要求 $\alpha + \beta < 1$ ,而金融数据中该和通常接近 0.95–0.99——表明波动率变化缓慢。
GARCH 是风险管理(VaR、期权定价)的标准工具,常与 ARIMA 均值模型联用:先用 ARIMA 拟合收益率,再用 GARCH 拟合残差平方。
指数平滑与 Holt-Winters#
$$\ell_t = \alpha\, y_t + (1-\alpha)\, \ell_{t-1}.$$ $$ \ell_t = \alpha (y_t - s_{t-s}) + (1-\alpha)(\ell_{t-1} + b_{t-1}),\\ b_t = \beta(\ell_t - \ell_{t-1}) + (1-\beta) b_{t-1},\\ s_t = \gamma(y_t - \ell_t) + (1-\gamma) s_{t-s}. $$这是 R 与 statsmodels 中 ETS 家族的核心,也是多次 M 竞赛优胜方法的源头。
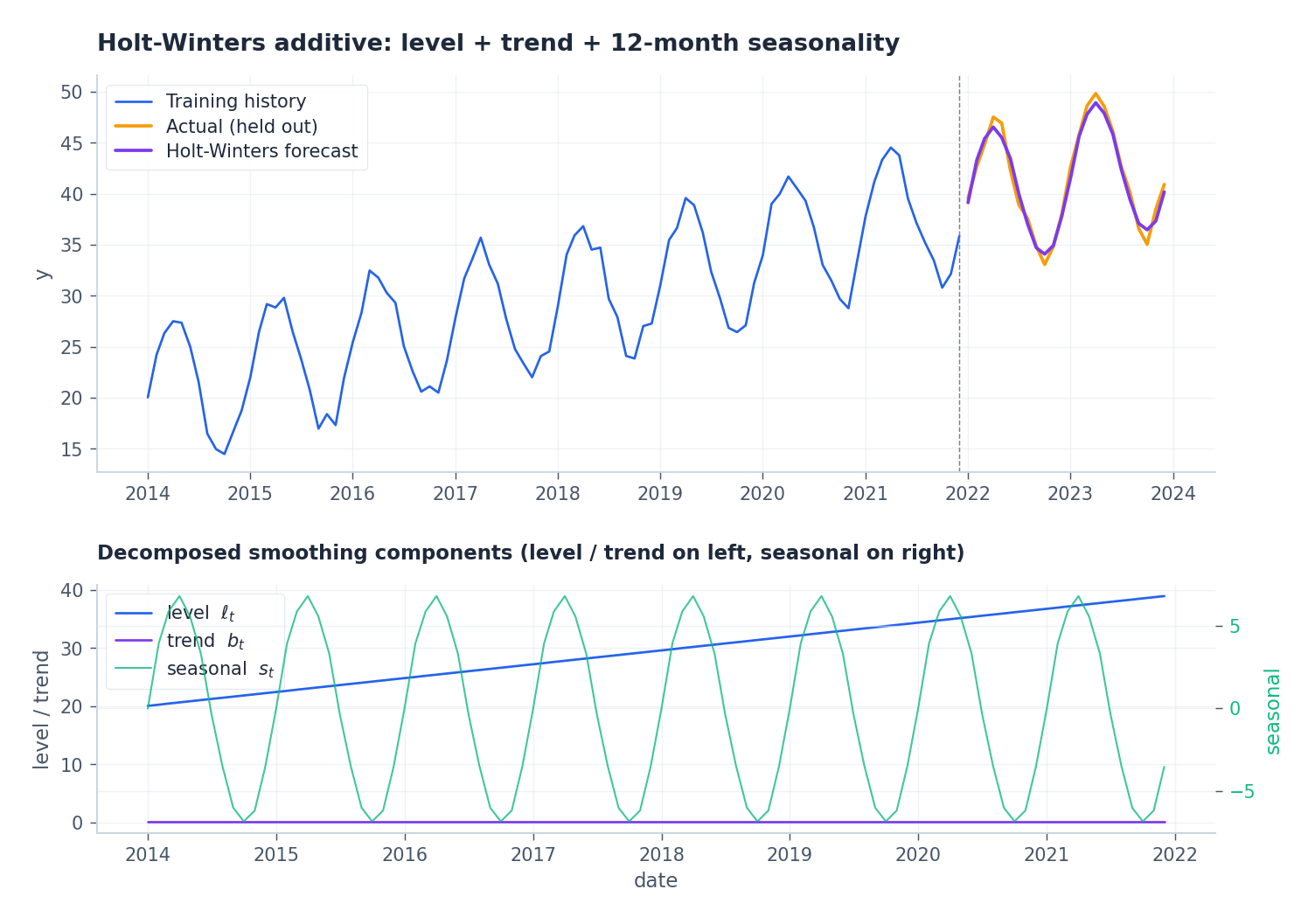
Prophet#
$$y(t) = g(t) + s(t) + h(t) + \varepsilon_t,$$其中 $g(t)$ 是带变点的分段线性或逻辑趋势,$s(t)$ 通过傅里叶级数建模多重季节性,$h(t)$ 编码用户指定的节假日。它通过 Stan 进行 MAP 或全贝叶斯拟合,仅暴露少量超参,且对缺失值与离群点鲁棒。尽管在基准测试中并非顶尖,但其 API 友好性和节假日处理能力使其成为产品分析的默认选择。
卡尔曼滤波与状态空间视角#
$$ \mathbf{x}_t = F_t \mathbf{x}_{t-1} + \mathbf{w}_t, \qquad \mathbf{w}_t \sim \mathcal{N}(0, Q_t),\\ \mathbf{y}_t = H_t \mathbf{x}_t + \mathbf{v}_t, \qquad \mathbf{v}_t \sim \mathcal{N}(0, R_t). $$ $$ \hat{\mathbf{x}}_{t|t-1} = F_t\, \hat{\mathbf{x}}_{t-1},\\ P_{t|t-1} = F_t\, P_{t-1}\, F_t^\top + Q_t,\\ K_t = P_{t|t-1} H_t^\top (H_t P_{t|t-1} H_t^\top + R_t)^{-1},\\ \hat{\mathbf{x}}_t = \hat{\mathbf{x}}_{t|t-1} + K_t (\mathbf{y}_t - H_t \hat{\mathbf{x}}_{t|t-1}),\\ P_t = (I - K_t H_t)\, P_{t|t-1}. $$其意义在于:ARIMA、指数平滑、动态回归、带季节哑变量的结构模型——均可嵌入此框架,并自动继承卡尔曼递推的优势。这正是 statsmodels 的 SARIMAX 底层实现机制,也是它能无缝处理缺失观测与外生变量的原因。
如何选择模型#
| 模型 | 最佳适用场景 | 应避免场景 |
|---|---|---|
| ARIMA | 单序列、线性自相关、无日历效应 | 强季节性或多输入 |
| SARIMA | 单一明显季节周期、中等长度 | 多重季节性叠加 |
| VAR | 多个平稳序列间存在反馈 | 高维($K \gtrsim 10$ ) |
| GARCH | 收益率/波动率数据、波动聚集 | 平滑且方差恒定的序列 |
| Holt-Winters / ETS | 强季节性基线、需快速重训 | 高度非线性或机制切换 |
| Prophet | 含节假日、缺失数据的业务序列 | 亚日级高频数据 |
| Kalman / 状态空间 | 在线更新、缺失数据、自定义结构 | 数据充足且可接受黑箱 |
