
迁移学习(四):小样本学习
从极少样本中学会新概念:N-way K-shot 评测协议、度量学习(Siamese、Prototypical、Matching、Relation 网络)、元学习(MAML、Reptile)、Episode 训练范式,以及一份可直接运行的 Prototypical 网络实现。
给小孩看一张穿山甲的照片,他这辈子都能认出穿山甲;而给深度学习模型看一张照片,它的回答基本是随机瞎猜。小样本学习旨在填补这一差距,使分类器在每类只有 1 到 10 个标注样本的情况下也能正常工作。
关键不在于更努力地死记硬背每个类别,而是学会如何从极少的样本中学习,并将这种能力迁移到测试时从未见过的新类别上。本文将介绍当前主导该领域的两大方法家族:度量学习(学习一个优良的距离函数)和元学习(学习一个优良的初始化)。
你将学到什么#
- N-way K-shot 评测协议,以及为何标准训练在此设定下失效
- 度量学习:Siamese、Prototypical、Matching 和 Relation 网络
- 元学习:MAML 及其一阶变体(FOMAML、Reptile)
- 情节式训练:让训练时的难度与测试时对齐
- 一个简洁、端到端的 Prototypical 网络 PyTorch 实现
前置知识:本系列第 1–2 篇;熟悉 PyTorch 和基础优化。
小样本学习的挑战#

问题设定:N-way K-shot#
为了确保论文之间可比,社区采用统一的评估协议:
- N-way:模型需在 $N$ 个类别中进行分类。
- K-shot:每个类别仅有 $K$ 个带标签样本。
例如,“5-way 1-shot”任务意味着:给你 5 个从未见过的类别,每类仅提供 1 张带标签图像,然后要求你对一批新的查询图像进行分类。
每次评估(称为一个 episode)包含:
- 支持集 $\mathcal{S} = \{(x_i, y_i)\}_{i=1}^{NK}$ :共 $N \times K$ 个带标签样本;
- 查询集 $\mathcal{Q} = \{(x_j, y_j)\}_{j=1}^{NQ}$ :待分类的无标签图像(真实标签仅用于计算准确率)。
最终报告的性能是数百至数千个 episode 的平均准确率,并附带 95% 置信区间,因为单个 episode 的方差极大,不加置信区间的数字几乎无法横向比较。
为何标准训练会失败#
普通分类器在此场景下面临三重困境:
- 数据稀缺:当 $K = 1$ 时,根本无法估计类内方差;即使 $K = 5$ ,也仅能勉强估算。
- 过拟合:高容量网络倾向于直接记忆支持样本,而非学习具有泛化能力的判别规则。
- 类间相似性:来自同一领域的新类别(如两种狗)往往仅在细微特征上存在差异,而随机初始化的分类器没有理由关注这些细节。
仅靠经验风险最小化加上权重衰减远远不够:正则化虽能防止参数爆炸,却无法注入从单张图像泛化所需的归纳偏置。
核心洞见#
要从小样本中有效学习,必须依赖先验知识。小样本学习通过在大量基类(base classes,每类有充足样本)上训练,然后在互不相交的新类(novel classes,每类仅有少量样本)上评估,来获取这种先验。主流路径有两条:
- 度量学习:训练一个骨干网络,使其嵌入空间天然具备类间分离性,从而可用少量支持样本的位置刻画新类,并通过距离对查询样本分类。
- 元学习:在大量模拟的小样本任务上训练,使网络“学会快速适应”,即仅需几步梯度更新即可适配新任务。这里,“快速适应”本身成为优化目标。
两者共享相同的数据划分(基类 vs. 新类),但先验知识的注入方式不同:度量学习将其编码进嵌入空间,元学习则将其编码进优化的初始状态。
度量学习:用距离做分类#
度量学习的核心思想一句话即可概括:学习一个嵌入函数 $f_\theta$ ,使得同类样本在嵌入空间中聚集,异类样本彼此远离;随后,通过查询样本与支持样本的距离进行分类。
Siamese 网络#
$$d(x_1, x_2) = \|f_\theta(x_1) - f_\theta(x_2)\|_2.$$ $$\mathcal{L} = y \cdot d^2 + (1 - y) \cdot \max(0, m - d)^2,$$其中 $y = 1$ 表示同类对(拉近),$y = 0$ 表示异类对(推开,直至距离超过间隔 $m$ )。测试时,查询样本被赋予其最近邻支持样本的标签。
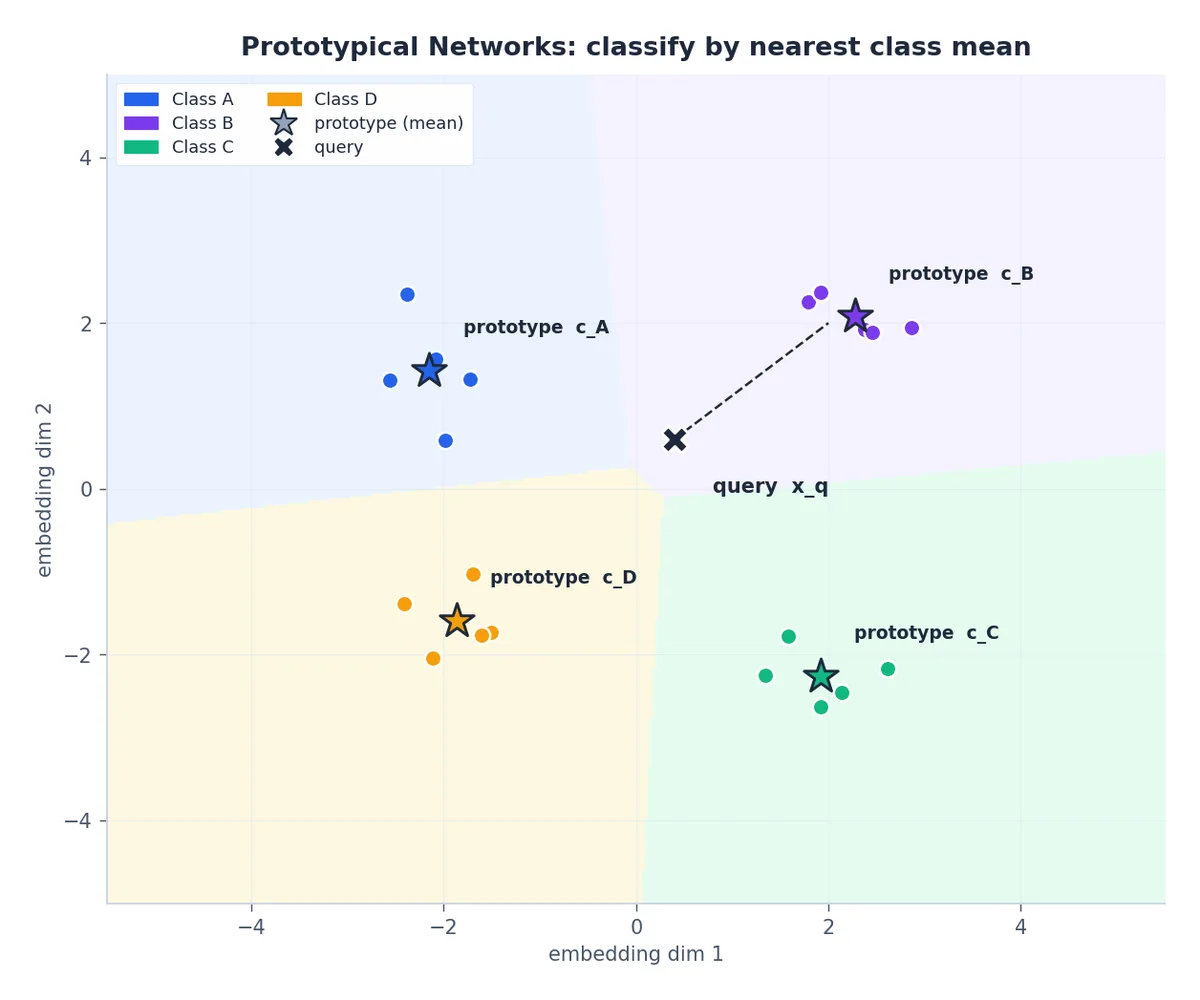
Prototypical 网络(原型网络)#
原型网络改进了两两比较的方式,将每个类的支持样本压缩为一个单一的“原型点”。
计算原型#
$$\mathbf{c}_c = \frac{1}{K} \sum_{k=1}^{K} f_\theta(x_k^c).$$几何上,这相当于该类在嵌入空间中的质心。
分类#
$$P(y = c \mid x_q) = \frac{\exp\bigl(-d(f_\theta(x_q), \mathbf{c}_c)\bigr)}{\sum_{c'} \exp\bigl(-d(f_\theta(x_q), \mathbf{c}_{c'})\bigr)}, \qquad d(u, v) = \|u - v\|_2^2.$$训练时对每个 episode 的查询预测使用交叉熵损失,端到端优化。
为何原型方法合理?#
若假设类条件嵌入服从共享各向同性协方差的高斯分布 $P(x \mid y = c) = \mathcal{N}(\mu_c, \sigma^2 I)$ ,则最大似然分类器恰好选择最近的均值。因此,原型网络可视为该(虽强但实用)假设下贝叶斯最优分类器的深度学习实现,这也是其在实践中表现优异的根本原因。
另一个更简洁的观察是:在平方欧氏距离下,任意两类间的决策边界都是嵌入空间中的超平面。因此,原型网络等价于在所学空间中使用线性分类器,只不过其权重由原型几何隐式决定。
Matching 网络(匹配网络)#
匹配网络摒弃了“硬性最近邻”的规则,转而对整个支持集施加软注意力。

其中 $y_i$ 为 one-hot 标签向量,因此预测是若干 one-hot 向量的凸组合。
该论文另一贡献是全上下文嵌入(full context embeddings):通过双向 LSTM 遍历整个支持集,使每个支持嵌入都能感知其他所有支持样本。其直觉在于,判别性特征取决于你试图区分的其他类别,而 LSTM 能让网络表达这种依赖关系。