实用建议:先以 ETS 或 SARIMA 作为基线;若关注方差,则叠加 GARCH;仅当残差呈现明显非线性结构,或拥有大量并行序列需共享信息时,才转向深度模型(LSTM、TCN、Transformer、N-BEATS、Informer——详见本系列后续文章)。
局限与下一步#
传统模型在以下情形中会触及天花板:
- 动态过程非线性(如机制切换、阈值效应、硬饱和);
- 需处理数百至数千条并行序列并共享参数;
- 相关上下文窗口极长,ARMA 根无法简洁表示;
- 信号分布严重非高斯,连 Box-Cox 变换也无能为力。
这正是后续七篇文章的起点。我们将从 LSTM(非线性序列建模的经典)开始,逐步深入 GRU、注意力机制、Transformer、TCN、N-BEATS,最终抵达专为超长序列设计的 Informer。每个深度模型都可视为对前述某类线性模型的扩展。请始终将 ARIMA / SARIMA / Holt-Winters 视为必须超越的基线,而非可以跳过的过去。
下一步#
到这里你已经手握一整套经典武器:ARIMA 处理均值动态、GARCH 处理波动率、Prophet 处理强季节性、卡尔曼滤波处理状态空间。这套工具在结构清晰、样本充足、不需要捕捉非线性交互的场景下,往往比深度模型更稳、更可解释、调参也更便宜。
但它们也有明确的失效边界:变量之间存在复杂非线性关联时(比如多传感器互相影响)、序列特别长(几千步以上)、或者你需要一个统一的模型同时预测几十万条不同的序列时——经典模型就开始力不从心了。这正是后续几章要解决的。
下一篇我会从最基础的循环神经网络出发,重点讲 LSTM :它如何用门控机制在长序列上保留有用的信息、消除梯度消失,以及为什么它在 2015-2018 年成为深度学习处理时序数据的事实标准。如果你目前的项目还在 ARIMA 阶段就够用,建议先把本章的 ACF/PACF 诊断流程练熟——它在后面任何模型上都用得着,包括用来检查深度模型的残差。
参考文献#
- Box, G., Jenkins, G., Reinsel, G., & Ljung, G. (2015). Time Series Analysis: Forecasting and Control (5th ed.). Wiley.
- Hamilton, J. D. (1994). Time Series Analysis. Princeton University Press.
- Hyndman, R. J., & Athanasopoulos, G. (2021). Forecasting: Principles and Practice (3rd ed.). OTexts. https://otexts.com/fpp3/
- Durbin, J., & Koopman, S. J. (2012). Time Series Analysis by State Space Methods (2nd ed.). Oxford University Press.
- Engle, R. F. (1982). Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econometrica, 50(4), 987–1007.
- Bollerslev, T. (1986). Generalized autoregressive conditional heteroskedasticity. Journal of Econometrics, 31(3), 307–327.
- Taylor, S. J., & Letham, B. (2018). Forecasting at scale. The American Statistician, 72(1), 37–45.