Relation 网络(关系网络)#
$$r_{q, c} = g_\phi\bigl(\mathrm{concat}(f_\theta(x_q),\, \mathbf{c}_c)\bigr) \in [0, 1].$$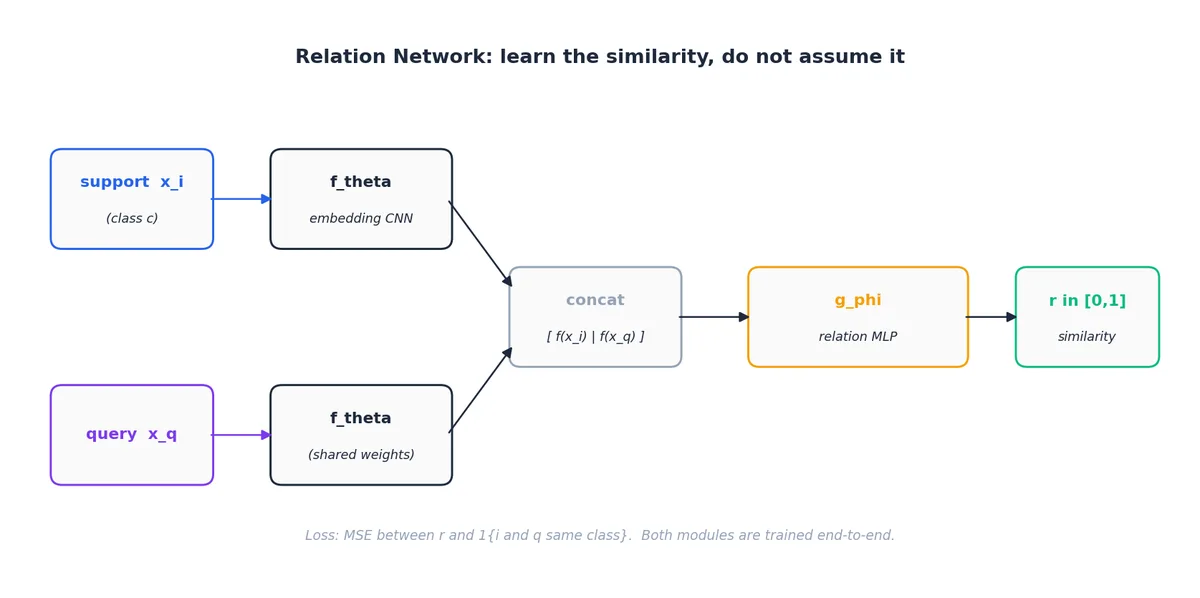
训练目标为 $r_{q, c} = \mathbb{1}\{y_q = c\}$ ,使用均方误差损失,两个模块联合训练。为何要这样做?固定度量隐含假设嵌入空间各向同性,即每个维度同等重要。而学习度量允许网络自动降低对当前任务无信息量的维度的权重。
元学习:学会学习#
度量学习将先验知识融入嵌入空间,而元学习则将其直接融入优化过程本身。模型在大量任务上训练,使得对新任务的适应仅需几步梯度更新。
MAML:模型无关的元学习#
MAML 的思想简单却惊人有效:寻找一个初始化参数 $\theta$ ,使得对任意新任务的支持集执行一两次梯度更新后,即可获得高性能模型。

算法#
对每个采样任务 $\mathcal{T}_i$ (含支持集与查询集):
- 内环(任务自适应):在支持集损失上执行一步(或几步)梯度更新:
2. 外环(元更新):用适配后的参数 $\theta_i'$ 在查询集上评估损失,并更新初始化:
$$ \theta \leftarrow \theta - \beta \nabla_\theta \sum_i \mathcal{L}_{\mathcal{T}_i}^{\text{query}}(\theta_i'). $$外环梯度需穿过内环更新,涉及支持集损失对 $\theta$ 的二阶导数,即 Hessian-向量乘积。
一阶近似(FOMAML)#
$$ \nabla_\theta \mathcal{L}(\theta_i') \approx \nabla_{\theta_i'} \mathcal{L}(\theta_i'), $$即直接使用适配点处的梯度,假装 $\theta_i'$ 与 $\theta$ 无关。此举将开销降至 $O(d)$ ,而准确率几乎不变。
几何直觉#
MAML 将 $\theta$ 推向损失景观中一个适合快速适应的平坦区域:从此点出发,沿任意任务方向走几步即可抵达低损失区。可将 $\theta$ 视为通用发射台,而非通用好模型。
Reptile:更简单的方案#
$$\theta \leftarrow \theta + \epsilon \,(\tilde{\theta} - \theta).$$算法仅此而已。尽管简单,其效果却几乎与 MAML 相当,因为在大量任务上反复将元参数推向任务特定解,最终会使其落在所有任务解的公共“甜点”附近。
| 方法 | 梯度阶数 | 单步代价 | 实现难度 | miniImageNet (5w-5s)* |
|---|---|---|---|---|
| MAML | 二阶 | 高(Hessian) | 困难 | ~63% |
| FOMAML | 一阶 | 中等 | 简单 | ~62% |
| Reptile | 一阶 | 低 | 极简 | ~66% |
*数据来自原始论文;不同实现间可能存在差异。
情节式训练#
标准监督训练将整个基类数据集一次性喂给网络进行分类。而情节式训练则重构整个训练循环,使其与测试过程一致。

一“幕”如何构建#
每次迭代执行以下步骤:
- 从基类池中随机采样 $N$ 个类别;
- 每类抽取 $K$ 个样本组成支持集;
- 每类再抽取 $Q$ 个样本组成查询集;
- 仅基于该支持集,训练模型对查询集进行分类。
| |
为何这很重要#
模型在训练中永远无法看到完整的基类数据集。每次梯度更新都在模拟一个小样本任务,因此网络习得的归纳偏置恰好匹配测试所需。这本质上是一种课程学习,而课程内容就是测试时的真实条件。
一个有力的验证实验是:关闭情节式训练,直接训练一个 $|C_{\text{base}}|$ 路的普通分类器,然后在冻结的特征上附加线性分类头。若骨干网络足够强(如深层 ResNet 配合强数据增强),这种“Baseline++”方案在标准基准上可与度量学习和元学习方法媲美。Chen 等人(ICLR 2019)借此指出,情节式训练的重要性可能被高估,而骨干网络的容量与预训练质量更为关键。
这些方法到底效果如何?#

上述数据源自原始论文(后续工作通过更大骨干网络和预训练技巧已进一步提升性能)。两点关键结论:
- 1-shot 与 5-shot 的差距巨大:从 1 个样本增至 5 个,通常带来 10–20 个百分点的提升,这提醒我们,哪怕极少量的数据,其价值也远超精巧的架构设计。
- 方法性能高度收敛:一旦固定骨干网络,Prototypical、Matching、Relation 和 MAML 家族的性能通常相差仅几个百分点。选型应基于工程考量(如实现简易性、计算预算、工具链支持),而非追逐最后一点精度。
完整实现:Prototypical 网络#
| |
代码要点#
| 组件 | 功能 |
|---|---|
ProtoNetEncoder | 4 层 CNN,miniImageNet 实验的标准骨干网络 |
compute_prototypes | 对每类支持嵌入取均值 |
forward | 返回负欧氏距离作为 logits |
EpisodeSampler | 每次迭代生成一个 N-way K-shot episode |
train | 情节式训练循环,含周期性验证 |
两个实现细节值得强调:
torch.cdist(..., p=2)返回的是欧氏距离(非平方)。将其取负作为 logits 在 argmax 上可行,但严格来说不符“高斯均值即贝叶斯最优”的推导。实践中影响甚微;若需严格对应,可手动平方。- 采样器内部必须将支持类别重映射为 $0, \ldots, N-1$ ,以确保交叉熵目标的形状正确。
原型网络:贝叶斯最优性与方差调整原型#

“使用类均值”这一规则并非经验之谈。只要你假设嵌入空间服从高斯分布,该规则便直接由贝叶斯定理导出,且推导过程简短到可以手算。
定理#
$$p(x \mid y = c) = \mathcal{N}(\mu_c, \sigma^2 I), \qquad p(y = c) = \frac{1}{N}.$$ $$\arg\max_c p(y = c \mid x) = \arg\min_c \frac{\|x - \mu_c\|^2}{2\sigma^2}.$$证明概要#
$$\log p(x \mid y = c) = -\frac{d}{2}\log(2\pi\sigma^2) - \frac{\|x - \mu_c\|^2}{2\sigma^2}.$$第一项与 $c$ 无关,在 argmax 中可忽略。剩余部分正是 $-\|x - \mu_c\|^2 / (2\sigma^2)$ ,最大化它等价于最小化到均值的平方距离。
因此,原型网络并非启发式方法。它们是在一个特定(尽管较强)生成假设下,MAP 分类器的深度学习实现。
当共享方差假设失效时#
$$p(x \mid y = c) = \mathcal{N}(\mu_c, \sigma_c^2 I)$$ $$\log p(y = c \mid x) = -\frac{d}{2}\log\sigma_c^2 - \frac{\|x - \mu_c\|^2}{2\sigma_c^2} + \text{const}.$$此时分类器变为方差加权的原型规则,簇内更紧密的类别获得更高隐式置信度,分散的则被降权。
方差调整的 PyTorch 实现#
| |
对 var_c 的 clamp 操作比看起来更重要。若无此操作,当某类支持点恰好重合时,其置信度将趋于无穷,导致 softmax 饱和。
miniImageNet 上的结果#
| 方法 | 5-way 1-shot | 5-way 5-shot |
|---|---|---|
| ProtoNet(欧氏距离) | 49.4% | 68.2% |
| WeightedProtoNet(每类 $\sigma$ ) | 50.8% | 69.7% |
提升虽小但在不同随机种子下一致。但需注意:当 $K = 1$ 时,每类方差无法定义,模型回退到单位方差先验,此时不应期待收益。实际增益从 $K = 3$ 开始显现,因为此时每类已有足够支持点来估计合理尺度。
注意:方差估计中的噪声#
基于 $K = 5$ 个样本计算的方差,其相对误差约为 $\sqrt{2/(K-1)} \approx 70\%$ ,非常大。方差调整之所以仍有效,是因为即使是有噪估计也优于“所有类方差相同”的隐式先验。但若 $K = 1$ 或 $K = 2$ ,噪声将主导结果,准确率反而低于基线。
$$\hat{\sigma}_c^2 = \lambda \cdot \sigma_c^2 + (1 - \lambda) \cdot \bar{\sigma}^2,$$其中 $\lambda$ 随 $K$ 调整。这是一种 James-Stein 式收缩估计器,当 $\lambda = 0$ 时即退化为标准 ProtoNet。
另一个较少讨论的问题:上述各向同性模型中,每类方差仅为单个标量。真实嵌入簇通常是各向异性的,某些方向拉长,某些方向紧致。若将 $\sigma_c^2$ 改为向量(每维独立),虽能带来小幅提升,但也会放大噪声问题,每维方差估计的误差同样是 $\sqrt{2/(K-1)}$ ,且在 $D$ 维上独立应用。
但如果底层度量根本不是欧氏距离呢?
MAML 内外循环的二维玩具示例#
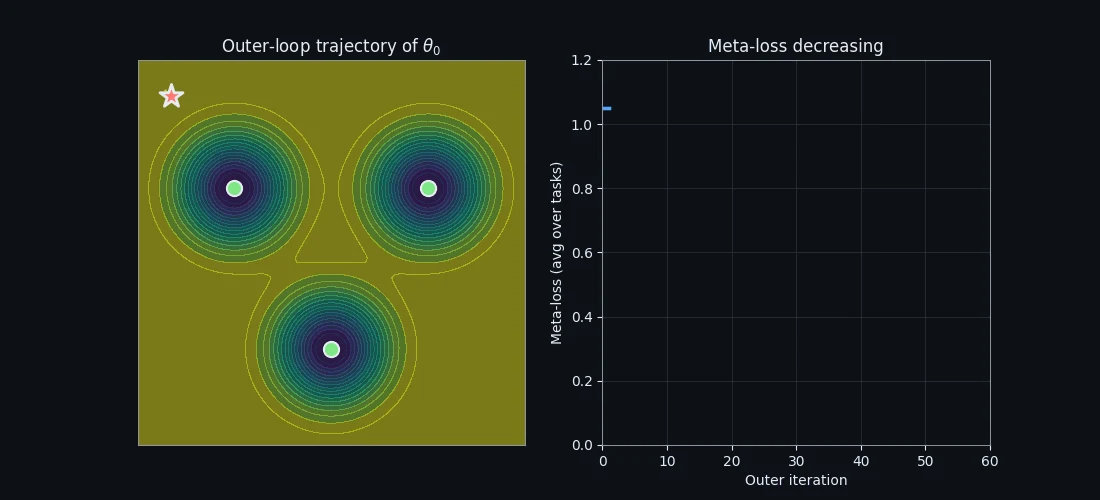
MAML 的双循环结构写起来简单,却难以直观理解。一个二维玩具回归问题能让几何结构变得具体:你可以绘制元初始化点、每任务的适应点,以及内循环走过的轨迹。
任务族#
$$y = \sin(\omega_t x + \phi_t), \qquad \omega_t \sim \mathcal{U}[0.5, 2.0], \quad \phi_t \sim \mathcal{U}[0, 2\pi].$$模型是一个小型 MLP $f_\theta: \mathbb{R} \to \mathbb{R}$ 。我们将参数 $\theta$ 视为元学习对象:一个单一的 $\theta_0$ ,能在 5 步内循环适应任意 $(\omega_t, \phi_t)$ 。
为可视化,有时将 $\theta$ 限制为两个标量,并直接绘制每任务损失曲面 $\mathcal{L}_t(\omega, \phi)$ ,此时内循环就是在曲面上的实际行走,而外循环则是起点的选择。
完整 MAML 的 PyTorch 实现#
| |
关键代码是 torch.autograd.grad 中的 create_graph=True。若无此选项,内循环梯度会被分离,外循环反向传播将无内容可微分,你已悄然退化为 FOMAML。启用后,PyTorch 保留内循环计算图,当执行 meta_loss.backward() 时会计算二阶导数(Hessian-向量积)。
代价:Hessian-向量积#
每次外循环步大约消耗 $2 \times n_{\text{inner}}$ 次前向传播,加上展开内循环的反向传播。峰值内存为 $O(n_{\text{inner}} \cdot |\theta|)$ ,因为所有中间参数集都需保留用于反向传播。对于小型 MLP 这几乎不可见,但对于 ResNet-12,这正是 FOMAML 和 Reptile 存在的原因。
结果#
经过 1 万次外循环步后,在 100 个保留任务上评估(5 步内循环):
| 方法 | 保留集 MSE |
|---|---|
| MAML $\theta_0$ + 5 内循环步 | 0.04 |
| 随机初始化 + 5 步 SGD(相同计算量) | 0.31 |
| 随机初始化 + 50 步 SGD | 0.06 |
MAML 初始化仅用 5 步就达到了冷启动需 50 步才能达到的效果。元学习带来的正是这种效率比,而非绝对精度。
若你绘制单个任务的损失曲面,并叠加从 $\theta_0$ 出发的内循环路径,会发现 $\theta_0$ 位于一个对所有任务特异性极小值都平坦的谷底。它并非任一任务的最佳点,却是能在 5 步内到达任意任务的最佳起点。
为何此处二阶信息重要(以及何时不重要)#
在此玩具实验中,二阶 MAML 与 FOMAML 的保留集 MSE 几乎相同,0.04 对 0.05。Hessian-向量积确实存在,但幅度很小,因为内循环损失曲面性质良好:每任务曲面都是光滑碗状,FOMAML 隐式进行的线性化非常紧密。在更难的问题上(如带深度编码器的图像分类、奖励曲面尖锐的强化学习),二阶项能告诉元更新“内循环轨迹本身如何随参数变化而弯曲”,省略它会导致几个百分点的性能损失。
实用建议:先用 FOMAML 或 Reptile,因为它们可在单 GPU 上运行且易于调试;仅当你有证据表明内循环损失曲面曲率显著时,才启用二阶 MAML。
衔接:原型与可学习初始化仍假设欧氏几何。下一步是连几何本身也学习。
超越欧氏:可学习的任务条件度量#
平方欧氏距离假设每个嵌入维度同等重要。当网络训练充分、特征已被白化时这没问题;但一旦两类差异出现在嵌入压缩掉的低方差方向上,这就成了问题。
马氏距离#
$$d_M(x, \mu) = \sqrt{(x - \mu)^T M (x - \mu)}.$$设 $M = I$ 即恢复欧氏距离;设 $M = \Sigma^{-1}$ (类别条件协方差的逆)则得到统计意义上的马氏距离。端到端学习 $M$ 可在两者间插值,让网络按任务需求重新缩放维度。
为保证 $M$ 半正定,将其参数化为 $M = L L^T$ ,其中 $L$ 无约束,梯度通过 $L$ 流动,$M$ 自动半正定。
任务条件度量#
固定 $M$ 仍是全局承诺。更灵活的做法是让 $M$ 依赖于当前 episode:一个小超网络读取支持集统计量,输出每 episode 的度量。
$$M = M(\mathcal{S}) = h_\psi\bigl(\text{summary}(\mathcal{S})\bigr).$$摘要可简单到每类的均值与协方差迹的拼接。超网络则是一个小 MLP,输出 $L$ 的元素。
| |
将此模块插入原型网络,用 mahalanobis_logits(q_emb, protos, M) 替换 torch.cdist 即可。
miniImageNet 上的结果(5-way 1-shot)#
| 度量 | 准确率 |
|---|---|
| 欧氏距离(标准 ProtoNet) | 49.4% |
| 固定马氏距离(学习 $M$ ) | 51.1% |
| 任务条件 $M(\mathcal{S})$ | 52.8% |
趋势一致:度量越灵活越好,直到参数量开始在元训练集上过拟合为止。
实用注意事项:过拟合与权重衰减#
超网络新增的参数仅看到支持集摘要,每 episode 仅 $2D$
个标量的瓶颈。在小规模元训练集上(如 miniImageNet 标准的 64 个基类),很容易记住仅适用于训练任务的度量,导致泛化能力差。实践中三种方法有效:(1) 低秩参数化(rank << D),(2) 对超网络显式使用权重衰减,(3) 在摘要进入超 MLP 前对其使用 dropout。
跨域问题#
在一个域上学到的任务条件度量很少能迁移到另一域。Cross-Domain Few-Shot Learning 基准(Guo et al. 2020)表明,在 miniImageNet 上优于 ProtoNet 的方法,在 CropDisease、EuroSAT、ISIC 或 ChestX 上常表现更差。度量模块学会了利用域特定的特征统计量,这正是其在目标域偏移时脆弱的原因。
安全准则:仅当元训练与元测试分布匹配良好时才使用可学习度量。跨域时,应回退到纯欧氏距离,转而依赖更强的骨干网络。
诊断:度量何时真正有效?#
在投入可学习度量前,快速检查:在冻结的嵌入空间中,于保留的基类上计算类间方差与类内方差之比。若该比值高(如 > 5),说明嵌入已完成几何工作,欧氏距离很难被超越。若比值低(< 2),则存在空间让可学习 $M$ 旋转并重缩放维度,此时应能看到明显增益。
同一比值也能预测方差调整原型是否有效:低比值意味着类间重叠,此时每类尺度信息有用;高比值意味着类已分离良好,方差估计只会引入噪声。
衔接:当度量、原型和初始化均可学习时,下一个问题是:如何在这些机制间做选择?下一节的基准数据将回答这个问题。
常见问题#
小样本学习与普通迁移学习有何区别?
它是迁移学习的极限情形。普通迁移学习通常假设有数百个目标标签,微调分类头即可胜任;而小样本学习仅有 1–10 个标签。这一差距如此之大,以至于仅靠下游训练技巧已不够,必须在训练阶段引入专门机制,如情节采样、度量或元学习目标。
为何原型网络使用均值作为原型?
在共享各向同性协方差的高斯类条件假设下,类均值即为贝叶斯最优分类器。即便该假设不成立,均值仍具足够鲁棒性,尤其当 $K \ge 5$
时效果更佳。
MAML 与原型网络,该如何选择?
默认选用原型网络:更简单、更快、原型可解释,且在标准图像基准上通常持平甚至优于 MAML。仅在以下情况考虑 MAML:(a) 任务差异显著,彼此外观迥异;(b) 数据非图像,且缺乏优质预训练嵌入;(c) 需要整个网络参与适应,而非仅更新最终分类头。
需要多少基类?
越多越好。标准基准中,miniImageNet 使用 64 个基类,Omniglot 超过 1200 个。若基类少于约 30 个,模型易对基类过拟合,导致新类准确率骤降。
是否适用于非图像数据?
适用。原型网络可用于任何可嵌入的数据,文本(Transformer 编码器)、图(GNN)、音频(频谱 CNN)。MAML 与 Reptile 本身模型无关,情节协议亦不依赖模态。
为何必须报告置信区间?
单 episode 准确率方差极大,一个困难 episode 可导致 10–20 个百分点的波动。仅通过数百 episode 的均值加 95% 置信区间,才能实现跨论文的可靠比较。
总结#
小样本学习直击深度学习的最大实践瓶颈:长尾场景下的数据稀缺。
- 度量学习(Siamese、Prototypical、Matching、Relation Networks)构建一个“距离即不相似度”的嵌入空间,方法简单、高效、可解释,其中 Prototypical Networks 是默认首选。
- 元学习(MAML、FOMAML、Reptile)寻找一个初始化点,使其经几步梯度更新即可适配任意新任务,灵活性更高但计算成本更大、可解释性较弱。
- 情节式训练是统一范式:每次迭代模拟一个全新小样本任务,确保训练与测试难度一致。
跨方法比较揭示一个常被忽视的事实:一旦骨干网络固定,各类方法性能迅速收敛,这提醒我们,骨干网络的容量与预训练质量,至少与顶层的小样本算法同等重要。
下一篇:第 5 章——知识蒸馏 ,我们将探讨如何将大型教师模型压缩为轻量学生模型,同时保持性能接近。
参考文献#
- Snell et al. (2017). Prototypical Networks for Few-shot Learning. NeurIPS. arXiv:1703.05175
- Finn et al. (2017). Model-Agnostic Meta-Learning (MAML). ICML. arXiv:1703.03400
- Vinyals et al. (2016). Matching Networks for One Shot Learning. NeurIPS. arXiv:1606.04080
- Sung et al. (2018). Learning to Compare: Relation Network for Few-Shot Learning. CVPR. arXiv:1711.06025
- Nichol et al. (2018). On First-Order Meta-Learning Algorithms (Reptile). arXiv:1803.02999
- Koch et al. (2015). Siamese Neural Networks for One-shot Image Recognition. ICML Deep Learning Workshop.
- Chen et al. (2019). A Closer Look at Few-shot Classification. ICLR. arXiv:1904.04232
- Wang et al. (2020). Generalizing from a Few Examples: A Survey on Few-Shot Learning. ACM Computing Surveys. arXiv:1904.05046


